这篇文章来介绍一下MegatronLM中,TensorParallel相关的实现,主要是面向源码。
相关论文:Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism,推荐先看一下
MegatronLM实现的TensorParallel需要对模型结构有改动,用支持并行计算的层来替换掉原始模型中的那些层,并不是类似Torch FSDP这种对模型结构无感知的实现方法。
所以在阅读代码的过程中,主要需要看两个点:
- 并行Layer的实现
- 代码主要在megatron/core/tensor_parallel目录下
- 如何组合这些并行Layer,组成更大的模型
- 代码主要在megatron/core/models中,这里支持了若干常见的模型,这次我们只针对GPT这个模型来看
Layers
Linear
ColumnParallelLinear
- 对应论文中,将Weight按照列来拆分。
- A = [A1, A2]
-
[Y1, Y2] = [XA1, XA2]
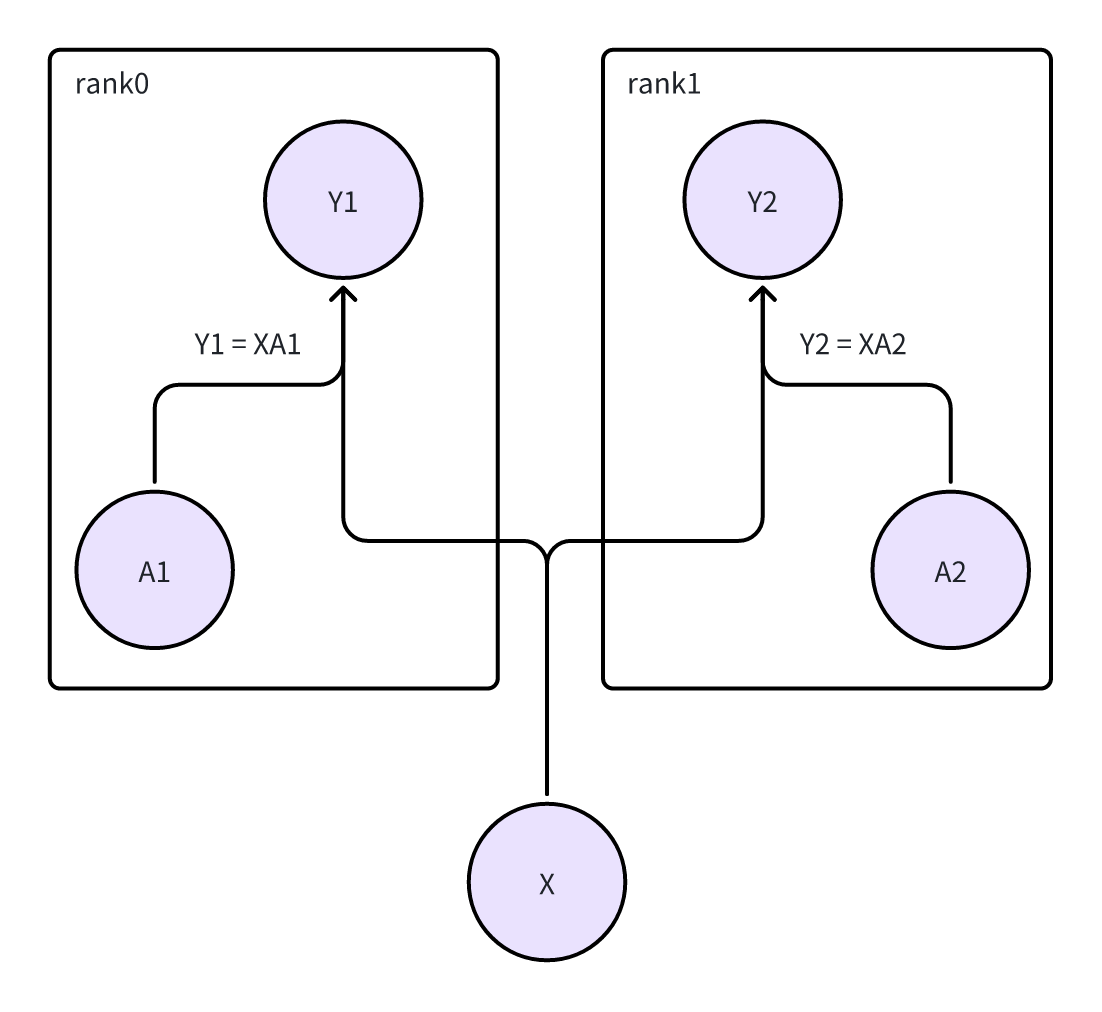
- 从计算图的角度来看,这里相当于X有两个下游节点。所以在反向传播的时候,需要汇聚来自Y1和Y2的梯度
- 同时因为X在两个rank上都有一个副本,所以可以理解成是用all-reduce来做“汇聚”+“复制”的操作
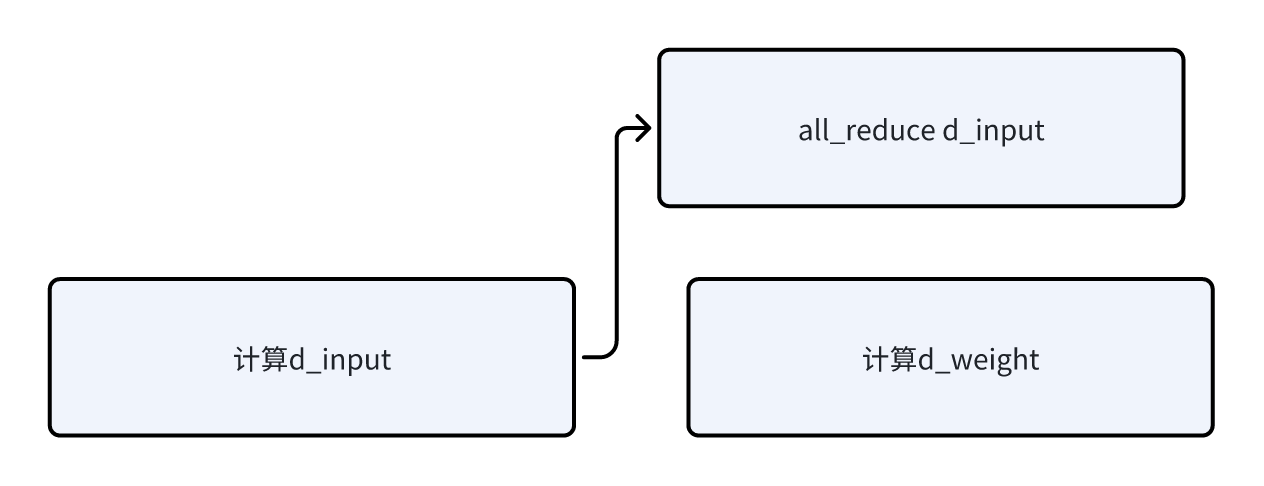
