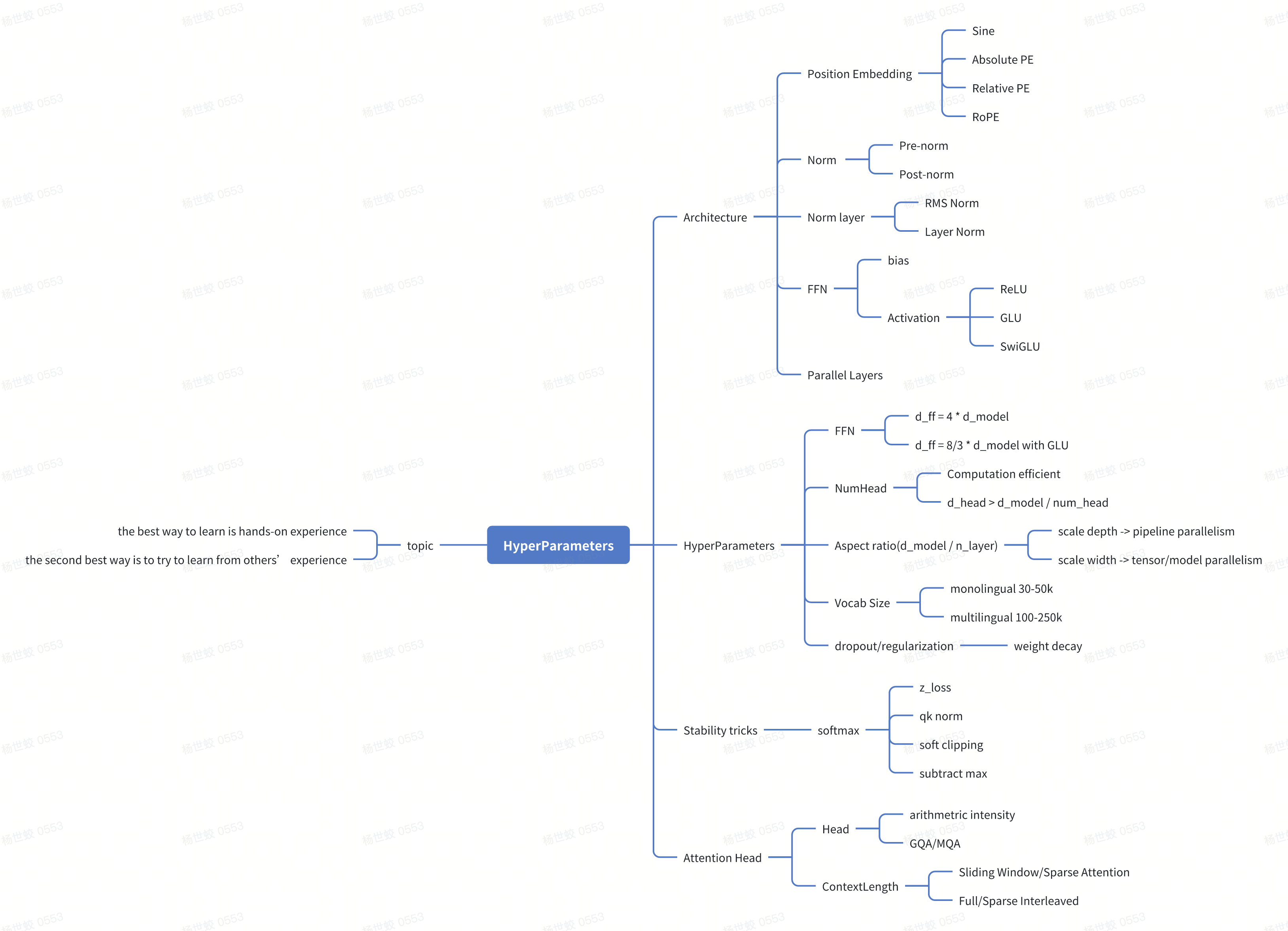
内容比较多,所以搞了一个mindmap:
第三课涉及了很多模型相关的知识,从基础的transformer出发,讲解了这些比较前沿的模型在上面的改动,以及为什么要这样改。所以这里需要有一个基础就是先学习过transformer
主题:
* the best way to learn is hands-on experience
* the second best way is to try to learn from others’ experience
DL这块变得更加需要经验,所以实操才是关键。
还有一个需要考虑的是,如果自己实践不了,那么从其他人哪里学习经验,也就是说其他人的paper中,实验的部分比较关键,而非思想。这块感觉和看一些系统的论文差距还是比较大的
第一块是模型结构相关的设计
Architecture
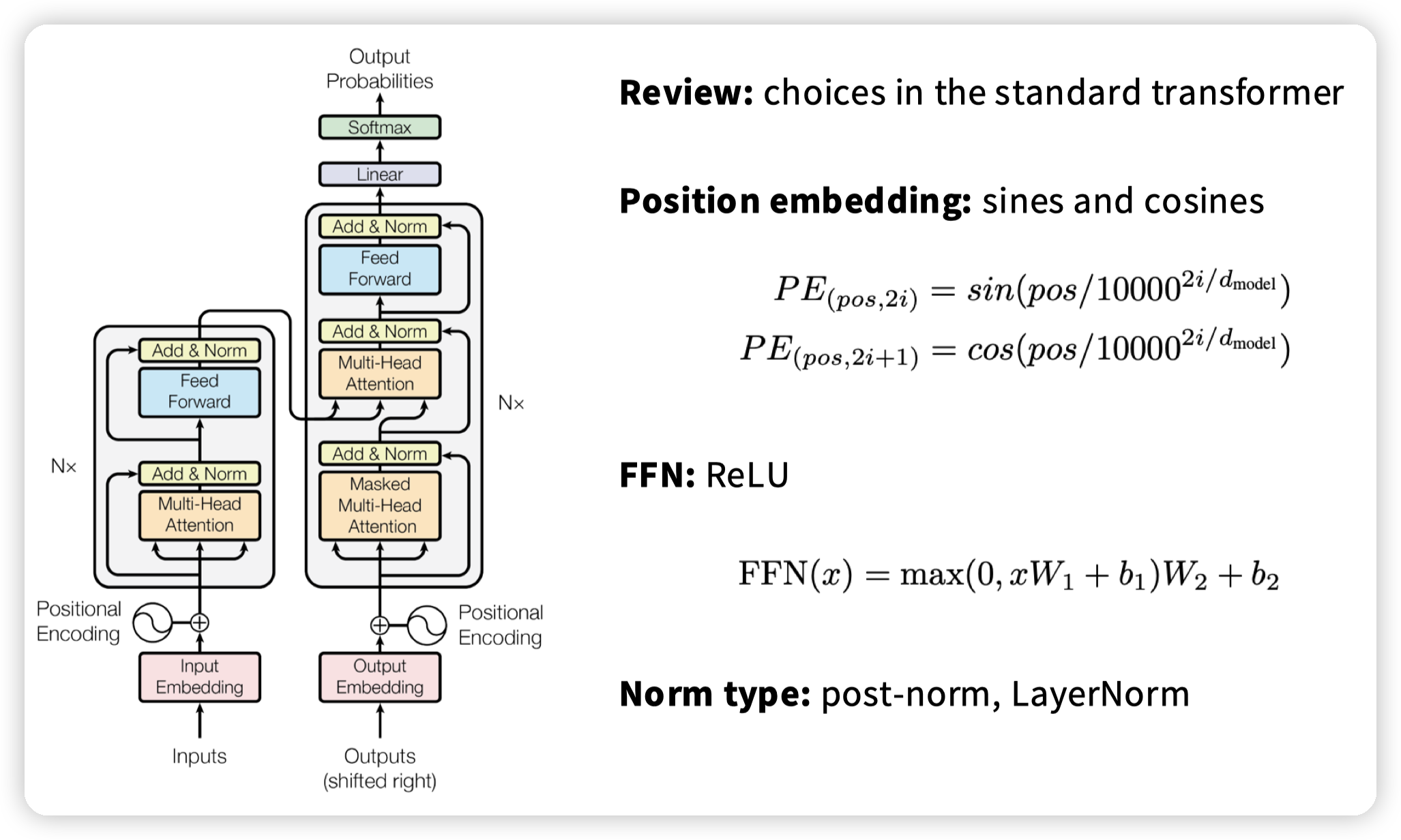
原始的transformer:
* Position Embedding用的是三角函数
* FFN用的是ReLU做激活,有bias
* norm的位置和方式分别是post-norm,以及LayerNorm
assignment中实现的是:
* RoPE
* SwiGLU,无bias
* Pre norm, RMSNorm
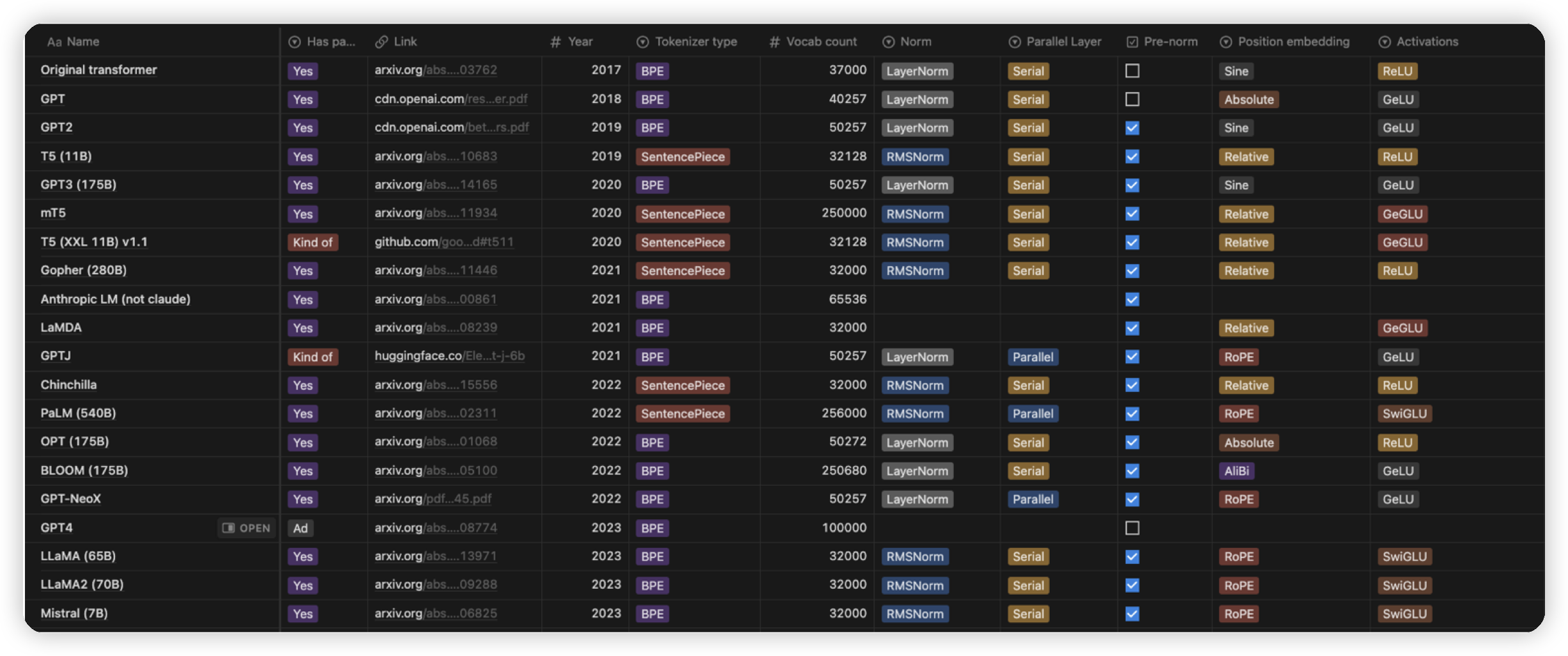
这块区分点除了参数量,在模型架构上主要看:
* Norm的方式,LayerNorm/RMSNorm
* Norm的位置,post-norm/pre-norm
* PositionEmbedding:目前主流使用的是RoPE
* FFN: 各种不同的激活函数,ReLU -> GLU系列 -> SwiGLU
