Log
这一次来看看日志,参考文章在这里
leveldb不提供事务,所以我们不必记录undo log来保证事务原子性。但是需要提供redo log来保证数据是持久化的。
每次写入write batch到memtable之前,要先将操作写入到日志中。保证写操作在之后是可以redo的。
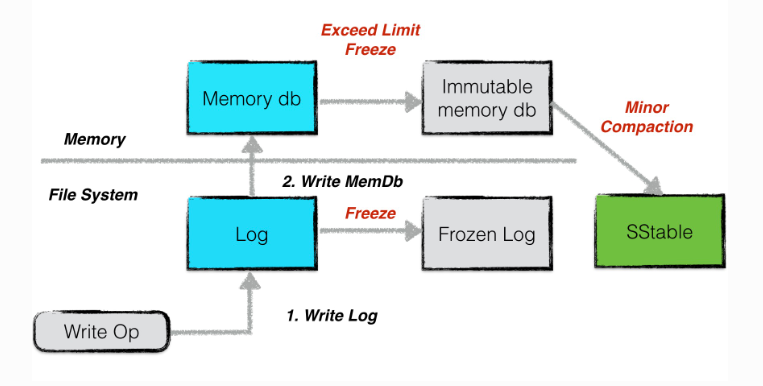
在将memory db冻结成为immutable memory db后,对应的日志文件也会被冻结。然后通过minor compaction将immutable memory db写入成SSTable后,冻结的log就可以被删除。因为他对应的数据已经被持久化为了SSTable。
这个immutable memory db的设计非常棒,可以保证我们在进行minor compaction的时候不会停止服务。
日志的结构是按照block来划分的。

每个block都是32kb大小。(我个人感觉除了为了对其磁盘块就没有其他的意义了,对齐磁盘块可以更高效的进行读写,以及删除)
每个block都对应了若干个chunk。其中有4中类型的chunk,分别是first,middle,last以及full。具体可以看参考文章中的定义。
写日志的代码在log_writer.cc中。在之前写操作流程的时候,就有看到过写入日志的调用。核心就是AddRecord
