最近偶然才读到了这篇paper,不得不说sql server还是太先进了,当时的设计影响了后面系统的决策。给出了一份比较好的,从传统数据库集成AP能力的答卷。
这篇文章是sql server在2014版本引入列存的能力后,在2016版本继续强化列存能力的方法,核心有4大块:
* 支持在in-memory table上增加列式的二级索引
* 列式二级索引支持更新
* 在主索引是列式索引的时候,支持增加btree索引作为二级索引
* 列式扫描的性能优化
上面这几点支持的能力虽然看上去没有什么太值得关注的,但实际上sql server在paper中给出了这些技术的需求点,以及设计时候的考量,非常值得学习。
首先介绍下sql server的背景:
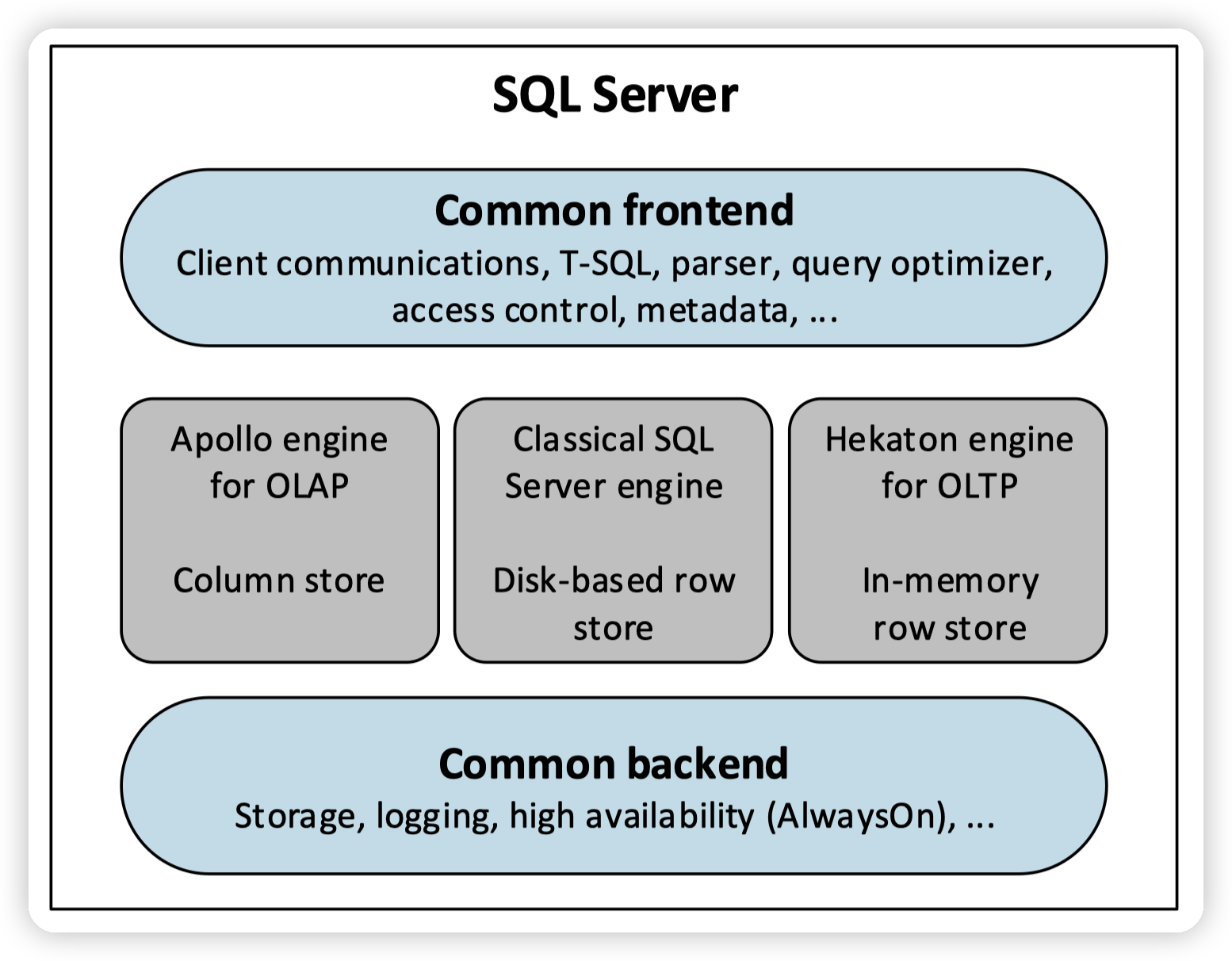
sql server下有三个引擎,这里的引擎包含了执行,以及存储
* classical sql server engine,行存储,磁盘存储
* apollo engine,列式存储,专门针对分析类查询
* hekaton engine,in memory OLTP引擎
sql server在2014年引入了columnstore index(CSI),可以作为primary index或者secondary index使用:
* row group划分,进一步拆分成column segment(这里就是感觉和duckdb很像,不过也可能是因为我没看过其他人是怎么做的,可能大家都是这样了)
* column segment通过LOB的形式存储在sql server中(暗示了是immutable的)
* primary CSI支持更新,通过delete bitmap + delta store
* delta store就是一个btree,key为RID。周期性的把delta store close掉,并转化成列式的格式存储到columnar storage中
* delete bitmap在内存中是bitmap,盘上是btree。(可能主要考虑的是复用盘上的结构,或者是觉得delete的数据少,用btree存属于稀疏存储,可能更优。)
* 执行引擎支持batch模式的处理,用row batch传递数据,内部是select vector表示
- 还有一些hekaton相关的就不介绍了,感兴趣可以再看hekaton的paper。知道他是个基于多版本的纯内存引擎就行。
CSI ON IN-MEMORY TABLES
这一节讲怎么在hekaton上支持CSI二级索引:
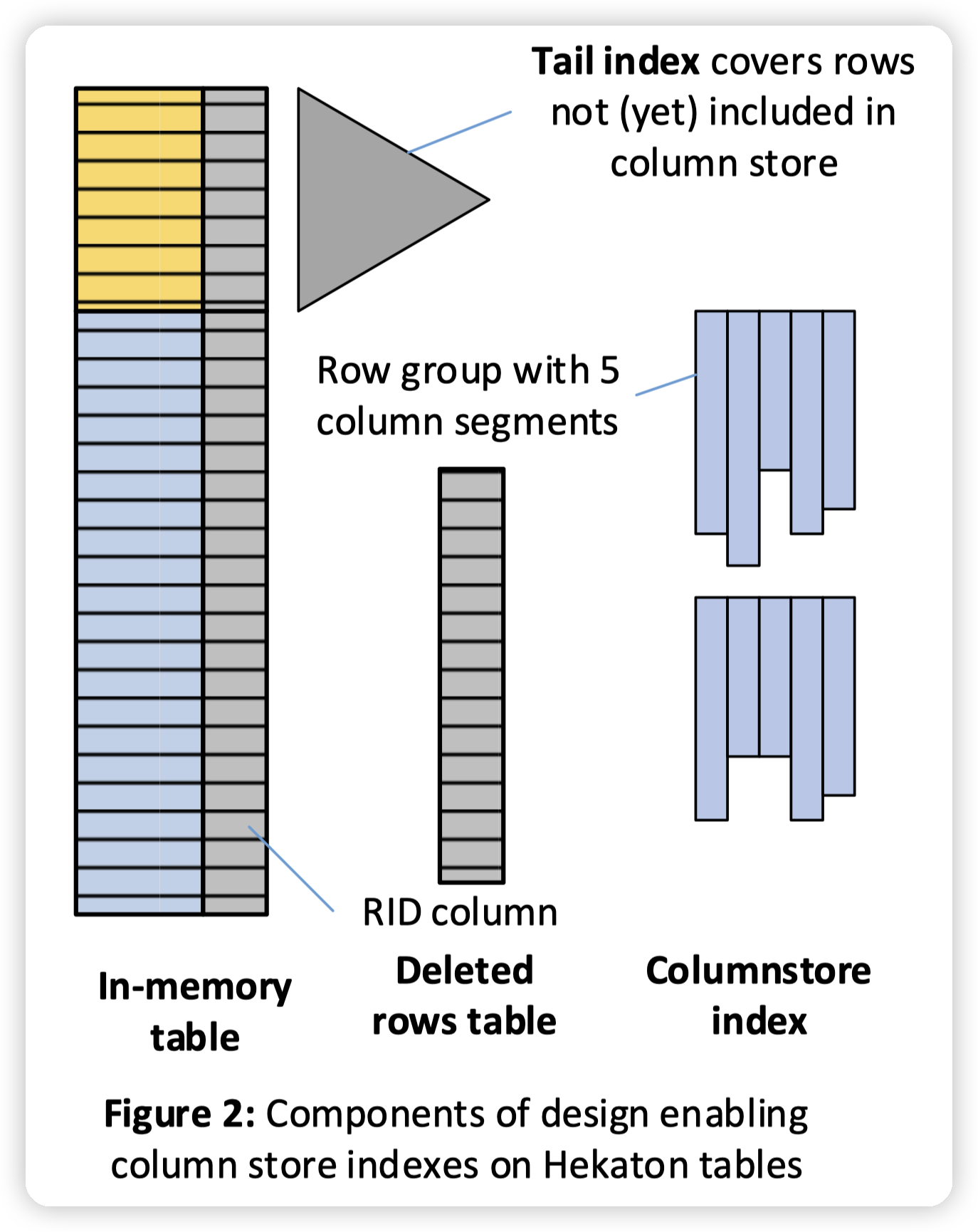
这里内存中的数据会复制一份,行存有一份,列存有一份。不过sql server说一般空间开销比较少,只有10%~20%,因为有压缩。(压缩比例这么高吗?)
