SSTable(3) Read & Write
参考文档在这里
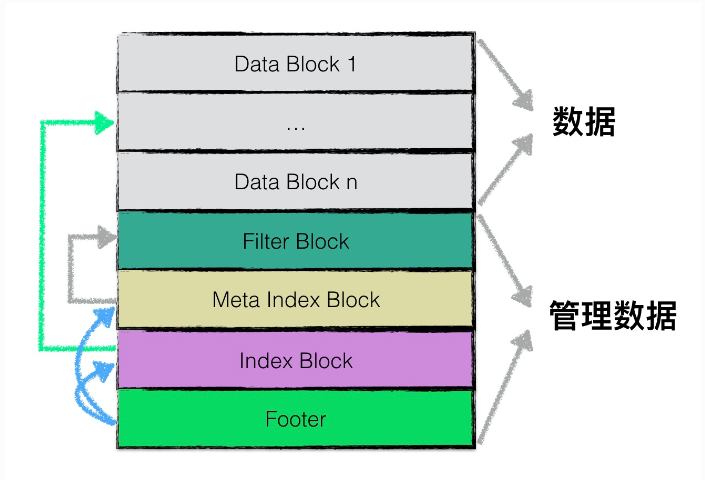
还是看这个图。footer是固定的,通过footer去找到meta index block和index block
meta index block指向filter block,为什么不直接让footer指向filter block呢?因为meta index block中存储了filter的名字,是变长的。而footer是定长的。所以增加了一个额外的indirection
代码中主要是在table builder做写操作
table builder中有个rep的结构,用来存储各种数据
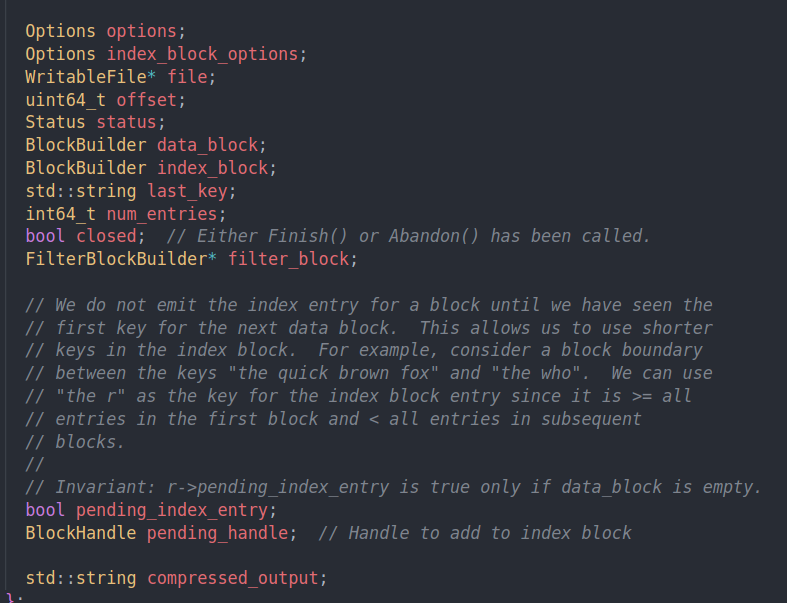
主要就是这几个block builder。
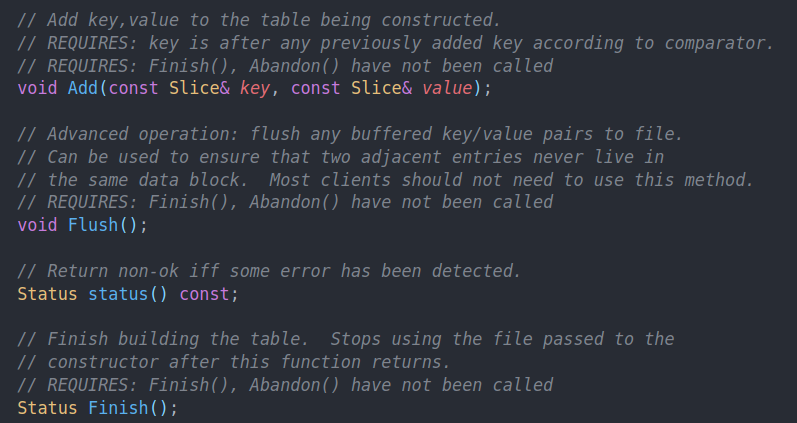
接口主要就是Add和Finish。在Add内部会调用Flush来构建新的块
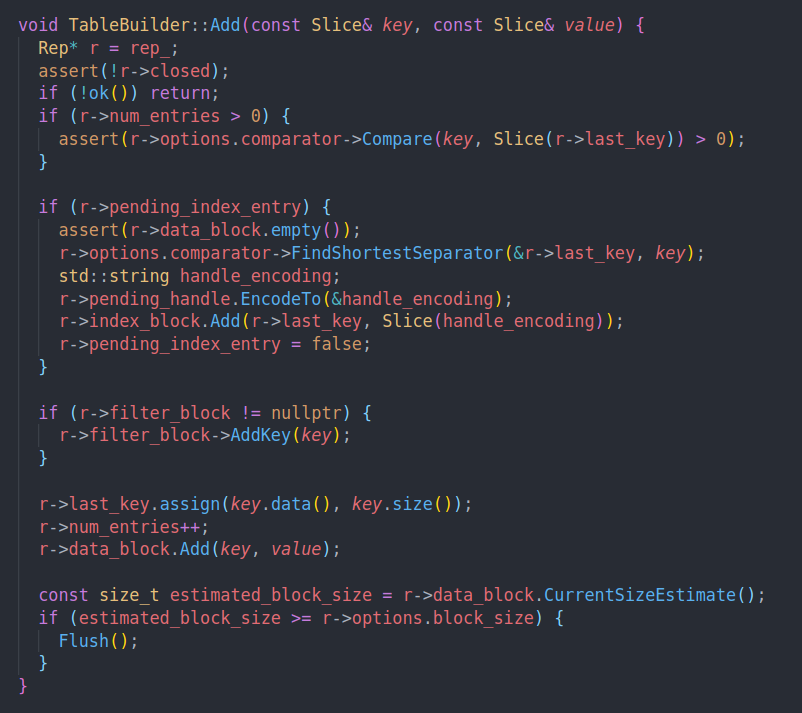
add的作用就是直接在data block中add一个kv pair。如果有filter block的话就也加入到filter中
然后当data block过大了,就调用flush

