这篇文章来介绍一下MegatronLM中DataParallel相关的实现,适合希望阅读源码的同学来看
主要会涉及到DDP/FSDP,distributed optimizer会单独再出一篇文章。
官方有一篇设计文档,可以简单看看https://docs.nvidia.com/megatron-core/developer-guide/latest/api-guide/custom_fsdp.html#
DDP
MegatronLM中DDP的代码主要在core/distributed/distributed_data_parallel.py中。
- 支持no_shard,也就是最简单的DDP,backward后通过all-reduce来计算全局梯度
-
通过distributed_optimizer来启动ZeRO1 style的DP。
先来看一下通过DistributedDataParallel这个类Wrap module之后,他会做什么:
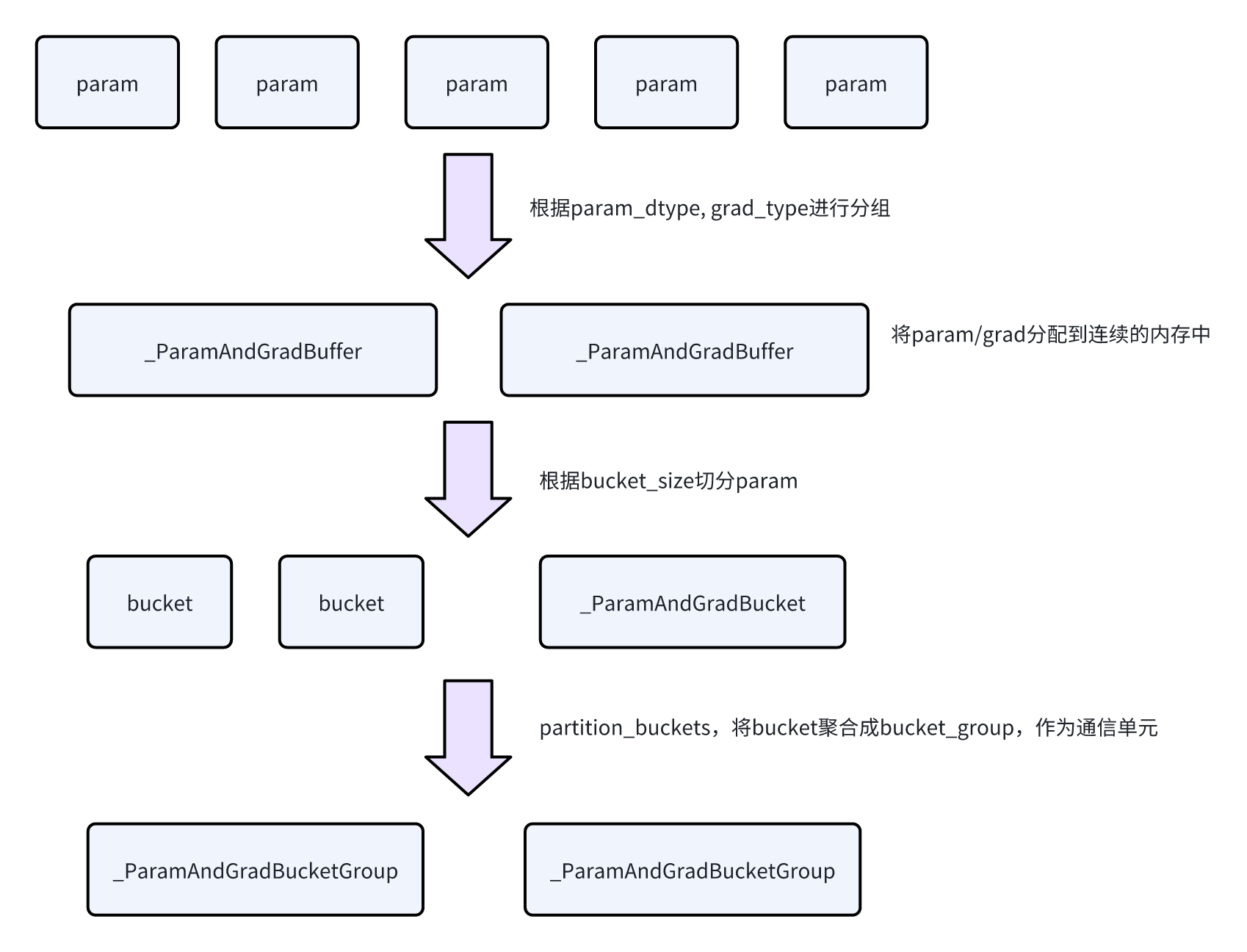
因为在ZeRO1中,涉及到参数的all-gather,以及grad的all-reduce。为了提高通信效率,DrDP会将模型的参数放入到连续的内存中并进行通信。
- Param会根据param_dtype, grad_dtype进行分组,构建出若干组
_ParamAndGradBuffer,一组参数的grad/buffer会放到这段连续的内存中 -
_ParamAndGradBuffer会根据配置的bucket_size来做切分,切分成若干个bucket,叫做_ParamAndGradBucket -
然后会给bucket做聚合,生成bucket group,代码中是
_ParamAndGradBucketGroup。这一步的目的是聚合多个bucket的通信,是通信的单元。- 聚合策略可以看
partition_bucket这个函数,更多是给fp8相关的配置做的处理。
- 聚合策略可以看
- 有一个比较关键的点要注意,上面说的划分是同一在expert/非expert下做的划分。也就是说expert/非expert的参数不会混用一个ParamAndGradBuffer,也就不会有相同的BucketGroup。因为他们的通信组不同。
DDP中,因为_ParamAndGradBucketGroup是通信的单元,所以涉及到数据同步的操作都在这个类中。核心的功能有几个:
- start_param_sync,做参数的all-gather
-
finish_param_sync,等待all-gather结束,并prefetch下一个bucket group的参数
-
start_grad_sync,做梯度的reduce-scatter/all-reduce
-
finish_grad_sync,等待梯度聚合操作结束
-
register_grad_ready,在参数的AccumulateGrad上调用的,表示这个bucket的部分参数的梯度已经准备完成了。当整个bucket group都准备好时,开始梯度的all-reduce。用来和梯度的计算做overlap。
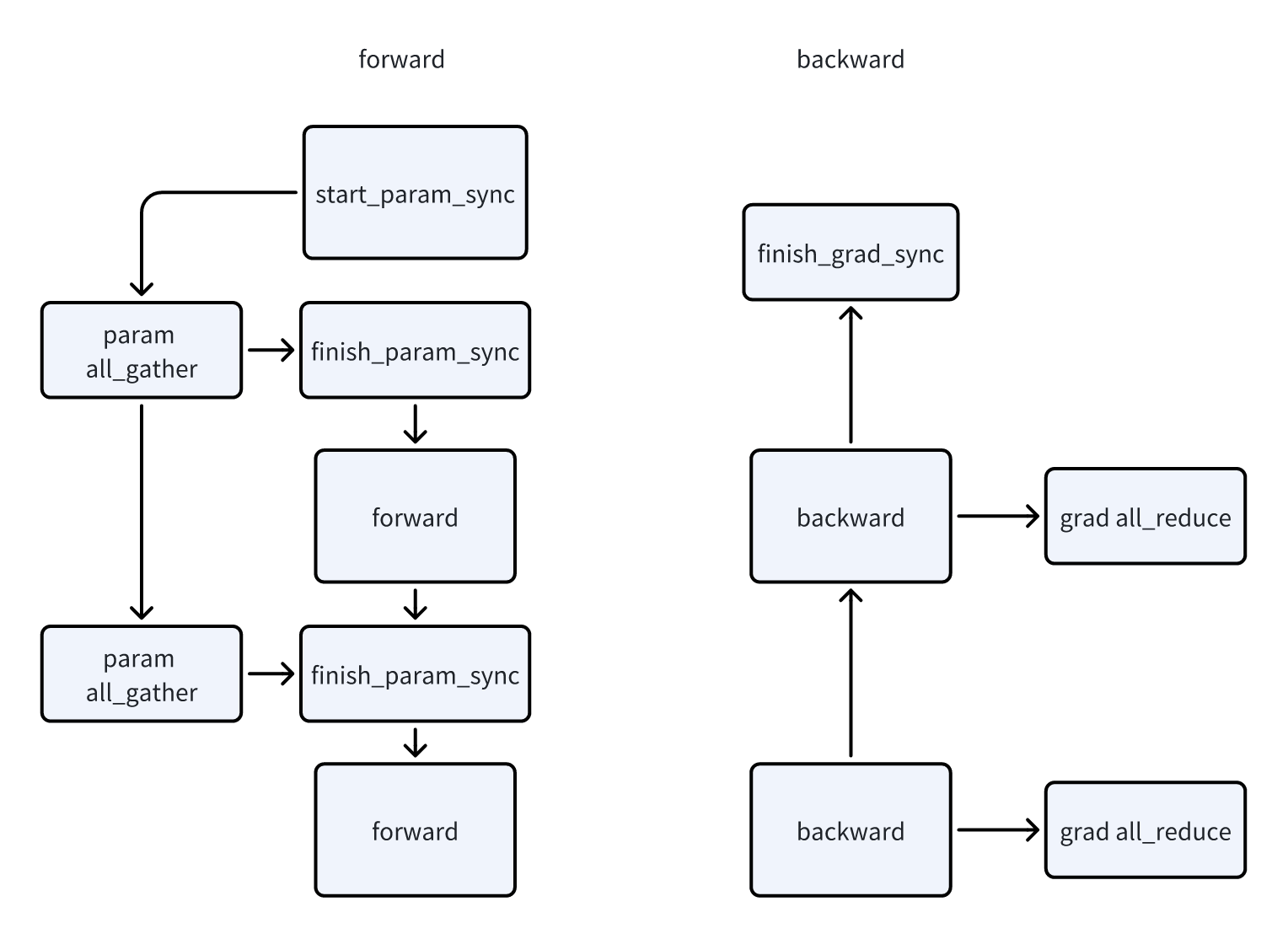
- 在AccumulateGrad上注册register_grad_ready
-
在module上注册pre_forward hook,进行param all_gather
with PP
MegatronLM提供的DP,包括DDP以及FSDP,都提供了一些接口是允许用户控制行为的,比如何时开始进行param sync,何时开始进行grad reduce。以及也需要用户最后调用finish_grad_sync,等待所有的grad同步完毕
- 在
training/training.py中,get_model中包含了通过DP来wrap module的代码 -
在相同文件的
train函数中,会给model config中设置上grad_sync_func,param_sync_func,以及finalize_model_grads_func,就对应了上面的start_param_sync等
