https://main-horse.github.io/posts/visualizing-6d/
DataParallel
- Identical copies of the model exist on every accelerator.
-
通过all reduce汇聚梯度
这里还提到了fsdp2这篇论文:SimpleFSDP: Simpler Fully Sharded Data Parallel with torch.compile
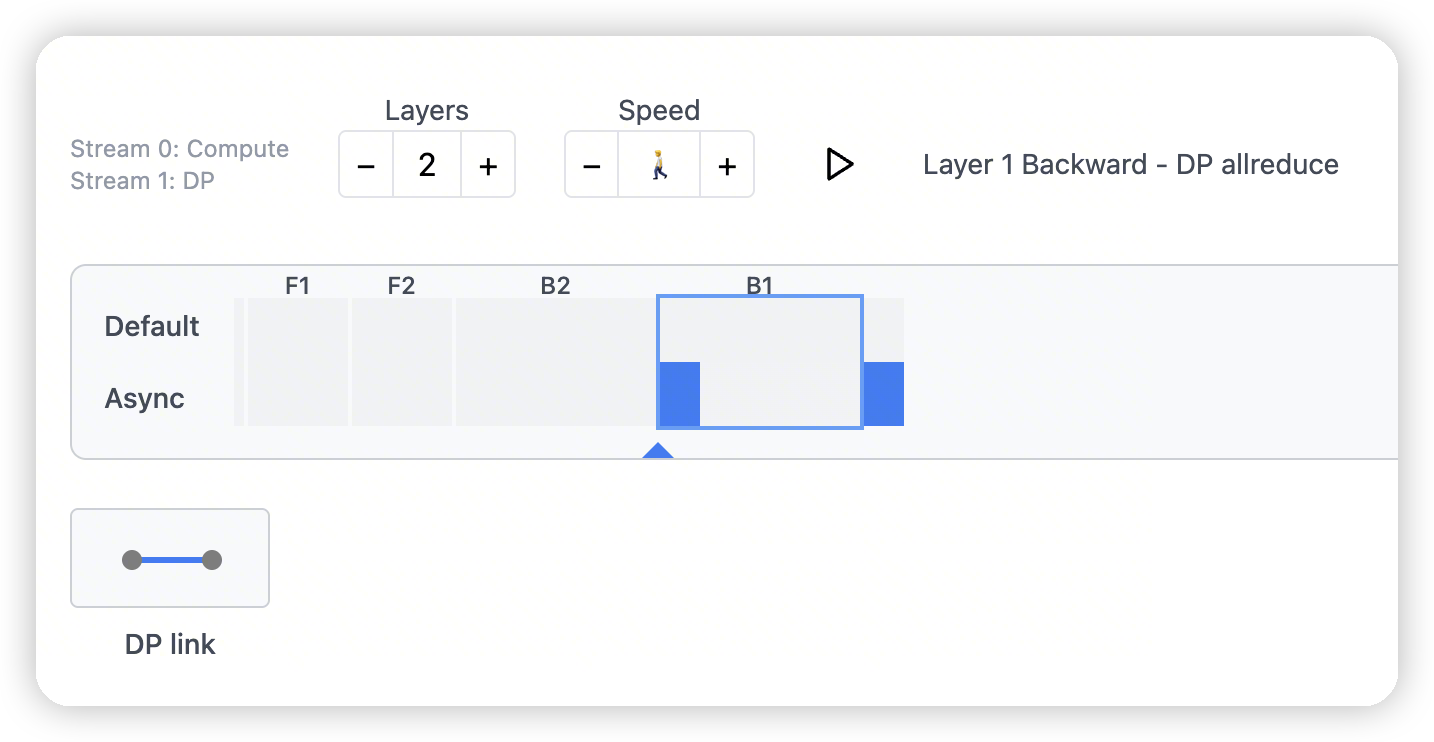
- backward之后,会进行dp link之间的通信
-
同时和下一层的backward进行overlap
Hybrid/Fully Sharded DP
