这篇文章来介绍一下torch/util/data目录下的一些组件。主要就是torch提供的Dataset和Dataloader
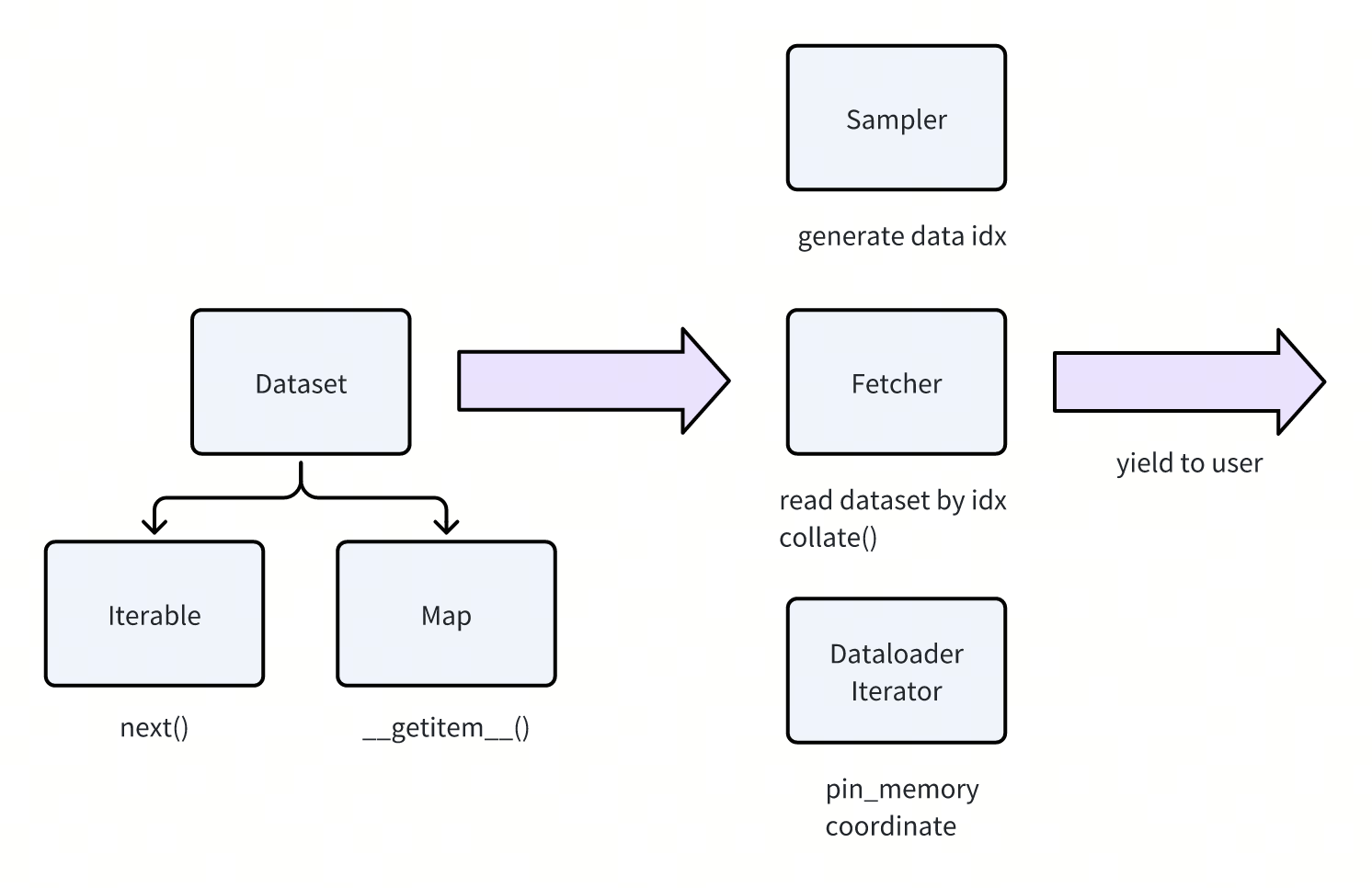
- Dataset负责做抽象数据的访问方式,提供两种Dataset。一般来说对应底层的存储方式
- Map,随机访问,给定index,给出sample
-
Iterable,顺序访问,给定一个iterator,每次next得到sample
-
Dataloader负责做数据的读取,包含三个组件
- Sampler
- 负责生成下一个访问的数据的index,给Map类型的dataset使用
-
支持一个BatchSampler,一次生成一批index
-
Fetcher
- 读dataset的逻辑。做batch读dataset,然后调用collate_fn。合并这一批的数据
- Iterator
- 负责协调Sampler/Fetcher,读取数据,做pin_memory,并把数据返回给用户
- Sampler
Dataset
dataset这里东西比较少,就简单介绍一下torch提供的dataset
核心代码在dataset.py中
两个基类:
- Dataset,需要子类实现__getitem__(index),支持随机访问
- 可以实现__getitems__,用来做加速。需要注意这个getitems是需要自己手动调用的,不是python内置的函数
- IterableDataset,需要子类实现__iter__,返回一个迭代器,流式访问。一般和dataloader配合使用
简单的衍生类:
- TensorDataset
- 传入若干个tensor,返回数据的时候用传入的index索引tensor的第0维。
- StackDataset
- stack多个len相同的dataset,每次返回(dataset1[index], dataset2[index], ...)
