纯记录,写的比较糊,包括assignment1的实验和习题的解答
BPE Tokenizer
Problem (unicode1): Understanding Unicode (1 point)
(a) What Unicode character does chr(0) return?
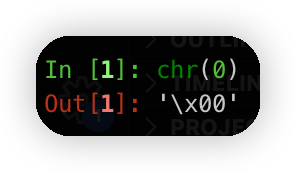
0这个码点代表的字符
(b) How does this character’s string representation (repr()) differ from its printed representation?

print用的是str,repr更精确,而str可读性更强,但是可能有歧义

(c) What happens when this character occurs in text? It may be helpful to play around with the following in your Python interpreter and see if it matches your expectations:
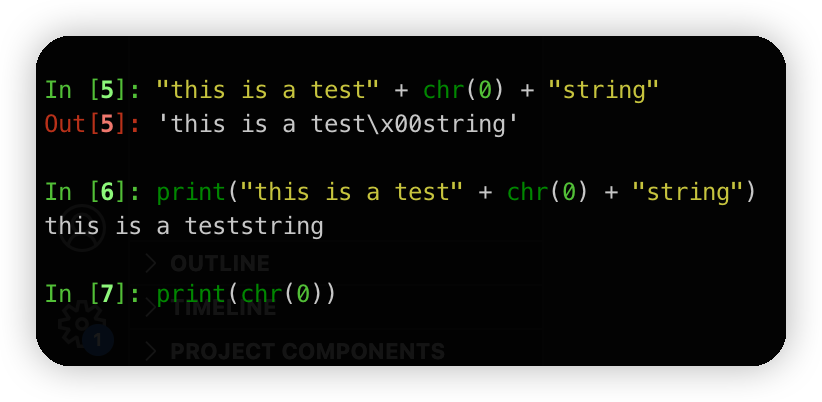
chr(0)代表的是空字符,所以print的时候是空的。
而REPL模式下,是通过repr打印的,方便debug。所以显示的是\x00
Problem (unicode2): Unicode Encodings
(a) What are some reasons to prefer training our tokenizer on UTF-8 encoded bytes, rather than UTF-16 or UTF-32? It may be helpful to compare the output of these encodings for various input strings.

utf8的编码可以生成更少的byte,节省计算资源。生成更多的byte更可能导致tokenize的时候生成更多的token,从而消耗更多计算资源。
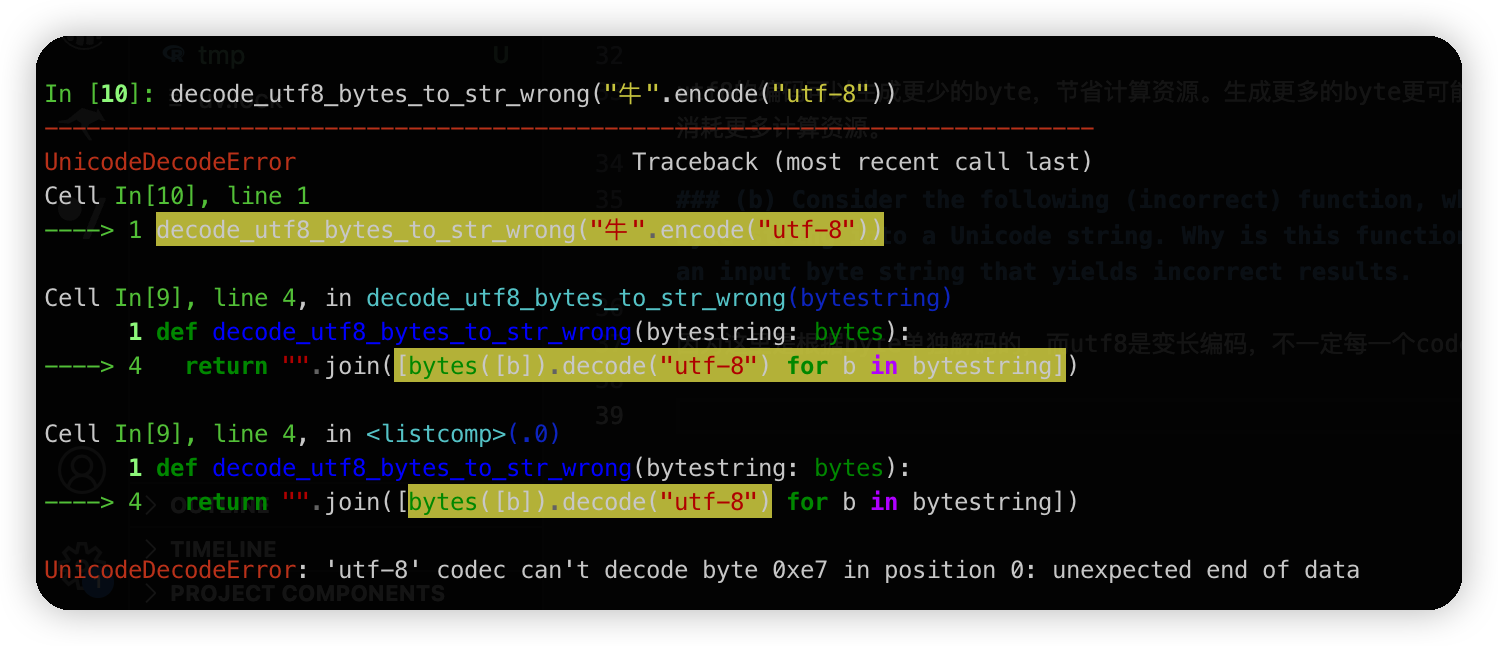
(b) Consider the following (incorrect) function, which is intended to decode a UTF-8 byte string into a Unicode string. Why is this function incorrect? Provide an example of an input byte string that yields incorrect results.