还有一些影响不那么大的,比如是否做并行,主要考虑资源
Norm
有一个比较知名的论文:On Layer Normalization in the Transformer Architecture
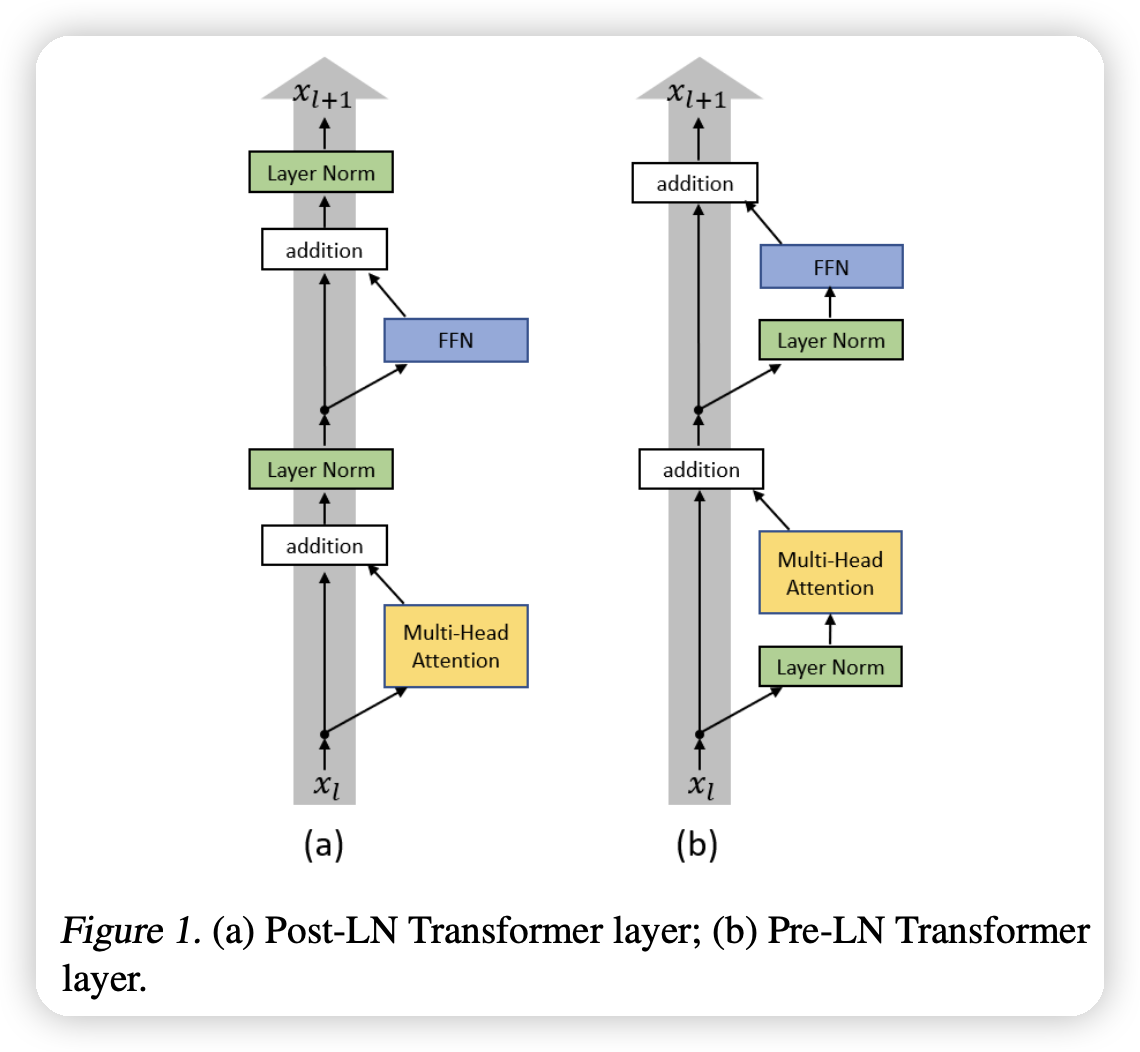
从图上直观看的话,之所以要做Pre norm是因为它没有堵在残差网络的主链路上,可以避免LN影响梯度的传播。
需要强调的是,LN本身的设计和这里的影响没有关联,LN的目的是为了解决数据输入分布偏移的问题(从而影响训练的稳定性)。
而这里的重点在于LN的位置,随着网络的加深,LN的放缩可能会导致梯度传播的问题,从而影响训练。
从实验上也可以看到,pre norm效果普遍更好一下,所以现在大家基本都选择pre norm

从图上可以看到pre-norm的梯度比较平缓,并且尖刺相对少一些,gradient也小一些。所以训练可以更加稳定。
这里是相关的paper:Transformers without Tears: Improving the Normalization of Self-Attention
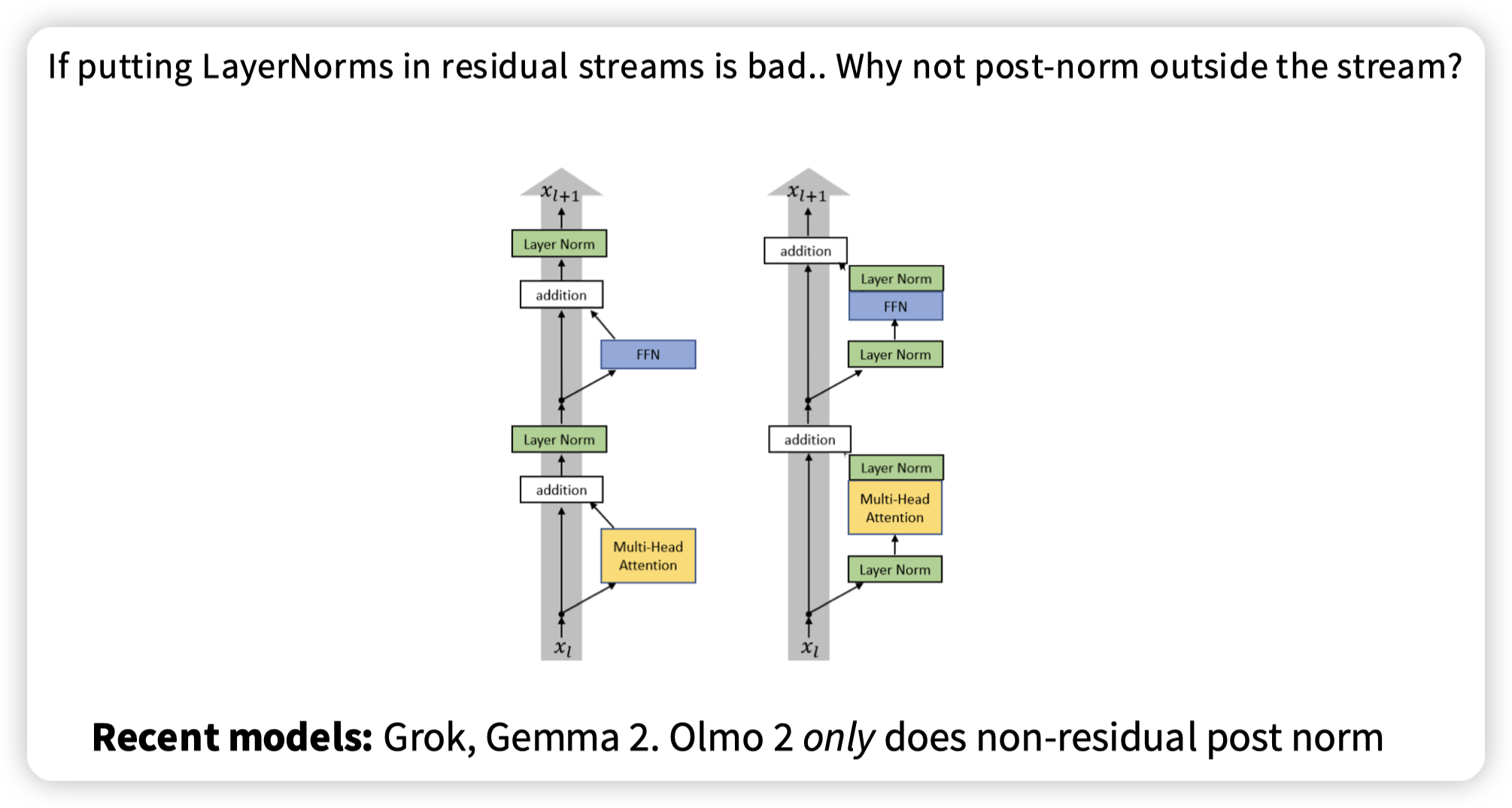
还有一个变体就是既然放到主链路上影响梯度,那可以post norm放到分支上。这里Grok/Gemma2用了前后两个norm。
* 个人主观的想法就是,放到FFN/Attention之后,到下一层也还是有一个norm,中间只是多了一个加法,并没有额外的参数需要学习,如果需要调整分布避免偏移的话,到下一层输入之前再调就好。所以感觉用处并不大,还会引入额外的计算量。
然后下一块是Norm的方式,有两个主流的:

RMSNorm主要是根据向量的长度做的归一化,没有考虑分布的中心。
为什么选择RMSNorm?