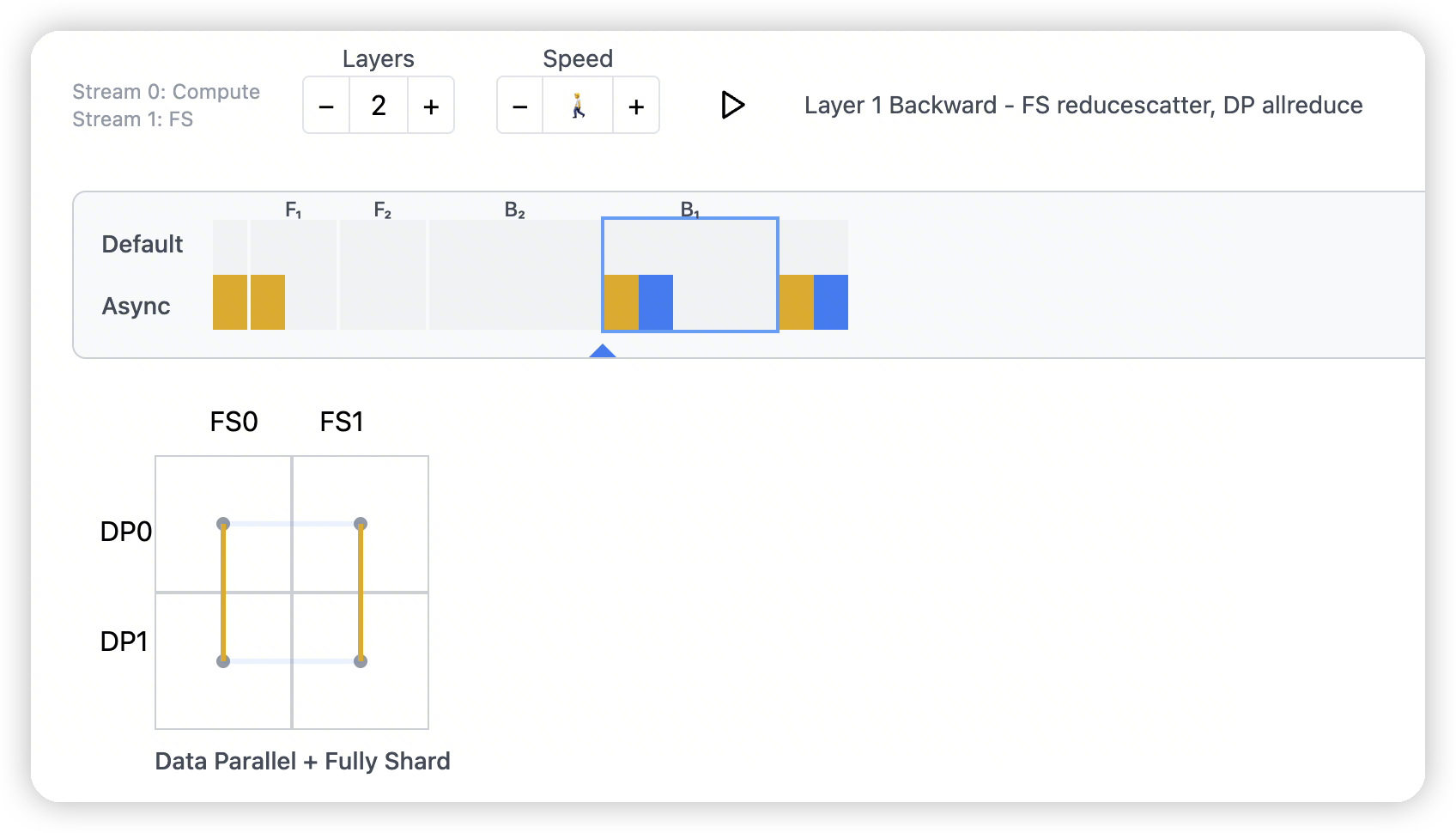
backward阶段,reduce-scatter之后,是all-reduce
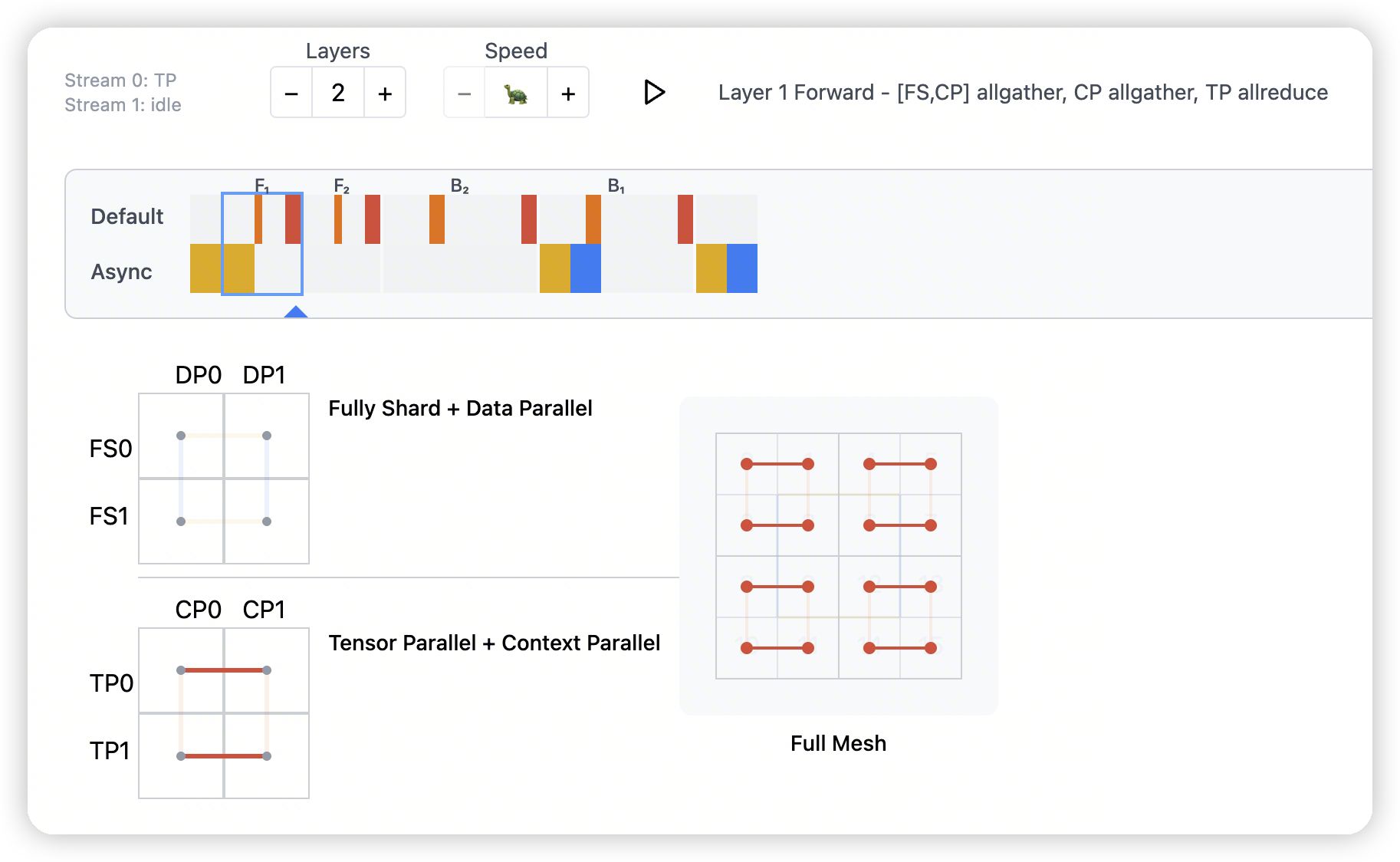
Tensor Parallel
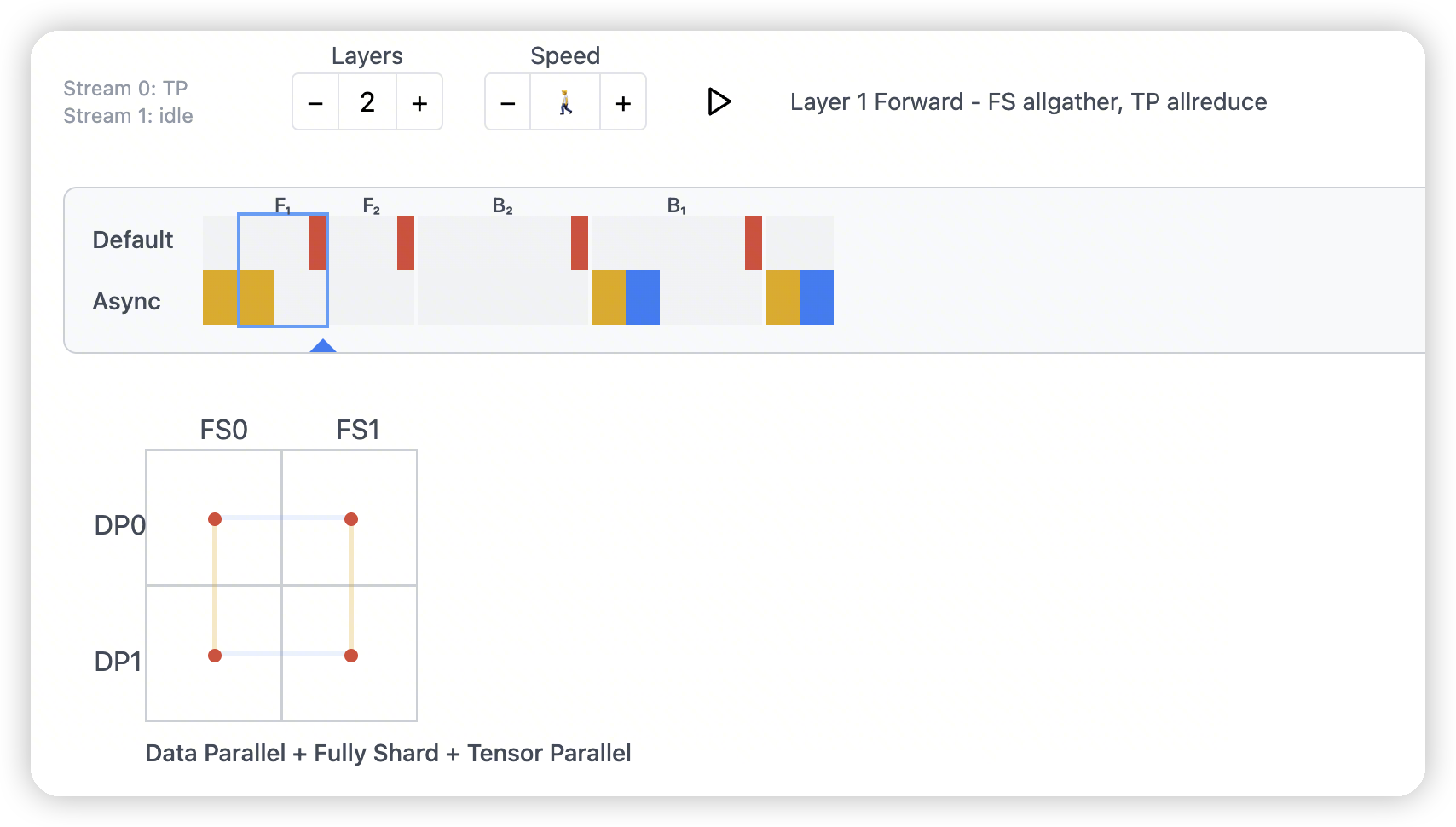
- TP + HSDP的结合
-
图上展示的每个点对应是个GPU pair
The inner dot within each square lights up whenever a TP communication occurs.
Why would you ever do this? Consider the simple case of an 8x3090 node, where:
- Pairs of GPUs are NVLink’d, making TP viable,
- Groups of 4x GPUs are separated across a NUMA Boundary.
- 不过GPU这里也会考虑numa boundary么?
- 首先在DP维度做all-gather,每个TP rank获得自己全量的参数
-
做TP,然后做TP之间的all-gather
Context Parallel
Context Parallelism is a form of data parallelism
CP shards data on the sequence dimension, rather than the batch dim, which requires extra communication overhead to synchronize ops that are sequence-aware, like Scaled Dot Product Attention or SoftMoE dispatch. If you have no sequence-aware ops, CP degrades to DP!
- 没有sequence-aware的操作,CP就会变成DP。
CP做了两件事:
- op synchronization. This is similar in functionality to TP – at specific execution points, activations have to be shared across each CP group.
