Improving Language Understanding by Generative Pre-Training
Language Models are Unsupervised Multitask Learners
Language Models are Few-Shot Learners
对应这三篇paper
https://zhuanlan.zhihu.com/p/609367098
知乎上有对应的讲解
GPT1的核心思路是,通过language model做预训练,然后再针对下游的任务做fine tune
- 在finetune的时候,他们会把Language model的损失也加入进去

- finetune的时候,也需要针对下游任务的输入格式做调整。这里GPT的调整更加简单一些,都通过文本输入就行。也有了一些zero-shot learning的雏形
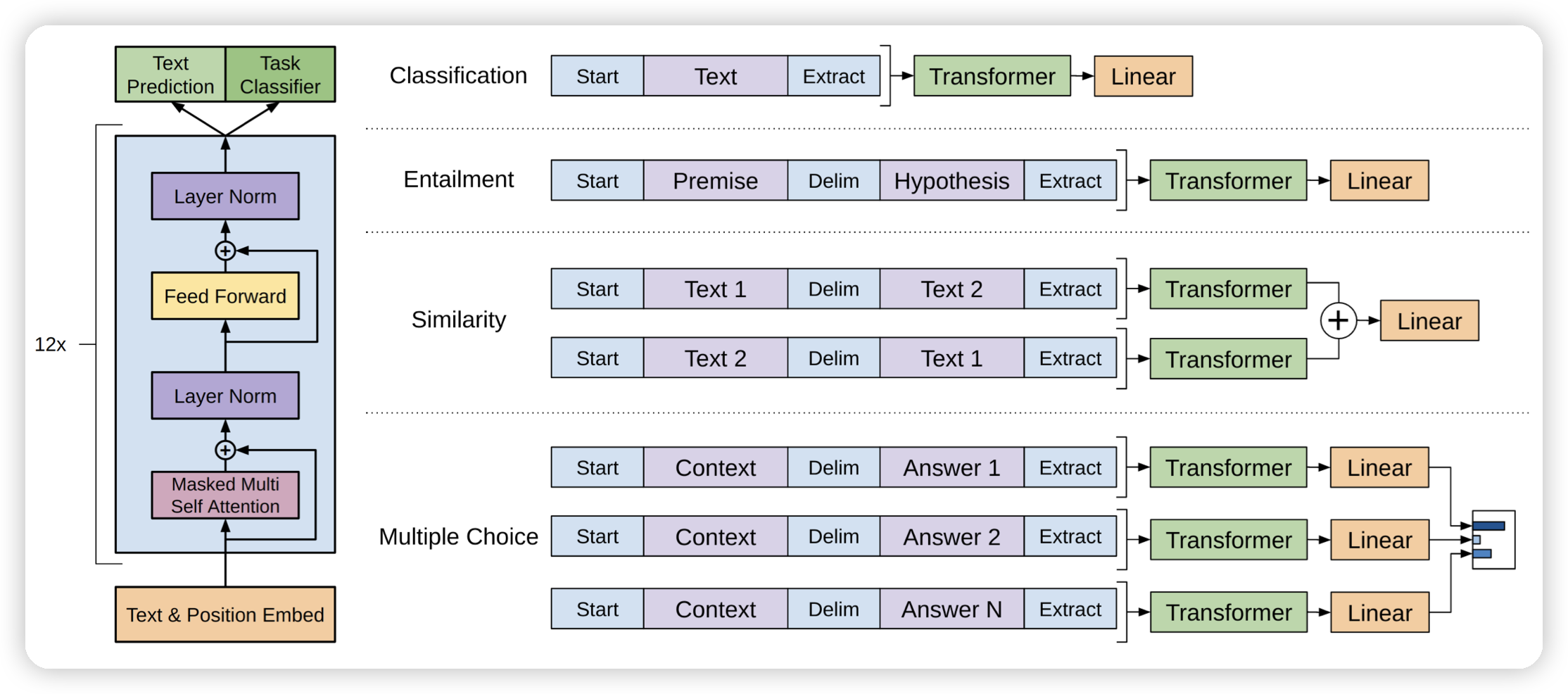
到了GPT2,则是把方向放在了zero-shot learning,不去做fine-tune,而是直接把任务描述和数据通过text sequence丢给模型
Our speculation is that a language model with sufficient capacity will begin to learn to infer and perform the tasks demonstrated in natural language sequences in order to better predict them
同时GPT2也进一步把模型做大,因为他们认为随着语言模型变大,他的通用性也会变强
- 语言模型还有一个好处是可以比较好的利用互联网上大量的无标签的数据,但是网络上的数据有质量问题。所以这里GPT2的思路是,从reddit上找向外引用的链接,然后从这些地方拉数据(这里思路就是,人在社交媒体上引用的文章的质量一般不会很差)
- 经过一些数据清洗之后,得到的数据规模大概是40G
- GPT2另一个优化点是优化了BPE的编码。用1个byte做基本的词表,然后逐渐做merge。(貌似BPE本来就是这样的?)
这里有关zero shot的能力来源的介绍,在知乎这篇文章里有一些描述:
GPT2希望通过喂给模型Zero-shot类型的样本,不告诉模型“做什么”,“怎么做”,让模型自己去体会。但是,你总不能让所有的数据都长成图例里Zero-shot那样吧,那和去标注数据有什么区别?所以,这时候,语言的魅力就来了。一段普通的文字里,可能已经蕴含了“任务描述”、“任务提示”和“答案”这些关键信息。比如,我想做英法文翻译这件事,那么我从网上爬取的资料里可能有这样的内容:
- ”I’m not the cleverest man in the world, but like they say in French: Je ne suis pas un imbecile [I’m not a fool].
