第五课主要讲GPU的一些基本知识,第六课则主要是讲如何做benchmark/profile,以及优化性能的一些方式
教授推荐了一个blog:https://horace.io/brrr_intro.html
很久之前学的CMU15418中也有GPU Architecture / Cuda Programming的东西,时间一看已经是2016年spring,接近10年了。
正好复习一下,然后结合这两个课程来介绍一下GPU相关的背景知识。
GPU Architecture
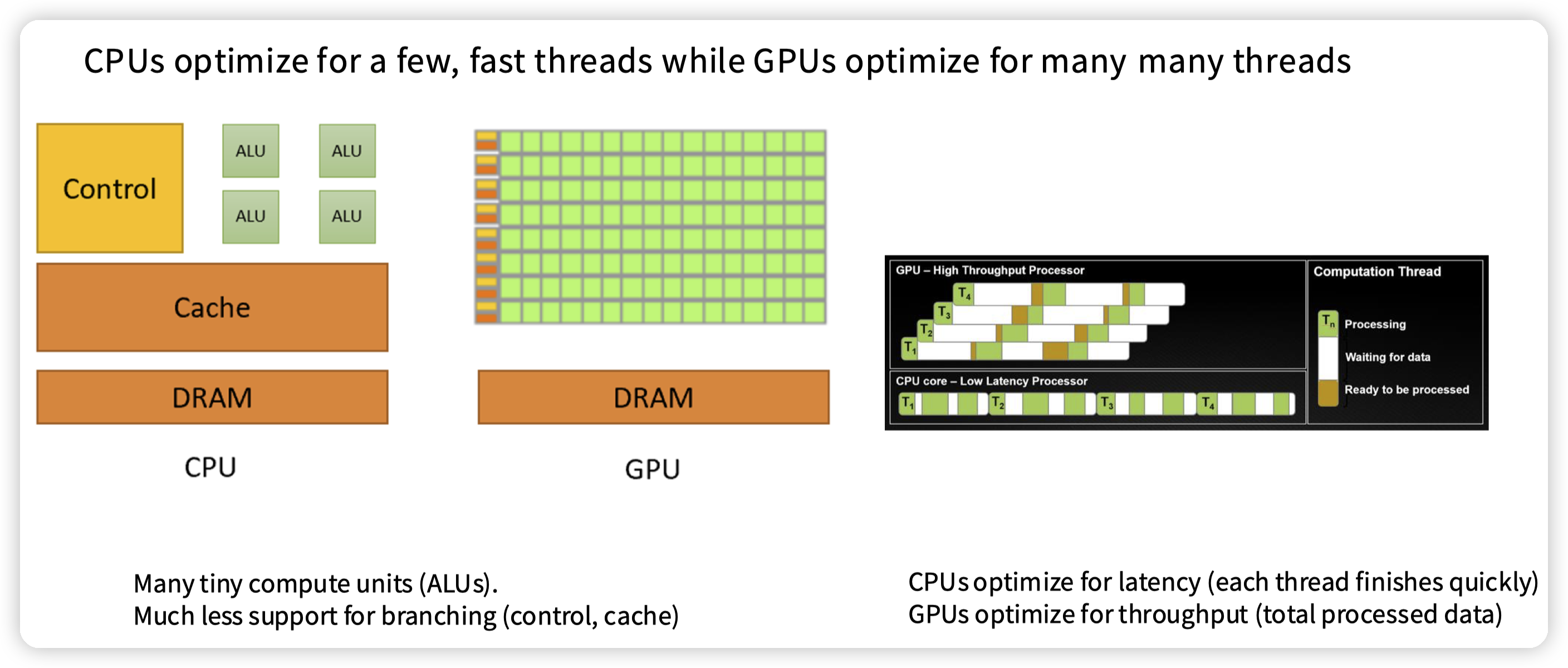
* CPU,针对latency优化,很多的地方会针对控制流优化,所以Control/Cache占用的部分比较多。
* GPU,针对吞吐优化,大量的芯片被分配到了计算单元上,少部分在control/cache中。
* 和CPU相比,线程状态更加轻量,所以上下文切换也更加容易
* 因为cache少,访存延迟也比较大。通过大量的线程来提高吞吐(提高并发)
