MegatronLM中实现了这个global load balance,这里来整理一下
论文:Demons in the Detail On Implementing Load Balancing Loss for Training Specialized Mixture-of-Expert Models
给aux loss起名,叫load balancing loss。
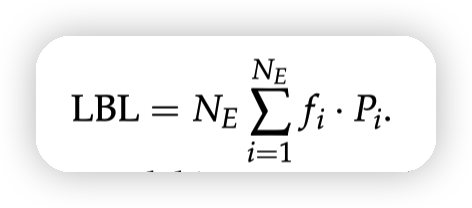
其中fi是路由到第i个expert的token的比例,Pi是router分配给expert i的概率
提到目前MoE framework实现的LBL的技术,都是在本地以microbatch级别做计算的。带来两个问题:
* 大规模的训练下,本地的microbatch很小,导致这个load balance几乎成为sequence级别
* microbatch中的数据可能有关联,强制要求在expert之间均衡可能导致性能损失
这里还提到pretrain的问题会更大,因为一个microbatch通常是一个domain下生成的数据,而global batch来自于多个不同domain下的microbatch。
* 这块感觉更多是实现相关
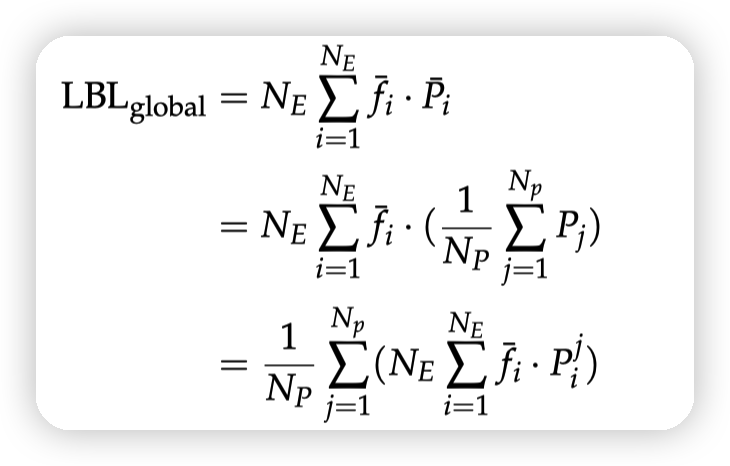
global load balance
先all-reduce 每个expert的token sum,通信量很低。
然后把这个公因子f提取出来,和local p做计算即可。

还有一种方法就是不做通信,而是通过一个buffer来近似global LBL。
在做gradient accumulation step之前,用一个buffer去积攒这个fi(图中叫ci),每次用这个积攒的fi去计算LBL
这样随着积攒数量的增加,fi就逐渐逼近了 global fi
然后来看一下megatron的实现逻辑:
- aux_loss
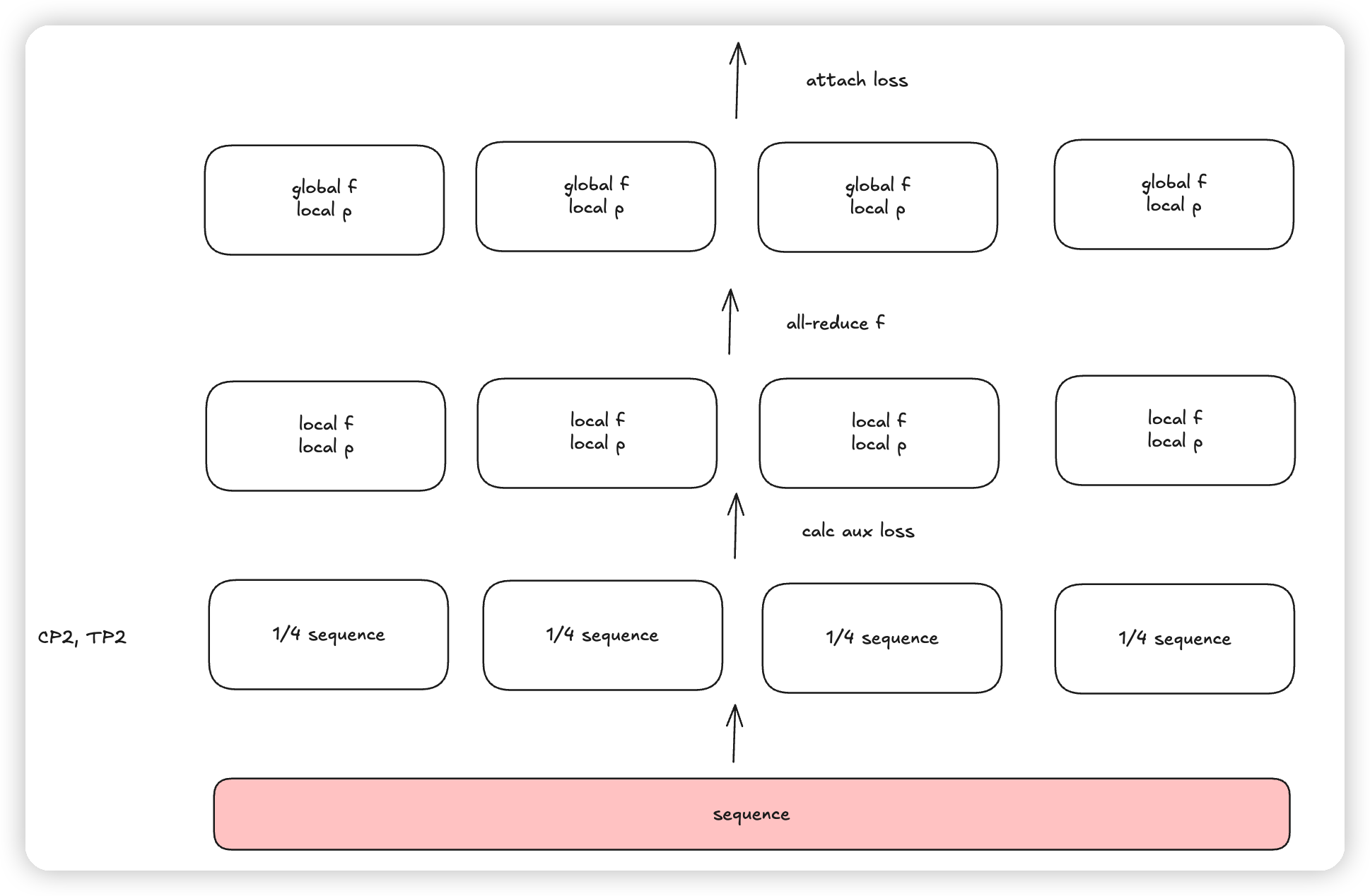