那么这一节的标题,DP和PP的关联是什么呢?
- 因为DP在做backward的时候,涉及到梯度的同步。而PP中会涉及到多个microbatch,也就对应了多个backward。我们只希望在最后一个microbatch做梯度的同步,减少数据的通信量
-
同时,因为PP本身控制着多个microbatch的调度。是可以做到比较好的overlap的
- 比如前一个microbatch的backward计算完之后,显示调用start_grad_sync,然后再开始下一个microbatch的backward计算。这样完全不需要模型内部做拆分+overlap,同时大块数据通信效率更高。
核心的代码都在pipeline_parallel/schedules.py中
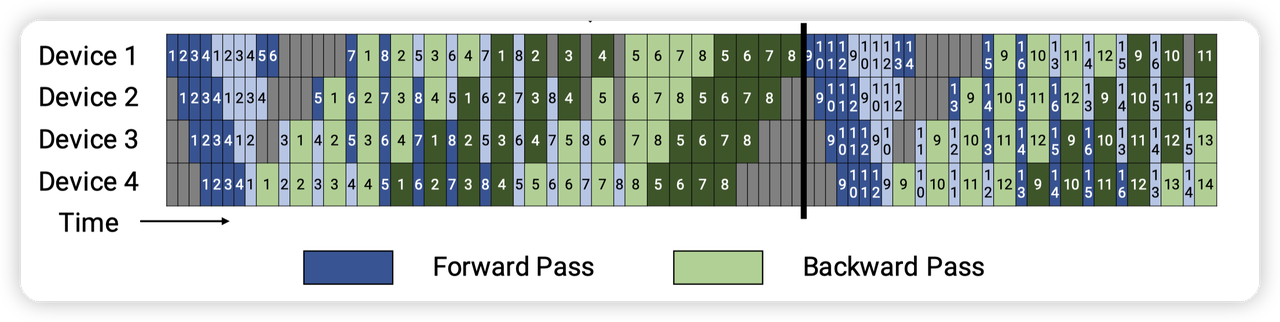
针对第一点:
- 在代码中有一个no_sync_context,在里面会设置DDP module的一个内置属性
is_last_microbatch。当is_last_microbatch为False的时候,调用start_grad_func会是一个no op -
在last microbatch的backward的时候,会将这个is_last_microbatch标记成true,从而启动梯度的同步
针对第二点:
- 在backward的last microbatch的时候,会关掉no_sync_context,这样模型进行完backward之后,就会启动grad reduce的流程
针对第二点,还有一个额外的优化这里也提一下。对应配置中align_grad_reduce/align_param_gather:
- 在设置了这两个配置之后,才会设置model config中的param_sync/grad_sync两个函数。作用是手动控制参数/梯度的同步时机。
-
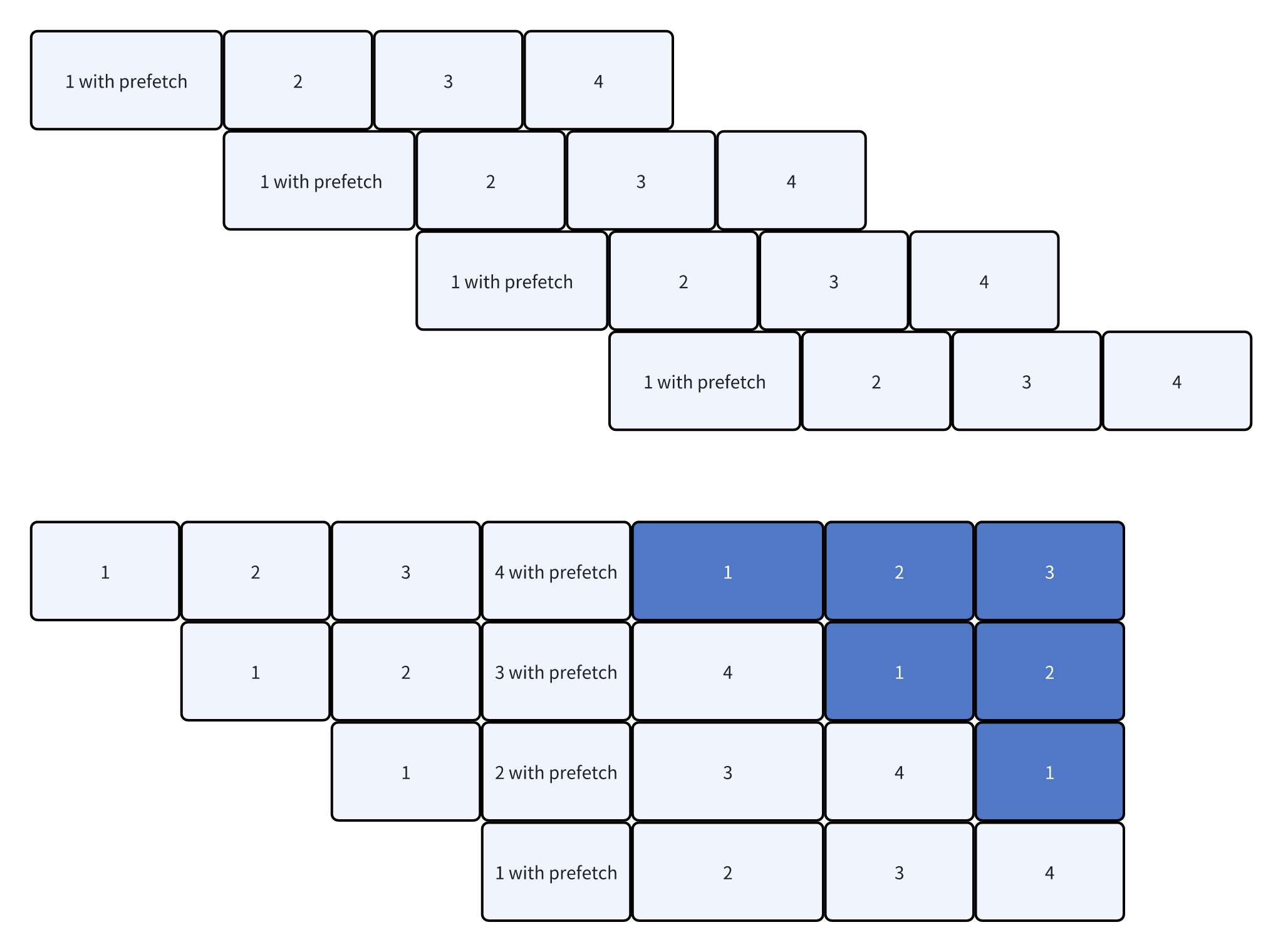
在使用virtual PP的时候,因为会有多个model chunk,我们是可以预判到下一个使用的model chunk的。所以在forward阶段会提前调用下一个model chunk的start_param_sync,从而预先准备好参数。
-
而代码注释中也提到,这里做当前batch的时候,去prefetch下一个model chunk,会影响当前batch的计算时间。进而导致延长下一个stage的等待时间。
-
如第一张图,如果我们每次都在第一个microbatch做prefetch的话,会导致pipeline出现错位,影响性能。
-
核心原因是每个stage的“第一个microbatch”并不是同一时间发生的,导致破坏了PP希望相互进行overlap的目的。
-
所以解决办法就是让prefetch发生在相同的时间,这里会根据当前rank计算一下。如图二,大家在同一个时间点进行prefetch,就不会引入额外的等待时间了。
-
这块只画了forward,backward的逻辑也是一样的。
除了上面提到的点之外,DP和PP还有一个关联点:
- 在DP中,会根据大小来划分参数组,用来做细粒度的计算/通信的overlap。
-
在PP without interleaving的场景下,只有第一个stage才涉及到上面的划分。剩下的stage都是把模型放到一个大的bucket中,一把通信,效率更高。代码中可以看
disable_bucketing这个参数 -
看图可以发现,因为整个PP的流程的瓶颈在第一个stage上面,后面的stage的backward都可以更早的完成。此时可以在stage0进行backward的时候,去进行grad reduce。
- 相当于全局层面的overlap了。overlap了stage0的计算和其他stage的grad reduce
- 既然瓶颈在stage0,stage0就需要进行bucketing,来做rank内的计算/通信的overlap,降低整个batch的执行时间。
-