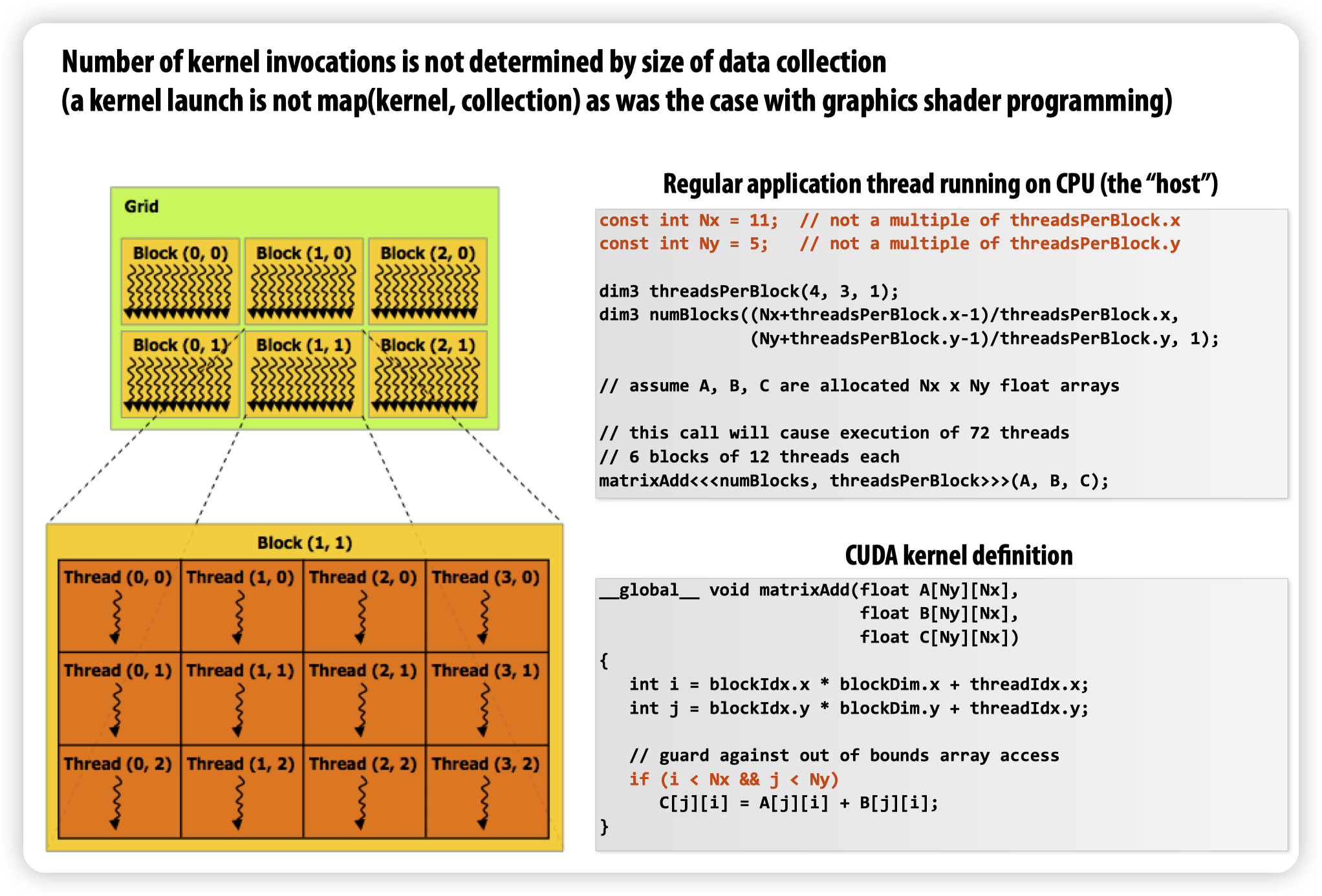
执行模型,336上那个我感觉可能导致迷惑,我把15418的摘出来:
* Abstraction上,或者说编程模型上(也就是CUDA的概念)。有三个概念,Grid,Block,Thread
* Grid是包含一组Block,一般就是用户的一个任务。其中Block可以按照多个维度进行索引,用来方便编程
* Block则是调度的粒度,包含若干个Thread
* Thread则是我们平常理解的thread,操作一份数据
* 注意虽然理解上是thread,但是实现上和CPU上是不同的

GPU实现上,也就是在硬件的概念上,有warp,和SM(streaming multiprocessor)
* 一个GPU会包含多个SM
* 一个SM同一时间会执行一个block,一个SM也就是一个多核处理器
* 一个warp对应是一组cuda thread。
一些额外的性质:
* 32个cuda thread会共享一个instruction stream,也就是所谓的SIMT。当不同线程出现不同的执行流的时候,通过mask关闭一些lane。
* 和CPU上线程的区别?比如不同CPU的thread,执行不同的任务不会相互影响(有不同的PC),而GPU中相同的warp中,执行thread A的任务的时候,thread B是关闭的。所以会相互影响,实践中也需要尽量避免这种情况。
* 这里图中有4个warp selector,所以最多可以同时执行4个warp,也就是4组线程。一个SM中最多可以保存64个warp的状态。
* 这里还提到了每一个warp可以选择两个可以执行的指令,说的是多发射的事情。
* 比如两个指令没有数据依赖,就可以并行做。instruction level parallelism
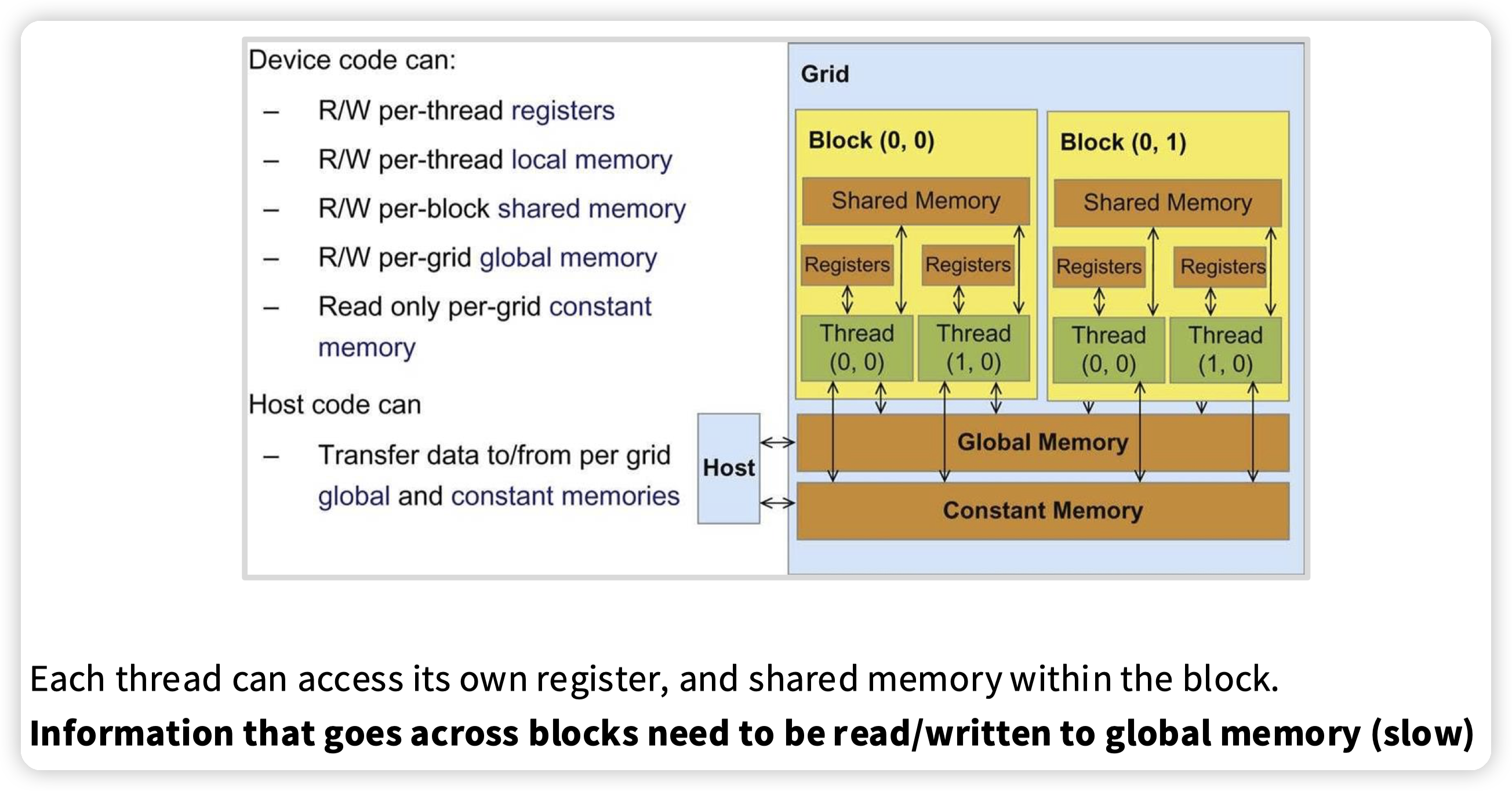
内存模型:
* thread有自己的状态
* 同一个block下可以共享shared memory
* 不同block通过global memory进行同步