-
例子中是text/image做配对
-
ConcatDataset
- 多个dataset concat到一起。
-
实现上就是先根据idx,在前缀和数组上二分一下这个idx属于那个dataset,然后再从具体的dataset里取
-
ChainDatasetSubset
- 用来把多个iterable dataset串一起。
-
实现上就是按顺序yield from dataset
-
Subset
- 随机访问dataset的一个子集。传入原始的dataset,以及一个index的映射
-
返回数据用dataset[indices[idx]]
Dataloader
这里先给出一个大纲,如果感兴趣阅读代码的话,可以关注这些位置:
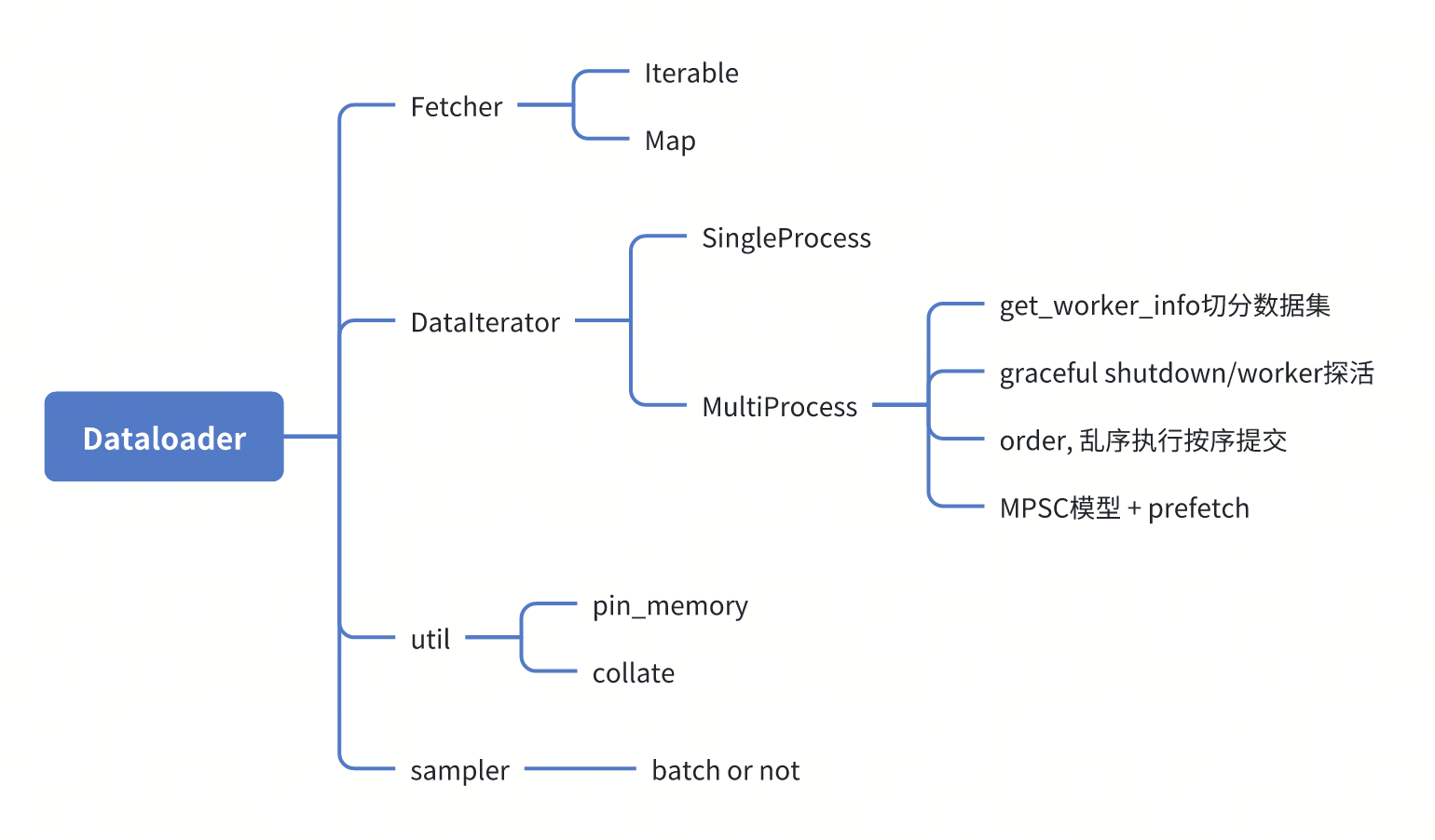
Sampler
sampler要求是map的dataset,因为是生成idx去访问。
对于iterable的dataset,如果也希望做shuffle的话,一般需要在dataset层配合存储方式做一些设计。感兴趣的话可以看看megatron-energon/streaming等项目,后面也会出一篇文章介绍一下
- SequentialSampler
- 按顺序返回,生成一个(0, 1, 2, ...)的iter
- RandomSampler
- 随机采样,采样num_sample个,然后有一个option是replacement,表示是否有放回。
