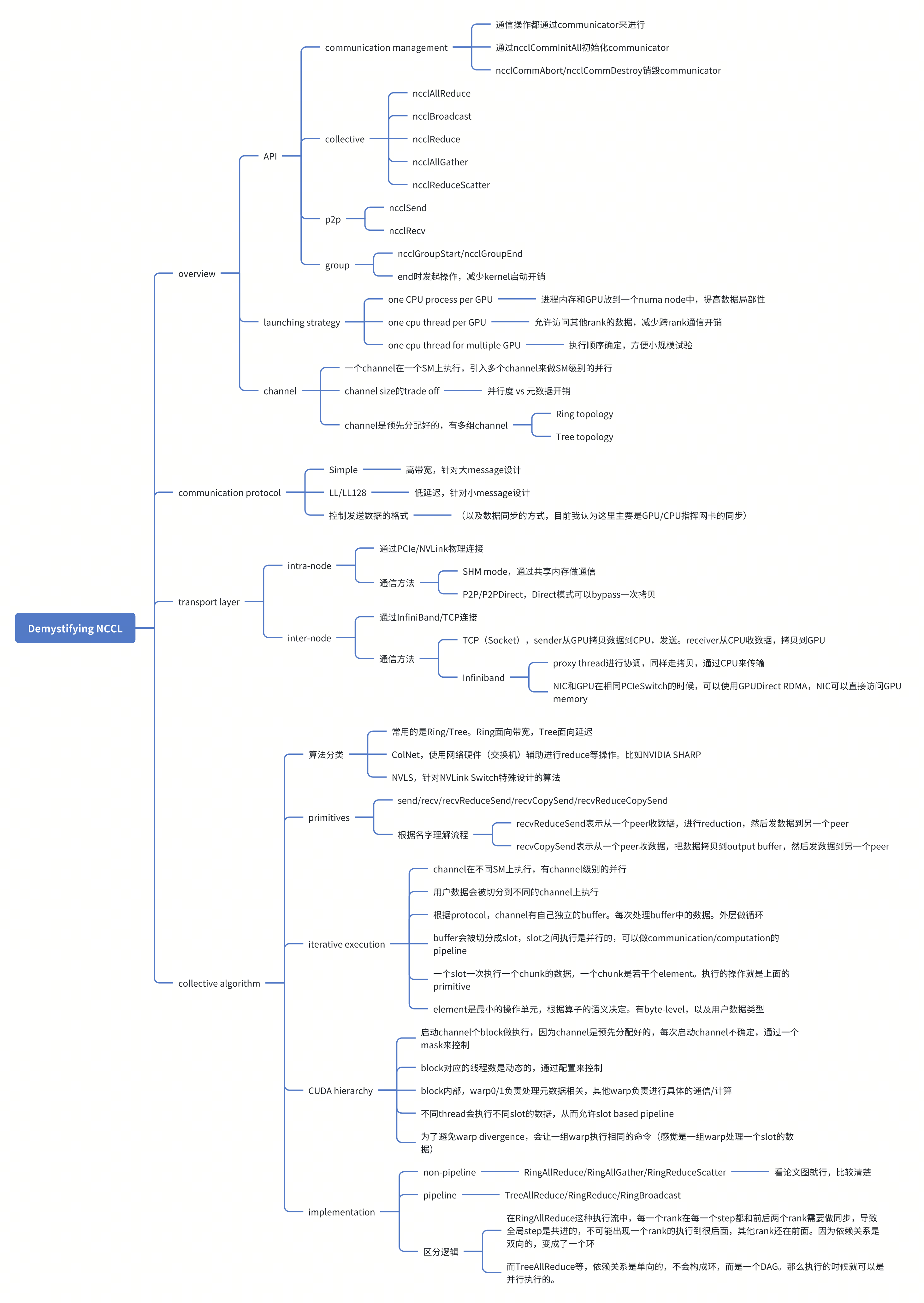
Overview
- API
- Communication management
- 通信需要通过communicator来进行。ncclCommInitAll来初始化communicator
-
ncclCommDestroy用来销毁一个communicator,会等待pending operation
-
ncclCommAbort立刻销毁communicator,取消pending operation,用来避免死锁
-
Collective communication
- ncclAllReduce, ncclBroadcast, ncclReduce, ncclAllGather, ncclReduceScatter
- 点对点
- ncclSend, ncclRecv
- Group calls
- ncclGroupStart/ncclGroupEnd
-
用来聚合一批操作,直到ncclGroupEnd的时候才发起操作。
-
用于减少kernel启动的开销
- Communication management
-
Launching Strategies
- One CPU process per GPU
- 一个进程的内存可以放到一个numa中,提高数据局部性
- yy一下就是放到和对应GPU pcie对应的numa block中,这样做GPU/CPU的通信更高效
- 一个进程的内存可以放到一个numa中,提高数据局部性
