这篇文章来介绍一下MegatronLM中,PipelineParallel的实现,主要是偏源码
主要相关的论文是这一篇:Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM
还有经典的一些前置的paper:
- GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism
-
PipeDream: Generalized Pipeline Parallelism for DNN Training
-
PipelineDream2BW: Memory-Efficient Pipeline-Parallel DNN Training
PipelineParalle的实现主要涉及几个点:
- 模型如何切分
-
计算流程
-
Interleaved 1F1B
模型切分/结构
在开始之前,需要大概有一个概念,PipelineParallel的实现是每一个rank上跑一个Model的实例,只不过不同的model负责不同的层。同时stage0对应的实例也负责读数据,其他rank的model的输入数据是上一个model发来的tensor。
MegatronLM的模型切分还是按照启发式的规则来的,并没有引入什么特别的组件。
这一次还是针对GPTModel来说。
- 每一个rank上有一个GPTModel的实例
-
每一个GPT Model有一个TransformerBlock
-
每一个TransformerBlock有若干个TransformerLayer。
- 具体的数量是根据total layer的数量,除以pp_world_size来算的
-
每一个Layer会记录自己全局的offset
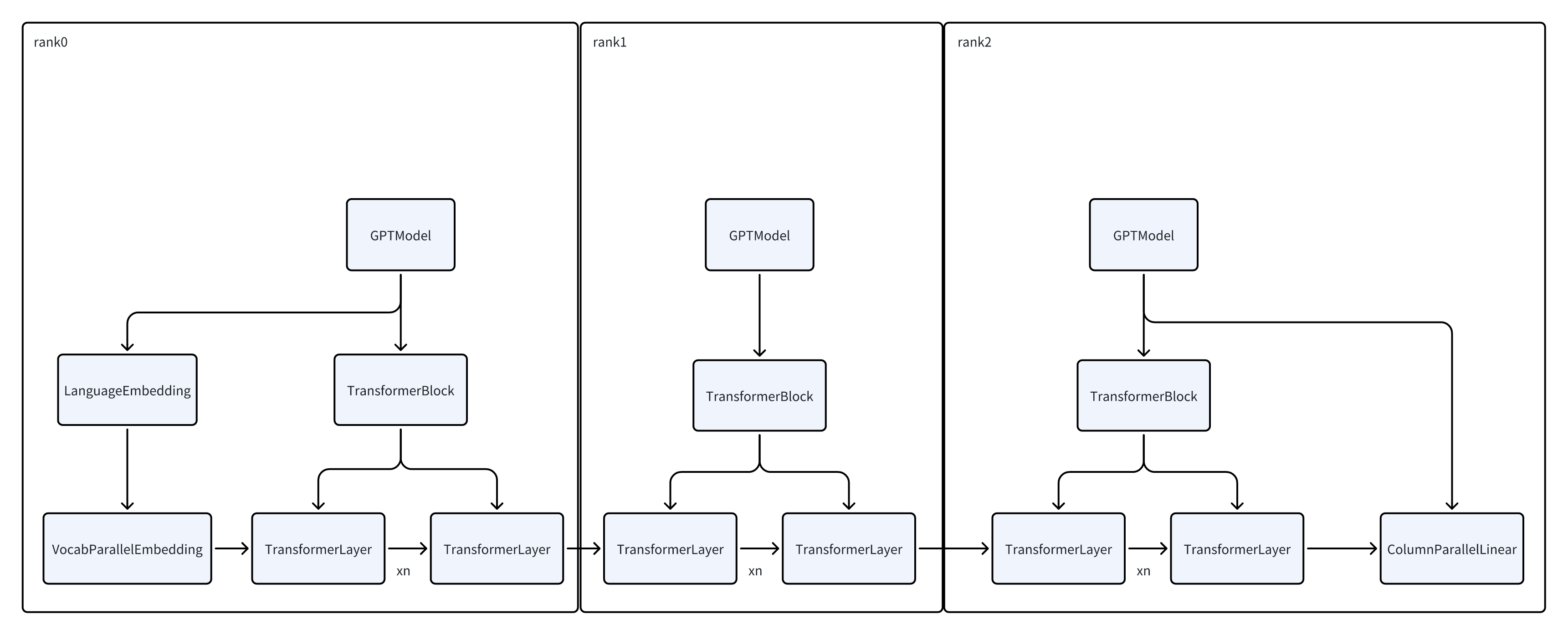