因为这里是根据byte单独解码的,而utf8是变长编码,不一定每一个code point都对应一个字节。
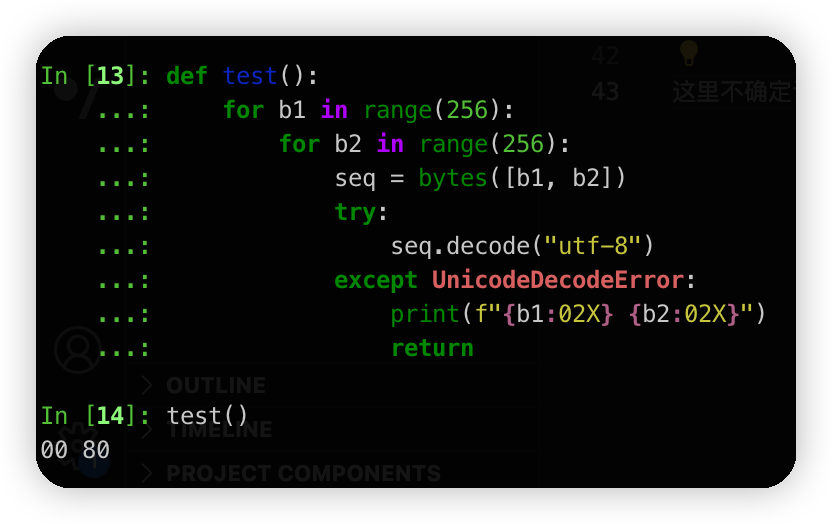
(c) Give a two byte sequence that does not decode to any Unicode character(s).
这里不确定说的是不是utf8的编码规则。简单操作就是for一遍,然后decode失败的时候就打印出来就行
后面都放到experiences中了
Tokenizer
tests/test_train_bpe.py::test_train_bpe_speed 1
pre tokenize 0.022261857986450195
merges with 243 times, 1.4453072547912598
最简单的实现用了1.4秒已经可以过测试了。也可能是因为我并没有每次都重新做tokenize,直接复用了上一次的freq dict。(其实感觉这样写更简单,否则还得走一次encode的流程)
打了一下统计信息:
tests/test_train_bpe.py::test_train_bpe_speed 1
pre tokenize 0.022825956344604492
merges with 243 times, 1.4578559398651123
calc_freq 0.6579418182373047
calc_candidate 0.026823759078979492
calc_occur_dict 0.7456707954406738
因为计算pair/total的freq涉及到遍历全部数据,所以比较慢。这块assignment里已经给了提示,可以直接做一下增量的计算,因为每次只merge一个,大部分的频率是不需要重新计算的。
搞了一个增量的优化,写的其实也比较糊:
tests/test_train_bpe.py::test_train_bpe_speed 1
pre_tokenize 0.030631065368652344
calc_candidate 0.031034231185913086
calc_occur_dict 0.1312110424041748
这块其实还可以再降低一下常数,因为现在我是把每一个变化的word都重新算了一遍,其实只算增量的那点token就行。
然后有关special token的处理,记得要先split by special token,再去做pre tokenize
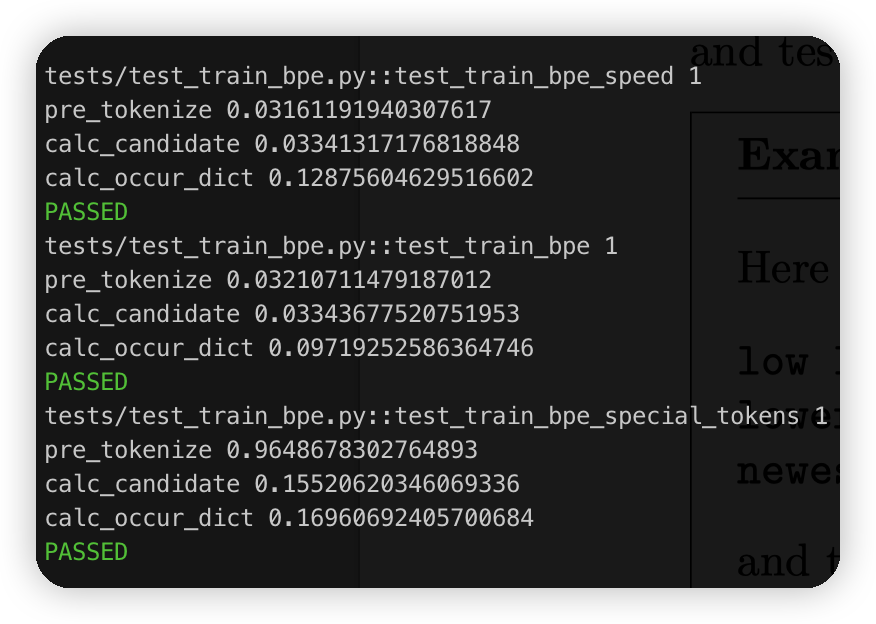
然后跑大数据集,做了一个tokenize的并行:
io consumption 0.009432077407836914
pre tokenize 0.973336935043335
initial calc 0.024617910385131836
pre_tokenize 0.9733319282531738
calc_candidate 6.40349555015564
calc_occur_dict 0.46723246574401855
发现现在瓶颈在calc_candidate上。用堆优化一下
优化了一下,这里我为了方便直接用了python的heapdict,有点不讲武德,有时间再手搓一个吧。这里heap的更新用的是懒标记,就是更新heap的时候是直接把新的数据插进去,带一个version,然后pop的时候把version不对的都扔掉。一些缓存淘汰之类的策略里应该也比较常用
以及是可能简单一点就是分个块,然后每次只更新有变动的块,维护一下块内的最值,这样可以少遍历一些。
