SSTable(2) filter block
文档在这里
这次代码比较简单
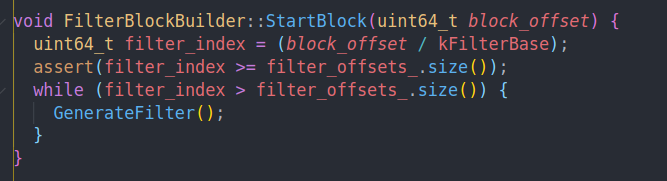
StartBlock的作用就是不断构建索引到filter offsets
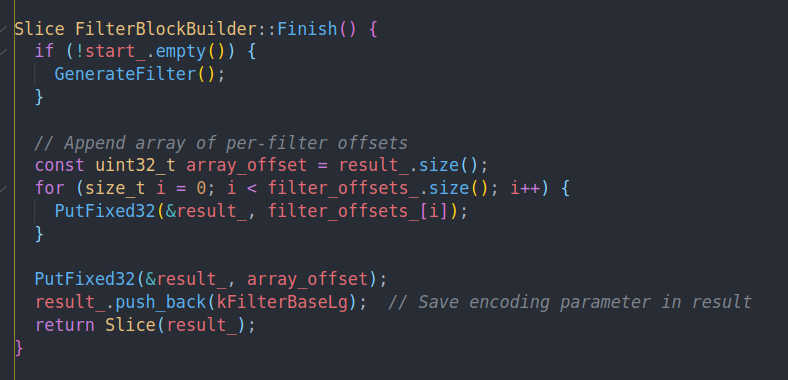
Finish会把剩下的数据的filter构建出来。然后把每块对应的offset追加进来,最后加上总共的array length以及BaseLg。具体含义可以看文档
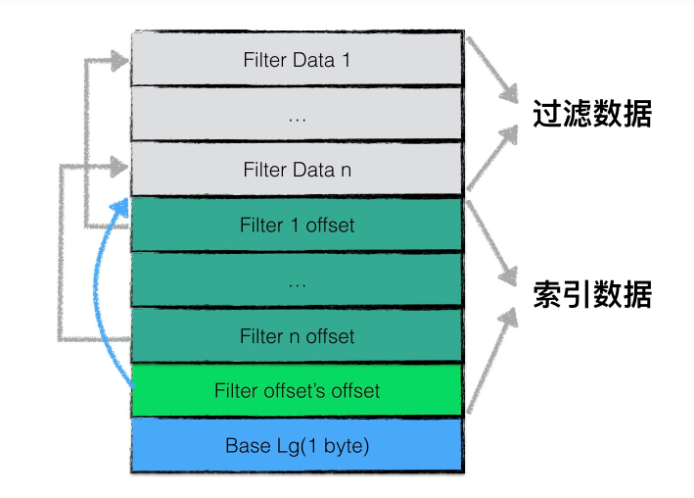
result就是这些data block
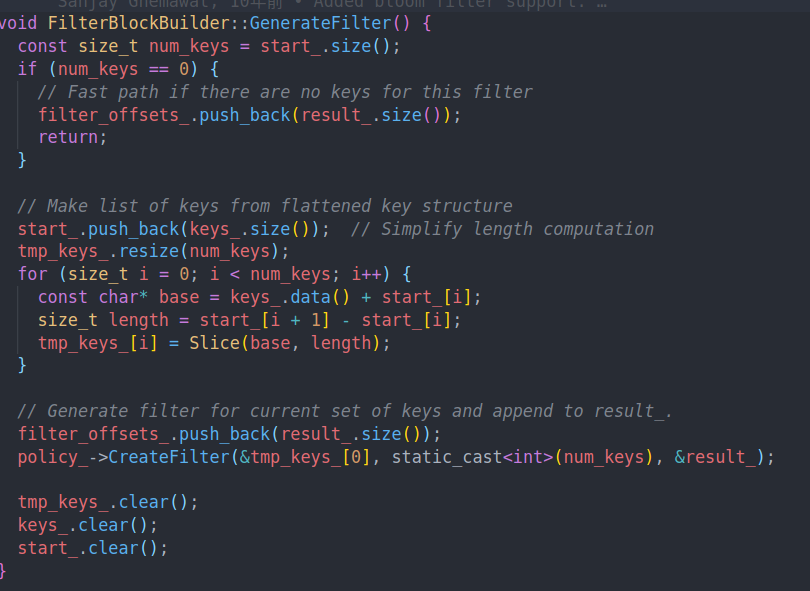
可以看到核心的逻辑就是这个GenerateFilter了。他会先把当前的buffer切成原本的key。然后通过CreateFilter创建filter
这里的CreateFilter就是创建bloom filter了,代码也比较简单
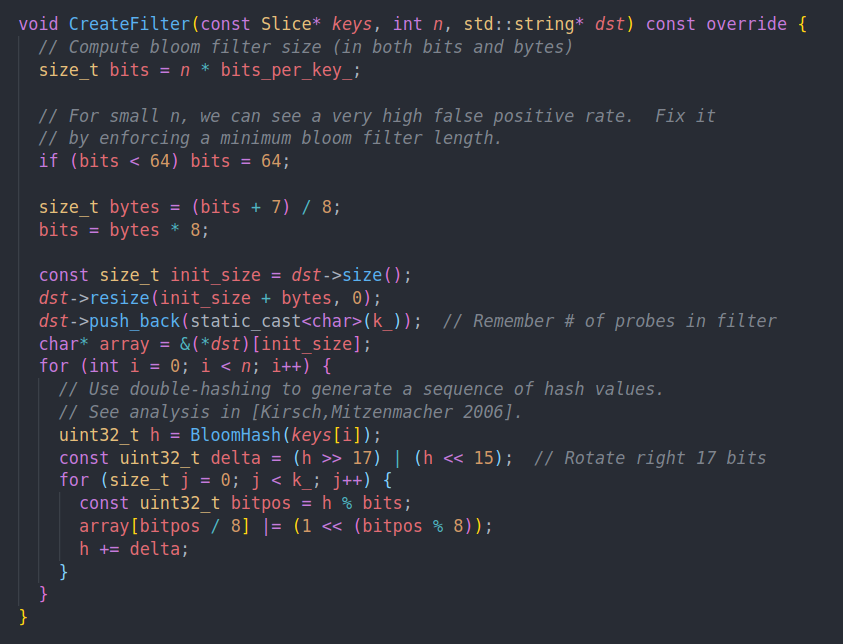
计算本次bloom filter需要的大小。就是bytes,然后resize为他分配空间
布隆过滤器在文档中也有写,在这里
k表示哈希函数的个数,插入到过滤器的尾部。
