整理几个核心的设计点
两种format:
* E4M3,适合权重和activation
* E5M2,适合梯度
The recommended use of FP8 encodings is E4M3 for weight and activation tensors, and E5M2 for gradient tensors.
This is consistent with findings in [20, 16], where inference and forward pass of training use a variant of E4M3, gradients in the backward pass of training use a variant of E5M2.
设计尽量贴近IEEE-754
* 逻辑更容易实现
* 依赖IEEE754的性质的实现还可以继续用,比如可以通过整数操作来做比较和排序
For example, IEEE floating point formats allow comparison and sorting of floating point values using integer operations. The benefit of increasing the maximum value from 448 to 480 for DL is not significant to warrant deviating from IEEE convention and losing software implementations that rely on it.
E4M3为了更大的范围,没有编码infinity
* IEEE754中应该是通过特殊的指数位来编码的infinity
* E4M3中,exp=1111是作为特殊值编码的
* 1111.111是NAN,其他的1111.xxx都是可以作为普通数值的。
* 而IEEE754中,1111.xxx都不是普通数值。所以多出来7个可以额外表示的数字。最大范围也从240变成了448
By contrast, the dynamic range of E4M3 is extended by reclaiming most of the bit patterns used for special values because in this case the greater range achieved is much more useful than supporting multiple encodings for the special values.
Exponent bias保留了IEEE的标准,而不是做成可编程的机制:
* 回忆一下exponent bias,是指数位的偏移。用来表示负的指数
* 改变exponent bias的本质是移动可表示范围。而这件事可以通过scale factor来做,并且更加灵活
* 同时部分情况还需要per tensor的偏移。
Leaving the per-tensor scaling to software implementation enables more flexibility than is possible with a programmable exponent bias approach the scaling factor can take on any real value (typically represented in higher precision), while programmable bias is equivalent to allowing only powers of 2 as scaling factors.
和FP16中的loss scaling比较像的是,FP8并不是直接转化后就结束了,而是也需要乘一个scaling factor,把数值移动到FP8更加适合表示的区间中进行计算,结束后再放缩回去。
* FP16中使用的遇到overflow后就跳过参数更新并不适合FP8,因为FP8的范围更窄更容易出现overflow
* 所以溢出的时候会转化成最大的可表示值
* 额外的放缩开销可以接受,因为对于计算密集型的任务来说,这里增加的计算量很少。对于memory bound的任务,这里没有影响。
Higher precision values need to be multiplied with a scaling factor prior to their casting to FP8 in order to move them into a range that better overlaps with the representable range of a corresponding FP8 format. This is very similar to the purpose loss-scaling serves in mixed-precision training with FP16, where gradients are moved into FP16-representable range [14],[13]
Values that overflow are then saturated to the maximum representable value.
Weight update skipping (and reduction of the scaling factor) on overflows, as used by FP16 automatic mixed precision training [13], is not a good choice for FP8 as overflows are much more likely due to the narrower dynamic range, resulting in too many skipped updates
For matrix multiplications, unscaling is applied once per dot-product, thus amortized by many multiply-accumulates with FP8 inputs. Less arithmetic intensive operations (such as nonlinearities, normalizations, or weight updates by optimizers) are typically memory-bandwidth limited and not sensitive to one additional arithmetic instruction per value.
这里只定义了format,没有定义具体的行为。比如:
* 高精度到FP8转化的时候,如果出现溢出,是什么行为?
