Memtable
这次到了memtable中,也就是leveldb的内存中数据结构
跳表的思路就是通过概率来进行平衡,而非平衡树那样强制平衡。从而使得我们的实现可以简化很多。
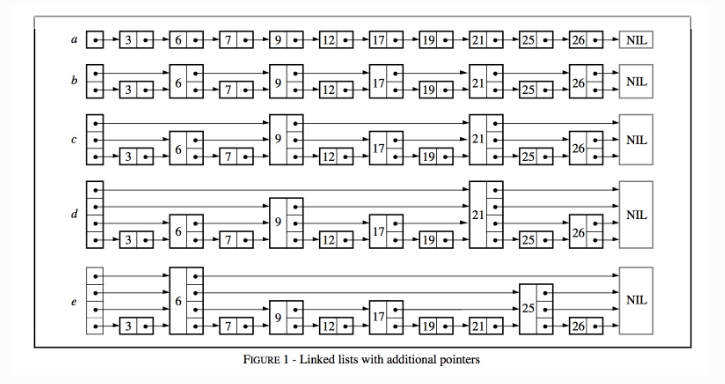
上面这个例子就是增加指针的链表。让我们可以稳定按照2的次幂的步数进行跳跃。但是缺点就是很不容易处理,因为插入的时候要去仔细计算我们跳过了多少节点,从而判断是否增加额外指针。
一个拥有k个指针的结点成为k层结点。50%的结点为1层节点,25%的结点为2层节点。如果保证每层结点的分布概率相同,则仍然可以拥有相同的查询效率。

有关更加细节的讲解可以看参考文章。这里我们开始看代码
skiplist是在skiplist.h中实现的,提供的核心接口就是Insert,以及Iterator
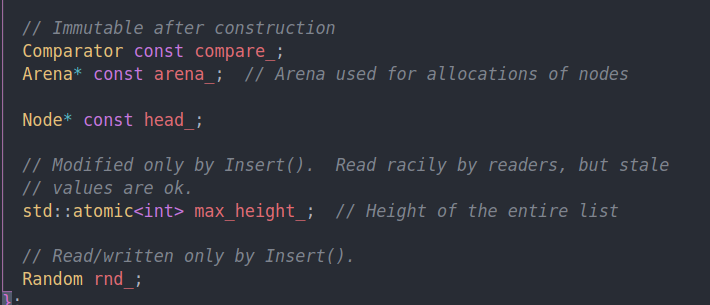
compare是用来比较的functor,核心在他的类型。
arena是用来分配内存的结构。head为链表头。
max height是最大高度。我们会在插入的时候更新最大高度。这样读取的时候才能根据最大高度去遍历。读到stale value是没关系的,相当于没有读到这个新的node