-
如果是没有replacement,那么就直接生成rand perm返回即可。
-
如果是有replacement,就直接做随机数生成即可,保证每次采样独立。
- 这里还分了个块,每次生成32个sample,防止占用过多内存。
- SubsetRandomSampler
- 无replacement,多了一个indices的参数,用来做位置的映射。
-
生成rand perm,然后再用indices重新映射一下作为最终的下标返回出去
-
WeightedRandomSampler
- 带权重的随机采样,也是支持replacement
-
直接调用的torch.multinomial
-
BatchSampler
- 一个sampler的wrapper,用来生成list[int]。也就是一次返回一批index。支持指定一个batch size
- DistributedSampler
- 如果没有启动shuffle,直接用range生成一个list,然后每个rank取自己对应的数据
-
如果启动了shuffle,会在所有的worker上,用相同的seed生成一个相同的random sequence,然后每个rank取自己对应的数据
-
这里生成sequence后,取数据不是用的连续的slice,而是跳着取的
Dataloader Iterator
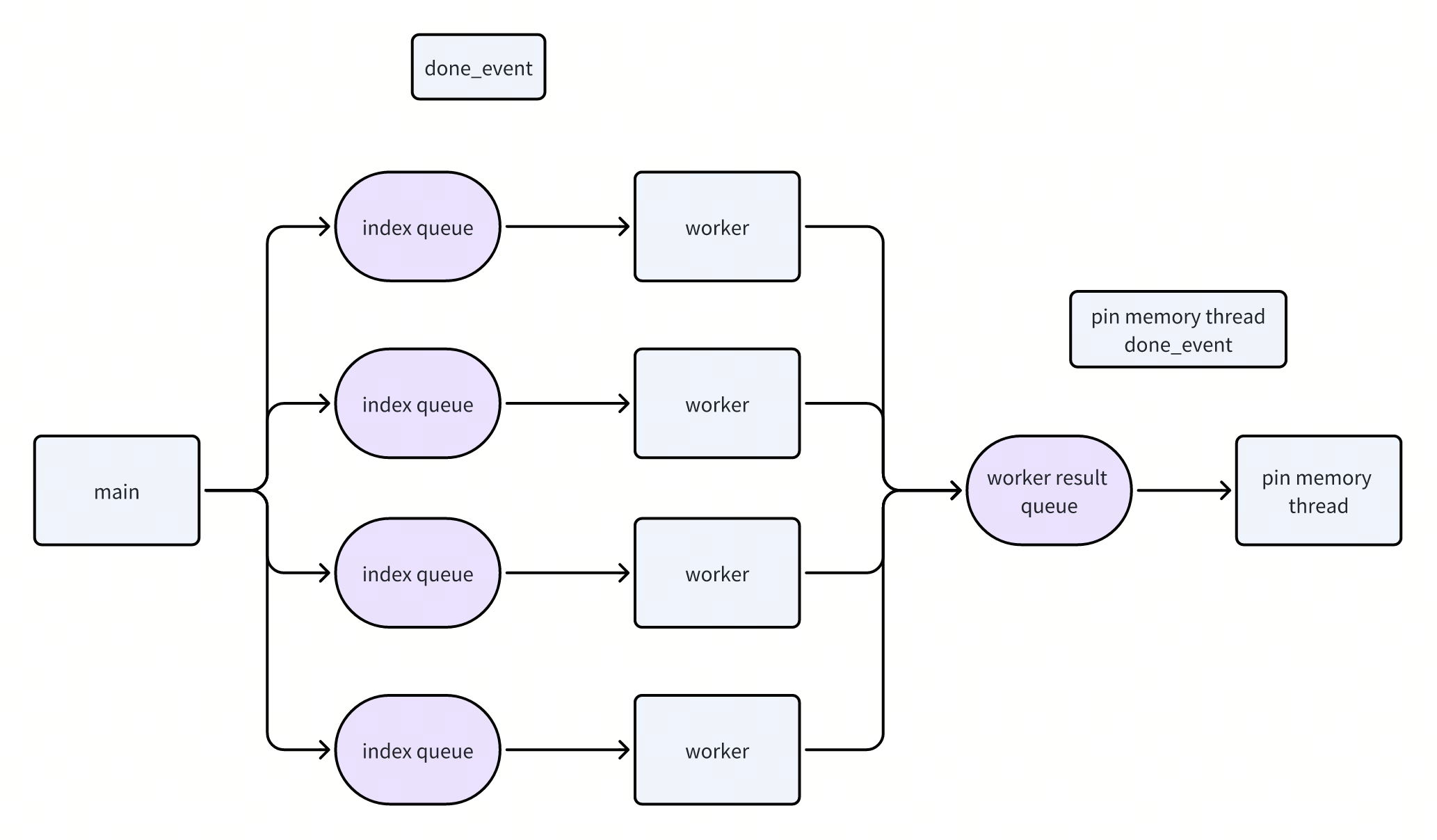
