这篇文章来介绍一下MegatronLM中的Dataset,核心的代码逻辑主要在megatron/core/dataset中
在readme里有写dataset相关的设计。
MegatronLM中的dataset逻辑相对简单,提供的功能也有限,MegatronLM官方文档中推荐使用https://github.com/NVIDIA/Megatron-Energon作为Dataset,更加适合作为一个生产级别的Dataset/Dataloader使用。后面有机会也会出一篇文章介绍一下。
MegatronLM的dataset设计分三层:
- IndexedDataset
- 负责做具体数据的组织。支持磁盘/OSS的接口。每个IndexedDataset对应两个文件.bin/.idx,对应token binary,以及每个sample在binary文件中的位置
-
继承自torch的Dataset,支持随机访问
-
MegatronDataset
- 抽象类,这一层会切Split(切分train/test/valid),以及用户自行实现的一些业务逻辑。后面会从GPTDataset中看到
-
继承自torch的Dataset,支持随机访问
-
GPTDataset,继承MegatronDataset。做了四件事:
- 根据配置中需要的token数量,对数据集做repeat
-
全局shuffle
-
按照sequence_length拼接样本,用于减少padding
-
构建loss_mask, position_id, attention_mask
-
BlendedDataset
- 负责将多个Dataset按照权重混合,拼接成一个dataset
IndexDataset
简单讲就是两个文件:
- .bin 只负责存连续数据
-
.idx 负责告诉你每条样本的长度与在 .bin 的偏移;
-
读取时先读索引,再用 offset/length 从 .bin 读具体的数据。
每一条数据Sample都是numpy.ndarray的格式,整个文件要求数据的dtype都相同:
- 比如存的数据就是token,那么dtype可能就是numpy.int32,或者numpy.int16
-
读写数据也基本都用的numpy的操作。写入是numpy.tobytes()转化成bytes写入到文件,读取则是numpy.frombuffer()
