论文:Rethinking Agent Design: From Top-Down Workflows to Bottom-Up Skill Evolution
代码整体比较简单,很多细节并没有仔细的处理,不过思路值得学习一下,毕竟是一个training-free的方法,适合没有算力的小伙伴
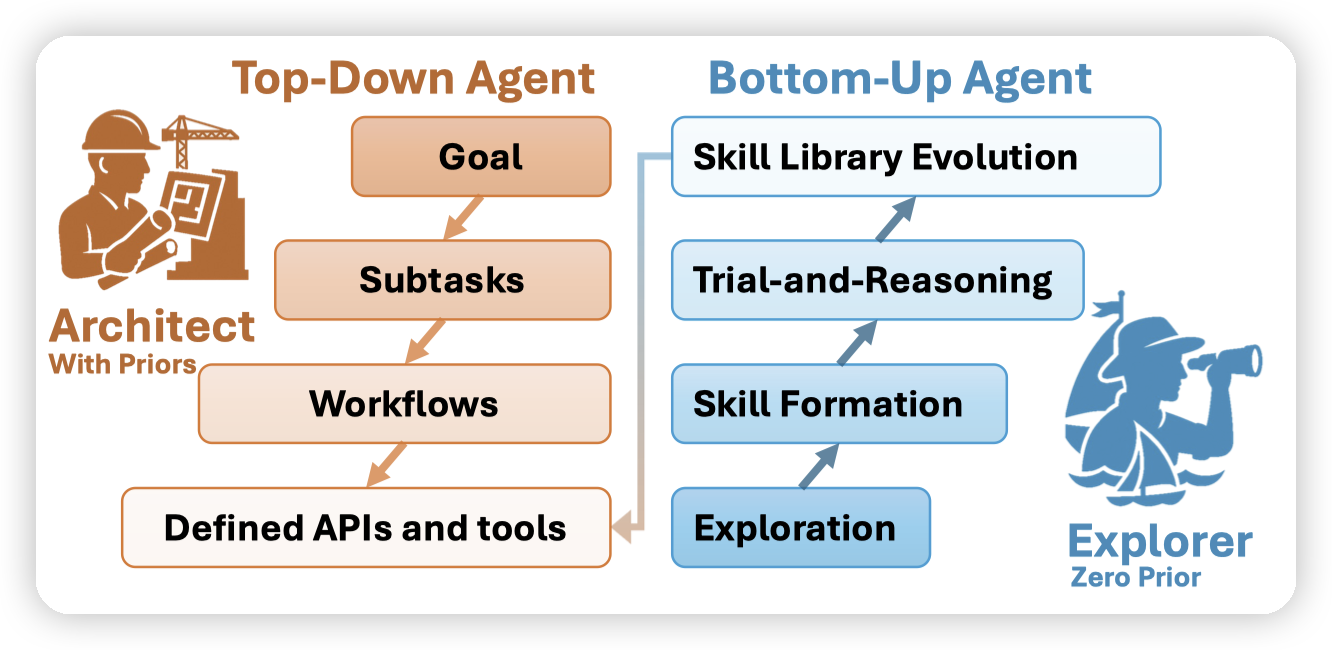
当前大多数 LLM-based agents(基于大模型的****智能体****) 都采用 自上而下(Top-Down) 的设计方式:
- 人类先拆解任务
-
设计工作流
-
指定 agent 执行每一步
➡️ 这种方式在基准任务上效果好,但 缺乏自我学习能力,无法适应开放环境。
论文作者希望实现一种与人类更相似的学习方式:自下而上的(Bottom-Up)技能演化****智能体****。 智能体通过:
- 自主探索
-
反思失败
-
总结技能
-
不断积累来逐步提升能力。
作者在Slay the Spire****(杀戮尖塔) 和 Civilization V(文明5) 两款复杂环境中验证了这种范式,智能体直接以 视觉输入 + 鼠标行为输出 与环境互动,无需任何游戏专用的提示词或API。
涉及到的技术点主要有两个:
- 如何做技能的探索,反思,总结。来做到不断积累
-
如何和环境做交互
Skill Evolution
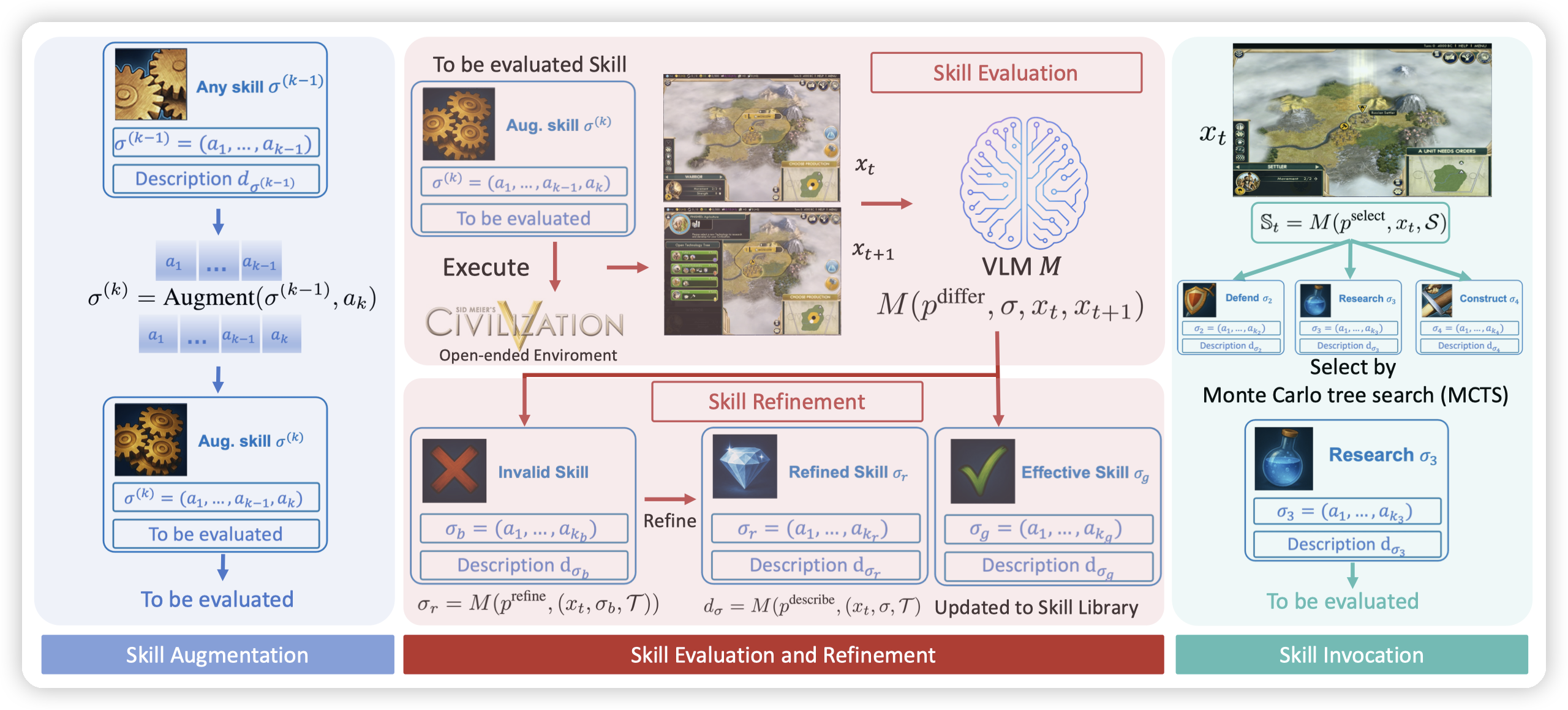
根据skill的生命周期,有skill的生成,评估,淘汰:
- 每一个skill是一系列的原子操作组成的。
- 比如攻击skill,是由[点击攻击卡,点击敌人]组成的
- Skill augmentation是根据现有的skill,增加一些原子操作,得到新的skill。
