这篇文章来介绍一下MegatronLM中,有关EP部分的代码。
因为我也是头一次接触MoE相关的,同时并没有对比过其他系统(DeepSpeed等)的实现,所以这块知识单纯讲一下MegatronLM中的一些细节。
理论基础的话,我在看相关代码的时候,看了这几篇Paper:
- GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
-
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
-
DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale
-
A Hybrid Tensor-Expert-Data Parallelism Approach to Optimize Mixture-of-Experts Training
-
A Survey on Mixture of Experts in Large Language Models
-
MoE Parallel Folding: Heterogeneous Parallelism Mappings for Efficient Large-Scale MoE Model Training with Megatron Core
以及推荐一下CS336中的MoE的课,讲了模型相关的事情
这篇文章主要介绍一下基本的流程,适合对MegatronLM MoE不熟悉的同学来阅读。有关MoE一些深度的优化,比如overlap_moe_expert_parallel_comm,DeepEP等,会单独再出一篇文章
System Design
在开始看模型之前,需要先了解EP是怎么做的,有一个大概的概念,然后再去看模型的实现。
- A Survey on Mixture of Experts in Large Language Models。这里有几个比较不错的图,演示了EP是如何和TP/DP结合的。
MegatronLM中,要求如果打开EP,一定要同时打开SP。同时MegatronLM MoE的paper也主要讲了5D parallelism。所以后面我们假设 tp(sp)/cp/ep/dp/pp都是打开的。
首先看TP/CP/EP这个维度,也就是假设相同的batch,同一个layer(在一个DP/PP group内),在没有EP的时候,Attention/MLP的输出是什么样的:
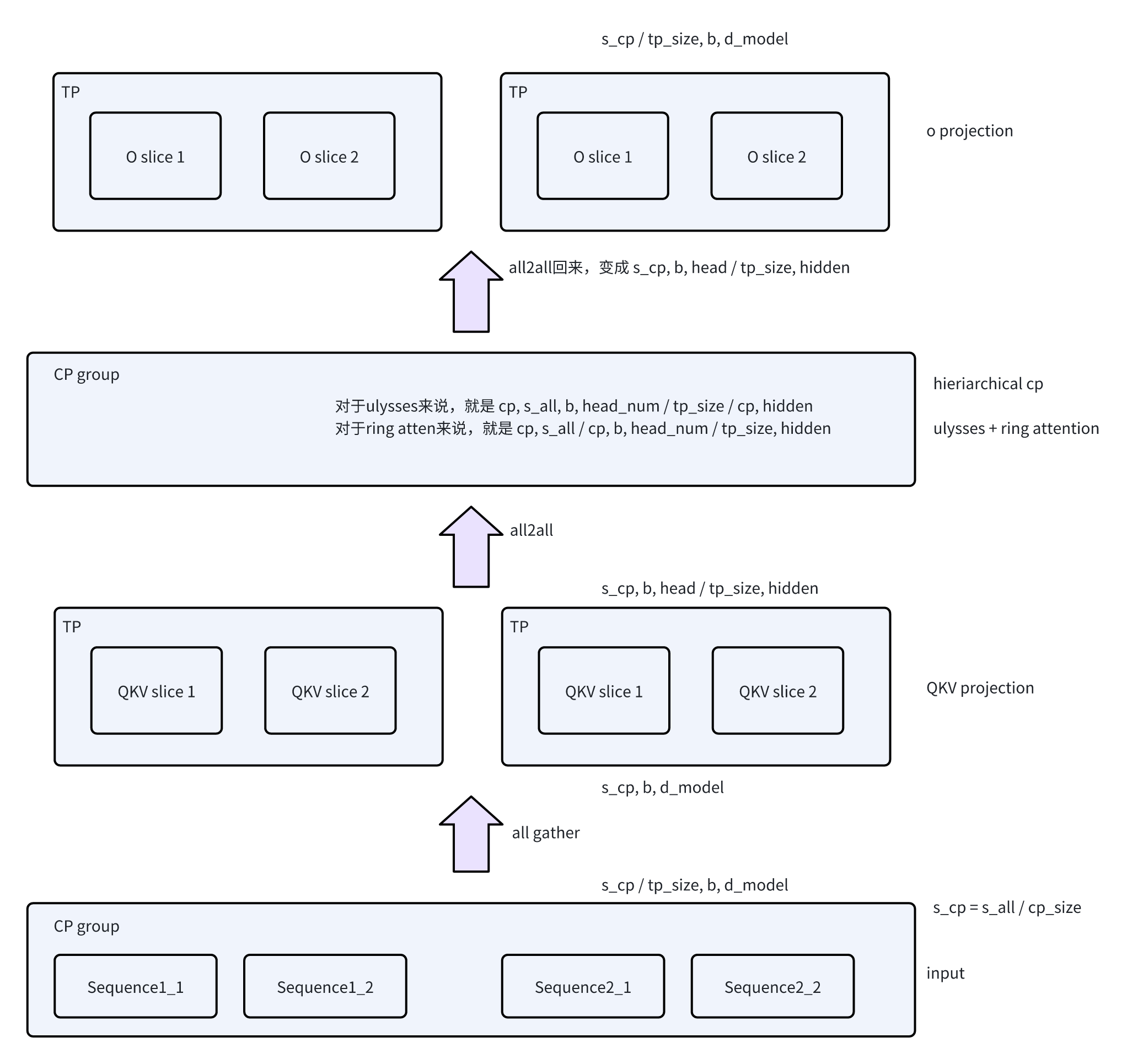
- 对于Attention来说,每一个rank的输出是[s_all / cp_size / tp_size, batch_size, d_model]
-
