General Agentic Memory Via Deep Research
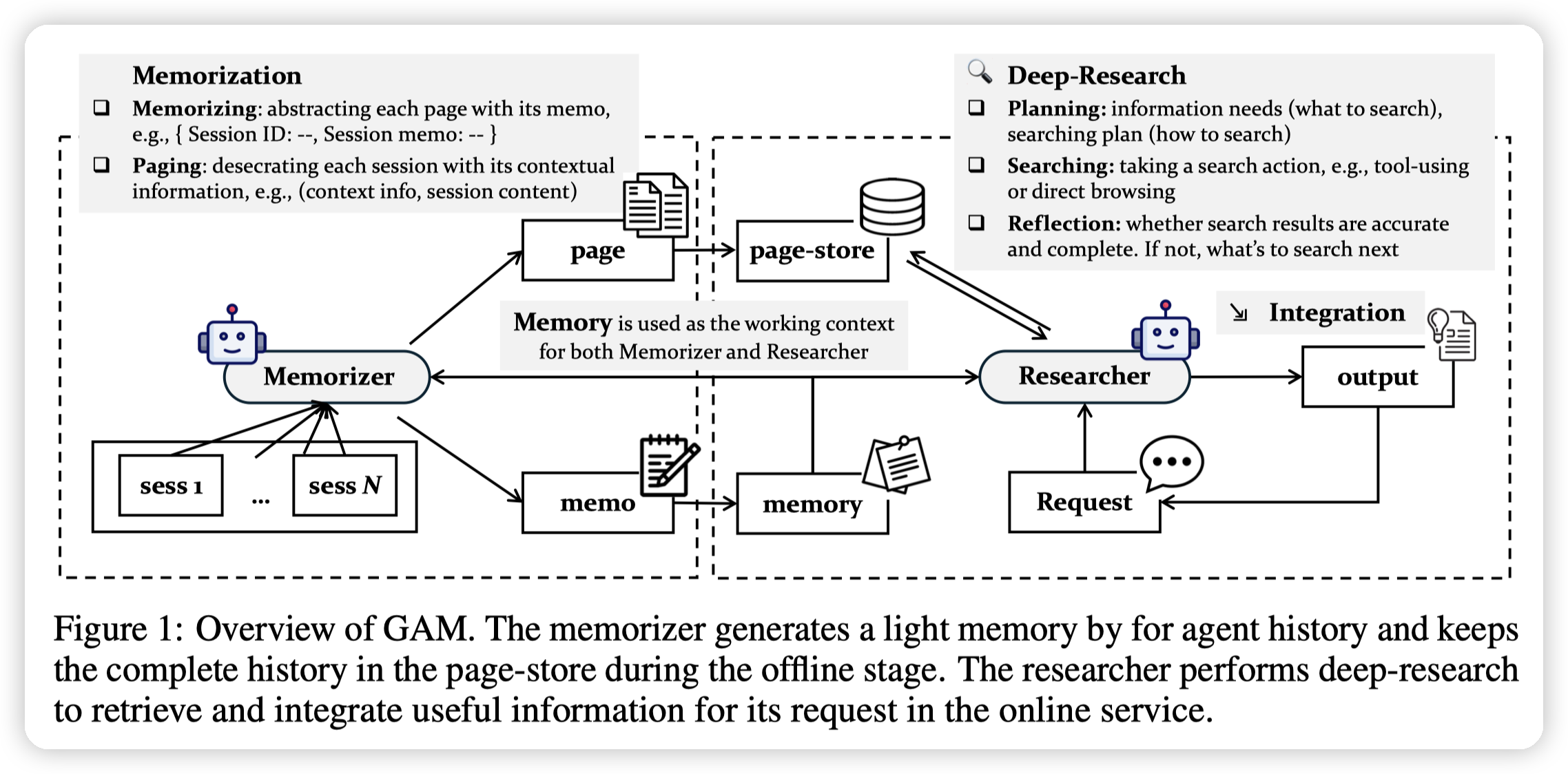
核心点分为两块:
- The Memorizer receives the client’s streaming history as a sequence of sessions, where it takes two actions: 1) it dynamically compresses the key historical information with a lightweight memory, and 2) it merges each session and its corresponding memory into a page and save all pages into a page-store, ensuring that the historical information is coherently and inclusively preserved.