* 效果没有变差
* 更少的计算量,不需要计算方差以及均值
* 更少的参数,没有mean了
这里计算量可以展开说一下,有一篇相关的paper(Data Movement Is All You Need: A Case Study on Optimizing Transformers):
* 虽然layer norm占用的flops很低,但是在runtime中占比比较高
* GPT老师解释了一下,layer norm涉及的操作比较复杂,并且有两次reduce,RMSNorm只有一次。reduce操作涉及到GPU上wrap之间通信,开销会比较大。
* 还有一块说layer norm会涉及到多个cuda kernel调度开销也会大一些。而RMSNorm简单,只有一个cuda kernel。这块涉及到cuda的知识,等后面再看看
核心点就是免费的性能提升,大家自然就都选了。

一个相似的观点,目前的LM的FFN中都没有bias,一个原因是表现足够好了,并且可以提升效率。还有一个原因是研究发现去掉bias后会提升训练的稳定性。(不确定是为什么,可能就是少一些参数?)
* 从这里也可以看到实验的结果比较关键,实验结果solid大家也都会跟进的。

一个我感觉比较关键的observation:
* 保证residual stream的传播,提高稳定性
* 观察每一层的梯度来尝试解决训练稳定性的问题。
Activation
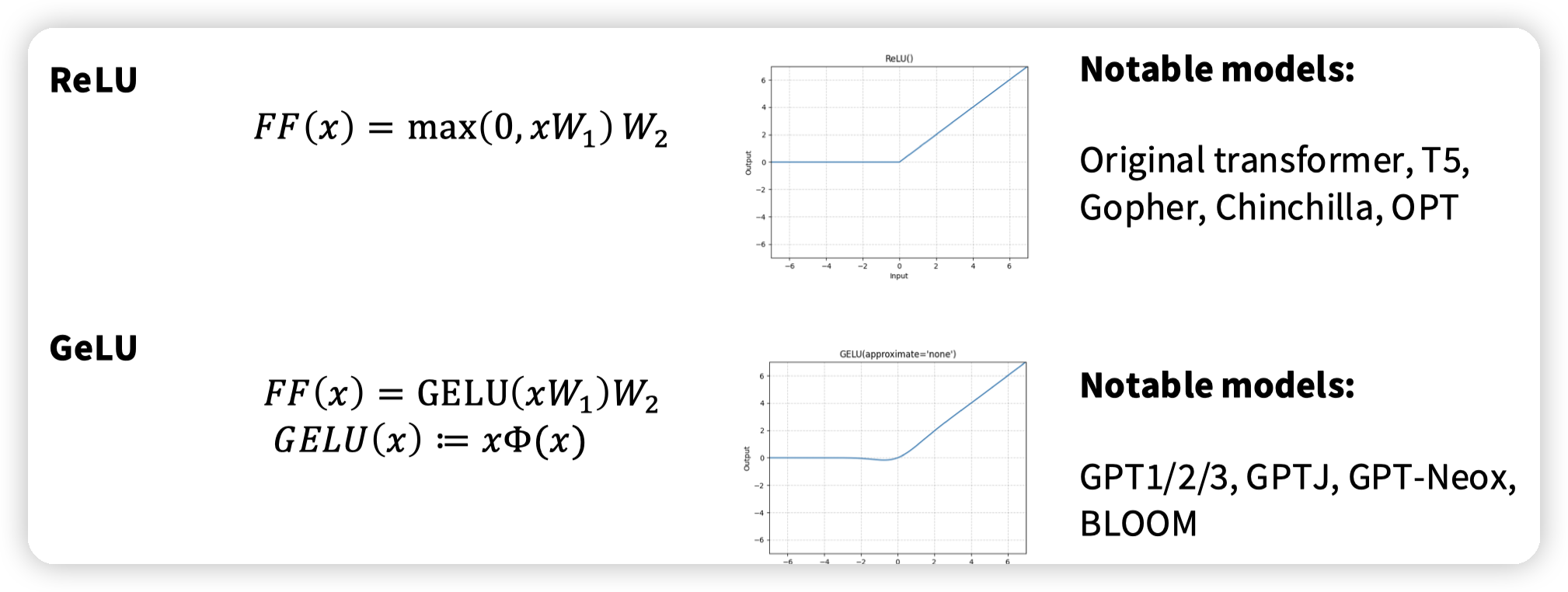
GELU(x)=x⋅P(X≤x)
GeLU是用概率保留,而非ReLU这样硬截断。x值越大,保留的概率就越大。其中X是(0, 1)正态分布。核心目的还是希望激活函数平滑。
* ReLU还有一个问题就是x < 0的时候梯度为0,如果有一个地方的输出始终是小于0的,那么这块的输出就永远不会改变,因为梯度一直是0不会更新。


GLU的思想就是像LSTM一样使用门控来控制信息流动,论文在这里:Language Modeling with Gated Convolutional Networks
然后这里的SwiGLU我也研究不太明白,实验效果好就完事了。然后了解到有这个趋势,从ReLU升级到GLU即可
这里有一篇论文有对这些激活函数有系统的研究:Do Transformer Modifications Transfer Across Implementations and Applications?