iterator这里主要关注一下多进程的iterator:
- 多进程的工作模型
-
如何做prefetch
-
如何做的worker的graceful shutdown
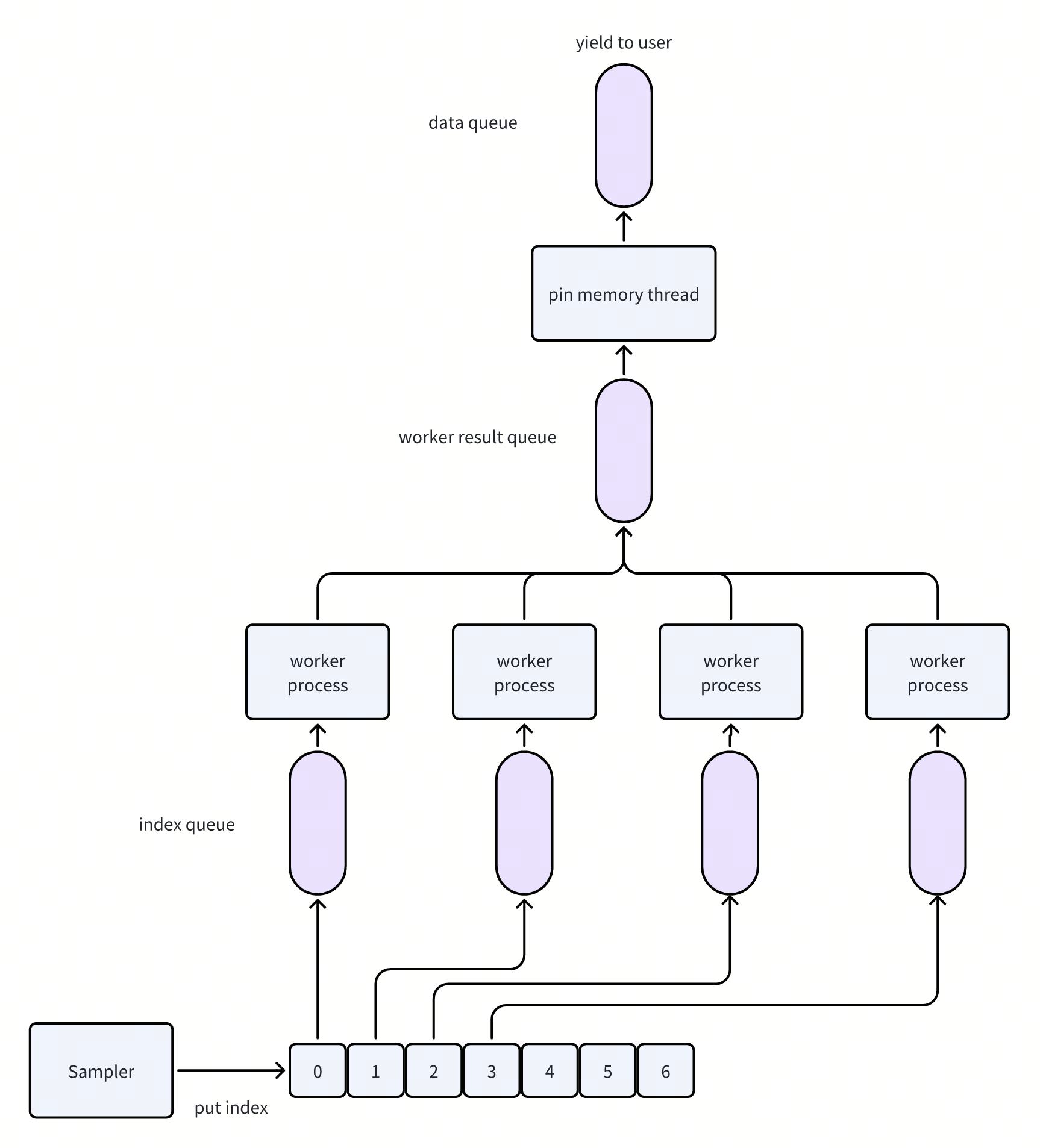
- 有若干个worker process,负责读取数据。i.e. 做IO,collate,以及可能dataset内部还会有一些transform的逻辑
-
一个pin memory thread,把读出来的数据做pin memory
-
主进程,负责从Sampler中拿取要读取的数据index,通过index queue发放给worker。并从data queue中读取数据,yield给用户。
确定好这个模型之后,做prefetch的逻辑就比较简单了:
- 每次读取数据的时候,会预先通过Sampler多取一些index,发放给worker。
-
prefetch的数量通过prefetch factor和worker数量决定
-
默认prefetch factor是2,也就是每个worker会多读两个batch的数据。
使用Dataloader的时候,还有一个in_order的选项。
- 默认是开启的,表示我们会按照Sampler给的idx顺序来读取数据。
- 比如生成了一批index 0, 1, 2, 3。worker0负责index0,worker1负责index1...