- 比如现有的skill的动作序列是点击一张卡。是一个完全无用的skill
-
在这个skill后面增加一个点击敌人的操作,就是发动这张卡,就会得到一个新的skill
-
通过MCTS做,会高概率的拓展一些高分的skill
-
Skill evaluation,就是评估skill的效果。
- 比如图示中,执行一个操作后,会得到一个新的界面。把这两个时刻的状态,和执行的操作输入给LLM
-
和论文里说的不太一样,看代码评估的点主要是两个:
- consistent,skill是否按照预期改变了游戏环境。(比如攻击预期敌人会掉血)
-
progressive,skill是否对游戏进度产生影响。(比如一直开关菜单不会对游戏产生什么正面的进度)
-
Skill refinement,对应skill的淘汰
- 部分skill在多次执行后,会发现用处不大,就会被skill library中删除掉
- Skill invocation:
- 这里会先让LLM根据语义从所有的skill中选择出来一个子集,比如当前状态决策要进行攻击。
-
然后通过MCTS来决策具体要执行那个skill
-
核心思路是让LLM做高层的决策,由MCTS来决定怎么做最有效
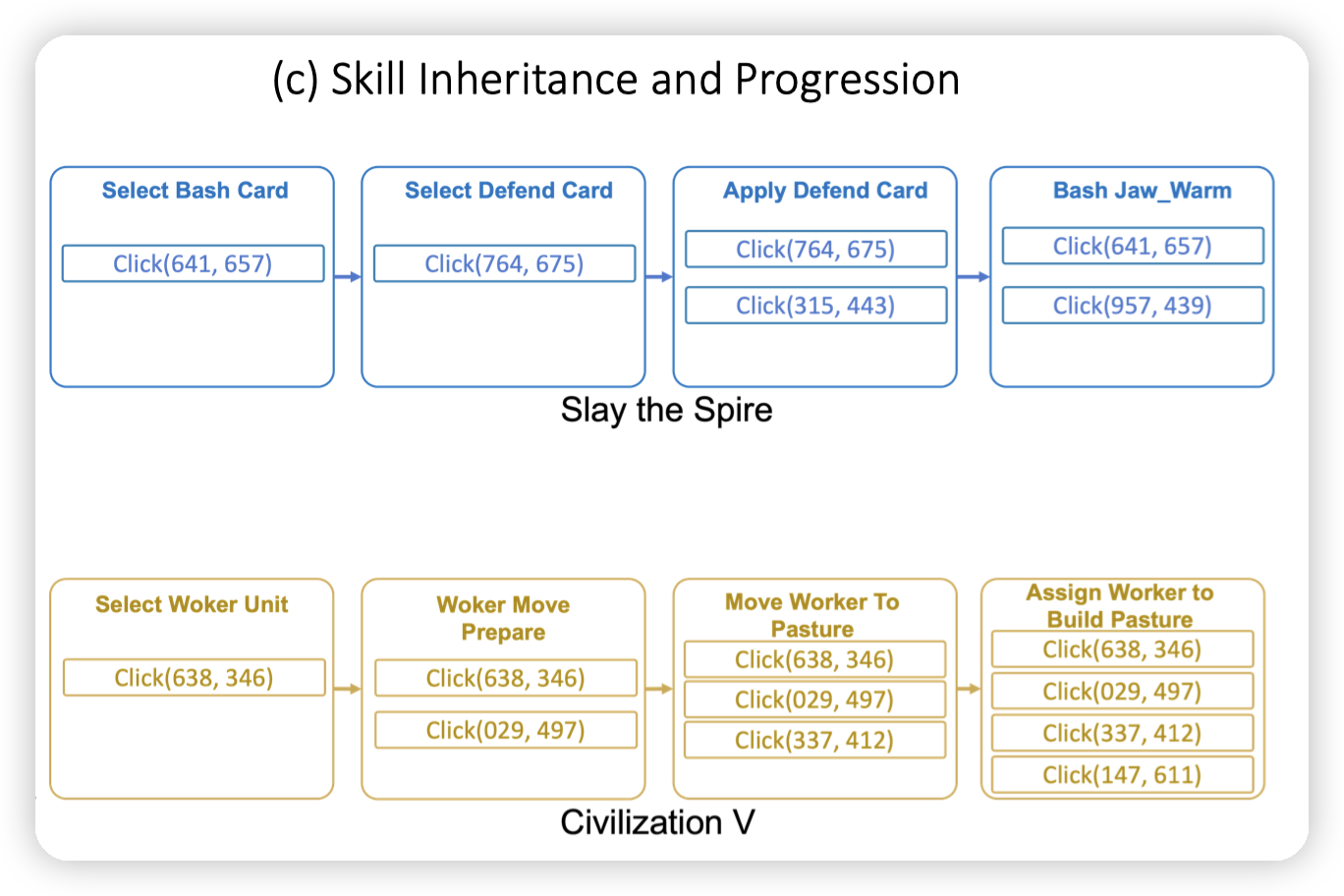
一个直观的理解,来看看skill都有什么
Environment Interaction
这块和一些GUI Agent是一样的,和环境的交互主要是两块:
- 感知环境
- 每一个状态对应的是游戏的一个截图。相似的状态会做去重(通过视觉模型的Embedding相似度卡一个阈值)
-
通过SegmentAnythingModel,得到当前游戏截图中的所有UI Object(bbox, image)
-
作出动作
- 通用的鼠标/键盘的输入
-