到MLP层,会根据TP group做All-Gather,在[s_all / cp_size]上做tokenwise的计算。
然后来看一下引入MoE后,有哪些变化:
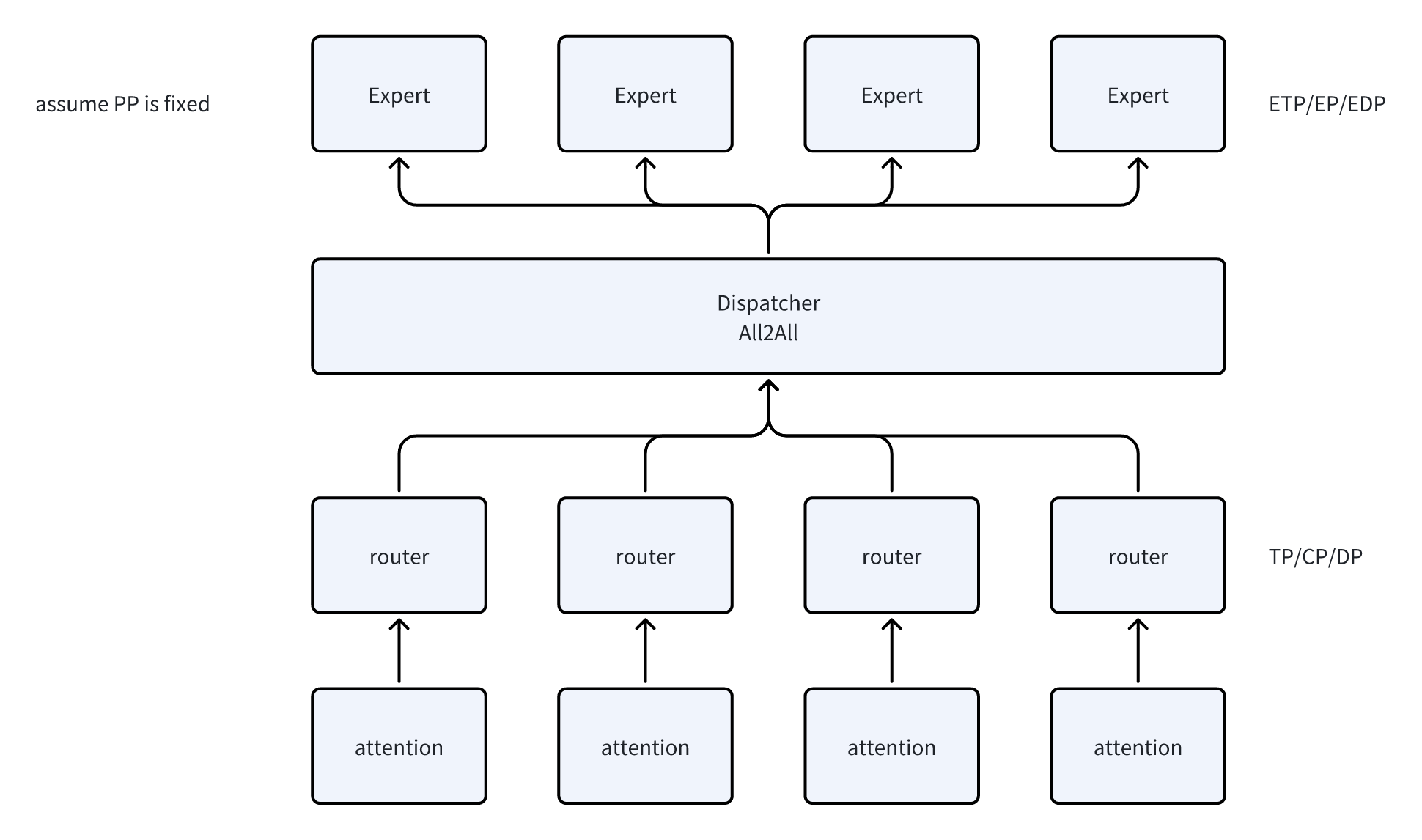
- expert的计算之前,需要通过MoE引入的两个新的组件,Router和Dispatcher
- Router做token-wise的计算,计算出每个token需要路由到那个Expert,并处理TokenDropping
-
Dispatcher负责做分发,实现上就是All2All/AllGather的通信
-
因为MoE的特性(动态路由),这里无法很好的标记每一个Rank的输入形状,这块我们主要来理解一下MLP层做EP的原理。
ParallelFolding
DeepSpeed-MoE/TED中,在Attention层使用TP/DP做并行,而在MLP层使用TP/EP做并行。EP的维度是和DP绑定的,TP的维度是固定的。这会导致一些sub optimal,来看一下论文中的例子:
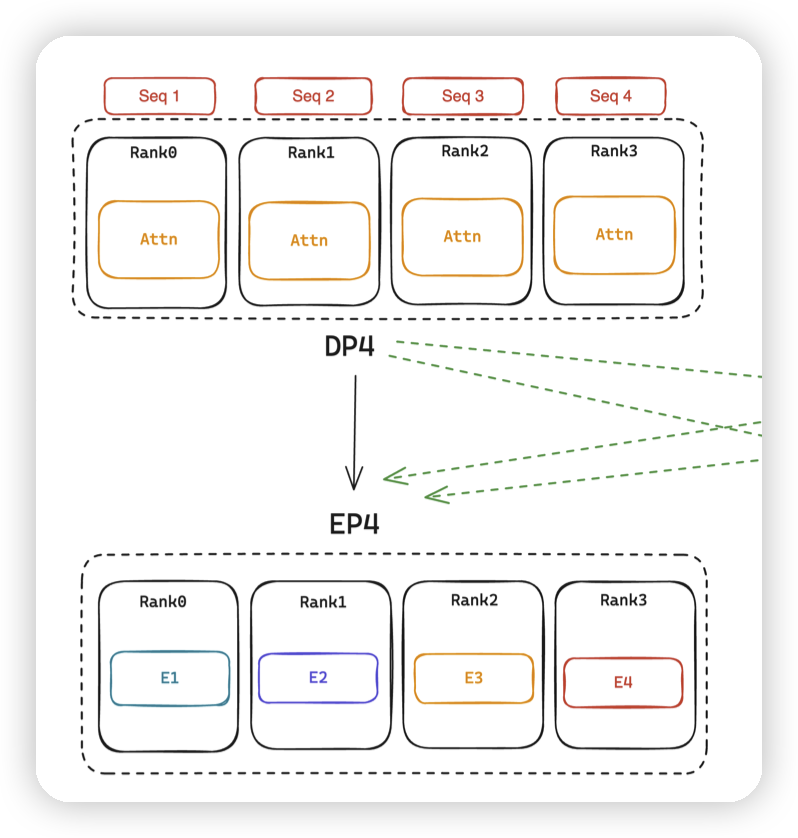
- 对应DP4转成EP4。此时如果希望扩展EP维度来提高效率的话,只能同时扩展DP,来消耗batch size
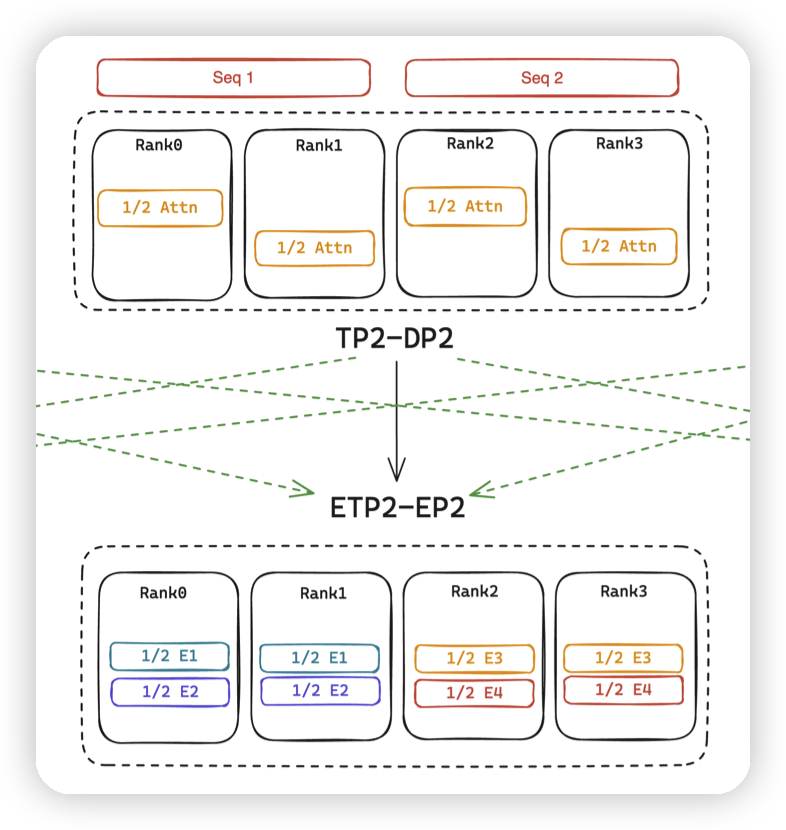
- 对应TP2转ETP2,DP2转EP2。
- 如果转化成EP4,TP1会更好。因为TP2有通信开销
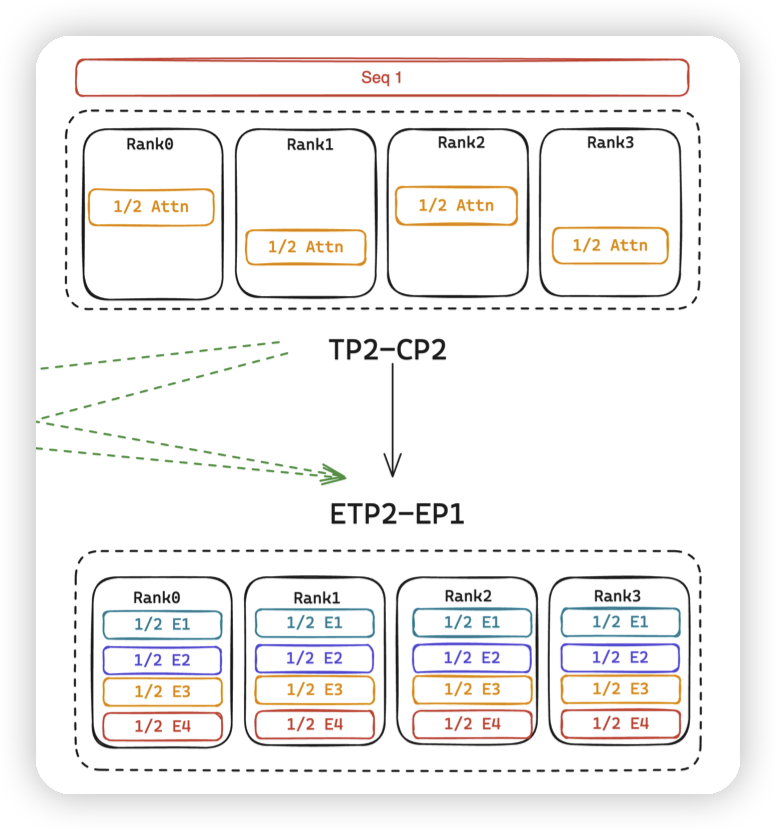
-
TP2转ETP2,CP2转成了DP2。此时所有rank都被DP/TP吃完,EP只能是1。
- 效率同样不如上面的EP4。或者做成ETP2,EP2也可以。
为了解决因为固定并行组导致的效率下降的问题,MegatronLM中引入了一个叫Parallel Folding的机制,允许在MLP这一层单独设置TP/DP的大小。
在实现上,就是两组process group:
- 在MLP层,使用的是ETP,EDP,EP group
-
在非MLP层,使用的是DP, CP, TP group
-
PP是固定的。
进程组的切换主要影响的就是数据的路由逻辑,发生在All2All的过程中。
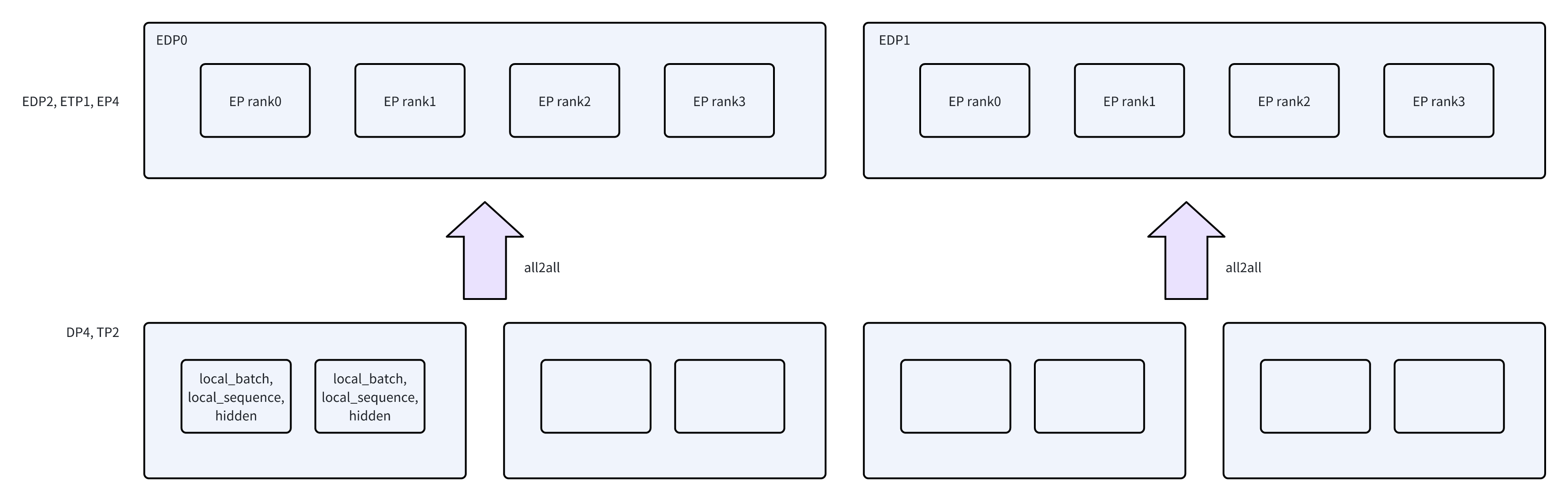
- 在All2All的时候,每个rank会在自己对应的EP/TP group中进行all2all,不同的EDP group之间不会相互通信。
-
在MoE层结束后,再通过All2All把token送回原本的rank上,恢复之前的group,继续进行后面的计算。
因为在EP层拍平了batch/sequence这两个维度,只有独立的token。同时DP/CP都涉及到模型的复制,只不过是数据切分方式不同。所以在EP这一层没有CP。