rnd则是用来生成随机数,在构建新结点的时候使用。
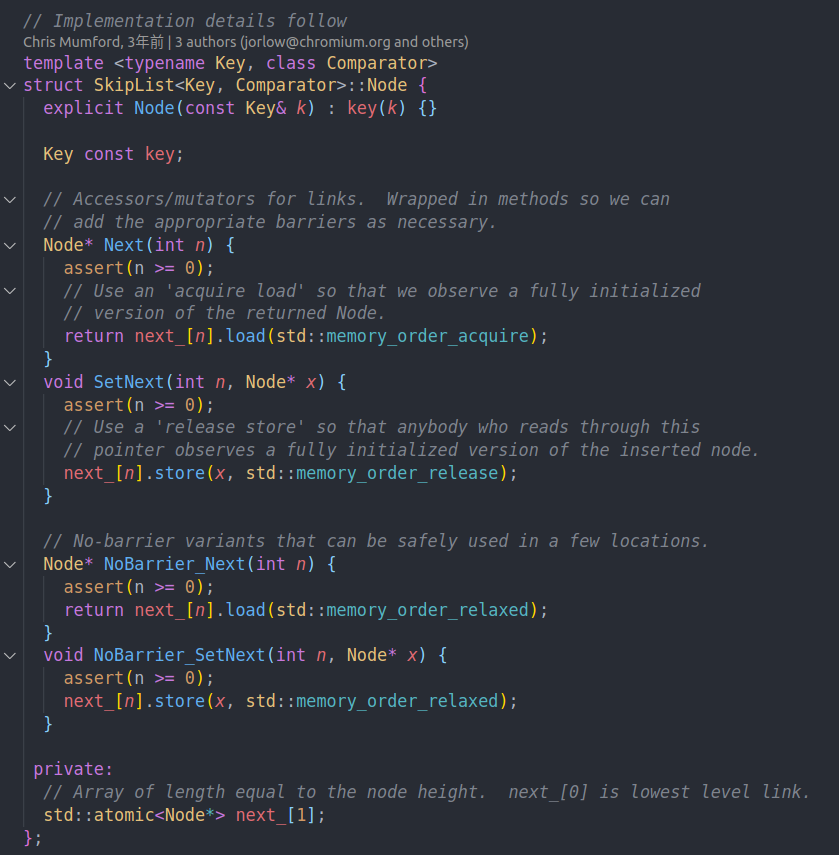
每个节点的结构。每个节点有k个指针。表现为atomic<Node *>。这里他初始化只有一个。在分配节点的时候我们会多分配对应个数的内存来存储其他层的指针。(感觉用弹性数据更直观)
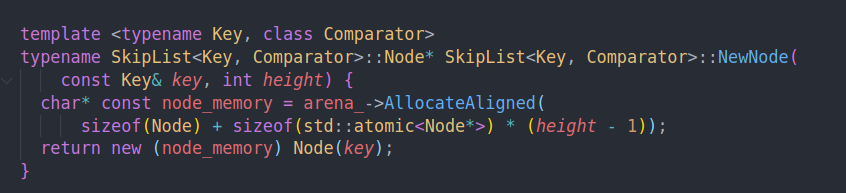
看起来leveldb很喜欢用这种placement new,这样我们可以通过不同的arena来实现不同的分配方案,从而加速分配。
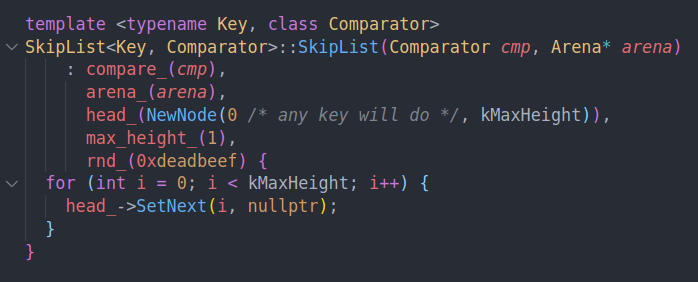
构造函数,head作为dummy node。简化空链表时候的操作。
为什么设置的时候不用Relaxed语义呢?应该是为了保证后续的操作可以立刻看到head的值。
跳表的insert是基于find的,所以先看find
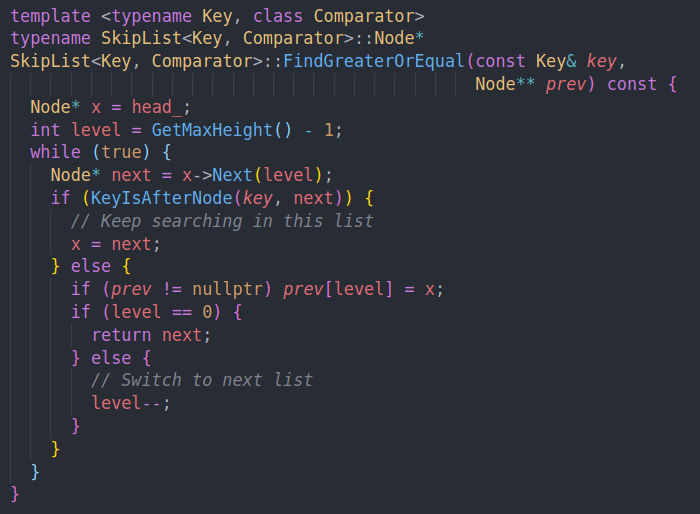
lower bound的语义。先尝试获取当前层的下一个结点。如果下一个结点超过了key,则我们不能跳过去。继续在当前结点的底层进行查找。否则的话就跳到下一个结点中。同时在切换层的时候要记录这一层的上一个结点。插入的时候使用。如果层数到0了,则直接返回,因为我们不能再减少层数进行细粒度的查找了,并且key在x和next之间。由于我们的语义的大于等于,所以返回next。