- “I hate the word ‘perfume,”’ Burr says. ‘It’s somewhat better in French: ‘parfum.’
如果我把这样的文本喂给GPT,它是不是就能在学习文字接龙的过程里,领悟到英法互译这一点?如果我的数据集又多又棒,那GPT自主揣摩的能力是不是就能更强?所以,GPT2在训练数据上,玩出了花样。它从著名的在线社区Reddit上爬取训练数据(数据具有一定的问答特性),并按社区用户的投票结果筛选出优质的内容。在这个方式下,训练出了1.5B的GPT2,效果基本与Bert差不多。从实用性的角度上,GPT2并没有带来突破,但是,zero-shot的训练方式,却有效证明了NLP领域训练出一个完全通用模型的可行性,这一刻开始,LLM走AIGC的路初见萌芽,因为整个训练流程看起来就像是模型自主学习知识。
虽然一定程度上验证了这种语言模型有zero-shot的能力,但是他们的效果并不是非常的好。根据上面OpenAI选手们的预测,他们决定继续增加模型大小。于是就有了GPT3
GPT3的核心思路有两点:
* 根据他们之前提出的scaling law,继续扩大模型和数据集
* 模型变成了175B
* 数据集没说多大,不过相比于GPT2用上了CommonCrawl的数据(筛选后的)
* 
* 用few-shot替代zero-shot,来优化效果
这里其实从GPT3到原始的transformer decoder有一些模型架构上的变化,这里让deepseek帮忙总结了一下:
GPT-3 的模型架构在原始 Transformer Decoder 的基础上进行了多项重要改进,主要体现在以下几个方面:
1. 稀疏注意力机制(Sparse Attention)
- 原始 Transformer:Decoder 使用标准的全连接掩码自注意力(Masked Self-Attention),每个位置需要计算与序列中所有之前位置的注意力权重。
- GPT-3 的改进:
- 引入 交替密集和局部带状稀疏注意力(Alternating Dense and Locally Banded Sparse Attention),灵感来自 Sparse Transformer。
- 局部带状模式:某些层中,每个位置仅关注局部窗口(如固定长度的相邻位置),而非全部历史位置。
- 交替结构:不同层交替使用密集(全连接)和稀疏注意力,兼顾全局与局部依赖。
- 优势:显著减少计算复杂度(尤其是长序列场景),同时保持对关键上下文信息的捕捉能力。
2. 预归一化(Pre-Normalization)
- 原始 Transformer:采用 后归一化(Post-LN),即在残差连接后应用层归一化(LayerNorm)。
- GPT-3 的改进:
- 使用 预归一化(Pre-LN),即在自注意力和前馈网络之前应用 LayerNorm。
- 优势:缓解深层网络训练中的梯度消失问题,提升训练稳定性。
3. 参数初始化和残差连接优化
- 修改的初始化方法:
- 对权重矩阵的初始化策略进行调整(如缩小初始化的方差范围),与 GPT-2 一致。
- 目的:适配深度模型结构,防止梯度爆炸或消失。
- 残差缩放:
- 可能对残差连接的权重进行缩放(如乘以 (1/\sqrt{n}),n 为层数),进一步稳定深层训练。
4. 纯 Decoder 架构与模块简化
- 原始 Transformer Decoder:包含 编码器-解码器交叉注意力层(用于 Seq2Seq 任务)。
- GPT-3 的改进:
- 移除交叉注意力:作为纯语言模型,GPT-3 仅保留自注意力机制,专注于自回归生成。
- 堆叠单一模块:每个层仅包含自注意力和前馈网络,结构更简洁。
5. 可逆分词(Reversible Tokenization)
- 沿用 GPT-2 的 Byte-level BPE(字节对编码)分词器,支持对任意字符序列的无损编码。
- 优势:避免未登录词(OOV)问题,提升对罕见词和特殊符号的处理能力。
总结:核心改进目标
GPT-3 的架构改进旨在:
1. 提升计算效率:通过稀疏注意力降低长序列处理的计算成本。
2. 增强训练稳定性:通过预归一化和初始化策略支持超大规模模型(1750 亿参数)。
3. 优化语言建模能力:简化结构以适应纯生成任务,结合稀疏注意力捕捉多层次依赖。
这些改进使 GPT-3 在保持与 GPT-2 相似架构的同时,能够扩展到前所未有的参数量级,并在少样本学习(Few-Shot Learning)中展现强大性能。
个人感觉比较关键的就是:
* sparse transformer,减少计算量
* 残差链接优化
最后简单总结一下:
* language model pre-train的好处是,可以利用未标注的数据做训练。并且生成式模型更加符合任务的需求
* GPT1最早和BERT竞争,用的是language model pre-train + finetune
* 在文章中也提到了,BERT能够看到上下文,在某些任务上天然就有优势。带来的缺点就是BERT的通用性并不强
* GPT2去除了finetune,通过zero-shot learning,验证语言模型的通用性
* GPT3则进一步大力出奇迹,训练175B的模型,加上few-shot learning,在保证通用性的同时,拿到了更好的效果。

文章评论