- 有关通信组的设置,可以看parallel_state.py这个文件
-
里面有一个RankGenerator,会根据RankGenerator划分的组来初始化通信组。
-
会区分expert rank generator,和非expert版本的rank generator
- Expert rank generator中,tp=etp, dp=edp, cp=1, pp不变
-
Rank generator中,则根据配置设置了tp/dp/cp/pp
除了parallel_state中,还可以看FSDPDistributedIndex的初始化逻辑,也有对expert的单独处理。
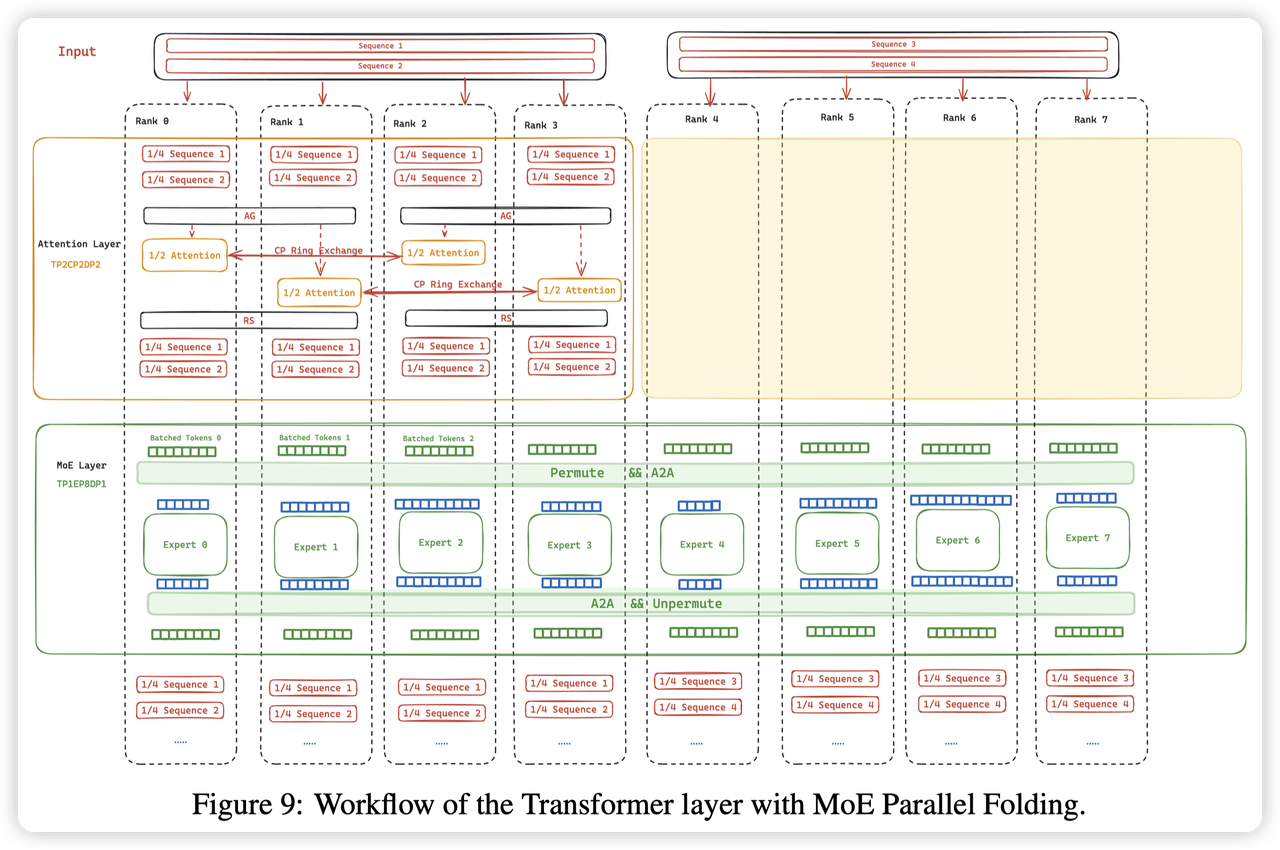
这里我再来解释一下论文中的图来帮助理解一下,从上往下看:
- 最上面的Input,是根据DP2进行拆分,每一个dp group负责两个sample。
-
rank0-3,对sequence进行了CP + TP的切分,这里是启动了SP,所以CP拆一半,SP拆一半,每个rank就是1/4的sequence
-
到Attention层,先通过AG来聚合TP的数据,让同一个TP group数据输入相同。然后TP来根据head切分attention层
-
CP group之间进行RingAttention,这里的rank0和rank2,以及rank1和rank3
-
Attention计算结束后,比如rank0,持有的是一半sequence,一半的head的输出。
-
通过ReduceScatter汇聚所有head的输出,同时切分sequence,恢复到CP2 + SP2
-
到MoE层,整个8个rank进行A2A,进行Expert的计算,再A2A回去
Model Implementation
TopkRouter
Router负责做几个事情:
- 根据router net来计算每个token的logits
-
根据score func(softmax, sigmoid)计算分数,选择token的topk个expert
-
处理TokenDropping,根据capacity丢弃多余的token。以及做padding,对于token数量不足capacity的expert,补充一些token。
-
增加辅助的loss,用于做loading balancing。expert/sequence等级别的load balance
核心代码主要在moe/router.py中
整体逻辑不算复杂,这里也就简单提几个点:
- 支持在计算token logits之前增加一个噪声,是switch transformer的思想,用来鼓励token探索新的expert。