这个函数思路很简单,就是尝试将当前的log写入到block中,如果满了就开一个新的block。直到写完为止。
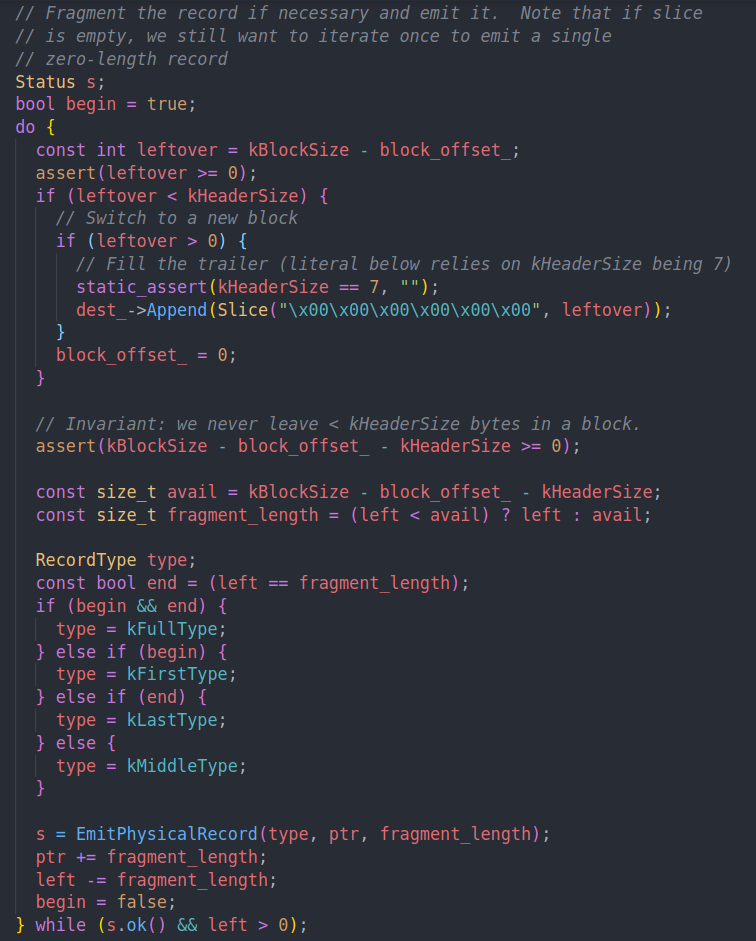
是do while,所以即便是left为0我们也会先写一次。
leftover取到当前block剩下的空间。如果不够一个header就补零,然后开一个新的block。
avail为真正存储数据的空间。然后根据本次日志的情况去设定type。最后写入到日志文件中。
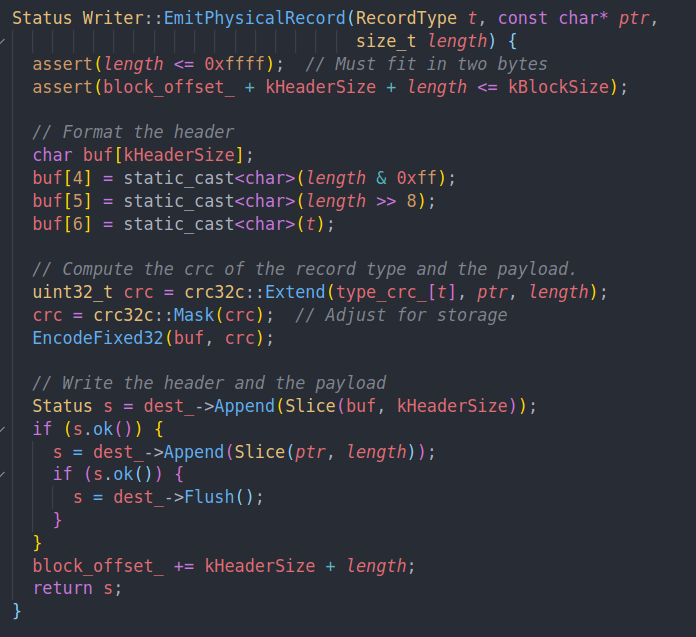
前4位是checksum,4和5位是长度。最后一位是类型。
计算crc,然后编码到前4位中作为校验码。然后append到日志中。就完成了一个chunk的写入。
如果option中有sync的话,我们会在完成所有写入后调用sync。而不是在AddRecord中调用sync
读日志则是在dp_impl.cc的RecoverLogFile中
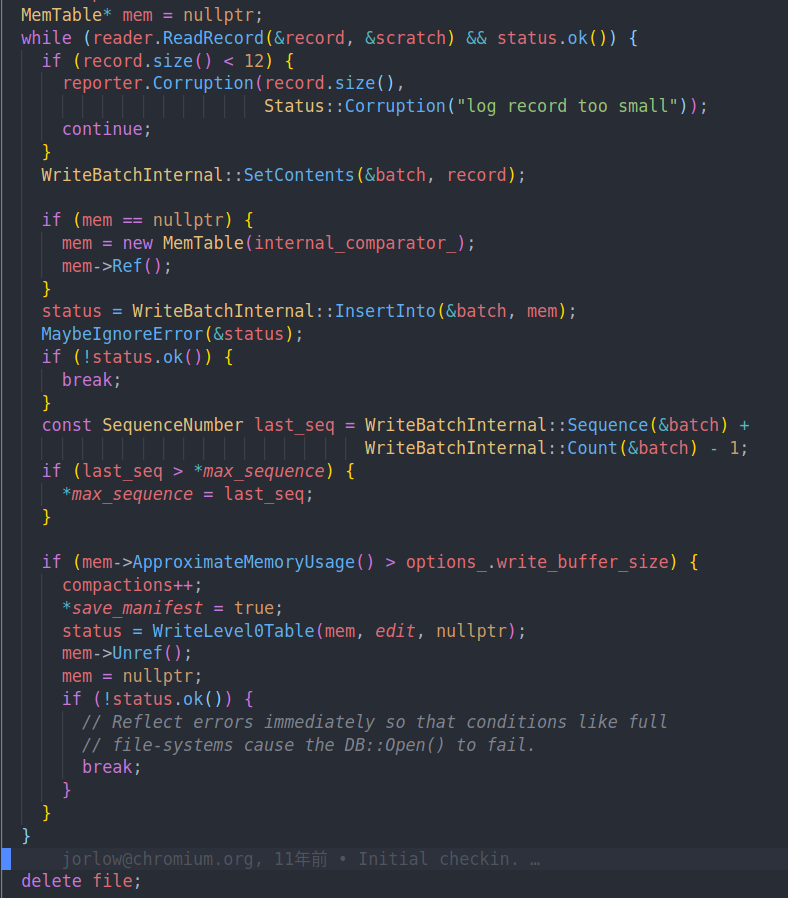
恢复日志的过程。scratch的作用就是作为一个string buffer,用来拼接log,log record会引用他来表示数据。
log中的数据会被恢复成WriteBatch的数据,然后插入到memtable中。
