简单介绍一下MegatronLM中,ContextParallel相关的实现,主要是面向源码
这一节相关的Paper也挺多,也有一些不错的知乎上的文章:
- Sequence Parallelism: Long Sequence Training from System Perspective
- Ring self attention,主要引入了分布式的计算。看论文描述应该是两轮,先算score,再算S * V
-
这里应该是要求同一个Q的S被放到同一个设备上了。没有做在线计算
-
所以这里是把Attention的activation从 S^2下降到了 S^2 / cp_world_size
-
Ring Attention with Blockwise Transformers for Near-Infinite Context
- 类似FlashAtten,做了在线计算,每次传K/V过去,直接算O
-
做了compute/communication的overlap
-
activation下降到了O(S / cp_world_size)
-
DeepSpeed Ulysses: System Optimizations for Enabling Training of Extreme Long Sequence Transformer Models
- attention之前,qkv projection之后做一次all2all,计算还是在一个设备上,只不过不同设备是按照head做的切分
-
利用了all2all通信开销低的特点
-
USP: A Unified Sequence Parallelism Approach for Long Context Generative AI
- 融合了DS-UUlysses和RingAttention。分析了他们的优缺点
-
分析了4D Parallel
这里还有一个不错的书,讲了多维并行的策略,https://huggingface.co/spaces/nanotron/ultrascale-playbook,里面有一些不错的动图来讲解RingAttention
Implementation
MegatronLM中的代码主要分为两块,分别是Megatron-core中有关数据切分相关的diff。以及TransformerEngine中具体的实现。
Megatron-core中主要是这个函数get_batch_on_this_cp_rank:
- Zigzag切分策略,用于解决CausalMask导致的负载不均衡的问题。
TransformerEngine中的Attention支持USP,代码中叫做hieriarchical_cp。启动后,在计算Attention之前,会先通过A2A,把Sequence切分转化成head切分。然后再做RingAttention。
如果希望阅读代码的话,可以看这几个:
AttnFuncWithCPAndKVP2P,支持hieriarchical_cp的Attention实现-