-
Compute topk的时候,支持一个group_topk,让token先根据expert group选择若干个group,再在group内选择topk。
- 目的是希望让一个token选择的expert固定到一些组内。比如DeepSeek的Node/Device limit routing
-
group的分数是每个组选
topk // group_topk个元素的分数和
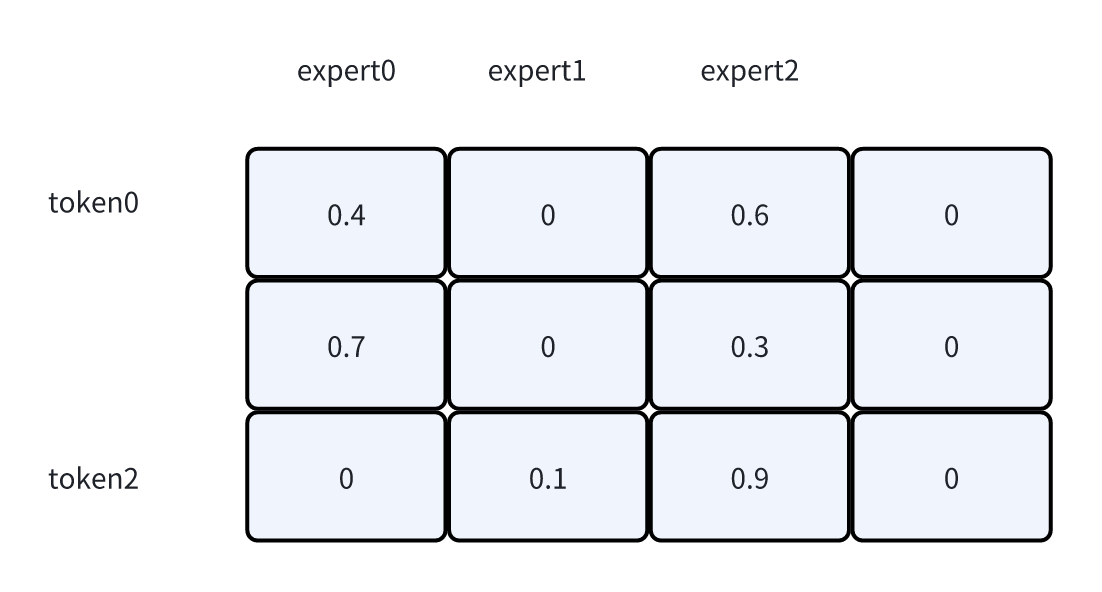
- Token dropping支持prob/position的逻辑
- prob就是根据概率选最高的。这里expert2选择的就是0.6和0.9
-
position就是根据位置选,expert2选择的就是0.6和0.3
-
pad_to_capacity
- 会强制让每个expert都有固定数量的token。可以对齐矩阵乘法的大小,同时也可以预先确定all2all的buffer大小(等下在all2all中会再详细说一下)
-
启动padding后,expert1就不只有1个token,而是会选择token0和token2(按照topk选的)
-
不过因为这个token在expert1上的分数是0,所以最终combine的时候还是没有贡献的。只是起到一个占位符的作用
-
AuxLoss如何生效:
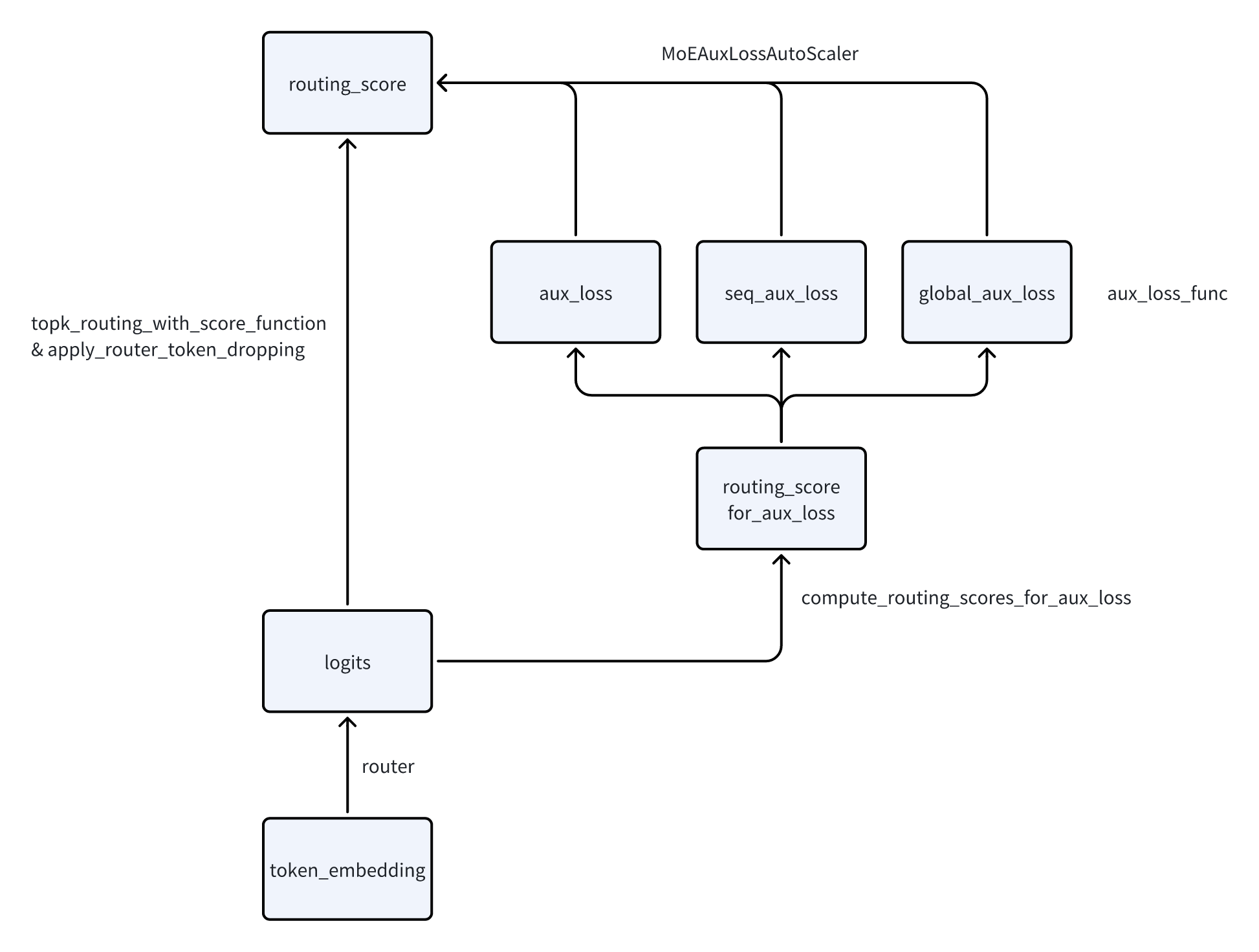
- 在主体的router链路增加了一个旁路,计算aux_loss,并通过MoEAuxLossAutoScaler接回到主链路。
-
反向传播的时候,梯度传播到routing_score上,会触发这里aux_loss的反向传播,把梯度累计到router上
-
AuxLoss的计算逻辑
- 核心都在switch_load_balancing_loss_func这个函数中,来自于switch transformer的aux loss。这个loss会期望让所有fi * Pi都是一样的值。

- seq_aux_loss
- 将routing_map/score的形状从[total_token_num, expert]转化成了[sequence, expert * batch_size]。每一个expert就变成了sequence级别的expert。在上面做load balance相当于是让每个expert在sequence级别做均衡。
-
逻辑上等价于对每一个sequence,调用switch_load_balancing_loss_func,然后再做avg。
-
global_aux_loss
- 在global_tokens_per_expert上维护了多个step的token_per_expert。用多个step的平均值来做load balance