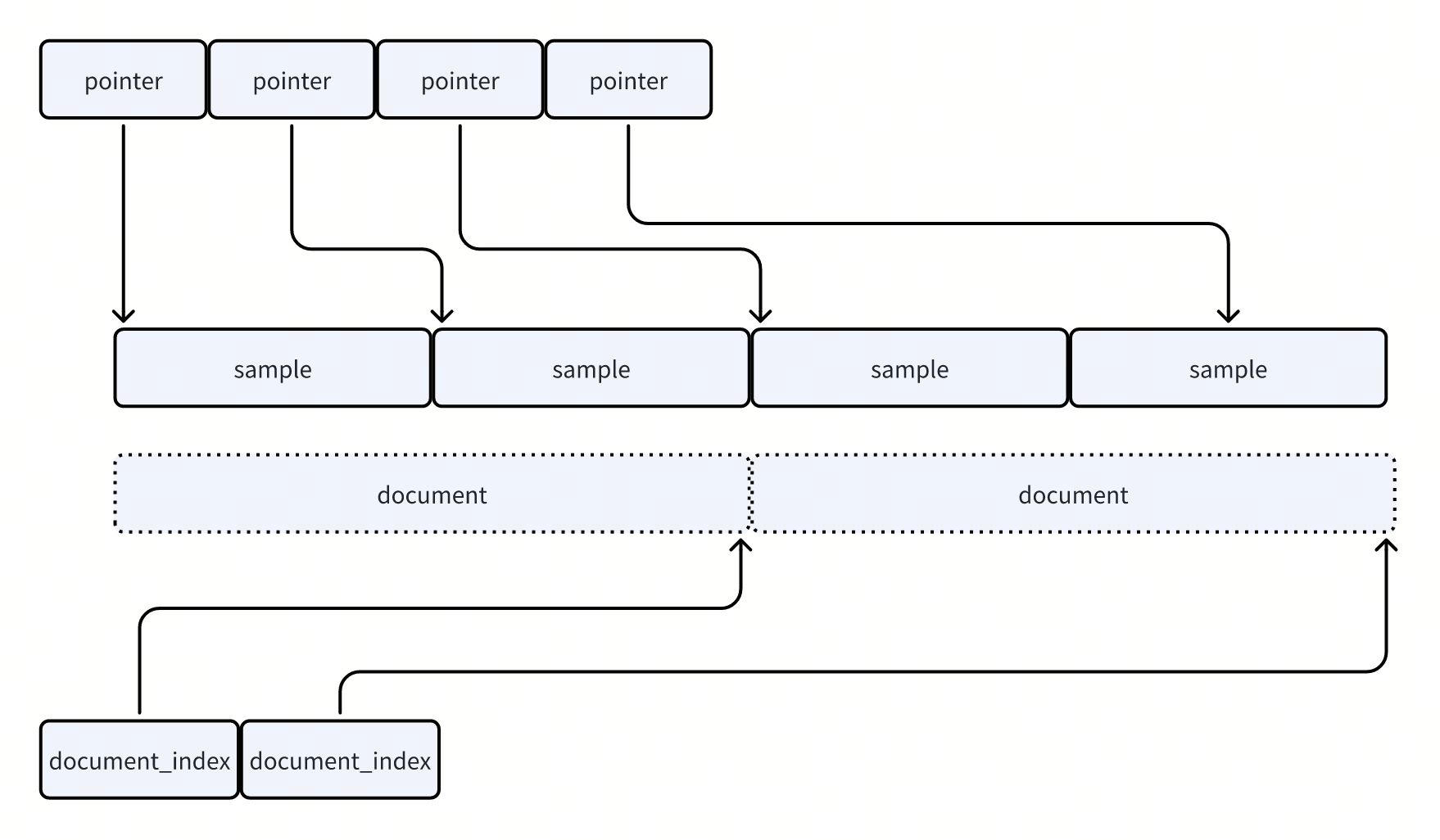
- 数据模型上,分为sequence和document
- sequence就是训练中的一条sample
-
document则是包含一批sequence,用来做train/test dataset的划分的。以及给bert准备数据集的时候,需要next-sentence-prediction
-
两者分别通过EOS/EOD来划分边界
-
.idx文件包括:
- 固定 header + version + dtype code,dtype code就是numpy dtype序列化后的结果,用来保存sample的类型
-
sequence_count(uint64)
-
document_count(uint64)
-
sequence_lengths(int32 数组,长度 = sequence_count)
-
sequence_pointers(int64 数组,长度 = sequence_count;每条样本在 .bin 中的 byte offset)
-
document_indices(int64 数组,长度 = document_count;标记文档结束位置的 sequence 下标)
读取方式:
- idx文件,通过mmap把上面的pointer/length等数组映射成numpy的数组。根据参数的idx计算出byte offset + byte length
-
本地文件,通过numpy的mmap,把.bin映射到内存中。根据byte offset/length切一下,然后numpy.frombuffer,按照ndarray的方式读
-
OSS
- oss中的idx文件会被下载下来,当成本地文件用mmap读
-
binary则是按照chunk读。每次读的时候判断一下要读的数据是不是在当前的chunk内。如果不是的话就读一个chunk。
-
默认chunk是256M
-
这些读取方式都比较依赖顺序访问,如果是shuffle的话,随机访问的性能会很差。
GPTDataset
按照上面说的,GPTDataset主要做了4件事,这一节主要来看一下具体是怎么做的
- 根据配置中需要的token数量,对数据集做repeat
-
全局shuffle