- One cpu thread per GPU
- thread在同一个进程空间,允许跨越rank访问内存(包括GPU的buffer),减少rank之间通信带来的内存拷贝
- One cpu thread for multiple GPU
- 简单,执行顺序确定,用来做小规模的实验
- One CPU process per GPU
- Communication channels
- nccl会协调三个硬件,GPU,CPU,NIC。
-
当只使用一个SM的时候,可能会出现SM的瓶颈(因为GPU上需要做data movement + reduction),导致无法利用好NIC
-
所以NCCL引入了channel,每个channel是在独立的CUDA block上,有独立的SM。同时nccl lib会切分input buffer,让不同的channel可以操作不同的chunk,并行执行。
-
无脑增加channel的数量也不好,会导致chunk变小,引入padding,导致低利用率。所以nccl有一个启发式的算法,会根据通信的数量大小调整channel size
-
communicator初始化的时候,会初始化一组channel,由nccl的策略,和集群拓扑决定。后续通信的时候就会使用这些预先构建好的channel
- Ring topology的channel中,每个GPU会记录他的前一个和后一个节点
-
Trree topology的情况下,每个GPU会记录parent和child
-
从这里也可以看出来,确实执行collective的时候,是会影响性能的,因为也需要SM来执行collective,同时需要的SM也不一定少。
- 所以做communication/computation overlap也需要更细粒度的控制,并不是无脑做overlap的
Communication Protocols
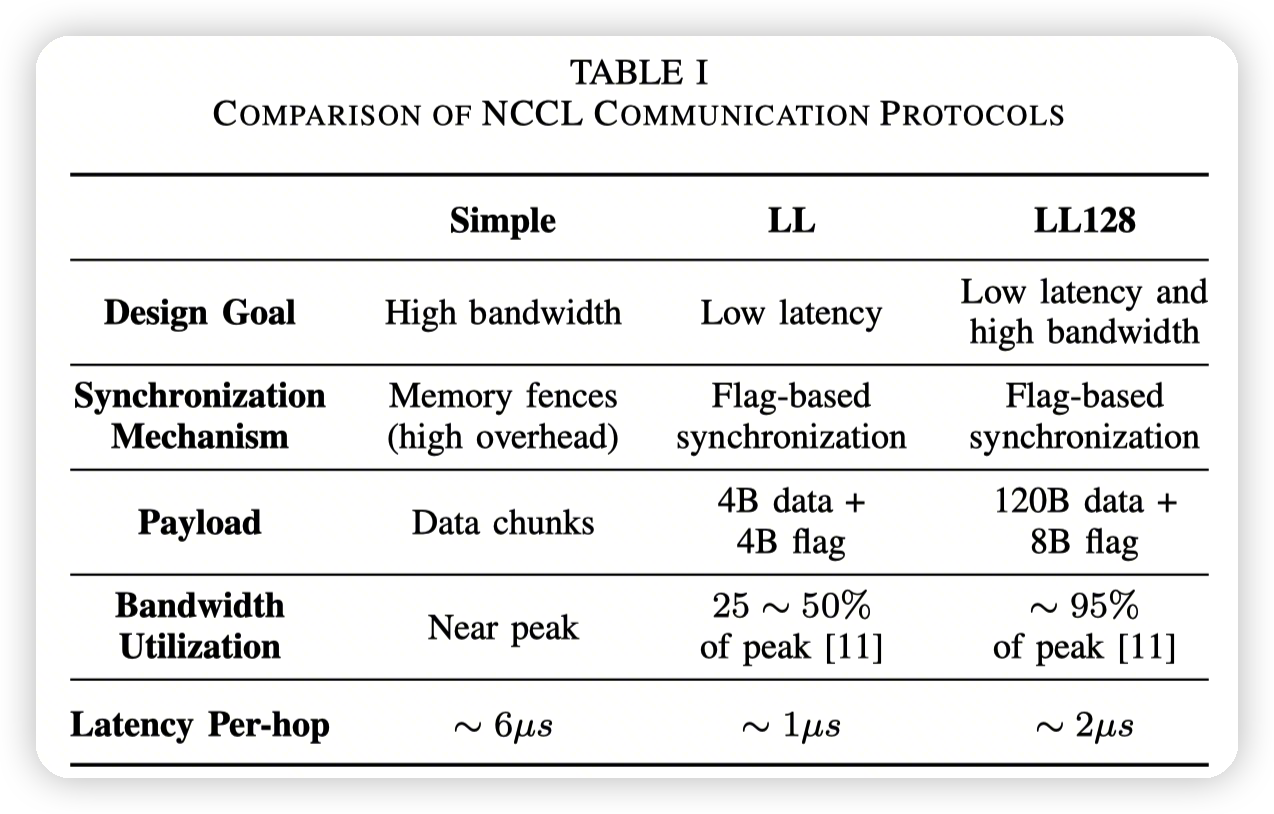
LL是low latency的意思
- Simple Protocol
- 针对最大化带宽来设计
-
使用memory fence来进行同步。
-
后面讲了一些设计,有点不太确定这里具体是在说哪里的问题,以及这里说的同步具体是谁和谁的同步(好像是CPU驱动NIC的操作和GPU prepare data)。不过直观感觉就这里并不需要上层开发者关心太多,所以先放一放在这
data transfer methods and transport layer

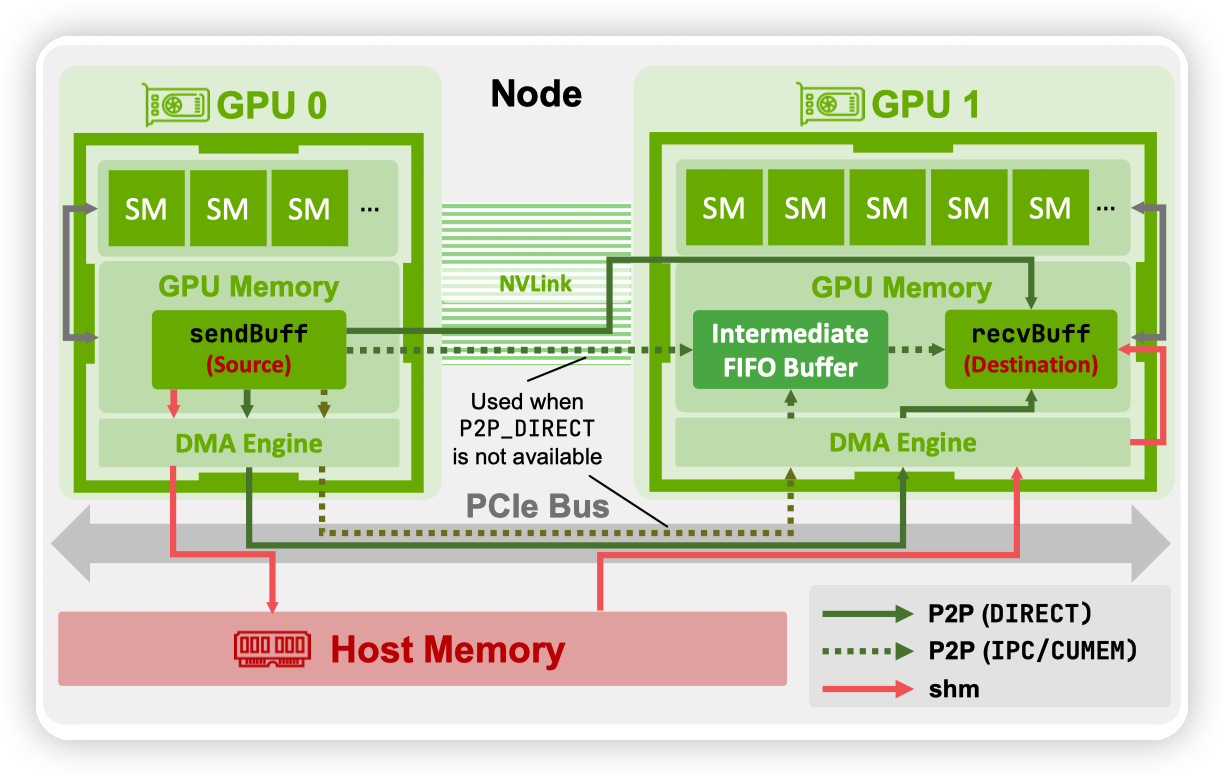
- Intra node transfer的示意图
- 这里主要讲了GPUDirect P2P的优化,跳过了图中画的intermediate FIFO buffer,直接写入到destionation中。
-
还有一种模式是通过memory/PCIe transfer,通过CPU memory来做通信,叫做SHM(share memory) mode
-