- Global load balancing,对应论文:Demons in the Detail: On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models
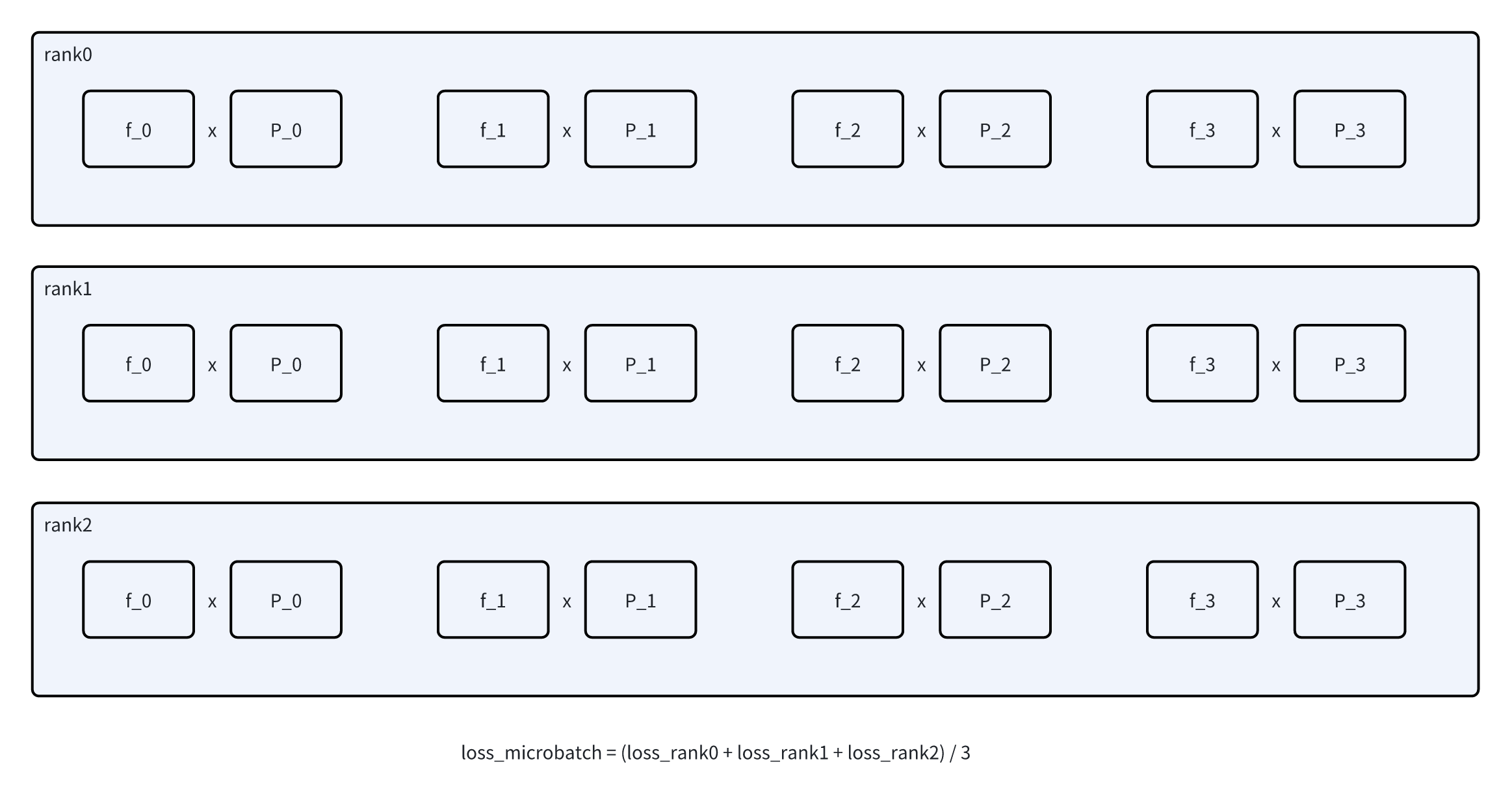
- 文中提到,在做分布式训练的时候,很多现有的MoE loadbalancing loss是先根据本地的micro batch算,然后做一下all-reduce作为最终的loss。相当于是做local rank内部的load balance。如图1
-
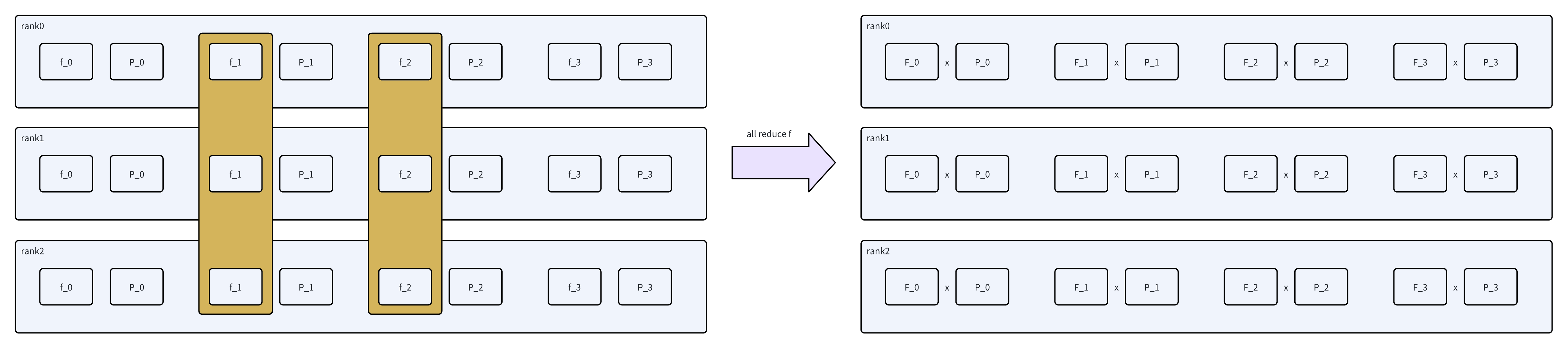
而实际希望做的是global load balance,希望计算全局的P和f。而全局的P和f需要做all reduce,这里有一个技巧,如图2。先all-reduce f,计算全局的F。此时所有rank的F都相同,就可以作为公因数提出来,用local P和global F来计算了
- 这里还有一个奇怪的点我还没搞明白,也可能是bug:
- AuxLoss这里做reduce的时候,是在tp_cp_group上做的。是非MoE的group
-
而AllToAllDispatcher是在MoE的tp_ep_group上做的。
-
这里实际分发的组和做load balance的组不是一样的。感觉可能有点问题
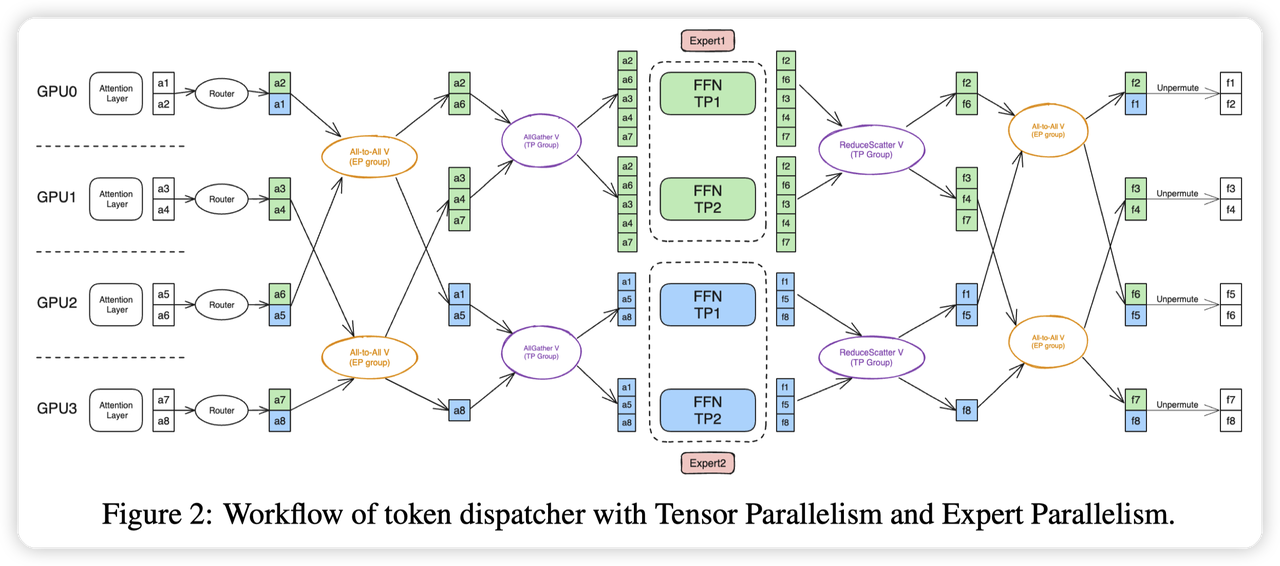
AllToAllTokenDispatcher
实现上有三个Dispatcher,AllGatherDispatcher比较简单;然后还有优化版本的FlexDispatcher,支持DeepEP;这里我们主要介绍一下比较经典的AllToAllDispatcher
AllToAllTokenDispatcher的核心逻辑就是做all2all,分发token,做完expert的计算后,再做all2all把token路由回原本的rank。代码上分为几个步骤,在注释中也有提:
- preprocess
- 计算通信需要的元数据,因为每个rank有local rank对应token的路由信息,通过all reduce来得到全局的路由信息。从而计算当前rank要给其他rank发多少数据,以及从其他rank收多少数据。
-
input_splits,all2all的输入,shape为(ep_size),表示给每个ep_rank要发多少token
-
output_splits,all2all的输出,shape为(ep_size),表示当前rank从每个ep_rank中收多少token
-