- 对应的就是attention层的cp group内的通信
- weight synchronization. The CP ranks have to participate in something like FSDP, and the easiest way to do this is to ‘fold’ the CP group into the FS-or-DP group. In the example below, the CP dim is folded into the FS dim; this is equivalent to creating
mesh['fs','cp']._flatten('fscp')and passingmesh['fsdp']tofully_shardin PyTorch.- 同样讲了将CP/DP fold到一起,给FSDP用
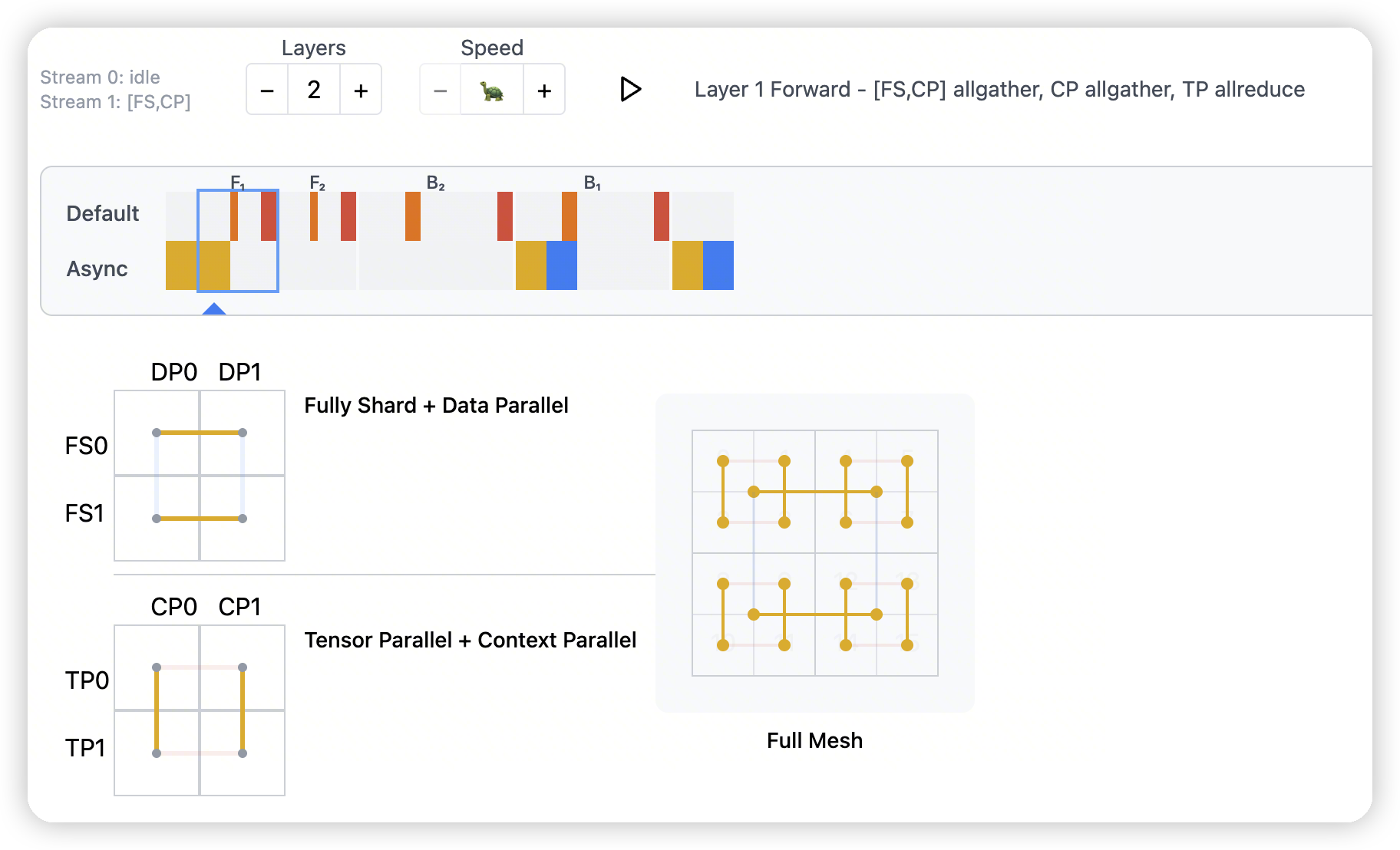
- 在DP + CP的层面上做all-gather
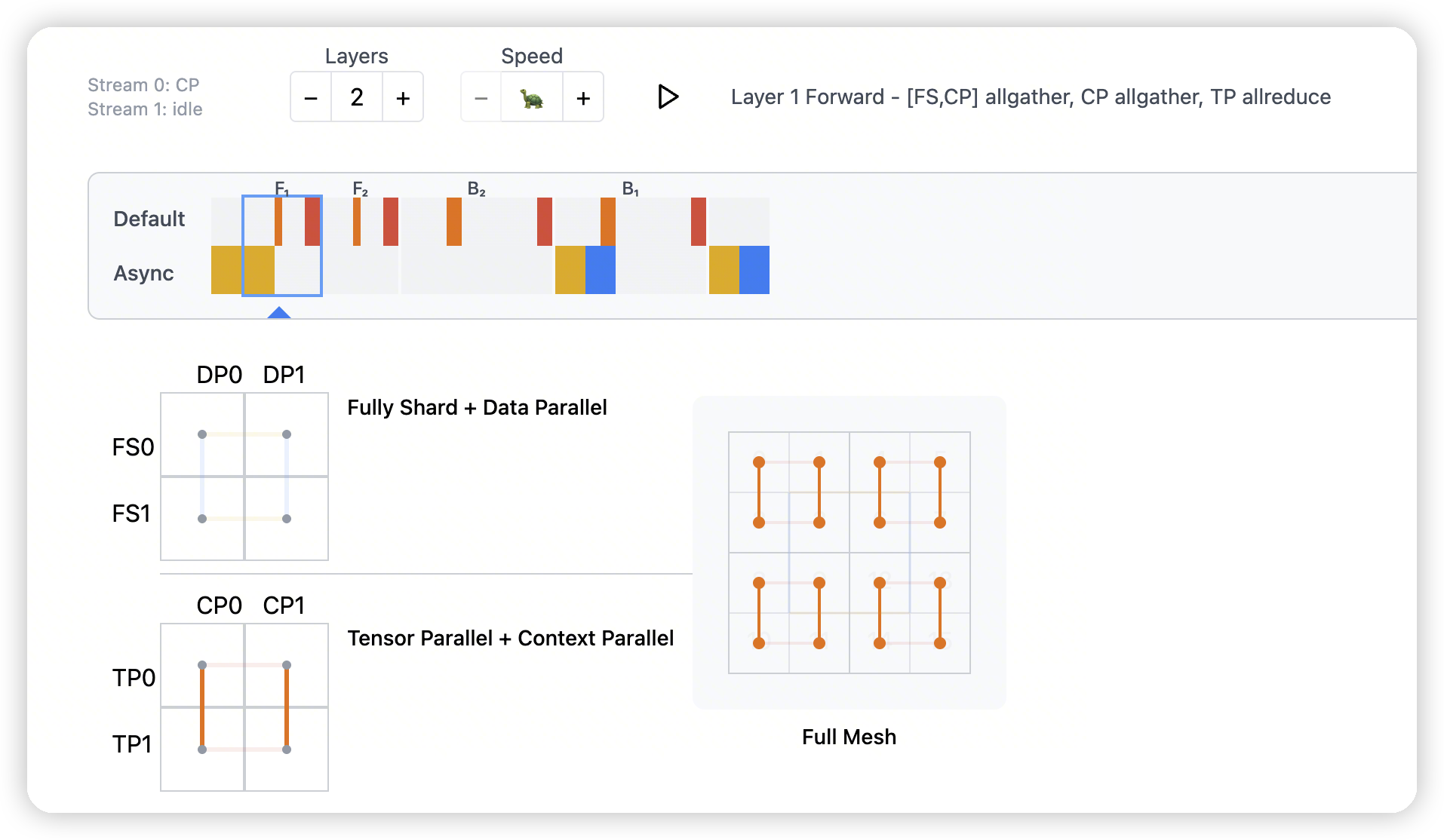
- 然后在cp group内做all-gather,收集全量的sequence
- 再做TP的计算+all-reduce
- 看这里的图很细节,对于cp来说,是先all-gather,做计算
-
对于tp来说,是计算完做all-reduce。
-
所以communication分布在两边
EP
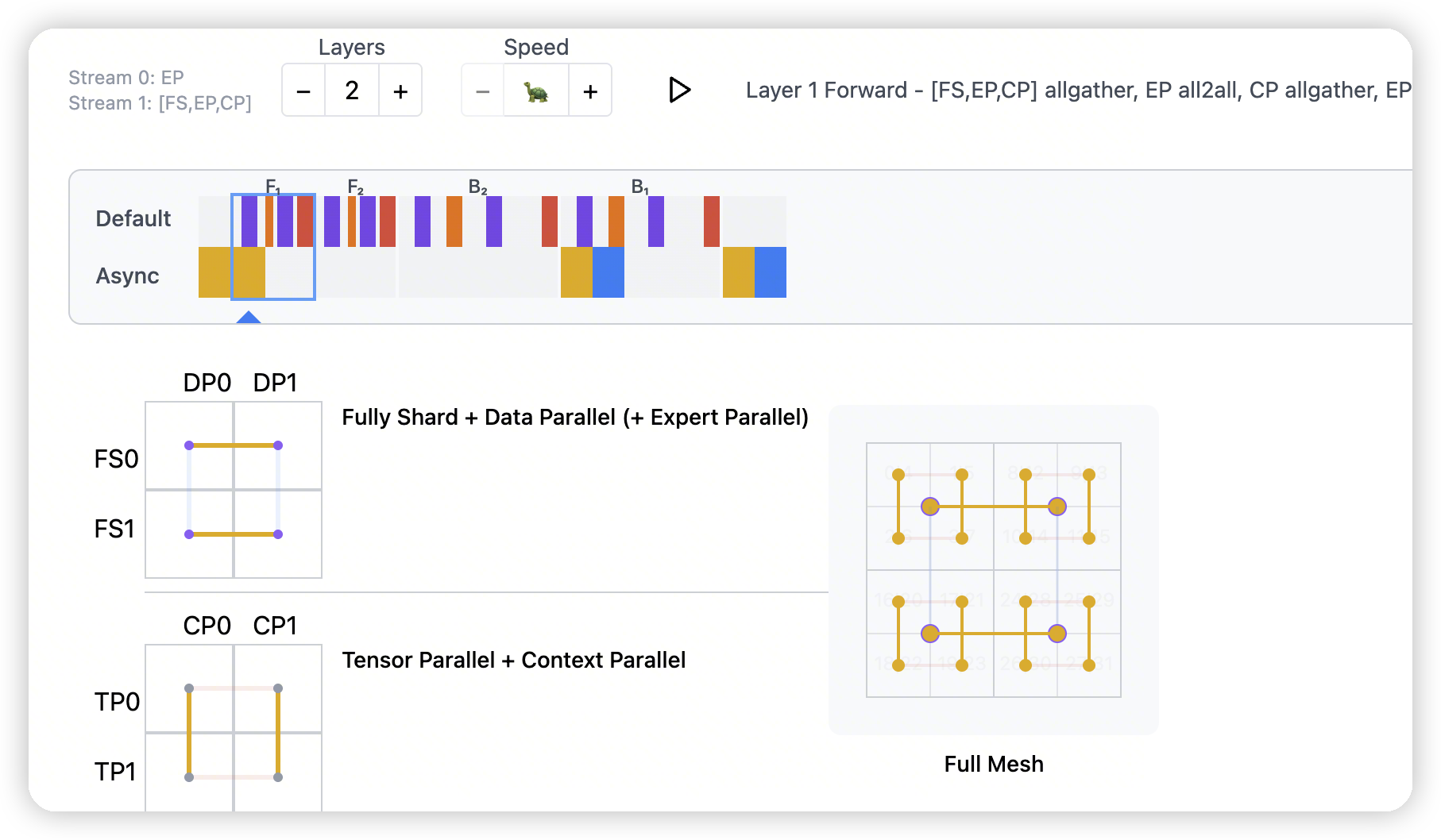