Multi socket系统的时候,每个GPU在一个CPU socket上,NIC支持GPUDirect RDMA的时候,可以走GPU-NIC-NIC-GPU链路,跳过CPU
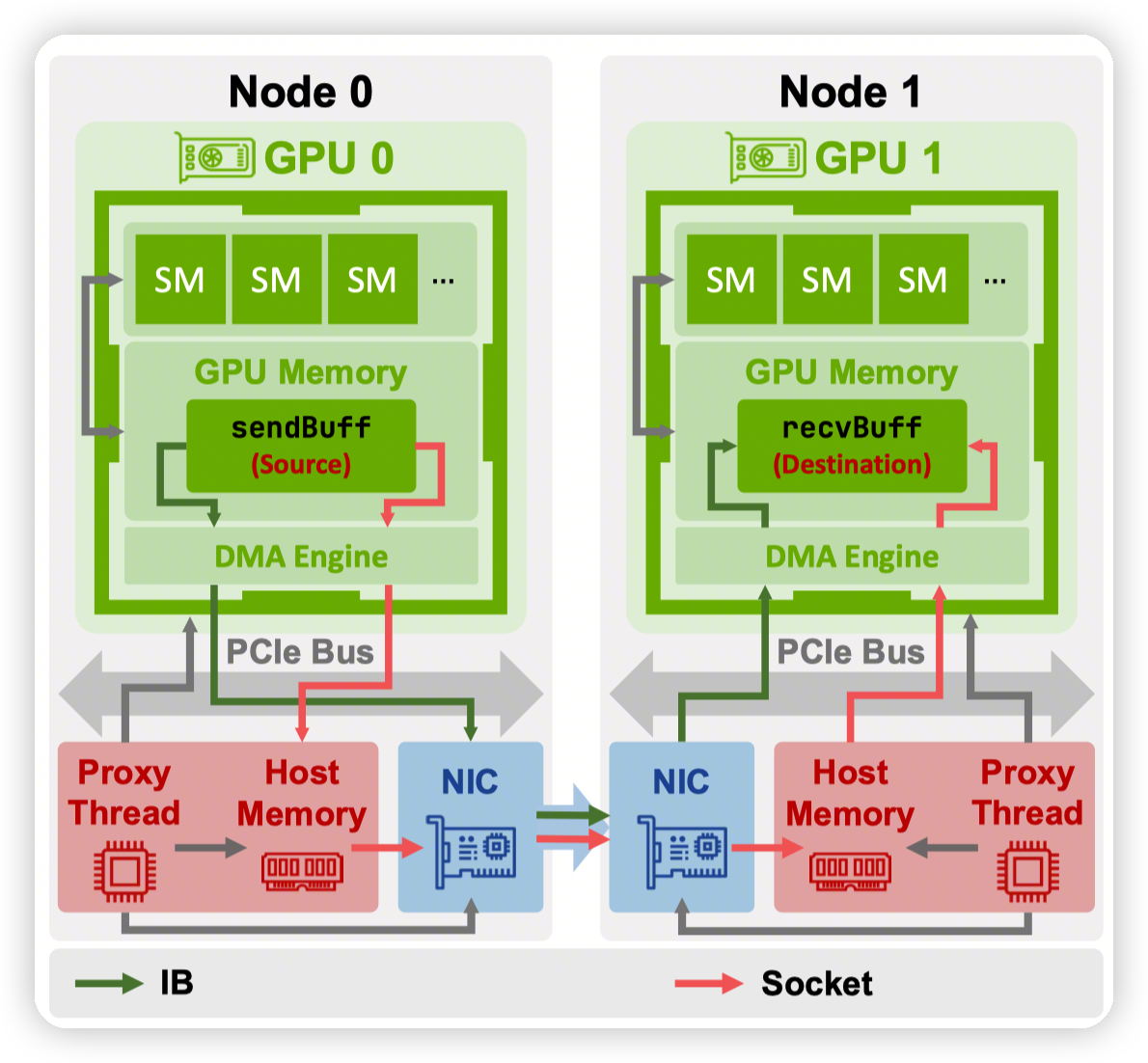
- Inter node transfer:
- 两种模式,socket-based和RDMA
-
socket-based:
- sender侧,分配pinned memory,从GPU拷贝过去。
-
receiver侧,CPU收到消息之后,拷贝到GPU中
-
IB(Infinity band)
- 默认情况下,NIC无法访问GPU memory,所以是先在host侧分配一个buffer,GPU拷贝过去,然后proxy thread触发RDMA operation。receiver侧的proxy thread再通过copy把数据拷贝到GPU上
-
在NIC/GPU在同一个PCIe Switch上的时候,可以使用GPUDirect RDMA
- 上面说的buffer可以直接分配到GPU memory上。
-
Proxy thread将这个buffer标记为RDMA-capable NIC(通过nv_peer_mem)。此时NIC可以直接访问GPU memory
-
NIC的dma engine会直接操作GPU memory
-
Per-peer Multi-channel Connections,没看懂,后面还有几个,也是和RDMA相关的,暂时先跳过
NCCL Collective Algorithms
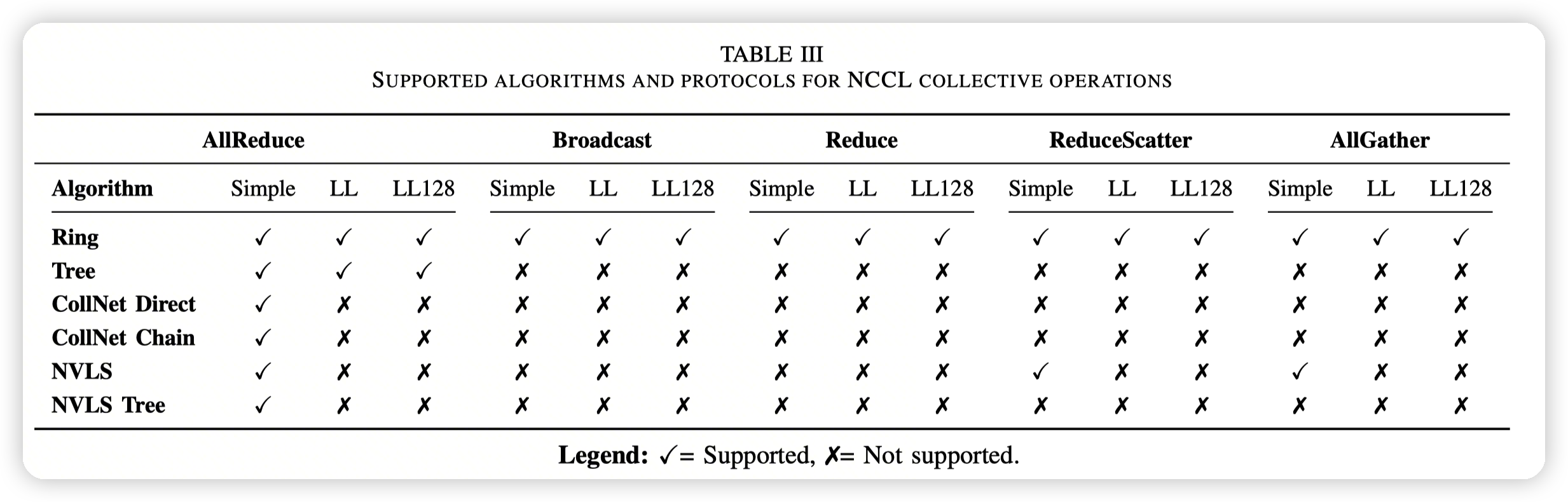
