之前有过FSDP1相关的介绍,这次来看一看FSDP2,也是偏源码分析级
不过有一个特殊的点是FSDP2在Github上的文档非常全面,把相关特性的支持,代码结构的设计讲的都很清楚,所以这篇文章主要是来做一个补全。推荐在阅读FSDP2的代码之前,先看看这个文档https://github.com/pytorch/pytorch/issues/114299
- 还有一个点是因为我个人对torch dynamo相关的不太熟悉,所以FSDP2和编译优化相关的事情就不提了
FSDP2和FSDP1个人认为最主要的区别点有几个:
- 不再使用FlatParameter,而是使用DTensor,相关的:
- 代码变得流畅很多,不需要各处为了各种功能来添加if else。对混合精度,冻结参数支持的更好。
-
用户不再会感受到自己在使用一个FlatParameter,各种参数相关的逻辑都需要调用FSDP特殊的版本。比如GradScaler,GradientClipping,StateDict等
-
和上面类似,使用DTensor/DeviceMesh来表示参数,可以更好的与其他策略进行结合。
- 官方的测试中有TP + FSDP的代码。
-
torchtitan在这块应该做的更多,不过我还没做深入研究
-
Memory的控制,不再使用RecordStream+CPU限流来控制内存,带来更确定的内存占用。这块在下面我们会仔细分析一下。
Implementation
