整理一下FSDP1相关的实现,偏源码级,适合想读代码的同学来看
Core
- 核心流程如图
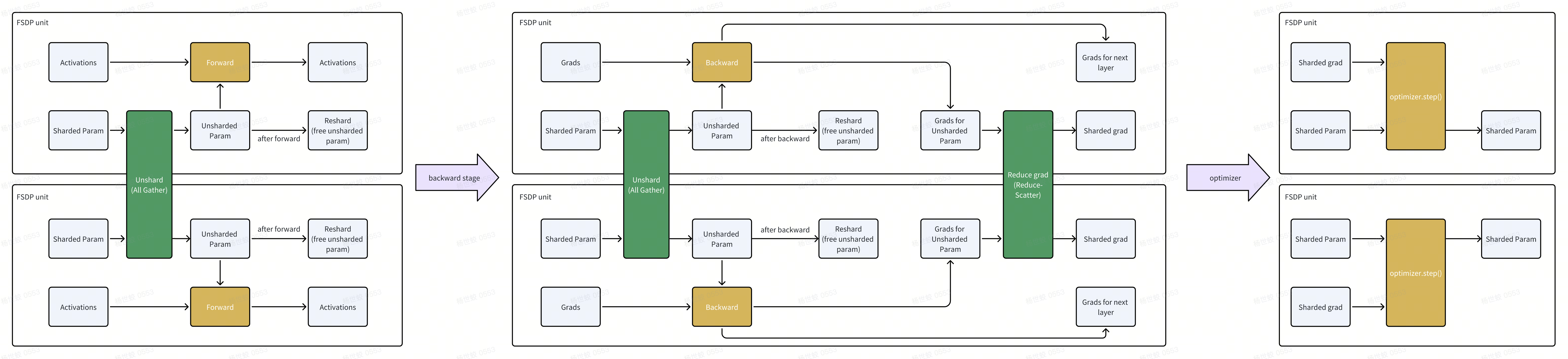
- 图中可以看到,FSDP虽然shard了模型,但是在计算(forward)的过程中,还是需要收集所有的参数做计算。所以他还是被划分成DataParallel
Init
主要分为两块:
- 把模型切分成fsdp unit
-
把每一个fsdp unit的参数展开成FlatParameter
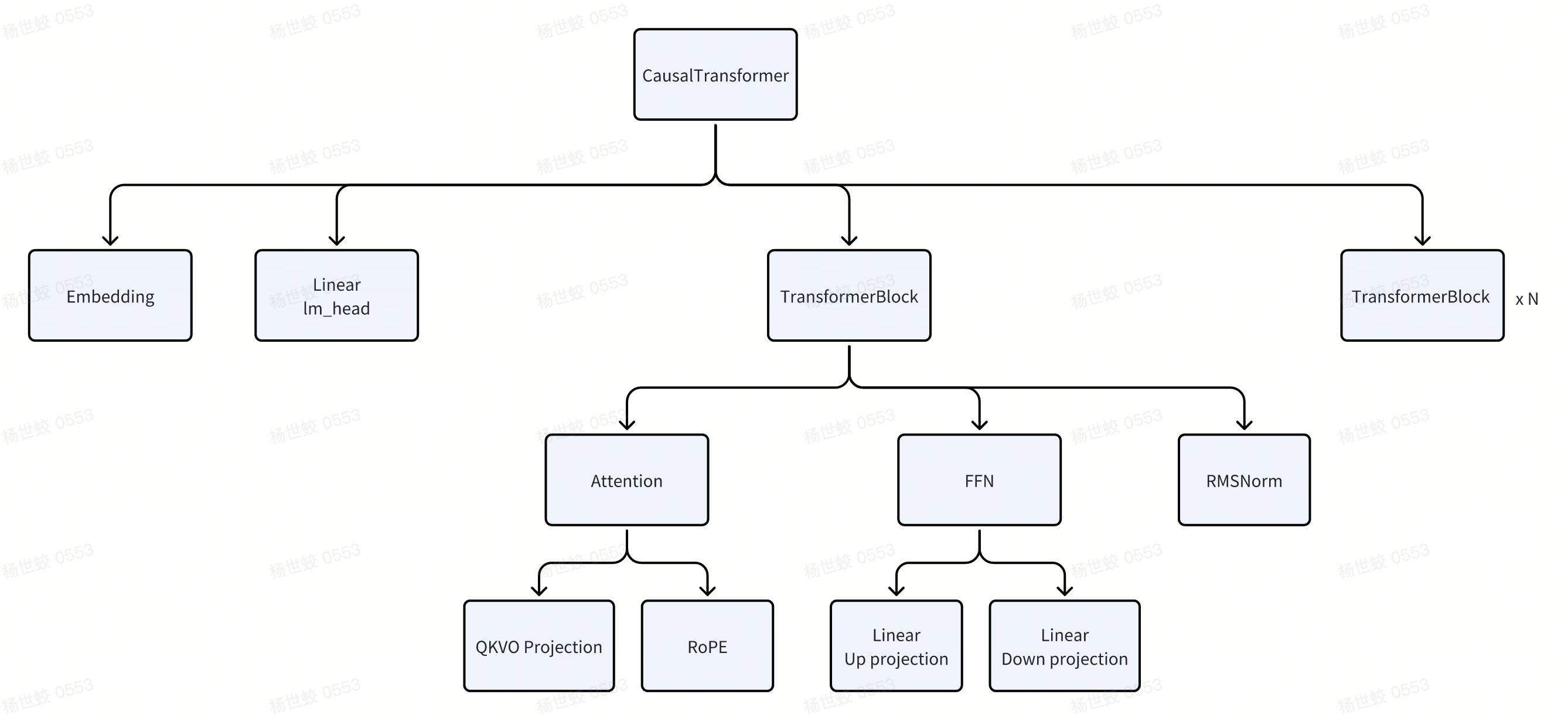
- 以一个CausalTransformer为例,模型会被组织成一个树形的结构。每一个节点都会有自己的Parameter,定义自己的forward计算逻辑。
FSDP的第一步是切分这个模型,把它划分成若干个FSDP unit。torch在这里把切分模型的任务主要给了用户,用户需要定义自己的模型切割策略,告诉FSDP那些module应该被划分成一个unit。
- torch默认提供的策略,比如size_based_auto_wrap_policy就是一个参考,可以根据module的参数大小来确定是否做切割。
-
还有一些策略,直接根据module的类型来切割。比如上面的CausalTransformer中,我们可以把每一个TransformerBlock划分成一个FSDP unit
-
有关unit大小的tradeoff,paper中并没有相关的讨论,这里就根据我的理解说一下。
- FSDP unit越大,肯定对内存的要求越高。因为计算时需要收集FSDP unit内所有的参数。
-
而FSDP unit越小,比如极端情况就是一个小矩阵的乘法,此时发起通信的开销比较大(虽然通信的总量是固定的,但是启动通信算子本身就有开销,这也是为什么要做batch)
- 不过猜测启动算子的开销应该到FSDP unit大到一个点的时候,就可以被overlap起来?或者是占比比较少了。
- 从上面的分析看,感觉更像是一个分段函数,开始的时候对着FSDP unit变大,吞吐会变大。到某一个点后这个增长的斜率会变缓
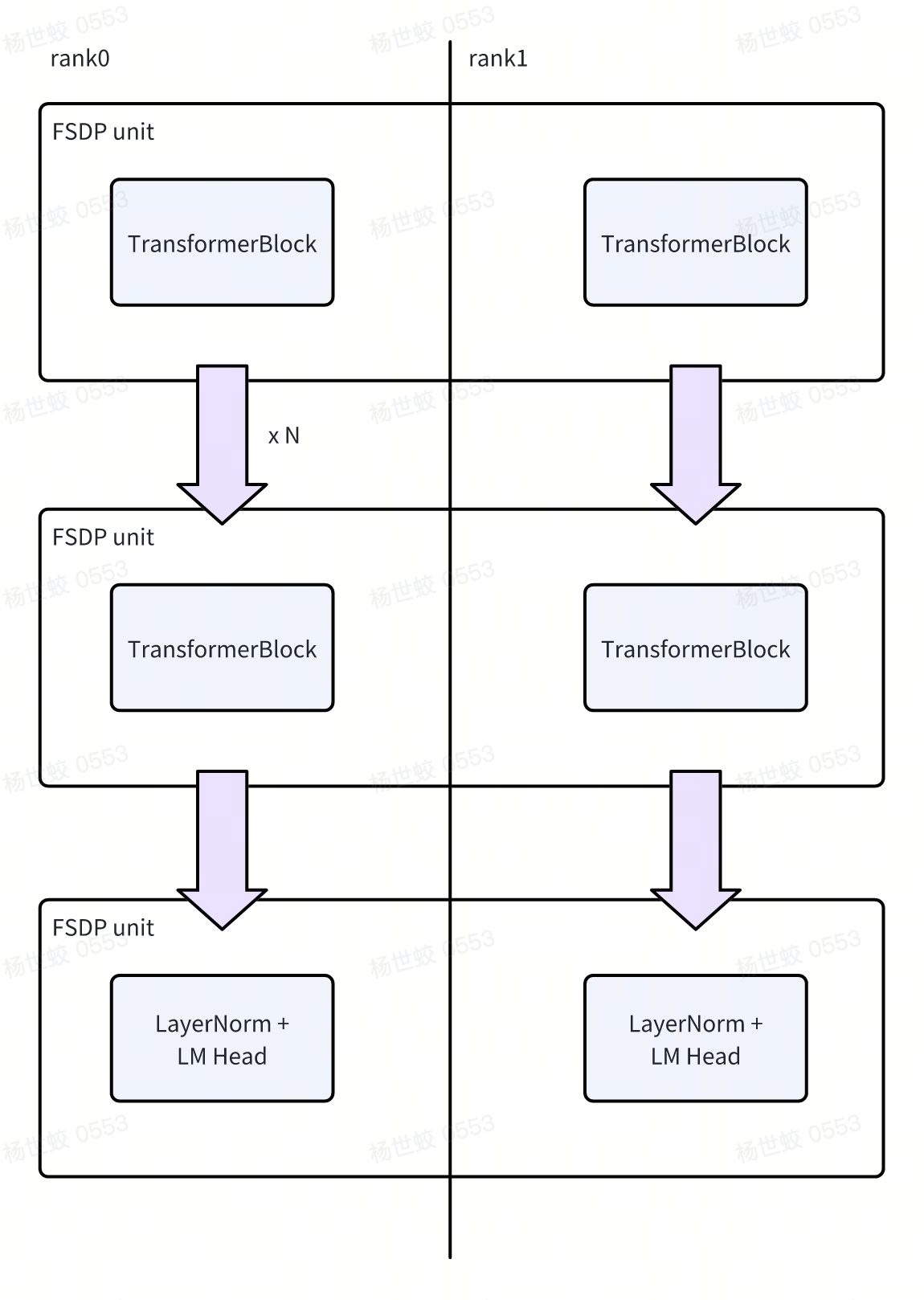
- 如图,如果按照TransformerBlock切的话,上面的模型切分完之后就是这个样子。再重复一下,每一个FSDP unit在执行时会收集所有分片的参数,所以这里切分就需要保证单个TransformerBlock能够放到GPU中,否则就需要继续做切分。
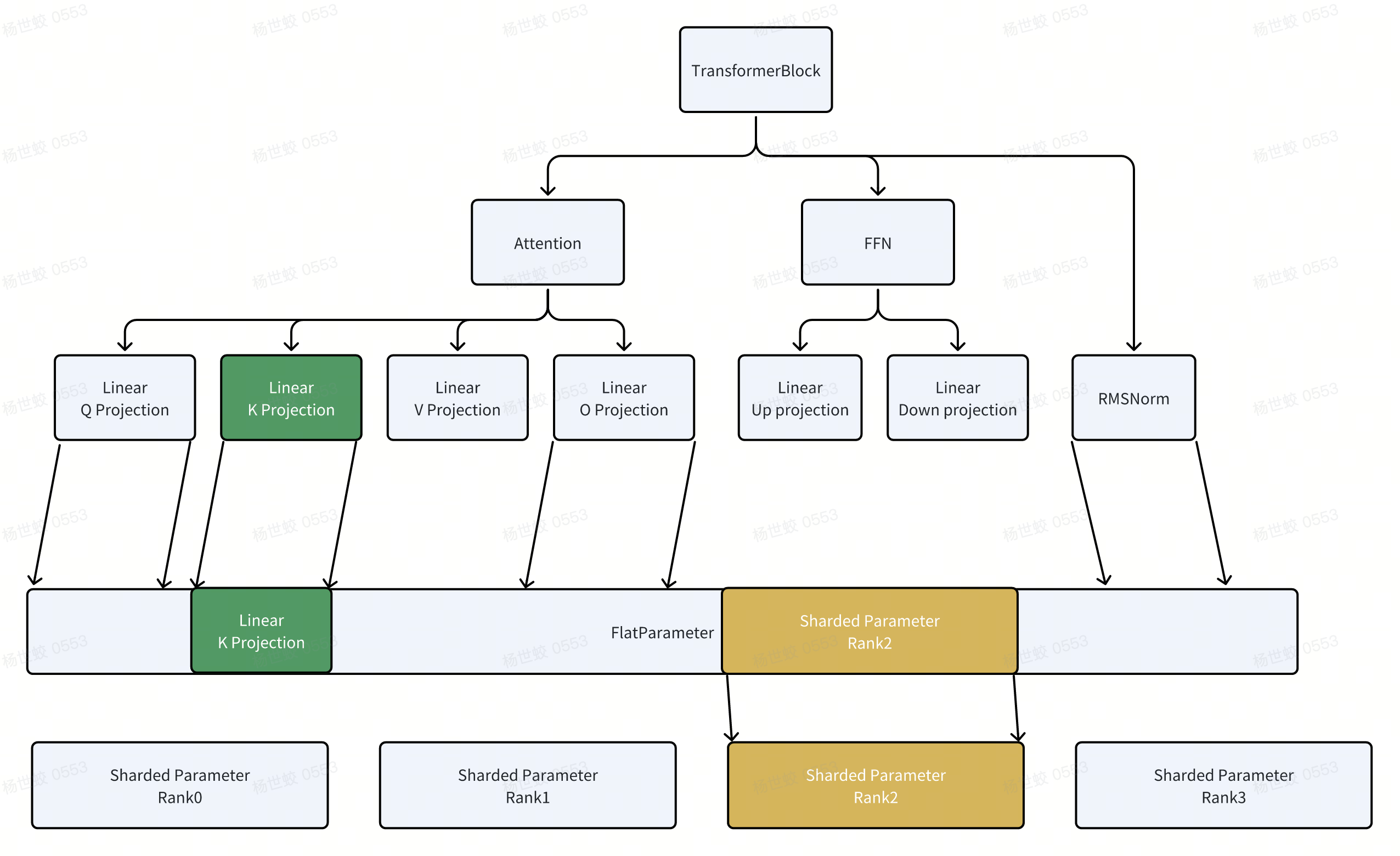
