2 Filtering common crawl
- look at cc
CC-MAIN-20250417135010-20250417165010-00065.warc.gz里面就是原始的html
.wet的就是提取的plain text。
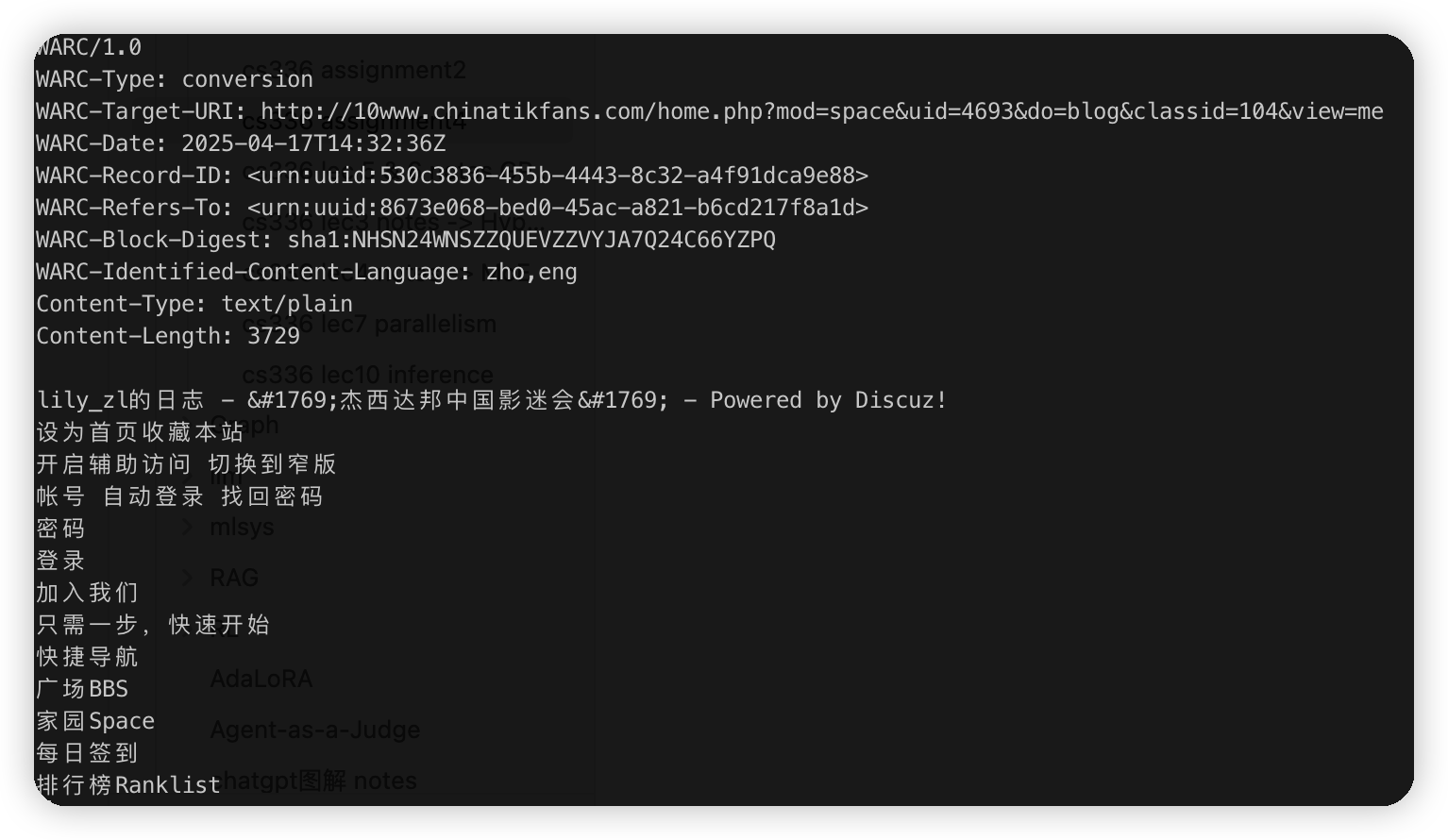
一堆奇奇怪怪的网站
http://10www.chinatikfans.com/home.php?mod=space&uid=4693&do=blog&classid=104&view=me
url是accessable的


看起来像是把html中所有文字给搞出来了。没有格式相关的信息
比如这里的discussion on plots | my creation | 杂谈,这些类似一些无关联的按钮排列到一起,肯定是不希望模型从这里学习东西的。