-
The Researcher receives an online request from its client and performs deep research based on the pre-constructed memory to address the client’s needs. It iteratively analyzes information need and plans search actions, retrieves relevant information from the page-store, and reflects on the results until the gathered information fully satisfies the client’s request.
Implementation
Memorizer
MemoryAgent_PROMPT = """
You are the MemoryAgent. Your job is to write one concise abstract that can be stored as long-term memory.
MAIN OBJECTIVE:
Generate a concise, self-contained and coherent abstract of INPUT_MESSAGE that preserves ALL important information in INPUT_MESSAGE.
MEMORY_CONTEXT is provided so you can understand the broader situation such as people, modules, decisions, ongoing tasks and keep wording consistent.
INPUTS:
MEMORY_CONTEXT:
{memory_context}
INPUT_MESSAGE:
{input_message}
YOUR TASK:
1. Read INPUT_MESSAGE and extract all specific, memory-relevant information, such as:
- plans, goals, decisions, requests, preferences
- actions taken, next steps, assignments, and responsibilities
- problems, blockers, bugs, questions that need follow-up
- specific facts such as names, dates, numbers, locations
2. Use MEMORY_CONTEXT to:
- resolve or disambiguate the entities, components, tasks, or resources mentioned in INPUT_MESSAGE,
- keep terminology (names of agents, modules, datasets, etc.) consistent with prior usage,
- include minimal background context if it is required for the abstract to be understandable.
You MUST NOT invent or add information that appears only in MEMORY_CONTEXT and is NOT implied or mentioned in INPUT_MESSAGE.
3. Your abstract MUST:
- summarize all important content from INPUT_MESSAGE,
- be understandable on its own without seeing INPUT_MESSAGE,
- be factual and specific.
STYLE RULES:
- Output exactly ONE concise paragraph. No bullet points.
- Do NOT include meta phrases like "The user said..." or "The conversation is about...".
- Do NOT give advice, opinions, or suggestions.
- Do NOT ask questions.
- Do NOT include anything that is not grounded in INPUT_MESSAGE.
OUTPUT FORMAT:
Return ONLY the single paragraph. Do NOT add any headings or labels.
"""
每次进来新的memory,会结合历史Memory提取的Abstract,生成新的abstract。作为这段memory的header。
然后把abstract + 原始的memory作为一个page保存下来
Researcher
和通用的DeepResearcher一样,只不过prompt里带一点memory相关的字段
- Planning
- 决定要使用的tool(keyword, vector, page_index(点查))
- 同时生成tool对应的参数(搜索的query)
- 会使用上面生成的Abstract作为背景了解这个记忆库都包含什么东西。
- 有点类似先retrieve,再plan。或者是用一些总结报告做plan
-
不过这里做的比较暴力,把所有的memory的abstract都列出来了
- 决定要使用的tool(keyword, vector, page_index(点查))
Planning_PROMPT = """
You are the PlanningAgent. Your job is to generate a concrete retrieval plan for how to gather information needed to answer the QUESTION.
You must use the QUESTION and the current MEMORY (which contains abstracts of all messages so far).
QUESTION:
{request}
MEMORY:
{memory}
PLANNING PROCEDURE
1. Interpret the QUESTION using the context in MEMORY. Identify what is need to satisfy the QUESTION.
2. Break that need into concrete "info needs": specific sub-questions you must answer to fully respond to the QUESTION.
3. For each info need, decide which retrieval tools are useful. You may assign multiple tools to the same info need:
- Use "keyword" for exact entities / functions / key attributes.
- Use "vector" for conceptual understanding.
- Use "page_index" if MEMORY already points to clearly relevant page indices.
4. Build the final plan:
- "info_needs": a list of all the specific sub-questions / missing facts you still need.
