Read
这次参考的文档还是读写操作。主要看一下读的过程

在db_impl.cc中的Get是读的核心逻辑
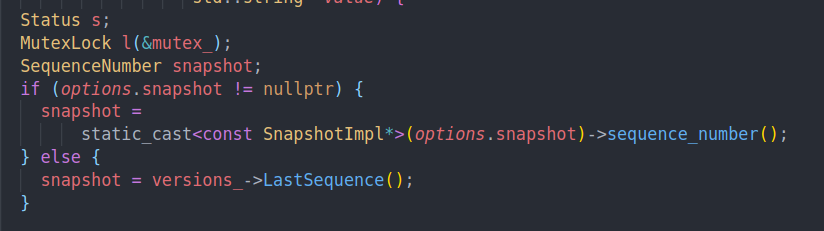
如果选项中确定了要读的snapshot,我们就拿到这个sequence number,否则的话就获得最新的sequence number
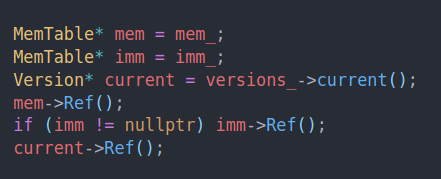
目前还没有仔细看version的结构,但是根据代码大概可以看出来。我们拿到当前活跃的memtable,不可变的immtable。增加他们的refcnt。这样可以防止我们在访问这个数据结构的时候他被其他线程删除掉。
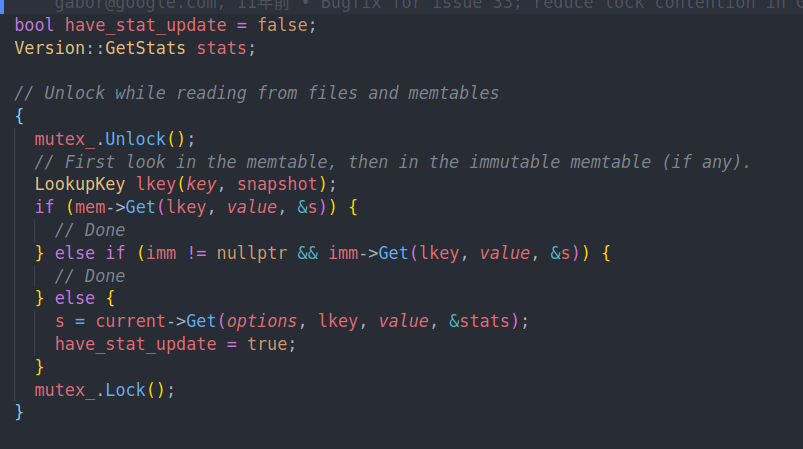
先尝试从memtable中读。如果成功的话就返回了。
否则的话尝试从immtable中读。这两个都是内存中的skiplist。
其中lkey就是将用户的key以及sequence number组合到一起成为internal key的格式。
如果内存表找不到的话,就尝试在sstable中查找。这里我们就会从version中调用Get尝试读取了。
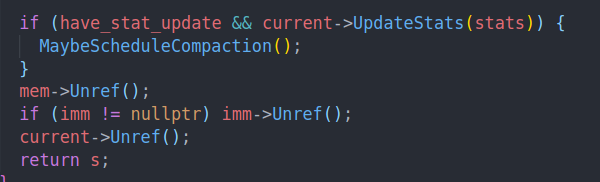
最后收尾工作,减掉refcnt,并且更新当前version的status。这里由于leveldb会统计读数据,从而进行compaction(在之后compaction中会说到),所以读完之后更新当前的统计数据,并在可能的情况下调度一次Compaction。
好奇的话可以看这个
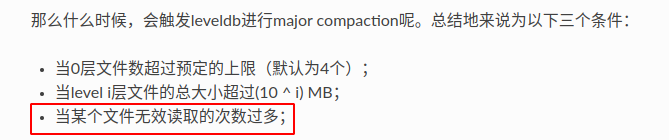