-
按照sequence_length拼接样本,用于减少padding
-
构建loss_mask, position_id, attention_mask
如果阅读代码的话,会发现他有一个参数叫indices,这个indices的使用在后面BlendedMegatronDatasetBuilder中会看到,含义是取底层的IndexedDataset的子集。
- 比如indices = (1, 3, 5),表示的是当前这个GPTDataset只会读取底层数据的(1, 3, 5)这三条数据
对数据集做repeat:
- 根据上面提到的indices,计算出当前这个Dataset,一个epoch的token的数量
-
根据配置中的num_sample, sequence_length,计算出需要的总的token数量
-
除一下,就知道了为了满足总的token数量,当前Dataset需要重复多少次。也就得到了epoch的数量。
- 当然这里不一定是整除,所以涉及到最后一个epoch只有部分样本。代码中对应separate_final_epoch,会在shuffle的时候单独处理一下
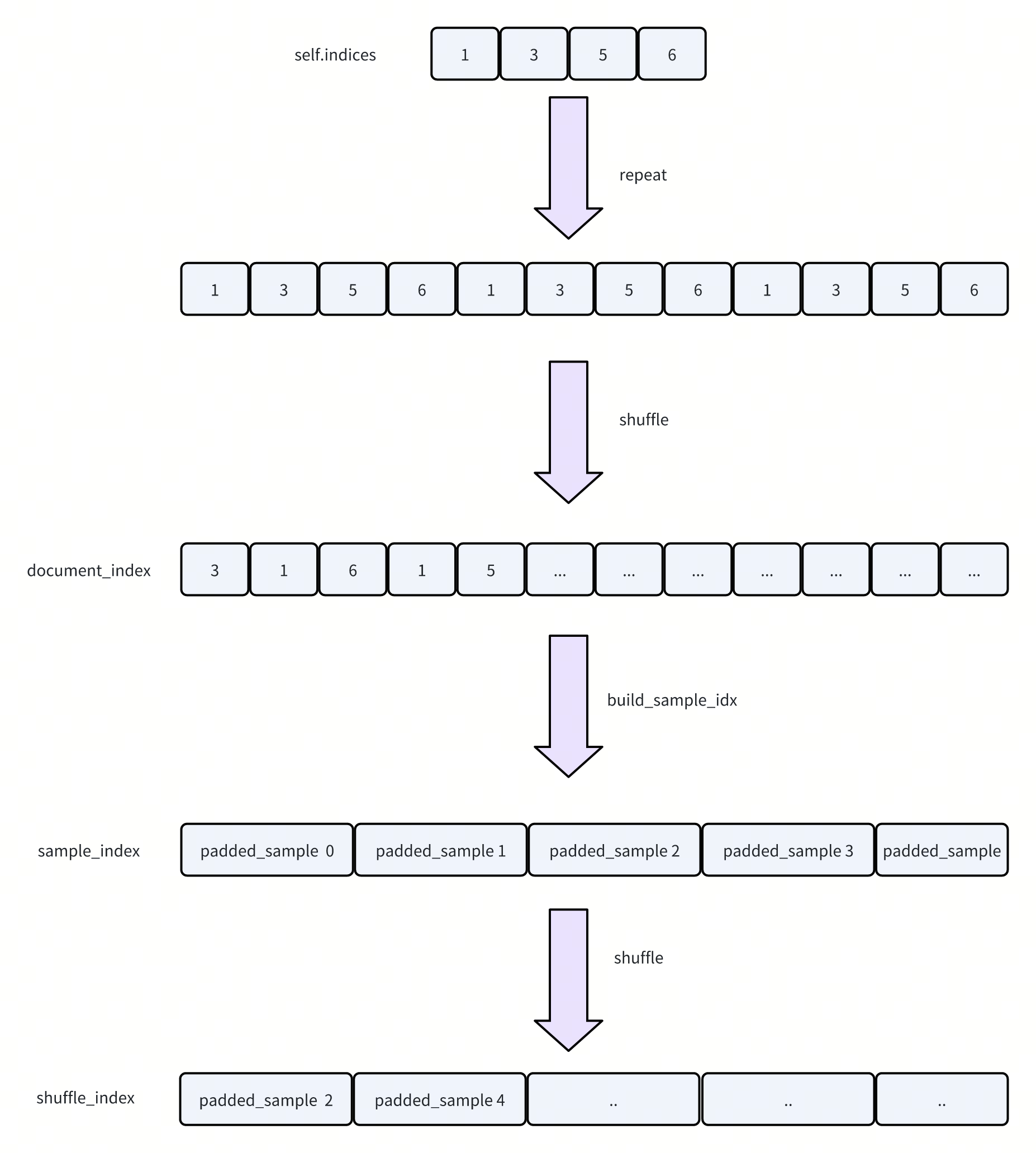
- 这里画了一个示意图,解释一下如何做的shuffle + padding
-
首先根据计算的epoch,对indices做repeat,得到多个epoch对应的数据下标。然后做shuffle。这里对应代码中的document_index
-
然后build_sample_idx,就是根据sequence来把多个sample拼接到一起
- 实现上,这里会看当前 sequence 还剩多少 token:sizes(doc) - doc_offset
-
如果这段不够凑满目标长度:把整个剩余段都吃掉,document_idx_index++ 跳到下一个 document,doc_offset=0,继续凑
-
如果这段足够甚至超了:只吃一部分,把 doc_offset 前移到“刚好切完一条样本之后的起点”,然后结束本条样本
-
构建好长度为seq_len的sample之后,再次做一下shuffle。
- 和前面shuffle的区别是,这里是shuffle 按照sequence length切分后的sample。而前面的shuffle则用于确定哪些sequence被切分到一起。