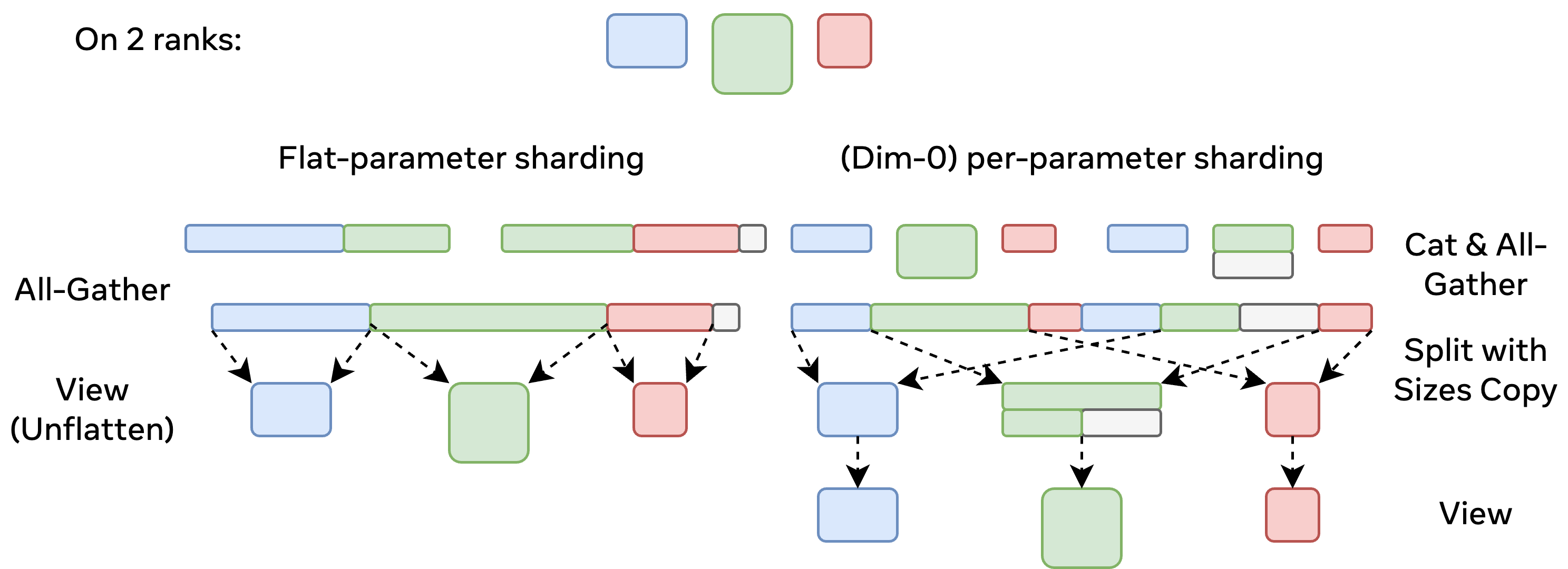
虽然文章里讲了,这里还是简单提一嘴:
- FSDP2不再使用FlatParam,而是使用Per-Parameter-Sharding的方式。
-
意思是每一个FSDP Unit的参数不再会统一放到一个FlatParam上管理,而是引入了一个新的概念FSDPParamGroup。在分片的时候,每一个Parameter都会被独立的划分到每个worker上。
-
支持在多维度进行划分
-
图中就是两者的区别,在FlatParam的情况下,可能会有部分参数完全放到一个worker上。(in_shard变量,如果读过FSDP1代码的同学可能会熟悉)。而FSDP2中每一个param是独立的,通信/重构不再依赖整个FlatParam
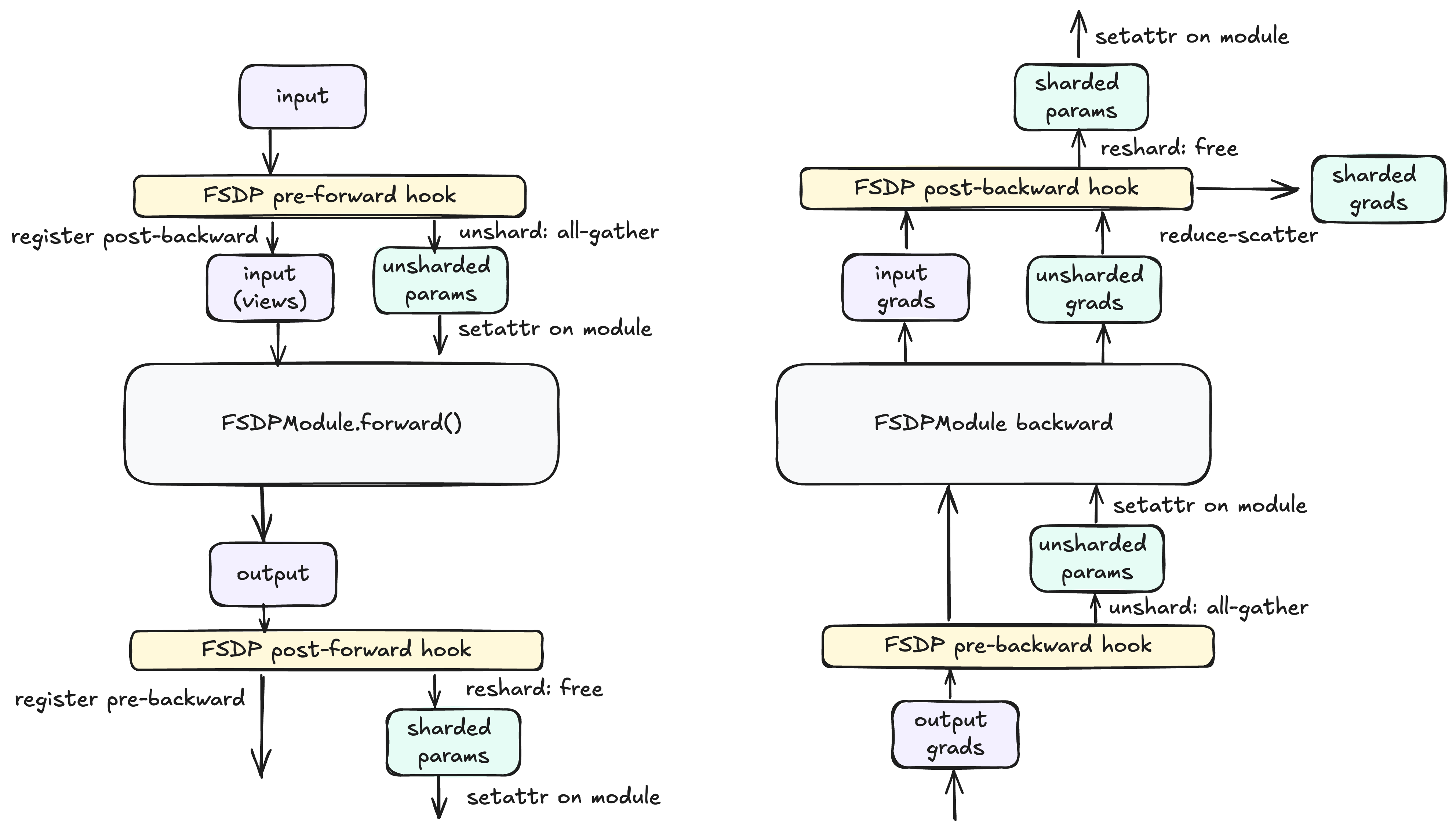
- Autograd相关的还是和FSDP1一样,需要用到之前文章中提到的Resize_()的技巧来保证释放内存后Autograd还能生效
-
不过register hook的位置有所改变:
- pre-backward还是在module output tensor上注册的。
-
post-backward则是注册到了module input tensor上。而不是之前的AccumulateGrad上。