- 核心思路是把所有的参数拍平,都放到FlatParameter中。然后再根据world size去切分FlatParameter,每一个rank拿到一部分的FlatParameter。
- 使用这种方式设计的原因在论文中有提,感兴趣可以看《PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel》
- 实现上,这里有几个需要注意的点:
- 通信库中(nccl)有部分高性能的通信算子要求各个rank输入的tensor大小相同。比如All Gather希望所有tensor大小相同。这里会把FlatParameter按照world size做一下padding,让FlatParameter的大小能够整除world size
-
因为后续使用上,还会涉及到通过view把FlatParameter的切片变换成原始的参数,所以为了提高访存效率,这里还会对每一个子的parameter按照16byte做对齐。
Runtime
有了切分好的参数后,就可以看一下FSDP是怎么把上面概念上的通信算子加入到计算逻辑中了。
FSDP wrap了原始模型,在forward链路增加了pre-forward/post-forward的逻辑。
- pre-forward的逻辑就是做unshard,通过All Gather收集参数,给后面模型的计算做准备
-
post-forward的逻辑就是做reshard,释放掉unsharded param来释放内存
forward阶段的逻辑比较好理解,这里需要关注的点主要是backward阶段,因为backward阶段是torch的autograd引擎自动执行的,无法直接像forward一样直接增加逻辑进去。不过autograd中提供了很多hook的能力来完成这个任务。
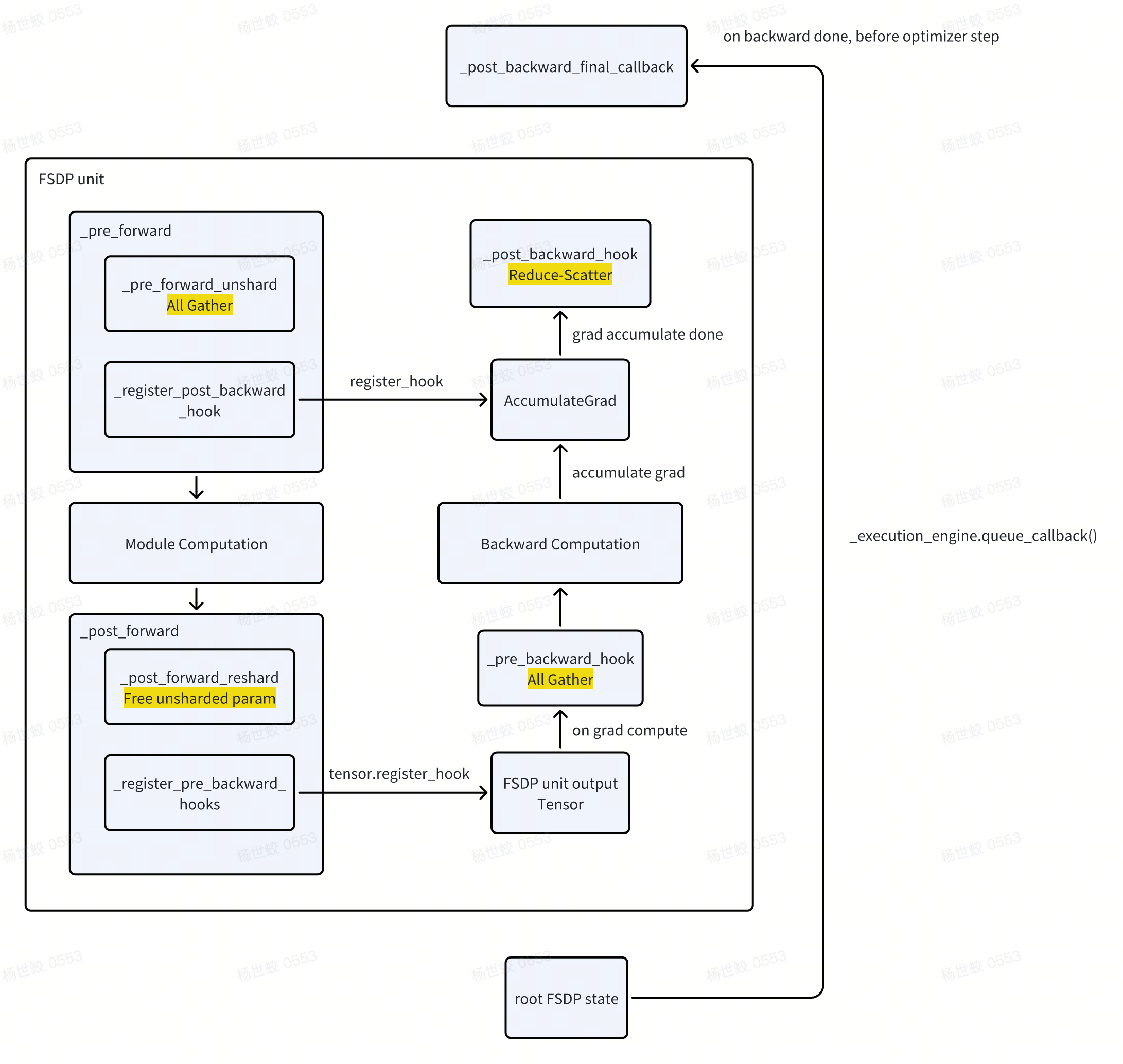
- _pre_forward阶段
- 会做All Gather,构建Unsharded Param
-
注册post_backward_hook,注册到AccumulateGrad对象上。每一个Parameter在计算图中都会有一个AccumulateGrad对象,用来累积梯度。当累积的梯度计算完(猜测就是AccumulateGrad入边都遍历完了),会调用这个hook。
- 执行_post_backward_hook,会对这个FSDP unit的梯度做reduce-scatter
- Module computation阶段,使用unsharded param做计算。
-
_post_forward
- 释放unsharded param,节省内存
-