具体执行动作时,比如点击object(1)这个动作,会被上面探测出来的UI Object,转化为点击(xxx, yyy)这个像素点
Framework
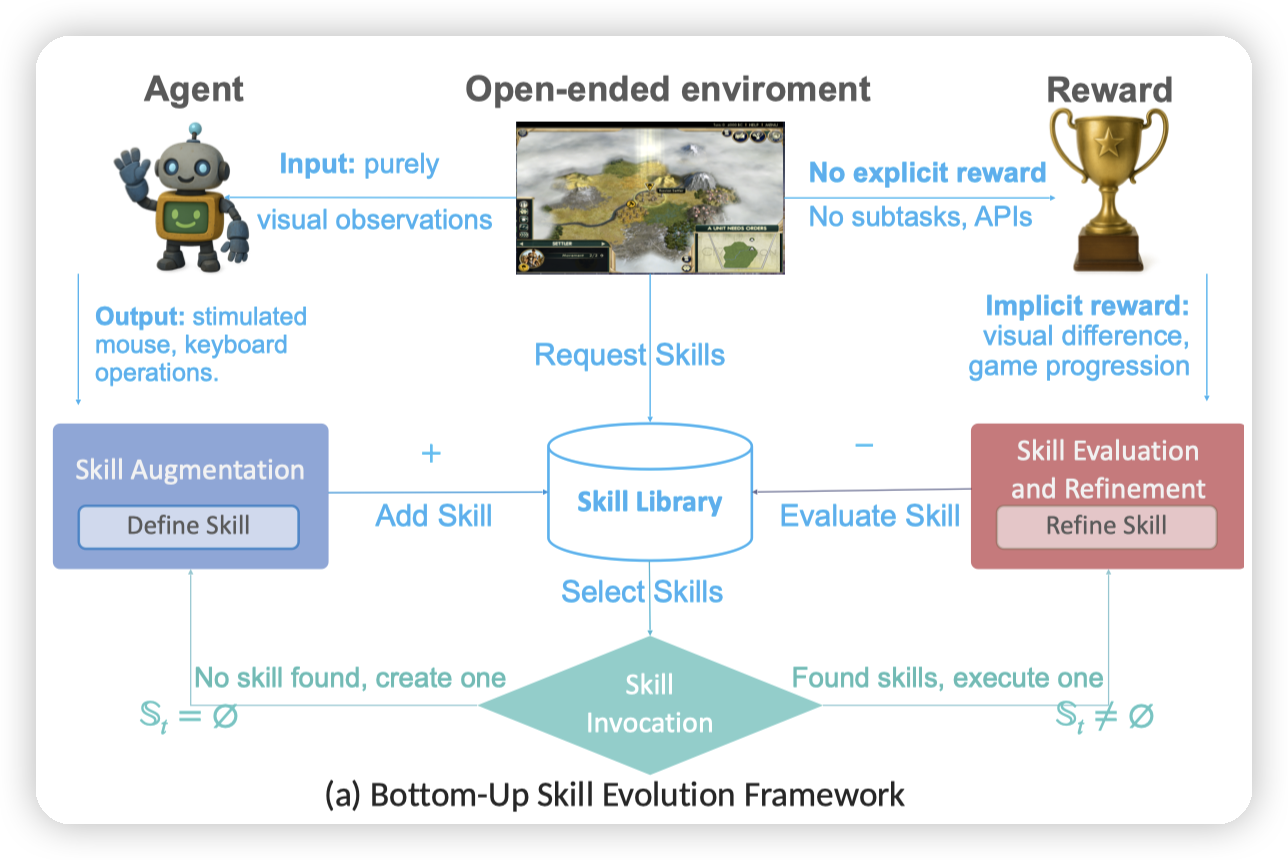
Agent在进入游戏后,会进入一个循环。每一个step会执行:
- 获取当前游戏截图,找到是否有相似的历史状态。从而得到当前的状态
- 比如对决相同的敌人
- 首先通过LLM,根据当前状态选择skill的子集
- 比如是要做进攻动作,还是防御动作
- 如果没有skill,会尝试做skill augmentation,生成新的skill
-
通过MCTS,在子集中选择skill进行执行。并评估skill的效果
- 这里因为是游戏环境,rollout不太好做。所以也没有那么MCTS,只不过是记录了每个skill的得分/尝试次数,然后用UCT(Upper Confidence Bounds for Trees)来算了个分数,平衡新策略的探索和老策略的利用
- 做skill evolution,清理无效的skill
CaseStudy


后续改进
可以看到上面的决策过程中,没有关注长期策略的影响,更多的是关注当前skill是否对游戏产生进展。同时也没有考虑状态之间的转移。
后续的一篇工作EXPERIENCE -DRIVEN EXPLORATION FOR EFFICIENT API-FREE AI AGENTS做了一些改进:
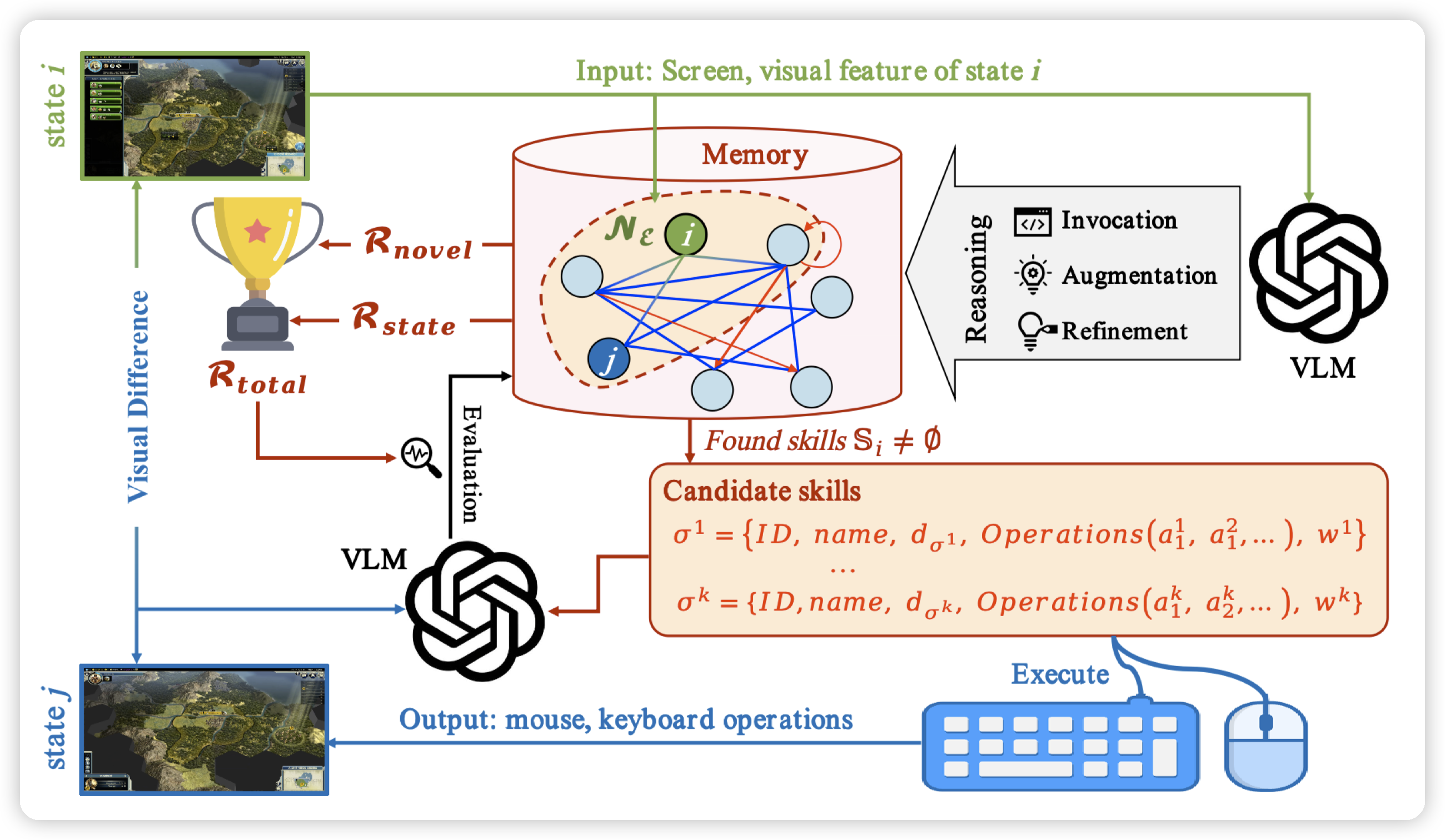
- 类似Q-Learning等方法刻画了动作价值,这里以图的形式记录了每一个状态下,执行不同skill可能得到的reward。
-
同时skill的reward会考虑到移动到新状态的价值。而状态的价值则由这个状态下skill的价值来计算得到。(非常类似贝尔曼方程刻画V/Q的关系了,只不过添加了一些偏启发的因素在里面)