-
返回数据的时候也是按照0, 1, 2, 3的顺序给用户
-
如果关闭后,就会变成一个乱序的MPSC,返回数据的顺序是不确定的,那个worker先读完就返回那个worker的数据。
- 对于顺序不敏感的情况,同时worker的负载不均衡的时候比较好用。因为可以选择
不过因为每个worker读取数据的时间是不确定的,所以丢到worker result queue中的数据也是乱序的。在我们开启in_order的情况下,就需要把乱序读取的数据重新排序,转化成顺序的数据返回给用户。
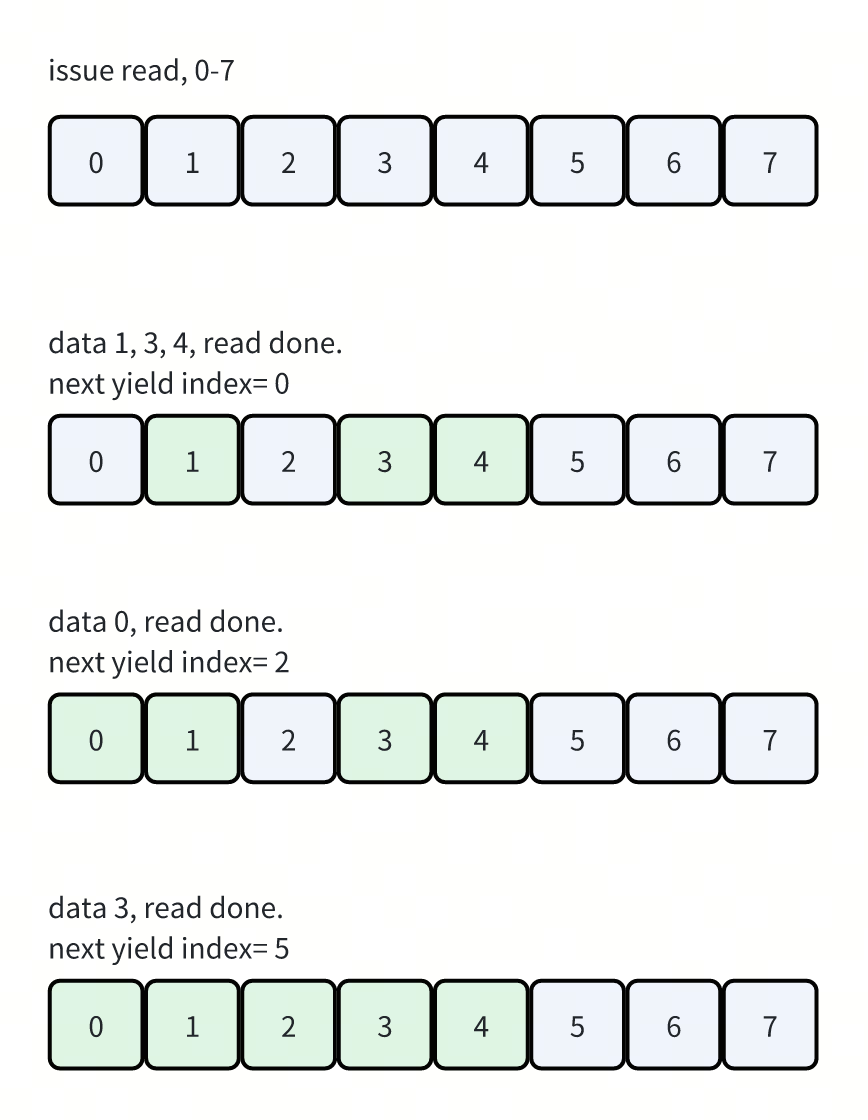
- 维护了一个buffer,记录了每个读请求的状态。看上图
- 初始状态发起请求,都没有读成功。所以此时不能yield任何数据
-
1, 3, 4读取完成后,因为0还没有读,所以还不能yield任何数据
-
0读成功后,0和1都可以进行yield
-
2读成功后,和后面的3,4连起来,就可以yield数据到5了。
这里有一个隐含的设计点:
- in_order的时候,分发task给worker也是round-robin(确定性的)。
- 实际上我们只需要上面的buffer就可以保证乱序转顺序
-
但是这里还是选择了round-robin,是可以确定worker yield数据的顺序
-
因为dataloader涉及到了prefetch,当我们希望做dataloader的ckpt的时候,需要考虑prefetch出来的这些数据。以及每个worker的进度。从而保证在恢复dataloader的时候,能够接上之前的状态。此时就需要能够得知每个worker的状态。
-
所以这里涉及到两个含义:顺序返回数据+确定性的worker的行为。
-
后面在解读megatron-energon的时候会看到这一点
Utils
collate
collate的作用是把一批独立读出来的数据转化成一个batch。同时类型也会被转化为tensor
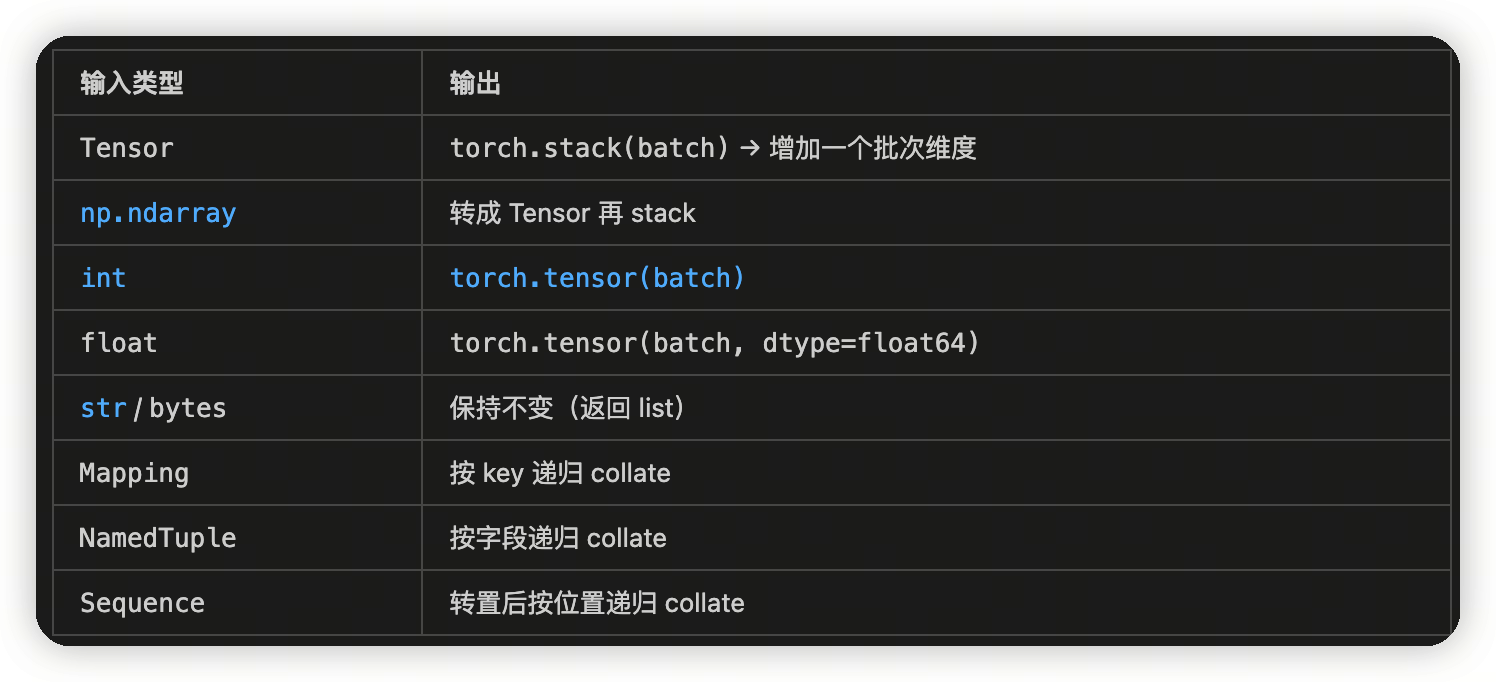
同样支持用户自定义collate函数。
默认的实现中,在collate_tensor_fn中可以看到一个优化点,如果自行实现的话可以借鉴一下:
if torch.utils.data.get_worker_info() is not None:
# If we're in a background process, concatenate directly into a
# shared memory tensor to avoid an extra copy
numel = sum(x.numel() for x in batch)
storage = elem._typed_storage()._new_shared(numel, device=elem.device)
out = elem.new(storage).resize_(len(batch), *list(elem.size()))
return torch.stack(batch, 0, out=out)
- 这里的核心逻辑是判断,如果当前collate的流程在后台,会使用shared_memory来保存这段collate后的数据。避免从worker进程传递到main process的拷贝了
pin_memory
Pin memory的目的就是让内存被pin住,不会被换到磁盘上。
- 因为cpu到GPU传输的时候,会走DMA,需要保证内存有效。所以对于非pinned memory,会拷贝到pinned buffer中,再传输给GPU