- "tools": which of ["keyword","vector","page_index"] you will actually use in this plan. This can include more than one tool.
- "keyword_collection": a list of short keyword-style queries you will issue.
- "vector_queries": a list of semantic / natural-language queries you will issue.
- "page_index": a list of integer page indices you plan to read fully.
AVAILABLE RETRIEVAL TOOLS:
All of the following retrieval tools are available to you. You may select one, several, or all of them in the same plan to maximize coverage. Parallel use of multiple tools is allowed and encouraged if it helps answer the QUESTION.
1. "keyword"
- WHAT IT DOES:
Exact keyword match retrieval.
It finds pages that contain specific names, function names, key attributes, etc.
- HOW TO USE:
Provide short, high-signal keywords.
Do NOT write long natural-language questions here. Use crisp keywords and phrases that should literally appear in relevant text.
2. "vector"
- WHAT IT DOES:
Semantic retrieval by meaning.
It finds conceptually related pages.
This is good for high-level questions, reasoning questions, or "how/why" style questions.
- HOW TO USE:
Write each query as a short natural-language sentence that clearly states what you want to know, using full context and entities from MEMORY and QUESTION.
Example style: "How does the DenseRetriever assign GPUs during index building?"
3. "page_index"
- WHAT IT DOES:
Directly ask to re-read full pages (by page ID) that are already known to be relevant.
MEMORY may mention specific page IDs or indices that correspond to important configs, attributes, or names.
Use this if you already know specific page indices that should be inspected in full.
- HOW TO USE:
Return a list of those integer page indices (e.g. [0, 2, 5]), max 5 pages.
You MUST NOT invent or guess page indices.
RULES
- Avoid simple repetition. Whether it's keywords or sentences for search, make them as independent as possible rather than duplicated.
- Be specific. Avoid vague items like "get more details" or "research background".
- Every string in "keyword_collection" and "vector_queries" must be directly usable as a retrieval query.
- You may include multiple tools. Do NOT limit yourself to a single tool if more than one is useful.
- Do NOT invent tools. Only use "keyword", "vector", "page_index".
- Do NOT invent page indices. If you are not sure about a page index, return [].
- You are only planning retrieval. Do NOT answer the QUESTION here.
THINKING STEP
- Before producing the output, think through the procedure and choices inside <think>...</think>.
- Keep the <think> concise but sufficient to validate decisions.
- After </think>, output ONLY the JSON object specified below. The <think> section must NOT be included in the JSON.
OUTPUT JSON SPEC
Return ONE JSON object with EXACTLY these keys:
- "info_needs": array of strings (required)
- "tools": array of strings from ["keyword","vector","page_index"] (required)
- "keyword_collection": array of strings (required)
- "vector_queries": array of strings (required)
- "page_index": array of integers (required), max 5.
All keys MUST appear.
After the <think> section, return ONLY the JSON object. Do NOT include any commentary or explanation outside the JSON.
"""
-
Search
- 执行搜索,做个RRF
- Integration
- 根据搜索到的内容尝试生成答案
Integrate_PROMPT = """
You are the IntegrateAgent. Your job is to build an integrated factual summary for a QUESTION.
YOU ARE GIVEN:
- QUESTION: what must be answered.
- EVIDENCE_CONTEXT: newly retrieved supporting evidence that may contain facts relevant to the QUESTION.
- RESULT: the current working notes / draft summary about this same QUESTION (may be incomplete).
YOUR OBJECTIVE:
Produce an UPDATED_RESULT that is a consolidated factual summary of all information that is relevant to the QUESTION.
This is NOT a final answer to the QUESTION. It is an integrated summary of all useful facts that could be used to answer the QUESTION.
The UPDATED_RESULT must:
1. Keep useful, correct, on-topic information from RESULT.
2. Add any new, relevant, well-supported facts from EVIDENCE_CONTEXT.
3. Remove anything that is off-topic for the QUESTION.
QUESTION:
{question}
EVIDENCE_CONTEXT:
{evidence_context}
RESULT:
{result}
INSTRUCTIONS:
1. Understand the QUESTION. Identify exactly what needs to be answered.
2. From RESULT:
- Keep any statements that are relevant to the QUESTION.