访问Global memory比较慢,所以一般是把数据拉到shared memory中来做计算:
* 这也涉及到一个核心的优化点,就是根据shared memory来考虑访存的局部性。比如mat mul,切成小块放到shared memory中来做
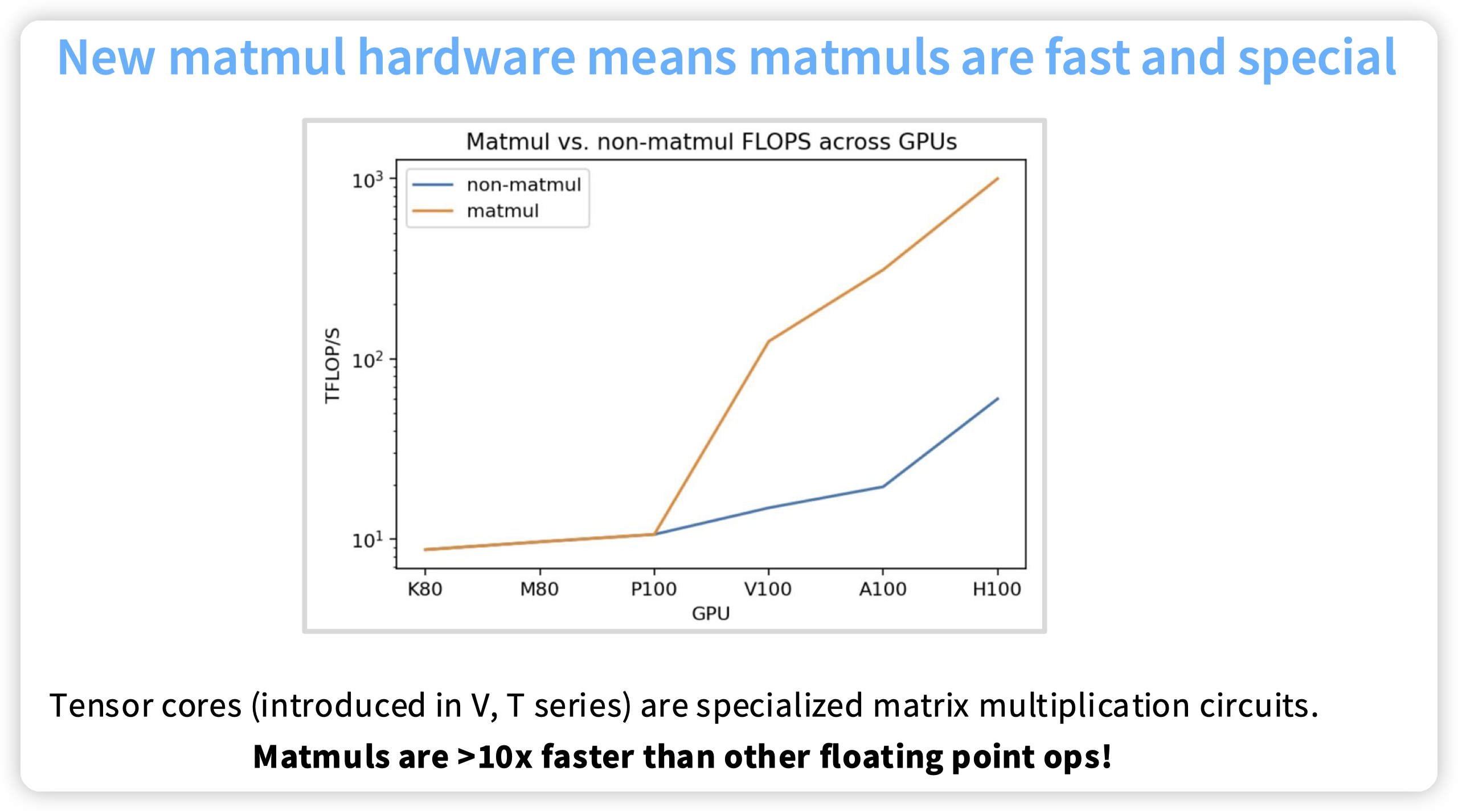
V系列开始,Nvidia引入了tensor core来优化矩阵乘法的速度。V系列也是10年前的东西了,现在淘宝上几百块就可以买一块。不知道10年后H100是不是也是这个价格
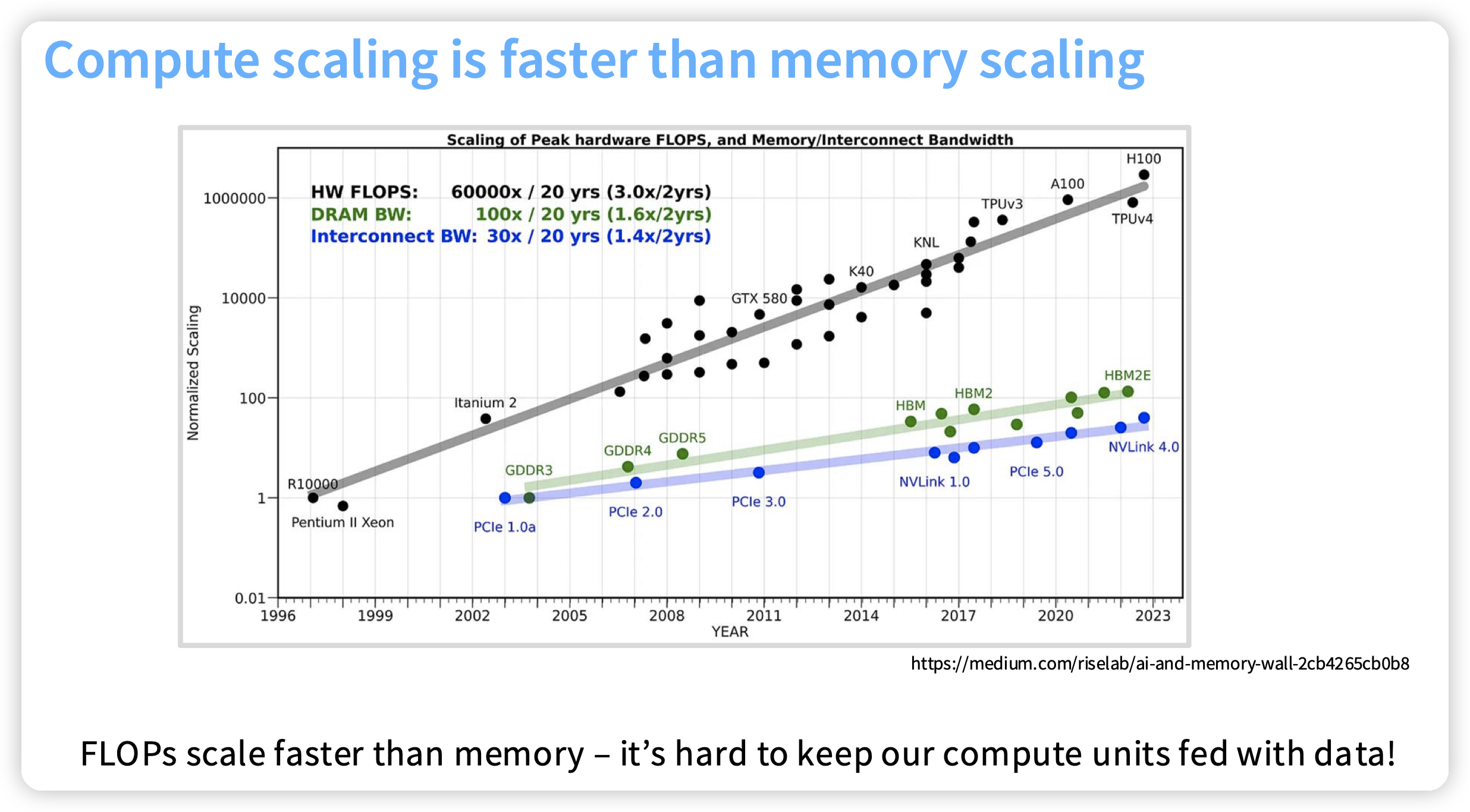
一张指导设计的图:
* FLOPS的增长速度远大于DRAM的带宽,以及互联网络的带宽
* 所以带宽瓶颈更容易出现。设计中偏向于用带宽去trade计算
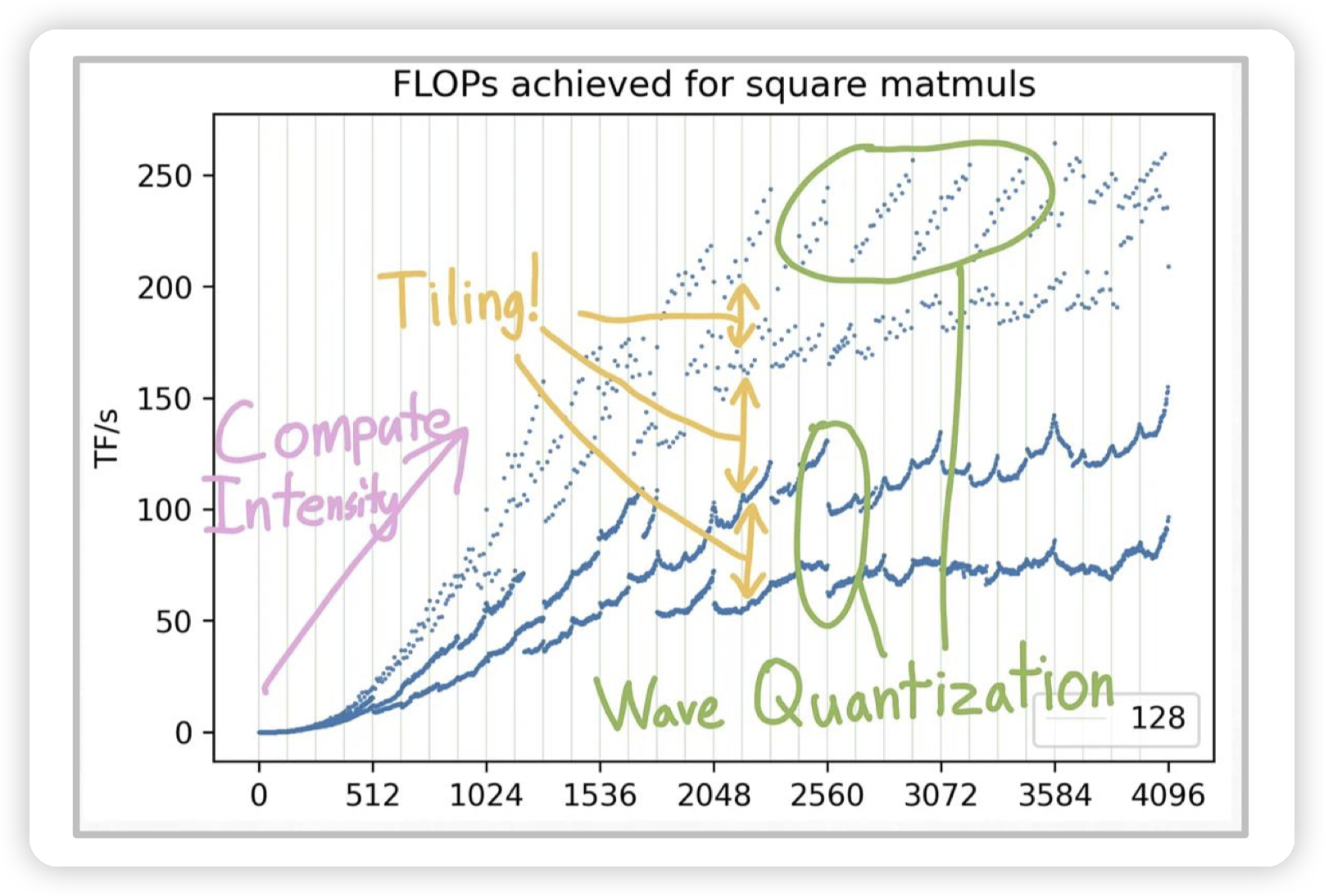
理解GPU性能的一张图:
* 横坐标是矩阵的大小,越大对应的计算强度越高。(因为访存应该是正比于单个矩阵的大小,而计算则是正比于两个矩阵大小相乘)