-
这篇paper感觉更像是,用RL的算法(或者说近似RL的算法)来跑策略,然后由VLM来生成reward
可惜的是两篇paper并没有类似这篇paper一样《SWE-Exp: Experience-Driven Software Issue Resolution》“针对轨迹进行反思,生成一些指导性质的策略,来辅助做后续决策的思路”,更多的还是类似RL这种比较“统计”一些方法
- 这种应用在现实中的Agent训练成本会比较高。
-
比如slay the spire中,通过轨迹总结出不同敌人的攻击模式/特性,来得到一些指导性的策略。
还有一个点,就是两篇paper都把整个过程建模为POMDP,也就是只能通过观测得到一个可能的状态,来做后续的决策。
- 游戏这种状态比较复杂的,无法单独通过一个截图表达状态。比如在SC2上做RL的时候,也会编码很多其他的数值特征放进去。
-
如果是以API-FREE的方式想,可能引入一些类似Agent Memory的机制,把一些关键信息记录下来做后续决策可能会更好一些。
- 比如state = (vision_embedding(screen_shot) | text_embedding(summary))
代码
https://github.com/AngusDujw/Bottom-Up-Agent
Hand
Hand 类是 Agent 的执行器(执行层),负责将决策转化为实际的鼠标和键盘操作,控制游戏或应用程序。可以把它理解为 Agent 的"手"
依赖pyautogui
- move/left_single_click/right_single_click(x, y)
-
do_operation() 高级操作:
- 没有单独的按键的操作,只有一个hot key是针对组合键的

