https://github.com/NVIDIA/nccl-tests/blob/master/doc/PERFORMANCE.md
基本概念
time:
- 小size的时候,用来衡量通信操作的overhead
-
大size的时候,带宽项主导,所以应该看算法的带宽来预估性能
Bandwidth:
- Algorithm bandwidth
- 代表的是纯数据的bandwidth,不看具体的算法。
-
就是输入的数据S 除以 花费的时间t
-
Bus bandwidth
- P2P的通信,上面的algorithm bandwidth就是真正的通信量
-
但是all gather这种,涉及到多个rank通信的,需要看具体的算法流程来计算通信量。
-
代表的是硬件中真正的通信量
具体算子
ReduceScatter
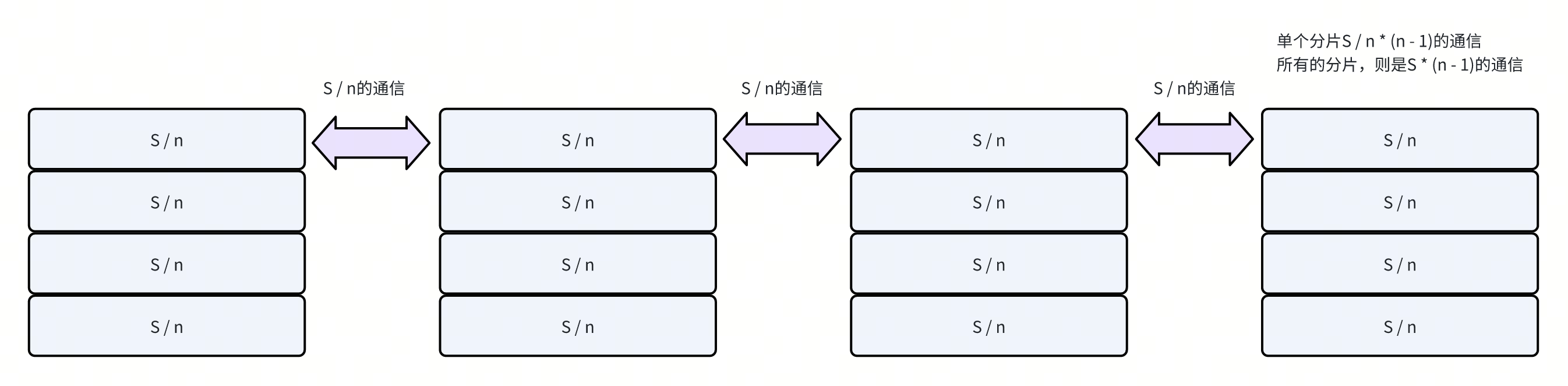
输入数据量为S
rank数量为n
每个rank对外的带宽为B
对于RS来说,每个rank最终的输出为 S / n,要收集来自其他rank的对应的数据
每一个数据都涉及到n - 1次跨rank的通信。
单个rank的通信量就是 S / n * (n - 1)
总的通信量就是S * (n - 1)
n个rank,拥有的总带宽是n * B
总共的通信时间就是 t = S * (n - 1) / (B * n)
那么B = S / t * (n - 1) / n = algbw * (n - 1) / n
AllGather
同上,每个rank最终的输出为S,输入是S / n