过程中不断更新max sequence number。并且在memtable过大的时候触发minor compaction。也就是将memtable写入到level0 SSTable中。这是因为我们可能在写入之前冻结的SSTable的过程中崩溃了,导致之前的log没有被截断。从而需要在恢复的过程中进行compaction。(一个问题是为什么不通过seqence number去判断log是否被持久化呢?我们可以遍历最新的SSTable去尝试找到最新的sequence number,然后跳过被持久化的数据)
读逻辑在ReadRecord中
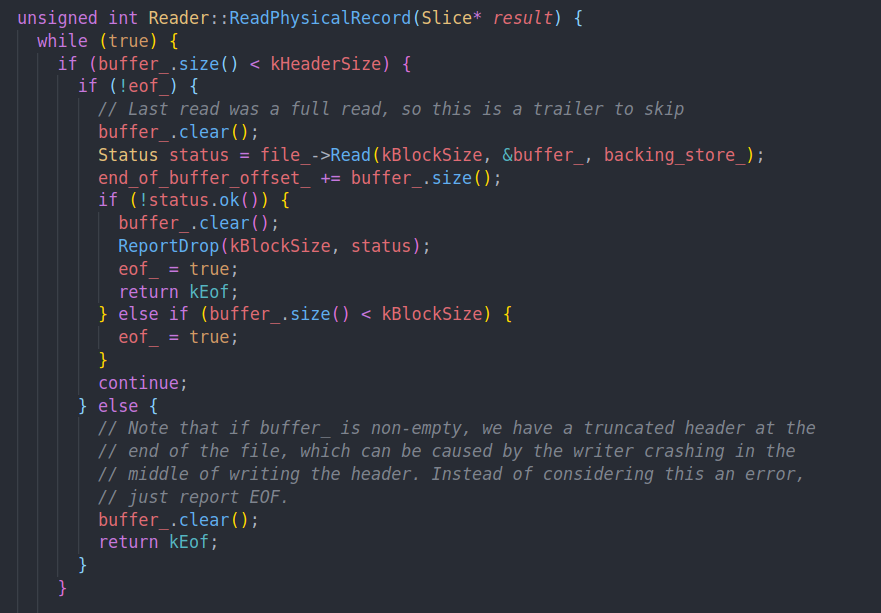
从文件中读32kb数据存到buffer中。如果buffer大小不够header size的时候就重新读。
然后每次调用会解析一个log record,具体来说就是读取长度并存到result中。并将type返回给上层做拼接。
然后我们会计算crc并和读取到的crc做对比。从而确保数据没有损坏。
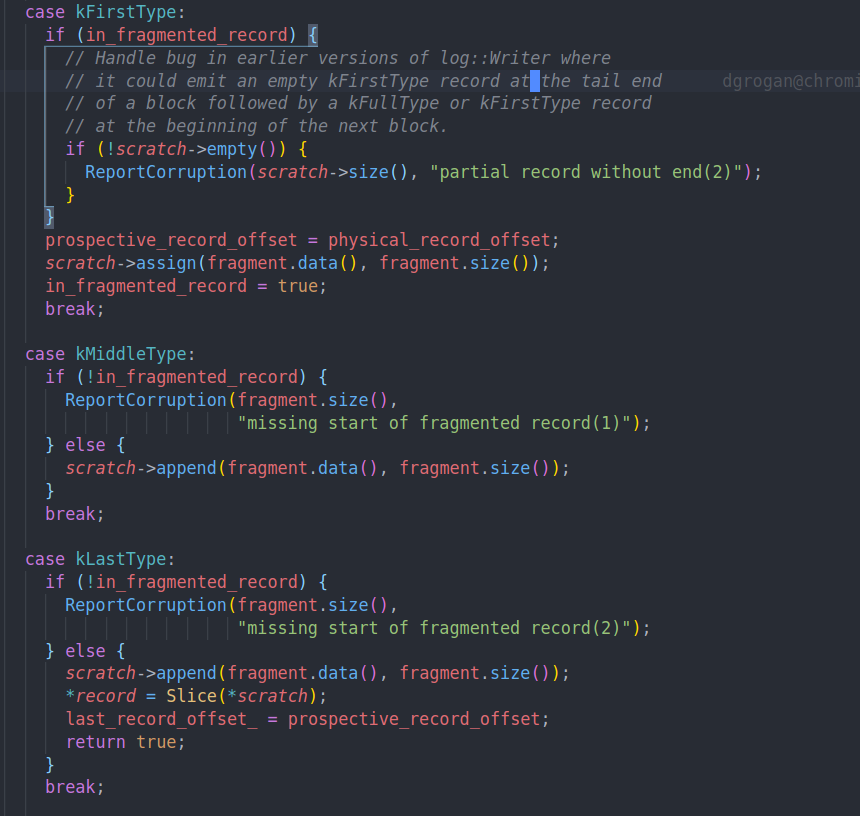
比如遇到middle type和last type的时候,我们要把数据append到一起将log重组。
读取的过程中会维护读取到的偏移量。从而跳过初始的record。这个我目前感觉作用不是很大就看得比较简略。

文章评论