- 实现上,有一个小的优化点,每个rank上计算了D_Y / D_X之后,会发起异步的all-reduce,同时计算D_Y / D_A。
- overlap了all reduce的通信和对Weight的梯度计算。大概示意图如下
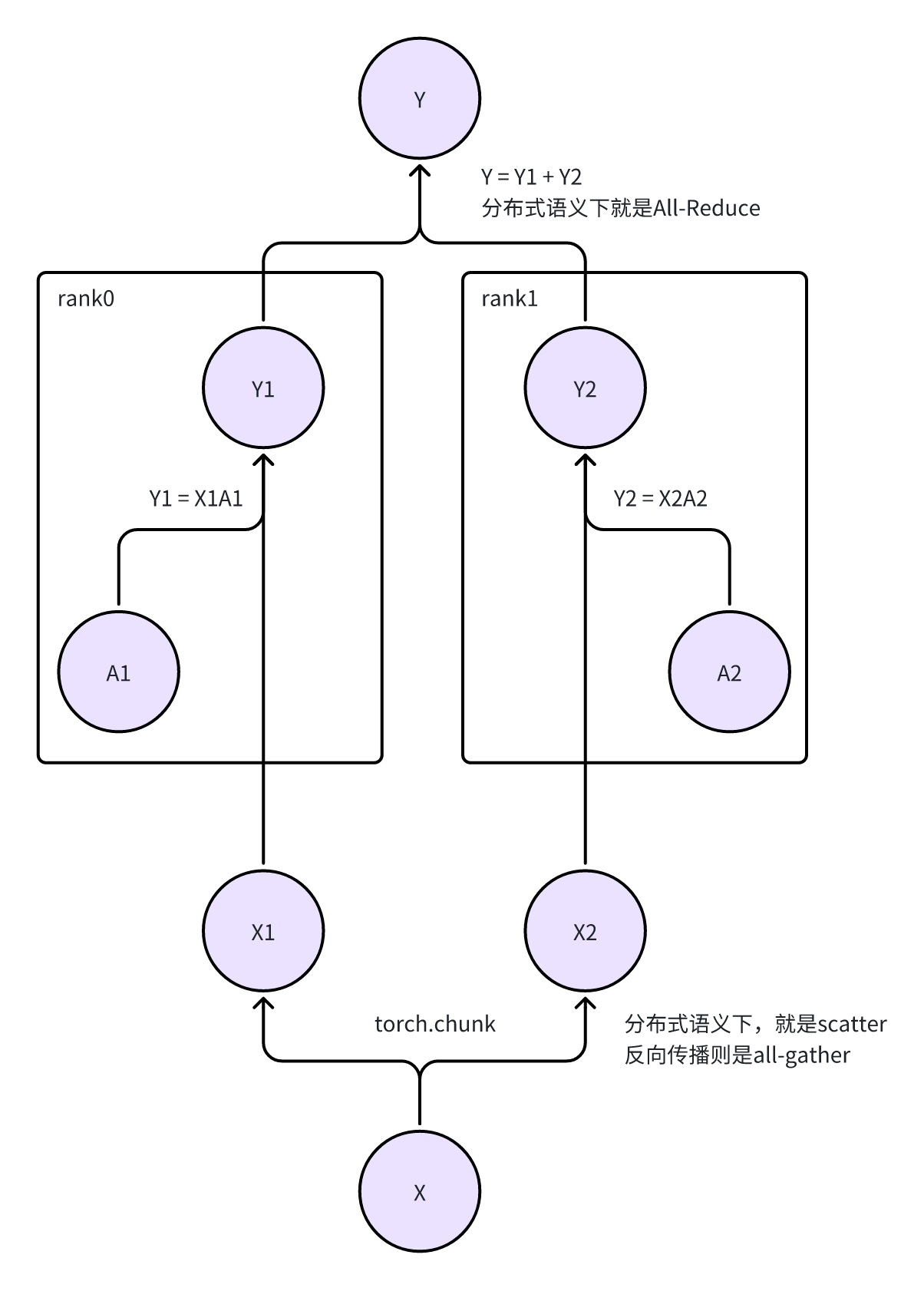
RowParallelLinear
- 对应论文中,将Weight按照行来切分。因为Y = XA,如果A按照行来切分了,需要让X按照列来切分
- Y = Y1 + Y2 = X1A1 + X2A2
- forward/backward和上面的Column版本的基本相同。因为每个Rank上仍然是 Y = XA的形式,只不过含义不同,以及有一些额外的通信操作。
- 说一嘴题外话,图画到这里感觉可以根据计算图来做一些切分,来做自动的tensor parallel?可能一些静态图的框架就是这样做的
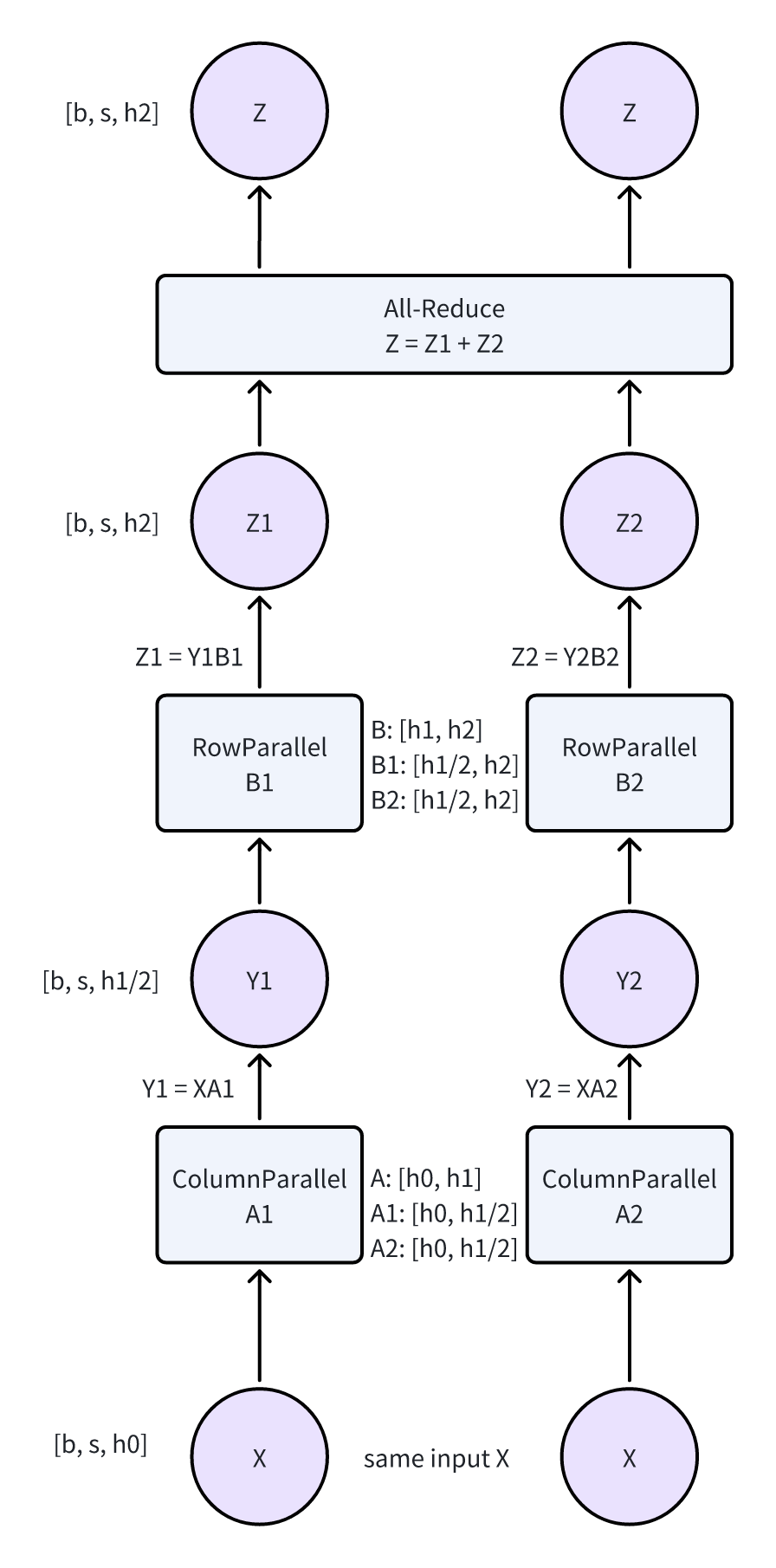
- ColumnParallel/RowParallel一般是成对出现的。具体的组合方式可以看上面的图。
- 同样标注了dimension
- 这块延伸讲,还有另一种设计思路。可以在每一个ColumnLinear内,做完计算后就执行一个All Gather。
- 如果hidden dim都一样的情况下(h0 = h1 = h2),通信量:两次All Gather和一次All-Reduce是一样的。计算量:差了两倍
-
同时因为这种先上投影+activation+下投影是一个比较常见的操作,在中间上投影后的层进行All Gather和最后下投影再做,通信量是不同的。