这里还需要注意的是PP with interleaving的场景下没有这个功能,应该是认为virtual PP已经把模型切的足够细,不需要再做chunk内的overlap了。
Partial DistOptimizer
这块主要对应代码中的num_distributed_optimizer_instances配置,在设置之后,optimizer不是在所有的dp rank上做shard,而是在部分dp rank上。
- 即是一个二层的分布结构,[Replicate(), Shard()]
对应的,在grad_sync的时候,会先做intra_group的reduce_scatter,再做inter_group的all_reduce
- 这样我们可以把inter_group这一维放到相近的rank上,来减少all-reduce带来的开销。
-
同时每个rank all-reduce的只有部分的梯度(因为reduce_scatter shard过了)。比全量的all-reduce少很多。
而param则没有影响,还是照常做all-gather
- 这块有一个扩展的问题,我们是否可以先进行all_reduce,再进行reduce_scatter呢
- 逻辑上是可行的
-
但是这样all_reduce的就是全量的参数,而非reduce_scatter后的shard版本的参数。导致通信量会变大
- 还有一个实现上比较有意思的点:
- 代码中有一个配置overlap_grad_reduce,启动后,grad的reduce-scatter会是异步的通信。不需要单独开一个stream管理了。
-
而使用了Partial DistOptimizer之后,需要在RS之后,再去做AR。此时两个操作是有依赖的。而async op本身无法表达这种依赖。
-
所以在异步通信+PartialDistOptimizer的场景下,这里会单独用一个stream来做通信,来实现异步通信的能力。
Grad Scaling Factor
在阅读代码的时候可能会发现有很多设置grad scaling factor的地方,同时夹杂着一堆if/else,以及各种ProcessGroup的混合,可能会看的比较糊。这块简单梳理一下设置grad scaling factor的逻辑。推导可能有点冗长,大家不感兴趣的话可以直接看下面的结论:
- 从模型本身上来看,loss是针对单个token算的。即这个任务为next (one) token prediction,所以每次只有下一个token的损失。
-
为了计算效率,我们加了batch/sequence。比如在pretrain_gpt.py中,返回了所有有效的token size,最后会除一下,算的是loss per token。但是更新模型的loss仍然是所有的loss per token的avg
- 好像还看到有一些可以对一些重要的token提高权重,做weighted sum
- 那么在分布式训练的场景,希望引入DP/CP/EP等技术后,得到的avg(loss per token)还是一样的,这是设计分布式训练模块的目标
-
先假设每一个rank的token数量相同,那么每个rank上计算好了自己的loss per token之后,可以做一下avg。然后一起做backward prop。但是这样backward都是重复计算。根据链式法则的话,我们把loss做一下放缩,等价于先算梯度,再放缩。所以我们可以每个rank单独做backward,然后对梯度做avg
- 这里想说的点在于,我们能够把token数量这个放缩逻辑下放到梯度计算之后
- 如果每一个rank的token数量不同,那么应该做weighted sum,因为token数量少的rank上的token loss被稀释的少一些,也就是权重更大一些。
-
暂时先不考虑溢出/精度问题。因为我们需要计算的是loss per token,我们可以简单的先算loss sum(of token),然后backward结束之后,把梯度都sum起来。全局做一次all-reduce计算global token num,然后做放缩即可。这样的话就没有token数量不同的问题,同时也不用考虑world_size对avg这个函数的影响了。
-