flush的逻辑就是写入data block,然后创建新的bloom filter
而write block的作用主要是调用BlockBuilder的Finish,结束Block的构建,然后将这个block压缩,并写入到文件中
这里flush会设置pendng index entry为true,下一次再插入数据的时候,就会在index block中插入last key,也就是插入上个block的最大key,作为索引项。至于为什么要在下一次插入的时候再去插入index,与这个FindShortestSeparator有关。之后去研究一下
而在最后的Flush中,我们会构建上面图中的其他块
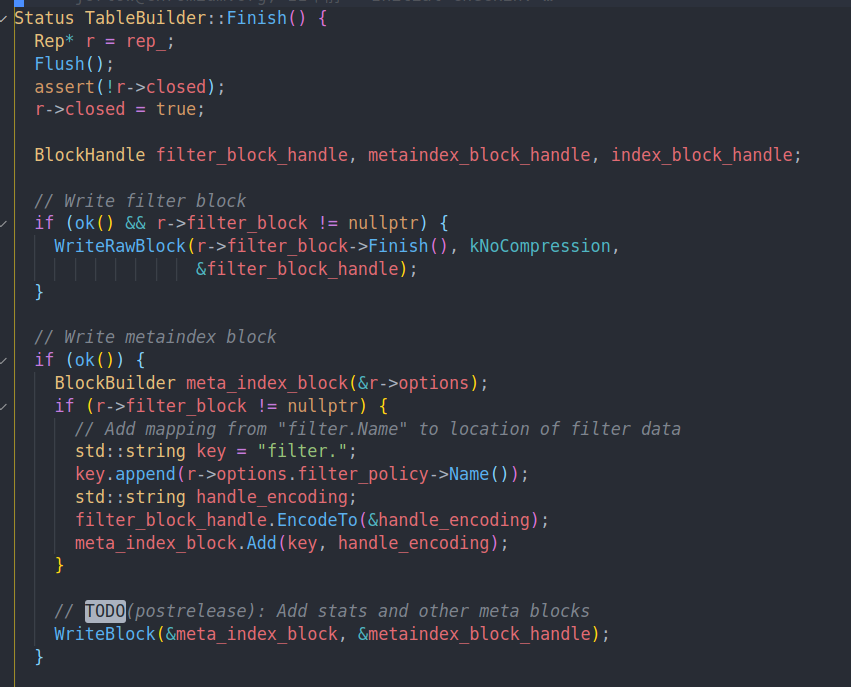
开始Flush一下,把之前剩下的写入到data block中
然后将写入filter block,并写入meta index block
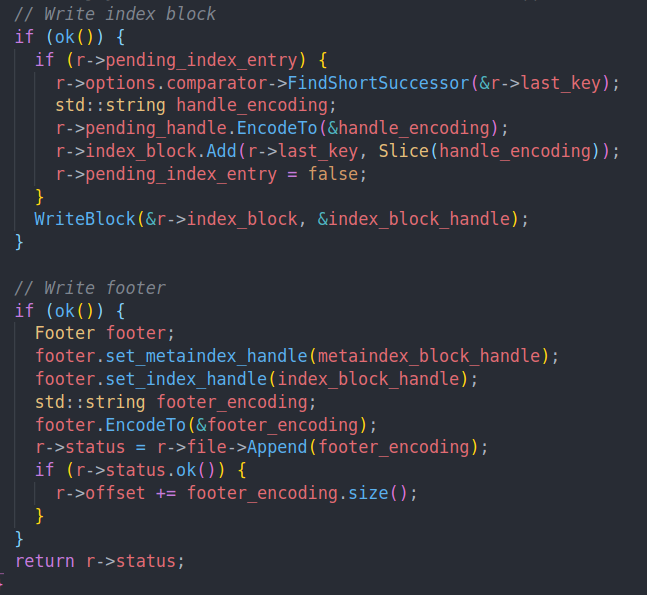
然后会再次插入最后的索引项。并把index block写入到sstable中。
并最后写入定长的footer。完成sstable的写入