示意图差不多就是这样,中间有的层只有TransformerLayer,首尾的层有Embedding/Output,以及数据读取和loss计算的任务。
- 在切分的时候也会考虑到这一点,减少首尾rank的TransformerLayer的数量
-
详细切分的逻辑感兴趣可以看
transformer_block.py的_get_block_submodules函数
计算流程
核心逻辑都在megatron/core/pipeline_parallel/schedules.py中,用于调度forward/backward的逻辑。
如果是阅读源码的话,推荐先读一下forward_backward_pipelining_without_interleaving理解基本框架,然后再去看Interleaved 1F1B
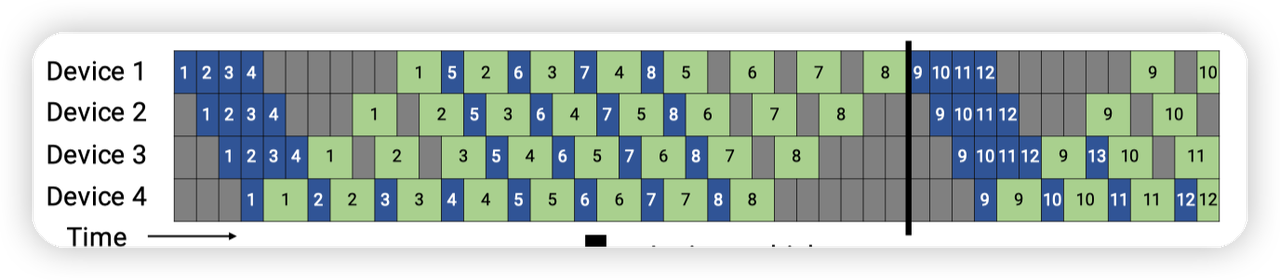
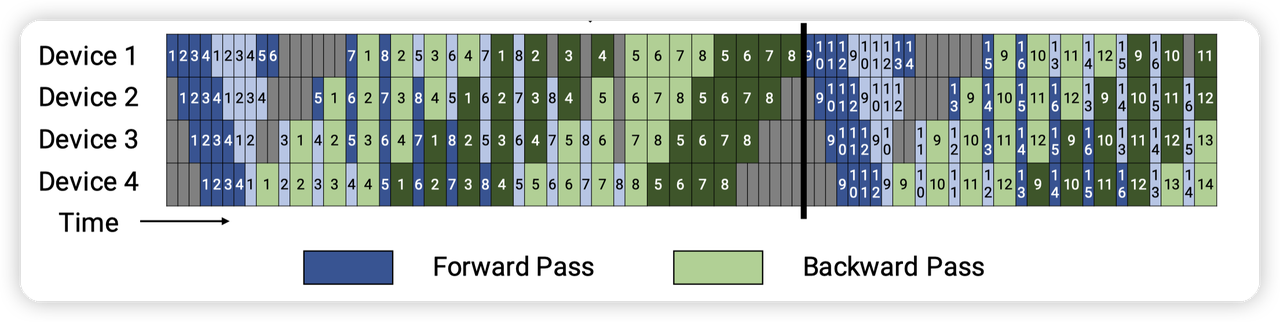
- 读代码时想着这个图即可。一个step整体分为3个阶段:
- warmup,对应图上左边几个格子,此时只有forward
-
Steady state,对应中间的格子,每个rank都是执行1F1B
-
cooldown,对应右上角的几个格子,此时只有backward
- 每一个rank进入阶段的时间点都不同,这里是以microbatch来计量的
- 比如最后一个rank,在第一个microbatch就进入了1F1B的steady state。同时也没有cool down的状态
-
而第一个rank的状态则更加复杂

- 三个状态的转移示意图,逻辑比较简单
- Warmup阶段,从前一个stage接收tensor,进行forward计算,然后发送给下一个stage
-
Steady阶段,通过send_backward_recv_forward接收上一个stage的forward,并发送计算好的grad给下一个stage,进行forward计算。然后通过send_forward_recv_backward发送tensor,并接受grad,再进行backward计算
