MegatronLM的SequenceParalle主要是针对TP做的
- DeepSpeed-Ulysses/RingAttention这种在MegatronLM中叫ContextParallel,会有单独的一篇文章介绍
论文主要是这一篇:Reducing Activation Recomputation in Large Transformer Models
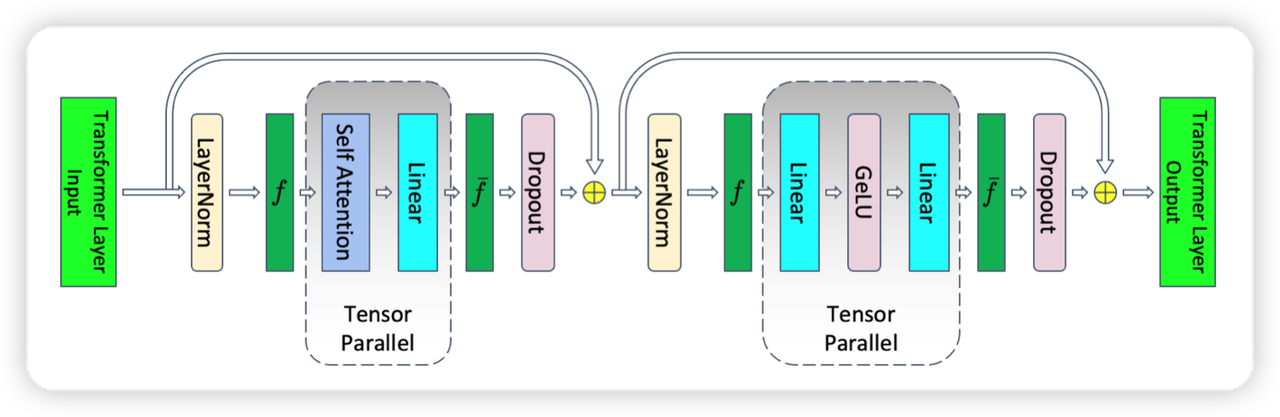
SequenceParallel的逻辑相对简单,之前TensorParallel的设计主要针对图中的MLP/Attention层,其他层的输入输出在所有的tp_rank上都是相同的。导致了冗余的计算以及Activation memory

- TransformerLayer的Activation memory中,有10sbh的数据是来自于LayerNorm/Dropout
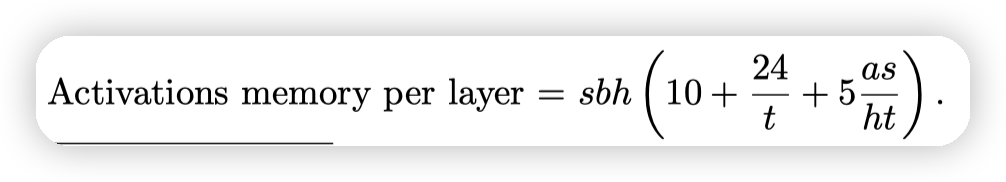
- 应用了TensorParallel之后,这10sbh的数据无法scale,导致占比变成大头。
因为这里的计算都是ElementWise的,可以按照sequence这个维度来切分
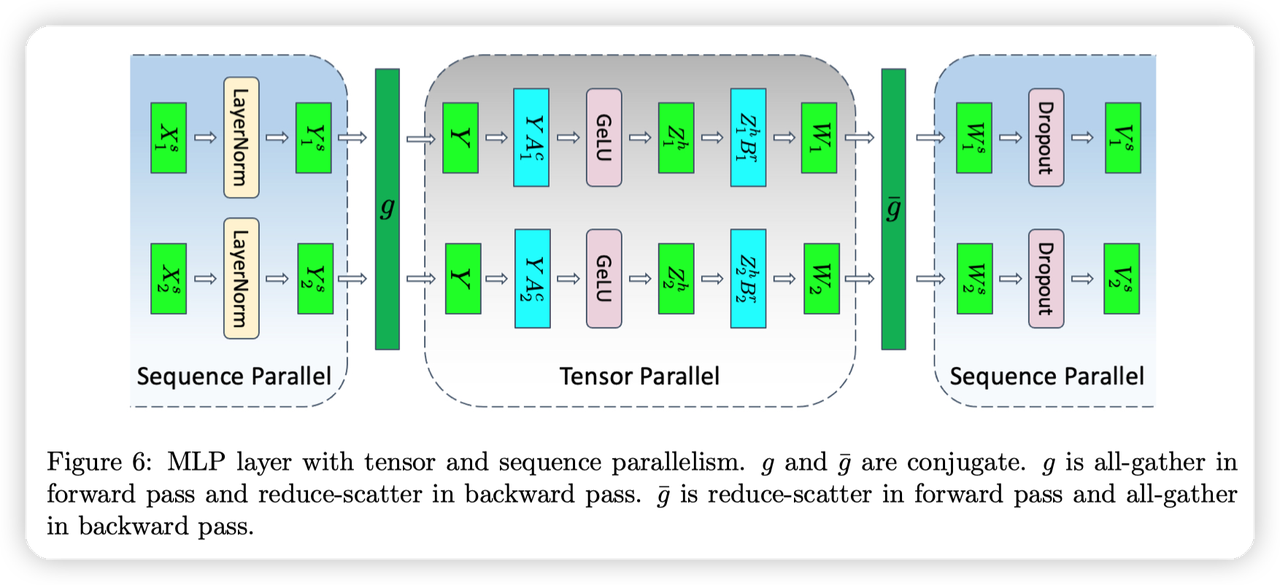
- 输入首先根据Sequence切分
-
在进入Tensor Parallel区域之前,进行All-gather,收集全量的数据
-
Tensor Parallel结束后,通过scatter,按照sequence再次切分。