io consumption 0.00877690315246582
pre tokenize 0.8549258708953857
initial calc 0.026500940322875977
train executed in 2.859879 seconds
print time statistics
pre_tokenize 0.8549208641052246
calc_candidate 0.0023012161254882812
calc_occur_dict 2.8174686431884766
然后是tiny story:
io consumption 2.124450922012329
pre tokenize 59.56451368331909
initial calc 0.1409592628479004
train executed in 15.113764 seconds
print time statistics
pre_tokenize 59.56451106071472
calc_candidate 0.0029633045196533203
calc_occur_dict 14.929845809936523
总用用了1分多钟,最耗时的就是这个pre tokenize了

然后打印了一些单词表,看起来后面基本都是一些具体的词了。
然后问题中说最大的我这里算出来是:
In [4]: max(vocab.items(), key=lambda item: len(item[1]))
Out[4]: (7160, b' accomplishment')
accomplishment
(cs336-basics) ➜ assignment1-basics git:(main) ✗ grep accomplishment data/TinyStoriesV2-GPT4-train.txt | wc -l
1510
我不确定答案对不对,就先放在这里了。
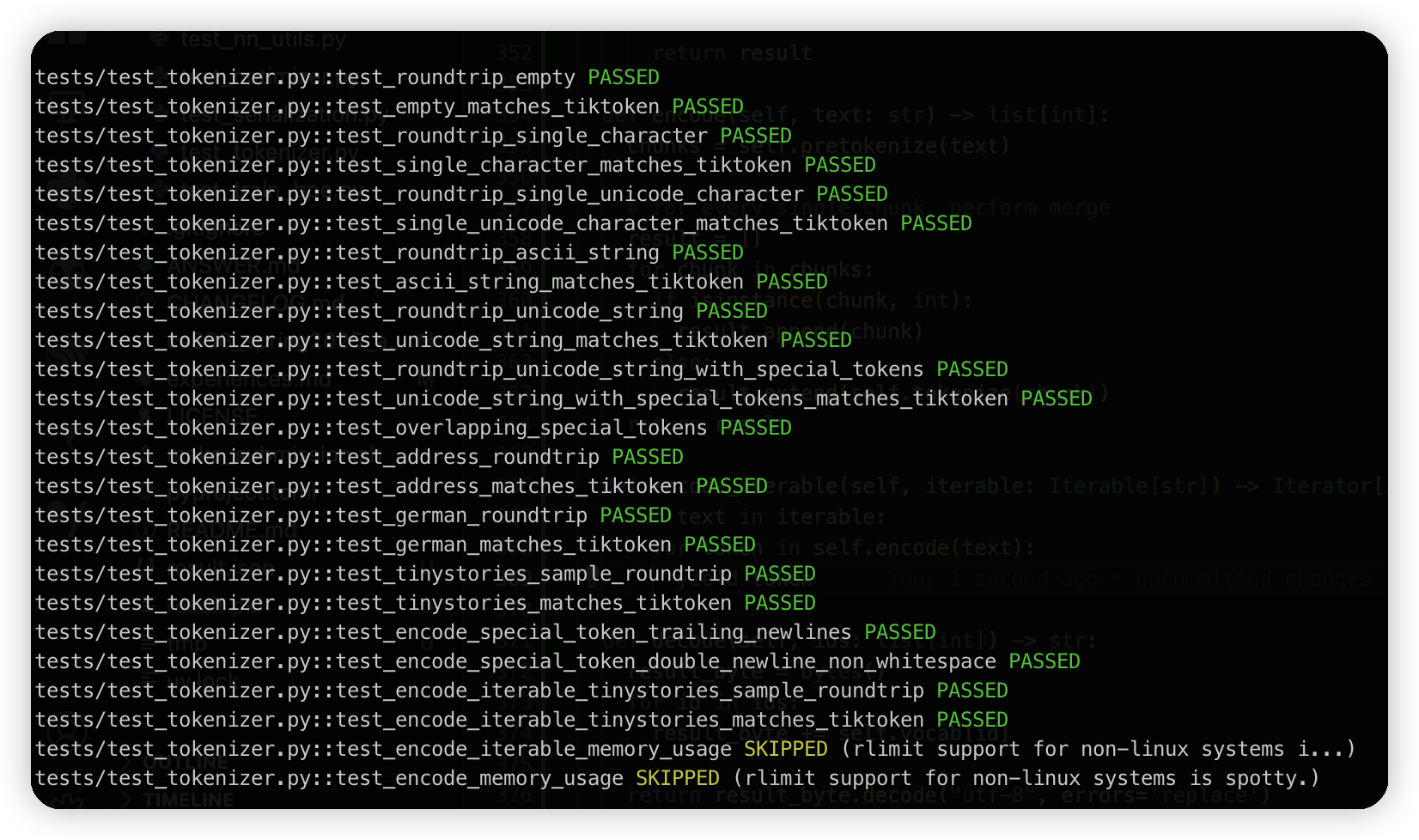
encode/decode,写的比较简单。for了一遍所有的merge,一个一个遍历,简单做了一个内存的优化。
然后回去训练OpenWebText的时候发现巨慢,开始猜测可能是每次把所有变化的sequence重新计算导致的,优化了一下好像效果不大。
现在打算针对sequence做一个映射。节省一下内存开销试试
train executed in 0.385936 seconds
train_from_scratch executed in 0.581723 seconds
print time statistics
pre_tokenize 0.19399690628051758
calc_candidate 9.560585021972656e-05
calc_occur_dict 0.367572546005249
优化了一波,和上面对比,就是calc_candidate还是很低的情况下,减少了calc_occur_dict的时间。从2s到了0.3
优化版本的跑了一下tiny story:
train executed in 7.634798 seconds
train_from_scratch executed in 64.814331 seconds
print time statistics
pre_tokenize 55.75555181503296
calc_candidate 0.003673553466796875
calc_occur_dict 7.412535905838013
优化了一倍
跑open web text的valid数据集:
train executed in 116.717627 seconds
train_from_scratch executed in 127.463858 seconds
print time statistics
pre_tokenize 10.122822046279907
calc_candidate 0.014718770980834961
calc_occur_dict 113.59550547599792
发现越到后面越快。应该是因为到后面token都是一些长尾,去修改对应的word的时候,数量比较少了。
open web text的train:
io consumption 12.17251706123352
pre tokenize 494.73776483535767
initial calc 33.54381990432739
train executed in 1840.086841 seconds
train_from_scratch executed in 2350.292584 seconds
print time statistics
pre_tokenize 494.7377610206604
calc_candidate 0.02803349494934082
calc_occur_dict 1792.9762513637543
这个在我的mac上跑会直接挂掉,pretokenize要切片一点一点来。最后的瓶颈还是在merge上

最长的是一个乱码一样的字符串

后面也都是一些生僻的字符串了。open web text的词表中就多了很多非ascii的
然后是算compression ratio的:
tiny story:
token_length: 2258. bytes_length: 9140. compression_ratio: 0.24704595185995623
open web text:
token_length: 5397. bytes_length: 22105. compression_ratio: 0.24415290658222122
换成tiny story的tokenizer
token_length: 8117. bytes_length: 27366. compression_ratio: 0.2966089307900314
没有针对性的训练压缩率没有很高了。不过30%也很厉害了。只下降了5%
用tiny story测了一下吞吐,每秒钟只有3k的吞吐,有点太低了。
token_length: 197656. bytes_length: 804583. compression_ratio: 0.24566266003631695.
tokenize time 213.52363300323486. estimate throughput: 3768.1215361664936 bytes/second
这里太低了我简单优化了下,加了一个set做了快速过滤,过滤那些不存在的merge
token_length: 197745. bytes_length: 806078. compression_ratio: 0.2453174506685457.
tokenize time 48.442100048065186. estimate throughput: 16640.03003998988 bytes/second
又加了一个优化,维护了一个pair set,用来快速判断是否能够走merge
token_length: 18920. bytes_length: 77802. compression_ratio: 0.24318140921827203.