-
Cooldown阶段,接受grad,计算backward,发送grad
实现细节
PipelineParallel的逻辑比较简单,但是实现细节还有一些需要关注:
- 上面提了,每个rank是根据microbatch来进行同步的。即根据当前的microbatch号,确定自己的阶段,是在warmup,还是在steady state,从而决定行为。
- 这块如果计算错位的话,因为这里的通信都是同步的,就可能导致死锁。
- 在steady state中,两个通信的算子都是所有rank同时从上一个stage接收一段数据,然后向下一个stage发送一段数据。
- (提前说一下)在interleaved 1F1B中,会出现环,导致有可能所有的rank都在等待上一个stage发送,没有人发数据,从而出现死锁。
-
MegatronLM这里的实现针对通信操作抽象了一个P2PCommunicator,对于这种同时收发的操作提供了一些原语,在里面会有一个死锁避免的逻辑。
-
简单来说,就是奇偶交错的发送,奇数号rank先发送,再收取。而偶数号rank则是先收取,再发送。
-
数据的收发
- 因为每个rank都是相同的forward逻辑(用户定义的),而在PP中,只有rank0才能读数据,其他rank都是读上一个rank的tensor。这块是怎么实现的?
-
在
pretrain_gpt.py中可以看一下用户定义的forward逻辑,读取数据的这块,需要用一个工具函数处理一下,基本逻辑是:- 只有pipeline first/last stage才能读取数据,其他时候传给模型的数据是None。
-
对于last stage是因为要读取label,以及loss mask
-