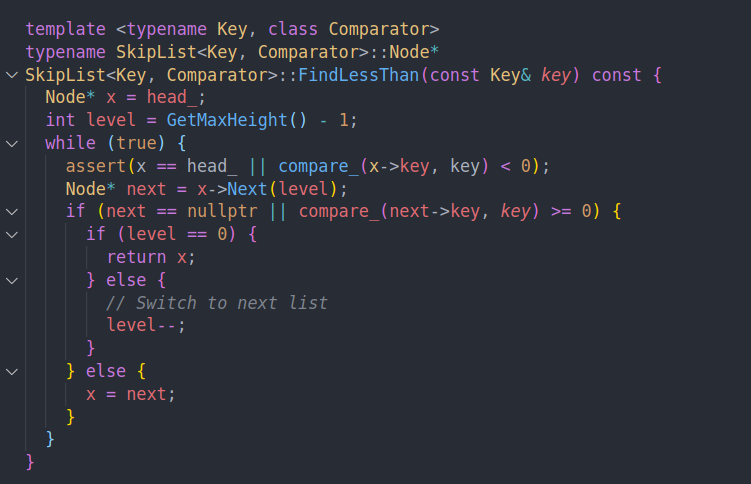
另一个相似的过程是less than。这里的判断和上面的完全相同。只不过在层数为0的时候返回的是x而非next。因为通过这个过程查找,即我们不断让next逼近小于key的最大值。这样最后level0的时候,大小关系就是x < key < next,然后根据需要选择x或者next就行。
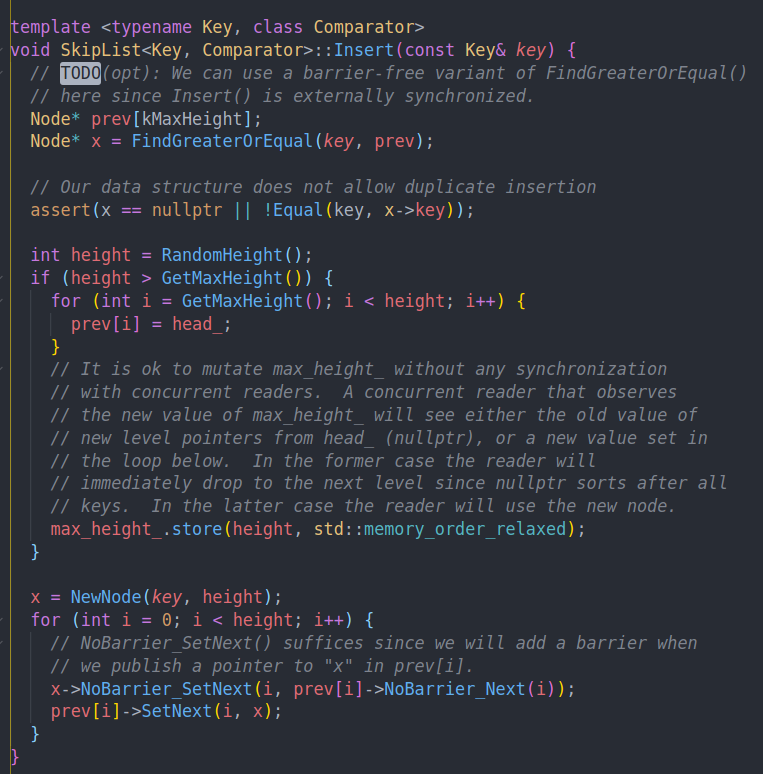
看一下插入。通过之前的Find找到的是大于key的最小的值,为x
然后随机一个高度。并在这个height大于max height的时候更新他
最后插入到链表中,就是正常的链表插入。对每一层都执行一次就行。不过这里用的是relaxed语义的插入,因为最后的SetNext会帮我们添加barrier。这里注释说的也很清楚。
对于max height的更新,读到旧值也没关系,因为最多就是在下一层多跳一次,即少一个shotcut。
写线程在读prev的next结点的时候完全不用担心读到stale value,因为leveldb只有一个线程在写。设置好x后通过release语义把它安装到链表中就可以。