GLU相关paper:GLU Variants Improve Transformer
Parallel layers

并行计算MLP和attention。在小模型上有一点点效果下降,不过看起来现在大多数的模型没有选择parallel layer
Position Embedding

几种常见的position embedding的方式:
- Sine Embedding
- 把position embedding加到token embedding中
- 相对位置可以通过
PE(A) * PE(B) = cos(p - q)来建模 - 无法学习
- Absolute embedding
- 加一个可学习的position embedding,自行学习位置关系
- 不容易外推,遇到没见过的关系就不行了
- Relative embedding
- 在attention计算的时候,显式的加一个代表ij相对位置关系的可学习向量,也是自行学习
- 更显式的建模相对关系,因为LM主要关注的还是相对位置关系
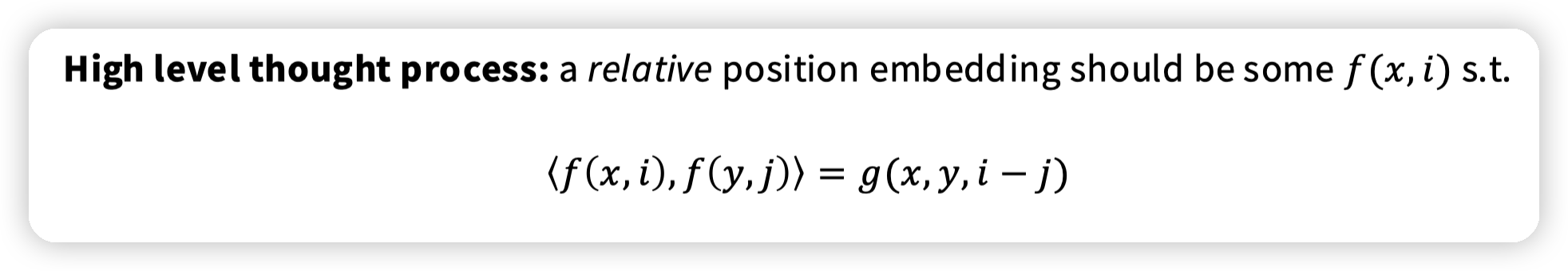
现在常见的RoPE的设计起点,希望position embedding有这样的性质。
* 如果 token i 和 j 的相对距离相同(比如都相隔 2 个词),那么注意力分数应该相同;
* 上面提到的PE方法都做不到
* 模型对序列的平移(shift)是不敏感的。
RoPE利用了旋转的性质,把每一个词向量在向量空间中根据位置旋转一定的角度,保证他们的inner product只依赖相对位置差
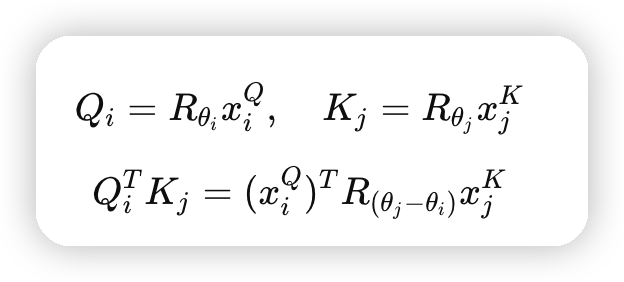
* 这块还有一些细节,是高维向量的旋转的选择是很多的,可以向任意方向进行旋转,那么旋转的时候我们应该向哪里旋转也是一个问题。这块感兴趣可以再去看原始的Paper
* 注意这里的PE不是加到token embedding中,而是在每一个attention层之前加上的。这个设计可以保证相对位置相同的token,attention score完全一样。
Hyperparameters
FFN
ffn的地方有一个先升维,再降维的操作。一般来说d_ff = 4 * d_model