对于中间tensor的传递,每一个stage接收到前一个stage传过来的tensor后,会调用model.set_input_tensor(),把这个tensor透传到模型内部。
- i.e. 这里是需要模型编写者提供这个接口,并且能够使用这里设置的input tensor。否则pipeline parallel就会失效
- backward的实现
- PipelineParallel可以看作是纵向切分计算图
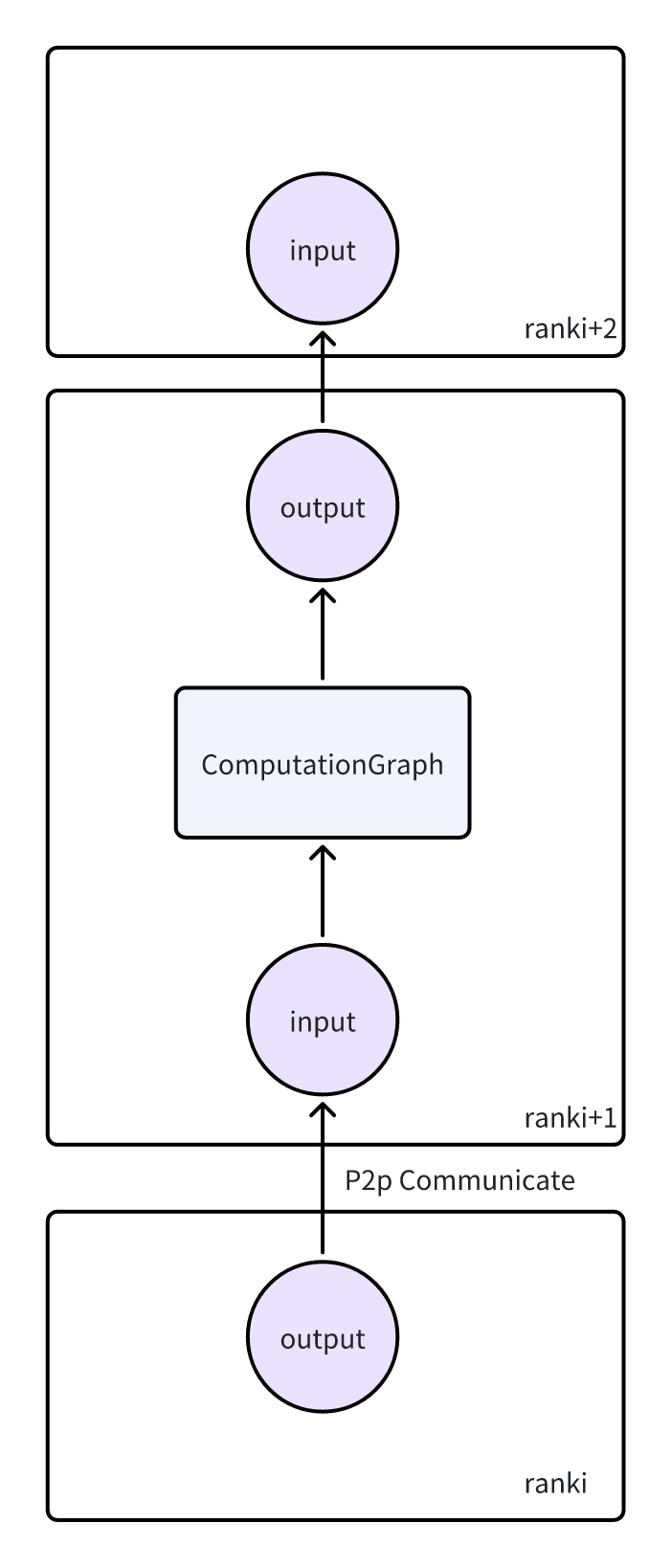
- 每一个rank的计算图的终点都在他的output tensor上。需要用这个output tensor来启动反向传播的计算
-
从上一个stage传过来梯度的时候,通过
torch.autograd.backward(output_tensor, grad_tensor=output_tensor_grad),就可以做反向传播。自动把input的梯度计算出来
优化
在这篇论文(Reducing Activation Recomputation in Large Transformer Models )中有提到这块实现。同时结合上面一节backward的实现:
- 在做反向传播的时候,每一个stage的output tensor的数据其实不会被用到
- 因为相关的计算其实在下一个stage的input tensor上发生。
-
所以这里output tensor唯一的作用就是保留计算图。
-
那么output tensor的数据本身就可以被释放。MegatronLM就提供了这样一个配置,可以forward阶段发送完数据后,释放掉output tensor的data
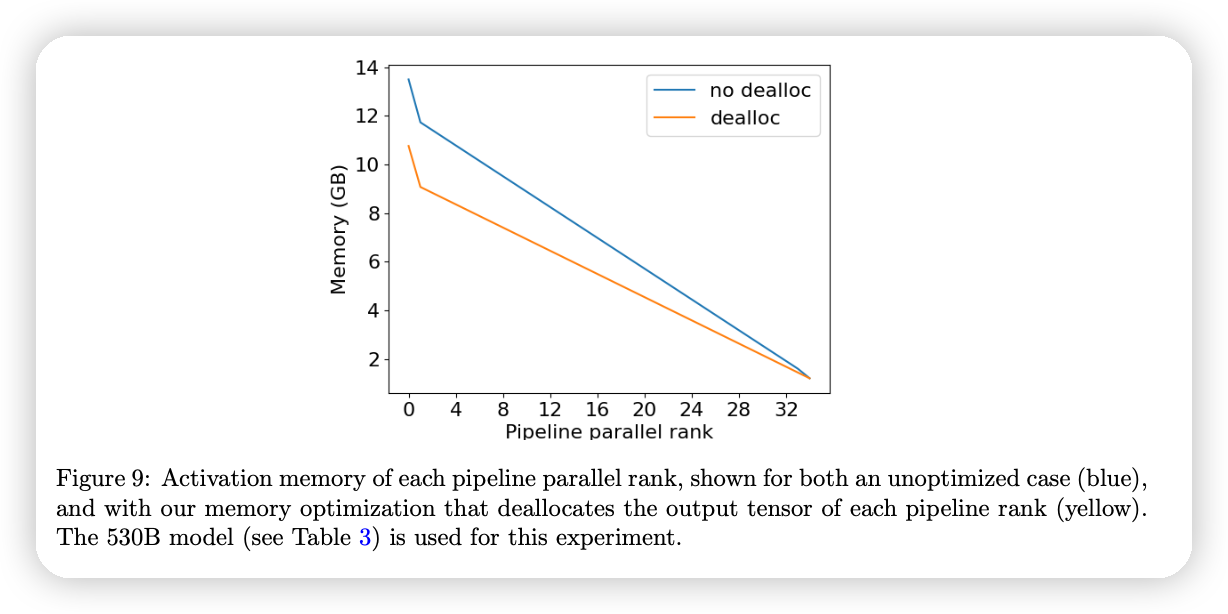
- 对应论文中的这两条线
-
同时,这里也来解释一下论文中这条线的含义,为什么rank低的地方,内存占用比较高呢?