- 图中是不同的算法的实现的支持。
- 比如AllReduce这种,就是支持不同协议下的RingAllReduce,以及Tree 拓扑结构的AllReduce
-
横轴表示对外的算子的语义,纵轴则是具体的实现方式
-
ColNet表示的是网络硬件可以辅助进行collective operation的操作,比如利用NVIDIA SHARP,可以在交换机上做一些reduction的操作
-
NVLS是使用的NVLink Switch,支持高带宽的GPU to GPU通信。简单想就是ColNet/NVLS是利用了特殊硬件的特殊算法。
-
Primitives
- send/recv/recvReduceSend/recvCopySend/recvReduceCopySend,是几种常用的primitive,nccl通过这些primitive来实现上层的各种算法
-
这里举了一个recvReduceSend的例子,表示的是GPU从另一个地方收到数据,然后做reduction,然后发送给下一个GPU
-
Iterative execution of NCCL

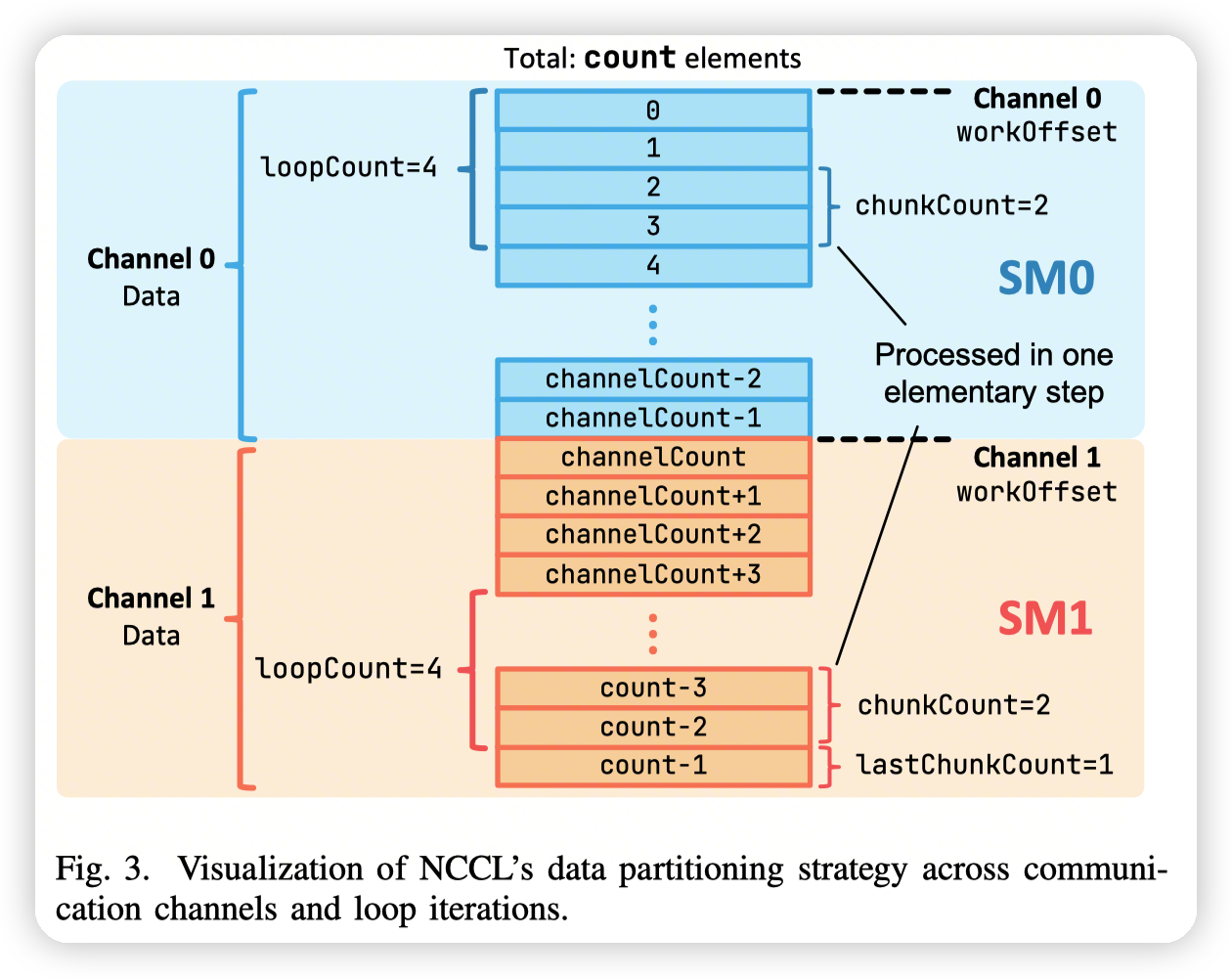
- channel放到不同的SM上,channel级别的并行。对应图中的两个channel,两个SM
-
用户的数据会被划分到不同的channel中并行执行
-
channel有自己的buffer,根据protocol来确定。当处理的数据超过了buffer的大小的时候,会有一个循环来控制。对应图中的loopCount