-
但是这种pinned memory没有内存池,分配开销较高。所以比较适合批量pin
-
不过实际上调用pin_memory也会发生拷贝,但是只有一次显式调用
Dataloader Graceful shutdown
这块东西比较多,就单独放一节出来。
因为内容涉及到multiprocessing库的一些东西,我没有研究过他的源码,如果解读错了还请各位大佬指正
PytorchDataloader这里有三个角色:
- Main process,负责协调数据读取,返回数据给用户
-
pin_memory_thread,和主进程在一个进程中,负责将读到的数据pin到内存中,加速H2D的传输
-
Worker process,负责做具体数据的读取,和主进程通过mp.Queue进行通信
这里的异常处理逻辑涉及到了main process和worker process,即两个process之间的graceful shutdown,以及main process和pin memory thread,即同一个进程内不同线程的graceful shutdown。
在看Dataloader是如何处理graceful shutdown之前,需要先明确有哪些shutdown的路径:
- 正常情况,此时主进程的Iterator读完,或者不需要再读数据了。主进程还会继续执行,此时外部通过调用Iterator.__del__()来通知Dataloader进行析构
-
主进程退出/解释器退出,比如可能是上层调用了system.exit()。
- 这种情况的主要问题是对象的__del__()不一定会被调用。
-
同时调用时机不确定,因为这个时间很多python的库中的资源都已经被释放了,此时执行逻辑(比如获取锁,join thread)很容易会hang住。
-
进程被fatal signal杀掉,此时甚至不会调用清理逻辑。
- 比如父进程被fatal signal杀掉后,子进程会变成孤儿进程,持续占用资源。
-
同时子进程可能会通过queue读取父进程的数据,导致hang住
然后来看一下Dataloader是怎么处理这几种case的:
首先对于第一种case,正常情况,线程/进程都是在执行正常的逻辑,此时只需要确定一个协议来做进程级别/线程之间的通信即可。
- 这块的逻辑基本就在__del__()中
-
因为没有异常逻辑要处理,所以这块主要是为了兼容后面两种异常情况的。等看完后面两种case,再回来看看这里del的逻辑即可。
对于第二种case,不能依赖__del__的调用,同时因为python corelib的资源都释放了,所以也不应该去调用corelib中的清理逻辑。
这里对每个角色的行为分析一下:
- Main process
- 在__del__逻辑中,判断
python_exit_status,如果是解释器正在做退出,不能后续再去操作multi processing相关的组件了。这里会做noop,然后直接退出 -
Main process和worker process有一个mp.Queue,叫做index queue。里面有一个后台的线程负责把数据buffer起来,发送给另一个进程。multiprocessing._exit_function()中会去join这个thread。
- 在异常退出的情况下,multiprocessing不再可靠,所以不能够去调用这个join。解决的方法就是通过queue.cancel_join_thread(),不去join这个线程,而是等整个进程结束的时候再去释放资源。
-