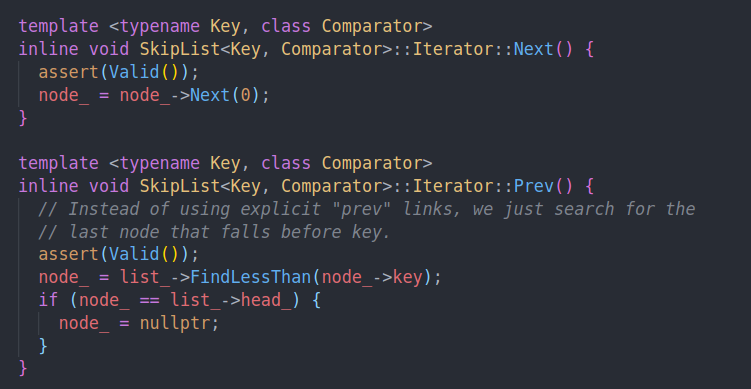
有关迭代器的遍历。初始化是通过上面的Find来实现的。而对于Next,就直接找第0层的下一个指针就可以。对于Prev,由于我们不是双向链表,所以是通过重新查找实现的。所以逆向遍历会慢一些。(因为lock-free的双向链表比较难实现)
可以看到整体的逻辑还是比较容易的。核心的代码就是Find和Insert。
为什么不实现成侵入式链表?因为没意义。侵入式链表用在单个节点存在于多个链上,导致一个链表内是数据,另一个是指针。所以可以通过侵入式链表来让数据和指针存到一起,从而减少一层indirection。
对于memtable,实际上是对skiplist的一个封装
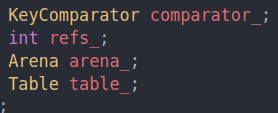
可以看到其实就多了一个comparator
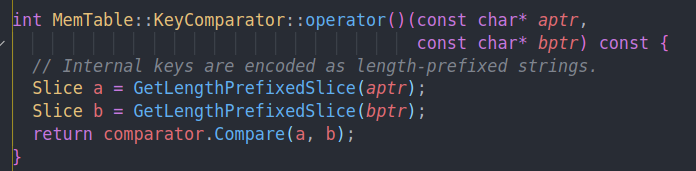
comparator的作用也很简单,就是比较两个slice。根据internal key的格式。即开始比较key,相同的key则比较sequence number。
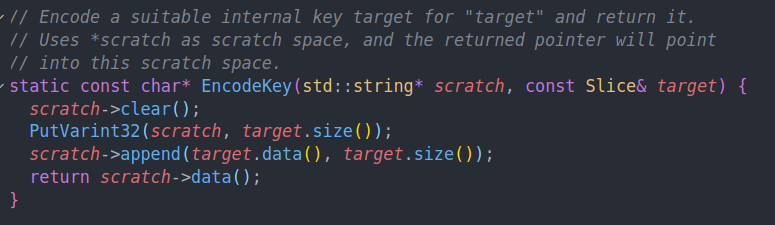