然后来到version中看他读取SSTable的逻辑
match的作用就是判断是否可以匹配。传入的arg就是一个state,用来记录当前匹配的状态,以及一些需要用到的元数据。
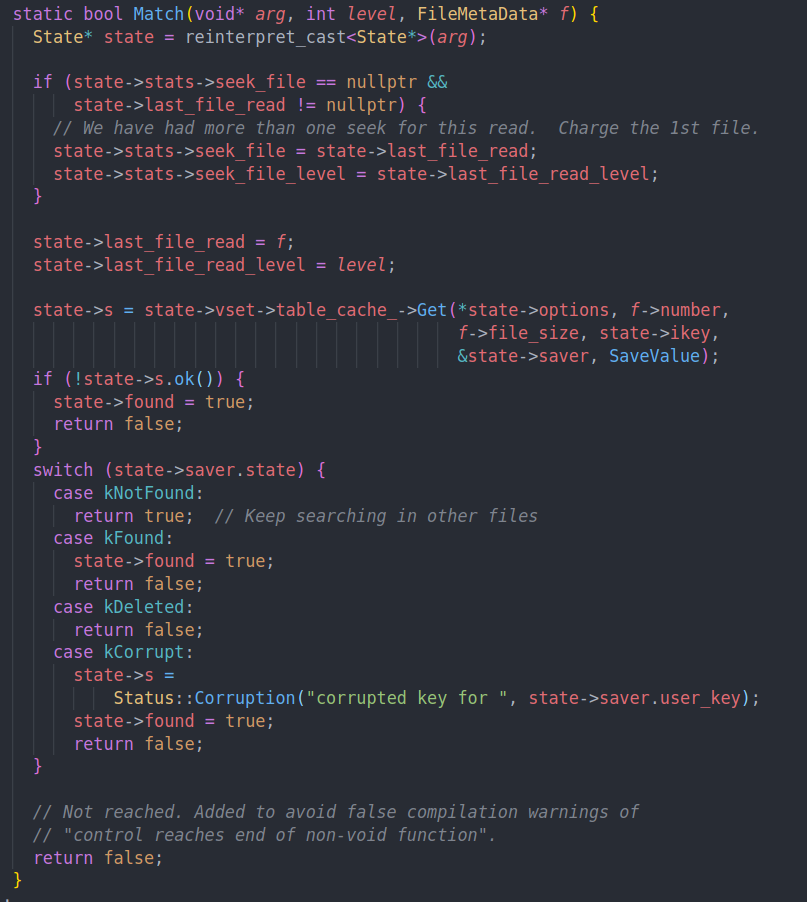
可以看到主要的匹配是调用table cache的get。match中传入的文件元数据就表示了本次匹配需要的文件数据。传给Get会让他通过元数据的file number找到具体的文件
这里通过FindTable找到对应文件号的文件。并将数据缓存起来放到LRU cache中。可以确定的是数据中有文件的元数据,在打开Table的时候会读取他的索引块。之后也会看到具体的实现。
然后通过这个InternalGet去匹配数据,并在发现匹配的时候调用handle result。这里的Release就类似Unpin,减少refcnt,从而允许缓存项被置换出去。
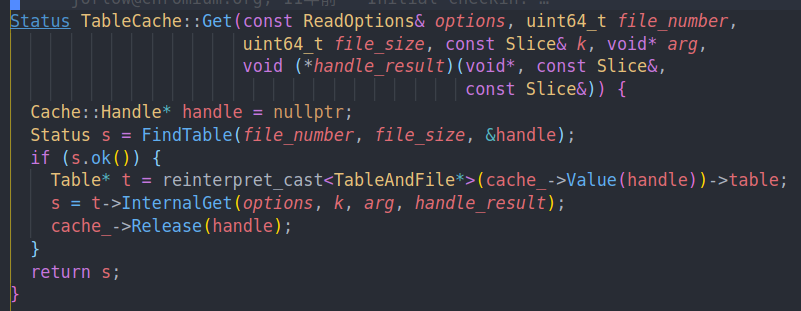
在刚才的Version的Get的最下面,会调用ForEachOverlapping,他会遍历所有的SSTable,并尝试通过Match去匹配他们。
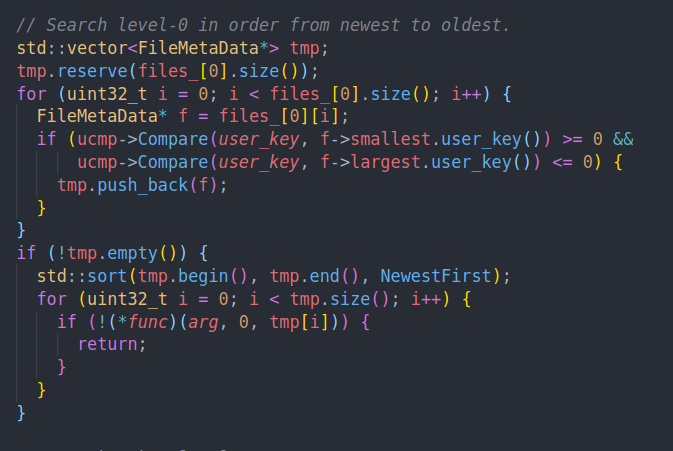
可以看到FileMetadata中还有文件的最大和最小键。我们从新到旧查找满足条件的文件,并用上面的Match去匹配他们。
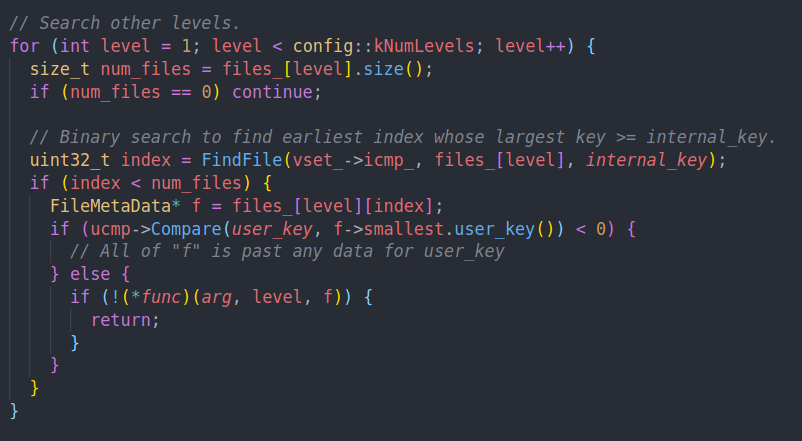
对于高层的SSTable来说,每一层最多只有一个文件可以匹配成功。所以这里通过二分找到符合条件的文件,并通过Match尝试匹配。成功匹配的第一个文件就会直接返回结果。从而完成本次读取。

文章评论