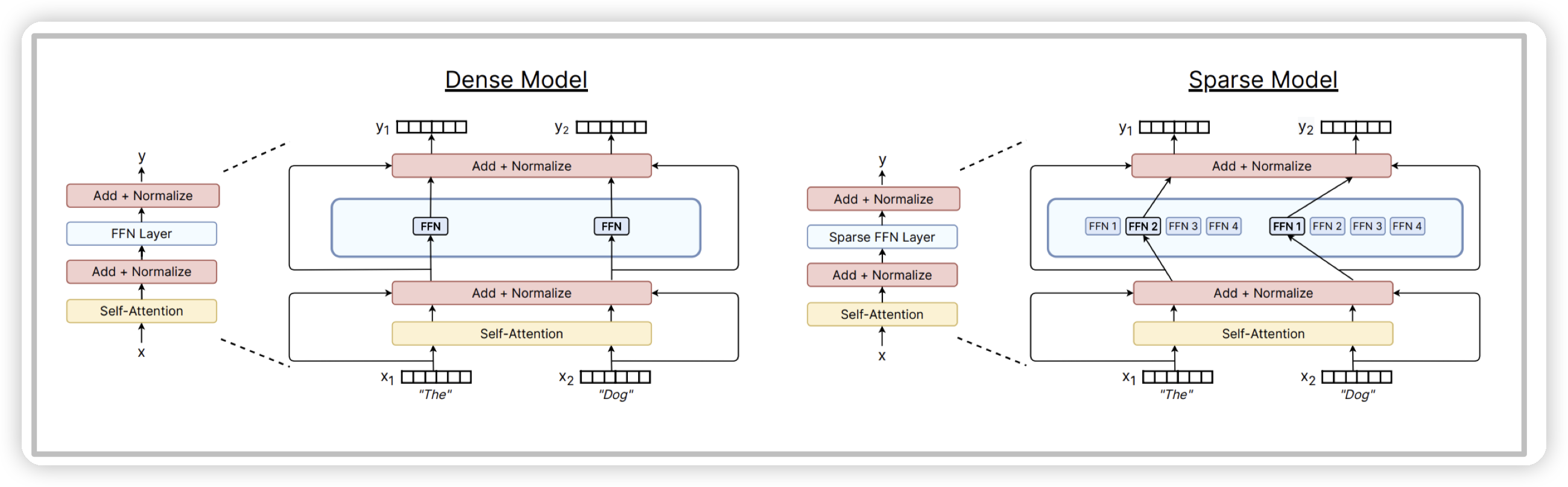
MoE的核心点是在attention block中的FFN层,加入多个FFN,然后根据输入选择不同的FFN来计算。
对应的一篇比较不错的综述:A Review of Sparse Expert Models in Deep Learning
作者同时也是switch transformer的作者,也是将MoE应用到了transformer中
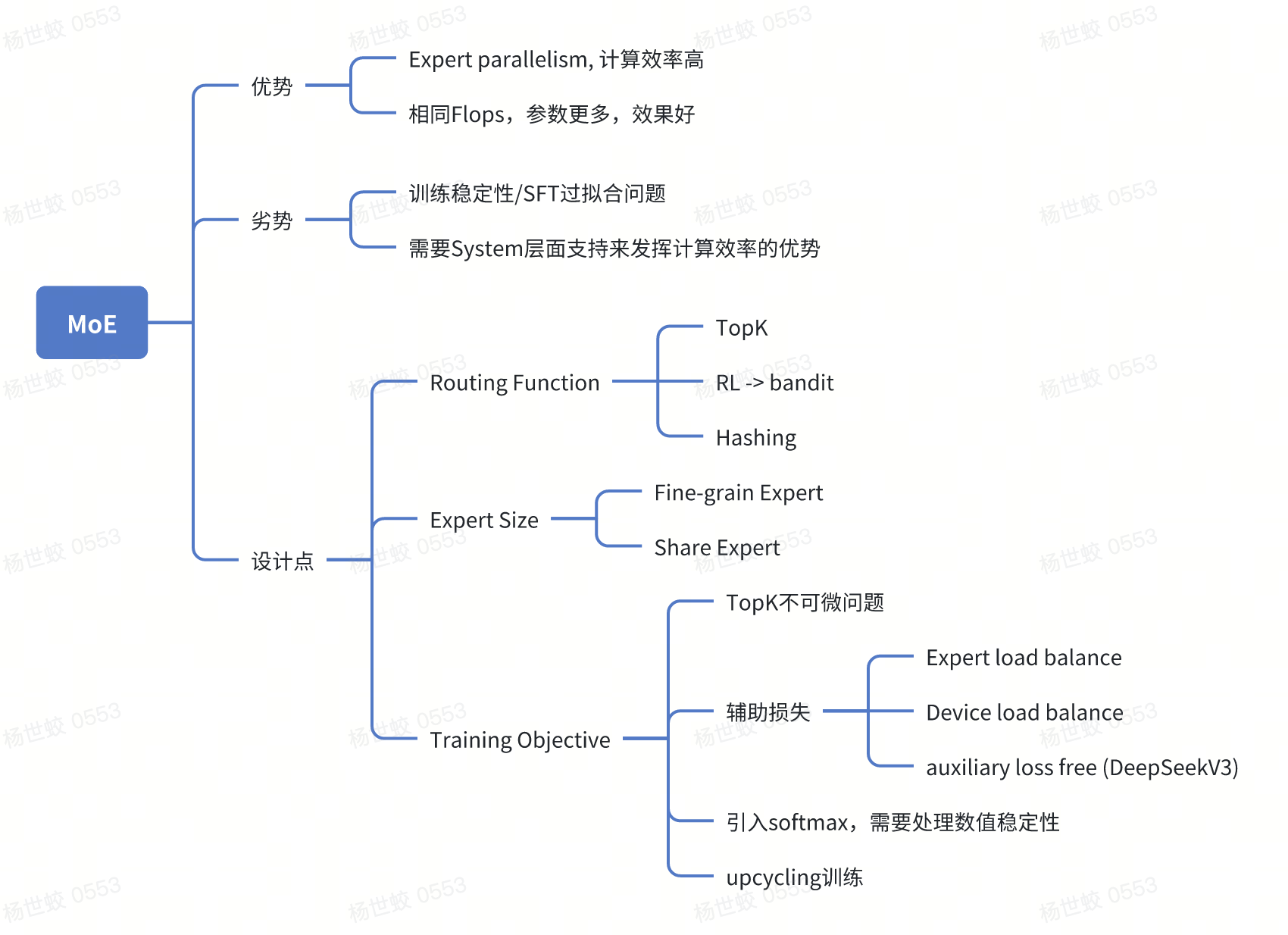
MoE有两个比较大的好处:
* 推理阶段,允许在相同的FLOPS下,使用更大参数量的模型。(直观感觉就是允许模型通过更多参数记忆更多世界知识)
* 验证效果更好,activation params相同的情况下,跑分更高
* 训练阶段,可以在多个expert之间进行并行,提高计算效率。

而之所以MoE没有广泛应用,主要有两个缺点:
* 要想利用好MoE带来的计算优势,需要Infra的支持。