-
buffer会被切分成若干个slot,通过NCCL_STEPS来控制,默认是8个。不同的slot可以有不同的阶段(进行communication/computation),用来做pipeline
-
一个slot一次执行一个chunk的数据,对应的是若干个element(对应图中是chunkCount个element),执行的就是上面提到的primitive(send/recv等)
-
element是操作的最小单元,由算子语义决定:
- AllGather/Broadcast这种,不涉及到计算的,element是byte-level的,不用关注具体的数据类型
-
RS/AllReduce这种,涉及到具体的计算的,element则是用户定义的数据类型,不能拆成byte
- Mapping communication pipeline to CUDA hierarchy
- NCCL kernels are launched with a grid dimension of (nChannels, 1, 1)
-
每个block对应的线程数是动态的,通过NCCL_MIN_NTHREADS/NCCL_MAX_NTHREADS来控制
-
Channel-to-block mapping,因为channel是预先分配好的,而每次使用的channel是变化的,这里用了一个mask来控制是第几个channel启动了。(说起来感觉还是有点抽象,最好还是读读代码)
-
block内部,warp0负责load metadata,warp1负责load channel specific data,其他的warp负责进行communication/computation
-
不同的thread会执行不同slot的数据,从而支持slot based pipeline
-
为了避免warp divergence,会让一组warp执行相同的命令(感觉就是一组warp执行同一个slot的数据)
后面的一节给出了具体RingAllReduce,RingAllGather,RingReduceScatter的实现
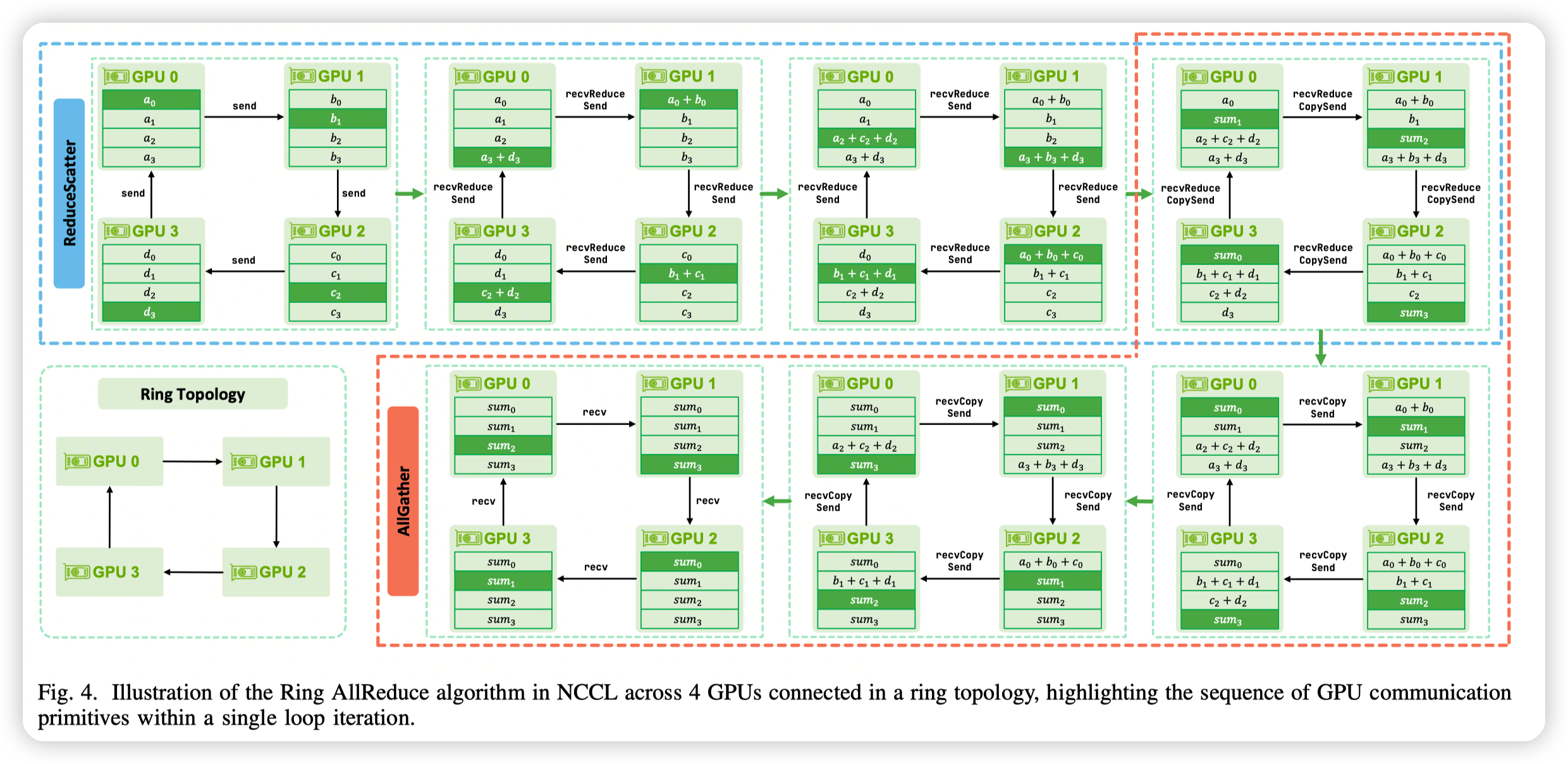

- table5的all reduce拆分开来就是reduce scatter和all gather
-
这种方式是non-pipelined pattern,每个step必须都执行完,才能执行下一个step
- In the non-pipelined pattern, each GPU must complete all tasks in one iteration before starting the next
- 然后还有pipelined pattern:
Pipelined Pattern: The Tree AllReduce, Ring Broadcast, and Ring Reduce algorithms in NCCL follow a pipelined execution pattern.