注册pre_backward_hook。注册到当前FSDP unit的输出上。tensor.register_hook的作用是当有梯度传过来的时候,会调用这个hook。对应的就是有梯度传到当前FSDP unit了,是当前FSDP unit开始做反向传播的时机了。
- 执行_pre_backward_hook,和pre forward一样,做All Gather,构建Unsharded Param参与梯度计算。
- _post_backward_final_callback
- 由FSDP root state注册到_execution_engine上的。这块因为我对torch的autograd并不熟悉,看注释就是在整个backward pass结束的时候调用。
-
这块主要做的是一些收尾逻辑,比如状态的清理有核心点在prepare_gradient_for_optim中,把反向传播阶段积累的梯度放到flat_param.grad上。从而实现每一个rank自己拥有的FlatParam上,都有sharded param + sharded grad,然后optimizer.step()即可。
Autograd
实现上,还有一个需要考虑的事情。既然FSDP引入了FlatParam,而用户定义的模型的参数都是保存在他们自身的模块中的。那么怎么做梯度的reduce-scatter,以及何时做,就成了一个问题。
- 比如可以尝试hack autograd引擎,在计算阶段手动遍历一下所有的param,看梯度是否已经计算完毕,然后发起reduce scatter。但是这个遍历的时机也很难把握,以及还需要处理mini-batch的case
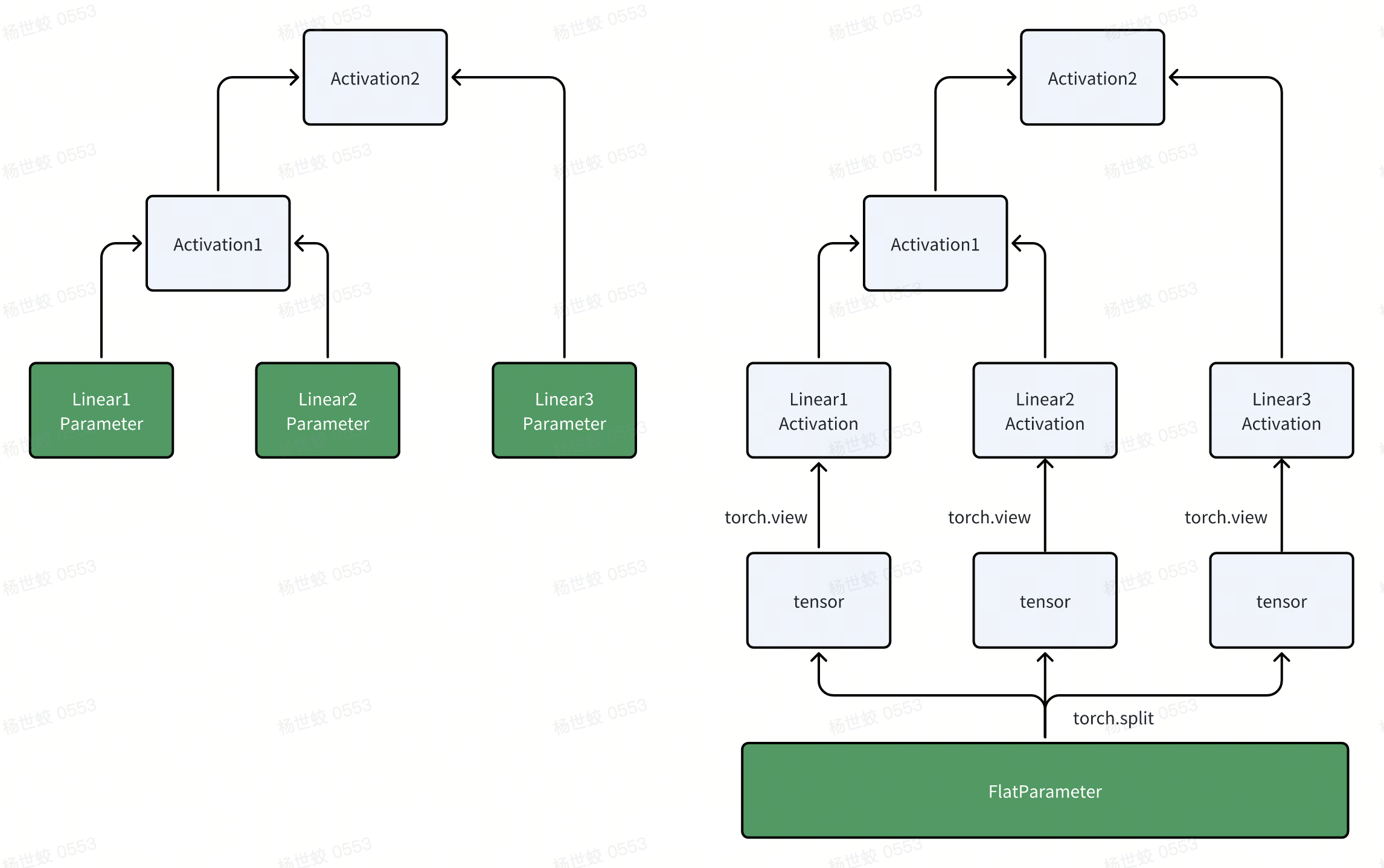
- 这里使用了torch的movement类型的操作,把原始module的参数看作是普通的tensor。真正的parameter只有FlatParameter。而原始module的参数是FlatParameter经过split + view变化之后得到的。
-
因为这些split/view也是会被autograd处理的,那么在反向传播的时候,梯度会自动从上面原始模块的参数Tensor中传播,直到下面的FlatParameter。
-
同时ReduceScatter的时机上面也提到了,因为Parameter上有一个AccumulateGrad的对象,可以在他累积梯度完成之后注册一个hook,完美契合我们希望做ReduceScatter时间。
如果阅读代码的话,有一个额外的点,就是在注册这个AccumulateGrad的post hook的时候:
- 新版本torch.compile支持了这个操作,直接执行register_post_accumulate_grad_hook即可