- 因为TensorParallel最后有一个All-Reduce,所以这里恰好可以把All-Reduce + Scatter转化成Reduce-Scatter
- 所以通信量是不变的,之前是一个All-Reduce,变成了一个All-Gather + 一个Reduce-Scatter
Implementation
ColumnParallelLinear
-
forward之前,有一个gather_from_sequence_parallel_region,做All-Gather。把Sequence切分转化成全量数据
-
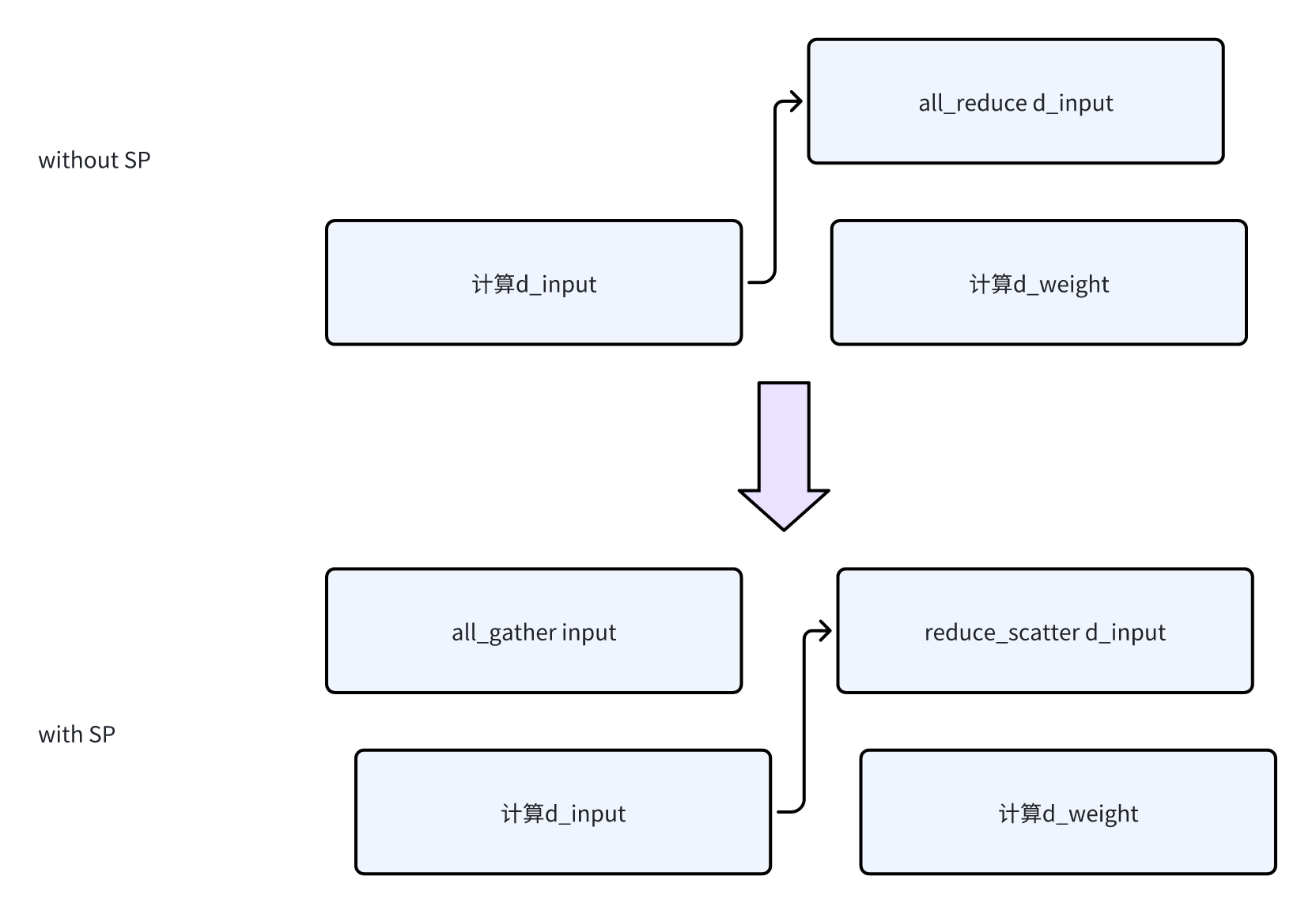
backward阶段,会再次做一下All gather(相当于是重计算),然后计算Grad
- 然后做reduce-scatter,把grad按照sequence切分给不同的rank
- RowParallelLinear不涉及到sequence parallel,因为他在Tensor Parallel region内
这里backward的时候,因为引入了新的通信操作,所以会再做一下overlap:
LanguageModelEmbedding
- 其实主要的实现还在之前提到的VocabParallelEmbedding中。
-
不启动SP的时候,Embedding生成后会做all-reduce
-
启动SP的时候,这里也是all-reduce生成全量Embedding,然后scatter切分sequence。也可以合并成一个reduce-scatter。
-
所以实现上,启动SP的时候,会先把数据从[b, s, h]转化成[s, b, h],然后再去做reduce-scatter
-

文章评论