EncodeKey的作用就是将target编码成LengthPrefixedSlice。用来传入给skiplist做比较

skiplist中的key是一个两个length prefixed slice组成的字符串。我们只会用第一个去比较,也就是internal key
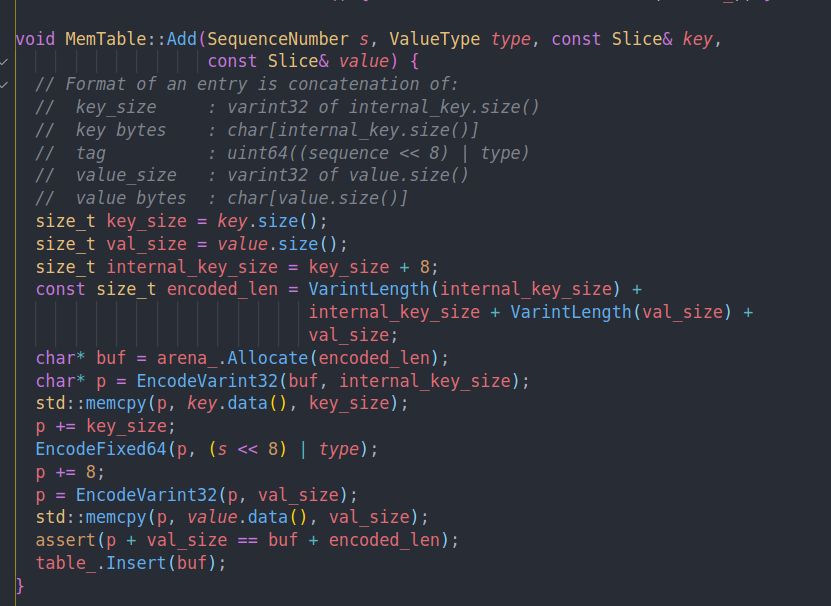
add就是将传入的key,value等信息按照上面说的编码起来传给skiplist
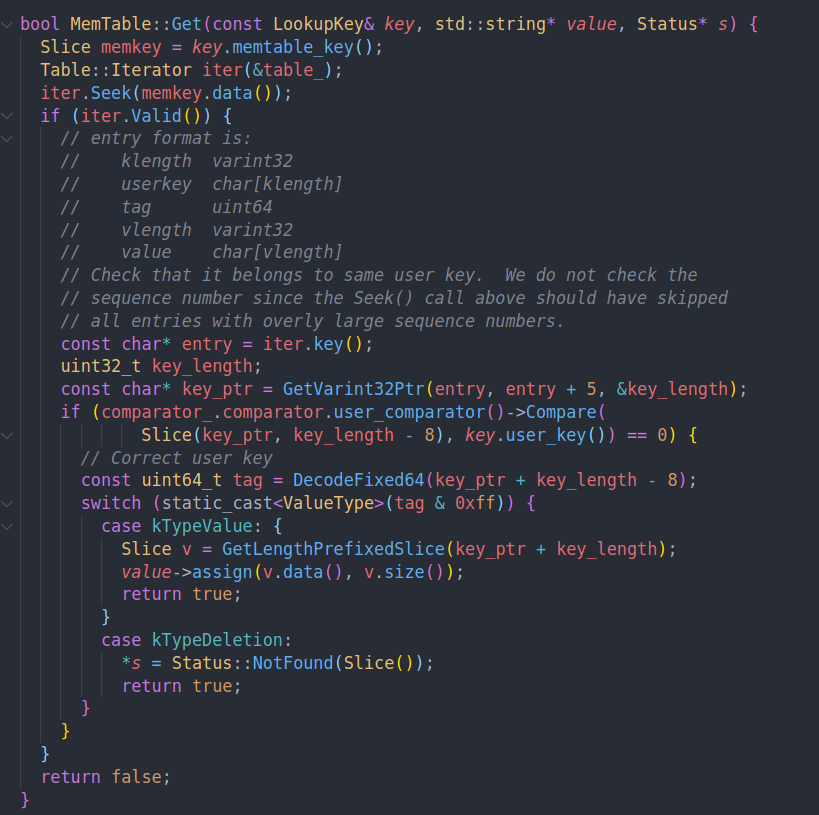
而get则是根据传入的key通过iterator找到对应的结点。然后按照原本的方式将value解码出来。
这里会通过user comparator比较一下传入的key和找到的key,确保相同。最后根据tag返回结果。因为这里的seek是lower bound语义,所以可能找到的key不是相同的。但是我们不需要保证sequence number完全相同。只要保证读到的值的seq number比传入的小即可。由于internal key中,seq number越大值越小,所以我们得到的iter的seq number一定小于传入的。所以只需要最后检查一下user key

文章评论