新写入的数据,但是还没有被转储到列存中的数据会被记录在tail index中。做分析类查询的时候,会merge CSI中的数据,以及tail index中的数据。
* 这里的tail index就是避免hekaton本身的TP性能被影响,所以做了异步的转储。也是牺牲了scan的性能,保证核心场景的优势。
然后图中还有一个deleted rows table。用来存储被删除掉的数据的RID,在扫描的时候,也会和这里的删除表做一次merge,把删除的数据过滤掉。
* 这里一个比较奇怪的点是,hekaton都是全内存的数据了,RID中也记录了对应的row group id,为什么不直接去row group中把数据删除掉,而是插入到一个delete table中做merge。
* 这里没有细想,可能主要是为了支持快照语意了
data migration,也就是从行存转移到列存的过程,没有特别多的insight,就不多赘述了。基本上就是扫一下tail index中的数据,把他们放到CSI中。
* 这里一个点是说,如果一行数据更新的频率很高,sql server不会把它放到列存中,因为他会污染CSI中的数据(更新会带来更多的tombstone,影响扫描性能)
* 但是感觉追踪这个更新频率也挺麻烦的。好一点可以搞一个page级别的,发现page更新频率低了,就把它转储到CSI上。
* 转储的时候还有另一个点,是SQL server考虑用户易用性的。这里是说,sql server在转储的时候,会涉及到通过hekaton的事务来更新一行数据(比如分配RID),如果此时用户有写入,会发生写写冲突。所以需要避免系统内部的机制影响用户的事务:
* 这里的做法是在发生写写冲突的时候,优先abort这些后台的内部事务
* 如果内部事务已经提交了,这里会做特殊的处理逻辑,把用户的更新的数据变成转储后的数据。(这里一听就比较麻烦,不过也能感受到,作为一个商业数据库做的细致的地方)