遍历每个key,这里是通过double hashing来生成若干个哈希值,而不是通过不同的哈希函数。根据代码可以看到,一个key走一次BloomHash,生成h。后续的哈希值都是通过原有的哈希值进行变换得到的。也就是说如果两个值的h生成的是相同的话,那么他们就会完全冲突。
直觉上讲,只生成一个哈希值感觉冲突会很高。但是换个角度我们可以这样看。我们将一个key,通过k个哈希函数,相当于是向k个1维空间做投影。得到k个数字。这里生成一次哈希再去做投影,所以其实是一样的,只不过这几个空间有一定的关联。
检查的逻辑也比较简单
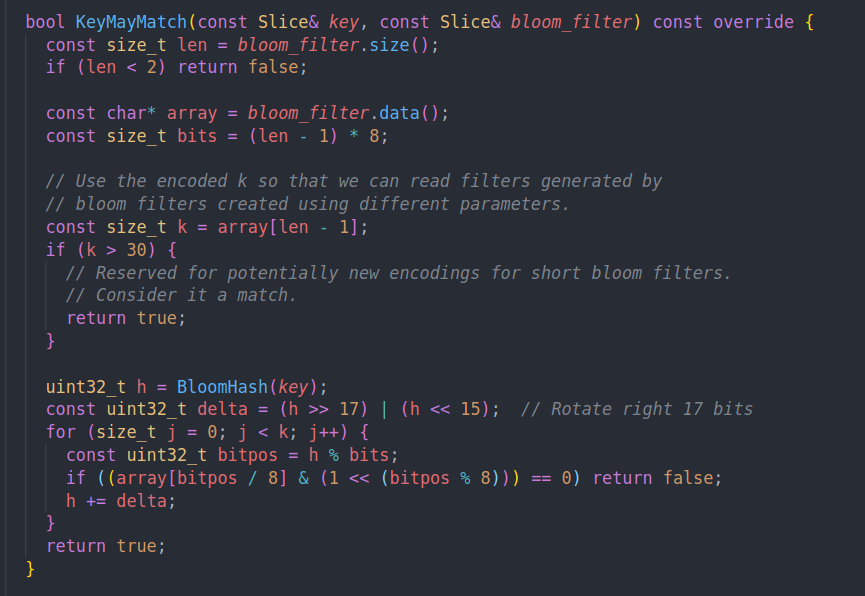
k作为最后一个byte存在。然后按照刚才的哈希方法,只要发现了有位不匹配就返回false
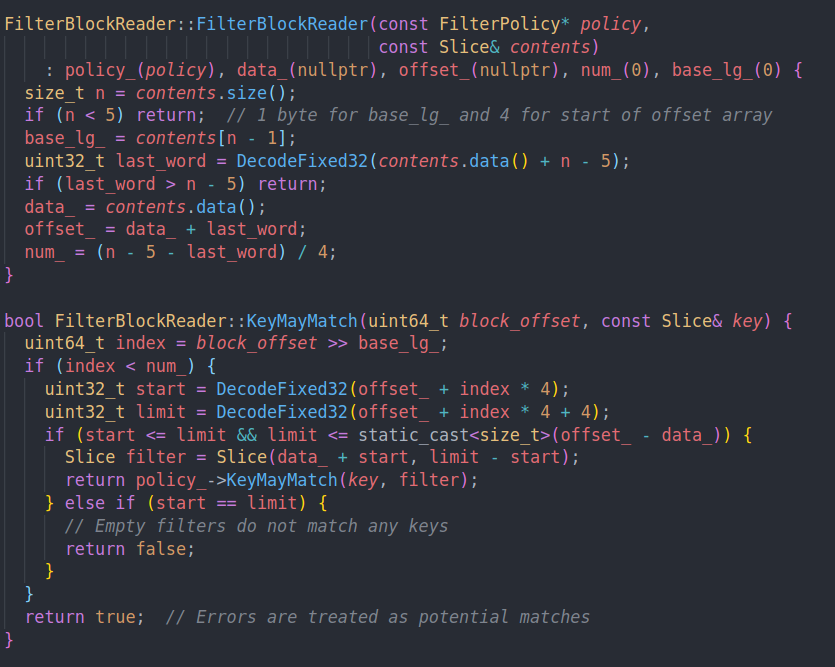
最后是filter block的读取
data就是布隆过滤器,offset则是布隆过滤器对应的offset,num则是布隆过滤器的数量
检查key是否match的时候,会先根据block offset来找到对应的布隆过滤器。然后调用刚才说的KeyMayMatch进行具体的判断。
构建filter block是根据data block来构建的。也就是说一个data block可能对应一到多个filter block。我目前的理解就是查找filter block的时候,是根据data block的offset来确定的,这个具体的过程还是要看table builder。之后的文章会讲具体的映射过程。

文章评论