每个rank需要把自己的数据发送给其他n - 1个rank。总共的通信量也是S * (n - 1)
其他推理过程同上,得到B = algbw * (n - 1) / n
AllReduce
AllReduce是RS + AG。所以通信量变成了2 * S * (n - 1)
B = algbw * 2 * (n - 1) / n
All2All
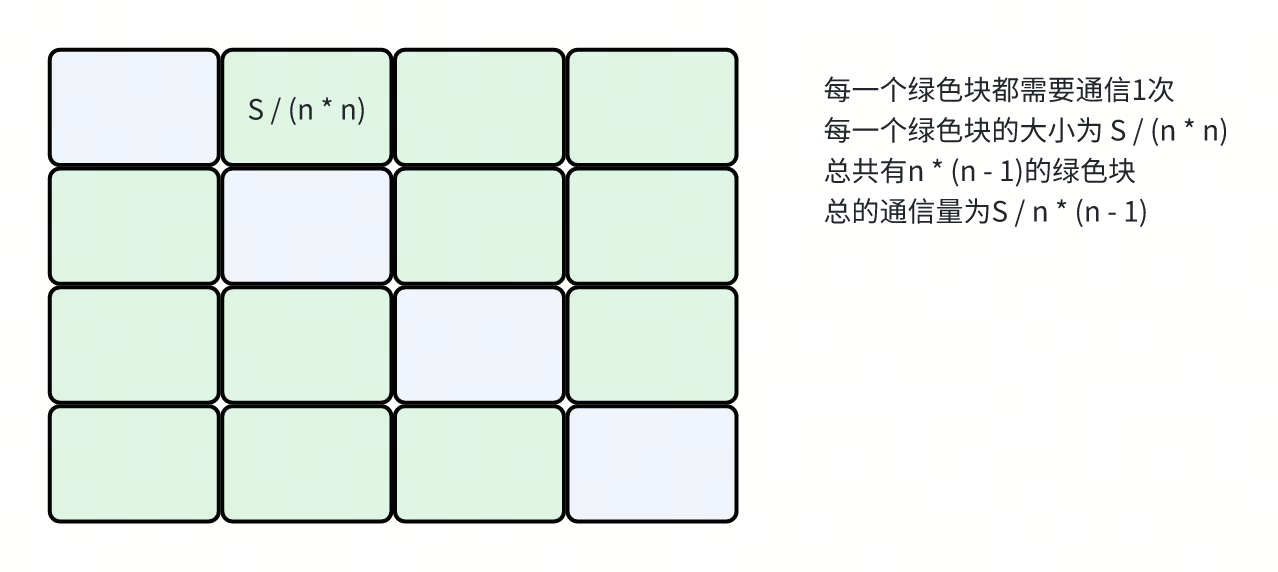
假设全局总的数据量是S
All2All的输入是S / n,输出也是S / n
每个rank包含S / n的数据,需要通信其中的(n - 1) / n份。
单个rank的通信量就是S / n * (n - 1) / n
总的通信量是S * (n - 1) / n
那么等式就变成了:
t = S * (n - 1) / n / (n * B)
B = (S / n) / t * (n - 1) / n
因为输入和输出都是S / n,所以algbw是(S / n) / t
那么factor就是(n - 1) / n
算法的选择
需要注意的是,上面在计算通信量的时候,都是按照最优的来计算的,并没有考虑具体的通信方式。
实际上常用的实现,比如RingAllReduce这种,通信量也是最小的。所以上面的结论是没问题的
不过这里要提的是具体的通信方式是有比较大的关联的。
比如AllReduce:
- 如果使用的是上面提到的RingAllReduce,通信量是2 * (n - 1) * S
-