* 一般在训练/推理阶段的data parallelism,不同的机器会有不同的data slice,每个机器会保存全量的参数
* 使用MoE后(相当于启动model parallelism),每个机器只保留部分expert的参数。在计算阶段需要做:
* token的路由(相对比较简单)
* expert的负载均衡(后面会提到也和模型本身有关)
* 多个计算节点之间的通信代价,需要考虑出现的带宽瓶颈。
* 使用MoE训练不稳定,后面也会提到,尤其是在做微调的时候容易过拟合
还有一个需要提的是,MoE一般只用在FFN中,不会用到attention上:
* 因为FFN是token-wise的,不需要考虑全局信息,做token级别的路由比较容易
* attention的projection会影响后面的全局attention score。
* 当然主要还是有实验效果
然后来看MoE中的几个设计点:
* Routing Function
* Expert size
* Tranining Objective
Routing Function
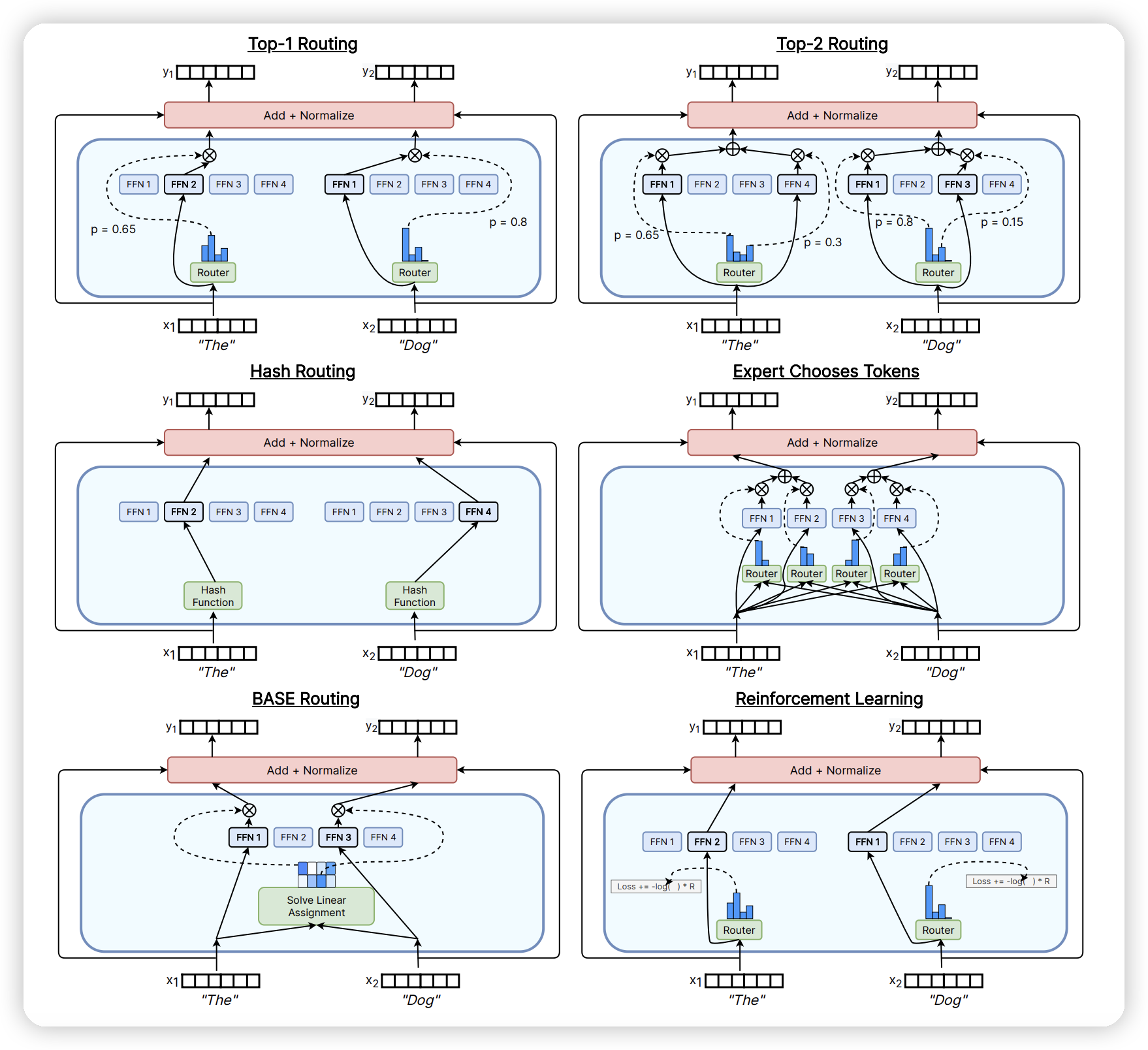

目前最常见的TopK Routing:
* token embedding和每一个expert学习到的一个向量做dot product,然后过一个softmax,得到每一个token到每一个expert的分数,然后取topk的expert,计算FFN后在融合embedding
* 融合有多种,相加,取mean,或者类似这里的用softmax的得分(有点类似topk的attention,从token到expert的)
Hashing:
* 根据token embedding确定性的hash到一个expert上
RL:
* 这里是我yy的,把bandit多臂老虎机的方法套进去。去根据当前状态(token embedding, 可能还有layer?)做出action(选择expert)。奖励是从loss得出来
Base Routing:
* 去解一个匹配问题,比如最优传输什么的。不过这块我还没有映射上去,还得具体看下paper
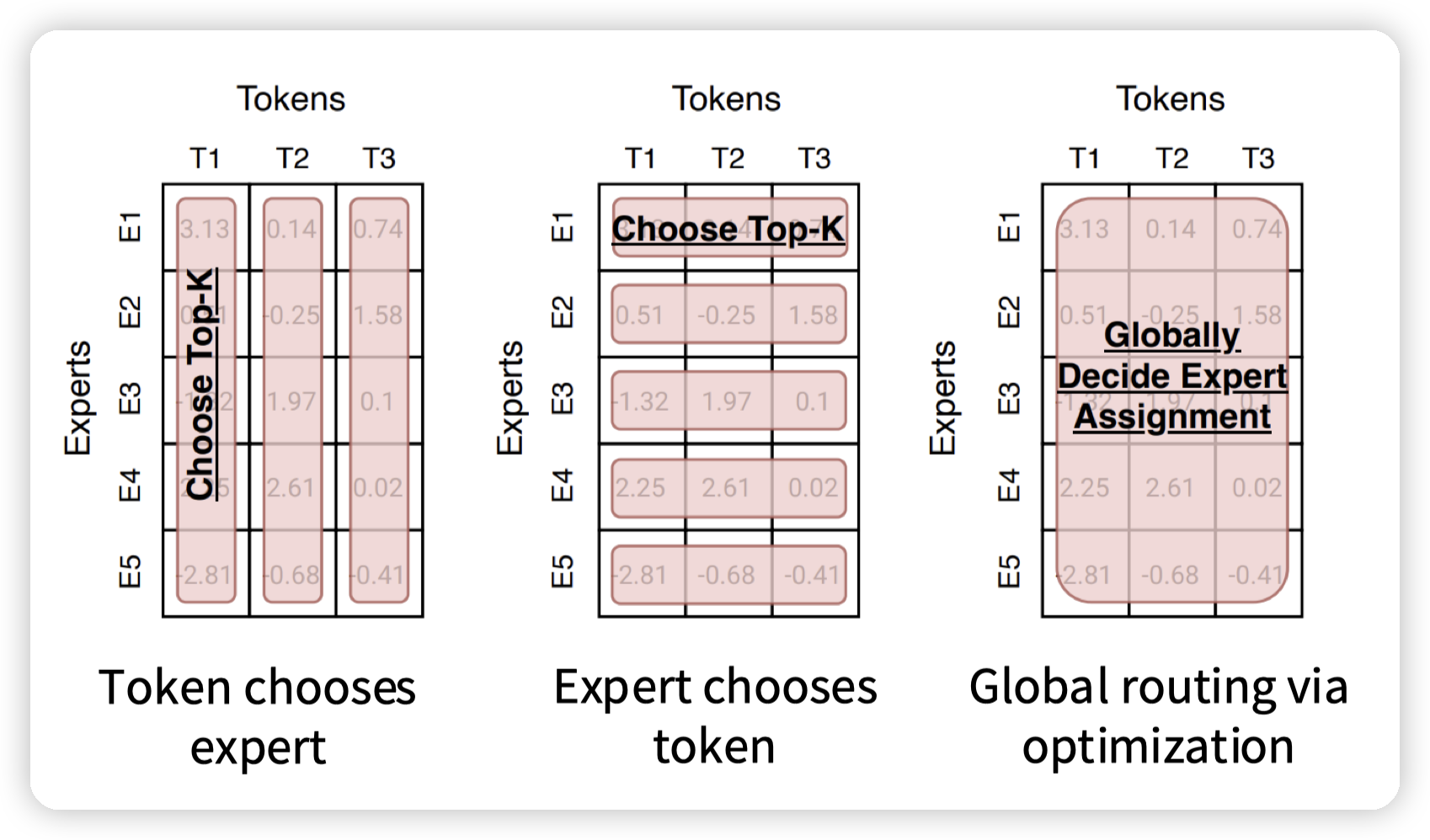