加上了GLU之后,因为从两个矩阵变成三个了,为了维持flops不变,维度也有所改变。
之前的计算量是 2 * 2 * d_ff * d_model * batch_size
现在变成了3 * xxx,所以需要把d_ff变成原来的2/3,也就是dff = 8/3 * d_model
为什么有这个值?实验出真知:
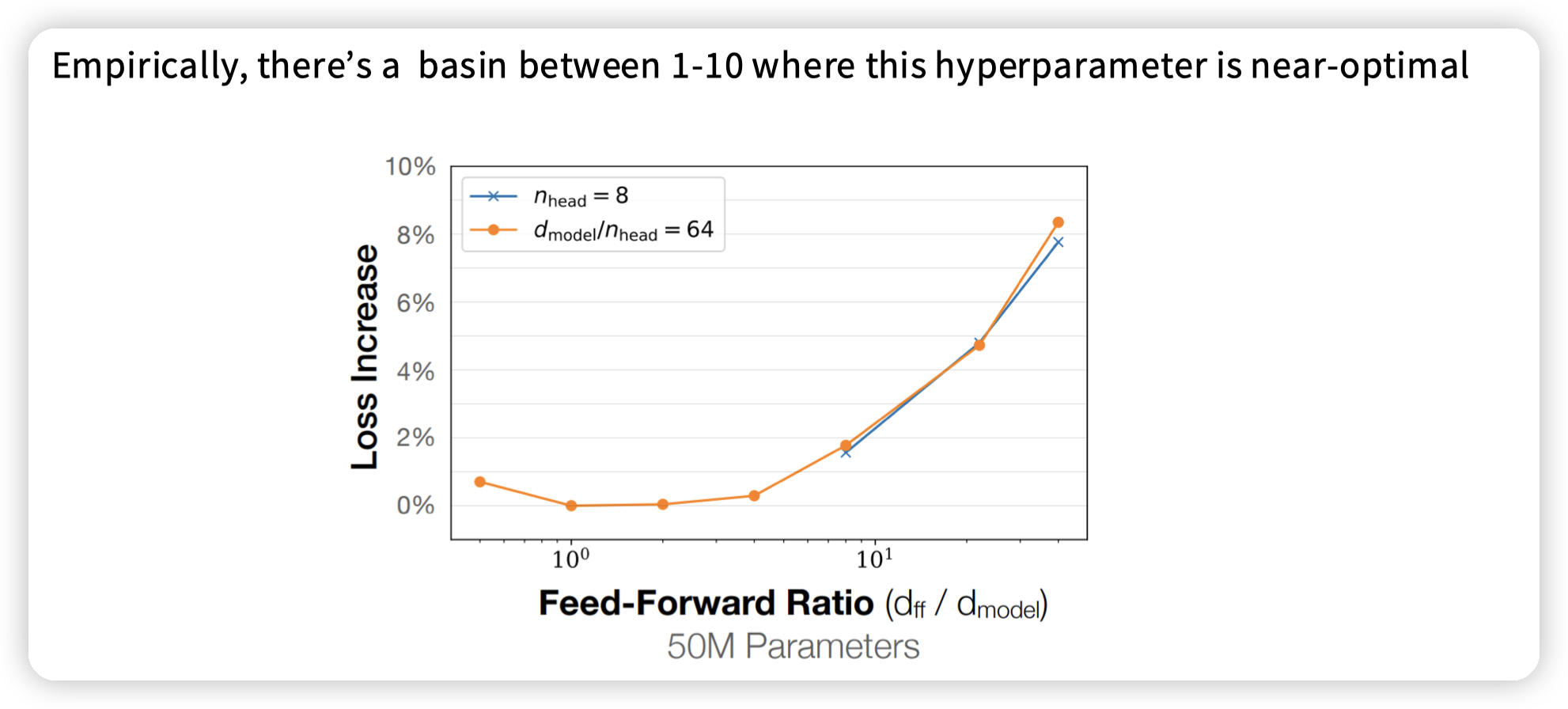
NumHead

虽然head不太影响计算效率,但是head一般不会太多。
* 这里有一个transpose,会导致计算attention的时候矩阵不连续,其实还是会影响效率的,问了下GPT说有一些cuda kernel,以及做一些fusion可以缓解这个问题。
## Aspect ratio
宽高比,说的是d_model / n_layer
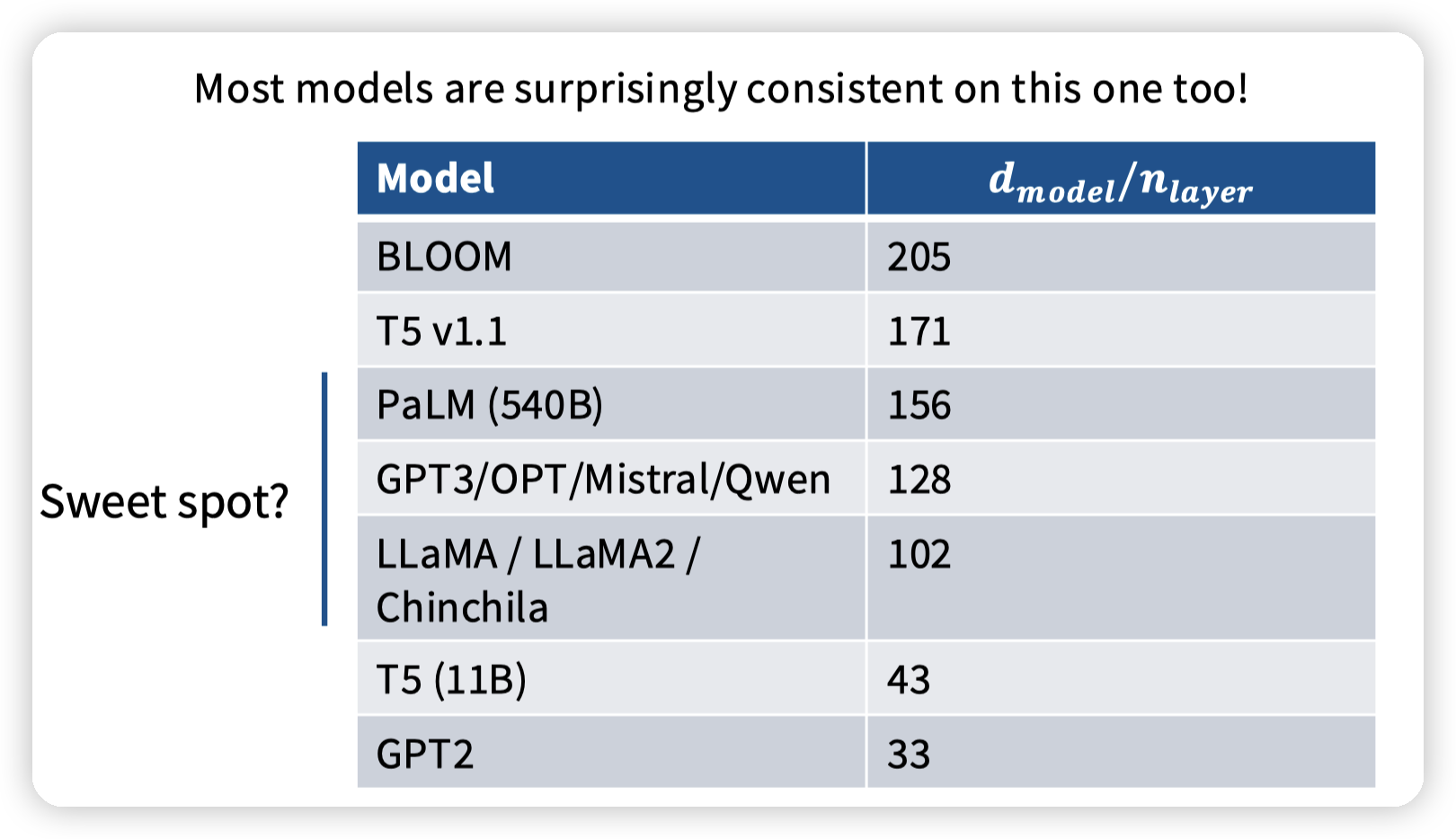
堆layer的时候,对应的d_model也需要上涨。
从计算角度来说,scale深度可以做pipeline parallelism,scale宽度可以做model parallelism
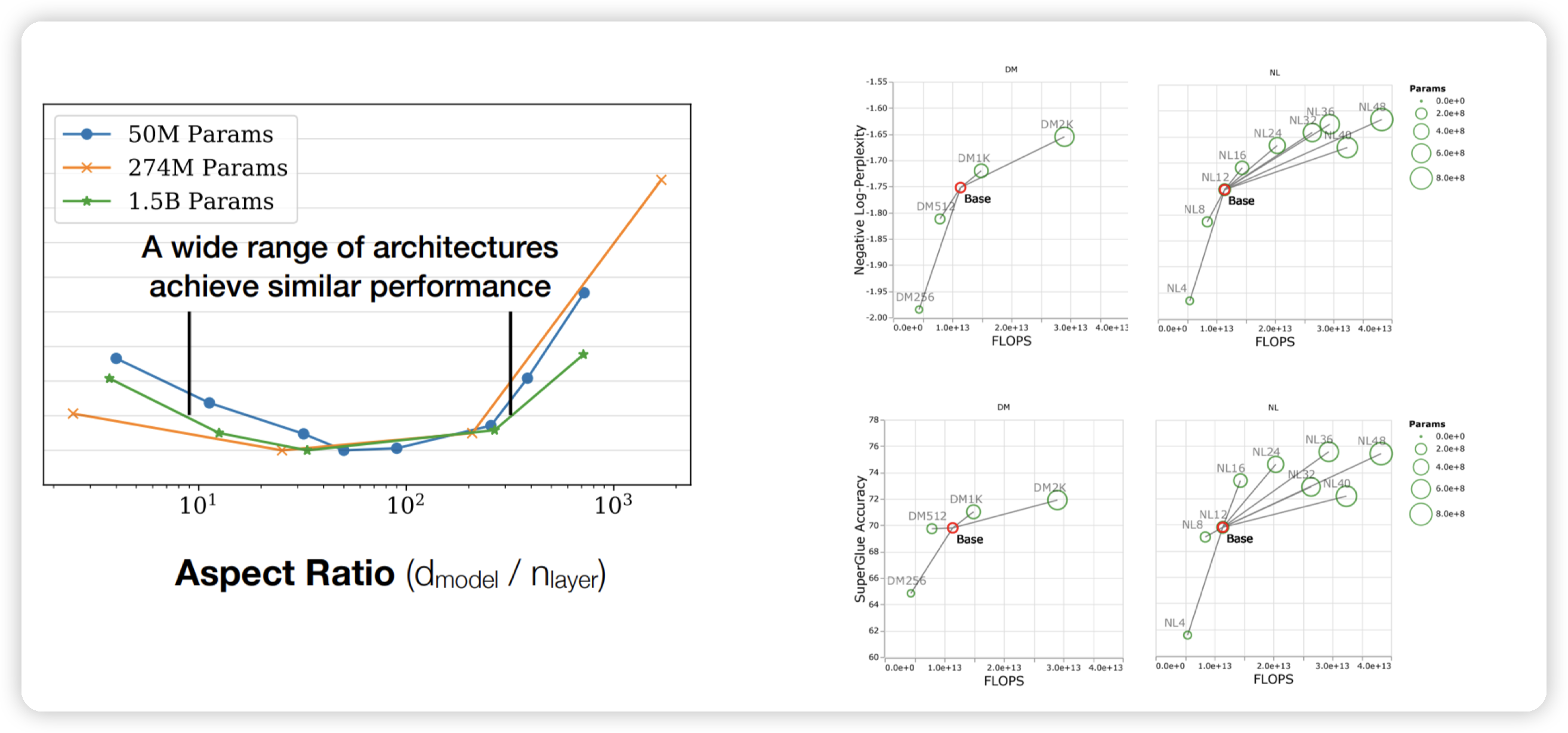
大多数的模型也有相似的aspect ratio,也是实践出真知
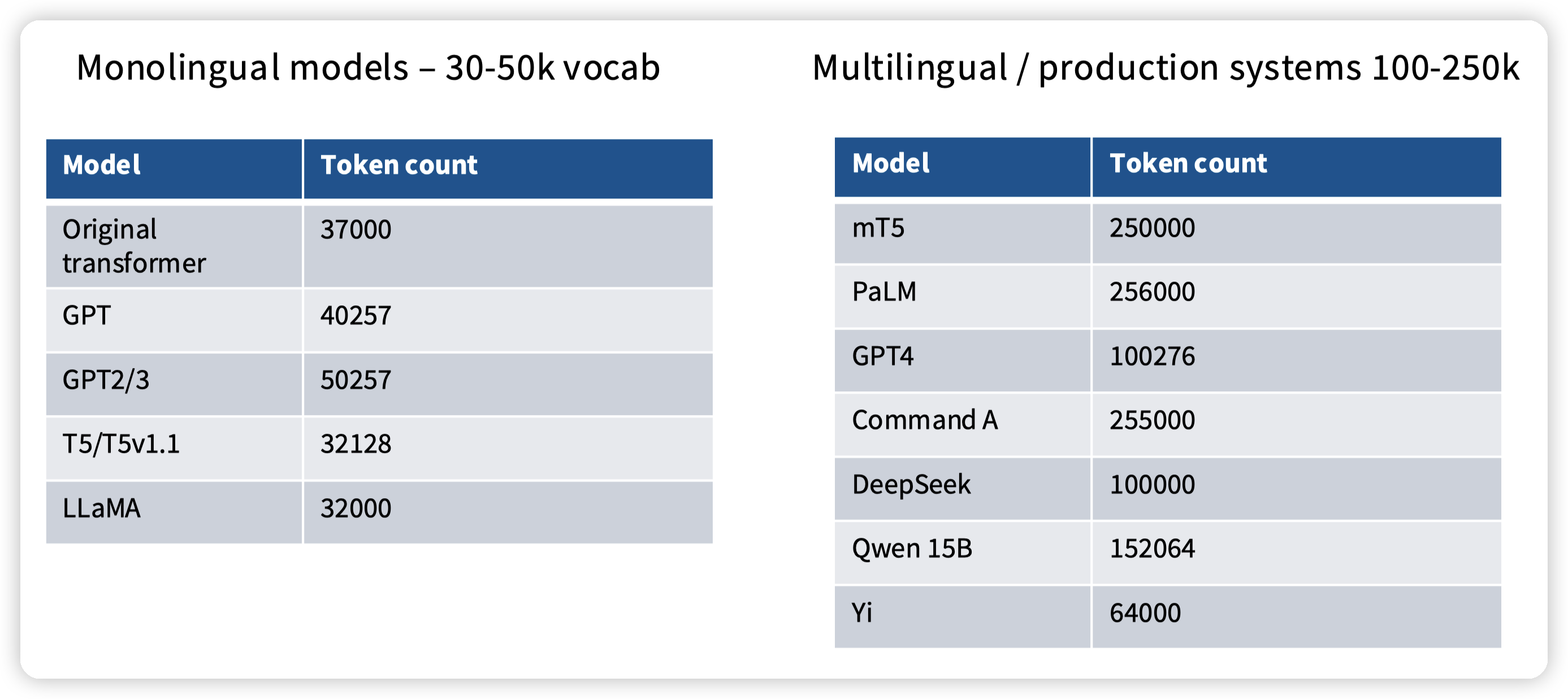
Vocab size
主要看语种,一般monolingual就少一些
Dropout and other regularization
一些正则化的手段,主要是为了避免过拟合的,但是现在LLM的训练基本都是跑一个或者不到一个epoch,没有过拟合的机会
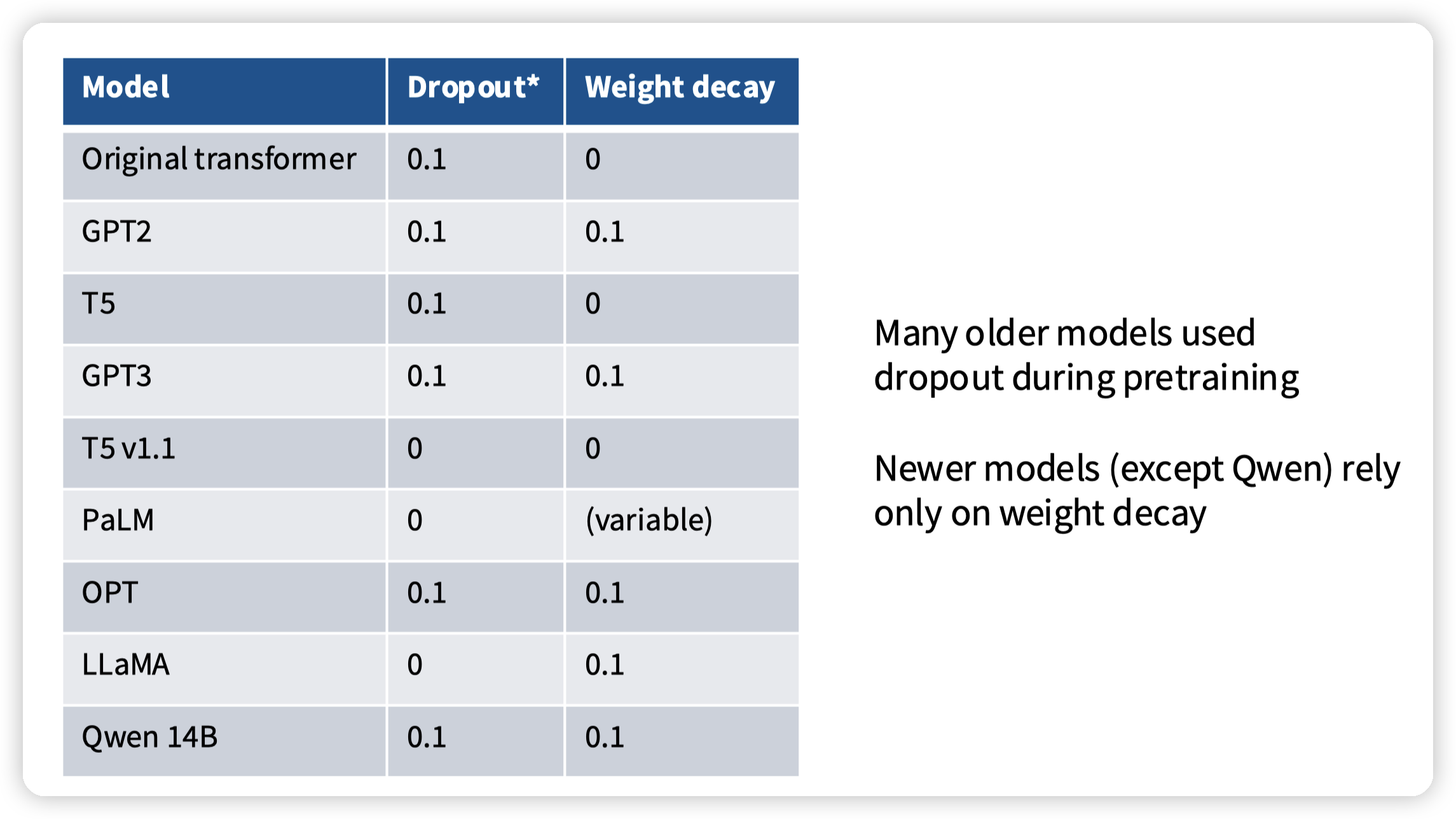
新的模型现在趋向于不做drop out,只做weight decay,理由也不是过拟合,而是weight decay在配合lr schedule的时候可以进一步降低training loss
这里有一篇相关的paper:Why Do We Need Weight Decay in Modern Deep Learning?