tokenize time 5.518702745437622. estimate throughput: 14097.878358155791 bytes/second
发现吞吐还低了一些,说明单独判断一个byte已经比较高效了
采了一个火焰图发现全都是在判断merge是否能够进行。(判断对应的pair是否存在),现在遍历所有的merge开销过大了。改一个策略就是只遍历我们存在的pair对应的merge。因为已经维护了pair set,这里的问题就是快速从我们的pair set中选出下一个需要merge的。
我们直接再加一个heap,用来按照merge的顺序,从小到大的从heap中选下次需要merge的pair就行,不需要每次都遍历。
token_length: 192324. bytes_length: 783407. compression_ratio: 0.24549691284351557.
tokenize time 4.0828869342803955. estimate throughput: 191875.75179278743 bytes/second
加了以后吞吐到了百k级别。先到这里吧,比较大的优化基本上做的差不多了,再往后就是扣内存等一些常数优化了
最后还有一个问题是问为什么用u16存token id好一些。因为这里我们的词表是32k,可以用u16保存,用u8就爆了,用u32浪费。
不过不确定这里的u16的值域是否在设置词表大小的时候被考虑到了,还是说主要考虑的还是词表太大可能影响训练。
* 这块问了下GPT说其实没有考虑词表大小对存储空间的影响,还是为了压缩率考虑的。感觉应该看看这些tokenize是不是有什么survey,看GPT说是根据压缩率选词表大小,有32k, 50k的。
* 说到这里,应该还有一个比较常见的是xxx_100k,这种自然就用不了u16了
* 一些multi lingual的一般词表都比较大,100k,256k等
Transformer
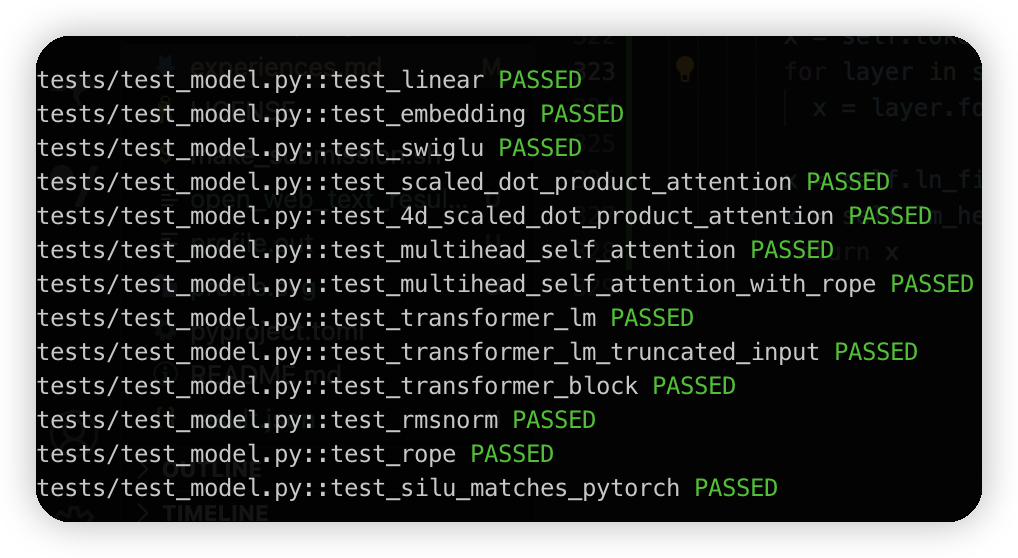
整体来说难度不大,每一个具体的任务都写明白了接口和具体的公式,跟着写就行。
不过我这里代码比较粗糙的是没有处理device/dtype,这个后面可以通过kwargs一路透传,晚点发现训练瓶颈的时候再加一下。
有一个比较坑的需要注意一下,就是在写TransformerBlock的时候,如果你感觉自己写的没啥问题,其他模块也都测试过了,但是还是过不了。它这里需要我们自己生成token position,文档里应该没有显示说明这一点,我最后还是看网上其他人的写法才发现了这个坑点。
可能也是我不太熟悉,不知道具体应该在哪里传入token position。其实课上教授也说了用了RoPE之后是每个transformer block内部加token position了
Resource accounting
A(m x n), B(n x p)的矩阵乘法需要 2mnp FLOPS
Embedding:
* 主要是查表,应该不算mat mul
RMSNorm:
* 对于每一个向量,d次乘法/加法,用来计算rms。然后d次除法除rms,再乘上weight,也是d次
* 一个向量就是4D次。n个就是4 * N * D次
* 不过实际上没有matmul
Linear:
* 就是matmul,2mnp,需要看输入的长度
SwiGLU:
* 3个matmul,假设输入的数据为(seq_length, d_model),那么计算量为6 * seq_length * d_model * d_ff
* 这里我们假设d_ff 是3/8的d_model,那么总共就是16 * seq_length * d_model * d_model
RoPE:
* 2*2的矩阵相互乘flops是2 * 2 * 2 * 2 = 8
* 假设输入是(seq_len, d_model), 计算量为8 * (d / 2) * seq_len = 4 * d * seq_len
Attention:
* QKV都是 (seq_length, d_k)
* QK是(2 * seq_length * seq_length * d_k)