- 文档中没说为什么,但是可以推测出来,因为AccumulateGrad是PerParameter的,而为了保证通信效率,FSDP2做的还是ParamGroup级别的Reduce-Scatter,那么多个AccumulateGrad的情况下,就不清楚什么时候触发ReduceScatter合适了,所以放到了module的出口中。
- 在被fully_shard包装后,用户能够看到的Parameter都是DTensor。forward阶段,FSDP会做all-reduce,将DTensor转化成full tensor供forward使用。
- 如果用户参数本身就是一个DTensor,那么forward阶段就仍然是一个DTensor。FSDP只做自己这一层的All Gather。即处理多维度的并行化
MemoryManagement
在讲清楚为什么FSDP2的内存占用是确定性的之前,需要先了解一下FSDP2在那些阶段会分配内存。以及FSDP2中,多个stream的overlapping是怎么做的。
上面提到了,FSDP2使用了per-parameter-sharding的方式。和FlatParam的区别就是灵活性变高了很多,用户可以独立操作每一个参数。但是因为内存是不连续的,那么在进行AllGather等通信的时候,要么是选择支持Group coalescing语义的通信算子,要么是拷贝一份。benchmark中发现用Copy的方式更好,所以选择了Copy。
FSDP relies on batched all-gather and reduce-scatter for communication efficiency. (HSDP additionally relies on all-reduce, but we omit that for brevity.) When using per-parameter sharding, the options include (1) copy-in/copy-out and (2) NCCL group coalescing. Our internal benchmarks show that the former is achieves higher bandwidth utilization than the latter (and aside from the copies, is the same as the existing FSDP collectives, making them more trustable), so we choose that approach. (Adding group coalescing as an option may be future work.)
所以来看一下FSDP2中的内存拷贝/分配发生在那个环节:
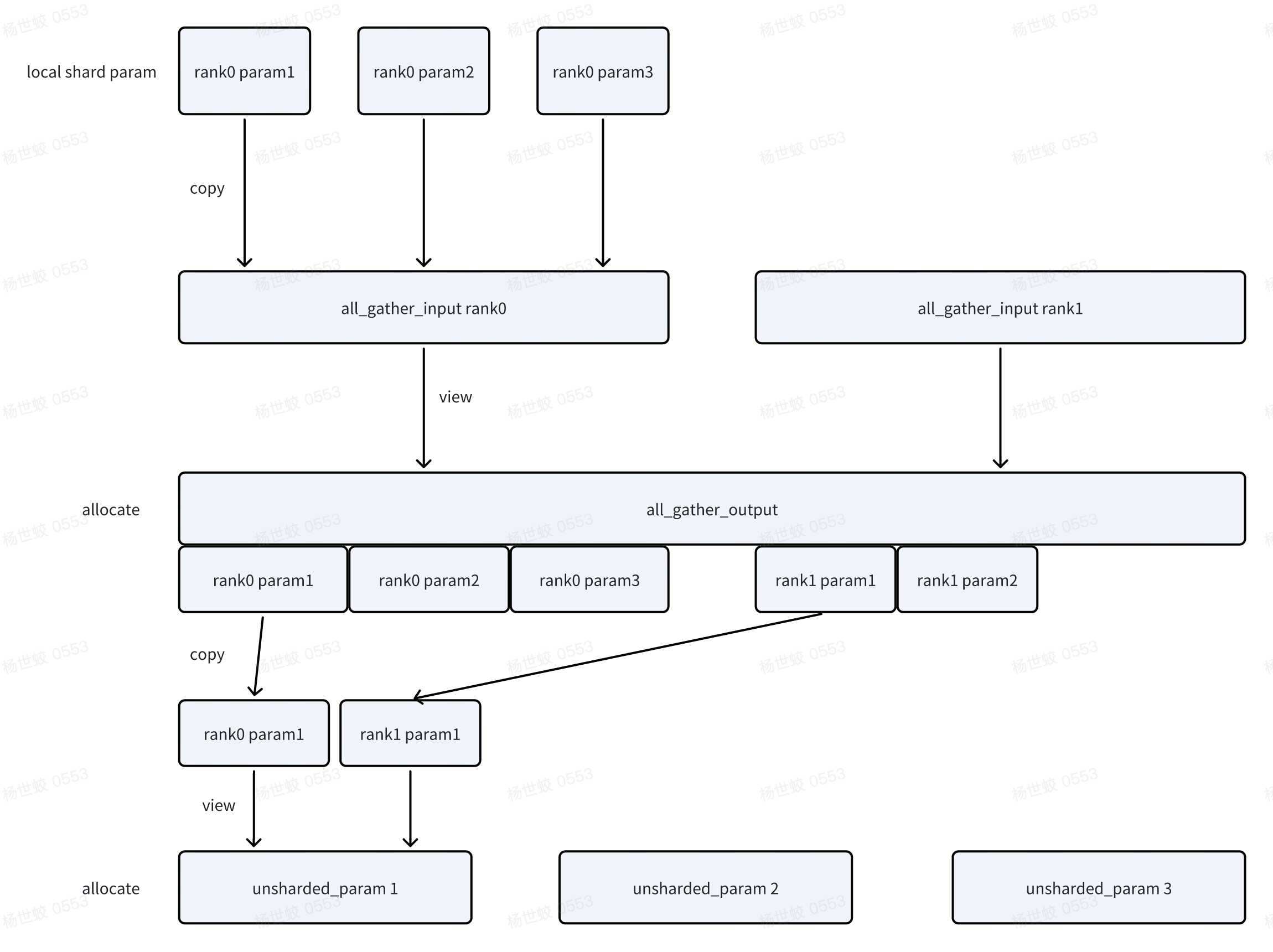
- unshard阶段,两次copy,两次allocate