下面一些用户具体说的内容可能就相对有用一些,至少是相对长一些,也有上下文关联
往下看了一些文档,感觉大多数都是一些黄色网站。。不知道是教授特意选的,还是这个数据集的sample都是这个鬼样子

这里有一个虽然是广告,但是文本长,而且内容比较通畅
感觉大多数质量都很差,从这里也可以看出来为什么要去书里,或者是reddit上找内容了。
- extract_text
探测一下encoding,然后解析了给extract_plain_text就行
质量上感觉没有wet的好,文本都差不多,格式上有一些差距,会有很多奇奇怪怪的空格
- language_identification:
What issues do you think could arise from problems in the language identification procedure?
可能就是有未识别到的语言。处理方法可能是放到一个other列表中。后续人工识别
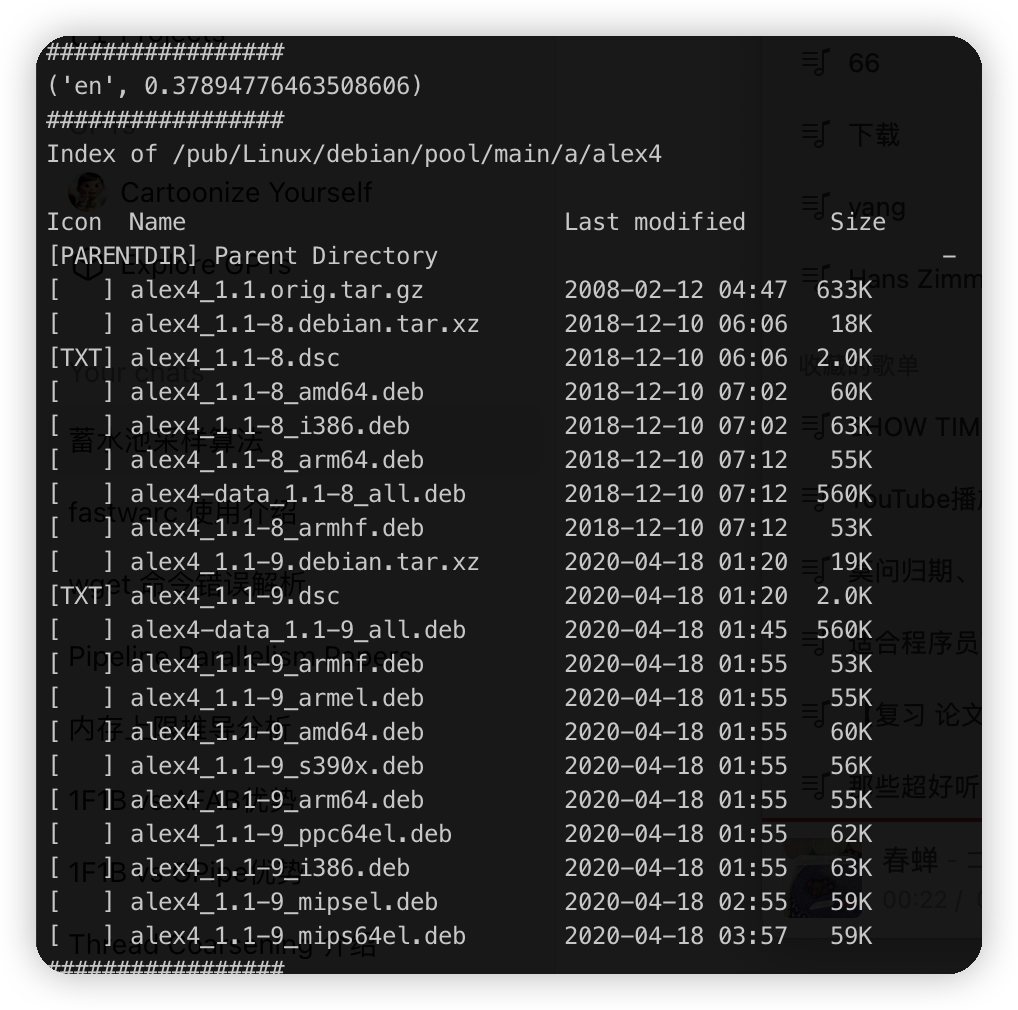
这个有0.3,不知道应该算什么语言。
不过感觉大多数都挺准的,基本都在0.9之上。
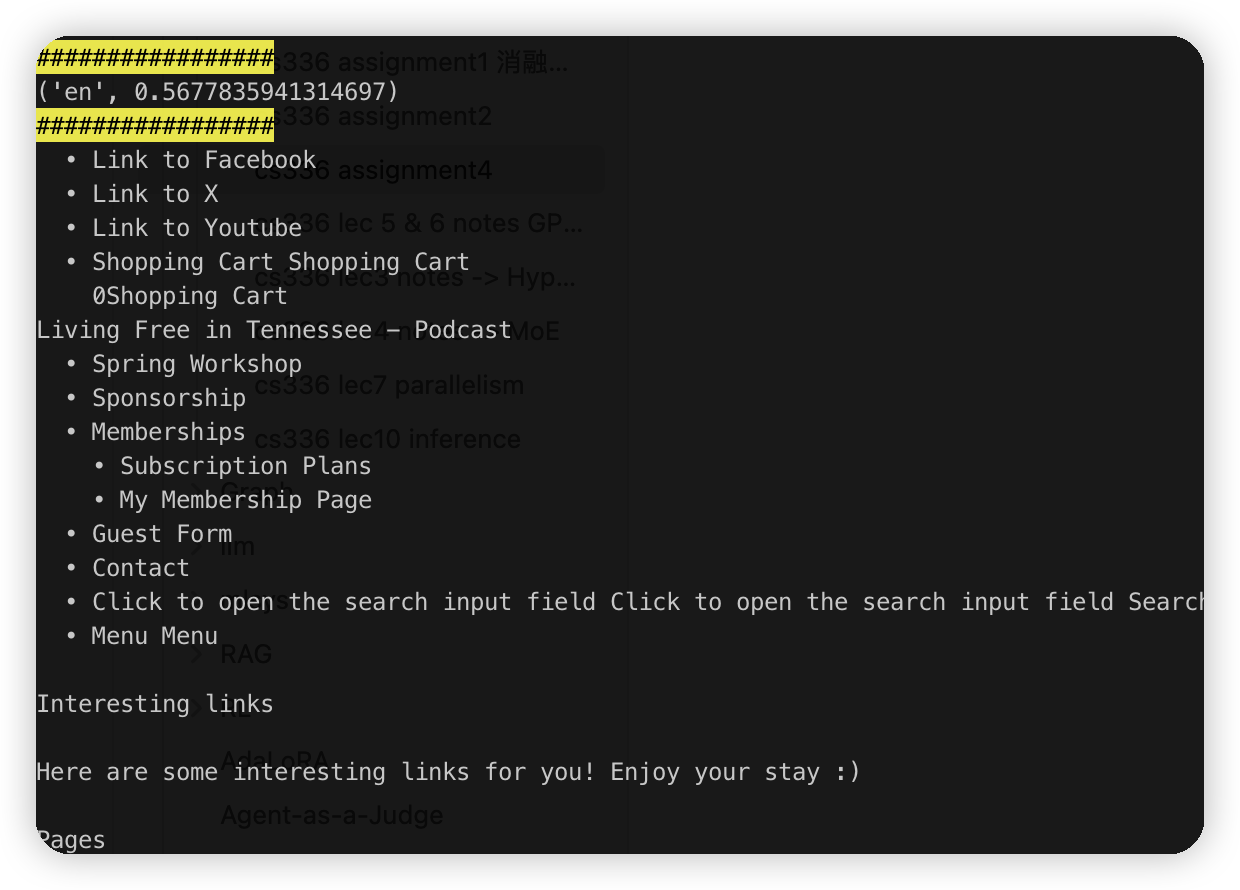
0.5的。也是ok的
从sample的这几个看,要准一点就定0.9了。
- pii
这个可能就是跟正则写的相关了,如果写的case多一些,应该就能减少一些误判。
但是如果是文档中就是 test@gmail.com这种东西,也会被替换掉,实际上这里并不是一个用户的信息,只是一个示例。
- harmful_content
total 27165
nsfw 71
toxic 223
这次就是全解析了一遍,发现有很多都解析失败了。
看了一下prob,好像也没太大影响,感觉只要label说是toxic的,基本就是toxic了。
- classifier