这里是从另一个视角看上面的一些方法,说的是计算出来token/expert的得分后,怎么去分发这些token:
* token choose expert,每一个token独立选,好处就是对token效果好,坏处就是可能负载不均衡
* expert choose token,则是会有负载均衡
* global routing,就是不用topk,而是引入一些其他的分配方法,和上面说的Base Routing是一样的
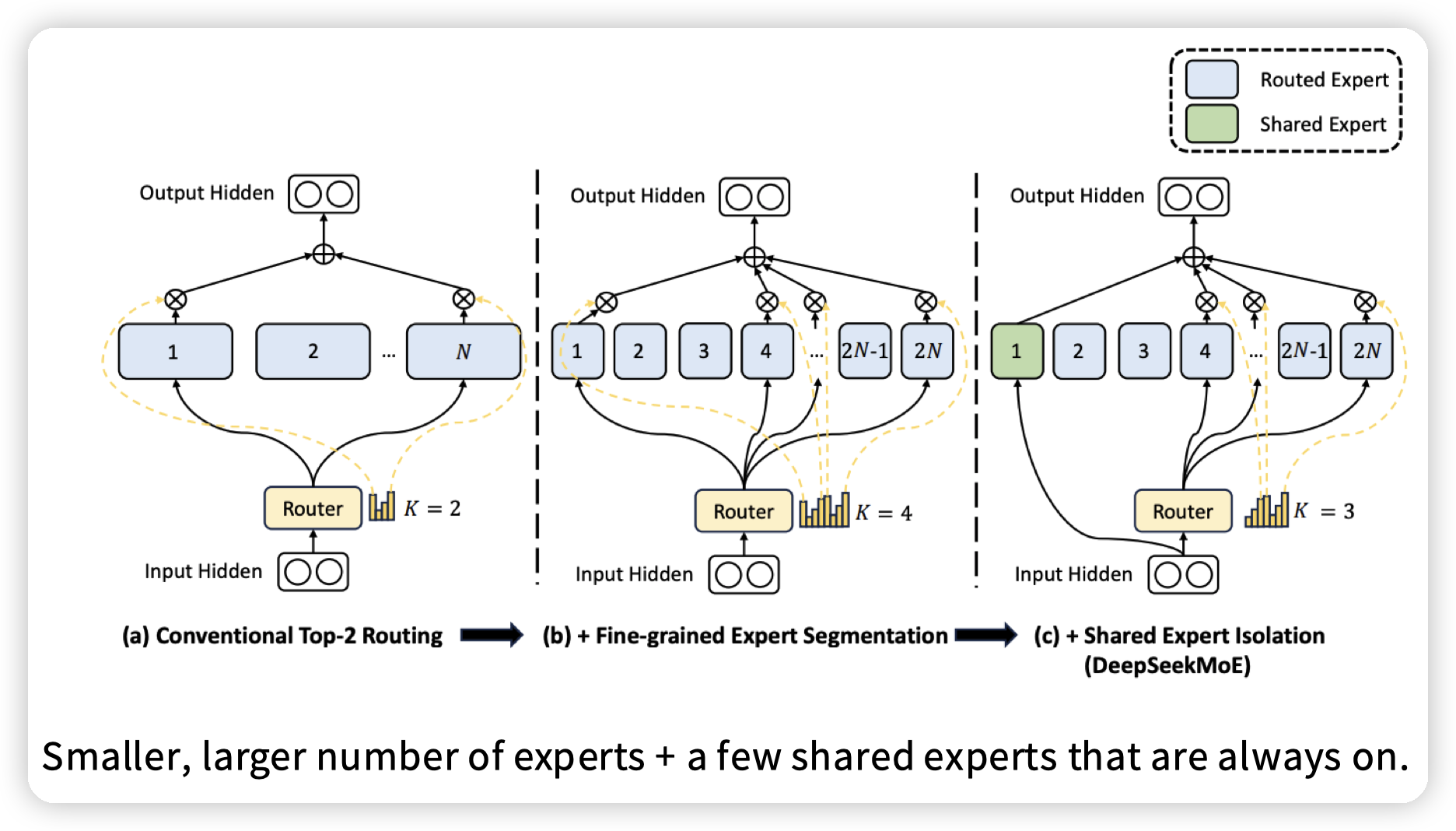
近年还发展了一些MoE变种,引入shared expert,就是每次都会选的expert。
Expert size
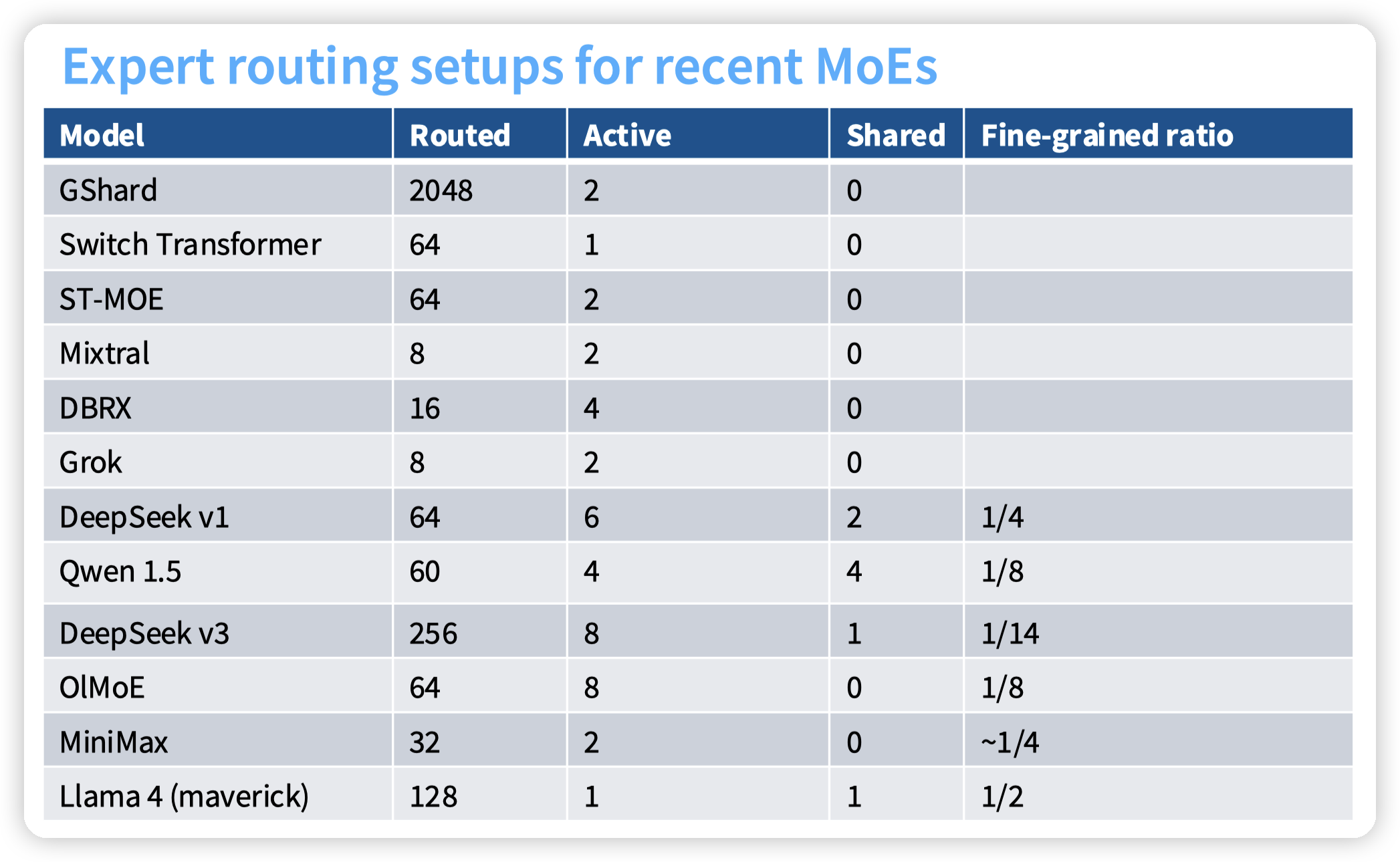
常见的一些MoE的超参数
需要注意的是,为了避免推理成本上升,当选择多个激活的expert的时候,这些expert的大小就不再是和非MoE中的FFN一样了。比如去调低d_ff