- 会首先分配用于All Gather的内存,input是作为output的view
-
把param拷贝到input的位置中。进行All Gather
-
分配每一个param的内存(这里应该可以复用),每一个param是独立的。再将All Gather的输出拷贝过去
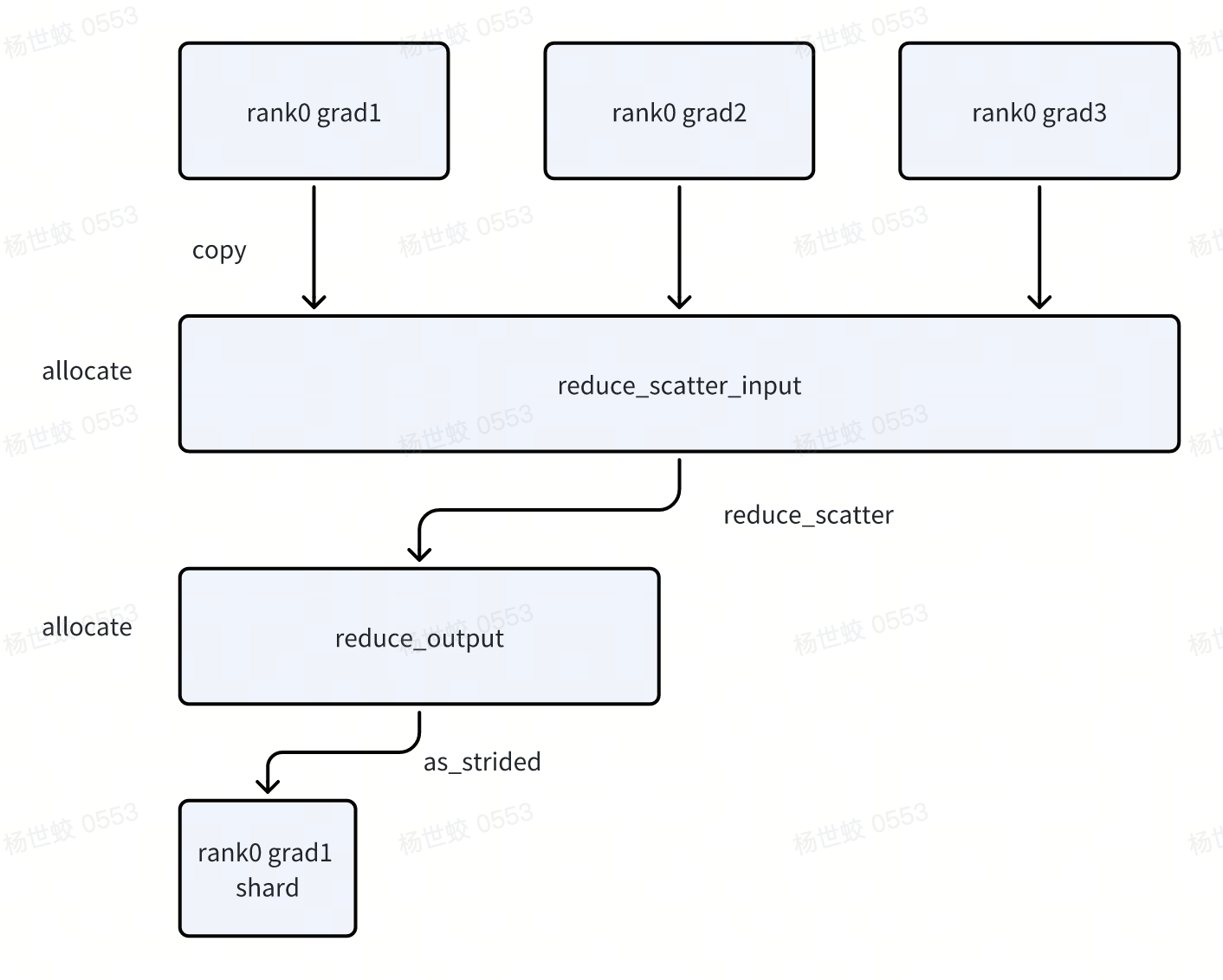
- reduce-scatter阶段
- 一次copy,两次allocate
-
分配reduce_scatter_input/reduce_scatter_output
-
Copy grad到reduce_scatter_input中,执行reduce scatter
-
grad会作为view保存到对应param中
然后来讲一下有关多stream的内存管理,这块问题就不详细说了,感兴趣的同学可以看:
- 有很多的图https://dev-discuss.pytorch.org/t/fsdp-cudacachingallocator-an-outsider-newb-perspective/1486
-
FSDP的论文
-
我之前的FSDP1的文章中也有写
核心点就是使用RecordStream可以保证内存不会被错误的释放,但是CudaCacheAllocator无法很好的复用内存,导致会有内存尖刺的问题。
FSDP2中换了一种思路,使用stream-stream的同步,不使用RecordStream,而是在“合适”的时间在CPU中释放内存,去主动做复用。