-
老版本没支持的时候,这里会hack的先做一次假的操作(expand_as),得到一个新的tensor。通过新tensor的grad_fn.next_functions[0][0],即在计算图上找这个函数的上游(反向传播的下一个节点),就是AccumulateGrad这个对象了。
还有一个实现上需要注意的点,就是FlatParameter在做unshard/reshard时的实现:
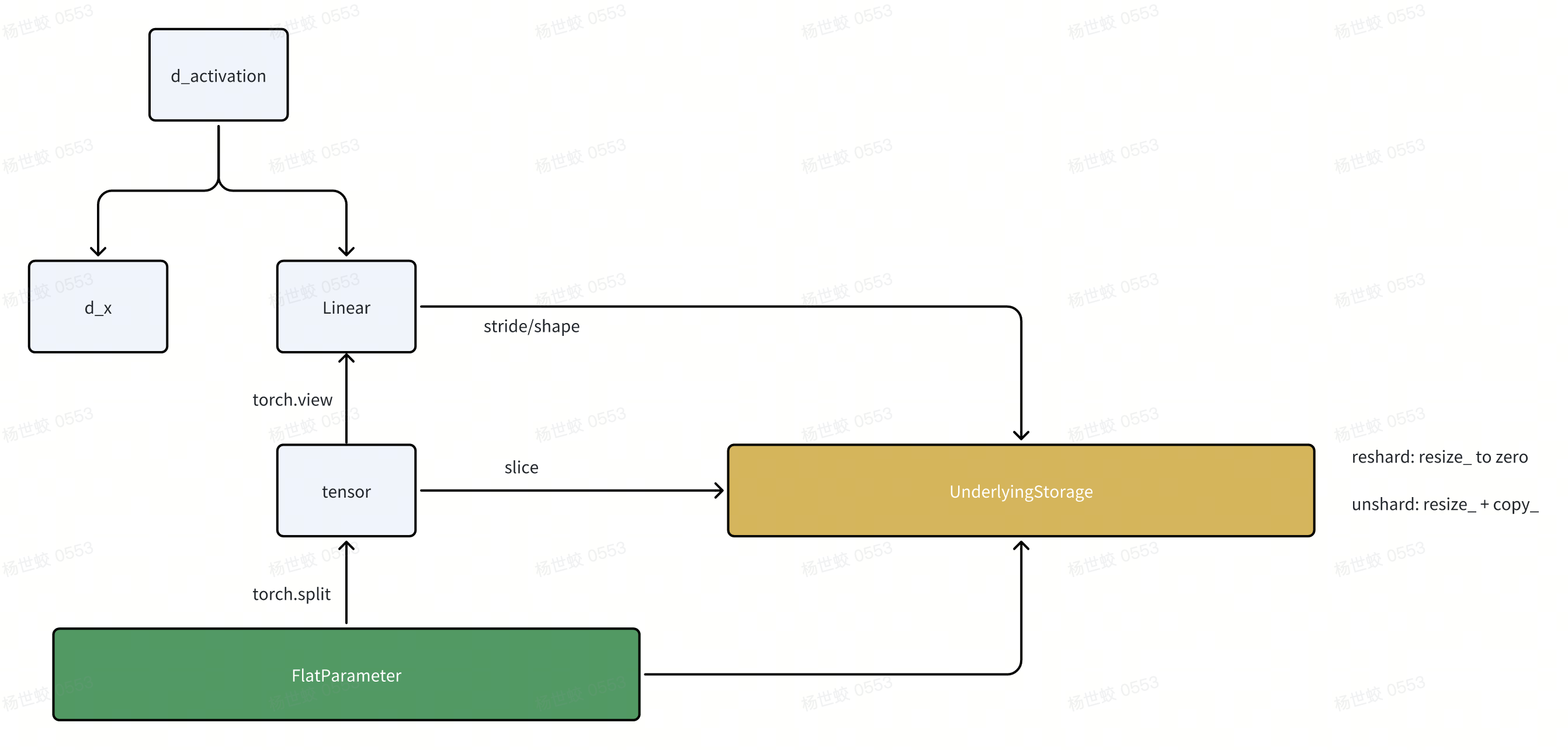
- 在计算dx的时候,需要用到linear中的权重。根据我们上面的讲解,linear的权重实际上是unsharded flat param的一个view。
-
在reshard阶段,我们会清空unsharded param,节省空间。backward的unshard阶段,我们会把unsharded param再拷贝回来。这个过程中我们需要保证上面的Linear的权重在反向传播时是有效的。
- 比如一种比较挫的实现,就是reshard阶段只是设置FlatParameter.data = None。因为Linear还持有这个view,所以不会发生GC,导致空间无法被释放。
-
而unshard的时候,如果只是设置FlatParameter.data = unsharded_param。只是更新了这个指针,Linear在autograd中,还是引用的forwad时用的weight tensor。
-
这里的做法是,这些tensor底层会共享相同的一个Storage的对象。上层autograd看到的是这里的tensor,而不会感知底层的Storage。
- reshard时,直接操作这个Storage对象,把他的空间释放到。
-
unshard时,resize这个Storage对象,并做拷贝。
-
在这个过程中,autograd始终看到的是相同的tensor/Storage对象。但是Storage对象对应的数据是有改变的。
Computation/Communication Overlapping
-
overlapping相关主要分两块
- 控制多个stream来实现计算/通信的并发
-
通过Prefetch,减少等待参数ready的时间
- stream,这块我也没抠过代码,主要知识还是来源于GPT老师
- stream可以看作是任务队列,队列内的操作是FIFO的。不同stream之间是并行的。
-
核心的几个API,在FSDP代码中会经常看到