* 这块还有一个值得关注的细节,如果是调低的话,按照一般的配置(d_ff = 4 x d_model)。如果缩小过多就会变成降维了,不知道是否会对效果产生影响。这块等下来再看一下DS V3的论文
Training

这里训练的一个问题是,我们使用TopK去选择Expert的时候,没有选择的那些Expert的向量表示的梯度是0。
* 个人感觉这块问题比较类似ReLU,负激活值的时候梯度会变成0,导致参数无法更新。
然而我们希望的是让模型在各个expert之间进行选择,探索最好的expert。而上面那个问题可能导致最开始选了一些expert之后,就一直选,没有考虑其他的expert,也就失去了MoE的作用。
上面也提了,这种平衡探索/收益的问题可以套到多臂老虎机上,然后用RL来解决。
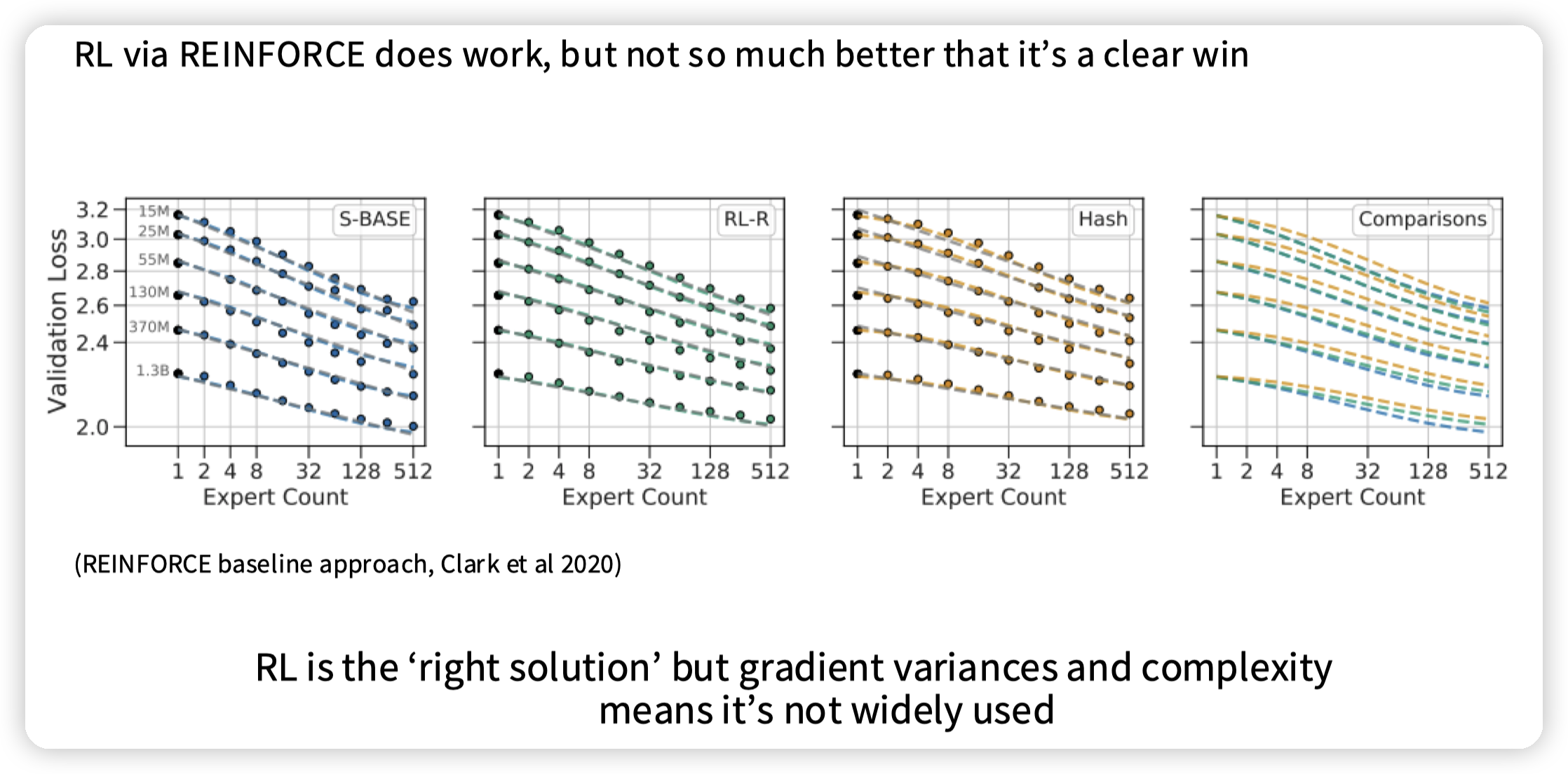
RL确实work了,但是和hash效果差距不大,并且RL本身训练比较困难,再加上需要引入额外的推理开销,所以用的不多。

另一种方法的核心出发点是增加探索的粒度,在计算每个Expert得分的时候,引入噪音,让模型也可以探索一些其他的expert。

第三个方法,也是现在比较常用的。核心思想是:
* 既然主loss因为TopK的原因传不下来,那我们增加一些辅助的loss,也在expert没有被选上的时候,调整对应router的参数
上面是switch transformer中的思路,给每一个switch层加一个辅助的损失:
* fi是这一层分发给expert i的token的比例
* Pi是这一层router对expert i的概率
* fi Pi是有一定正相关性的,这里搞两个我猜测也是考虑有一些额外的负载均衡策略,导致Pi无法真正反映负载
* 然后损失函数优化的是一个均值不等式,当fi x pi都相同的时候取最小。直观想优化目标就是希望每一个expert都拿到相同的token,避免负载不均衡,同时也给那些没有被选上的expert赋予了梯度,避免陷入局部最优。
(这块发现一个比较有意思的事情是,上面的这个均值不等式,在实践中是可以通过这个梯度来计算出来在什么情况下取最小的。这么看一些优化算法都可以尝试通过梯度下降来优化?