* score * V的计算量是(2 * seq_length * seq_length * d_k)
* 总共是4 * seq_length * seq_length * d_k
MultiHeadSelfAttention:
* projection: 3 * (2 * seq_length * d_model * d_model) = 6 * seq_length * d_model * d_model
* attention: 4 * seq_len * seq_len * ((d_k * head) = d_model)
* rope: 8 * d_model * seq_len (2个RoPE)
* 最后一个projection: 2 * seq_len * d_model * d_model
* 总共是: 8 * seq_len * d_model * d_model + 4 * seq_len * seq_len * d_model + RoPE(太小了不想算
TransformerBlock:
* attention + ffn
* 24 * seq_len * d_model * d_model + 4 * seq_len * seq_len * d_model
* 如果不把上面的d_ff代换过去的话,就是:4 * seq_len * seq_len * d_model + 8 * seq_len * d_model * d_model + 6 * seq_len * d_model * d_ff
TransformerLM:
应该可以看出来被transformer block中的attention占据主导了,num_layer * TransformerBlock
然后看参数量:
Embedding:
* vocab_size * d_model
RMSNorm:
* d_model
FFN:
* 3 * d_ff * d_model
RoPE:
缓存的就先不算了
MultiHeadSelfAttention:
* d_model * d_model * 4
TransformerBLock:
* d_model * d_model * 4 + 3 * d_ff * d_model
然后是问答环节:
Suppose we constructed our model using this configuration. How many trainable parameters would our model have? Assuming each parameter is represented using single-precision floating point, how much memory is required to just load this model?
把上面的参数带入进去算:
* vocab_size * d_model = 80411200
* num_layer * (d_model * d_model * 4 + 3 * d_ff * d_model) = num_layer * (10240000 + 30720000) = 1966080000
* lm_head = d_model * vocab_size = 80411200
总共是2126902400, float32就是7.923328876495361 G
写了一个脚本,再resource_account.py中:
embedding_layer: 306.7MB
lm_head: 306.7MB
single_transformer_block: 156.2MB
total_transformer_block: 7.3GB
total_size: 7.9GB
Identify the matrix multiplies required to complete a forward pass of our GPT-2 XL-shaped model. How many FLOPs do these matrix multiplies require in total? Assume that our input sequence has context_length tokens.