output_splits_tp,表示当前的tp_group,要从其他的ep_rank中收多少token。下面会详细解释这个流程
-
num_tokens_per_local_expert,表示all2all结束后,每个local expert要负责多少token。用来做rank内部的重排布
-
num_global_tokens_per_local_expert,shape为(tp_size * ep_size, num_local_experts),含义同上面的num_tokens_per_local_expert,只不过是记录了所有rank的信息
-
dispatch_preprocess
- preprocess,对应上面的函数,计算通信需要的元信息
-
做permute,将token hidden state进行重排,将相同expert的token重排到一起,用于后面的all2all。核心流程如图,claude给画的。
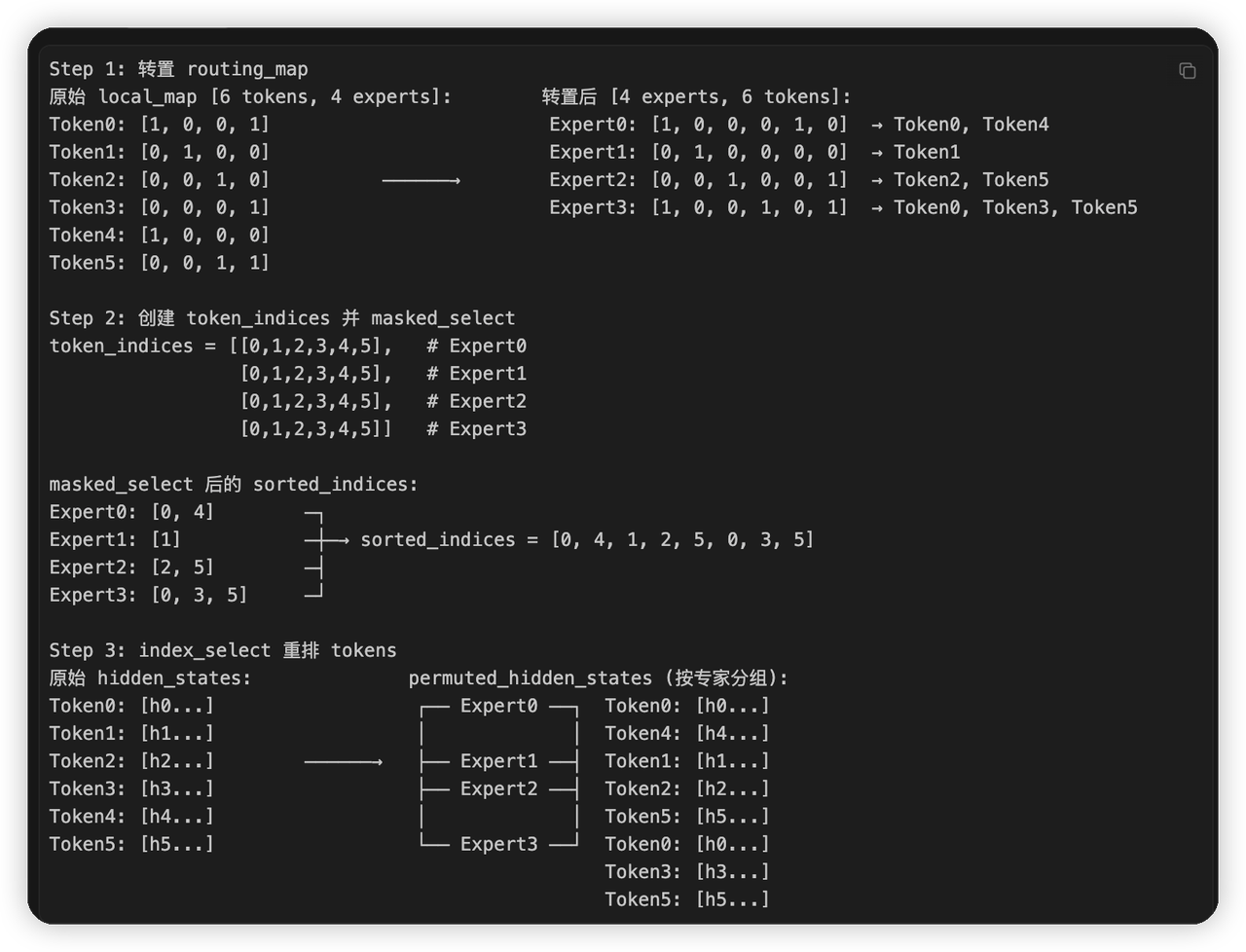
-
token_dispatch
- 对hidden_state和prob进行all2all。
-
对prob进行all2all的原因是要在expert计算的时候把加权这个事情fuse进去。
- 另一个做法就是all2all回来的时候,和shared expert一起做。
-
不过因为hidden state比较大,所以这里prob通信量远少于hidden state,所以也不是什么问题
-
dispatch_postprocess
- 做tp group的all-reduce,保证tp group中输入的token是相同的。
- 因为每个rank都负责独立的一部分token。这里会先在ep_group中做All2All,再在tp_group中做AllReduce
-
做完后,就切换到了expert的parallel group中,这时候使用的就都是ETP/EDP了
-
个人感觉这里MegatronLM要求开启SP,让每个rank都负责独立的token,让这个切换逻辑变得更简单了。否则还需要处理新旧TP group的redistribution了
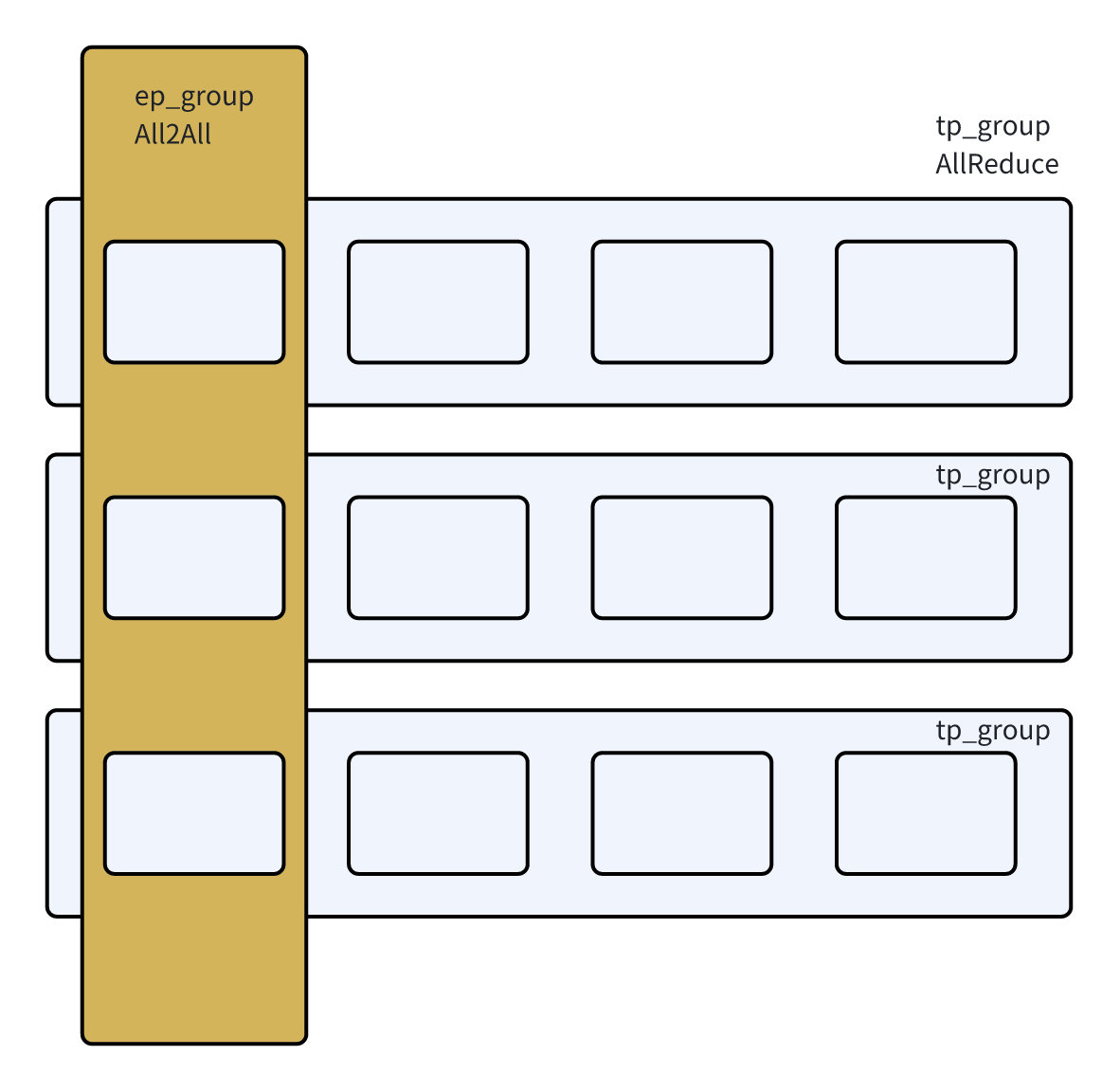
这里可能看MoE parallel folding这篇paper的图更好理解:
- all2all结束之后,buffer的第一维是rank。比如rank0_expert0, rank0_expert1, rank1_expert0, rank1_expert1。这种排布在expert上是不连续的,我们需要再重排一下,变成rank0_expert0, rank1_expert0, rank0_expert1, rank1_expert1这种。在sort_chunks_by_idxs来做。