* 整体是roofline model,左边上升的这一块对应的是memory bound的情况,此时矩阵比较小
* 不同的斜线对应的是不同的memory,比如从DRAM加载,从GPU memory加载,以及从shared memory加载
* 右边则是达到计算强度上限
* 横线不一样是因为tiling,直观理解就是矩阵的大小不是一些整数的时候,会导致需要额外的padding等操作,也无法利用对齐访存带来的优势,无法完全发挥计算能力。
* wave quantization的原因是矩阵大小变动的时候,会导致block的数量有所变化。而图中的硬件A100有108个SM,当使用的block只超过108一点点的时候, 会导致额外等待一些block的执行。
* 所以block数量要么小于SM数量,要么远大于(一般都是远大于)
Optimization
优化memory bound的多种方法
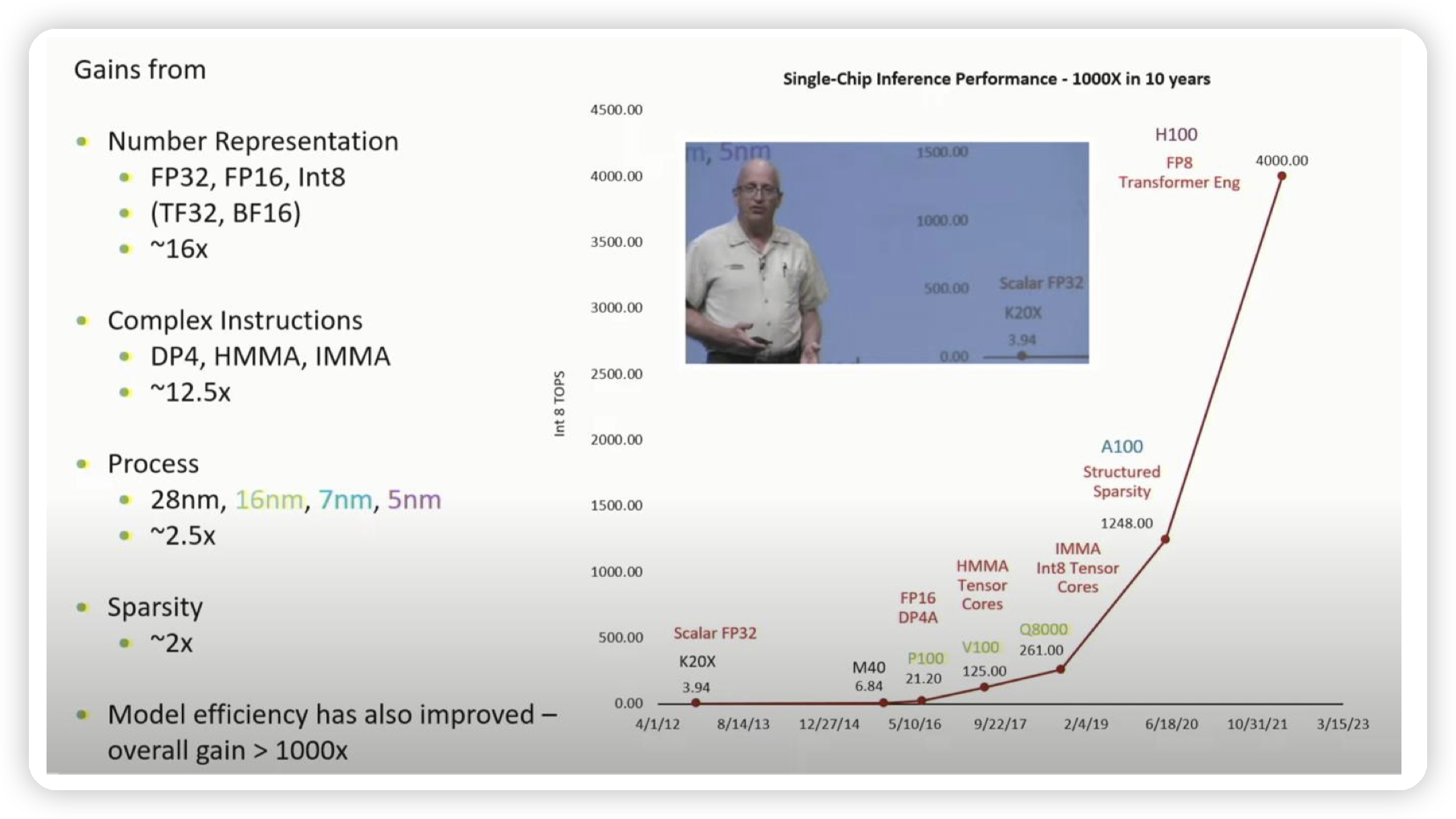