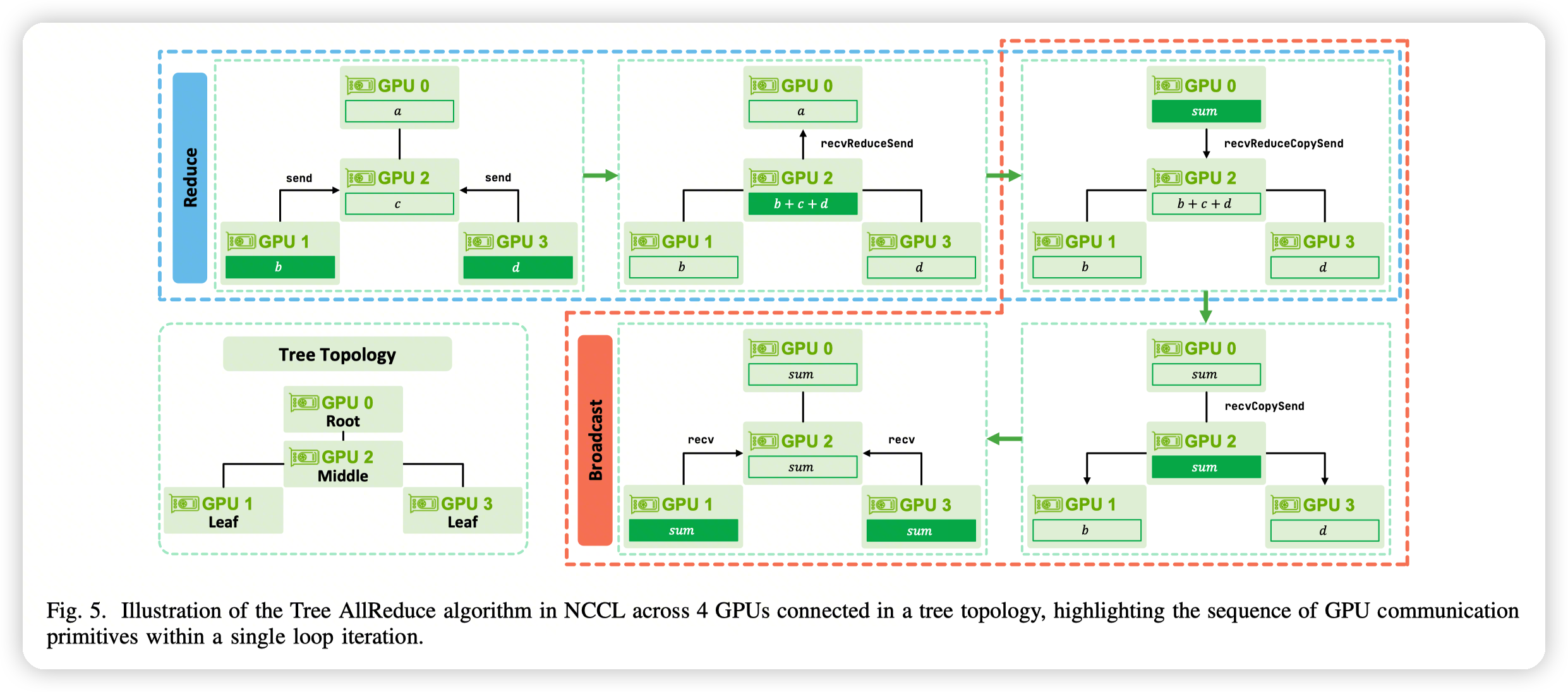
- Tree-all reduce,先通过reduce收集到root上,然后再做broadcast,发放给所有的rank
这里理解pipeline/非pipeline的逻辑是:
- 如果每个rank的执行是任意的,允许跨越step的执行,就是pipelined。
-
在RingAllReduce这种执行流中,每一个rank在每一个step都和前后两个rank需要做同步,导致全局step是共进的,不可能出现一个rank的执行到很后面,其他rank还在前面。因为依赖关系是双向的,变成了一个环
-
而TreeAllReduce等,依赖关系是单向的,不会构成环,而是一个DAG。那么执行的时候就可以是并行执行的。
- 比如在reduce阶段,每个rank只依赖他的子节点。那么兄弟节点之间的step就是不同步的,可以任意执行。
Ref
-
Exploring gpu-to-gpu communication: Insights into supercomputer interconnects,
-
Understanding data movement in tightly coupled heterogeneous systems: A case study with the grace hopper superchip
-
Collective communication performance evaluation for distributed deep learning training
-
xccl: A survey of industry-led collective communication libraries for deep learning,

文章评论