- 根据tp_cp_group.size()做all reduce,all reduce token_per_expert。因为megatron中是开了SP + CP,这里相当于计算DP rank的microbatch内的token_per_expert
- 用本地的score,和dp rank的token_per_expert,以及microbatch token count计算aux loss
- 这里相当于也是Global LBL的思想,只不过用在了microbatch内部。
- seq_aux_loss
- 这里的逻辑希望等价于在每一个sequence上做aux loss,然后整体做一下avg
- 因为每个tp_cp_rank只有一部分的sequence,这里会先把routing_map reshape成(sequence_length, batch_size)的样子,然后在sequence_length这一维度做sum
- total_num_tokens变成了全局的sequence length
- 算完aux loss之后,再除以batch size,就得到了sequence级别的aux loss
- global_aux_loss,这里就是上面paper中的逻辑了
- 在self.global_tokens_per_expert中维护了每个ga step的token_per_expert
- 通过多个step的积累,让global_tokens_per_expert逼近全局的token per expert
- 整理的计算逻辑和上面的aux_loss是一样的
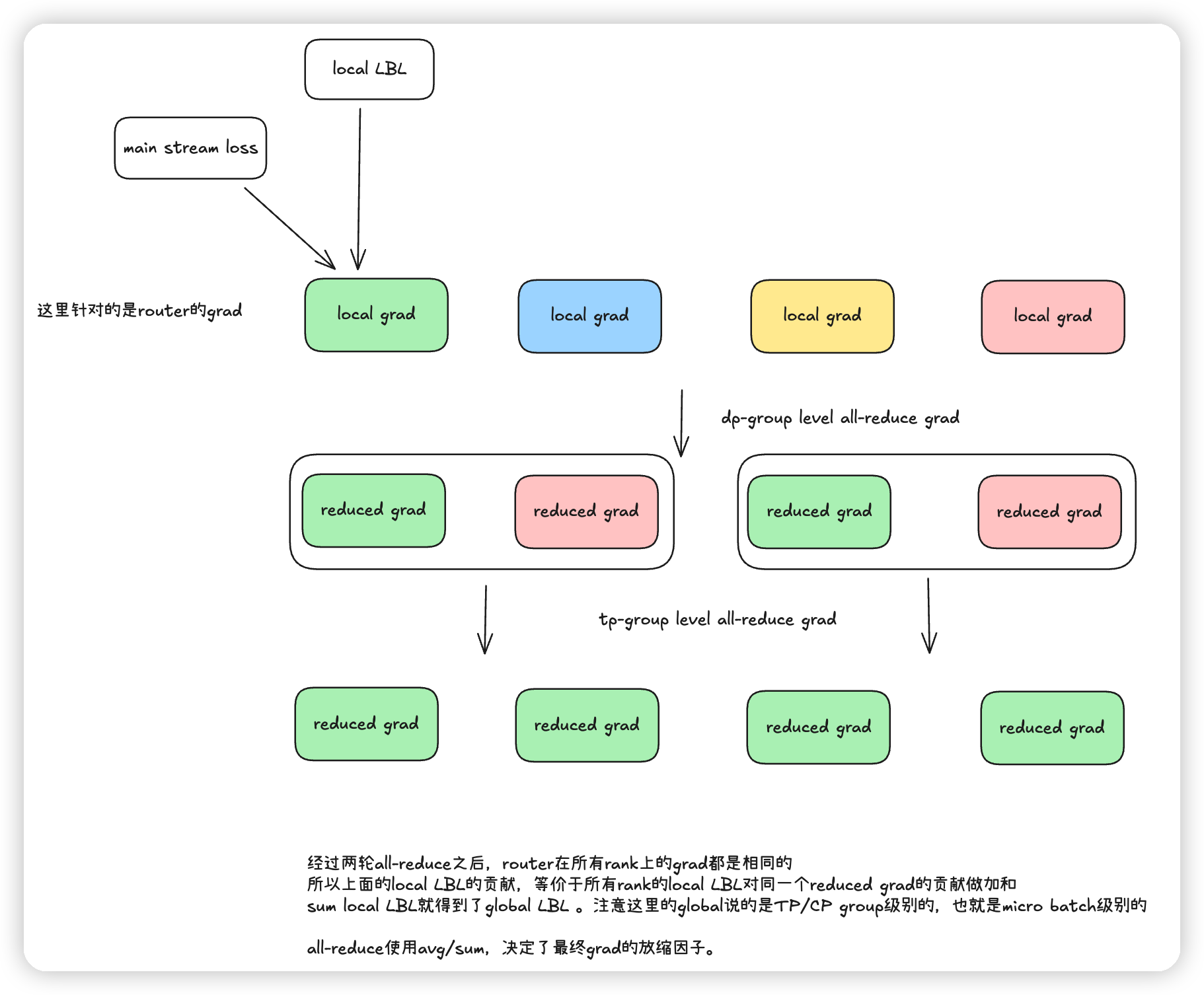
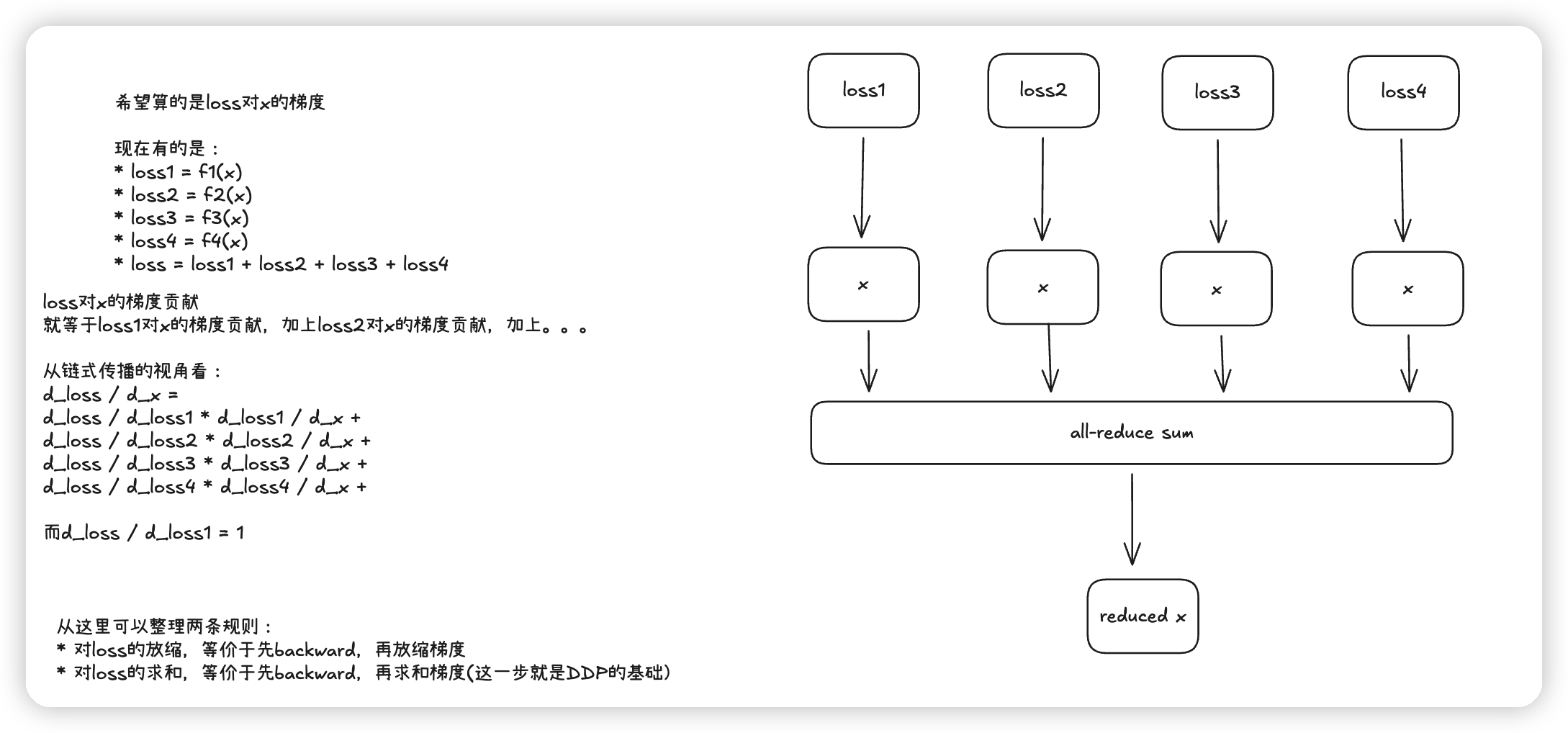
看完上面的实现,还有一个问题是,每个rank都是单独attach自己的aux loss。他们是否等于sum aux_loss,再做backward呢?