后面的分析图偏源码级别,比较适合配合源码食用
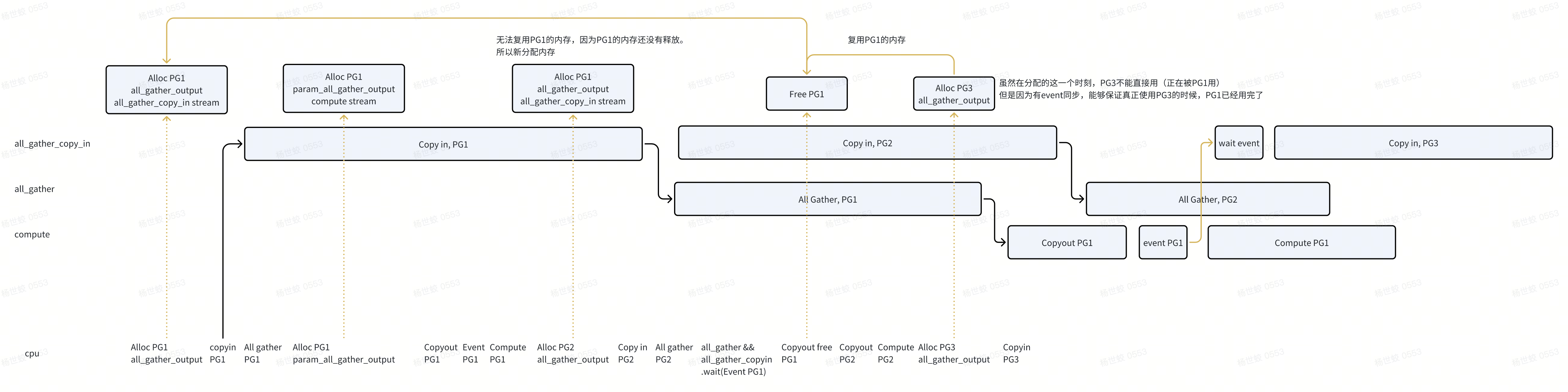
- unshard阶段,这张图解释了overlapping,以及内存复用的逻辑
- 这里的核心点在于,CPU释放内存的时间在waitEvent之后。所以在后面PG3的分配中,虽然复用了PG1的内存,但是使用时间仍然在PG1完全使用完这段内存之后。
-
需要小心的是,这种设计的内存分配要尽量在特殊的stream中,我们可以显示的控制什么时候分配内存,否则如果误复用了内存并使用是会出问题的。
- 比如这里Free PG1后,如果有一个相同stream其他链路的内存分配复用了这块内存,并立刻使用,就会和All Gather冲突。
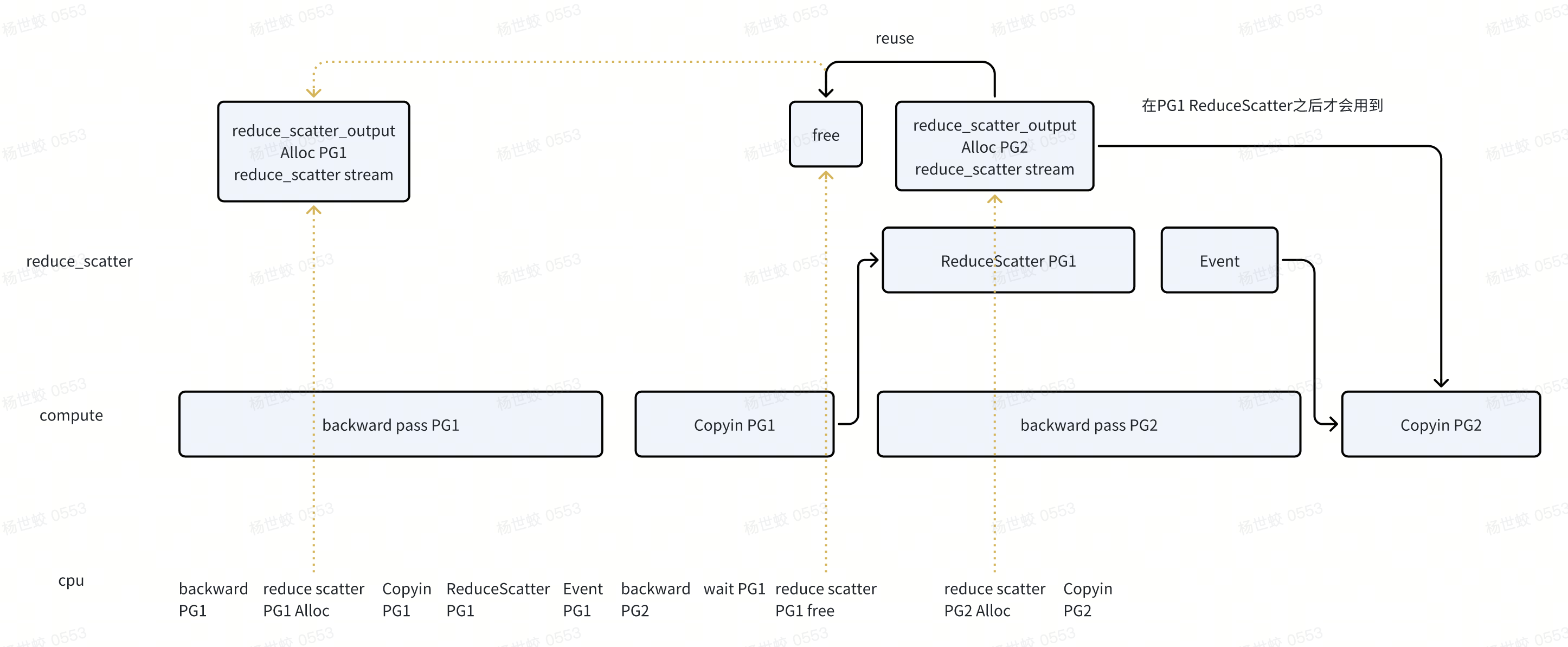
ReduceScatter的,思路是类似的:
- 不过需要注意的是在设计文档中,写的是reduce_scatter_input是分配在reduce_scatter_stream中的,代码中实际上是在compute stream。不过目前的实现也是没有问题的。
- 因为即便后面有backward pass PG3复用了reduce scatter的input,也会在Copyin PG2之后才会使用。
这块可以延伸一点,假设我们跟着设计文档的思路走,会是什么样的?
