最近在用python处理一些大数据相关的工作,就无可避免的涉及到了pandas。迟早还是要学一下的,就在这里简单看一看。
pandas的核心数据结构:
* DataFrame,二维表格,由Series组成。和关系表一样。行列组成,列是有相同的schema
* Series:一维表格
在此之上提供了:
* 数据对齐,用来做数据的合并和join
* 数据清洗:做数据类型转化,异常值处理,处理缺失数据
* 可视化:与Matplotib等库无缝集成
* 性能:内部使用numpy,性能比较好
* 生态:与其他数据科学相关的库都有比较好的集成,比如NumPy,SciPy。还有Arrow等。也支持各种数据格式的读取和写入,比如CSV,Json,Parquet
https://zhuanlan.zhihu.com/p/340119918
这篇文章对基本概念讲的比较清楚:
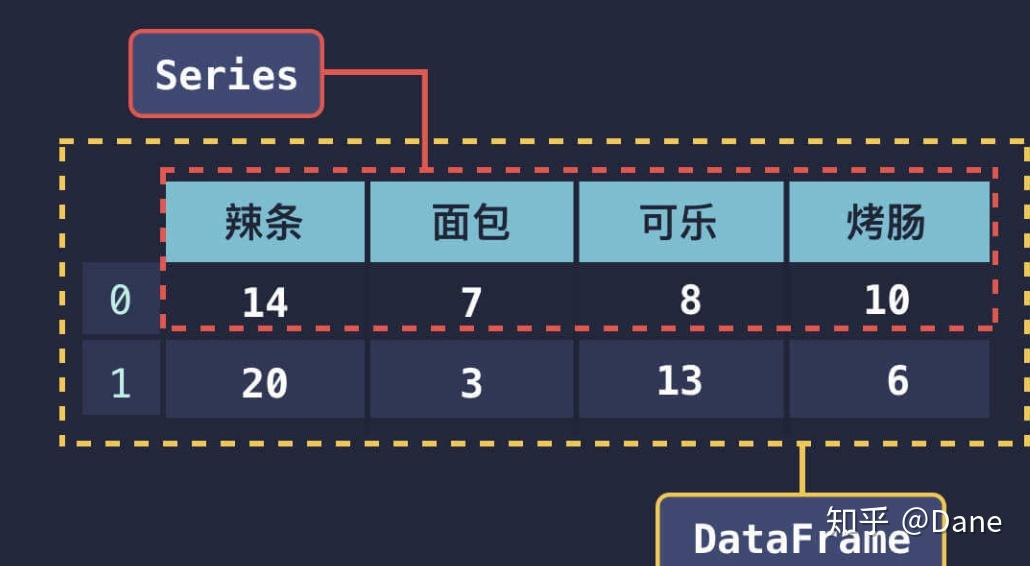
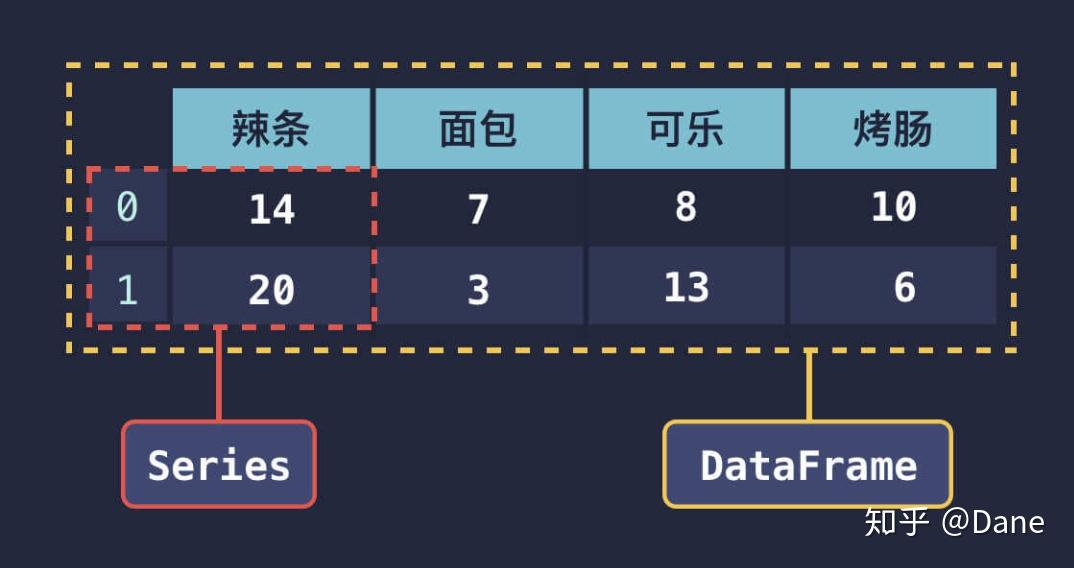