Eye
Eye 类是 Agent 的视觉感知层(观察器),负责获取游戏窗口的屏幕截图和检测画面变化。它就像 Agent 的"眼睛",用来观察环境状态。
- get_screenshot_cv获取窗口截图
-
detect_acted_cv获取两次截图的diff,看像素差值是否过大(用来节省输入给模型的图片)
Detector
Detector 类是 Agent 的视觉理解层,负责从屏幕截图中提取和识别可交互对象。它结合了 SAM(Segment Anything Model) 进行对象分割和 CLIP 进行图像编码。
- 分割相关
- extract_objects,提取场景中的对象,并做一下过滤/去重的清洗,获取对象的:
- Boundary box/area, hash, center, image
- update_objects,提取对象,并和之前提取的对象做去重。(尝试合并object)
- extract_objects,提取场景中的对象,并做一下过滤/去重的清洗,获取对象的:
-
编码:
- 用的ViT-B/32模型,clip库可以load一些这种多模态的模型,提供encode_text/image的接口,生成图片/一段文字的embedding
-
encode_text
-
encode_image
LongMemory
LongMemory 类是 Agent 的长期记忆系统,使用 SQLite 数据库持久化存储游戏状态、对象、技能和技能簇等信息,让 Agent 能够跨会话学习和复用知识。
不是我们通常认为的会话类的memory,更像是知识库一样
三组接口:
- Object,处理binary,比如图片的存储
- get_by_id
-
update_object。
-
States
- save_state
-
get_state
-
Skill/SkillCluster
- get_skill_cluster_by_id/save_skill_cluster
-
get_skill_by_id/save_skill/delete_skill
PreKnowledge
通过Prompt注入的一些任务相关的知识
比如slay the spire的:
You are an AI assistant playing the deck-building roguelike game **Slay the Spire**. Below is a summary of the game rules and controls you must know:
Game Overview:
- You control a hero who climbs a spire by defeating enemies in turn-based card battles.
- In each battle, you have **energy** (default 3 per turn) to play cards.
- Cards can be **Attacks**, **Skills**, **Powers**, or **Curses**.
- The goal is to reduce the enemy's HP to 0 while surviving.
Card Types:
- **Attack**: Deals damage to the enemy.
- **Skill**: Provides defense (block), buffs, or utility.
- **Power**: Applies a passive effect for the rest of the battle.