Stability tricks
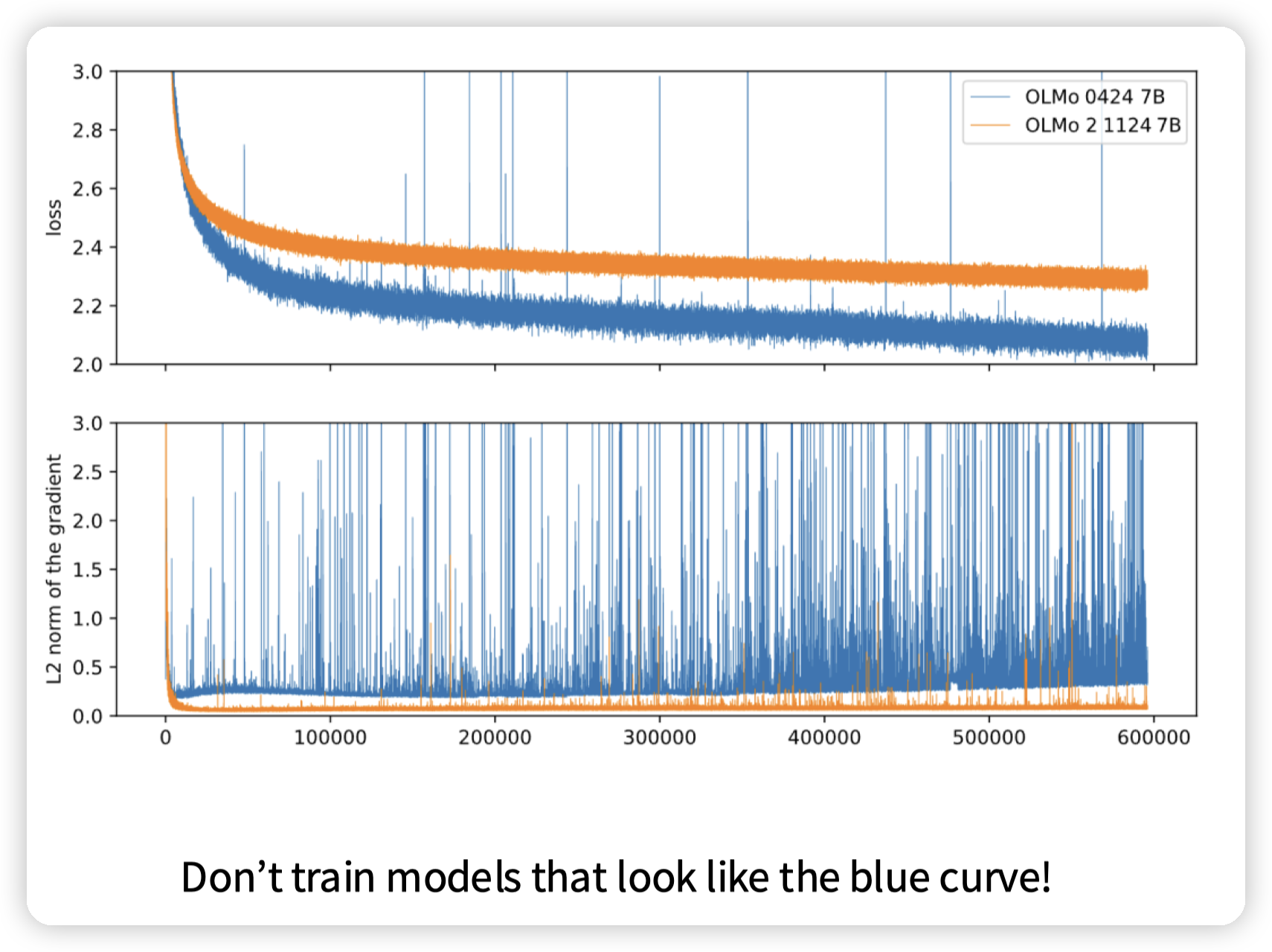
虽然蓝色的线loss更低,但是gradient抖动的很厉害,看起来非常不稳定
softmax
softmax有指数项参与计算。
assginment中要求实现的softmax就让减去了最大值,把最大值控制在0,避免指数项过大。

- 这里还有一个z loss的方式,通过让Z loss逼近0,来用log把原本的指数项给抵消掉。
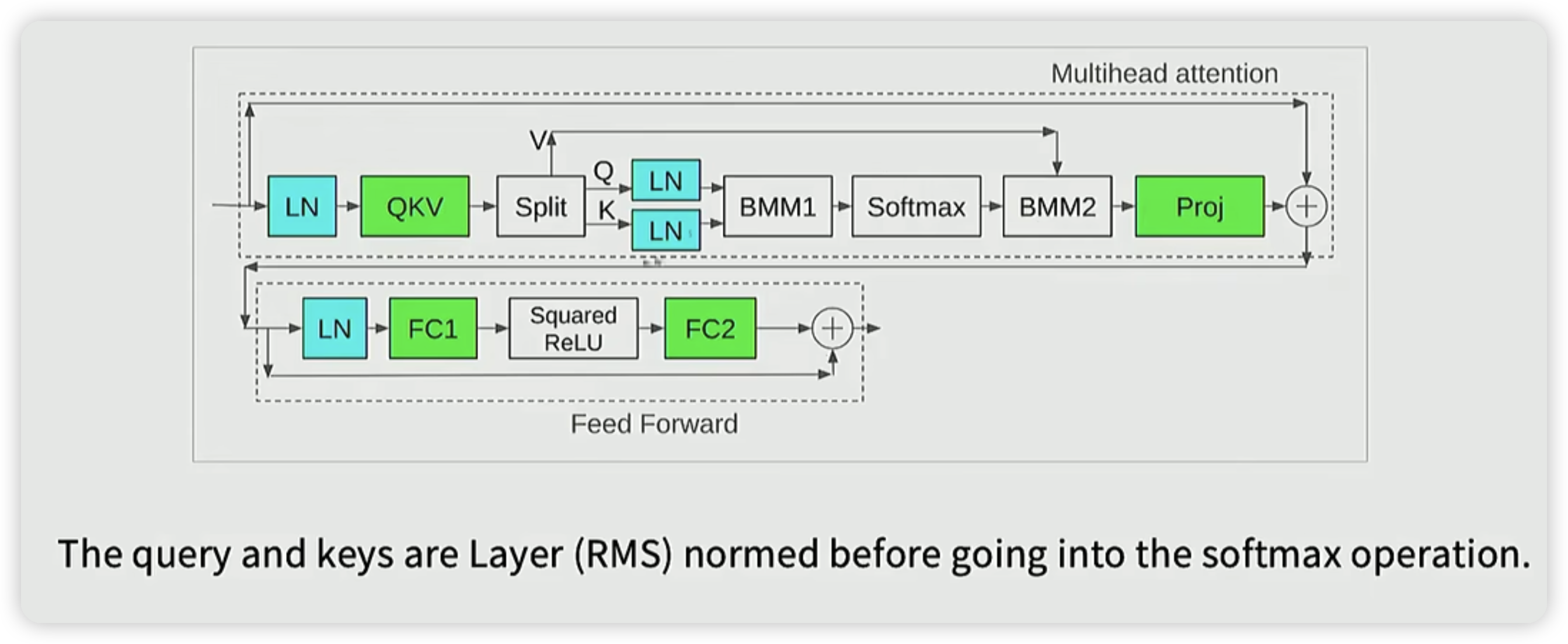
在attention层还有一个softmax,通过在QK后面引入norm,控制QK的范围,从而控制softmax的输入
教授在这里也提了一个笑话,发现layer norm在提升稳定性的方面做的很不错,所以就持续增加layer norm。
* 间接的也可以看出来,数据分布,以及数据的范围对模型训练的效果的影响。

还有一种手段,soft cap,软截断的感觉(soft clipping),控制logits的范围,避免输入给softmax过大的值