* 可以看到GPU的性能上升很多地方来源于对低精度的支持。
* 低精度不仅可以提高计算速度,更少的空间占用代表可以移动更多的数据,缓解带宽瓶颈问题
* 软件层面上,使用混合精度做训练/推理。
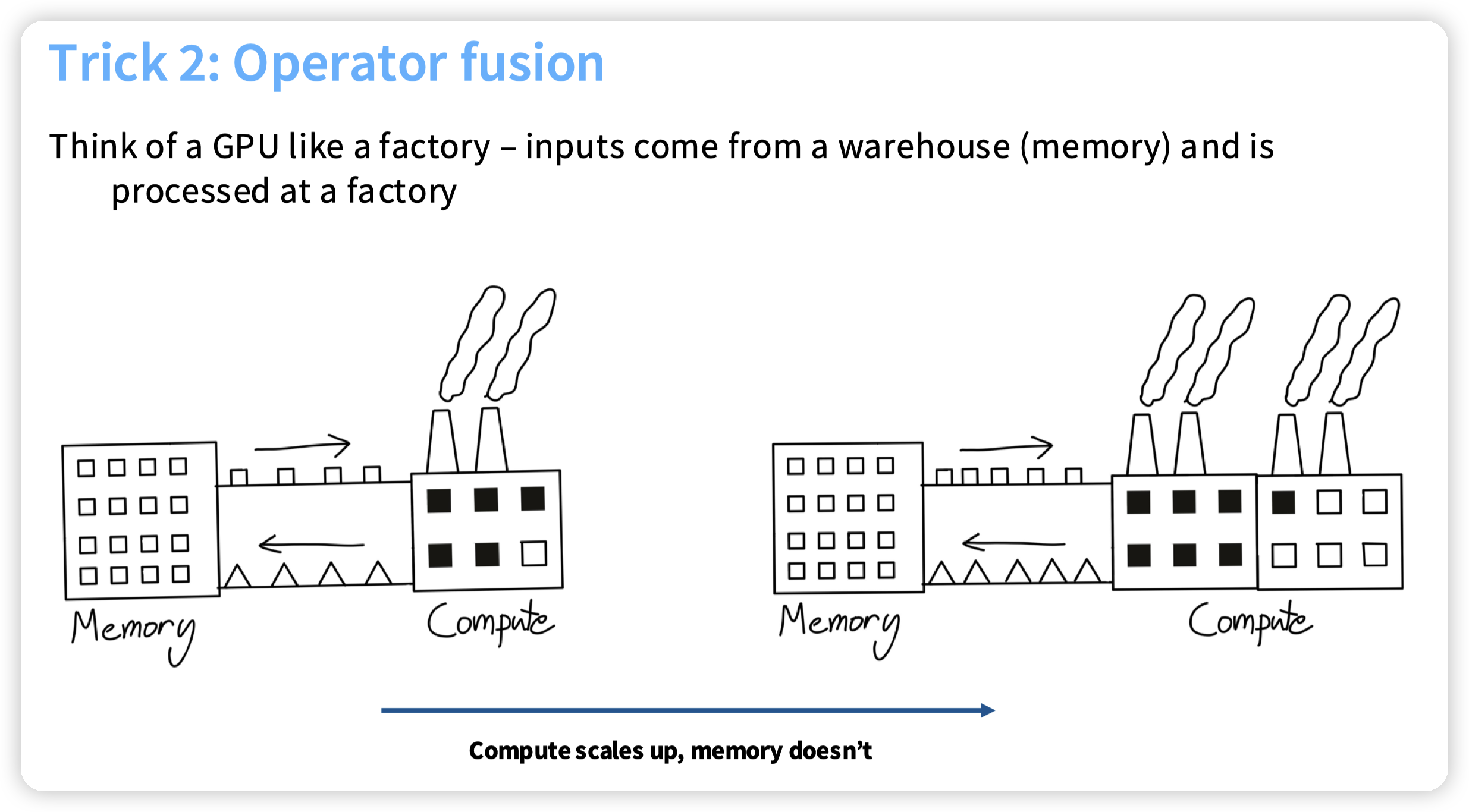
operator fusion,减少从内存到计算单元的移动。
* 这块还有一些额外的,可以减少cuda kernel的调度开销
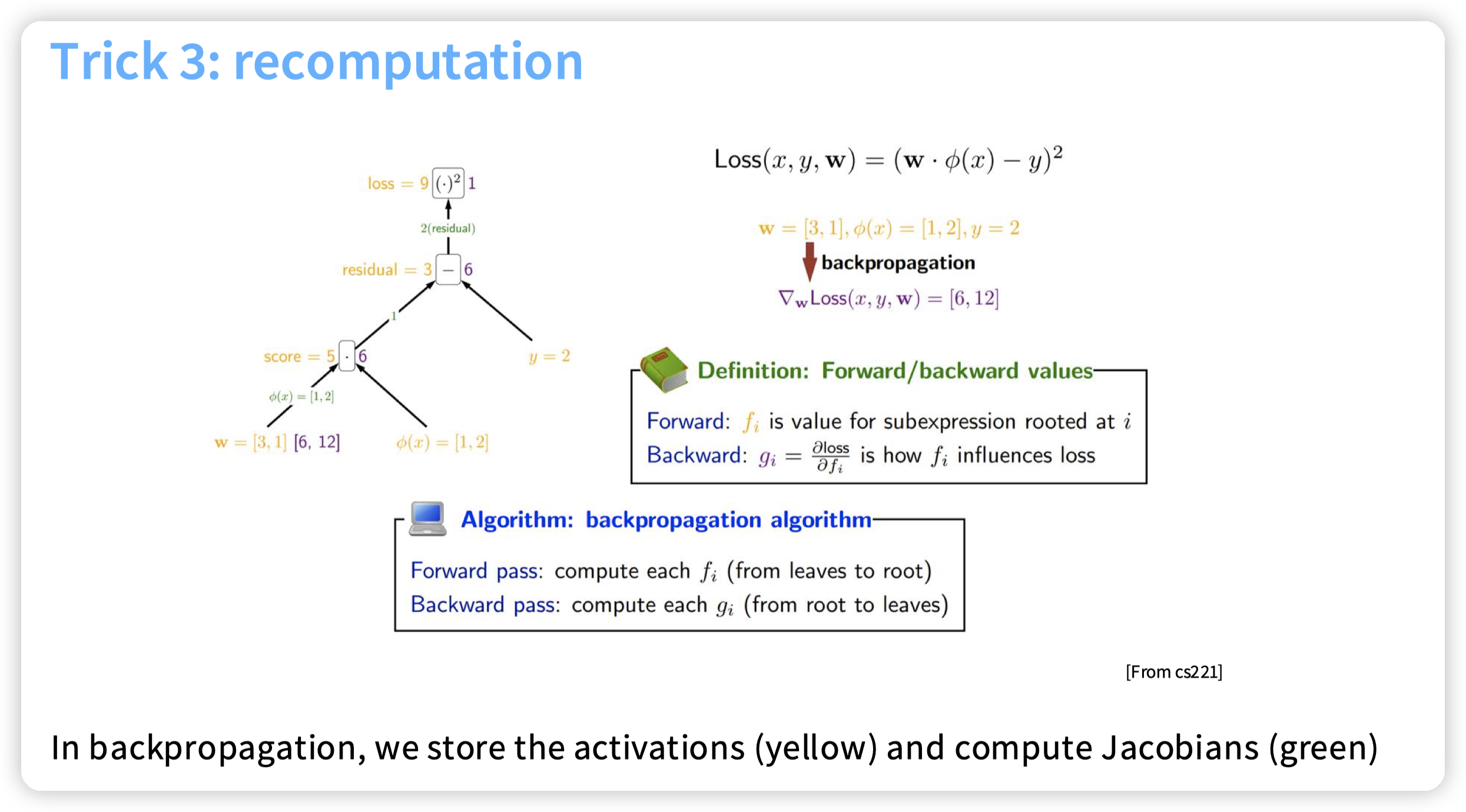
* 和训练的时候不保存activation,重新算activation的思路类似。
* 一个是为了减少对内存的访问
* 另一个则是减少对内存的占用(也可以转移到保存磁盘/DRAM中,然后减少对这些存储的访问)
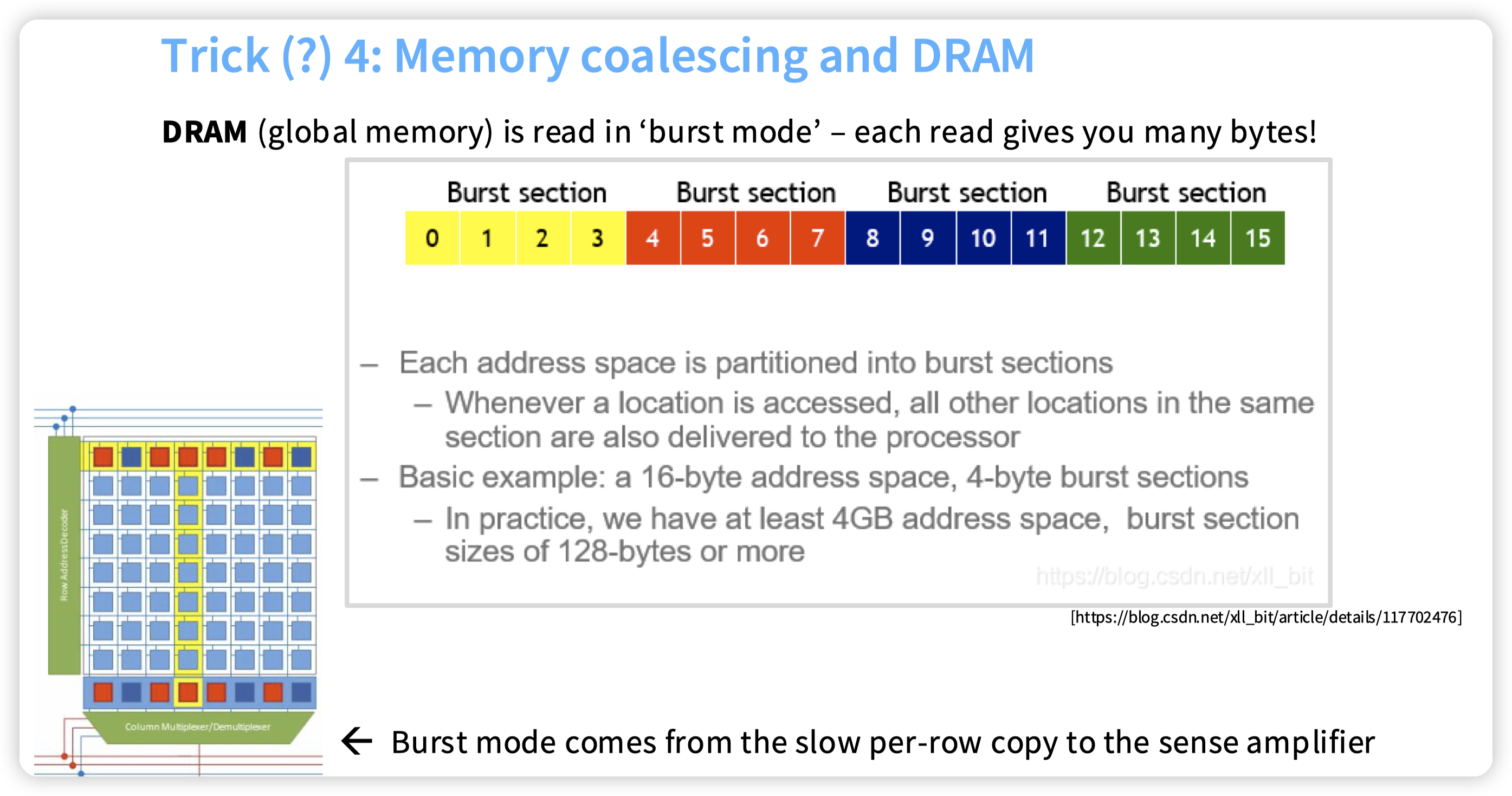
* GPU访存是批量的,利用这个性质来提高带宽利用率。
* 这块和DRAM/SSD这些应该都是类似的,避免寻址开销过大,一次都会激活一批的存储单元。