- with stream(StreamA),表示切换stream,默认情况下有一个stream。切换stream后,会把CUDA相关的操作都提交到对应的新的stream上。那么通过with stream切换,就可以实现提交多个并发的任务
-
streamA.wait_stream(StreamB),stream之间做同步。相当于在streamA中提交一个任务,这个任务的语义是在StreamB当前提交的所有任务执行完之后,再去执行streamA的操作。
-
tensor.record_stream(StreamA),告诉allocator,tensor会在StreamA上使用,所以在StreamA的操作完成之前,不要释放tensor
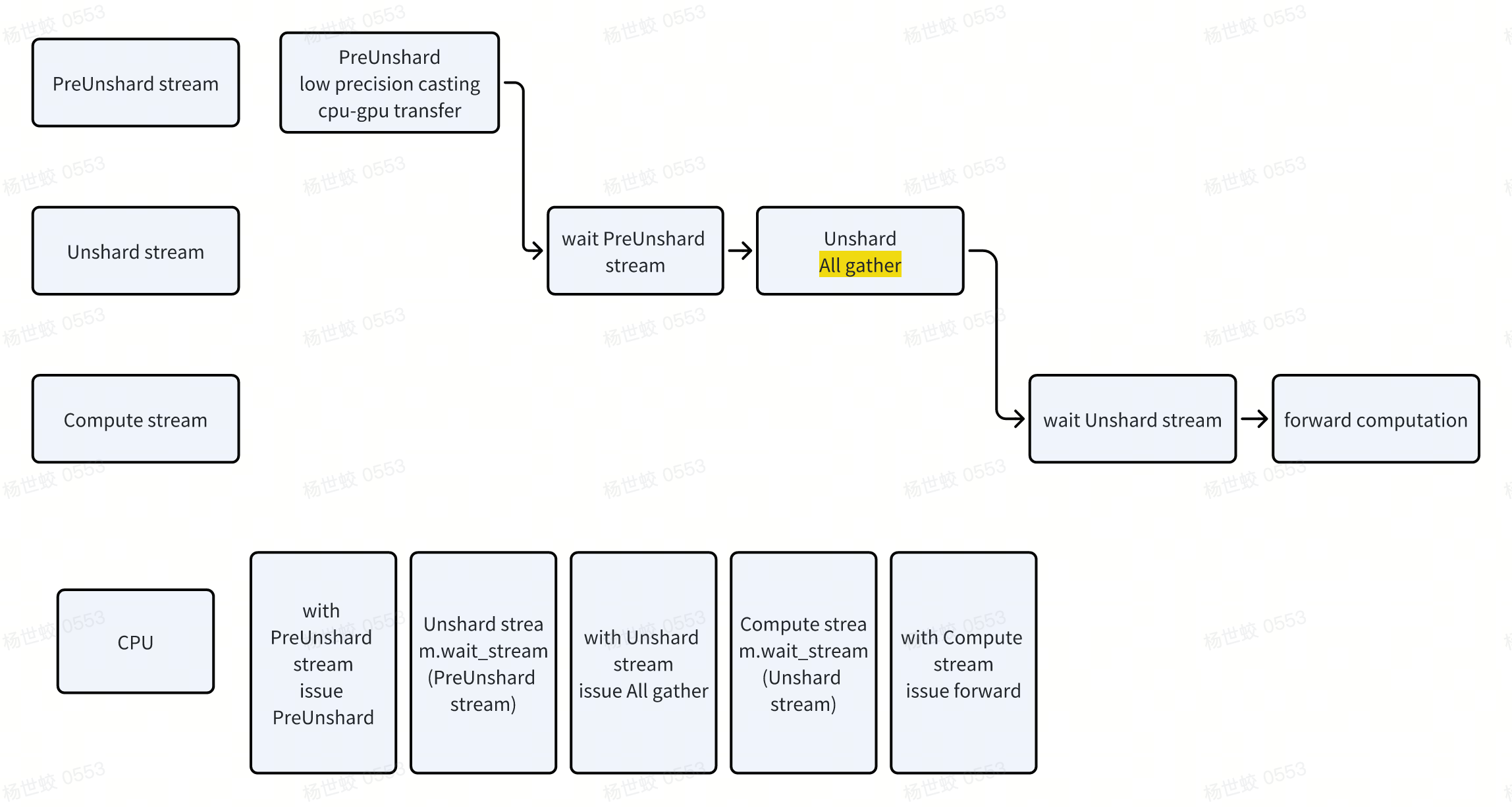
- 这里是pre forward阶段的示意图。这种在stream之间切换,pipeline的模式。就是多种任务的overlapping。
- PreUnshard stream使用的是precision casting的资源(不知道是不是独立的),以及cpu-gpu的移动(PCIE的带宽)
-
Unshard stream使用的是网络带宽
-
Compute stream使用的是GPU的计算资源。
- 第二块就是prefetch,这块相对简单
- FSDP维护了每一个fsdp unit的pre/post forward的执行顺序。执行的时候,就会根据当前的阶段,以及之前记录的pre/post forward的执行顺序,来尝试对下一个FSDP unit做prefetch,即做unshard param(All gather)
-
pre_forward阶段,记录pre forward的执行顺序。这里假设是静态图,所以只会在第一个iteration做记录。每一个FSDP unit的状态上会记录自己执行的顺序。
- 即假设forward是根据pre forward的顺序来的。
- post_forward阶段,记录每个FSDP unit post forward的执行顺序,用来做backward的prefetch
- 即假设backward是根据post forward的逆顺序来的
- prefetch这块有一个额外需要注意的点,就是forward阶段的prefetch默认是关闭的。
- 因为CPU的执行一般快于GPU,所以按顺序执行forward的时候,后面FSDP unit的All Gather都已经被提前发起了。
-
当部分CPU bound的场景时,All Gather快于CPU的执行,此时需要通过CPU预先发出后面的All Gather。才需要prefetch forward
-
那么相关的问题,既然CPU执行这么快,backward阶段应该也不需要prefetch呢?