从这里其实可以看出来,reduce grad过程中考虑world_size,更多的是因为使用了avg等操作。因为实际需要计算的是 sum of loss / num of token,没有world_size的参与,也就不需要考虑模型划分什么的事情。
- 转化到grad就是sum of grad / num of token
- 既然sum of grad在reduce grad的时候就已经做了。主要考虑的就是这个缩放因子 num of token了。
-
在MegatronLM中,有几个处理的地方
- Loss func,会做loss /= (local) num of token。在PP schedule.py中
-
剩下的就是在DDP这里了。既然PP中已经做了local num of token的平均了,这里剩下的就是global / local了,其实对应的就是调用loss func的rank的数量。
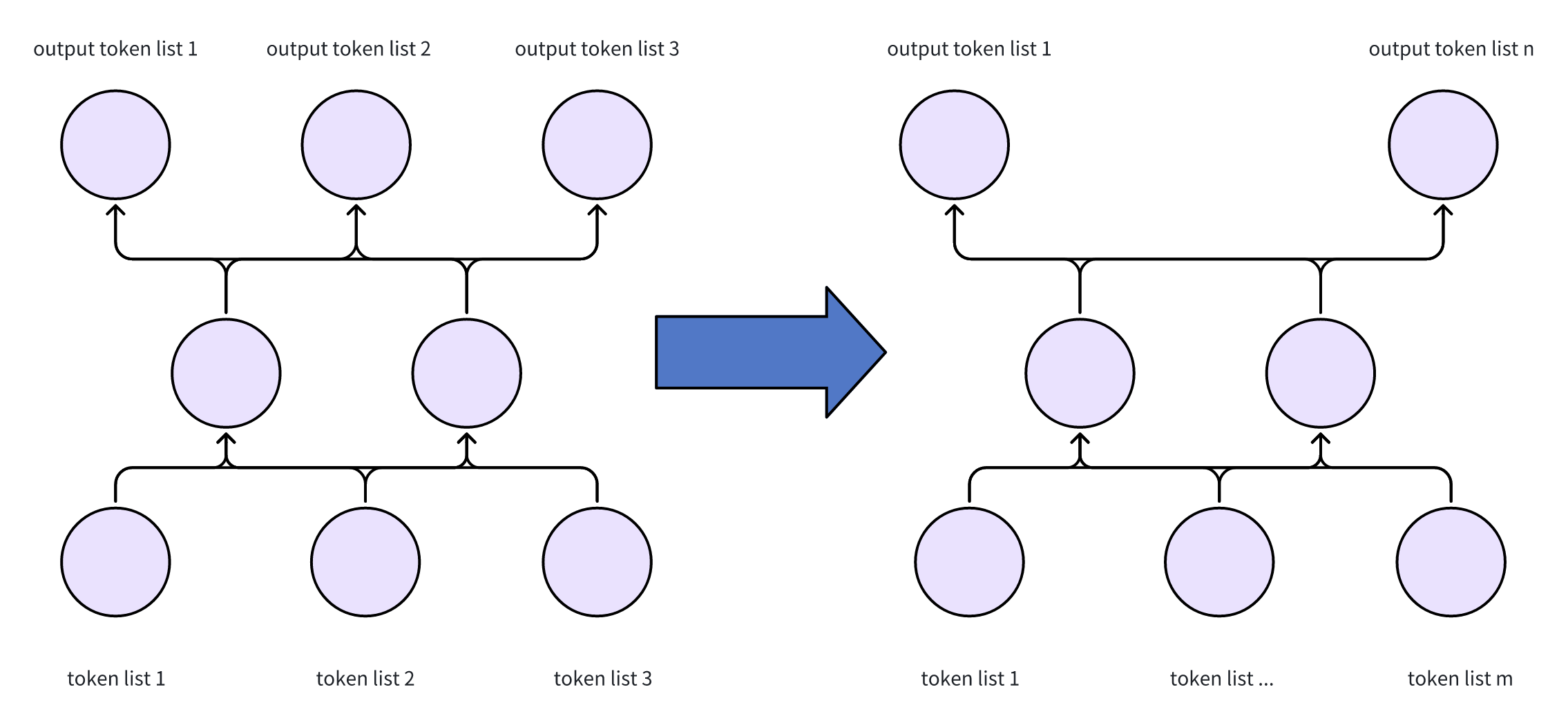
- 对于transformer这种,就是左边这个图。输入和输出是对应的(不用考虑中间的cp/ep等混杂交错)
- 所以再根据输出head的数量做avg即可,在MegatronLM这里,就是DP + CP
- 其实可以泛化,比如输入是n个rank,输出是m个rank,只要知道最终输出的总token数量,就可以保证正确计算。
结论:
- 因为每个rank算了 loss /= (local) num of token了。要获得最终的梯度,只需要再除一下global_token / local_token即可。也就是调用loss_func的rank的数量
- 其实严谨点应该用weighted sum
- 那么在MegatronLM中,这个rank的数量就是dp_cp_group.size(),因为在dp/cp上模型做了复制。
- pp是纵向切,只有一个head
-
ep是切mlp,不影响head
-
tp虽然影响,但是最后会有all-reduce,计算结果是相同的
-
所以放缩的因子都是固定的 1 / dp_cp_group.size()
最后提一嘴,上面说的更加精确的loss per token的计算在MegatronLM中通过calculate_per_token_loss支持了。
- 在schedule.py中,会计算本次global batch的token总和。
-
在finalize_model_grads中,会做all-reduce,计算global token的数量,并对loss进行放缩。
FSDP
使用上类似torch的,可以通过fully_shard来wrap一下,也可以通过MegatronFSDP这个类来wrap一下。底层都是MegatronFSDP
Implementation
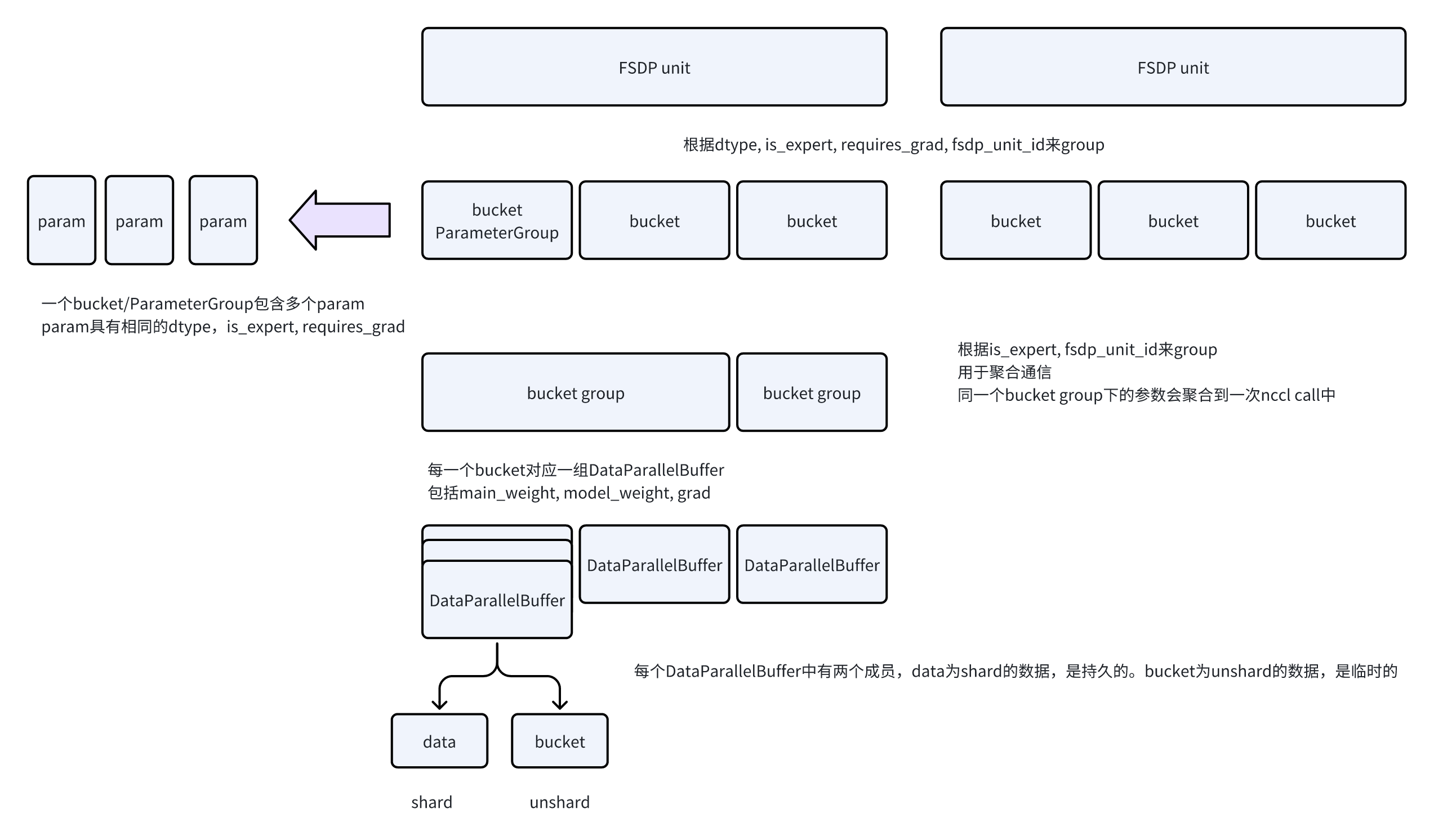
MegatronLM的FSDP的划分策略更简单一些,就是让用户定义FSDP unit的类型,根据module类型直接拆。
这里wrap的过程会发生几件事:
- 首先,根据用户定义的FSDP unit的类型,拆分出FSDP unit。比如一个TransformerLayer就是一个FSDP unit
-
将FSDP unit中的参数,按照dtype, is_expert, requires_grad, fsdp_unit_id来进行分组,生成若干个bucket。代码中叫ParameterGroup
- 根据dtype划分是为了支持不同精度的参数
-
根据require_grad划分是为了支持部分参数frozen的场景
-
is_expert划分是因为EDP和DP是不同的通信组
-
接着,根据is_expert, fsdp_unit_id再去group,用于聚合通信
- 同样,因为EDP/DP是不同的通信组,无法聚合通信,所以分成两个组
- 每一个bucket底层对应一个几个DataParallelBuffer,负责维护shard/unshard的数据
- 根据shard策略的不同,对应的DataParallelBuffer的数量也有不同。
-