* CPU上一般也都有考虑,不过不太受到人关注的原因我估计是因为CPU的缓存比较大。线程数也不多,所以不会把缓存冲烂。
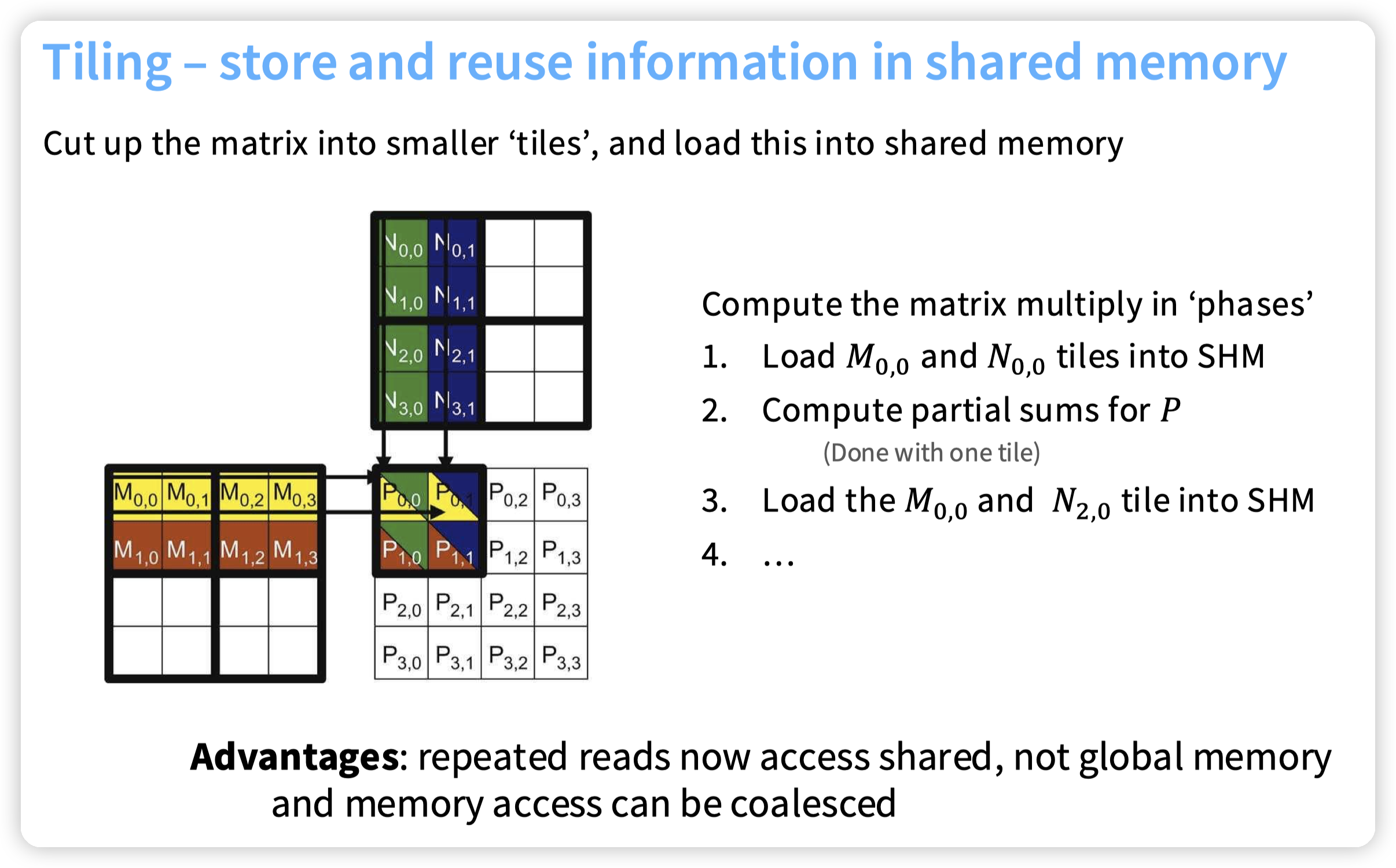
* tiling,这个比较常见。上面也提了是为了减少对global memory的访问,切块后把数据拉到shared memory中。
* 和一些其他系统设计是类似的,只不过区别是从disk/DRAM转移到了GPU DRAM和DRAM而已。
* 最直观的类比就是数据库系统中,一些chunked join
CUDA
这块我再从15418上补充一些cuda的概念,和一些执行的细节。

* 代码上,可以通过shared/global来访问shared memory和global memory。不特殊声明就是thread级别的。
* 支持block内的thread synchronization
* 支持atomic operations

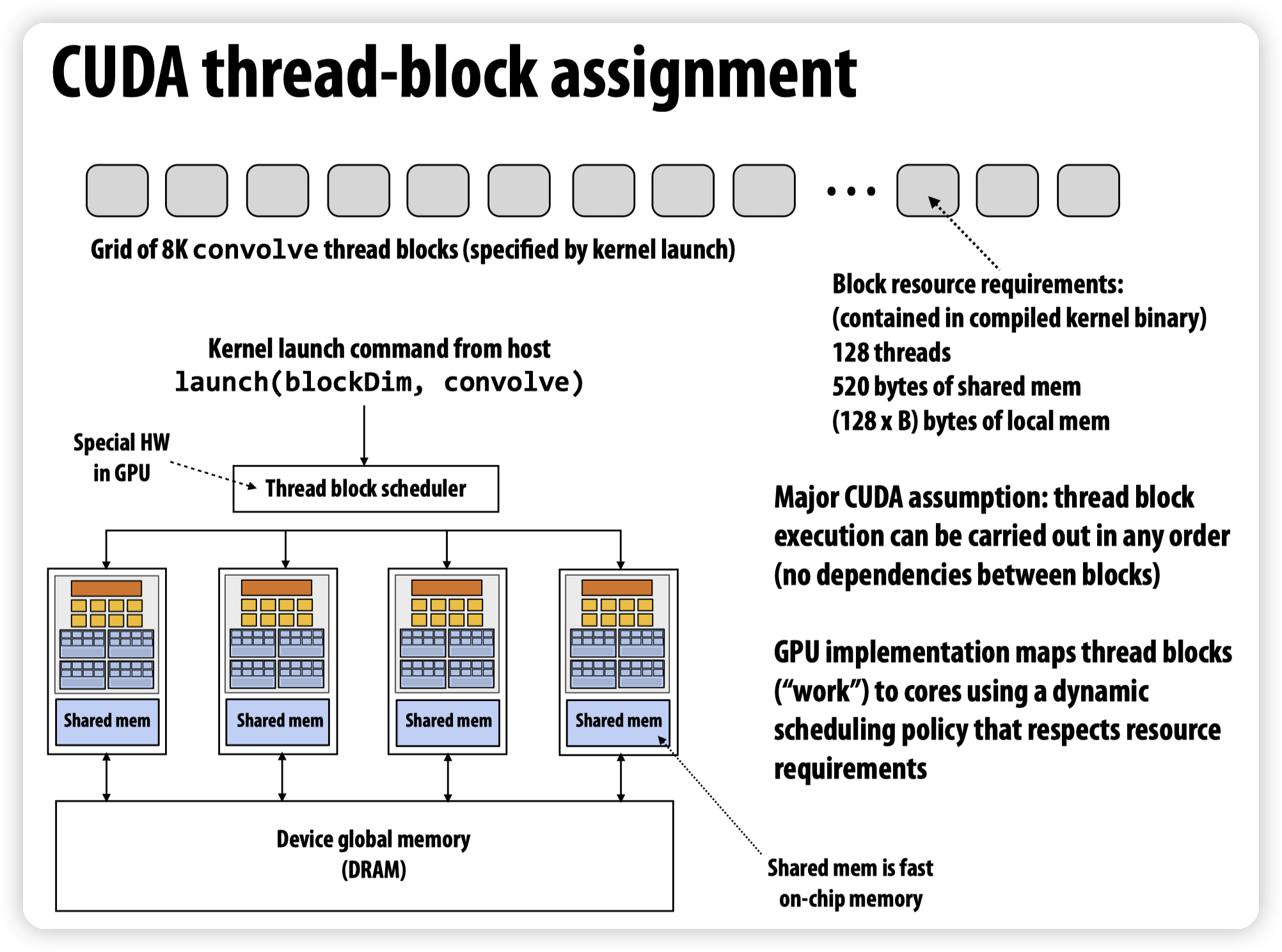
* cuda代码编译好后,会携带着block的线程数,需要的shared mem/local mem发送给scheduler。
* scheduler会动态的把block分发给SM
Profile
主要是用来profile的工具
https://pytorch.org/tutorials/recipes/recipes/profiler_recipe.html
https://docs.pytorch.org/tutorials/recipes/recipes/benchmark.html
Nsight profiler
课上还给了一些手写cuda,以及写triton的例子。
https://openai.com/index/triton/
triton可以让我们在python里写类似cuda的代码,可以帮助编译成low-level的代码发送给GPU。assignment2里会有涉及,这里就不细说了

还有一坨Further reading有空再看看。

文章评论