UPDATING SECONDARY COLUMN STORES
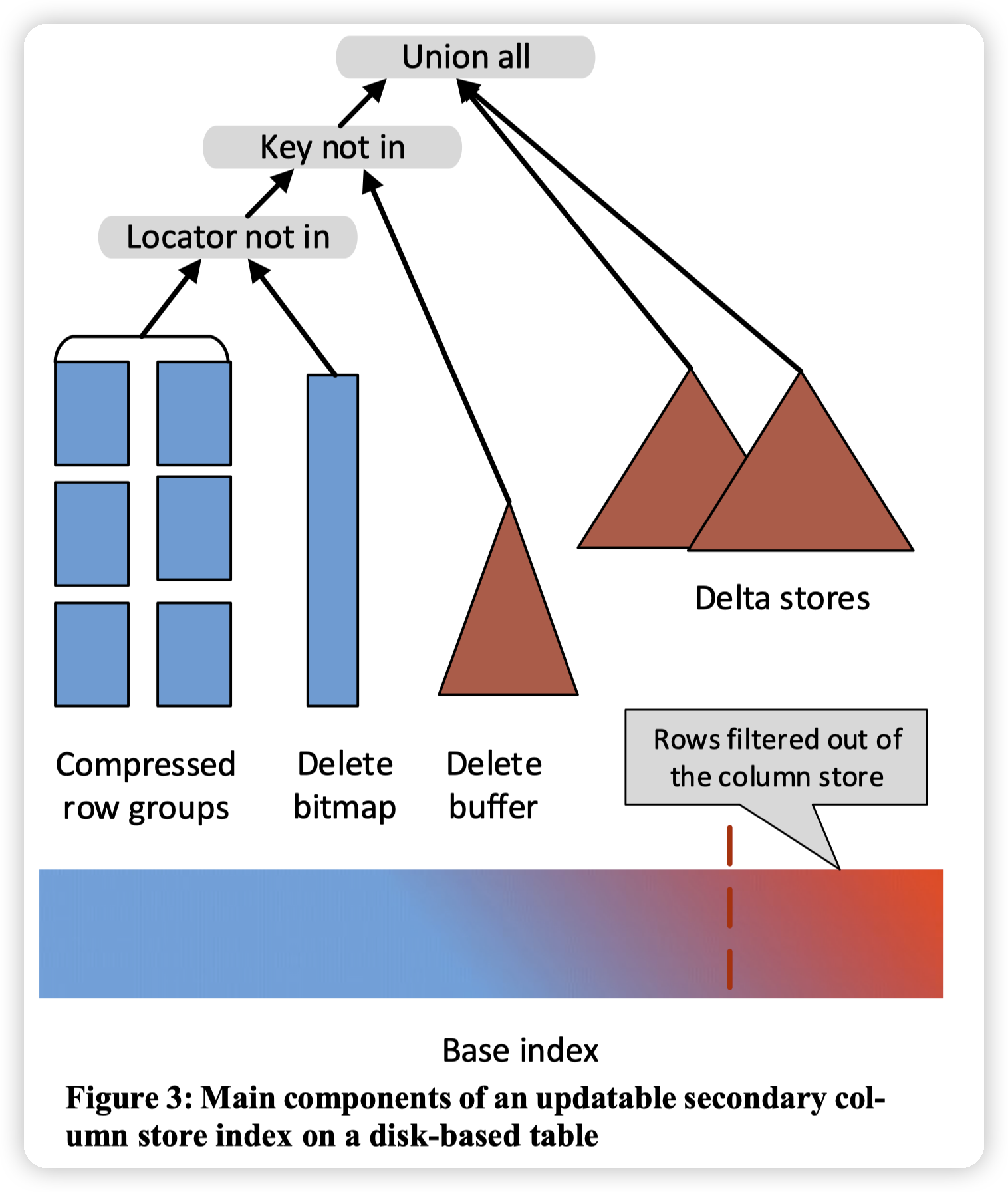
这一节的主要点是在说,sql server 2014中,如果给一个表加了CSI的二级索引,那么会导致这个表无法更新。
secondary CSI和primary CSI有基本一样的结构。但是在设计点的偏向上有所不同:
* secondary CSI面向的场景是给OLTP加速分析能力,但是不能影响OLTP本身的性能。
* primary CSI面向数仓类场景,一般都是插入,并且对更新需求不高。但是对扫描的性能要求高。
这就带来了scan/update的trade off。primary CSI会优先选择scan,而secondary CSI则是优先选择update了。
- 在具体的实现中,sql server说他们在删除一行数据的时候,(应该是因为row group是压缩的),所以定位到具体的一行数据需要把整个row group都扫描一遍,这样会导致删除变得非常的慢。
- 所以在图中,他们引入了一个delete buffer,用来处理“热”的删除。即删除操作会先进入到delete buffer中,此时只是一个插入操作。
- 然后在scan的时候,会做delete buffer和row group的merge。牺牲scan的性能(需要merge)来提高delete的速度。
B-TREES ON PRIMARY COLUMN STORES
这里还是针对sql server 2014的缺陷,使用primary CSI的时候,无法定义主键,以及unique constraints,因为他们不能增加二级索引。
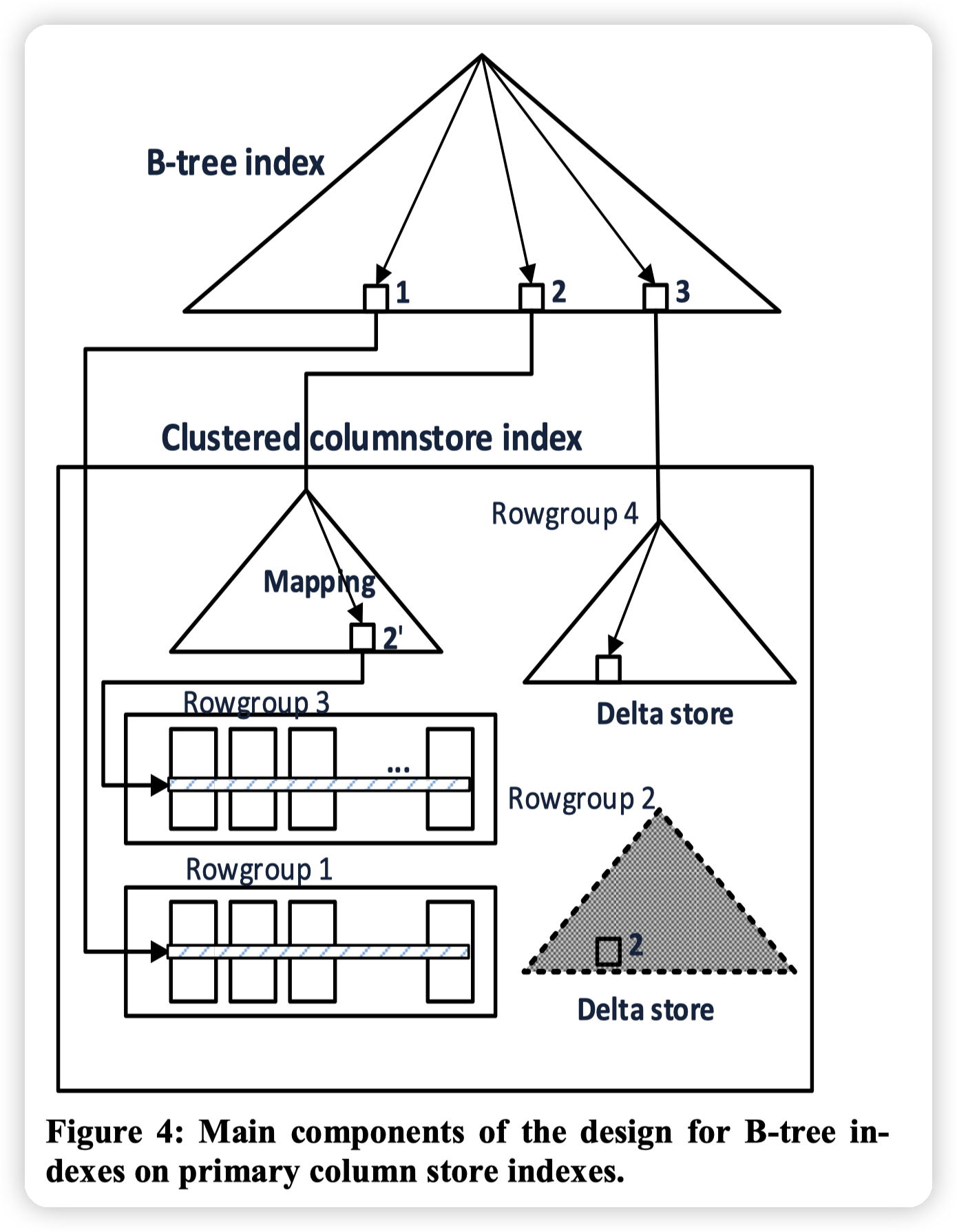
* 这里的主要挑战是,如果增加了二级索引,那么二级索引上的value应该是这个数据的RID。因为row group需要做compaction,做数据搬移。此时RID会发生改变,如果也去修改二级索引,会导致产生大量的日志,并且数据量是和二级索引是成正比的。