有关一些特殊的变量,比如pending handle。他的作用是记录上次写入的data block的位置。这里的BlockHandle就是指向文件中的一块位置,也就是data block的指针。在插入索引项的时候,就会将这个指针作为value插入进去。
可以发现leveldb通过BlockBuilder来抽象这些kv表示的block。不只是data block中有restart point,在index block中restart point也是存在的。我们第一层先找到index block,然后根据restart point去找index,再根据index找到data block,从data block中的restart point去找key,最后再去遍历查找。有点高层的btree的感觉。
接下来看一下读SSTable
sstable主要是由若干个block组成的。打开SSTable的时候就会读取footer,然后将index block,以及filter block读出来。
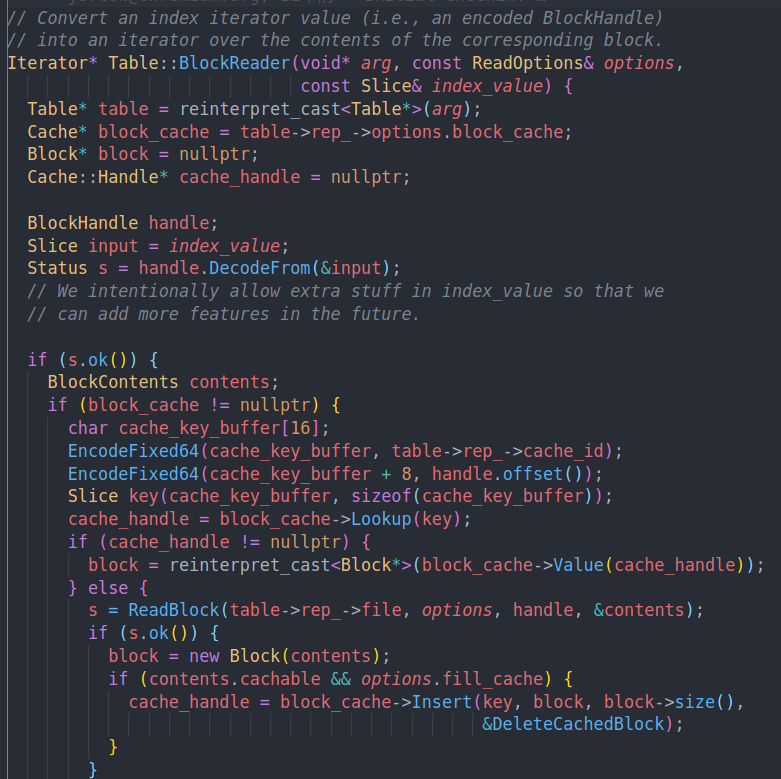
block reader的作用在注释中也有写,传入index value,也就是一个BlockHandle,然后返回一个在对应的Block上的迭代器。
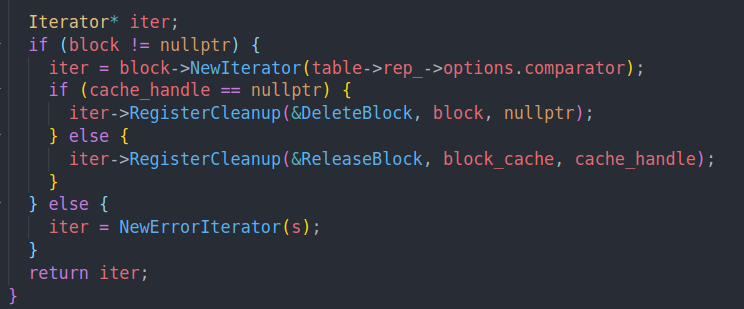
最后根据读到的Block创建迭代器。