ffn: 3.020e+12
attn_dot_product: 3.221e+11
attn_proj: 1.007e+12
total: 4.349e+12
这里d_model/d_ff比较大,同时context length比较小,所以主导的是FFN
gpt2_small
ffn: 1.739e+11 64.29%
attn_dot_product: 3.865e+10. 14.29%
attn_proj: 5.798e+10 21.43%
total: 2.706e+11
gpt2_medium
ffn: 6.185e+11 66.67%
attn_dot_product: 1.031e+11. 11.11%
attn_proj: 2.062e+11 22.22%
total: 9.277e+11
gpt2_large
ffn: 1.450e+12 68.18%
attn_dot_product: 1.933e+11. 9.09%
attn_proj: 4.832e+11 22.73%
total: 2.126e+12
gpt2_xl
ffn: 3.020e+12 69.44%
attn_dot_product: 3.221e+11. 7.41%
attn_proj: 1.007e+12 23.15%
total: 4.349e+12
占据主导的始终是ffn,随着模型规模变大,ffn的比例也在提高。
这是因为模型规模和d_model相关,随d_model的平方正比,而attn则是跟着seq_length走
gpt2_xl_long
ffn: 4.832e+13 32.89%
attn_dot_product: 8.246e+13. 56.14%
attn_proj: 1.611e+13 10.96%
total: 1.469e+14
扩大上下文长度后,flops上升了两个量级。attn占比上升了很多
和GPT老师对了下答案应该没啥问题,然后这里还让他给了一下激活值的内存占用,也有一个直观的了解:

需要注意的是,attention这一层的内存消耗是head * (T**2),因为这个T * T的矩阵里记录的是softmax的分数,不会乘上d,所以内存主要消耗还是KV Cache的地方
Training
Problem (learning_rate_tuning): Tuning the learning rate
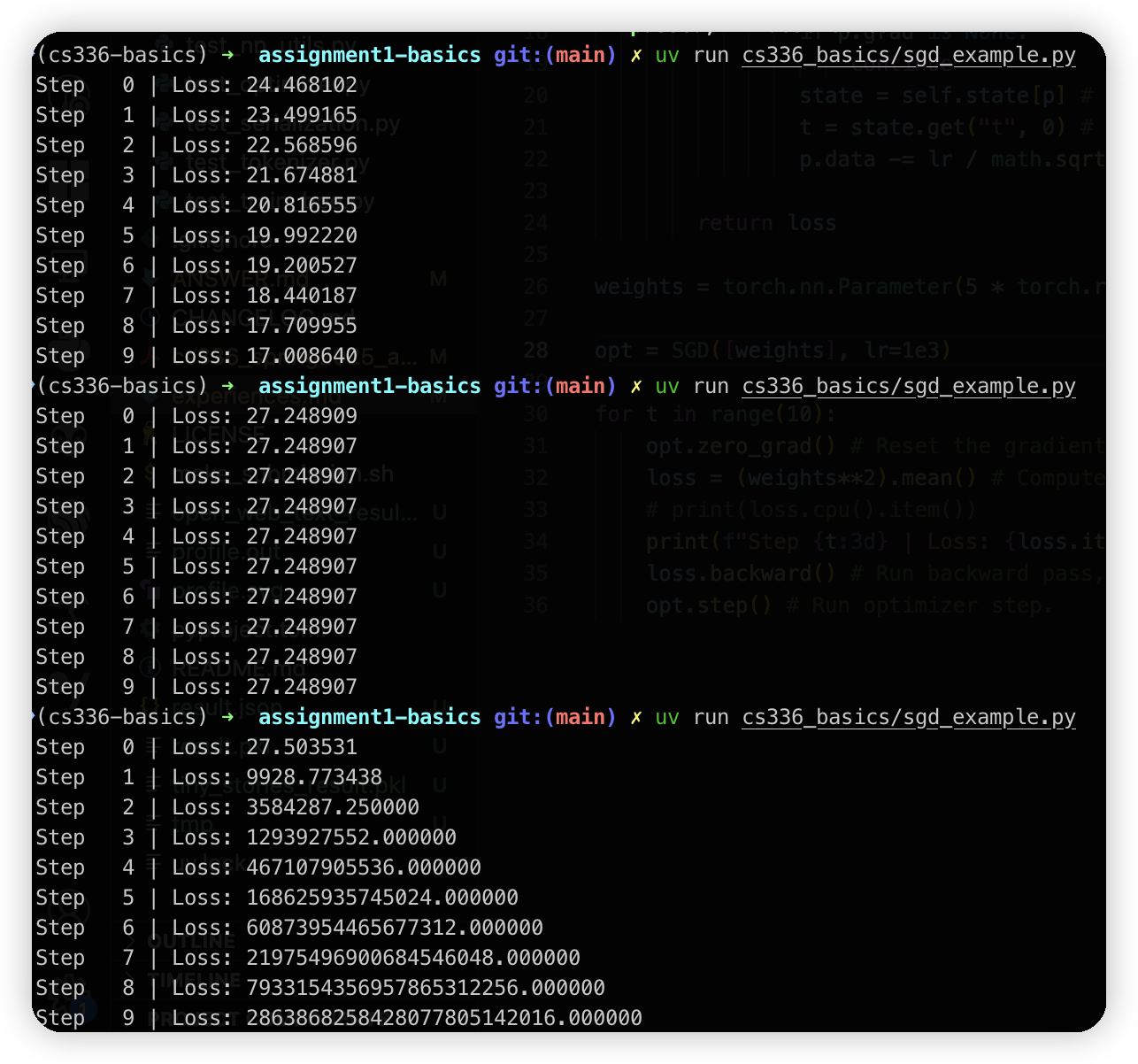
LR低的时候在逐步收敛了,LR高的时候loss就起飞了
1e1的时候收敛比较慢,1e2的时候收敛比较快,1e3无法收敛
gradient clipping记得是算全局的梯度。
Resource accounting
这里还有一个训练阶段的resource accounting,主要看内存
参数
参数内存之前也算过,如果dff按照8/3 d_model算的话,总体的参数量应该是12 * d_model * d_model * layer + 2 * vocab_size * d_model
梯度
梯度和参数的数量是一样的, dtype也是一样的
Activation
这里列出来有点多,我单独放到一个地方写一下文章吧,结论是大概为(9 * d_model * seq_len + 2 * seq_len * seq_len) * layer
这里主要算的是transformer那块,没有带上embedding和lm head的
最后再乘一个batch size
Optimizer
对于每一个参数,AdamW会存两个值,m和v,m是梯度的一阶矩,v是梯度的二阶矩。
一般是fp32存,数量是 2 * Parameters
gpt2_xl
param_mem: 6.1GB
grad_mem: 6.1GB
optimizer_mem: 12.2GB
activation_mem: 3.0GB
total: 27.4GB
一旦batch size大了,activation mem的占用量会急剧上升
对于GPT2_XL,放到80G的显存上的话。公式就是3 * batch_size + 24.4 <= 80.