首先,因为loss是一个标量,所以sum of loss对各个参数的梯度,等于先local算loss,再做梯度的sum。
想象成是每个local rank单独贡献一块梯度,最终求和即可。
megatron中,如果开启了cp的话,在dp的时候会给梯度做all-reduce。
然后在开启SP的时候,尤其是针对这里的router,会把gradient在all-reduce之后,再做一次sum。
所以这里最终计算出来的grad的逻辑是:
* dp_cp group做all-reduce,avg
* tp group做sum。
* 等价于所有dp rank的microbatch做aux loss,然后对梯度做avg。最后再除了cp_size倍。(因为正常的计算应该是cp + tp group做sum)
* 对于全局来说,可以看作是所有microbatch做aux loss,求和,然后放缩dp_cp_size倍。
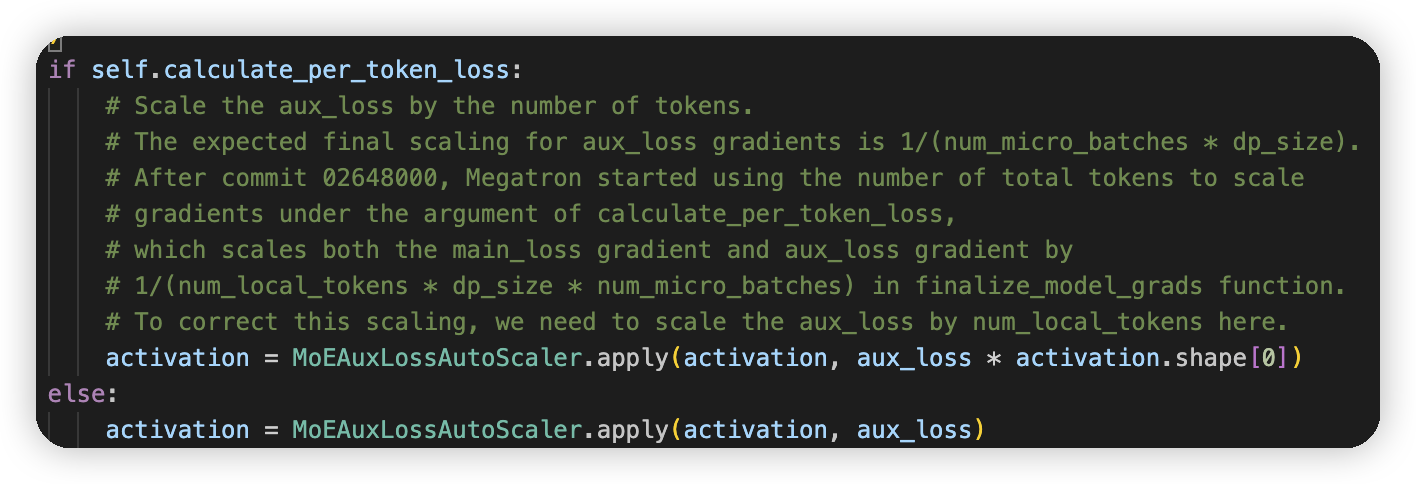
这里的注释也提到了:expected final scaling for aux_loss_gradient is 1 / (num_micro_batches * dp_size
* 感觉一般把dp_size认为是dp_cp_size也是没问题的
* microbatch num的放缩是通过gradient accumulation做的,这里不需要特殊处理。
启动per_token_loss的时候:
* 全局的grad会做sum,然后通过global token num做放缩。这个操作也会影响到aux loss的gradient,所以这里就提前放大一下。
* 主要的区别是,dp_cp的gradient不做avg,而是做sum。外面统一除一个global token num。
* gradient不做avg的话,放缩的因子就少了dp_cp_size倍。因为global_token_num = dp_cp_size * local_token_num。所以额外放缩一下local token num,也就是activation.shape[0],就可以对齐上面的实现了。
* 之所以global_token_num = dp_cp_size * local_token_num,是因为dp/cp是唯二的切分数据的方法。
再来画点图:


文章评论