* Series就是一维数据,可以带上tag。用起来就可以类似dict一样
* DataFrame理解成Series组成的表:
* 每一行可以看作一个Series,其中tag就是列的名字,value就是这一行对应的value
* 每一列也可以看作Series,其中tag就是行号,value就是对应行的value
https://pandas.pydata.org/docs/user_guide/10min.html
官网上有一个简单的user guide
- df.head()/df.tail()可以看数据的头尾
- df.index可以看行的tag
- df.columns可以看列的tag
- df.describe()可以展示数据的摘要
- df.info()也可以看数据摘要

* loc可以做row/column的slice
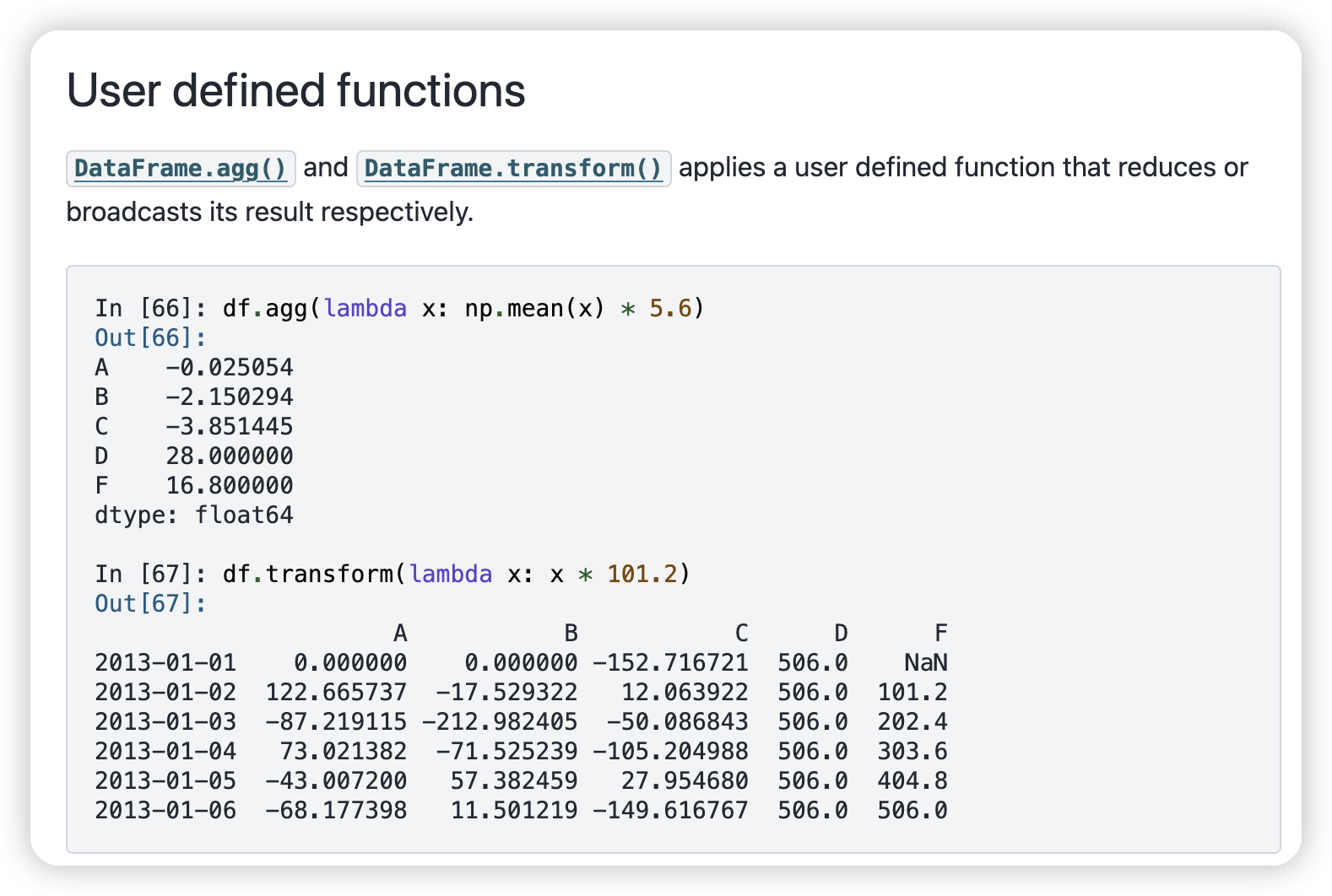
可以做agg/transform
- pipe可以做table级别的转化