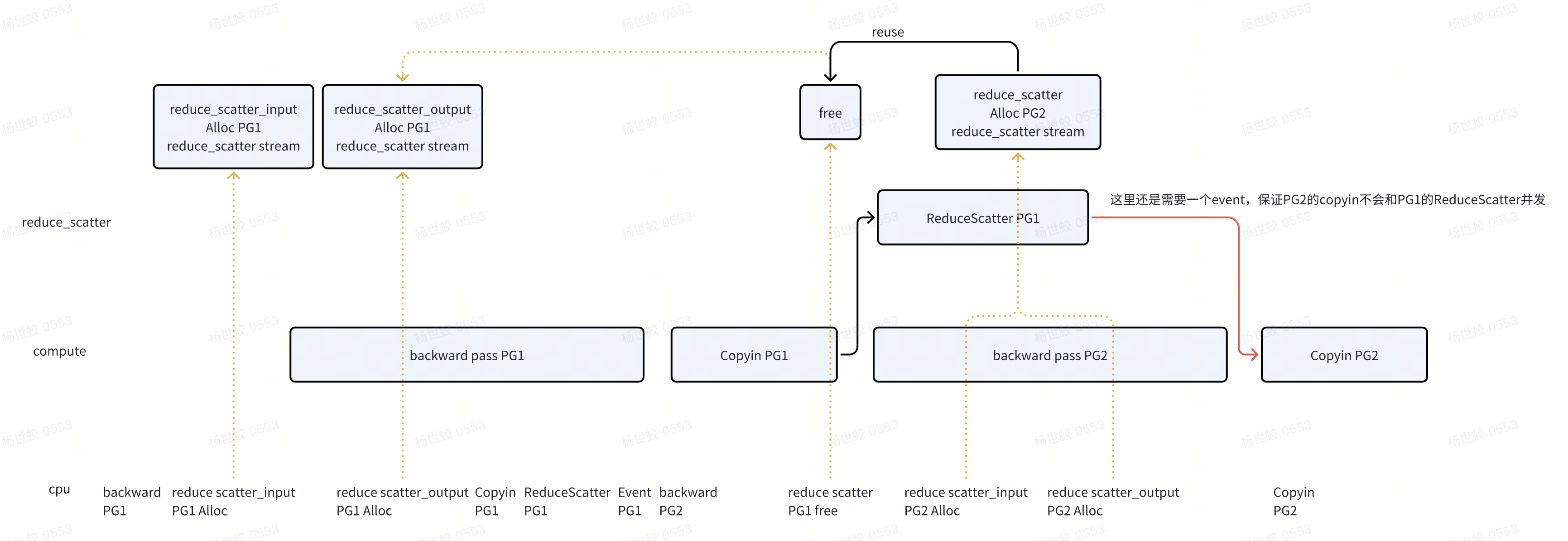
- 个人感觉基本没有差别。不过从上面提到的“安全性”来讲,确实更安全一些,因为compute stream不知道是否会有奇怪的内存分配出现,出现误复用。
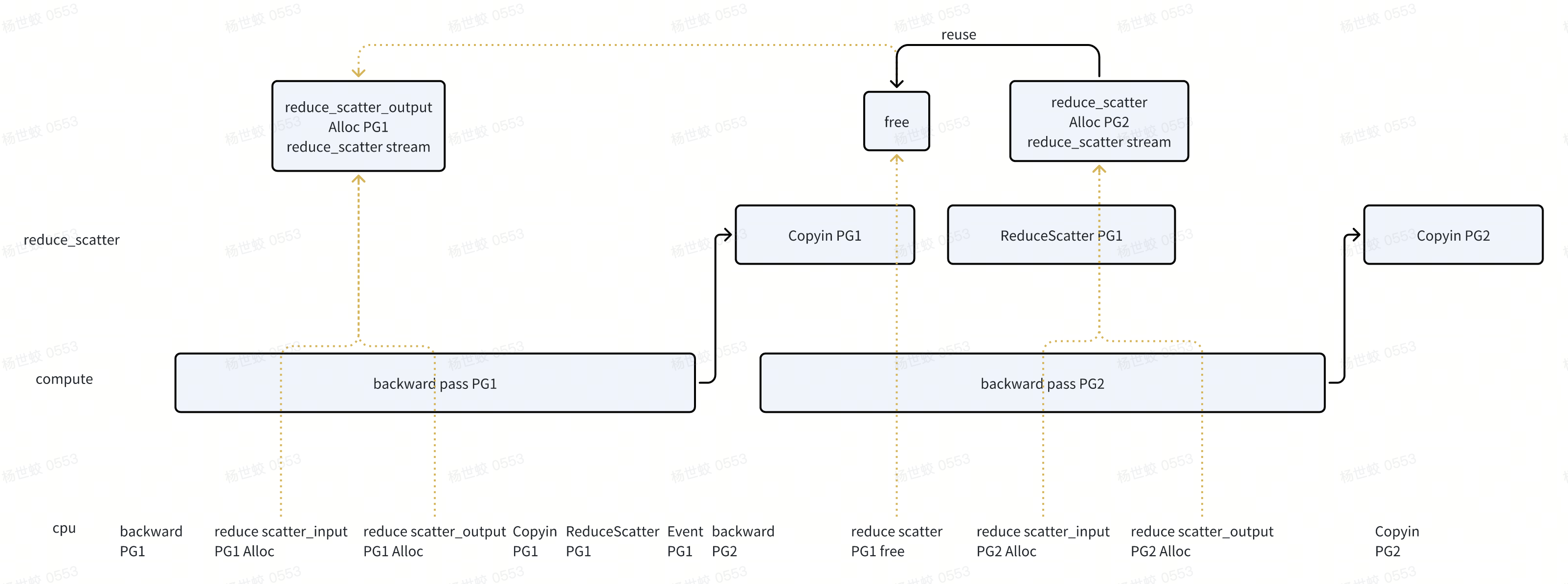
- 还有一种选项是把Copyin 放到reduce scatter stream中。这样需要引入的同步就是backward pass -> PG1的
-
两种不同的设计,核心区别是copyin放到reduce_scatter stream中,还是放到compute stream中。
- 如果ReduceScatter耗时高,那么把copy + backward放到一起更好
-
如果backward耗时高,那么把copy和reduce scatter放到一起。
-
从目前的设计看,应该就是ReduceScatter的开销更大一些。所以选择把copy + backward放到了一起
- 总结一下
- FSDP2的这种方式可以做到更激进的内存复用,从而控制内存占用。但是需要对链路上的内存分配有比较好的把控,才能够保证不会复用到错误的内存
-
RecordStream这种方式更加保守,但是不会出问题。这种方式下CPU执行过快无法及时做内存复用的情况下,就需要用CPU的限流器来控制内存占用了。
在额外提一嘴的是,不使用CPU限流之后,forward阶段就可以走implicit prefetch了。这样forward也不需要依赖静态图。
- 不过backward还是需要prefetch,原因个人认为还是和FSDP1一样,主要是为了reorder,减少下次compute的等待时间。
DTensor
这块就简单说一下DTensor相关,不做详细的分析(因为还挺复杂的)。详细的文档可以看这里
- https://dev-discuss.pytorch.org/t/dtensor-status-design-and-looking-forward/2749
-
https://github.com/pytorch/pytorch/issues/88838
DTensor可以指定Placement(Shard的方式),以及DeviceMesh(在那些设备上进行Shard)。Shard的方式包括:
- Shard(dim),指定Tensor的维度进行Shard,比如做行切分。
-
Replicate(),在这个维度的DeviceMesh上进行复制