3. From EVIDENCE_CONTEXT:
- Extract every fact that helps describe, clarify, or support an answer to the QUESTION.
- Prefer concrete details such as entities, numbers, versions, decisions, timelines, outcomes, responsibilities, constraints.
- Ignore anything unrelated to the QUESTION.
4. Synthesis:
- Merge the selected content from RESULT with the selected content from EVIDENCE_CONTEXT.
- The merged text MUST read as one coherent factual summary related to the QUESTION (not the direct answer).
- The merged summary MUST collect all important factual information needed to answer the QUESTION, so it can stand alone later without needing RESULT or EVIDENCE_CONTEXT.
- Do NOT add interpretation, recommendations, or conclusions beyond what is explicitly stated in RESULT or EVIDENCE_CONTEXT.
RULES:
- "content" MUST ONLY include factual information that is relevant to the QUESTION.
- You are NOT producing a final answer, decision, recommendation, or plan. You are producing a cleaned, merged factual summary.
- Do NOT invent or infer facts that do not appear in RESULT or EVIDENCE_CONTEXT.
- Do NOT include meta language (e.g. "the evidence says", "according to RESULT", "the model stated").
- Do NOT include instructions, reasoning steps, or analysis of your own process.
- Do NOT include any keys other than "content" and "sources".
- "sources" should on incluede the page_ids of the pages that supported the included facts.
THINKING STEP
- Before producing the output, think about selection and synthesis steps inside <think>...</think>.
- Keep the <think> concise but sufficient to ensure correctness and relevance.
- After </think>, output ONLY the JSON object. The <think> section must NOT be included in the JSON.
OUTPUT JSON SPEC:
Return ONE JSON object with EXACTLY:
- "content": string. This is the UPDATED_RESULT, i.e. the integrated final information related to the QUESTION, if there not exist any useful information, just provide "".
- "sources": array of strings/objects.
Both keys MUST be present.
After the <think> section, return ONLY the JSON object. Do NOT output Markdown, comments, headings, or explanations outside the JSON.
"""
- Reflection
- 决定是否继续搜索,还是去生成答案
-
生成答案是单独又用了一次大模型,有一个FollowUpRequest的prompt
InfoCheck_PROMPT = """
You are the InfoCheckAgent. Your job is to judge whether the currently collected information is sufficient to answer a specific QUESTION.
YOU ARE GIVEN:
- REQUEST: the QUESTION that needs to be answered.
- RESULT: the current integrated factual summary about that QUESTION. RESULT is intended to contain all useful known information so far.
YOUR OBJECTIVE:
Decide whether RESULT already contains all of the information needed to fully answer REQUEST with specific, concrete details.
You are NOT answering REQUEST. You are only judging completeness.
REQUEST:
{request}
RESULT:
{result}
EVALUATION PROCEDURE:
1. Decompose REQUEST:
- Identify the key pieces of information that are required to answer REQUEST completely (facts, entities, steps, reasoning, comparisons, constraints, timelines, outcomes, etc.).
2. Check RESULT:
- For each required piece, check whether RESULT already provides that information clearly and specifically.
- RESULT must be specific enough that someone could now write a final answer directly from it without needing further retrieval.
3. Decide completeness:
- "enough" = true ONLY IF RESULT covers all required pieces with sufficient clarity and specificity.
- "enough" = false otherwise.
THINKING STEP
- Before producing the output, perform your decomposition and evaluation inside <think>...</think>.
- Keep the <think> concise but ensure it verifies completeness rigorously.
- After </think>, output ONLY the JSON object with the key specified below. The <think> section must NOT be included in the JSON.
OUTPUT REQUIREMENTS:
Return ONE JSON object with EXACTLY this key:
- "enough": boolean. true if RESULT is sufficient to answer REQUEST fully; false otherwise.
RULES:
- Do NOT invent facts.
- Do NOT answer REQUEST.