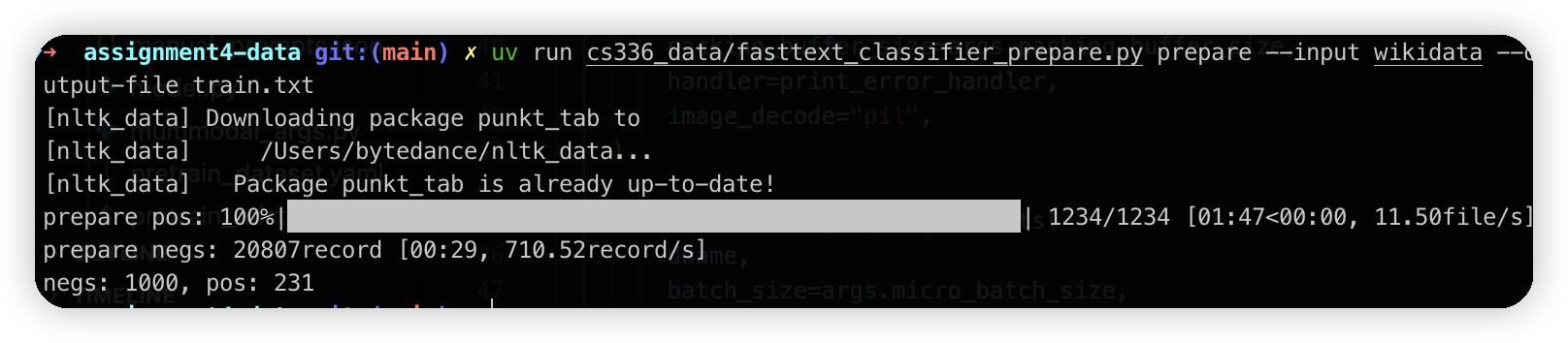
下载了2000个utl,有1200个下载成功了,跑html的解析+过滤,最后只有200个
最终生成的正样本有230个,负样本有1000个。
结果跑inference的时候都认为是负样本了。
我这里按照长度构建了一下负样本,让cc的data都是短数据,然后wikidata都是长数据。然后多跑了几个epoch,loss下来后就可以跑过测试了。
对比验证了一下。
如果是按照长度取数据的话。loss可以很快压下来,在train/test上的验证效果都很好。
而随机选sample的话则比较难。跑200个epoch loss也降不了多少。
lr调大点到0.5可以了。
在train上的f1是1,感觉是过拟合了
在test上的f1是0.79
跑测试的话也可以过。
后面的minhash/lsh之类的比较简单。就按照描述实现就行。

文章评论