batch_size最大是18
然后adamW的计算量为:
* 计算m: 两次乘一次加,3 * param
* 计算v: 两次乘一次加,一次平方,4 * param
* 更新data: 一次乘,一次开方,一次除,一次减,一次加, (4 + 20) * param,开方按照20次算的
* weight decay: 一次乘,一次减, 2*param
总共是33 * param次
第四题,按照上面算的,batch_size为1024应该无法放入显存中,我就只按照flops算了
gpt xl的前向传播是4.349e+12
反向传播乘个2,就是8.698e+12
参数更新大概是7e10,直接忽略掉。然后乘上batch size,1.33e+16
A100的峰值是19.5e12, mfu 50%就是9.75e12
差不多一个batch需要1000s
400K个step,需要跑 400k * 1000 / 86400 = 4629天
看起来跑一个GPT2也远远不是单卡可以搞定的,无论是需要的计算量还是显存瓶颈
GPT老师给拓展了一下,我们用scaling law算一下:
GPT2_XL的参数按照2e9算,需要的token是20 * N = 4e10
注意力长度比较短的时候,一个token大概需要6 * N 的flops
那么需要的flops就是4e10 * 6 * 2e9 = 4.8e20
MFU 50%算,一块A100就是4.8e20 / 1e13 = 4.8e7
100块A100就是4.8e5 ~= 5天 (不算scalbility的问题)
Experiment
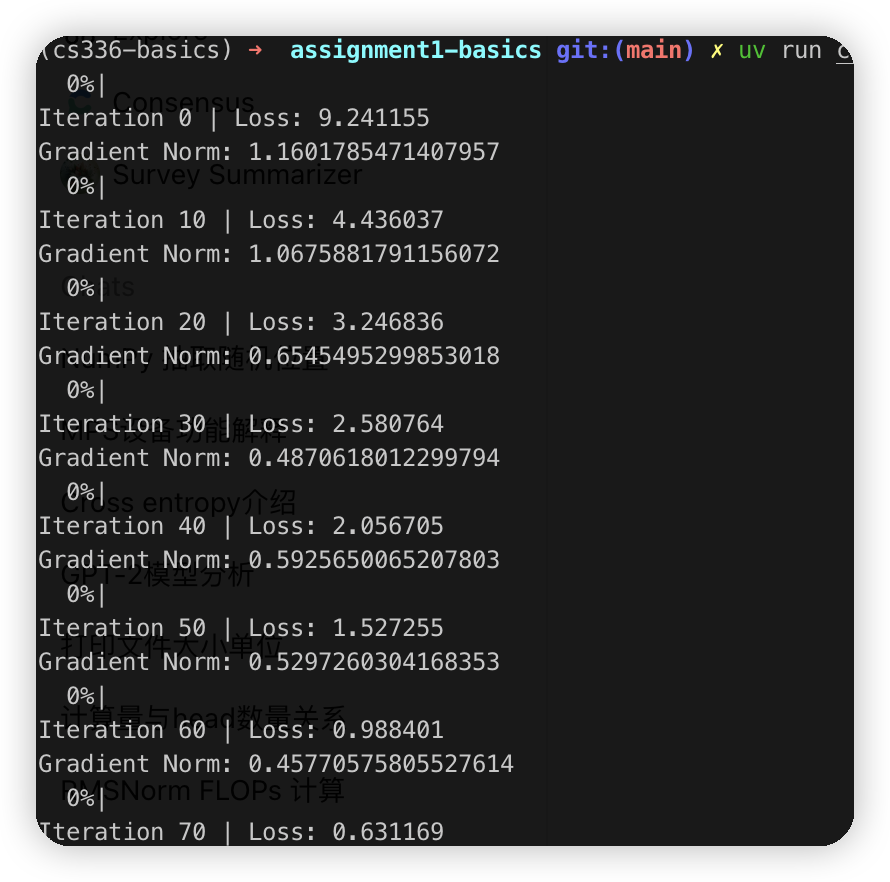
最开始写的train代码有一点问题,没有调用optimizer.zero_grad(),所以梯度会累加,导致gradient norm越来越大。
排查的思路是把step中的gradient norm打印出来,看看趋势
解决后大概20多个iteration就可以把loss跑到比较低,注意这里是用了一个比较小的数据集,先测试代码可以收敛。
现在这块还有一个问题就是速度过慢,我在写代码的时候没有怎么关注dtype/device,现在基本是1s一个step,这里batch size是16
在mac上试了试mps,好像和纯cpu区别不大,32的batch size,都用了torch.compile,基本都是2s一个step. 看GPU监控也确实用上mps了
现在有点迷惑的是不知道是不是我代码的问题,assignment里写 M3芯片,32batch size跑5000个iteration,在cpu上也只需要一个半小时,用了mps就是30多分钟。
我这里测下来,我这个是M1,相同的batch size,5000个iteration用cpu和mps都需要3个小时
优化了一波还是差不多2s 32个batch,cpu和mps差不多。不过发现一个问题是打开gradient norm之后,mps上的gradient会直接爆炸,loss就飞起来了,但是cpu上没有问题,不知道是啥原因,就用cpu训练了。
2025-10-05 11:26:24,209 - INFO - Iteration 3000 | Loss: 1.656939
2025-10-05 11:26:24,209 - INFO - Gradient Norm: 3.549e-01
2025-10-05 11:26:24,209 - INFO - Learning Rate: 3.769e-04
在tiny story上3000个step跑到了1.65的loss,M1跑了两个小时
看了看wandb的曲线,大概在1000个step就可以跑到2一下的loss了。gradient clip和lr schedule都打开了

文章评论
老哥写的好哇,打个卡😀