- Do NOT include any explanation, reasoning, or extra keys.
- After the <think> section, return ONLY the JSON object.
"""
GenerateRequests_PROMPT = """
You are the FollowUpRequestAgent. Your job is to propose targeted follow-up retrieval questions for missing information.
YOU ARE GIVEN:
- REQUEST: the original QUESTION that we ultimately want to be able to answer.
- RESULT: the current integrated factual summary about this QUESTION. RESULT represents everything we know so far.
YOUR OBJECTIVE:
Identify what important information is still missing from RESULT in order to fully answer REQUEST, and generate focused retrieval questions that would fill those gaps.
REQUEST:
{request}
RESULT:
{result}
INSTRUCTIONS:
1. Read REQUEST and determine what information is required to answer it completely (facts, numbers, definitions, procedures, timelines, responsibilities, comparisons, outcomes, constraints, etc.).
2. Read RESULT and determine which of those required pieces are still missing, unclear, or underspecified.
3. For each missing piece, generate ONE standalone retrieval question that would directly obtain that missing information.
- Each question MUST:
- mention concrete entities / modules / components / datasets / events if they are known,
- ask for factual information that could realistically be found by retrieval (not "analyze", "think", "infer", or "judge").
4. Rank the questions from most critical missing information to least critical.
5. Produce at most 5 questions.