flash_attn_a2a_communicate/flash_attn_p2p_communicate
- 这里forward实现可以基本想象成是分布式版本的FlashAttention2的实现
- 没有单独拆Chunk,直接按照sequence / cp_size来切分的
-
外层循环Q,内层循环KV,每次接受一个Block,做本地的FlashAttention的计算。
-
FlashAttention会返回output,以及LogSumExp
-
因为FlashAttention计算的只是局部的QKV,为了计算全局的,还需要对局部的LSE/Output做修正。
-
推导流程可以看这个
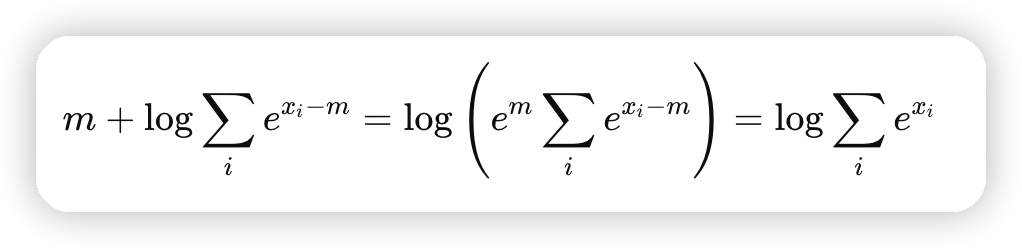


-
KV循环结束,得到全局的LSE,再去修正O。这里会把当前Q chunk对整个sequence的output都保存下来,并没有做在线计算。所以占用内存也是O(s^2/cp_size)级别的
-
这里按照FlashAttention2的算法做一下改造,做在线计算比较简单,就不详细说了
- 实现中,还有一个overlapping
- 因为计算的内容和通信的内容不耦合,所以计算当前KV的时候,可以并行的去收发下一个KV。做到通信/计算的overlap
-
实现上,用了两个stream,以及两份的q/kv input buffer。循环中通过