- 这里EP和FS放到了一起
-
先通过all-gather来同步non-expert-weights。对于这里来说就是router
-
router计算完之后,紫色的部分就是做all2all。
-
做完all2all后,后面的计算和之前直接使用cp+tp是一样的。
- 不过感觉这里有点点混乱,因为一般可能认为moe是放到mlp上,就没有cp通信的事情了。
-
放到attention层的话,对应的就是不同的sequence可能使用不同的attention。吗?
PP
The SOTA in pipelining is ZBPP, which promises something close to perfect pipelining, at the cost of your entire codebase + my entire visualization setup thus far
Perfect pipeline, at the cost of your entire codebase
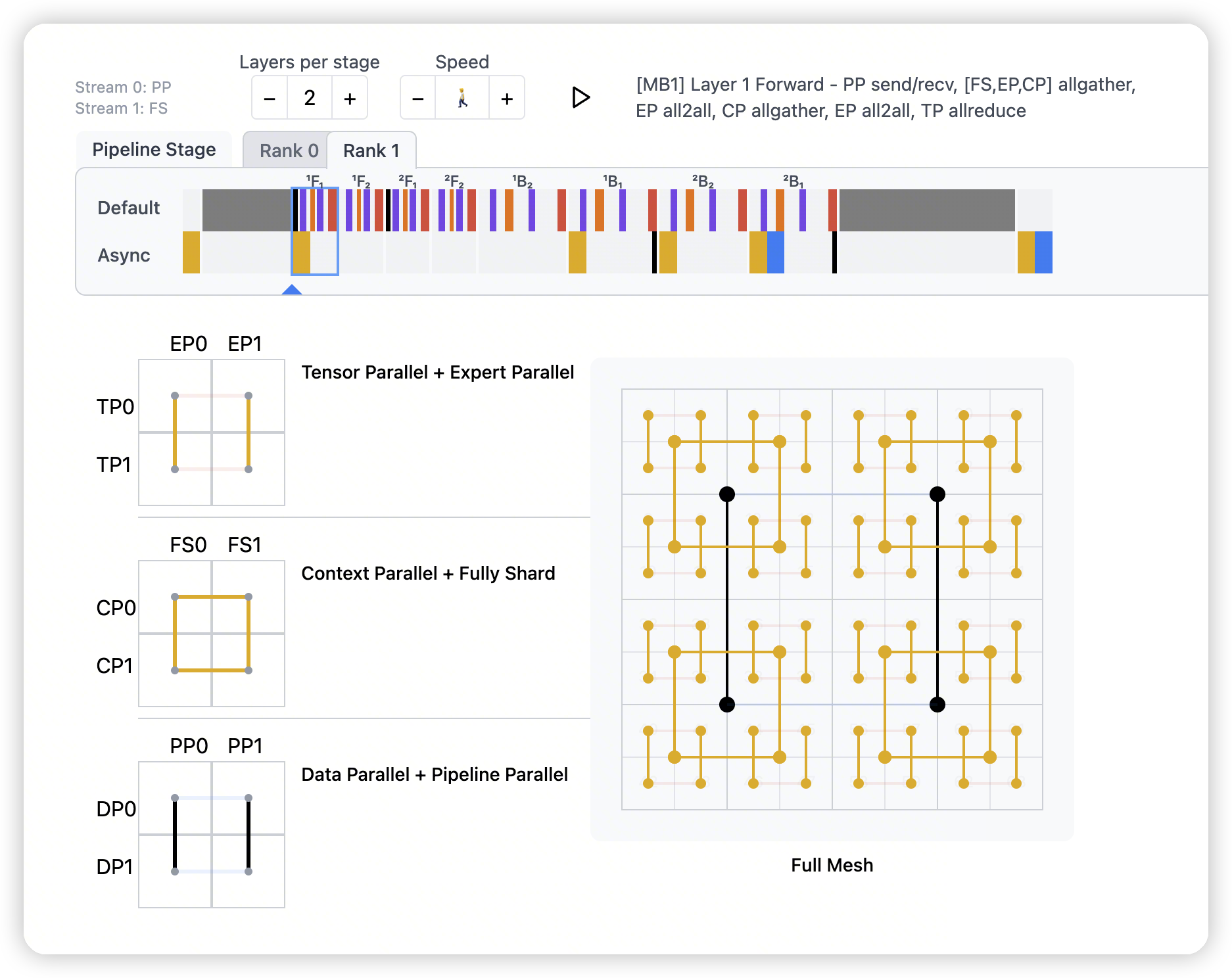
- 感觉像是对整个device mesh再复制了一块。
-
每个pipeline stage算完之后,会引入PP group的通信。
-
剩下的就都是PP group内的各种操作了。所以PP的通信频率是远低于其他的并行方法的
后面还有一些设计决策
That hierarchy isn’t important for a mere 2⁶ GPUs; but it could make sense at scale:
- TP=8 applied within-node, with low-latency async TP over NVSwitch.
-
EP=16 across rail-optimized leaf switches for best all2all perf
-
CP×FS×DP=256, such that the 5D submesh
[TP,EP,CP,FS,DP]fills a 32k island- CP>FS>DP in terms of latency priority
- PP=? across islands
- 这里说cross island network速度比较慢,所以把PP放到这里
PP and FSDP
If you allowed for a naive implementation of FSDP to be used, each forward and backward microbatch in a pipeline schedule would require its own allgather/reducescatter. This quickly pushes up the communication cost of FSDP by O(microbatches), which will obviously destroy MFU if e.g. microbatches>=24 as in ZBPP.
- 因为FSDP在每一层引入了通信,而PP的microbatch会多次执行forward/backward
-
导致PP和FSDP结合的时候会放大FSDP的通信量
-
如果不希望放大的话,避免通信,会导致FSDP的memory saving能力失效
这里作者也提出了一个新的方式:
-
in GPipe, because all forward steps are executed at the start, and I’m using ZeRO2, only 1x allgather of params is required per layer.
-
for every backward layer step, I create new local gradients and reduce-scatter them to accumulated gradient shards. This ensures that the total memory required for storing gradients is always roughly equivalent to that of their sharded size.
-
only for the last microbatch’s backward, I apply an allreduce of gradients across the DP axis. Meaning: nosync is applied for DP, but not FS.
-
就是用ZeRO2,但是会做FS group中梯度的RS。最后再做DP层的all-reduce

文章评论