Other
除去Linear层可以并行之外,还有起始的输入,最后的lm_head,这两个在论文中也提到一般是共享权重的。以及因为lm_head输出的logits也是分片后的,所以MegatronLM还支持了使用这个分片后的输出计算cross_entropy_loss(当然也在论文中有提到)
对应代码中的cross_entropy.py文件,以及VocabParallelEmbedding
VocabParallelEmbedding
- 这里有两个选择,按照embedding_dim切,或者是按照词表切。
- 如果按照embedding_dim切,后续要做一下all reduce。或者是进入到QKV projection的时候,用RowParallel算QKV,然后再做all reduce。(不过QKV之后再all reduce的话,因为head * head_hidden一般大于d_model,不太划得来)
-
同时如果按照embedding_dim切的话,最后计算loss的时候还需要做all-reduce + cross-entropy
-
综上,这里选择的是根据词表切。
- 每一个rank有部分的词表。如果输入的token不在自己负责的词表中,就输出一个0。
-
计算完自己负责部分的Embedding后,做All-Reduce,就可以得到整个序列的Embedding了
CrossEntropy
这里计算CrossEntropy的时候,也是Fuse了Softmax和CrossEntropy:
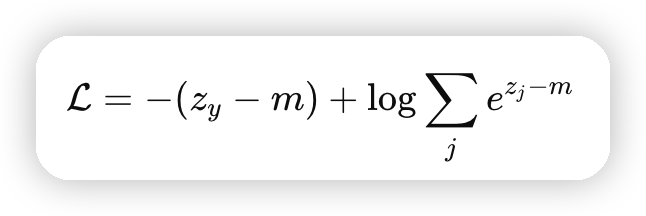
并行的设计上,每一个rank有部分的z_j。这里MegatronLM的做法是:
- all_reduce,计算全局的max
-
用本地的logits,减去全局max,然后计算本地的sum_exp
-
all_reduce,计算全局的sum_exp
-
all_reduce,同步全局的predict_logits
-
按照上面的公式计算即可
这种方法在论文中也提到,可以把通信量减少sequence倍,因为现在只需要通信统计值,不需要通信原始的logits了
Model
有了上面的layer,现在来尝试组装一下模型。
首先是MLP和Attention,这两个在论文中也有图了,这里就简单讲讲实现点
MLP
- MLP的实现就是简单的两个Linear,对应上面的一个ColumnParallel和一个RowParallel
-
按照hidden_dim来切分,每个rank上持有部分的hidden_dim
-
同时支持GLU,实现上就是up_projection之后,把得到的hidden_dim对半分(因为要做element_wise的相乘)。计算
activate_func(x_glu) * x_linear,其中[x_glu, x_linear] = XA_r
Attention
-
qkv的矩阵是放到一起的,作为一个ColumnParallelLinear出现。其中
- query_projection_size = kv_channel * num_attention_head
-
kv_projection_size = kv_channel * num_query_groups,用来支持GQA
-
ColumnParallelLinear的output_size就是query_projection_size + 2 * kv_projection_size
-
每一个rank按照head做切分,过完Linear之后,再根据上面计算的projection size切分成QKV三组
- 按照head切分后,后面的Attention就可以独立计算了
- 最后还有一个o的矩阵,是一个RowParallelLinear,正好对应了每个rank上不同的head,也就是不同部分的hidden_dim。最后再做All-Reduce,计算就完成了。
实现上,可能还有一个小问题是模型切分是在哪里做的呢?
- MegatronLM有一个全局的ParallelState,可以得知各种并行策略对应的world_size/rank
-
在每个module内,判断如果启动了TP,需要调整对应Linear层的size,除以world_size
总结一下每一个TransformerBlock:
- MLP按照d_model切分,up_projection是Column切分,down_projection是Row切分
-
Attention按照head切分,qkv projection是Column切分,output projection是Row切分
-
forward阶段一共两次all-reduce
通过TransformerBlock构建GPTModel就与单机无异了。

文章评论