(课上还提到一个细节,QK norm引入后,可以允许更大的学习率,从而可以更好的推动optimizer,降低loss。这块有两个问题,为什么QK norm可以允许更大的学习率,为什么更大的学习率可以推动optimizer)
Attention Head
主要讲在attention上的优化,优化计算效率,提高context window等
GQA / MQA
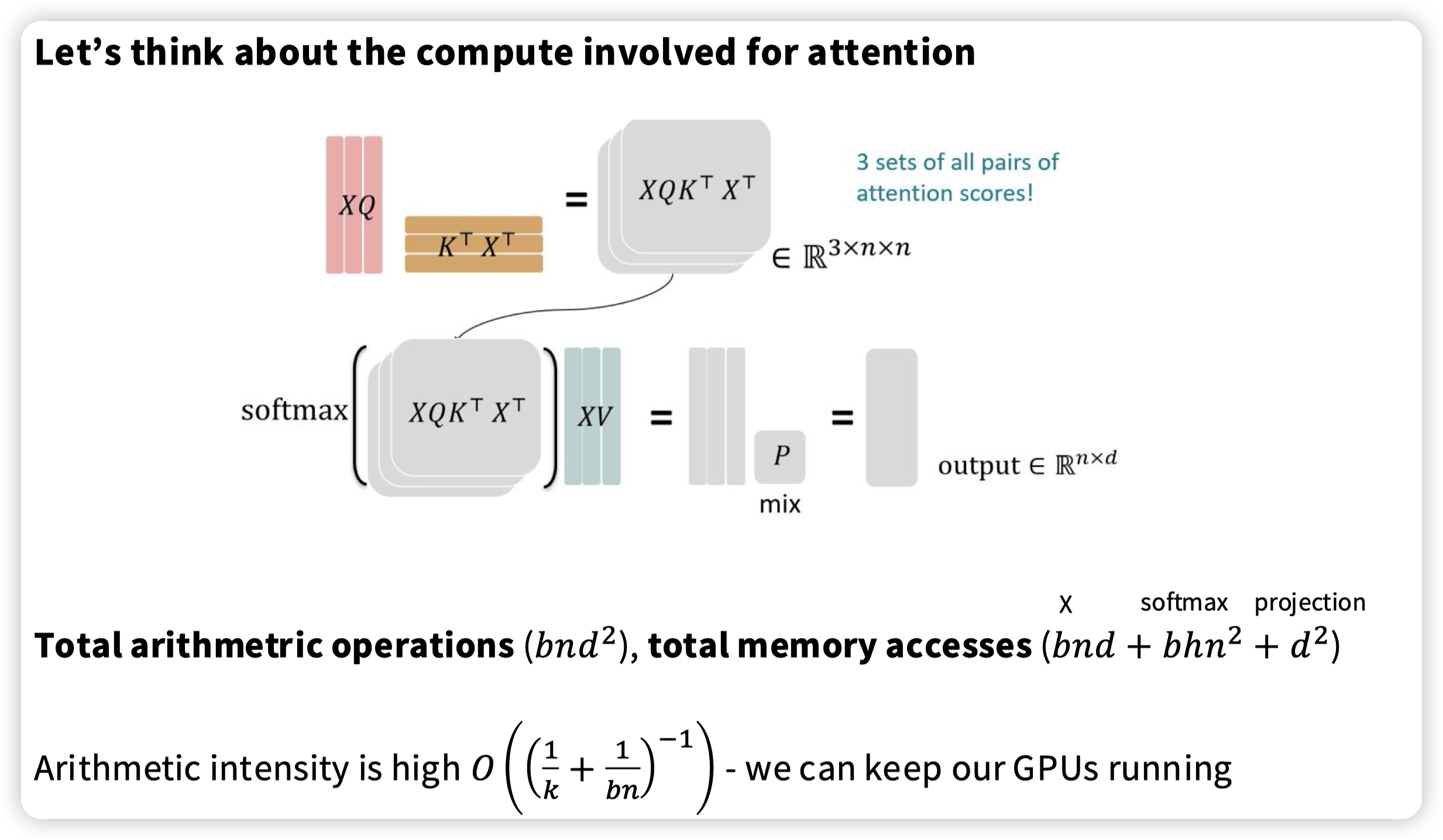
引入算术强度的概念,大概感觉是flops / memory access。
不过这里没有算projection的,不太明白是为什么。以及一次projection应该就是bnd^2了。
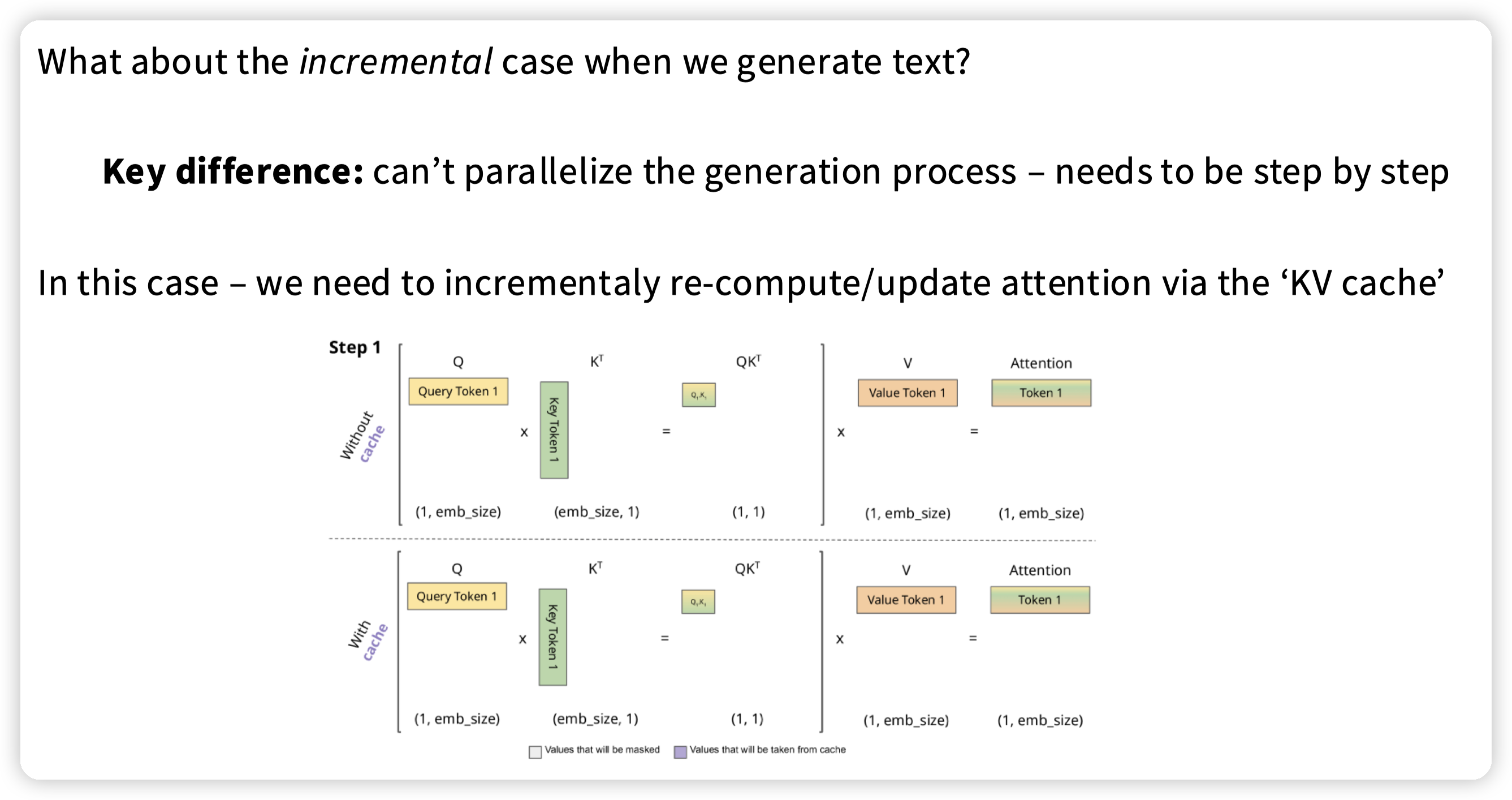
推理阶段算术强度变低了。
然后为了减少访存,以及这里应该对训练/推理都有优化,引入了MQA/GQA
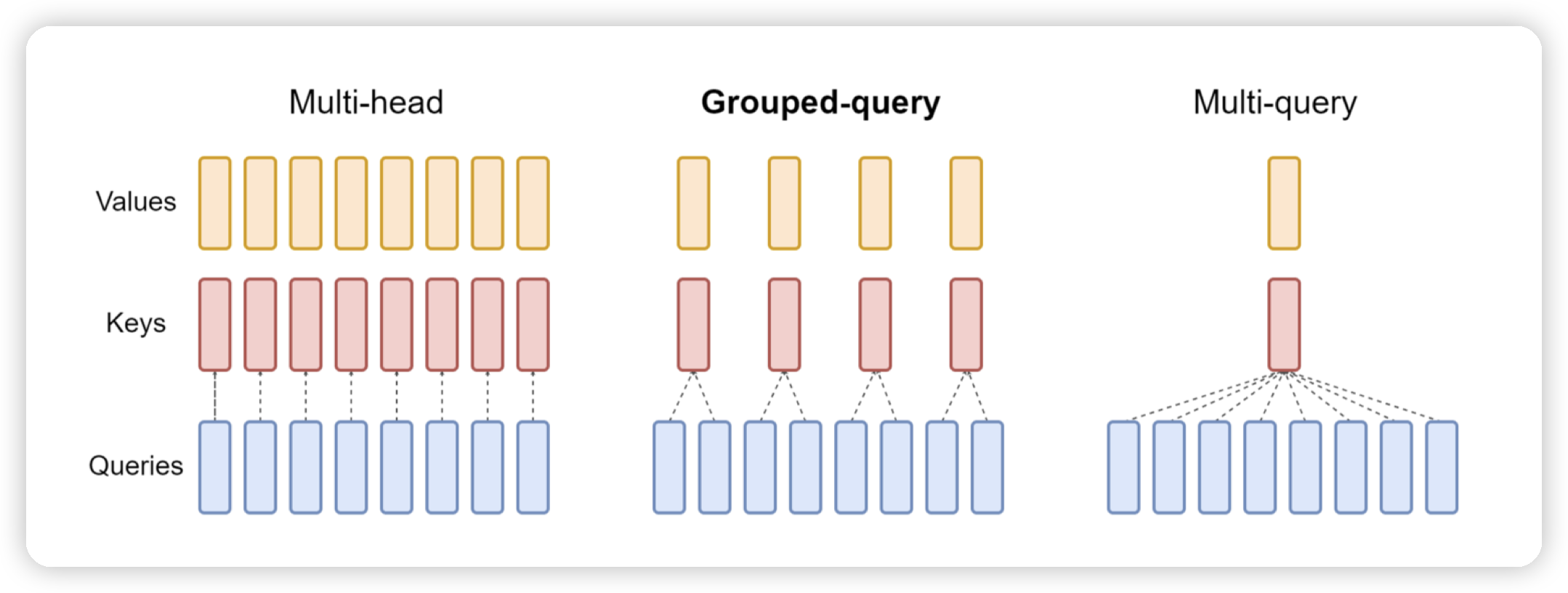
原本的MHA就是相同的head中,query去找对应的kv。