model_weight_buffer,负责维护训练时的模型参数,用于forward/backward,一般是低精度fp16等类型
-
main_grad_buffer,负责维护梯度,backward之后会将梯度放到这里,做RS
-
main_weight_buffer,负责维护master weight,用于混合精度训练。不会做unshard。
-
这块在划分的时候还有一个chunk_size_factor的逻辑我没看懂,如果有了解的大佬还希望帮忙讲解一下。
除了上面的划分逻辑之外,wrap module还会做两件事:
- 注册hook,pre/post forward/backward,state_dict等
-
同时会将Param替换成DTensor,类似torch FSDP2的设计。对用户暴露的是DTensor,而非shard版本的参数。
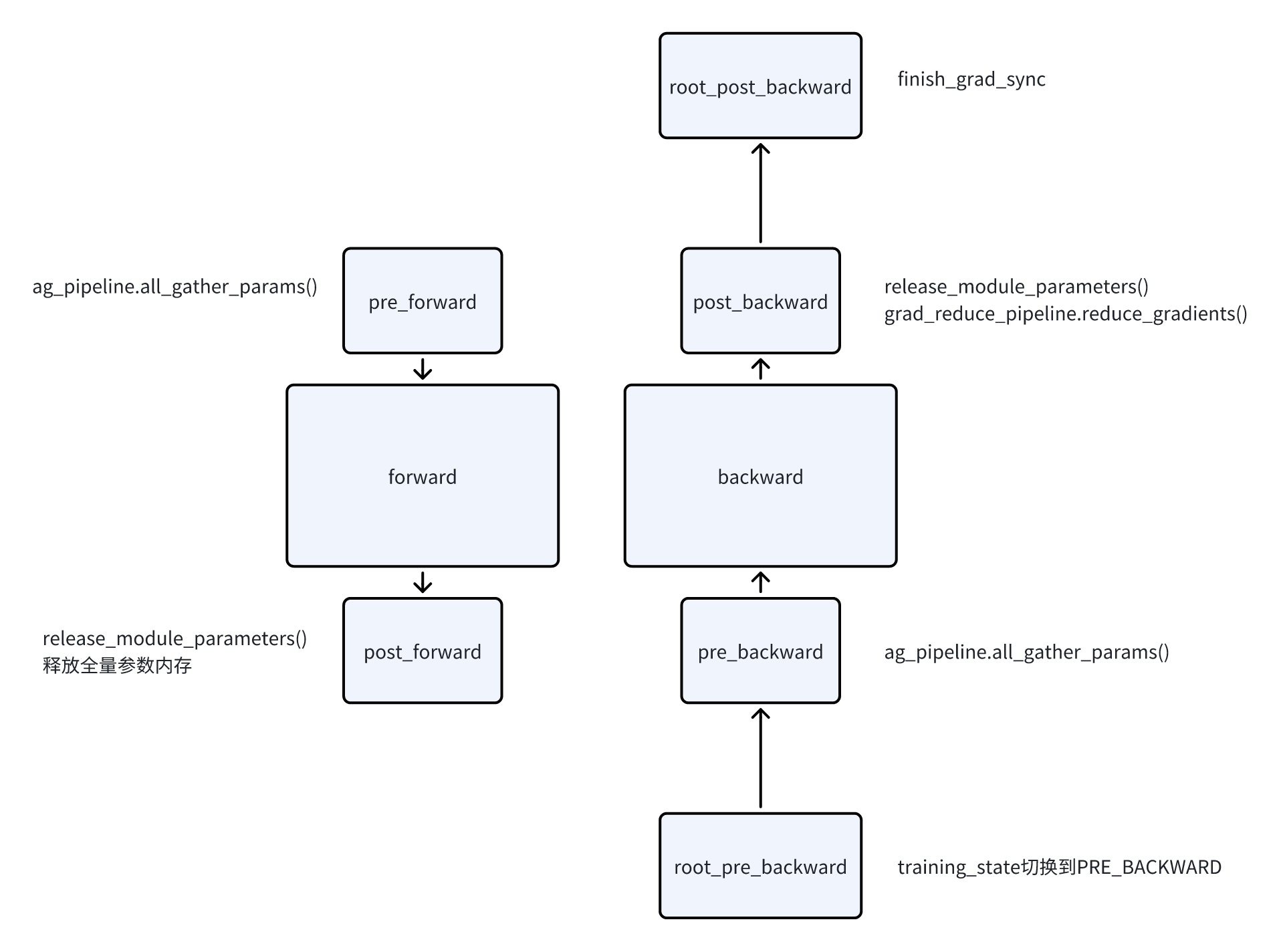
Runtime相关的逻辑被抽到了两个子类中,GradReducePipeline和AllGatherPipeline
GradReducePipeline的核心逻辑在reduce_gradients中,会做梯度的RS,以及相关的限流。
AllGatherPipeline的核心逻辑在all_gather_params和wait_bucket_ready中,会做prefetch,参数的AllGather,以及限流
流程如图所示:
详细的实现细节就放到我的源码阅读笔记里了,感兴趣的同学可以自行翻阅。这里再提几个值得关注的点:
- post_forward/post_backward并没有做reshard(),替换模型参数等操作(类似torch FSDP)。只是单纯释放了内存,此时param指向的就是一个空的内存。
-
同样有training_state来区分当前的状态,用于区分pre_forward是在做forward,还是在做activation recomputation。避免重复做all gather
-
做梯度的同步的时候,需要把所有require grad的参数都拿出来同步,而不能只是同步grad is not None的。比如在MoE场景,可能部分expert没有被路由到,导致梯度为None,此时如果不进行reduce的话,会卡住其他进程的通信操作。
DTensor & Optimizer
因为FSDP将参数包装成了DTensor对用户,外部可以使用一个支持DTensor的optimizer来优化参数。
而在使用过程中,Megatron没有依赖DTensor的redistribute,而是自己实现的all-gather相关的逻辑。
同时,因为混合精度训练的原因,我们需要把optimizer优化的参数更新到低精度的参数中。
这一节来整理一下这个流程:
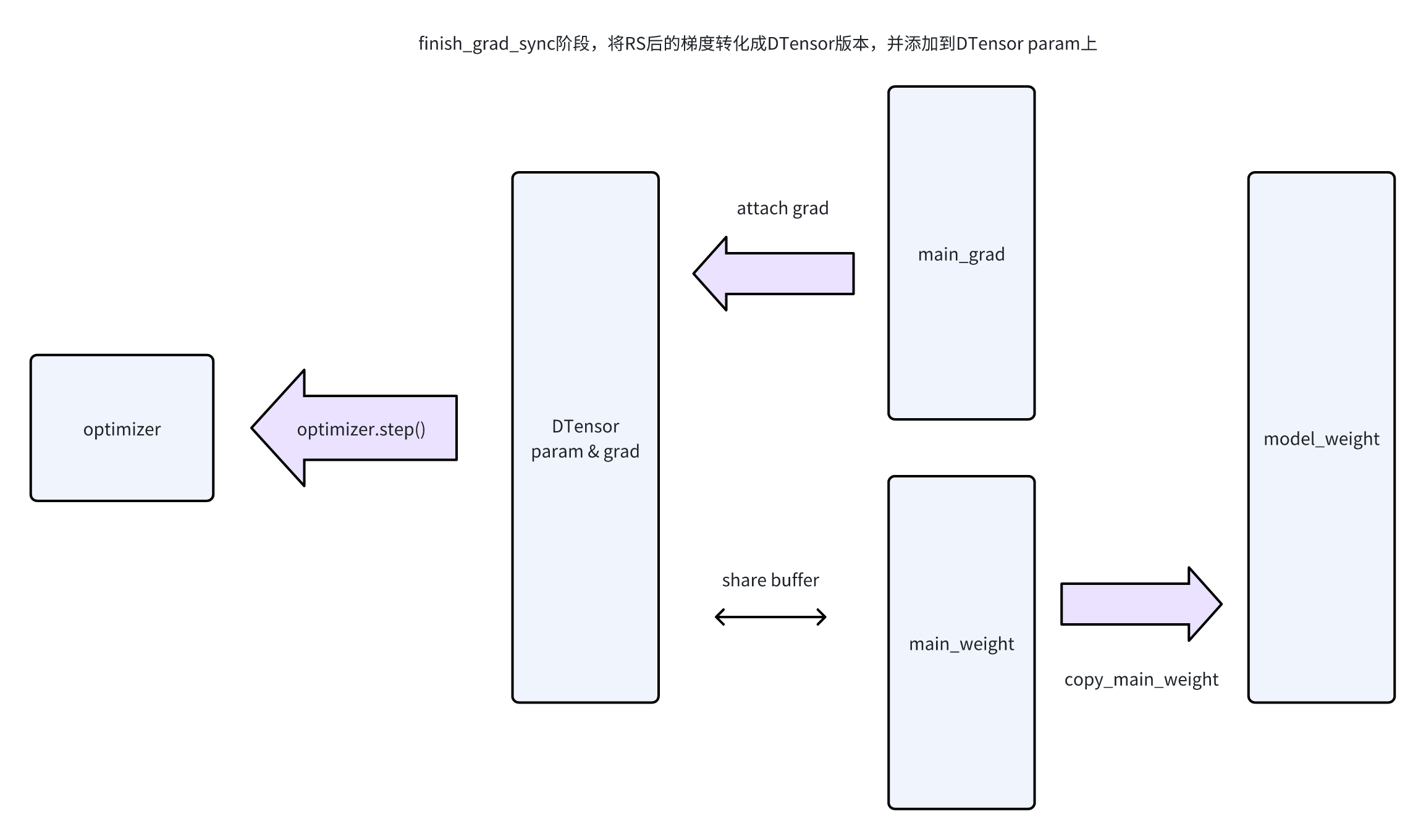
- 一个step计算结束后,调用finish_grad_sync,此时会将grad设置到DTensor param的grad上
-
optimizer.step(),读取DTensor param,进行更新。同时因为DTensor param的data buffer和main_weight的data buffer是共享的,所以也更新了main_weight_buffer
-
optimizer.step()后,通过copy_main_weights_to_model_weights,把参数复制到model_weight上
虽然这里传给optimizer的是DTensor,但是在使用的时候还是用的local tensor,所以不用担心有额外的通信开销:
- 对于grad norm clipping,会用local tensor来算,再去reduce
-
对于Adam.step(),这种element-wise的操作不会涉及到通信,DTensor会直接在local_tensor上执行
还有一点要提的是,MegatronLM中这里的DTensor的创建,相比于fsdp2更加复杂,考虑了DP/CP/EP等方式,是一个更加复杂的DTensor,感兴趣可以看make_fsdp_dtensor这个函数。