-
Partial(),从文档看是一个中间状态,对应只保存部分的参数
DTensor提供了几个 关键的API:
- from_local(),通过local tensor + Placement/DeviceMesh来构建DTensor
-
to_local(),根据当前的rank,获取DTensor对应的local tensor
-
redistribute(),做DTensor -> DTensor之间的转化,改变数据分布的方式
这几个API都是支持autograd的,结合Autograd就可以比较好的做一些自动的TP:
- 比如简单的Linear,就可以把Input和Weight在两个维度做划分,然后分别做matmul之后,再组合成新的DTensor。
这几个API,实现上的复杂点主要在redistribute(),因为from_local()/to_local()都可以被表达为redistribute。因为可能涉及到分布的变化,比如[Shard(0), Shard(1)]变成[Shard(1), Shard(0)],里面还会有一个planner来根据代价选择一个开销比较低的变化路径。感兴趣可以去读读redistribute_local_tensor这个函数,后面有机会再单独写一篇文章讲一下。
然后主要讲讲和FSDP的关联;
- 上面提了,fully_shard wrap之后的模型参数会变成DTensor,用户在做一些parameter相关的计算的时候,比如norm.clip_,GradScaler,可以像操作普通tensor一样。然后在dispatcher层会识别出来这些DTensor,转化成local tensor进行计算。
- 不过如果是转化成full tensor做计算的话,开销是比特化的版本要大的。比如norm.clip只需要通信一个local sum就行。这块我没有深入研究了,因为暂时对dispatcher还不熟悉
- 和TP的结合,比如参数可以表示成[Shard(0), Shard(0)]的DTensor,对应[FSDP, TP],每次unshard阶段,都是将这个DTensor转化成[Replicate(), Shard(0)],然后在第二维做TP。
- 不过虽然FSDP将参数表示成DTensor,但是分布的转化(上面的Shard转Replicate)还是自己实现的,没有复用DTensor的。可以做更好的overlapping,以及内存的控制。

文章评论