- **Curse/Status**: Unplayable or harmful cards.
Turn System:
- Each turn, you draw 5 cards.
- You can play cards as long as you have energy.
- Enemies show **intents** (e.g. attack, buff, block) above their heads.
Combat Strategy Basics:
- **Block** mitigates damage but disappears at the end of your turn.
- Use **energy efficiently** — don't waste points.
- Prioritize removing enemies with high damage output or debuffs.
- Watch for **vulnerable**, **weak**, and **frail** effects (common debuffs).
Controls (UI-based):
- Click on cards to play them (if you have enough energy).
- Drag cards to enemies or yourself depending on the target.
- Click the “End Turn” button to end your turn.
- Hover or click on enemy intent icons to see what they plan to do.
Goals for AI:
- Analyze visible cards, energy, and enemy intents.
- Decide the best action: which cards to play, which enemies to target.
- Consider card cost, effects, and current HP/block values.
Main
在main之前还有一个brain更核心,但是因为是主体的驱动流程,所以和main一起看
- run_step
- get_observation,获取当前屏幕的截图,以及对应的embedding
-
从long memory中查找和当前屏幕状态相似的历史状态
-
如果没有相似的,那么会初始化一个新的state,包含:
- state_feature,就是截图的embedding
-
object_id
-
一个空的mcts,和空的skill cluster
-
下一步会让模型选择Skill cluster
-
然后根据skill cluster,选择skill
-
选择出来的可能是explore,探索新的技能,或者是exploit,执行已有的技能。
- 为了避免无限重试,如果执行技能失败了会重试,并将失败的技能记录下来,下次不会选择。
- 同时这里好像会把skill cluster下所有的skill都执行一遍
- Explore
- 通过skill augment生成新的技能,并保存下来
- 这里会先把当前mcts节点下的operation都执行了,然后更新屏幕里的object id
-
然后生成potential operation:对于所有object,都click一下
-
对于当前mcts节点的所有子节点,过滤一下已经存在的operation
-
剩下的就是未被探索过的operation,这里会随机选一个,或者是让人来帮忙选一个
-
然后做do operation,看新的这个操作是否会导致屏幕变化。如果没有变化,则探索失败
-
如果屏幕变化了,会生成新的skill,并且如果state feature有改变,则会设置node.fixed,并退出生成skill的环节。
-
生成的skill会利用大模型做cluster,得到skill cluster
- 通过skill augment生成新的技能,并保存下来
-
Exploit
- 对于选中的skill,skill会包含若干个operation,对每一个operation
- 首先进行grounding,把操作的对象id映射到屏幕的坐标中,然后执行操作
- 执行完之后,会判断执行后和执行前的diff,如果差距过小,则说明执行失败,返回失败
-
没有失败的话,会开始进行技能的评估,brain.skill_evaluate
- 用大模型做的
- 如果技能执行效果和描述的一致,会增加skill_fitness。如果技能使得任务有进展,也会增加skill_fitness
-
保存skill的fitness和evaluate num,返回continue继续进行下一个skill的执行
- 对于选中的skill,skill会包含若干个operation,对每一个operation
- 为了避免无限重试,如果执行技能失败了会重试,并将失败的技能记录下来,下次不会选择。
-
最后还会有一个skill evolution,会根据一个阈值,清理掉执行次数多,但是fitness比较低的skill
- 比如有的skill点了一直没啥用。或者点了没有使任务产生进展,就会被删除掉
Prompt
然后来看看一些核心任务的Prompt
| Generate skill |
```Markdown | 通过operation生成skill的描述 |\
|| Objectives: |\
|| - Analyze the recent UI-level operations you performed. |\
|||\
|| Inputs: |\
|| 1. A list of UI-level operations: '{operations}' |\
|| 2. Screenshots of the game captured during these operations. |\
|||\
|| Instructions: |\
|| 1. Determine which UI elements were interacted with, based on the coordinates provided. |\
|| 2. Analyze how the game screen changed during the operations. |\
|| 3. Give this sequence of operations a meaningful **name** and a **description** that includes: |\
|| - What the operation does (its function) |\
|| - Any precautions to take |\
|| 4. The name must be highly relevant to the actual operations performed. |\
|| 5. If the operations are **meaningless**, use the `no_meaning_skill` tool to report it. |\
|| 6. If the operations are **meaningful**, use the `save_skill` tool to save the result. |\
|| 7. Think step by step before making a decision. |\```
</th>
</tr>
</thead>
<tbody>
<tr>
<td>Cluster skill</td>
<td>
```SQL | 聚类相似的skill,生成skill cluster |\Background: |\ You are an assistant for grouping similar skills. |\ Input: a JSON array called “new_skills”. |\ |\ Task: Identify skills that are nearly identical in meaning or function, even if their expressions differ. |\ • Group together skills that essentially perform the same task or behavior, even if worded differently. |\ • Do not group skills that express different functions or intentions, even if they appear related. |\ • Think of this as merging duplicates or near-duplicates, not broad semantic clustering. |\ |\ Output must strictly call the function “cluster_skills” with no extra text. |\ |\ Here is the list of new_skills (id, name, description): |\ {json.dumps(skills, indent=2)} |\ |\ Please: |\ 1. Identify cluster of functionally equivalent skills. |\ 2. For each cluster, select a representative “action_name” and “action_description”. |\ 3. List its members as an array of action ids. |\ ```