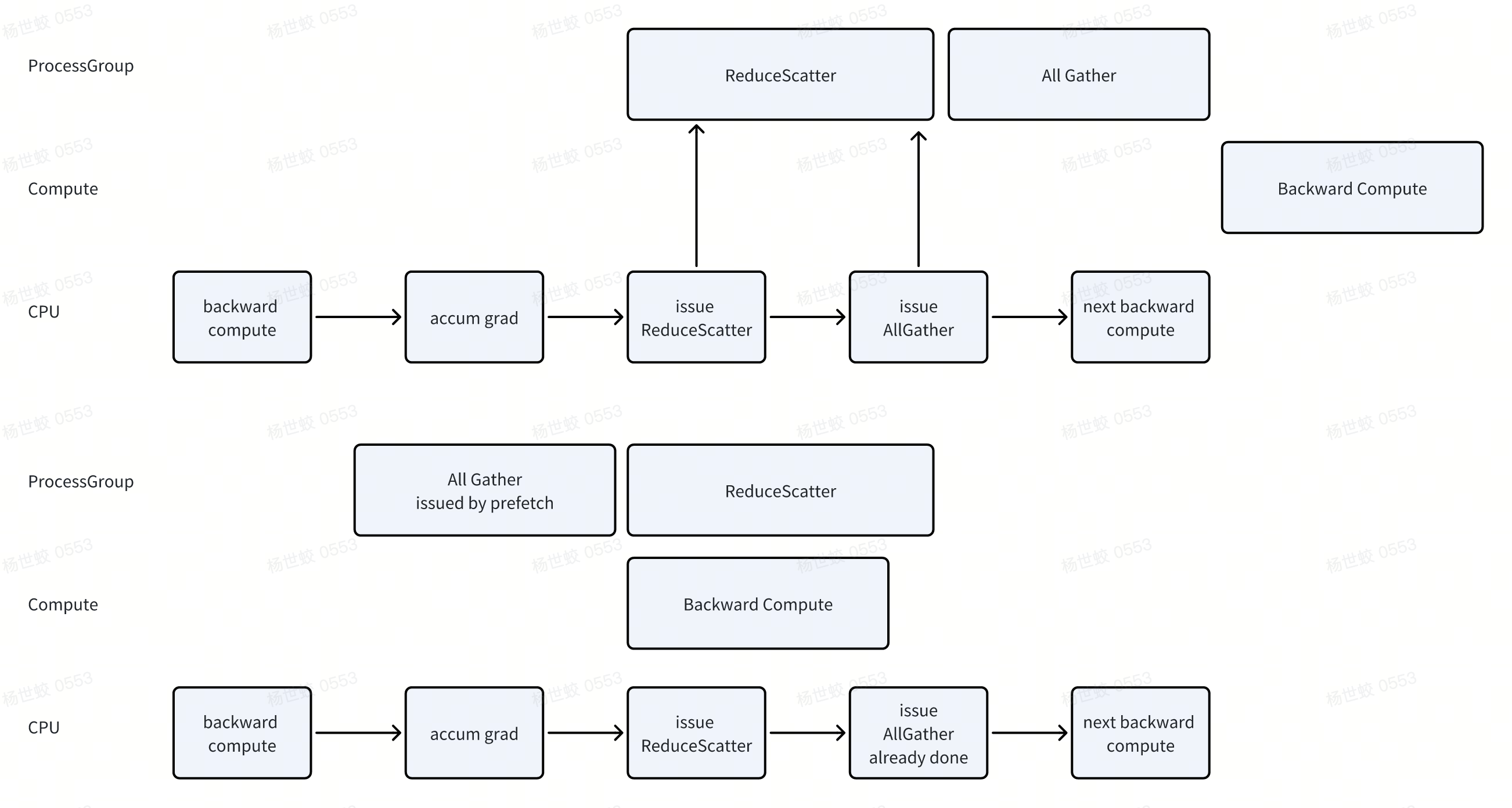
- 这块在论文中已经有回答,因为ProcessGroup中通信时串行的,如果不做Prefetch的话,那么有可能先执行ReduceScatter,再执行AllGather。导致阻塞下一次backward compute的进行
-
所以做一下prefetch可以先发起All Gather,让后面的Backward compute和当前的ReduceScatter并行。
MemoryManagement
-
这块主要是follow论文中的描述,以及对应的实现。这块不看论文/经过大量实践的话,感觉完全发现不了这个问题,估计是工程团队实践出真知了,感谢分享。
-
先看一下Pytorch的CUDA Allocator的工作原理:
- 使用GPU内存/释放内存的时候,需要调用cudaMalloc/cudaFree,会产生设备的同步,开销比较大。
-
为了缓解这个问题,torch自己搞了一个缓存分配器,会先从cuda中分配比较大的block,然后自己内部复用这些block,尽可能的减少cudaMalloc/cudaFree的调用
-
torch的allocator是在CPU中工作的。是在执行到这个代码的时候立刻做决策的,而CPU/GPU是异步的,所以他需要做估计,来决定尝试复用那些block。
-
在单个stream的语义下,所有的操作都是串行的。所以这个决策比较容易做,看一下队列里的任务对于某一个block都用完了,就可以做复用了。
-
在多个stream的情况下,因为执行是并发的,stream之间没有顺序保证,所以复用策略比较保守,此时就会更容易多分配一些内存。
-
那么,那么可能出现一些stream疯狂的发起操作,尝试申请内存,然后发现内存满了,触发cuda的内存分配。
- 比如producer stream(unshard stream),发起了很多all gather操作。占用了大量内存无法被复用。(因为这些内存还等着用完了给consumer stream做计算)
- 同时,block的分配是stream级别的,无法跨stream使用。就更容易出现这个问题。比如上面的case,producer stream分配了一堆block,consumer没有的用了,就会在分配内存的时候触发同步。
-
这里核心问题是cpu执行过快,解决方法是all gather做限流,当发现all gather发的比较多了,就挂起cpu做等待。
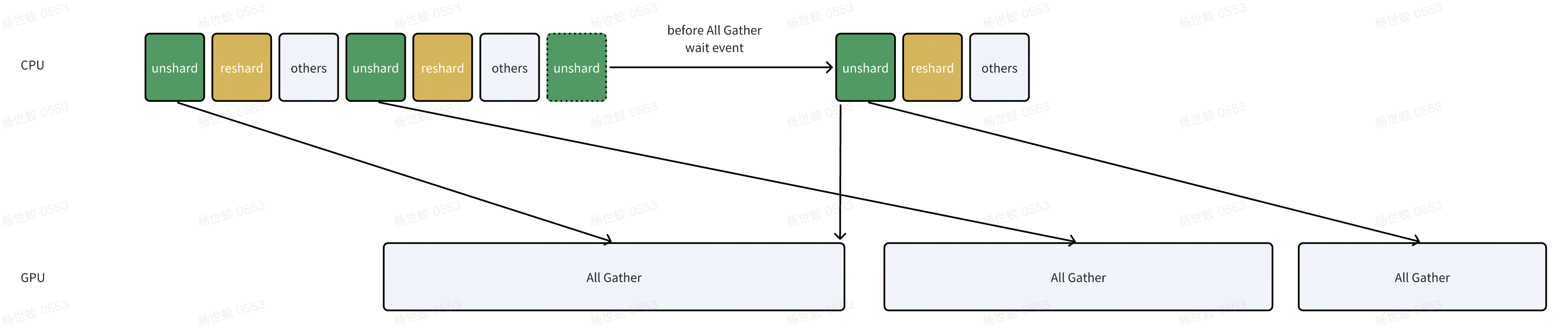
- 实现上,有一个_FreeEventQueue。每次All Gather之前,会等待上上个step的unsharded param释放。
-
比如图中,第三个all gather要发起的时候,发现此时有两个unsharded param还没释放,说明可能有两个inflight All Gather,就会做一下等待,等待上上个unsharded释放后,那么此时一定只有一个All Gather。在发起当前的All Gather
-
所以任何时间最多有两个并发的All Gather
-
实现上,_unshard/_reshard在整个链路中多次配合使用(pre/post, forward/backward)。来做param状态的切换,以及实现上面的限流逻辑。
ParamInit
-
好像没看到论文里说记录fake device上的操作,这块可能是我理解不到位。也可能是在torchdistX中做了,这块没有研究。
-
目前看到的init主要就是每一个FSDP unit单独做初始化
- 如果用户参数的设备是meta(没参数,只有shape),就会做materialize_module,把它移动到GPU上。
-
调用module.reset_parameter()或者调用用户传入的param_init_fn
-
初始化完成后会立刻做shard
Implementation Details
这里记录一些在阅读源码时可能比较迷惑的代码,以及一些invariance,方便在读代码时有一个直观的感觉
FlatParam状态切换
- FlatParam在执行过程中,会进行状态的切换。需要明确一下,否则读代码的时候容易搞混
- 因为在Optimizer的视角下,只能看到FlatParam和对应的梯度,此时他应该对应这个rank所负责的那块分片的参数
-
而在Forward/Backward阶段,我们需要unsharded param做计算,同时也需要autograd参与,需要保证在这个计算过程中FlatParam的data/grad这两个字段都是unsharded的。
-
同时,因为还有MixedPrecision/CPUOffload这些feature,也需要涉及到参数的变化。
-
为了维护上述的状态,FlatParam会把很多中间状态的参数存到他的成员变量中,在阅读代码的时候可以看FlatParameter中的注释,这里列举几个变量给一个直观的概念:
- _local_shard,保存的就是当前shard的参数。在optimizer阶段。
flat_param.data.data_ptr() == flat_param._local_shard.data_ptr() -
_full_param_padded,unsharded param。在计算阶段,
flat_param.data.data_ptr() == flat_param._full_param_padded.data_ptr() -