主进程和worker进程通信的index_queue,会在启动的时候就做cancel_join_thread(),保证主进程不会因为这个join而hang住
-
启动worker/pin memory thread的时候,设置为daemon,避免后续做join
- 在__del__逻辑中,判断
-
Worker process
- 对于worker process,他会有一个watchdog,启动的时候记录一下parent pid,每次循环的时候看一下parent pid是否有变化。如果有变化,说明自己变成了孤儿进程,此时会主动做退出。
-
worker这里的逻辑是可控的,认为没有解释器退出的情况,所以没有做cancel_join_thread(),这种情况下会做后台线程的join
-
Pin memory thread
- 因为是和main process在同一个进程中,主要依赖的是main process整个进程的回收,所以这里没有做特殊的处理。
对于第三种case,考虑成producer/consumer可能任意一个突然挂掉,需要能够探测他们的状态,同时保证读写数据时不依赖对方的状态。(比如不能因为consumer挂了,producer写数据就hang死)
- 探活
- worker中有一个watchdog,上面也写了,会探测自己的parent pid
-
Main process因为启动了worker,持有worker的handle,可以通过worker.is_alive()判断进程状态
-
同样main process启动了pin memory thread,也可以通过thread.is_alive()来判断状态
-
需要在主循环中每次都做探活,worker如果发现main process挂了,就会自己退出。而main process发现worker挂了,就会进入回收流程,然后对上层抛异常。
-
Queue
- queue的get会被设置上超时。当发现queue get超时后,会去主动看一下对应worker的状态,即主动做一下探活。
-
对于put的话,正常情况并不会阻塞。但是调用cancel_join_thread的时候,如果使用时机有问题,会导致其他的读写者hang住/读到corrupt data。
-
cancel_join_thread保证其他人不会依赖这个队列读取正确数据之后,才能调用
- 对于main process,他会把index queue在启动的时候就调用cancel join thread。因为如果main process挂掉了,worker process也不需要读数据了,通过探活发现main process挂掉后,自己退出即可
-
对于worker process,因为main process还可能读里面的数据,所以只有在main process保证不读数据之后,才会调用cancel join thread
-
对于pin memory thread,不是mp.Queue,没有后台线程,也不需要考虑这个问题。
结合上面的分析,再来看一下每个角色具体的shutdown逻辑,在注释中有一个简短版本:
In short, the protocol is that the main process will set these `done_event`s and then the corresponding processes/threads a `None`, and that they may exit at any time after receiving the `None`.