-
document_index shuffle(Do_idx):决定把哪些 sequence 按什么顺序拼成一个长 token 流。
-
sample_index(Sa_idx):在这个拼接后的 token 流上,每隔 sequence_length(+1) 切一段,得到样本边界;这一步本身是“顺序切块”。
-
shuffle_index shuffle(Sh_idx):把“顺序切块得到的样本 id”再随机打乱,避免样本顺序带来局部相关性(例如相邻 sample 来自同一段 token 流、共享大量上下文)。
-
再整理一下,这里构建了三个索引:
- document_index(1-D,int32):长度约为 num_epochs * len(self.indices)
- 把一个 epoch 要遍历的元素列表重复 num_epochs 次,并 shuffle。
- sample_index(2-D,形状 (num_samples + 1, 2)):每一行是 (doc_index_pos, offset)
- 第 j 个样本的起点是 sample_index(j),终点是 sample_index(j+1)。
- shuffle_index(1-D):长度 num_samples
- 把样本 id 再洗牌:外部 idx → 内部样本顺序 j。
- document_index(1-D,int32):长度约为 num_epochs * len(self.indices)
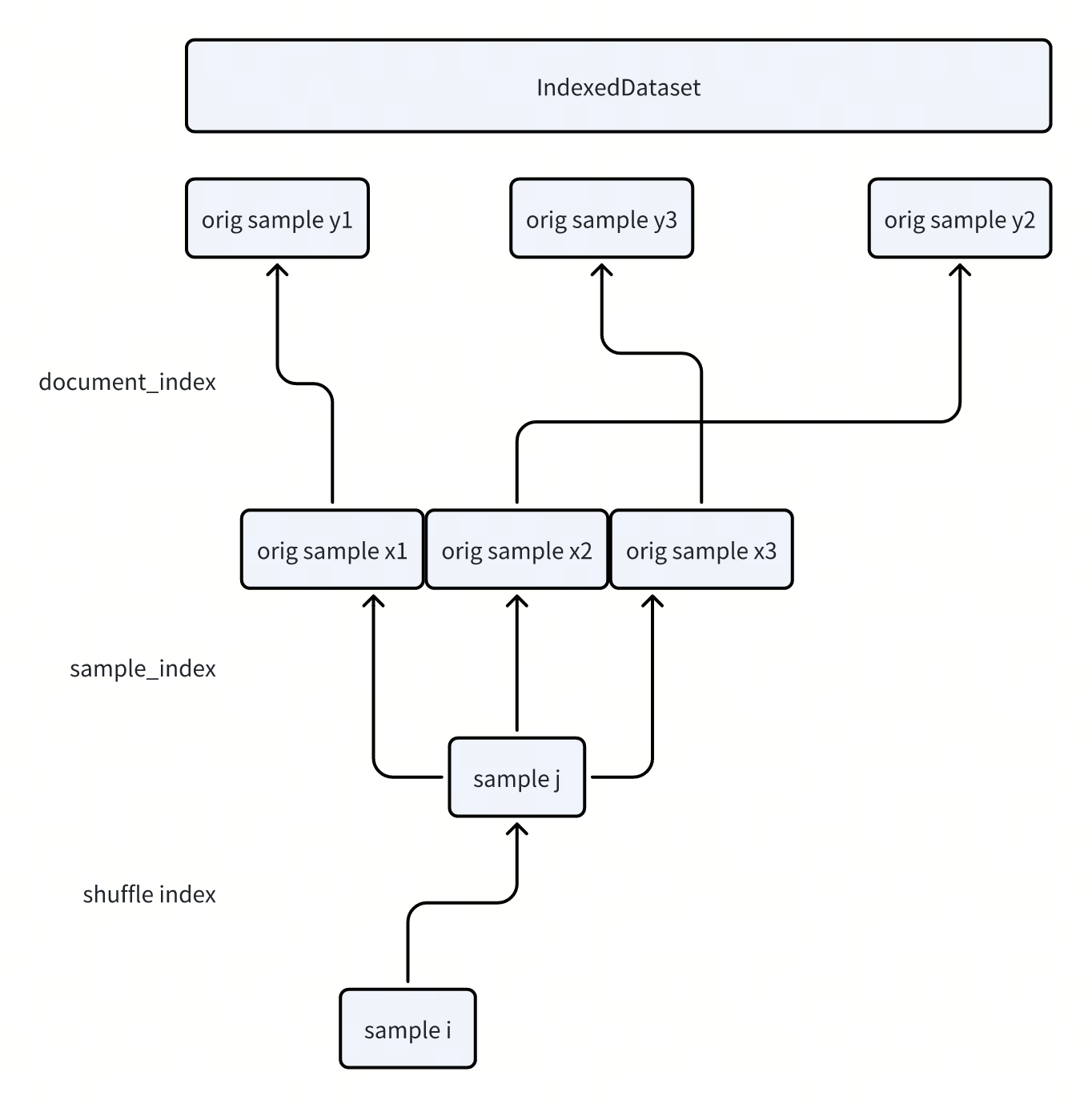
查询的时候,就需要利用一下上面构建的这些索引,定位到IndexedDataset中的数据,并做具体的拼接。核心代码在_query_document_sample_shuffle_indices中:
- 通过shuffle_idx,定位到具体要访问的样本
-
通过sample_idx i, i + 1来得到是哪些原始的sample组成了当前的sample
-
再通过document_index 映射到具体的sample id
-
再去IndexedDataset中访问数据,并进行拼接
读取数据的时候,除了上面的拼接,还需要构造一下loss mask, attention mask, position_id等:
- 因为一个sample内可能包含多个独立的sequence,所以需要对attention mask,position id单独处理一下
-
把attention_mask从一个三角矩阵,改成一个分块的三角矩阵。避免出现跨越sequence的attention
-
PositionID:每遇到一个 EOD,就把后面那一段的 position 统一往回平移,使得新 document 的第一个 token position 从 0 重新开始计数
-
Loss mask主要是在EOD上做的。表示不需要对EOD这个token做预测
BlendedDataset
接口传入的是list dataset以及list of weight,weight标识这个dataset对应的权重。
- 这里是在初始化的时候就确定好了sample的顺序,核心逻辑在_build_indices/build_blending_indices中。
- 构建策略不是做真的random sample,而是维护一下每个dataset都分配了多少条数据,然后每一步挑选dataset的时候,选择"当前分配次数落后于目标比例最多"的dataset。
- 构建好这个索引之后,读取数据的时候就可以先根据这个索引确定dataset,再从dataset中读数据即可。
- dataset内部是从0开始顺序取数据的
BlendedMegatronDatasetBuilder
用来构造Dataset的,负责做blend + split。
给定一个MegatronDataset,比如GPTDataset,以及split/blend的配置,会构建出每个split的一个BlendedDataset
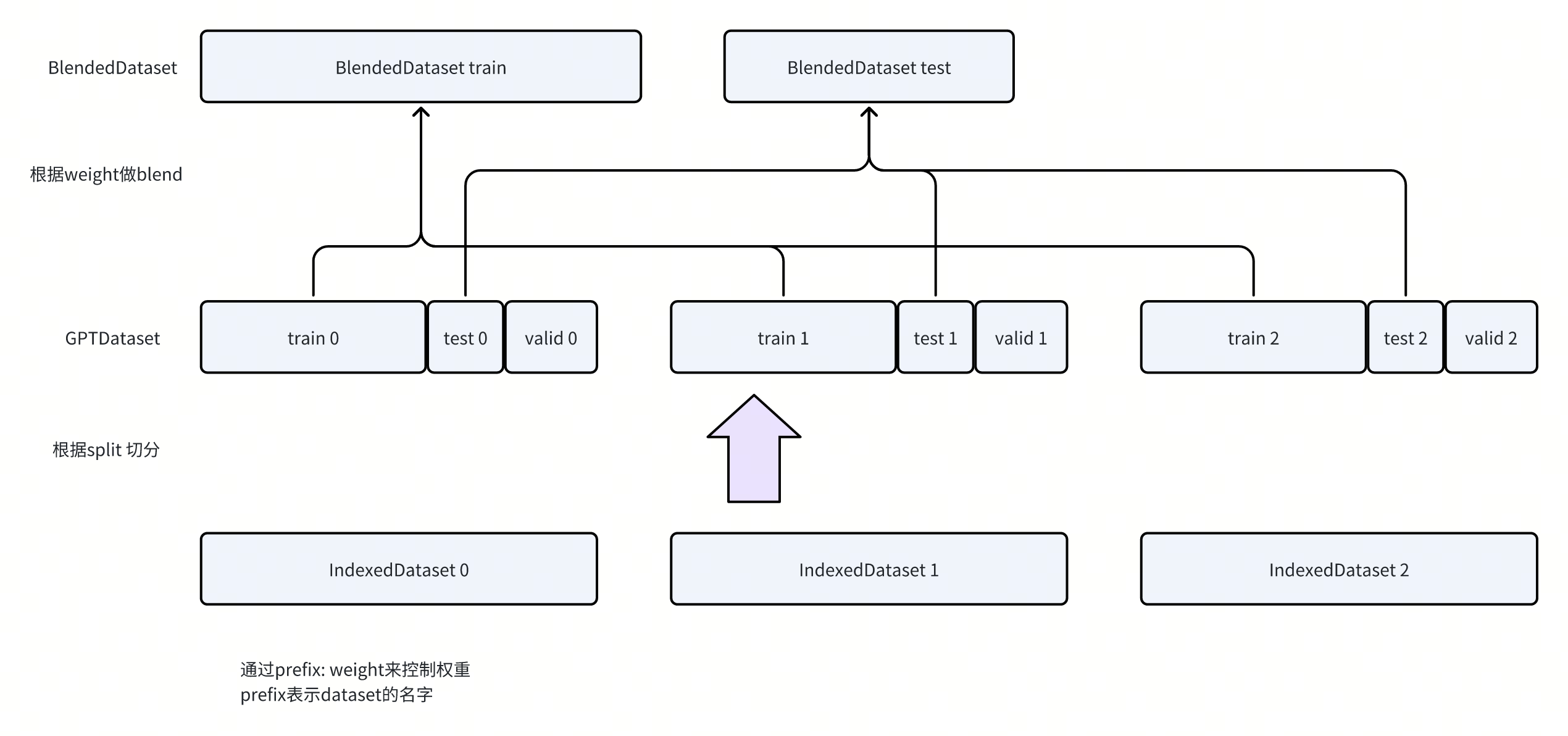
- 展示了一种切分的逻辑,就是每个split的blend比例是固定的
-
会通过上面提到的indices,把IndexDataset切分成train/test/valid三个GPTDataset
-
然后通过BlendedDataset组合到一起
Dataloader
-
Dataloader的逻辑主要在build_pretraining_data_loader,使用的还是torch的dataloader,可以通过传入consumed_samples来做恢复