multi query就是KV只有一个head,不同的query head去找同一个kv。
grouped query就是折中,部分query去找一个head中的kv
Sparse or sliding window attention
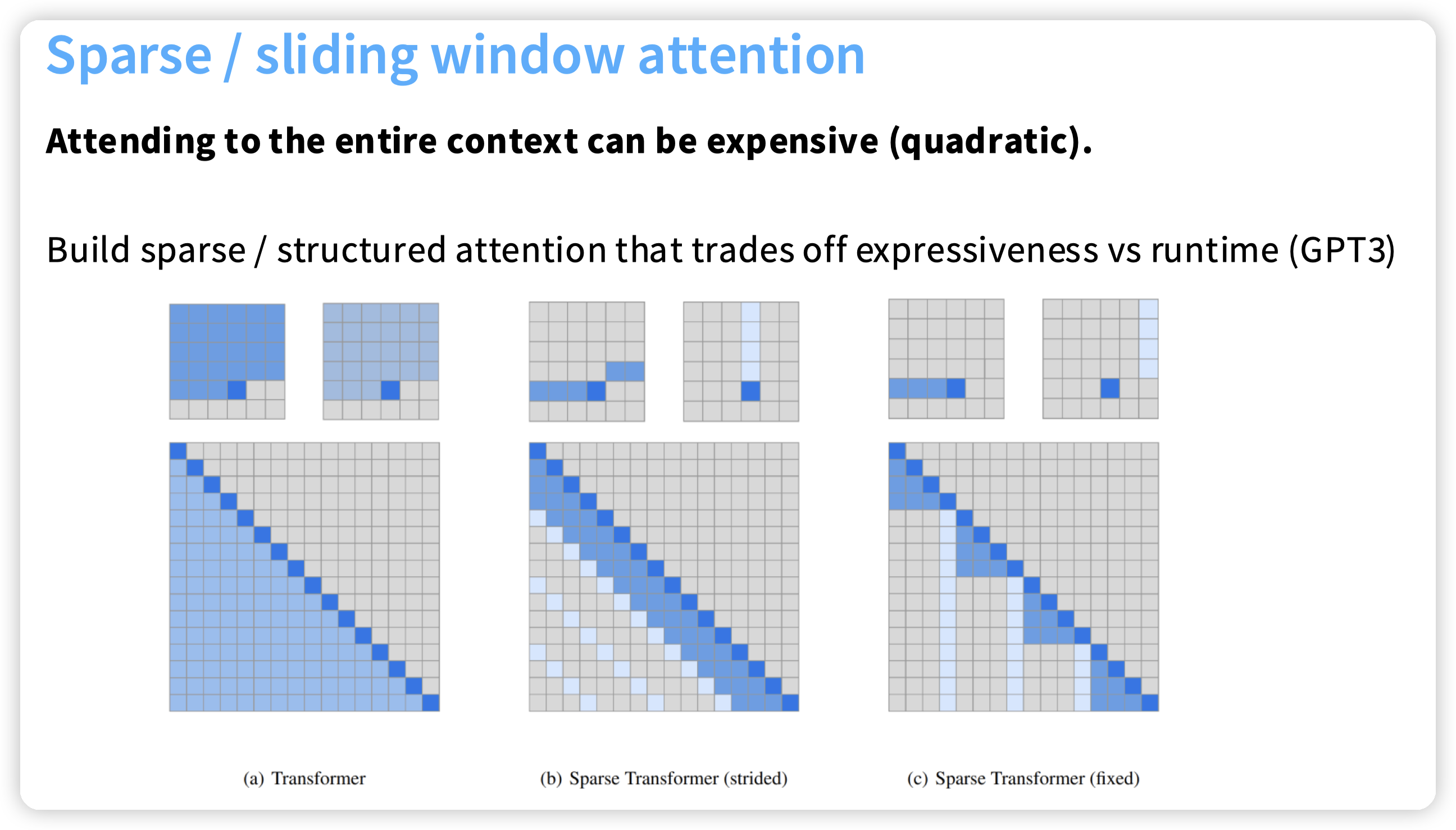
第二个图,每一个元素关注前面一个小窗口,以及满足一些特殊条件的元素,比如这里就是关注一列中的元素。第三个图也类似,关注同一行等。
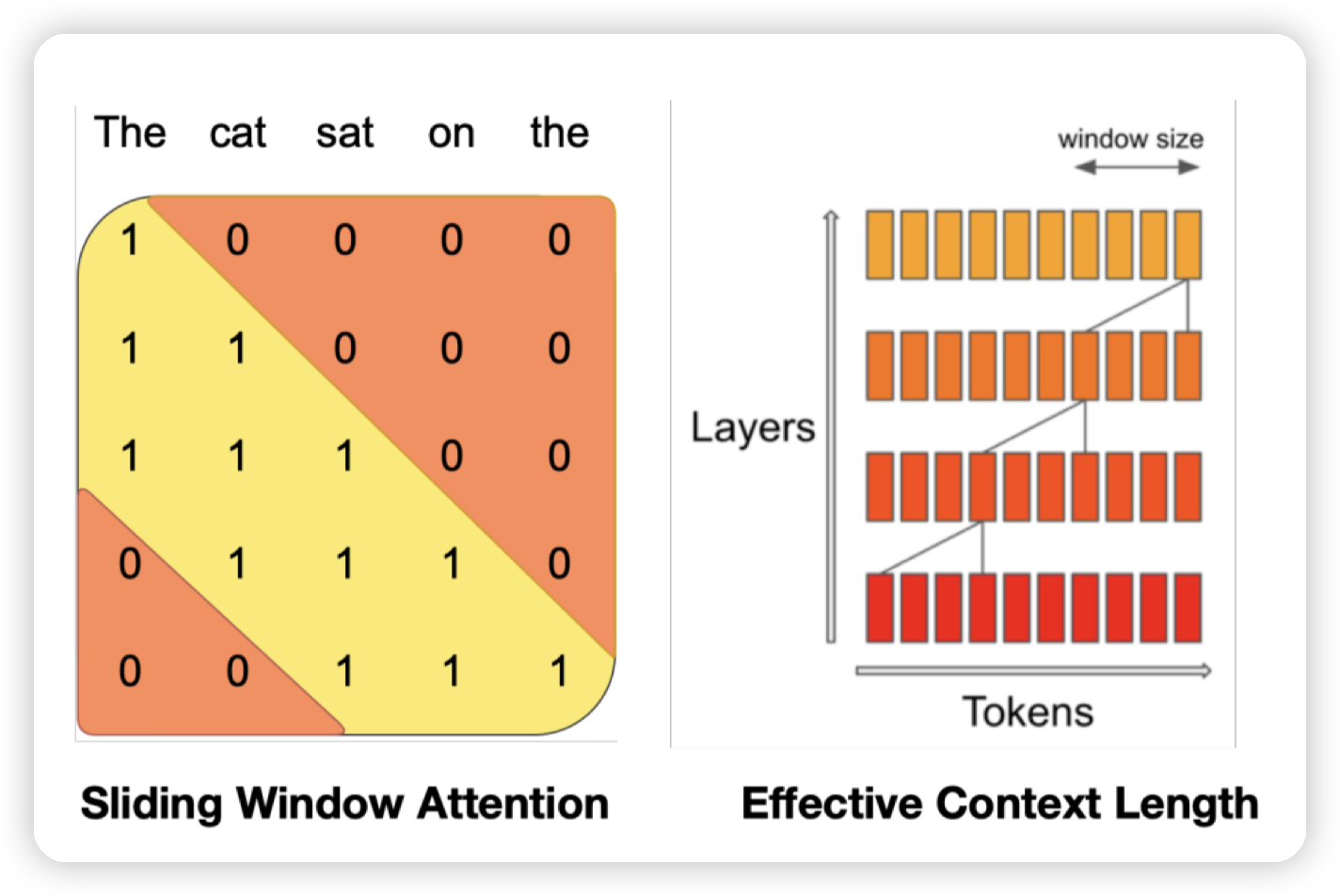
然后通过堆叠layer来实现对更远的位置的关注。
核心目的是避免n方的attention复杂度,提高context window的限制

另一种手段,交错的attention,每过几层做一次full attention NoPE,中间层就用sliding window attention + RoPE。
这里教授提到,full attention没有做position embedding,也就无需关注位置信息,可以更好的做外推

文章评论