但是如果是每个rank都收集来自其他rank的全量数据。相当于只有一跳。此时每个rank都会接收(n - 1) * S的数据,总共就是n * (n - 1) * S
-
这里也有一些带宽/延迟的tradeoff的感觉,当然也要考虑网络的拓扑结构。
![[Pasted image 20260130100958.png]]
比如这种yy的all-reduce的方法,通信量就变成了S * (n - 1) * (n - 1)。和上面算的2 * S * (n - 1)就不一样
统计口径
上面在计算通信的时候,考虑的是单向的收发,即:
A 发数据给 B
- A 在 TX(发送)
-
B 在 RX(接收)
-
数据在物理链路上只沿一个方向流动
-
此时占用的带宽认为是1
-
而不是A发送,B接收,认为是2
比如上面的AllGather,每个shard都收(n - 1)个rank的数据。并没有考虑发送的情况。
参考这里https://zhuanlan.zhihu.com/p/1957457076080076392
以及nccl test的文档
现实硬件常见有两种“带宽口径”:
(A) 单向带宽(unidirectional bandwidth)
比如说:NVLink x 50 GB/s(举例)
意思是:
- A→B 最多 50 GB/s
-
B→A 最多也 50 GB/s
但如果你只做 A→B,就是 50 GB/s。
(B) 双向带宽(bidirectional bandwidth)
硬件宣传里经常写 “100 GB/s bidirectional”
其实就是把两个方向加起来:
- A→B 50
-
B→A 50
-
双向合计 100
⚠️ 但注意:这 100 只有在 两个方向同时满速 才成立。
所以,如果你只传 A→B,而 B→A 没传,那你最多只能用到一半(单向那部分)。
从这里看的话,如果算法可以利用到双向的带宽,效果会比只能单向传输的算法效果会更好。
比如NCCL的一些算法(GPT说的,我没有研究过代码),会考虑用多个channel,让一部分数据顺时针通信,另一部分逆时针通信,这样在ring通信的场景,就可以利用到双向的带宽。
另一个点,All2All天然就是双向的:
- 每个rank会发送(n - 1) * S / (n * n)的数据。同时也会接收这么多数据
CaseStudy
RingAllGather
我自己yy的,不一定是真的
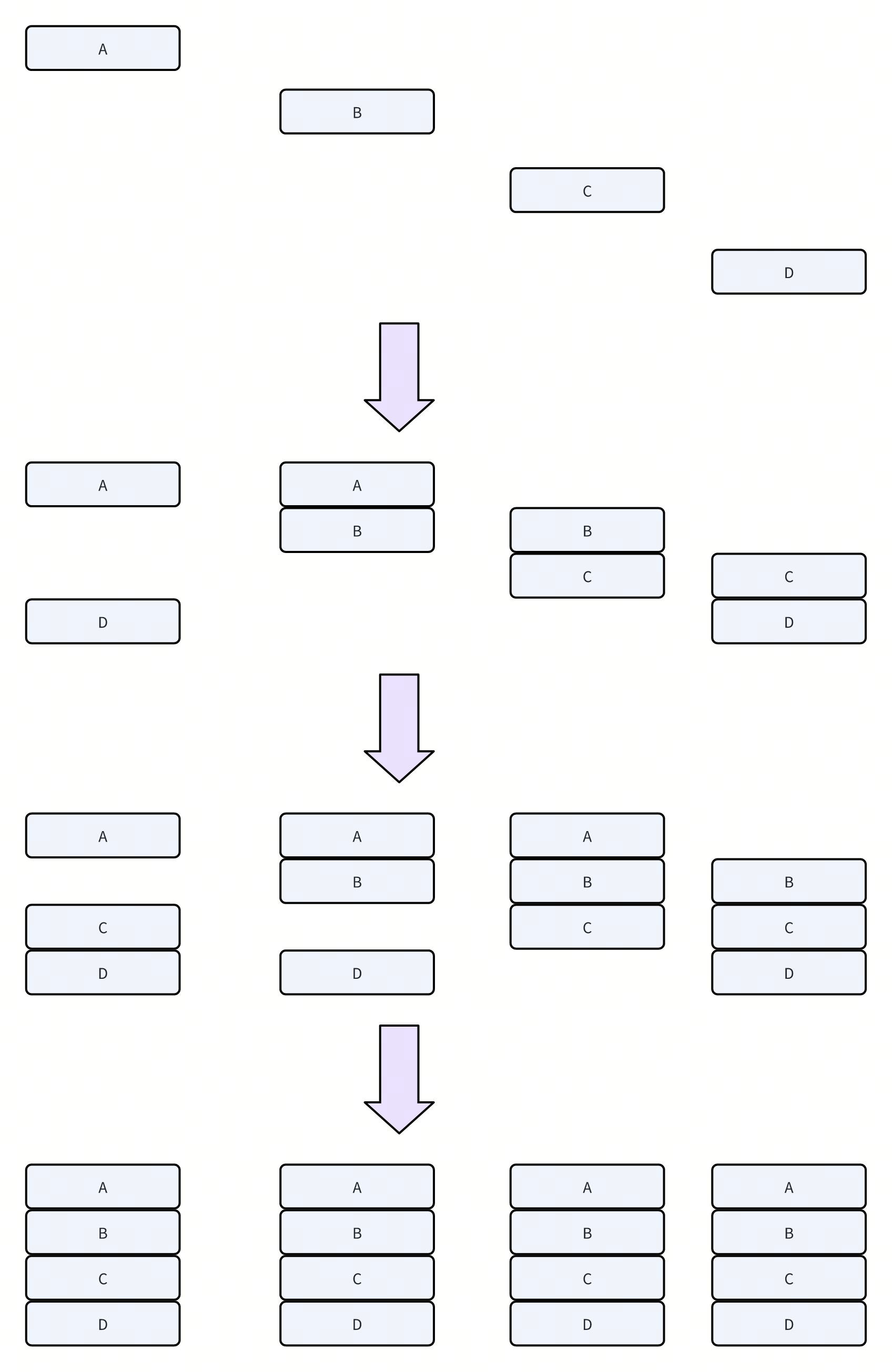
- 每个rank,每次发送S / n的数据
-
需要n - 1次iteration,共n个rank
-
总共发送的数据量为 S * (n - 1)
RingReduceScatter
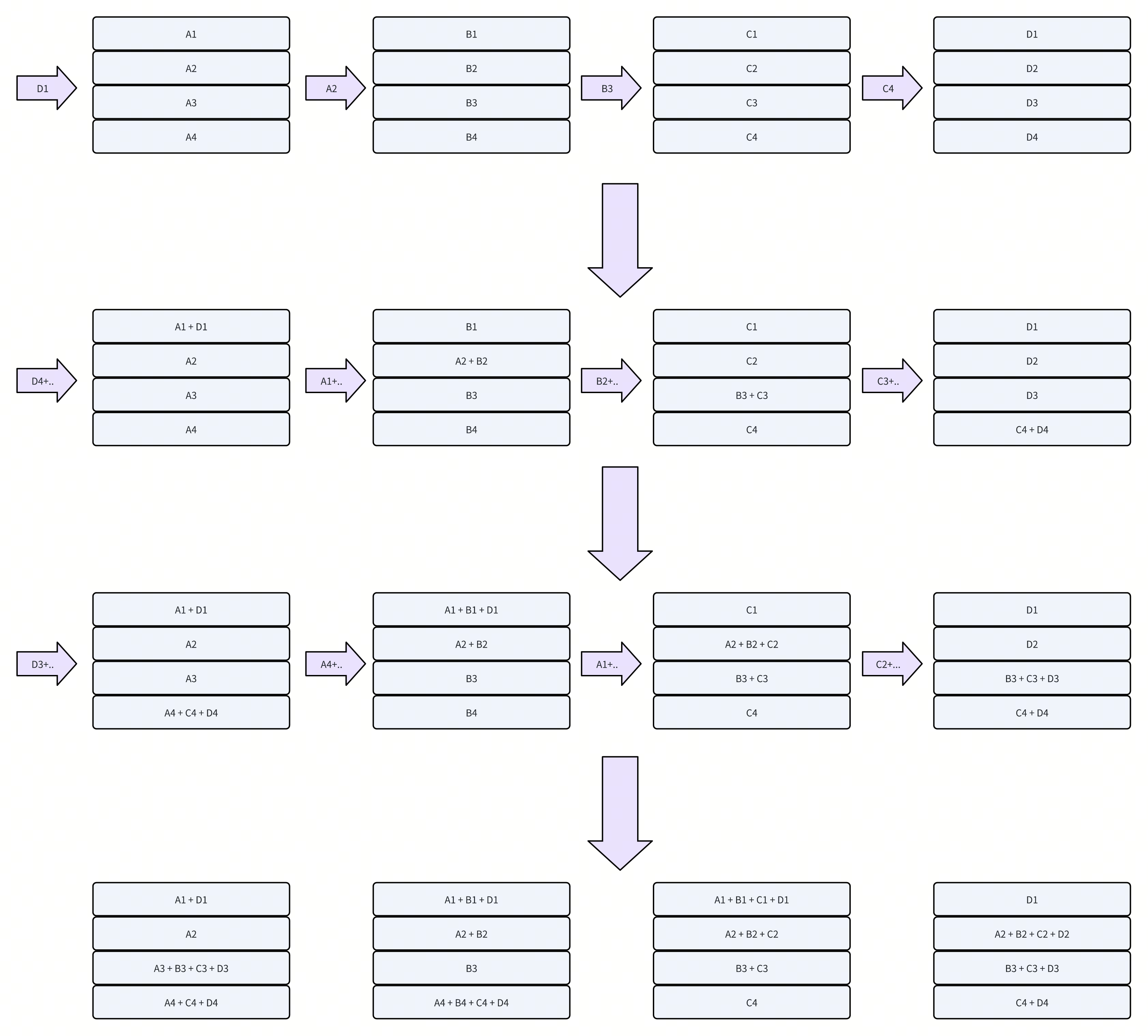
- 每个rank,每次发送S / n的数据
-
需要n - 1次iteration,共n个rank
-
总共发送的数据量为 S * (n - 1)
-
最后再把多余的数据释放掉即可
上面这些的通信模式都是和邻居收发消息的,根据具体的拓扑结构,应该还有一些更加高效的算法(延迟高效,带宽应该上面分析的就是理论的最优质了)

文章评论