_mp_shard,低精度的参数,用于混合精度训练
-
_cpu_grad,用于offload grad到CPU上
- _local_shard,保存的就是当前shard的参数。在optimizer阶段。
- FlatHandle有一个状态的切换,代码中的逻辑会根据这个状态来决定走不同的分支
- 比如根据当前状态决定是否做prefetch(BACKWARD_PRE/BACKWARD_POST)
-
比如在BACKWARD_PRE阶段,如果发现进入了forward的链路,说明是启动了activation checkpoint,会跳过这次preforward(因为不需要重复做unshard)
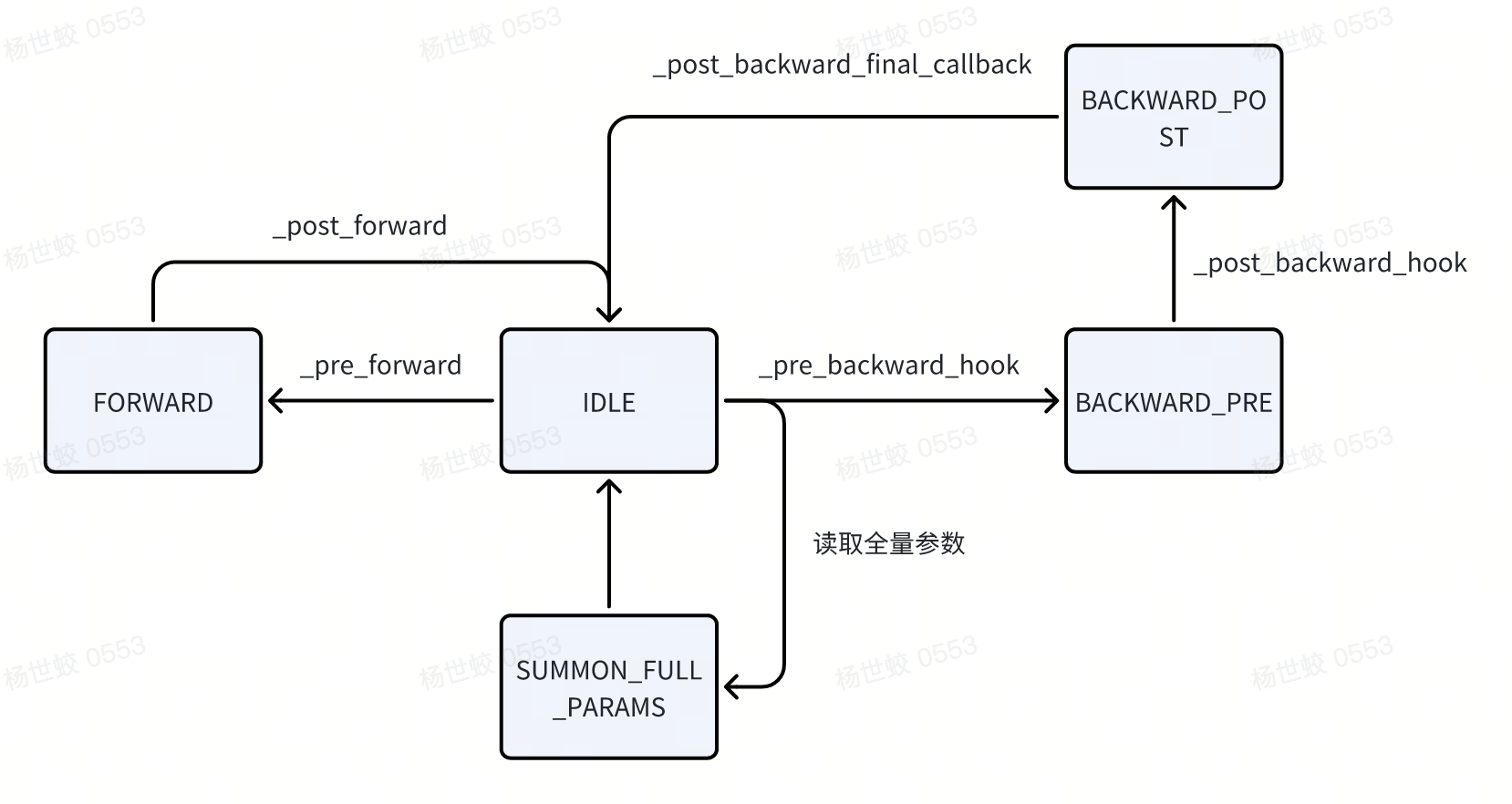
- FSDP state中也有一个training state,不过状态更少,主要是用来做一些入口的检查,防止不合法的状态。相对比较简单。
LazyInit
- 或者这一节也想讨论一下module的嵌套。
FSDP中,有一个root state,套着所有的子的fsdp state。这个root state负责初始化runtime相关的各种变量,比如stream,event queue等。
- 在forward时,第一个执行的state就是root state,此时会做LazyInit,做上面初始化的操作
- 之所以不在init时做,是因为init时用户可能自己单独用FSDP去wrap module,所以无法得知正确的fsdp state。
- LazyInit中,root初始化相关变量后,会把这些变量都传递给子的fsdp state,防止重复初始化。
-
那为什么代码中有一个reset_lazy_init呢
- 这是因为用户可能单独调用一个子模块的state_dict,此时会触发all gather,需要lazy init所初始化的stream。但是他并不是一个真的root。真的root需要在forward时才能知道。所以最后再重置一下状态。
有关FSDP的嵌套:
- 嵌套实际上是一个不太好的行为,因为嵌套的FSDP unit会在递归的调用preforward,内存占用是累加的。违背了FSDP希望节省内存的初衷。
-
不过还是有可能出现嵌套,比如一个简单的情况CausalLM中,我们的root FSDP state中,包含若干子的FSDP state,和lm_head + embedding这两个没有被wrapp的模块,这种情况下lm_head/embedding就会持续在内存中,和root fsdp state一起。
- 延展一点就是如果共享参数的param如果被手动放到了不同的shard上会怎么样。答案是不支持
Features
这一节简写一下FSDP相关的一些小feature的实现
StateDict
允许用户通过state_dict读取模型参数/进行修改。state_dict有多种模式,这里主要看FULL_STATE_DICT这种,对应state_dict返回的是unsharded unflatten param。也就是最符合直觉的一种。
- FSDP的实现没有重写state dict,而是注册了_pre_state_dict_hook, _post_state_dict_hook, _pre_load_state_dict_hook, _post_load_state_dict_hook。
-
主要做的就是两块:
- Unshard param,然后把初始化的时候记录的原始的模型参数都设置回来,方便用户通过named_parameters()来访问。这块实现上和forward阶段的unshard是一样的,做All Gather
-
Reduce grad,因为grad也是shard的,返回给用户的时候需要把grad也收集起来。
-
在state dict访问结束后,有可能用户修改了参数的内容,这里还会有一个write back的选项,把参数同步到flat param中
GradientClipping
因为GradientClipping需要收集全局的梯度,所以这里FSDP也提供了一个针对FSDP模型的实现:
- 每个模型本地计算自己的sum(grad ** p_norm)
-
all_reduce,计算全局的sum。再计算全局的norm
-
放缩梯度即可
MixedPrecision
https://zhuanlan.zhihu.com/p/694288870 这篇文章的图示画的已经非常清楚了。这里主要提一些要注意的点:
- FSDP的mixed precision是fsdp unit级别的,没有做到更细粒度的划分。
-
在forward/backward的unshard阶段,会把master weight(_local_shard)在精度转化,放到_mp_shard中,做后面的计算。
- post_unshard阶段就会释放掉这些低精度的参数。
- Backward reduce-scatter时,会根据配置转化成对应的低精度的类型做reduce。累计精度的时候,会用全精度的。
- 这里还有一篇讨论reduce type的文章https://main-horse.github.io/posts/reduction-precision/
- ShardedGradScaler
- pytorch提供了一个GradScaler的工具,为了避免梯度计算时的underflow的问题,他会先给loss乘上一个比较大的值,然后做backward pass。最后再把梯度缩回来。