fully_shard这里还提供了一个fully_shard_optimizer的能力,(猜测)可以支持任意的optimizer,会在optimizer.step()/zero_grad()上注入上面说的hook,做install_grad,以及copy_main_weight
Memory management
内存主要是FSDP本身使用的,即上面的main_grad_buffer/main_weight_buffer/model_weight_buffer。以及是在做prefetch预先分配的内存。
先看Prefetch相关的逻辑,看一下是怎么做overlap,以及限制并发的。在代码中主要是wait_grad_reduce,以及wait_bucket_ready
- wait_bucket_ready
- cpu进行同步,等待当前module的param ready
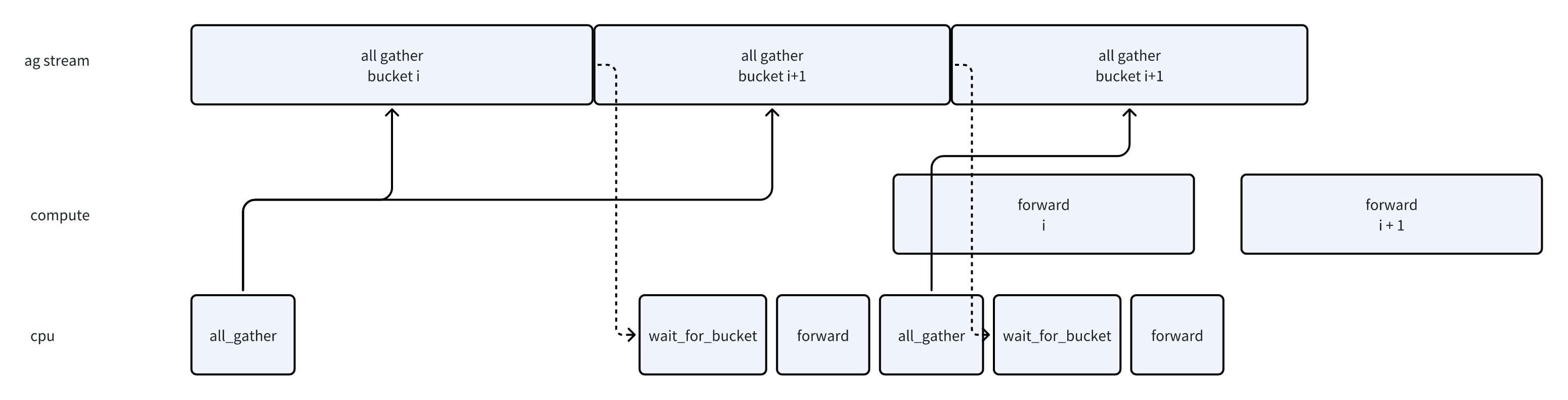
- 从图上可以看出来,每次cpu会同步等待all gather的结果。同时因为prefetch每次都是基于当前的module计算的,在prefetch没预判错的情况下,最多是会有AG_prefetch_size这么多额外的数据。
-
这块的实现也有点类似torch FSDP1,就是通过cpu的等待来避免发出过多的all gather
-
wait_for_previous_grad_reduce
- 维护了当前inflight的grad reduce操作。inflight size超过阈值就会做cpu同步等待
-
对比一下,torch那边就是直接释放了,但是用了RecordStream来避免内存出错
在阅读代码的时候会发现MegatronLM中没有RecordStream,而是主要依赖CPU来进行同步。这里来分析一下All Gather的case:
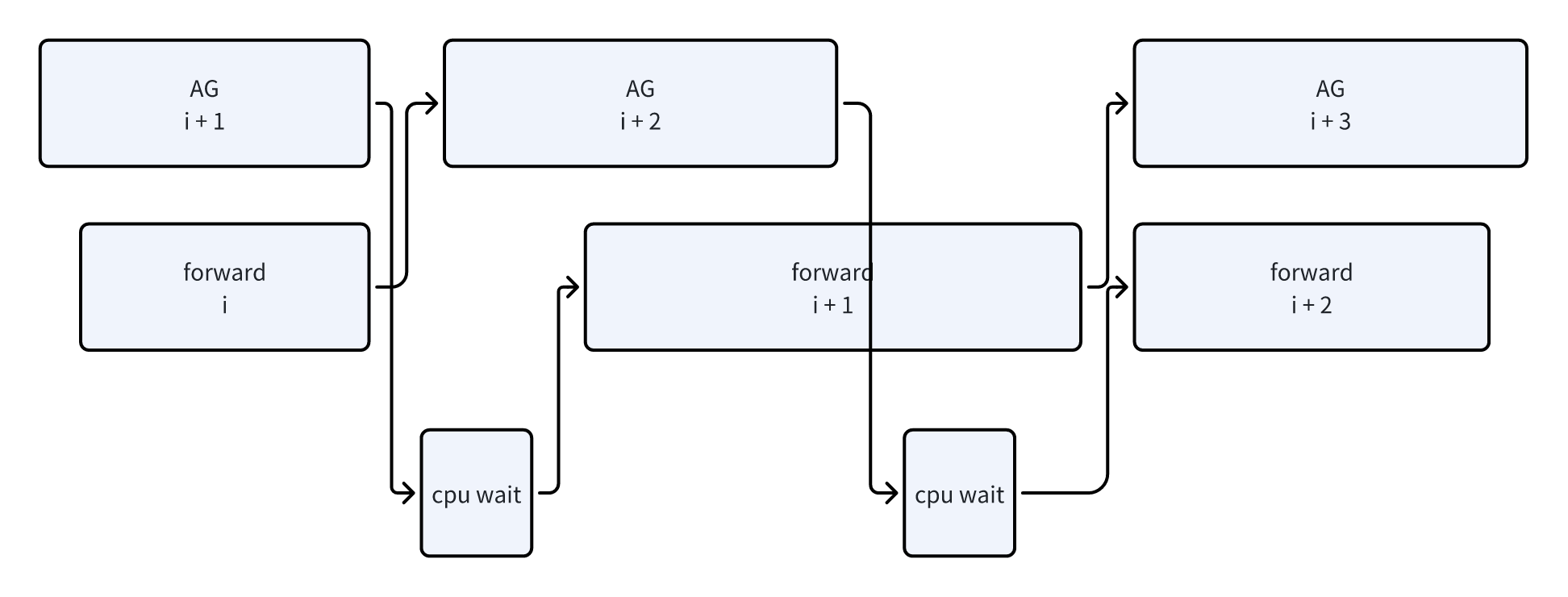
两个同步点:
- CPU wait,在第i个forward之前,等待第i个all gather完成
-
每次all gather之前,在ag stream上等待前一个forward完成。这里就是针对防止内存复用设计的
- 考虑第i个all gather,分配了一段内存。进行forward,然后post forward释放掉这段内存
-
第i + 1个all gather在执行时,会申请内存,因为第i个all gather的内存已经释放了,所以此时第i + 1个all gather就可能复用到第i个all gather的内存
-
但是此时CPU执行i + 1 all gather内存分配时,GPU还在使用第i个all gather的内存。所以为了避免第i + 1个all gather使用时,第i个forward正在执行(因为在同一个AG stream,所以不可能和第i个all gather冲突),所以这里让AG stream等待前一个compute stream
-
不过这并不代表串行执行,因为prefetch的原因,第i + 1个param可能早就完成了,第i+1个all gather是发起更后面的module的AG
有关模型内存:
- main_weight,持久在内存中,存全精度参数。不会进行unshard
-
model_weight,存低精度参数,preforward做unshard,postforward会释放
-
main_grad,post backward阶段会释放model_weight,然后分配buffer,做reduce scatter,完成后会释放
Other
有一个额外的小细节可以关注,就是代码中有一个grad_added_to_main_grad的标志:
- 他的作用是表示梯度是否已经累积到main_grad_buffer中了。
-
在TransformerEngine的算子中,可以直接把grad累加到main_grad上,而不需要先放到param.grad,再拷贝到main_grad_buffer中。所以需要这个grad_added_to_main_grad标志来记录梯度是否已经被累加这个行为。