这里的BlockIterator在之前的文章中有介绍过,这里就不再赘述了。
有关Cache的逻辑我们之后再系统的去看
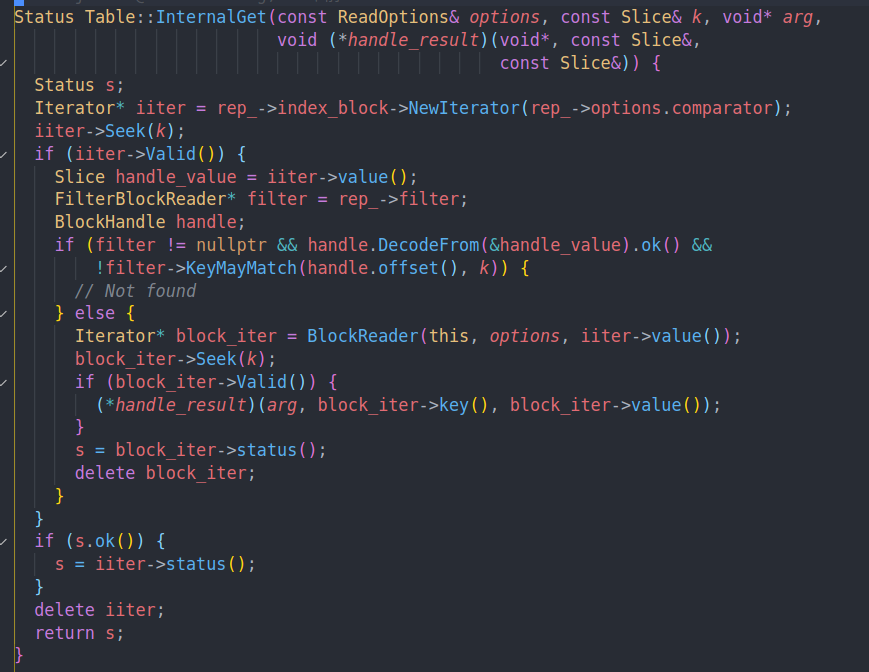
InternalGet就是读取的逻辑了
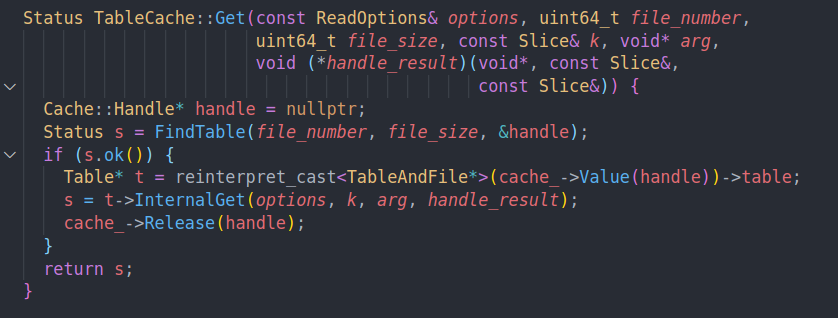
之前的TableCache中就有用到。从Cache中找到Table的metadata。然后通过InternalGet读到这个值。
先从index block中通过Iterator的Seek找到这个键。Seek的语义是找到第一个大于或者等于k的位置。也就是对应的data block的handle。
然后如果有filter的话就根据尝试过滤一下。这里传入了data block的offset,用作filter的index。
如果没有被过滤掉的话,我们就构建data block的iterator,然后找这个key
然后调用对应的handler来处理结果。
整体逻辑还是比较清晰的,但是Cache的地方还需要额外看一看

这里BlockReader这块,会注册删除iterator的时候的callback。如果不是从cache中读的话,结束后就直接把这个block删掉。如果是cache中读的话,读结束的时候,就把这个block从cache中unpin。从而允许被换出。

文章评论