- row/column级别的转化通过df.apply(axis)。比如做row/column级别的agg
- 单个value级别的,就是用transform了
- 单个value级别也可以用map
-
可以用df.iterrows()来实现对df的迭代。此时每一个row是一个Series。
- 可以用df.itertuples()来迭代value,会比iterrows()快很多,因为不需要涉及到列的信息
- 一般来说,iterate df会比较慢,建议使用df自带的各种函数。
https://pandas.pydata.org/community/ecosystem.html
这里还有pandas支持的生态。
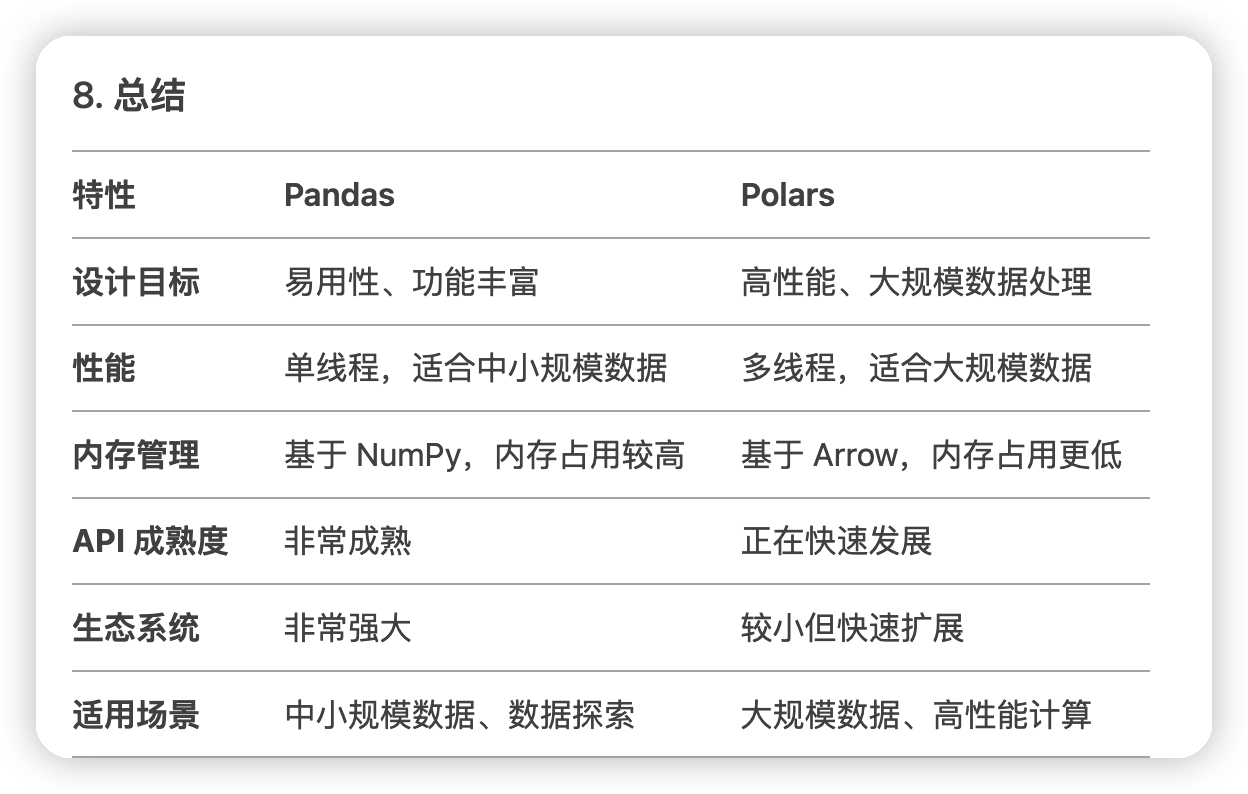
还有简单对比了一下pandas和polars:


貌似还没有遇到pandas处理数据出现瓶颈的case。


感觉是pandas适合利用生态/易用性快速实现功能。如果遇到性能瓶颈,再尝试用polars优化即可。

文章评论