- 这里的内存统计的是activation memory。每一个microbatch在forward之后都会保留对应的activation,并等待backward结束后才能释放。
-
从pipeline schedule中可以看到,rank号越小,越容易有更多inflight的activation。
- 比如rank0,在上面图中,有4个。而rank4,只有1个。
Interleaved 1F1B
Interleaved 1F1B的代码主要在这个函数中forward_backward_pipelining_with_interleaving
- Interleaved 1F1B可以等效的看作是有更多的microbatch。那么就可以进一步hidden bubble。缺点就是通信量更多了。在论文中的实验也可以看到
-
Interleaved 1F1B引入了两个概念:
- virtual_pipeline_stage,表示一个rank,要处理多少个pipeline stage
-
microbatch_group,因为一个rank有多个pipeline stage了,所以在处理数据时可能会面临一个决策,我是要处理新的microbatch,还是要处理存量的microbatch但是是新的stage。
-
比如图中第一行第五个块,device1可以选择处理microbatch5,或者是处理microbatch1的第5个stage。
-
这里group的作用就是,每处理一个group的数据,就切换一下stage。
-
代码中有一个get_schedule_table,来描述对于每一个virtual_microbatch,当前要处理的是第几个microbatch,以及对应的stage是什么。
-
因为有多个stage,所以现在每一个rank上不只是有一个model,而是一个model list,称为model chunk。对应的是不同的virtual stage。
边界计算
-
Interleaved 1F1B的调度的核心思路是尽早的进入steady state,按照这个原则来理解代码中的一些边界计算条件会好一些。我这里简单画了几个不同group/virtual stage的图来辅助理解
-
virtual_stage = 3
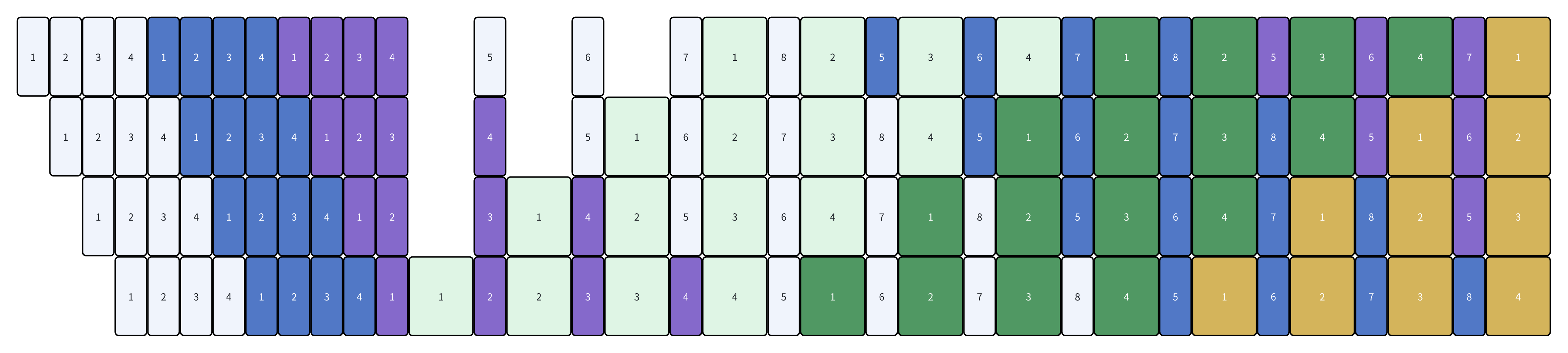
- microbatch_group = 8
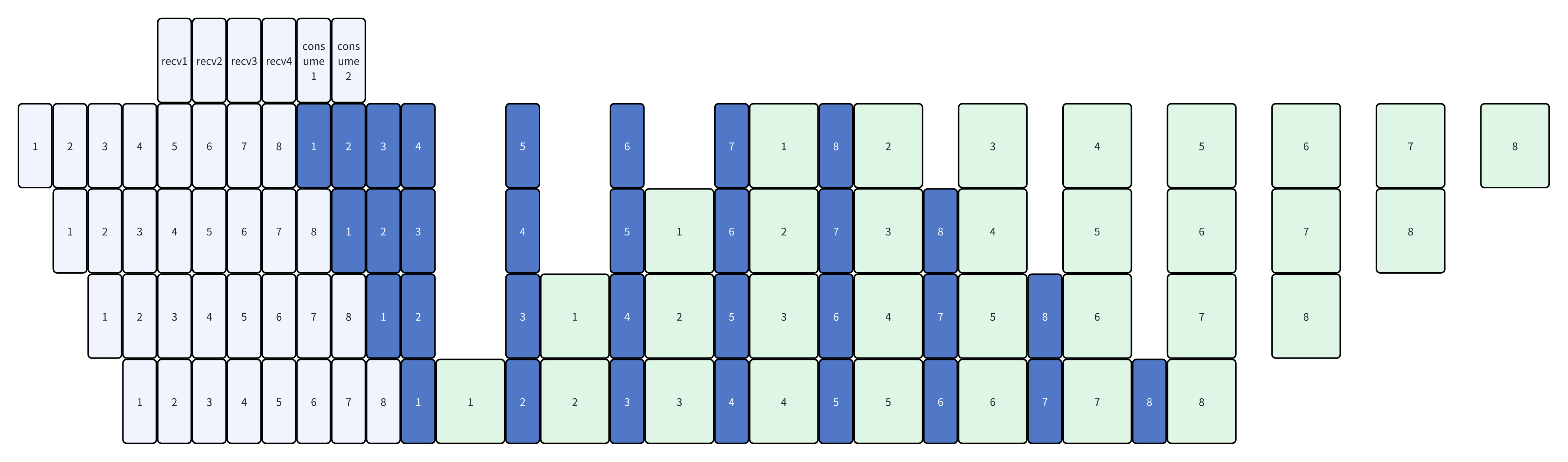
上面提到了,几个阶段的切换点比较关键,如果写错容易死锁,相关的代码在get_pp_rank_microbatches中,这里给出一个偏直观的解释,解释一下warmup stage的计算逻辑
- 对于最后一个device来说,第一个backward发生于
- group_size * (vp_size - 1)这个microbatch上
-
因为是处理一个group后,才会切换到下一个vp stage。所以到达最后一个vp stage之前,需要(vp_size - 1) * group_size这么多个microbatch。到了最后一个vp stage之后,可以立刻进行forward + backward,从而进入steady state
-
对于非最后一个device来说,首先需要等last stage这么多。
- 然后为了保证后面的stage能够尽快进入steady state,需要额外做一下forward
-
每一个stage会比上一个stage晚一个microbatch,同时需要多做一个batch的forward
