Cache
这次看看Cache
和文档中的不同,文档中的这个是goleveldb的。而我们看的是C++的leveldb
C++的leveldb就是一个简单的LRUCache
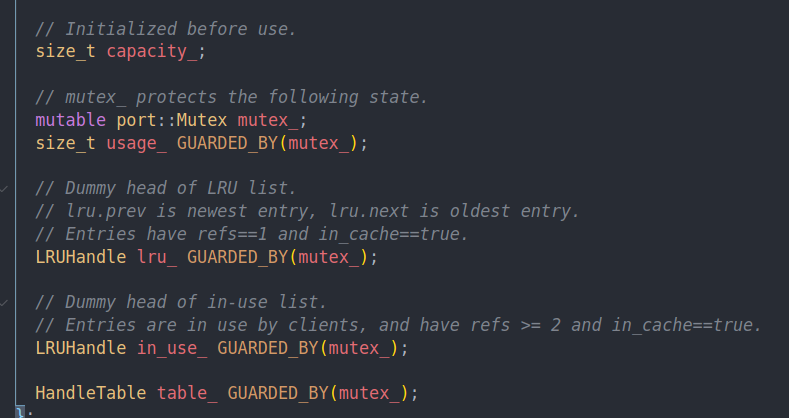
并发控制通过一个大mutex来保护。为了减少冲突分了Shard
不过leveldb中的LRU是intrusive的,他的Node内嵌了list和hashmap的变量
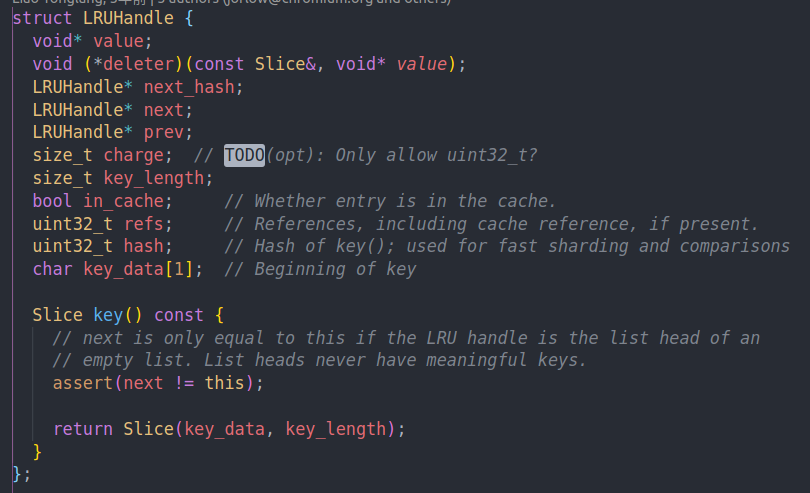
LRU的主体在这里,其中HandleTable是一个哈系表,由key映射到Handle上
lru和in use其实可以猜到,一个是lru的链表,一个是当前使用的,也就是pin住的链表
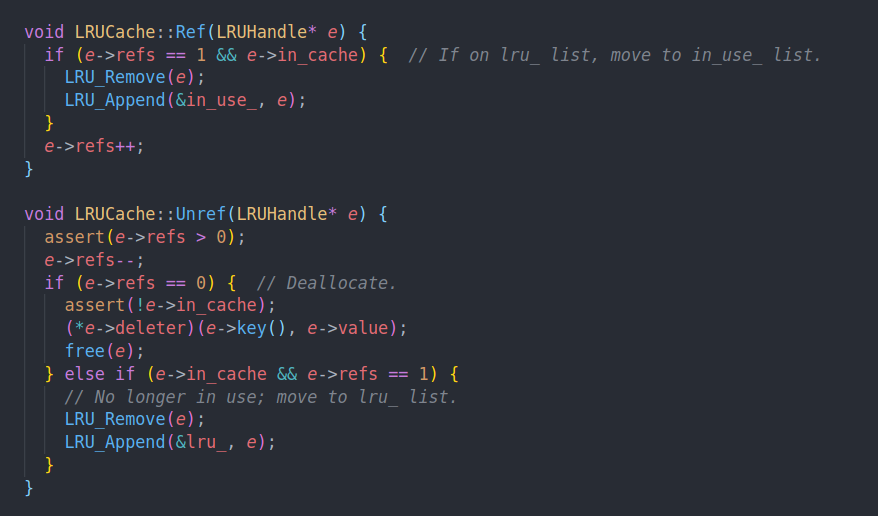
ref和非ref的作用就是把handle从list中摘掉,然后插入到in use中
有点不同的是leveldb不仅仅把refcnt交给用户使用,他自己也会用一次。在insert的时候,他会主动增加一个refcnt。表示这个handle在链表中。
当这个handle被evict的时候,就会主动调用Unref,减少他的引用计数。从而完成释放。
基本上就是这两点。剩下的就是平常的LRU了。即intrusive node,以及自己实现的引用计数来控制节点的生命周期。incache项则用来debug
LRU看完之后,看一下Leveldb是怎么用这些Cache的
leveldb中的Cache有两种。block cache和table cache
block cache负责缓存某个块。在打开一个table的时候,会为其分配一个unique的cache id,标识这个table。某个block的key则是由他的table id加上block handle offset来决定的。
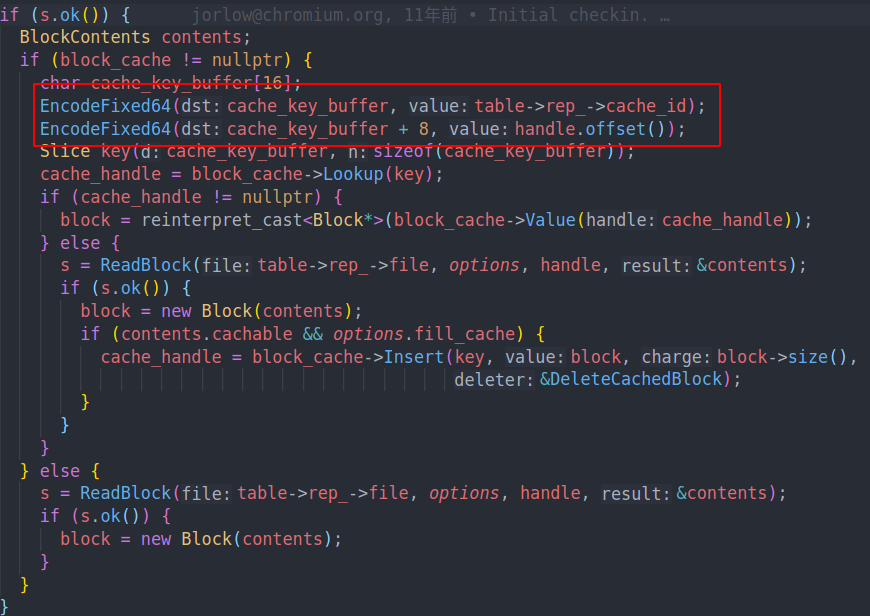