-
在这一层会通过Sampler来做DP数据的划分,支持两种Sampler:
- MegatronPretrainingSampler
- 目标:在全局样本索引 (consumed_samples, total_samples) 上顺序走;每凑齐一个“全局 batch”(大小 = micro_batch_size * data_parallel_size),按 data parallel rank 切一段连续的 micro_batch_size 给当前 rank。
- 全局 batch 的构造方式:不断 append 全局 idx;凑够 micro_batch_size * dp_size 就 yield。
-
本 rank 拿哪一段:start = dp_rank * micro_batch_size,end = start + micro_batch_size。
- 目标:在全局样本索引 (consumed_samples, total_samples) 上顺序走;每凑齐一个“全局 batch”(大小 = micro_batch_size * data_parallel_size),按 data parallel rank 切一段连续的 micro_batch_size 给当前 rank。
-
MegatronPretrainingRandomSampler
-
目标:实现“cyclic/random” 风格的数据遍历:基于 consumed_samples 推导当前 epoch,通过epoch做random seed,保证相同epoch下的数据shuffle的结果相同。
-
data_sharding打开时,会把total sample分成dp rank块。每一块内部自己做shuffle。
-
data_sharding关闭时,会对total_sample做shuffle。然后每个rank按照dp_size跳着取
-
这里还有一个额外的点,要求consumed sample需要对齐microbatch_size * dp_size。也就是对齐global batch size。这样每次都按照global batch size做对齐,恢复会比较容易。
-
- MegatronPretrainingSampler

文章评论