</td>
</tr>
<tr>
<td>Merge skill cluster</td>
<td>
```SQL | 把skill合并到cluster中 |\Background: |\ You are an assistant that merges and clusters skills in one call. |\ Input: |\ • existing_skill_clusters: clusters with cluster_id, name, description, members |\ • new_skills: raw skills with id, name, description |\ Instruction: |\ 1) Cluster new_skills among themselves by semantic similarity. |\ 2) For each resulting new cluster: |\ - If it matches an existing cluster, merge into it (reuse that cluster_id). |\ - Otherwise, assign cluster_id = -1. |\ 3) Each output cluster must include: |\ - cluster_id |\ - name & description (representative) |\ - members: combined list of all action IDs. |\ Output: |\ Exactly one function_call to "merge_skills", no extra text. |\ |\ existing_skill_clusters: |\ {json.dumps(existing_skill_clusters, indent=2)} |\ |\ new_skills: |\ {json.dumps(new_skills, indent=2)} |\ |\ Please perform the merge as specified. |\ Return the merged list under the key "clusters". |\ ```
</td>
</tr>
<tr>
<td>Select skill</td>
<td>
```SQL | 实际上是选择skill cluster |\Objectives: |\ - Select the best skill from the provided skill list. |\ |\ Inputs: |\ 1. A list of learned skills. |\ 2. A screenshot of the current game state. |\ |\ Skills: |\ {skills} |\ |\ Instructions: |\ 1. Analyze the screenshot to understand the current state of the game. |\ 2. For each skill, assess: |\ - Whether the execution conditions are currently satisfied. |\ - Whether it is functionally suitable for current state. |\ 3. First, eliminate any skills that are not currently executable. |\ 4. Then, among the remaining executable skills, choose the one most appropriate. |\ 5. Must return your selection using the function tool provided — do NOT respond with text. |\ 6. Think step by step before making your final decision. |\ ```
</td>
</tr>
<tr>
<td>Skill evaluate</td>
<td>
```SQL | 评估skill是否progressive,以及效果是否一致 |\Task: |\ - '{task}' |\ |\ Inputs: |\ 1. Action Information |\ Name and description of the action: |\ {skill_info} |\ |\ 2. Screenshots |\ A pair of images showing the game state before and after the action. |\ |\ Instructions: |\ |\ Step 1: Expected Change |\ - Based on the action description, summarize what is expected to change in the game state if the action works as intended. |\ |\ Step 2: Actual Change |\ - Analyze the differences between the before and after screenshots. |\ - Describe all observable UI changes (e.g., elements, values, progress bars, icons). |\ |\ Step 3: Consistency Check → is_consistent|\- If the actual changes match the expected outcome (in type and magnitude), set is_consistent = true; otherwise,false. |\|\ Step 4: Progress Indicators |\ - Identify at least three concrete, task-relevant indicators that suggest progress toward the task goal. |\ |\ Step 5: Progress Check → is_progressive|\- Evaluate whether any of the indicators were clearly met. |\ - If any indicator is met meaningfully, set is_progressive = true. |\- If none are met, or if changes are negligible/irrelevant, set is_progressive = false. |\- If the action is only preparatory (e.g., hovering, previewing, selecting without effect), set is_progressive = false. |\|\ Step 6: Default to False |\ - If information is incomplete, unclear, or ambiguous, default both booleans to false. |\|\ Remember: |\ → Do not guess. |\ → Only return the action_reflexfunction call with the evaluated booleans. |\```

文章评论