* 可能需要考虑的是算式需要是可微的。然后梯度下降也可能陷入局部最优,毕竟算是一种随机算法?

DeepSeek在此之上增加了Device级别的load balance,思路也是一样的,只不过根据device做了一下聚合

DeepSeek V3则是给gating增加了一个per-expert的bias,然后根据expert的使用情况在线的去调整这个bias:
* 简单想就是使用频率越高,调这个bias调的越小
然后还增加了一个sequence级别的expert平衡。和上面的区别就是上面是batch 级别的,会受到batch的影响,这里只加了一个sequence级别的,保证单个sequence内不会出现偏斜。
* 可能是认为单个sequence有expert偏斜会导致expert无法均衡之类的事情

还需要注意的training stability的问题是这个router也引入了softmax,所以也需要小心数值的问题。用lec3提到了一些优化技巧。
这里还举了一个例子:
* 10个logits,最大值是128.5,减去最大值后,bf16的roundoff error把-0.5变成了0,导致最计算的得分差了36%
* 可以看出来数值误差的问题影响还是比较大的,对于这些指数计算的用高精度一些的好一点。
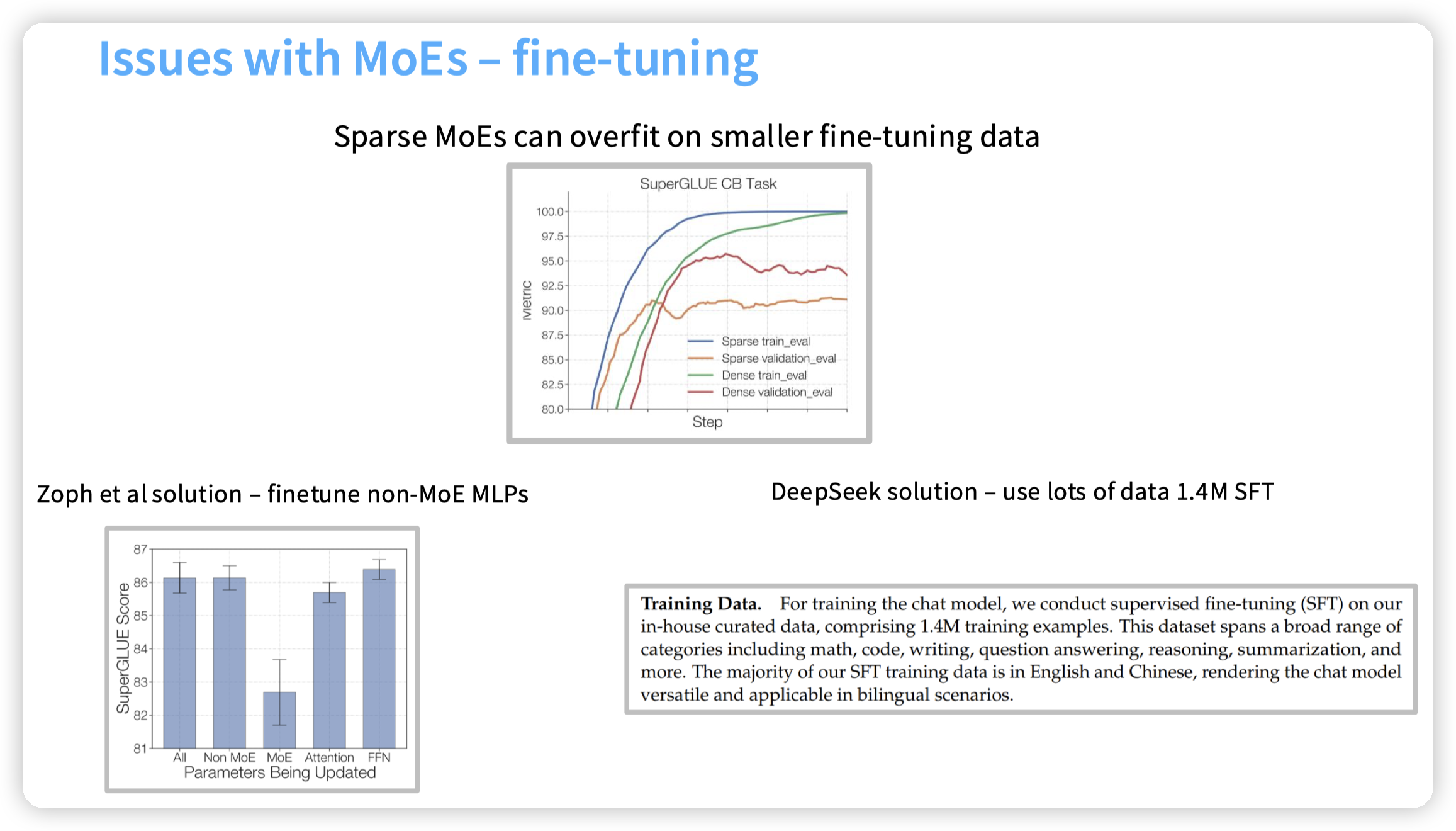
还有一个过拟合的问题。DeepSeek的结局方法是使用大量的SFT数据。
* 不过这里过拟合的问题如果来自于数据量的话,应该不只有MoE会出现问题
* 可能是因为MoE的FFN比较多,导致容易记住这些数据
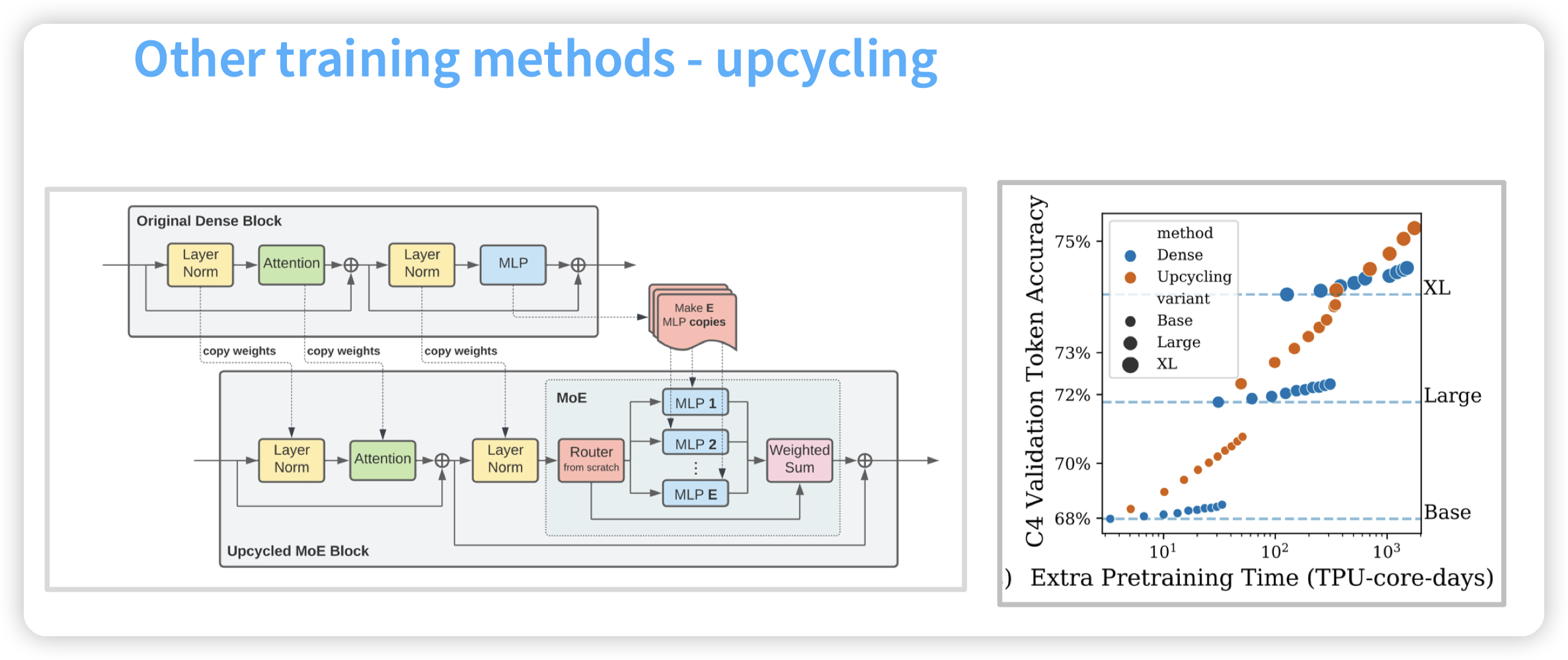
还有一个技巧,把一个dense model转化成MoE,复制预训练好的dense model的FFN,再去做训练。看图中数据可以更快速的收敛
课程最后还讲了DeepSeek的一些其他技术,比如MLA,以及和System结合的一些设计,这个就不在这里写了,后面单独分析DeepSeek的paper的时候再写吧。

文章评论