-
最后一个rank就是0,倒数第二个就是2,倒数第三个就是4。
-
所以最后是(pipeline_parallel_size - rank - 1) * 2
这块还有一个细节可以提一下,就是针对microbatch_group size > pp_world_size的情况的,可以看一下上面画的microbatch_group=8的图:
- 在第5个batch的时候,此时已经收到了最后一个device传来的1的计算结果。但是因为当前microgroup还没算完,所以需要把这个结果缓存下来。
-
所以在代码中会看到,对于first stage,buffer数组的大小会大一些。而其他stage的buffer size都是只有1。
Overlapped
计算的核心流程和非Interleaved差不多,这里就不再重复了。主要说一些多的东西。
- Interleaved 1F1B还支持一个overlap的功能。通过forward/backward的计算来掩盖对方的通信开销。
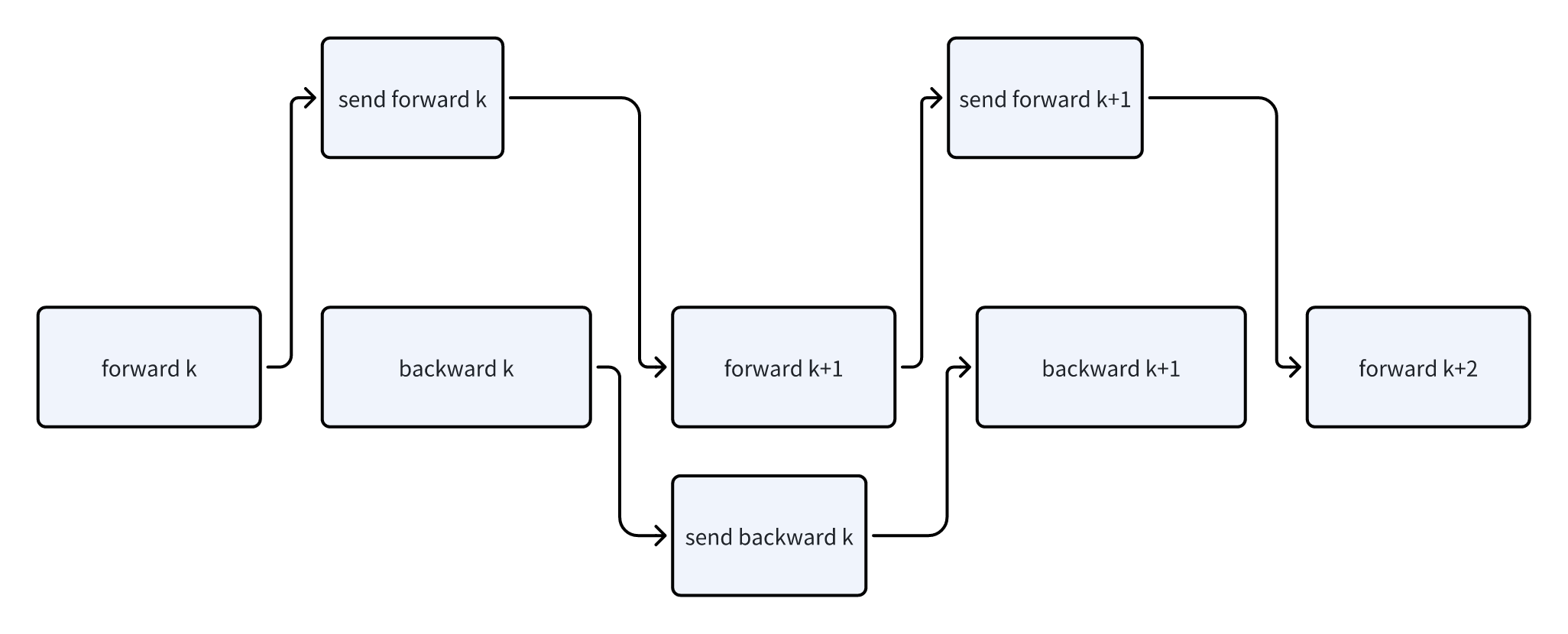
- 实现上,在forward/backward阶段引入了
pre_forward/post_forward/pre_backward/post_backward,用来做异步收发消息的逻辑
可以看出来,这里的overlap主要对1F1B生效。不过实现上还有一个额外的配置,可以对warmup/cooldown阶段也做overlap,不过这块优化应该相对有限,主要是overlap一些算子启动的逻辑。这块就不详细讲了,如果感兴趣可以看我的源码阅读笔记
除了和P2P的通信做overlap之外,还有PP针对DP的优化,这块我们放到DP的文章中来讲。

文章评论