-
相当于从[rank, expert, hidden]变成[expert, rank, hidden],只不过是变长
- 做tp group的all-reduce,保证tp group中输入的token是相同的。
-
combine_preprocess
- 这一步是已经经过expert计算完毕了,开始做数据的还原。combine_preprocess这一步对应的是dispatch_postprocess的逆操作。会重排数据,让buffer变回[rank, expert, hidden]。
-
然后做reduce_scatter,因为mlp的输出在tp group内是不同的,所以需要做all-reduce + chunk,就合并成了reduce_scatter。和没有expert的TP MLP层是一样的
-
token_combine
- 做all2all,对应token_dispatch的逆操作
- combine_postprocess
- 对应dispatch_preprocess的逆操作,做unpermute。因为combine之后,得到的是每个expert的token输出,同时涉及到一个token路由给多个expert的case。这里按照token原本的顺序还原回去,同时把多个expert的输出累加起来。
cuda_dtoh_stream
从上面说的逻辑可以感受到,All2All这里复杂性的来源主要是每个expert的token是动态的。逻辑上其实比较类似矩阵的转置,但是因为动态输入的缘故,需要多写很多代码来处理。
同时,因为动态输入的原因,这里还会涉及到两个性能相关的问题:
- 上述preprocess过程中涉及到的计算,都是在GPU上做的,来算global token num,token per expert等。但是因为需要这个信息来分配all2all的buffer,这个内存分配的行为是在CPU上做的。所以需要引入一个device/host的同步,等到GPU上的数据计算完,再回到CPU上分配。
-
动态的输入也会影响cuda graph的构建,进而导致launch kernel的开销变大。
所以MegatronLM这里提供了一个padding的功能,让每个expert的token数量的对齐,这样buffer大小是确定的,每次矩阵乘法的大小也是确定的。就可以解决上面的问题。在上面dispatcher的流程中,都会对这个配置做特判,来简化计算逻辑。感兴趣的同学可以跟着drop_and_pad这个变量看看。
这一节主要说一下优化DtoH的方式,这块还是偏源码解析一些:
- 这里引入了一个额外的stream:cuda_dtoh_stream
-
_maybe_dtoh_and_synchronize,表示用来启动DtoH的流程,并等待host上的数据准备好。