-
在torch中,有意的把FlatParam加入到计算图中,让梯度可以直接流到FlatParam上,可以节省一次拷贝。
-
而MegatronLM中,类似FSDP2,没有修改原始的param,就需要引入一次额外的拷贝。但是通过TransformerEngine可以消除掉这个拷贝。
-
除去TransformerEngine的算子,在TP的LinearWithGradAccumulationAndAsyncCommunication也可以看到,打开
gradient_accumulation_fusion后,会将梯度直接写到main_grad中
在使用MegatronFSDP类的时候,外面套了一个FullyShardedDataParallel来初始化一些相关的参数。比较关键的一个就是描述并行策略的FSDPDistributedIndex:
- 启动了Partial DistOptimizer,也就启动了HSDP
-
DP和CP是被拍平的,FSDP中的DP就是DP+CP
-
EP/非EP中,DP/TP group不同。所以在做同步的时候,需要根据当前参数类型来选择group
-
默认的切分顺序是dp_cp, ep, tp
代码中还有HSDP,nccl_ub等功能没有解释,后面再单独出一篇文章。
DistributedOptimizer
这一节是后面更新的,简单讲一下DistributedOptimizer相关的逻辑,以及MegatronLM中是怎么使用的。
optimizer的创建逻辑在get_megatron_optimizer中:
- 根据用户的配置,给parameter划分组
-
区分expert/非expert参数,分别构建Optimizer,并使用ChainedOptimizer组合它们。
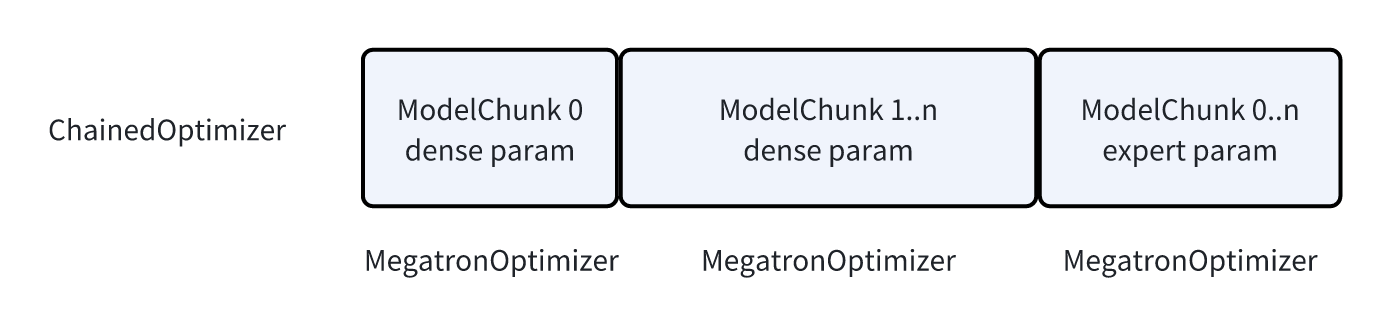
划分差不多是这样
MegatronLM中,支持的optimizer算法就是SGD和Adam。不过有几个版本的实现,来自torch/transformer engine/apex。在此之上构建了一些额外的Optimizer wrapper,用来提供不同的能力
主要需要了解的就是两个,Float16OptimizerWithFloat16Params,以及DistributedOptimizer
Float16OptimizerWithFloat16Params的核心逻辑就是让优化器永远更新 fp32 main 参数,而模型前向/反向仍用 fp16/bf16(以及原生 fp32)参数。维护了2组参数:
- float16(fp16, bf16),模型中使用float16,会将float16转化成fp32保存在optimizer中
-
fp32,模型中本身就是fp32的参数,在optimizer中保持不变
那么在optimizer.step()的时候,就是从float16的参数中把梯度取出来,转化成float32版本保存到fp32的参数中。在参数更新完成后,再把fp32的参数拷回float16的参数中。
除了精度转化的逻辑外,作为用于混合精度训练的Optimizer,还支持了做GradScale。这块逻辑和其他框架一样,就不单独介绍了。
MegatronLM的optimizer还做了两个额外的处理:
- main_grad的转化,optimizer中只认param.grad,而MegatronLM中的梯度都是积累到了main_grad上。所以会在optimizer step之前把main grad移动过去。
-
Grad clipping。也是类似FSDP1,提供了分布式版本的grad clipping的实现。在计算完本地的grad norm之后,需要在parallel group中做all-reduce。实现上区分了data_parallel_group和model_parallel_group
- expert的model_parallel_group是expt, tp, pp
-
非expert的model_parallel_group是tp + pp
-
data_parallel_group来自于DTensor,代表dp + cp