-
这个过程中,因为乘上了一个比较大的scale,所以可能出现overflow,当出现overflow的时候,这一个pass会被跳过。
-
对于FSDP来说,需要保证当一个rank出现了overflow,所有的worker都需要停止这次更新。ShardedGradScaler帮忙做了这个事情,会在optimizer之前做一次all reduce,同步overflow的数量,所有worker看到相同的overflow的数量,作出相同的决策,是选择做梯度更新或者是跳过更新。
CPUOffload
-
CPU offload,支持将master weight和grad offload到CPU上。核心思路可以参考Zero-offload。同时如果和上面的MixedPrecision配合起来的话,可以做到Zero-offload一样的效果。
-
启动cpu offload之后,会把_local_shard对应的master weight放到CPU上。
-
unshard阶段,会把master weight从CPU移动到GPU上。如果有mixed precision,也会在这个阶段做转化。计算完之后再释放掉这段内存
-
backward阶段,做完reduce-scatter之后,会把grad移动到_cpu_grad中。因为optimizer要求param和grad在同一个设备上,才能做计算。
UseOriginParam
use_orig_param的目的是让用户在使用FSDP的时候,也可以通过parameter()访问到原始的那些参数,同时支持了frozen/un-frozen混合的训练。给用户更丝滑的使用体验。
这一节因为比较细节,更多是讲实现相关的。按需阅读即可
在代码上,主要关注的就是四个地方:
- 参数划分
- ShardParamInfo中会记录,对于当前rank,每一个参数是否有一些数据保存在当前rank中。如果有,他对应的offset/length是什么
-
FSDP提供给用户的参数就是这里被切分后的参数,梯度也是一样。
- 比如一个weight,有一部分在rank0,一部分在rank1。那么rank0就看到的是一个1D的tensor,对应这个weight的一个切片。
- unshard
- 这里也是把原始模型的参数替换成tensor slice。但是会把新的tensor slice也注册到module.parameter中
-
生成的tensor slice会被保存下来。
- 因为如果有reentrant AC,在backward pre阶段会再次调用forward。此时需要用slice再替换掉之前的parameter。
-
为了保证两次forward相同,这里会用第一次forward的tensor slice来替换,只不过data会被重新复制。
-
相关的一个问题是,为什么use_orig_param=False不需要做这个处理呢?
- use_orig_param=False的时候,reshard不会做任何操作,不会去操作这些tensor slice。所以再次forward的时候,没有人动过这里的结构。
-
而use_orig_param=True的时候,reshard会把原始的parameter替换回来,所以pre forward时候需要再把之前的tensor slice拿回来。
-
至于data,我个人感觉可能不用重新赋值,因为他们应该始终都是指向同一个flat param的storage
-
reshard
- 会把之前module的param切回来。然后把data设置成当前shard的flat param的slice。如果param不在当前shard的话,会被设置成0
-
在post backward阶段的reshard,会把grad也切分,分发到对应的param上。如果require_grad=false,梯度也会被清理掉。
- 这里就解释了fsdp是如何支持frozen/unfrozen一起训练了:
- Use orig param= true的时候,在backward阶段,会把梯度再重新赋值给各个param。如果是frozen的param,require grad就是false。此时就不会传梯度给他。
-
同时也可以解释为什么说一起用的时候资源占用会多,因为fsdp的backward是统一给的flat param。在backward阶段没有区分frozen/un frozen。而是计算完之后,最后分发的时候做的区分。
- 个人感觉做这个区分应该不算很复杂,可能就是给tensor param哪里设置一下require_grad = false就行?
- 这里就解释了fsdp是如何支持frozen/unfrozen一起训练了:
- manual
- 因为用户有权限访问原始的param,那么他就有可能去修改原始param的数据,或者是尝试主动去清理梯度。这些操作会被记录下来
-
在pre_unshard阶段,会去同步用户的操作和flat param/grad。核心函数在_writeback_orig_params中。
-
这里会去判断param的数据是否有变化(是否和flat param指向相同位置),如果有变化会把对应位置的数据拷贝到param中。梯度也是同理。
Reference
https://zhuanlan.zhihu.com/p/694288870
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel

文章评论