- cuda_sync_point表示何时进行同步
-
cuda_dtoh_point表示何时启动DtoH
-
在preprocess中,会做各种计算,用来给后面的流程准备元数据。不同的数据使用的位置不同。
-
cuda_dtoh_point固定为before_permutation_1,含义是在这个节点之前,所有的数据计算都已经提交到GPU上了。现在我要开始到CPU的转移了。
-
cuda_sync_point表示何时等待数据同步完成。
- 比如ep_alltoall的时候,就依赖input_splits, output_splits这两个数据来分配内存。所以会在计算input_splits,output_splits的位置设置sync_point,在all2all之前来等待这个sync_point
通过这种方式来尽量延迟CPU等待GPU的位置,从而减少这里D2H的等待开销。毕竟在关键路径上。
Experts
Expert这块的实现有几种,这里主要讲一下GroupedMLP,也是推荐的参数。
GroupedMLP核心目的是做并行的计算,把多个Expert的计算用Grouped GEMM来加速。这块我对grouped gemm并不熟悉,就说一下模型划分这块。
这里会根据ETP来做划分,有两个weight矩阵,逻辑上可以看作是先把原始的ffn 乘上local_experts,然后再根据tp来切,大概是这个感觉:

还有一个SharedExpertMLP,继承自MLP,所以自然就有TP的能力,但是这里TP group用的是非expert版本,对应的就是MoE的普通MLP。同时额外支持一个gate的功能。
还有一个特殊的点是这个SharedExpertMLP,因为计算不需要做通信,所以在Dispatcher中支持在通信的过程中做SharedExpertMLP的计算,做计算/通信的overlap
overlap的示意图如下:
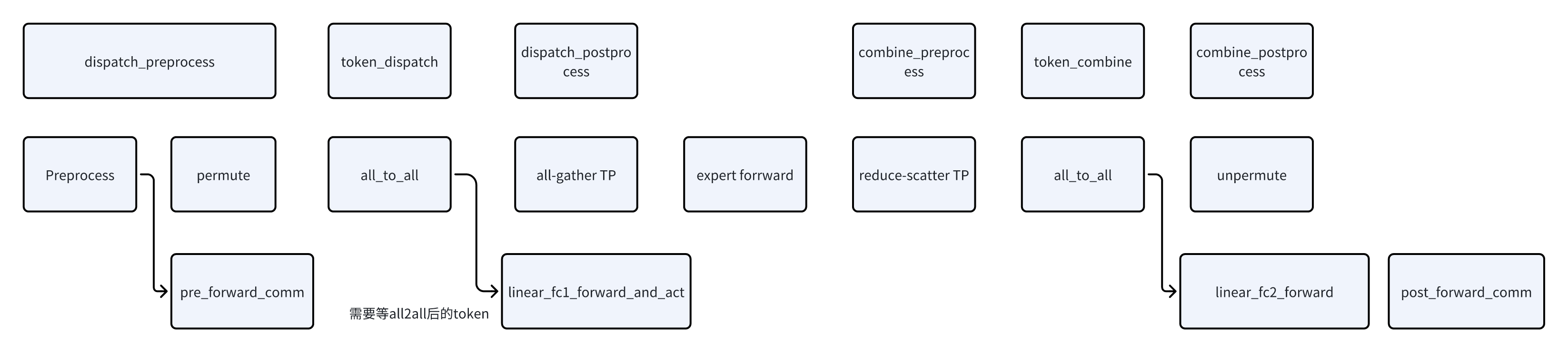
- 这里的pre_forward_comm对应TP的all-gather
-
post_forward_comm对应TP的reduce_scatter
MoELayer
MoELayer就是负责把上面的组件都串一下,并没有额外的任务。这里就画一个简单的示意图
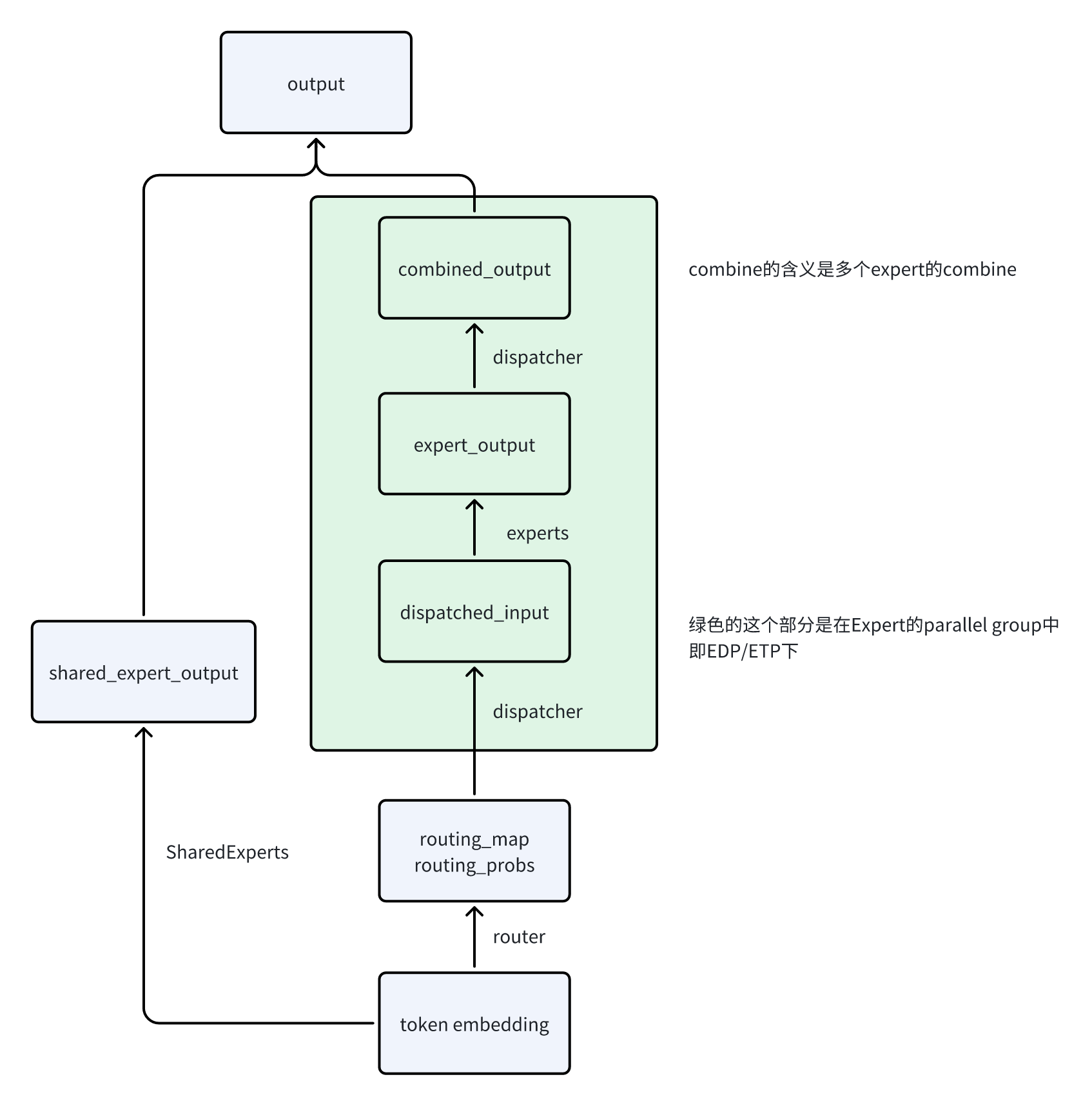
- 绿色的部分在计算的过程中使用的都是ETP/EDP这些expert专用的group
-
SharedExpert不参与通信
最后MoE这块还有一些进阶的优化,比如和PP结合的batch level A2A overlapping,后面有机会再单独出一篇文章来讲解。

文章评论