对于DistributedOptimizer,其实复杂的逻辑主要在distributed checkpoint上,我们放到checkpoint的文章再讲。这里主要讲一些计算相关的。
DistributedOptimizer主要和上面提到的这两种DP方式(DDP,FSDP)来配合,同时支持MixedPrecision。
- 所以一部分逻辑是在处理上面说的精度转化,main_param/param的拷贝,main_grad/grad的拷贝。
-
还有一部分逻辑负责处理数据的分片。
当使用FSDP的时候,精度的转化,param/grad的拷贝都在FSDP的几个buffer中做了。DistributedOptimizer没有做什么额外的操作。更多的就是调用一下本地的optimizer.step()
当使用DDP的时候,每个rank上会保存全量的参数,以及grad。但是optimizer是切分的。所以这里做的事情包含:
- 维护每个rank本地optimizer负责的那块参数。在汇聚梯度阶段DDP会做ReduceScatter,每个rank最终会得到一部分的梯度。但是因为梯度的buffer是全量的,所以需要维护一下当前grad buffer中,那些数据是真的有效的,对应当前rank的。
-
optimizer中维护shard版本的param/grad,在optimizer step之前,根据预先计算好的索引,从grad buffer中取出对应部分的梯度,放到main_param上。optimizer step结束后,将对应的shard版本的main_param拷贝回model param上。
-
因为每个shard上现在只有部分参数,DistributedOptimizer会负责在optimizer.step()之后启动参数的all-gather
- 对于FSDP来说,就是异步的all-gather,相当于进行prefetch。
-
不过这里会对所有的model_chunk都启动all-gather,感觉对于后面的chunk有点早了。同时和之前提到的在VPP中做all-gather也有一些冲突。感觉是在VPP中做的会更好一些。
ChainedOptimizer还有一个优化是overlap_param_gather_with_optimizer_step:
- Chained optimizer中可能包含多个optimizer,比如VPP的时候多个model chunk。以及启动EP的时候会对expert/非expert进行分组。
-
开启overlap_param_gather_with_optimizer_step后,第一个model chunk会在optimizer完成后立刻进行start_param_sync,开始做参数的all-gather。这个all-gather就会和后面参数的optimizer step overlap起来
-
这块优化和上面DistributedOptimizer的优化有一些类似,都是提早启动all-gather
这一堆优化的参数感觉不太好理清楚,看到这里的时候我还发现一个比较怪异的逻辑
- 在开启overlap_param_gather_with_optimizer_step后。或者是单纯开启MoE + DistributedOptimizer的时候。如果使用DDP来wrap model
-
DDP的start param sync是启动全量参数的sync。而启动MoE + DistributedOptimizer的时候,会是一个ChainedOptimizer,每个子的Optimizer是一个DistributedOptimizer。
-
在dense param的optimizer step之后,就会启动model的param sync。这个param sync同步的是model下全量的参数。而此时moe param应该还在更新。
-
而moe更新之后,会再次做一次all gather。所以实际上做了两次all-gather。
不过从现在代码趋势上看,估计都要被megatron fsdp这个给收编了,可能后面也就不用DDP了。

文章评论