[i % 2]的方式切换两个buffer -
不过在LSE correction上,这里实现还有一个特殊设计,会先去提交下一个step的attention/communication,才去做上一个step的LSE correction。
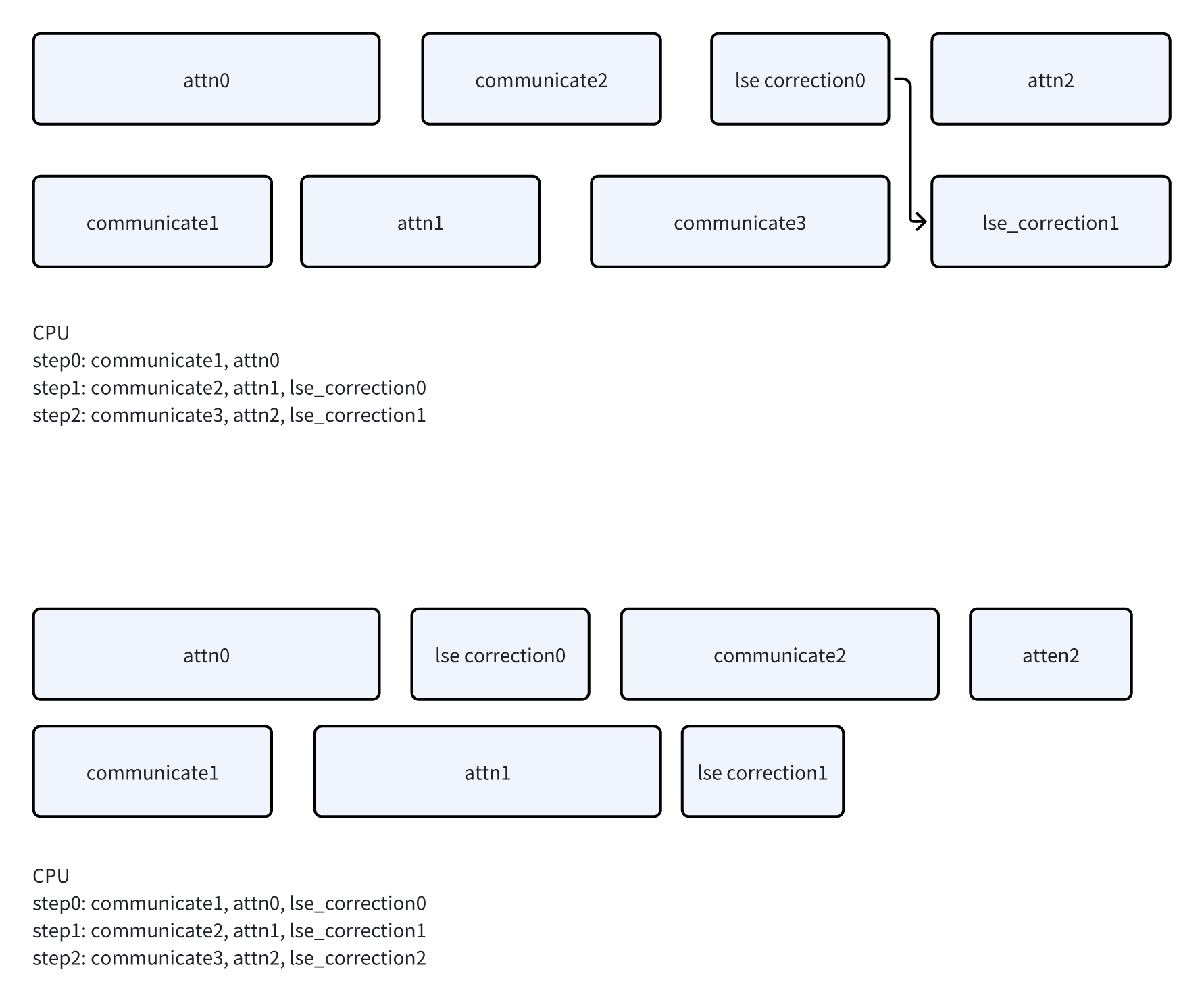
- 画图看好像区别不大,因为一个step的attn一定是排在对应的communicate,和上上个step的lse correction之前的。所以即便是重排了communicate/lse_correction,也不会影响
- 这块想了半天也没想明白,等大佬指导了
A2A & CausalMask
如果读代码的话,可能会在代码中看到这样一个函数reorder_seq_chunks_for_a2a_before_attn,可能会比较迷惑,这里解释一下。
- 在hieriarchical_cp中,第一维是a2a,第二维是p2p。
-
所以一个[4, 2]的cp,会在[1, 2, 3, 4]和[5, 6, 7, 8]这两组rank分别做a2a
-
配合上zigzag的数据分配,假设sequence为16,那么a2a之后会变成:
- [0, 15, 1, 14, 2, 13, 3, 12]和[4, 11, 5, 10, 6, 9, 7, 8]
- 此时这个reorder函数会发挥作用,把这里乱序的sequence转化成顺序的,得到:
- [0, 1, 2, 3, 12, 13, 14, 15]和[4, 5, 6, 7, 8, 9, 10, 11]
- 用这两个sequence做RingAttention。对应的causal mask为
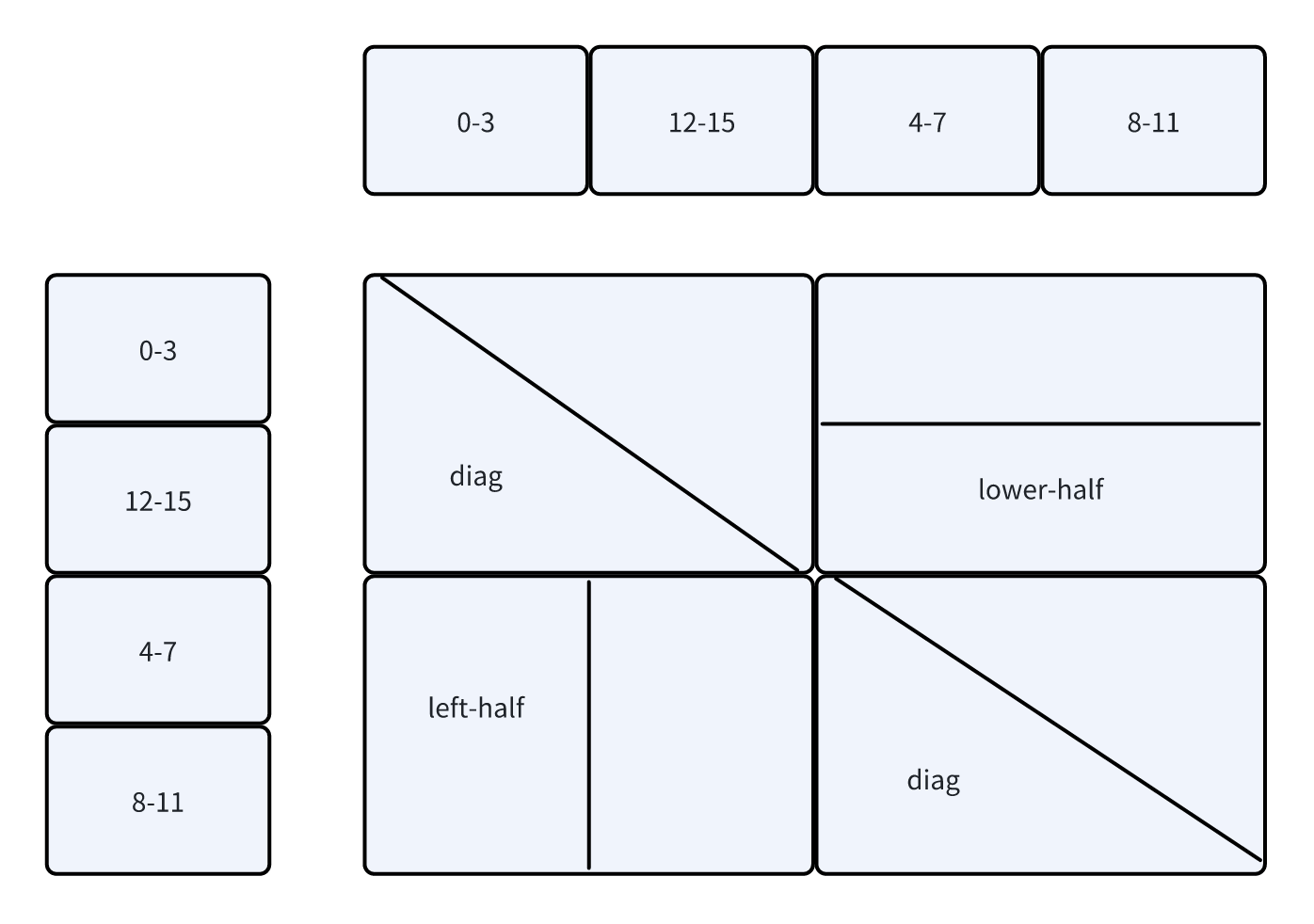
- 此时会出现3种类型的CausalMask:
- diag,和单机情况一样。还是对角线的CausalMask
-
left-half,表示只需要计算左半块
-
lower-half,表示只需要计算下半块
-
这里的三种CausalMask,就对应了Forward函数中的一堆if-else,会根据当前的位置来使用不同的CausalMask
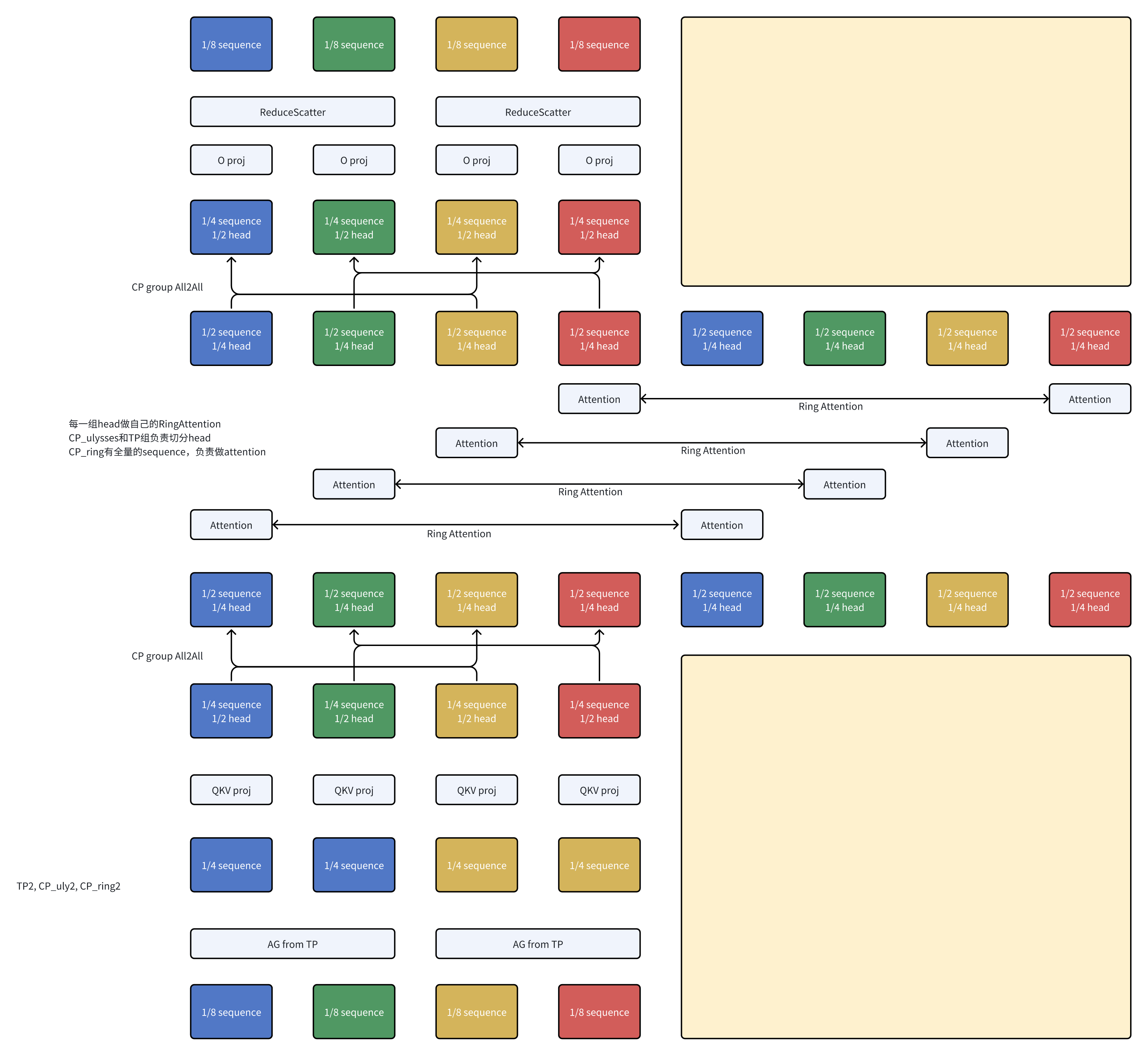
With TP
DeepSpeed Ulysses是将sequence拆分通过all2all转化成了head拆分,而TP在做attention的时候也是head拆分。这里来梳理一下他们的关系:
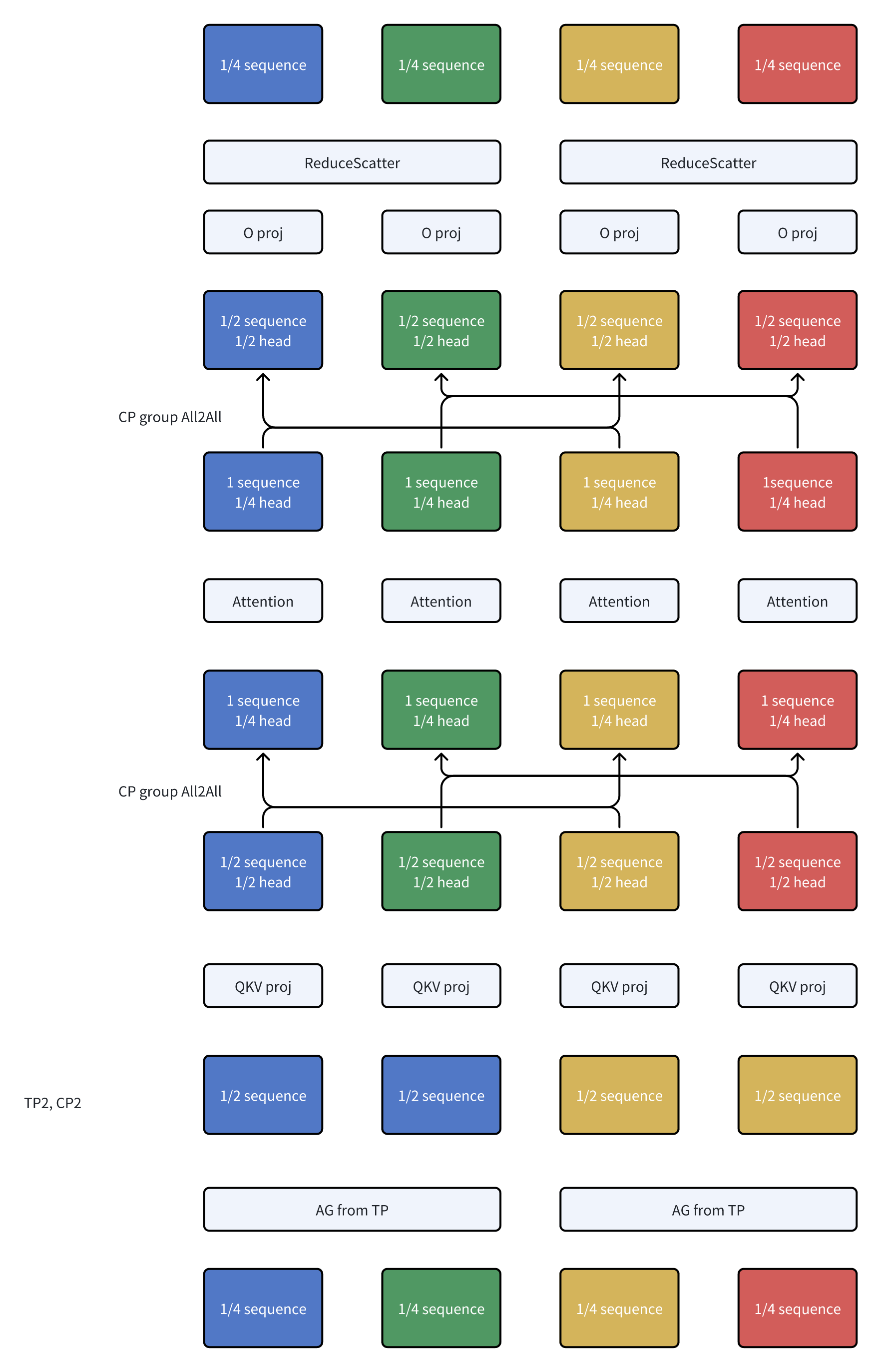
再配合上RingAttention的话,就是这样:
Reference
最后推荐一些相关的文章:
- https://zhuanlan.zhihu.com/p/698447429,讲cp的代码实现
-
https://zhuanlan.zhihu.com/p/703669087,USP的作者

文章评论