Worker process:
- While main_process.alive(),通过watch dog探活
- 读取index_queue
- 读空了,继续循环
-
如果读取到了None,break循环
-
否则则为普通数据
- 看一下done_event是否设置了:如果设置了,说明进入了终止流程,此时会跳过data process的流程,一直读数据直到读到None
-
没设置done_event,根据index去dataset中读取数据,放到data queue即可
- 读取index_queue
-
判断是否设置了done_event
- 如果设置了,说明是正常的shutdown流程,main process已经不会再去读数据,调用data_queue.cancel_join_thread()
- 保证不会因为main process不读数据,导致mp.Queue的后台线程刷buffer卡住,进而导致join卡住
- 没设置,直接退出。
- 这里因为父进程已经挂了,后台的线程去写数据会失败。join不会卡住。
-
这里应该调不调用cancel_join_thread都可以,个人感觉这里可能就是为了减少干预,保证只有大家都活着的时候,走正常的协议来退出才需要设置。
- 如果设置了,说明是正常的shutdown流程,main process已经不会再去读数据,调用data_queue.cancel_join_thread()
Pin memory thread:
- While pin_memory_thread_done_event not set
- 读取worker_result_queue的数据
- timeout则继续循环
-
正常数据,做pin_memory,然后把结果放到out_queue中
- 读取worker_result_queue的数据
-
这里每一步,包括读取worker_result_queue,以及pin_memory,放结果,都会检查一下pin_memory_thread_done_event
-
因为和main process是相同的进程,所以不需要做进程的探活。所以main process挂了的情况(对应上面第二第三种情况),等进程自动退出即可
-
对于正常的退出,则依赖main process设置done_event
Main process:
- __shutdown_worker
- 退出pin_memory_thread
- 设置pin_memory_thread_done_event
-
给worker_result_queue中写入None,应该没必要,设置了done event就够了
-
Join pin memory thread
-
worker_result_queue.cancel_join_thread()
-
退出worker,这里会遍历所有的worker
- 设置worker_done_event
-
给index queue写入None
-
Join worker,会等待worker的进程结束。为了避免卡死,这里会有一个timeout
-
最后还有一个兜底机制,就是上面退出worker的方法如果不生效的话,会直接kill掉这个worker
- 退出pin_memory_thread
-
上面有提到,在读取数据超时的时候,会做探活。如果发现worker进程挂了,会把其他正常的worker也退掉,走的也是上面的__shutdown_worker的逻辑
除去上面提到的几种退出路径,还有一种情况涉及到回收worker:
- 当worker是iteratable dataset的时候,一般每个worker都会有不同的数据。可能出现某个worker的dataset先消费完的情况。
-
此时worker会给main返回一个_IterableDatasetStopIteration,main process会触发上面的stop worker的流程,把这个worker停掉,同时后面也不会再给这个worker分发任务了。
-
这个停单个worker的需求,就要求我们有细粒度控制worker的能力,所以这里设计的停止方案是给这个worker对应的index queue发送None。并不会设置done event。
还有一些小细节这里再提一嘴:
- dataloader这里给主进程注册了SIGCHLD的handler,当子进程退出的时候,会调用这个handler。
- 这里handler中会判断子进程的退出逻辑,并在发生错误的时候抛出异常。
-
不过因为本身主进程也有了探活逻辑,所以这里我认为是一个快速退出+丰富错误信息的设计
-
详细的handler可以看DataLoader.cpp
-
对于worker来说,控制退出的逻辑主要是读到None。而done_event是用来跳过数据处理逻辑,加速退出的。
- 实际上如果没有上面的单个worker退出需求的话,全局都读done_event也是可以work的。
-
但是因为有单个worker退出的需求,就需要做细粒度的控制了。此时done_event的作用就变成了加速退出。注释中也提了不设置done event也是可以work的。
回过头来,再来从torch这里看一下,python多进程工作的时候,我们需要关注的点,以及如何做处理:
对于比较简单的单进程多线程场景:
- 一般来说不需要做额外的考虑,通过队列/信号量做同步即可
-
为了避免析构的时候卡住,会把这些线程设置为daemon=True
-
线程内的工作逻辑要避免永久等待的逻辑
-
协调者需要增加判断线程存活的逻辑,避免线程一声不吭的挂掉
-
正常退出场景,通过设置信号量,通知线程退出。外层做join即可
-
异常场景,整个进程退出,不需要做回收。工作线程会随着进程的退出而退出
对于多进程场景:
- 同样,在进程内的工作逻辑要避免永久等待。启动进程设置daemon=True
-
对于协调者/工作者这种模式,比如MPSC之类的,涉及到两个进程通过队列进行通信。两个进程都需要有探活的逻辑。避免对方挂掉后,自己持续等待数据。
-
使用队列的场景mp.Queue,需要小心producer侧,他的后台有一个工作线程,会去把通信的内容写到管道中。如果对端不消费的话,则写管道可能卡住,进而导致在后续析构的逻辑中,join工作线程卡住。
- 通用的处理逻辑是,规定好协议,协调consumer不读数据之后,调用producer侧的mp.Queue.cancel_join_thread()。
- 正常退出场景,同样通过信号量/队列,通知worker退出。协调者join这个进程即可。
-
异常退出场景,multi processing库内部的状态不可靠。此时不要操作multiprocessing库提供的组件。
-
通过atexit.register(),设置一个全局的变量python_exit_status,表示解释器正在退出。
-
对于涉及到multiprocessing库的析构逻辑(比如上面说的正常退出场景,需要用到multiprocessing的同步原语来做通知),发现python_exit_status后,需要跳过析构逻辑。
-

文章评论