* saturating conversion,变成FP8的最大可表示值
* non saturating conversion,变成NaN/Inf
* 高精度转化到FP8的时候,如何做舍入。Rounding mode
* nearest-even,确定性的选择最近的
* stochastic rounding,随机选
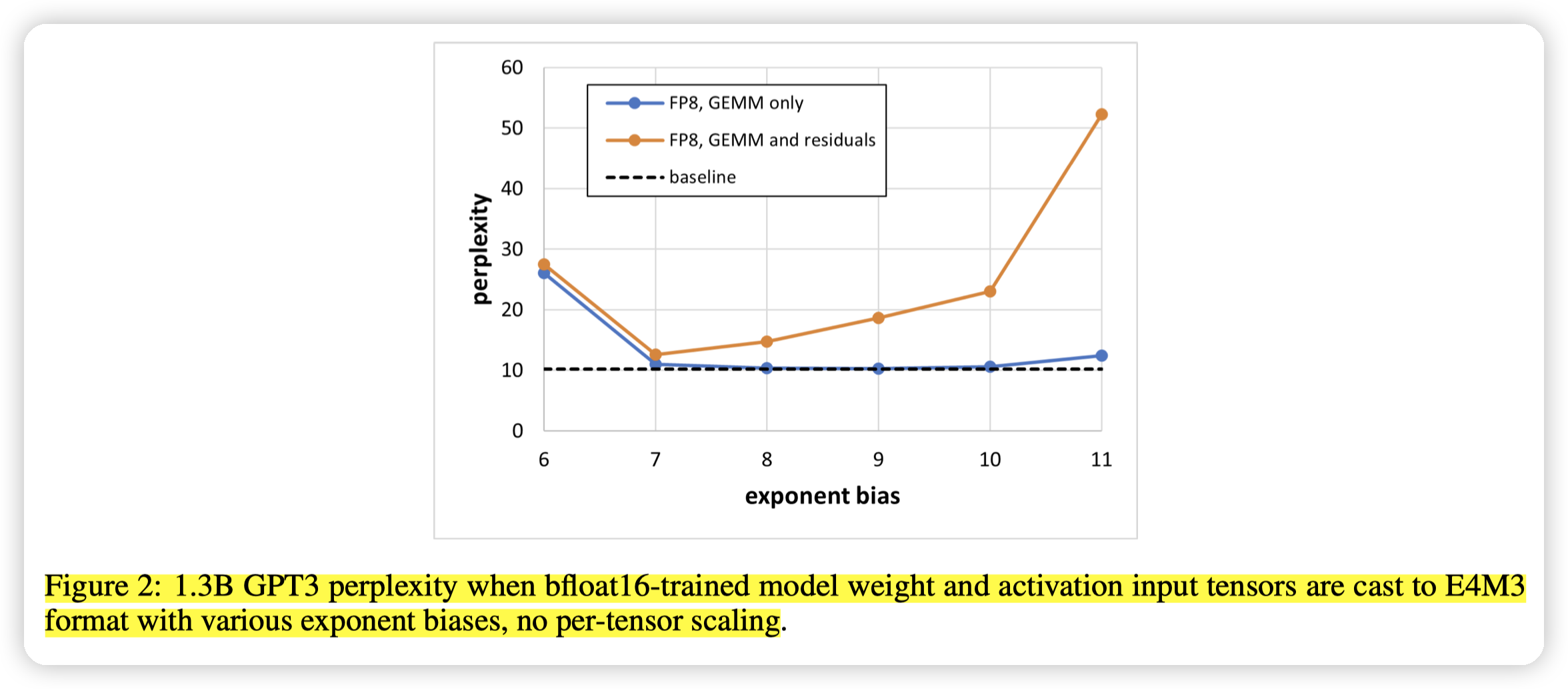
when casting to FP8 only the inputs to GEMM operations (both weighted GEMMs as wells as two attention batched matrix multiplies that involve only activations), several exponent bias choices in the [7, 10] range lead to results matching the bfloat16 baseline
then no single exponent bias value leads to sufficient accuracy - even exponent bias of 7 results in perplexity of 12.59 which is significantly higher (worse) than 10.19 for the bfloat16 baseline.
引入GEMM和residual的时候(网络更复杂的时候),没有一个很好的exponent bias可以保证精度。而只有GEMM的时候,7到10这段区间效果都还可以。
同时也提到了如果做per-tensor scaling的话,效果会好很多。所以这里也说明了per tensor scaling的关键性

文章评论