在尝试读取block的时候,就会先尝试从LRU中获取这个block。如果找到的话我们就可以直接使用。否则的话就需要从文件中读取,然后再根据配置去填充这个缓存项。
在iterator中的删除方式也有所不同。如果我们没用缓存的话,删除的时候就是直接delete掉这个block
如果用了缓存的话,则是减少对应的引用计数。而具体释放block的操作则在insert处。注册了deleter,会做真正的删除。LRU会在evict这个block的时候调用deleter
另一个cache则是table cache。table cache是固定存在的,不像block cache可以配置。生命周期和整个db一样长。
table cache缓存的是table的元数据。这样我们就不需要每次读取table的时候都去open他。这样在读取的时候我们真正需要做IO的就只有index block和data block了,并且读取这两个block的逻辑是相同的
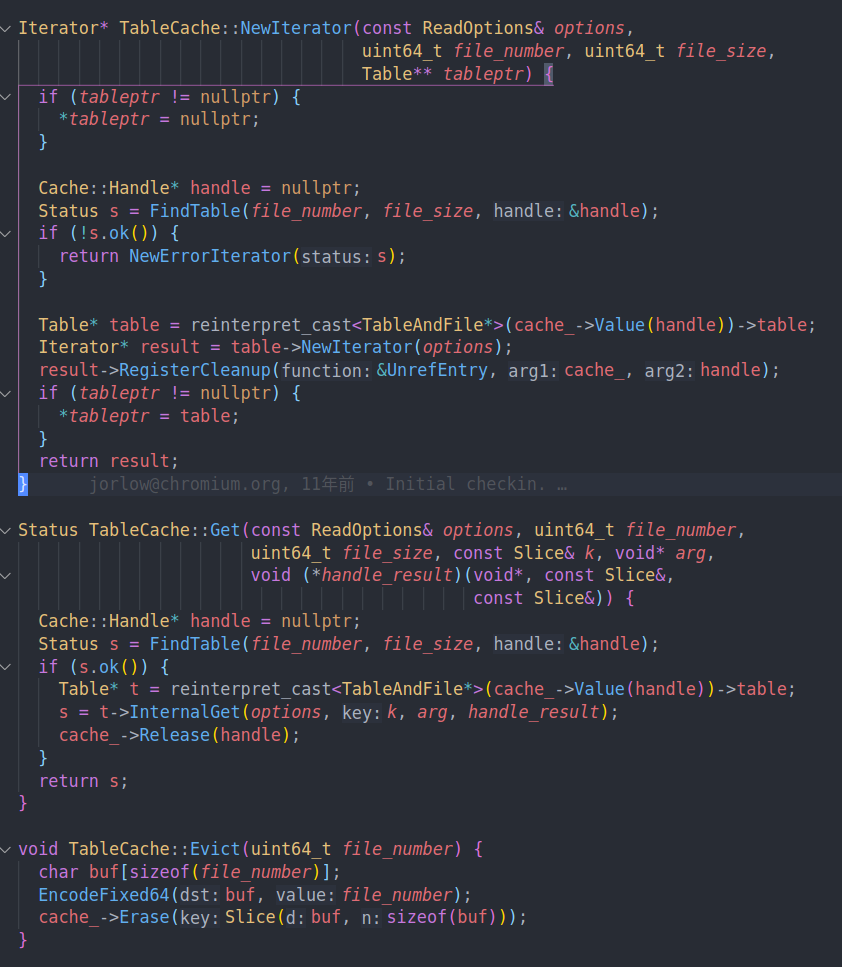
读取的时候对外的接口主要都是由TableCache来提供的。这里的Get就是读一个值,在之前我们解析的时候看到过。现在可以完整的串下来。
FindTable会在没有找到这个Table的时候读取这个Table,并插入到LRU中。使用结束后会调用Release减少引用计数。
NewIterator则是提供遍历Table的接口。并在iterator删除的时候减少对Table的引用计数。
为什么table接口对外这么简单?因为sstable只读,要么就是单点读,要么就是range读,也就是iterator扫描。
返回的这个Iterator叫做two level iterator。也就是之前说的两层,第一层是index iterator,第二层才是data iterator
这两个iterator都是iterator wrapper,wrapper的作用就是提前缓存key和valid,因为我们在外面会频繁调用这两个函数。缓存起来可以直接返回,而不需要再去调用block iter的对应函数,减少一次虚函数调用。

文章评论