https://github.com/SuperMedIntel/Medical-Graph-RAG
这里的文章,简单看了一下:
是针对医疗数据做的GraphRAG。核心目的是为了提高生成内容的准确性,即不能让大模型胡说。
为了做到这一点,MedGraphRAG在graphrag上做了两点改进:
* 在实体提取的时候,会把实体和可信医疗源,以及受控词汇表连接起来
* 针对医疗标签做总结,而非使用通用的社区总结
具体来说:

会有一些置信程度比较高的资料,在RAG的时候,会把实体和这些置信程度比较高的资料链接到一起。
这里有点类似LightRAG,允许插入用户自定义的知识图谱,来强化知识的置信程度以及质量
然后在做社区总结的时候,不用leiden去做发现社区+总结,而是使用层次聚类,并且用预定义好的医疗标签集合去总结社区。
相比之下,就是用一些特化的知识替换通用的社区总结,因为医疗标签也属于社区总结的一种。
在查询的时候会做类似dynamic community search的方法。从顶层标签开始,逐渐搜索下层社区。
看了下代码有点对不太上。我这里解释一下代码的逻辑:
构图:
* create_metagraph,这里就是上面说的实体提取,存储到一个图中。不同的文件有不同的graph id
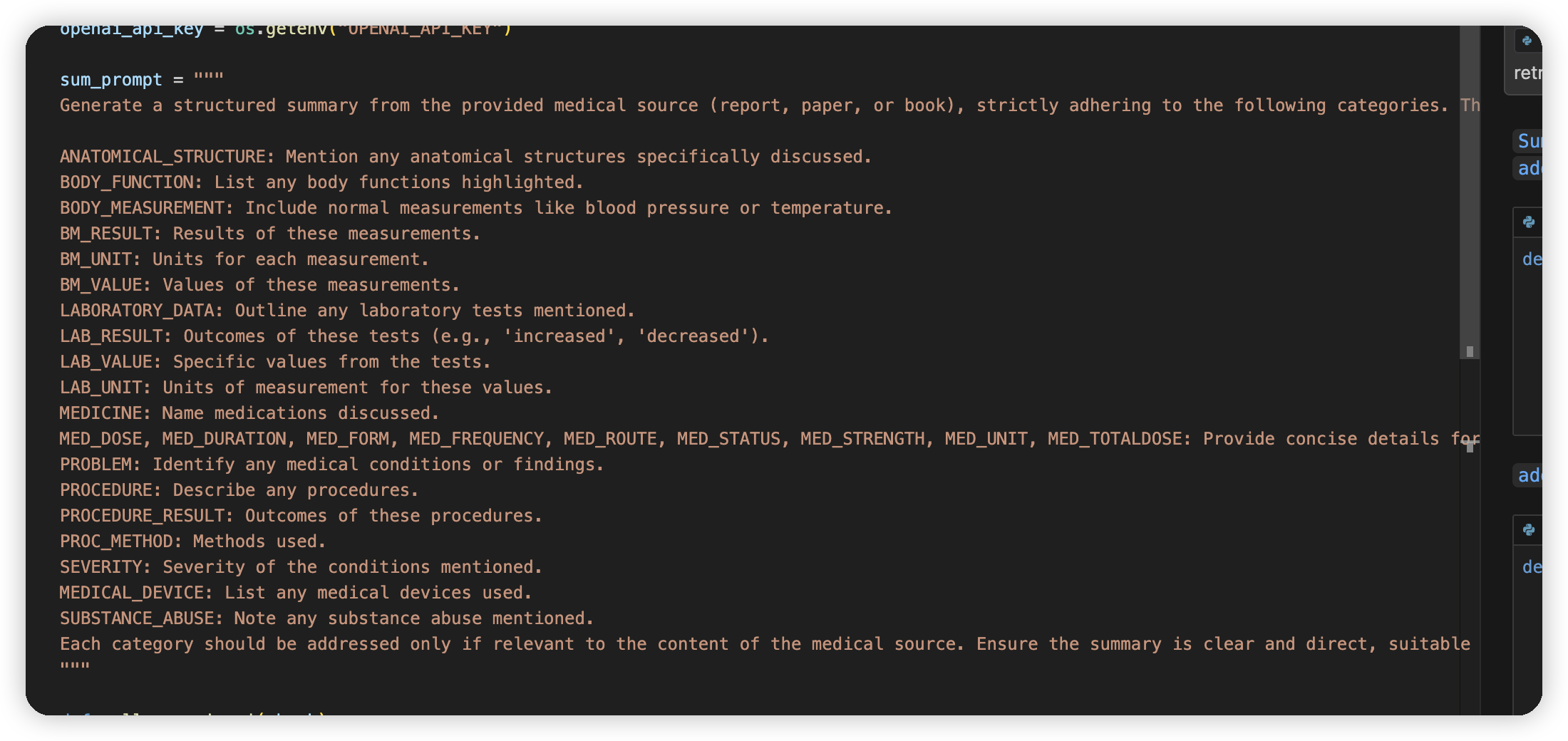
* 会根据这个格式做文档的总结,存储到summary中
查询:
* 查询的时候,会遍历所有的summary,用LLM判断是否和用户query相关。
* 找到最相关的那个图,做local search
* 然后再在相关的图中,做ref search,即去查找上面说的预提供好的医疗知识库

文章评论