THINKING STEP
- Before producing the output, reason about gaps and prioritize inside <think>...</think>.
- Keep the <think> concise but ensure prioritization makes sense.
- After </think>, output ONLY the JSON object specified below. The <think> section must NOT be included in the JSON.
OUTPUT FORMAT:
Return ONE JSON object with EXACTLY this key:
- "new_requests": array of strings (0 to 5 items). Each string is one retrieval question.
RULES:
- Do NOT include any extra keys besides "new_requests".
- After the <think> section, do NOT include explanations, reasoning steps, or Markdown outside the JSON.
- Do NOT generate vague requests like "Get more info".
- Do NOT answer REQUEST yourself.
- Do NOT invent facts that are not asked by REQUEST.
After the <think> section, return ONLY the JSON object.
"""
Experiment
-
对于hotpotQA这种,是把所有的文本先做chunk,再去把每一个chunk作为一段memory保存下来的。和通用RAG一样
-
对于locomo这种,是一个session一段memory保存下来的
- DeepResearch这种,主要问题就是在线serve的延迟比较高。不知道受众如何
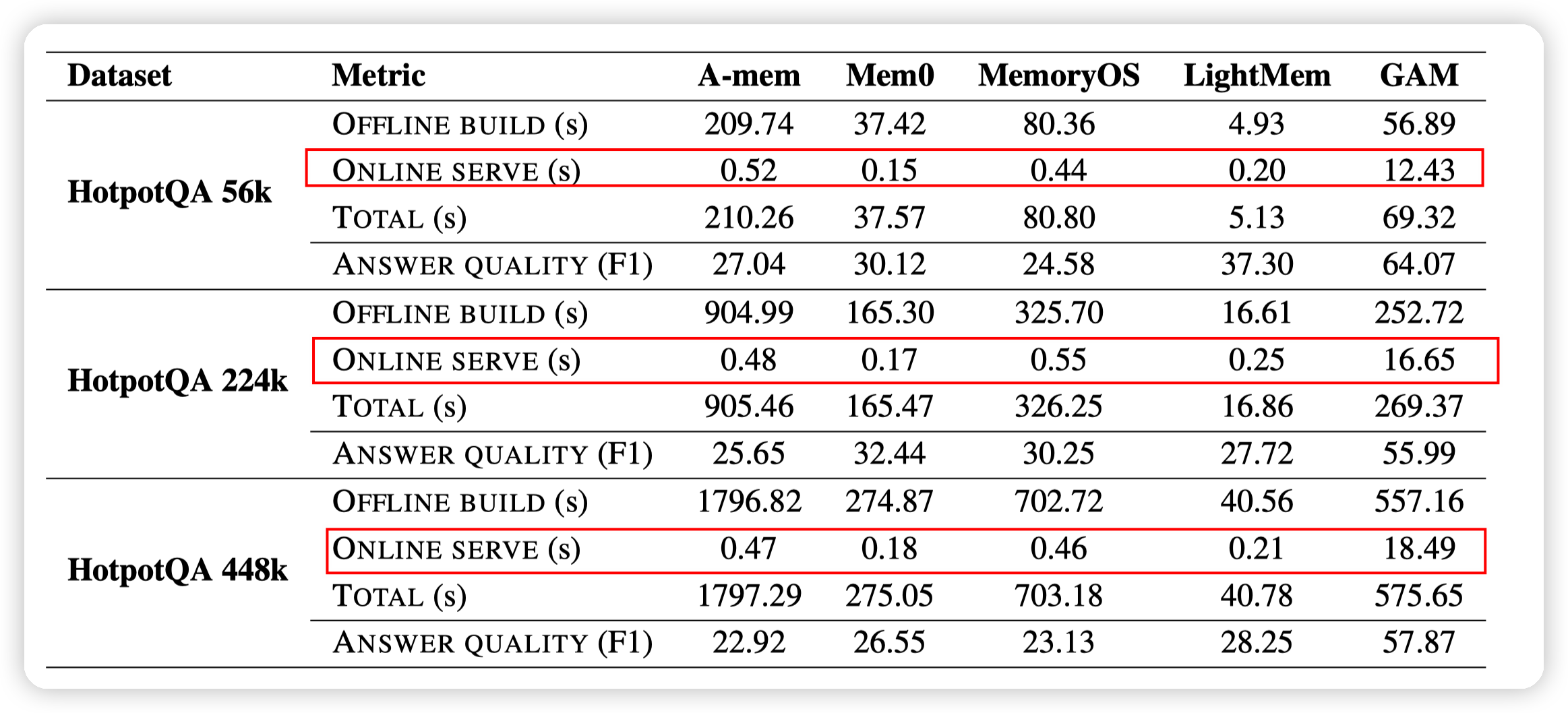
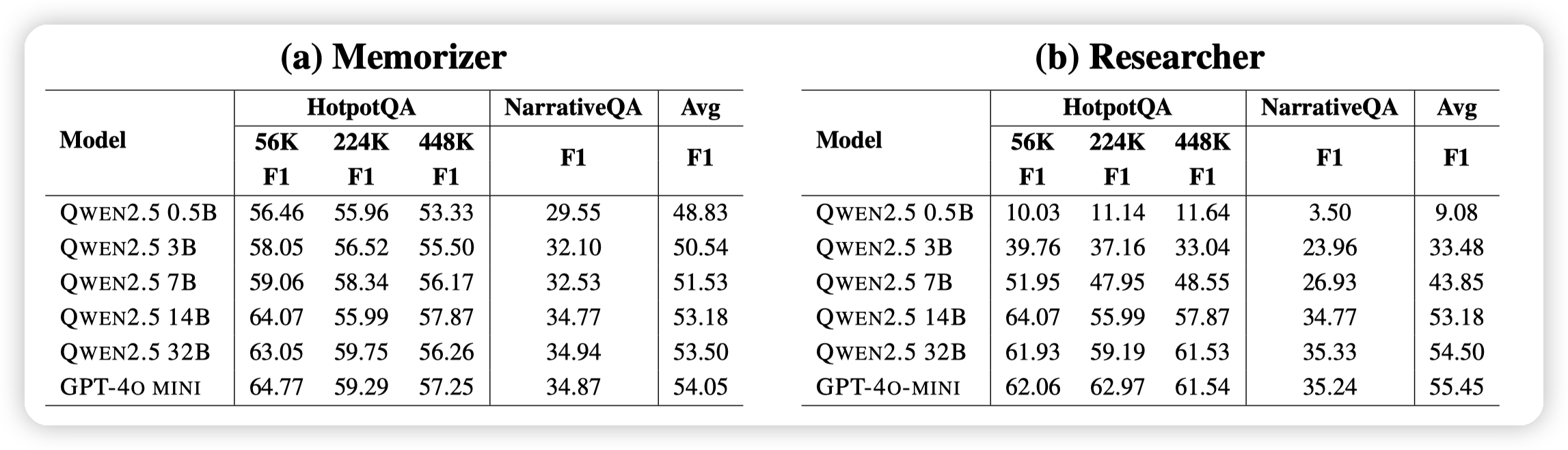
- 不同模型的实验:
- 模型对memorizer影响较小,对researcher影响比较大。
-
用轻量级的索引方式提高索引效率。然后在问答阶段引入更强的模型和Agent。也符合现在Agent发展的思路
Ablation
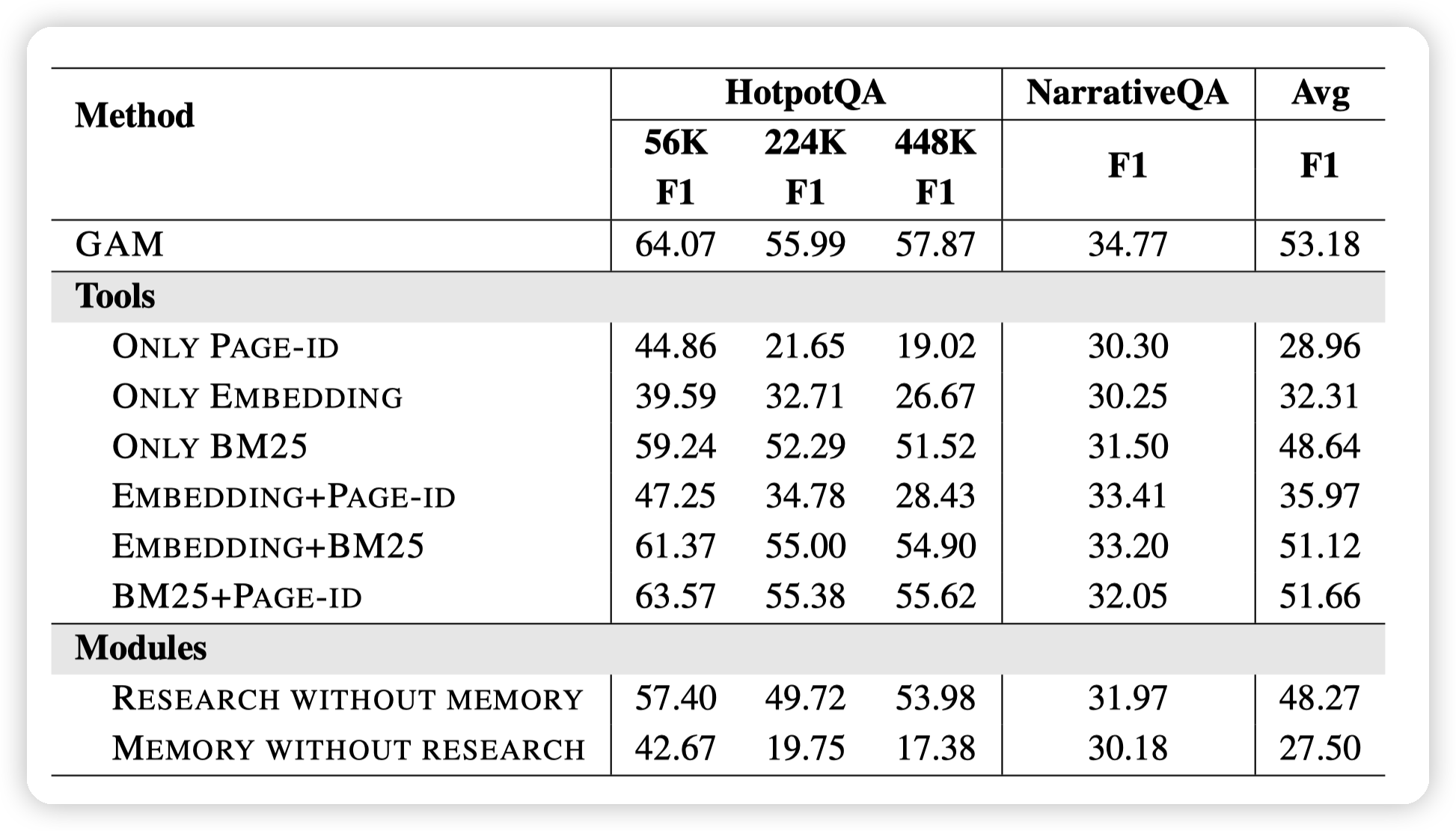
- DeepResearch的消融实验,主要是search之后,做后续反思的时候是否是用总结,还是带上原文。
- With page就是带上原文,效果会更好一些
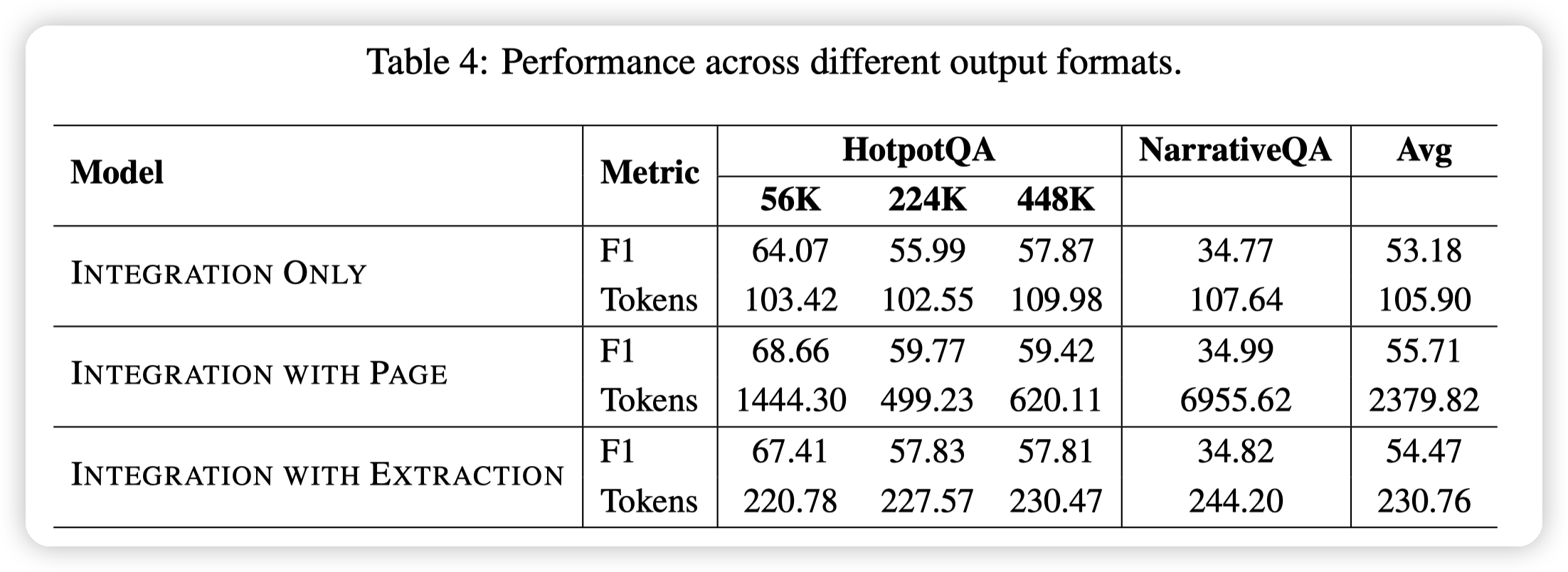
- 上面是搜索的消融实验,总之就是都加上效果会好一些
-
下面则是对Research的消融,可以看到hotpot QA 448k这种超大的知识库,deep research发挥的效果还是比较明显的。
- 启发?对于我们一些比较大的知识库,是否可以推销一下Agent问答的方式

文章评论