sql server解决这个问题的方式是引入了间接层:
* 增加了一个mapping index。在搬移row group的时候,记录新老row group的映射。那么在查找的时候,就可以通过mapping index去找到正确的row group。
* 这种方式只会稍微影响二级索引的查找,对主链路的scan是没有开销的。
LSM kv分离的设计中,也有一样的思路。这种设计可以应用在key -> RID的索引上,一般索引上记录的是数据的位置,而非数据本身,那么在数据搬移的时候,为了避免对索引产生影响,可以用这种mapping的方式。
* 这种mapping的方式有一个隐含的缺点是mapping自身的gc,可能需要考虑周期性的全量重建,否则mapping index的数量会无限的递增
其实这里还有一种解决的方式,因为主要问题是更新二级索引会产生大量的日志,如果二级索引支持批量更新(类似CSI一样),那么可以走批量更新的接口,减少日志的数量。
* 比如常见的LSM中,就可以走直接写SST的方式,避免写WAL。
CSI SCAN IMPROVEMENTS
这一块就是讲读取的加速了:
* 支持在压缩后的数据直接apply filter
* 使用SIMD加速处理
* avoid branch misprediction
* 这个没有细说,主要是工程细节
其实上面几个点我感觉都是工程细节,没有什么特别的思路要看。研究的话应该看看现在开源的ap数据库,比如duckdb啥的就行。
技术上在当时看应该还挺新颖的,不过现在看都是比较常见的技术,比如在字典压缩的数据上做filter,做比较什么的。
个人感觉这篇文章的主要点还是在于:
* 讲述了在不同的应用场景上,为什么需要CSI,以及CSI的更新。
* 给出不同场景上,如何让CSI支持更新
还有一个点可以再提一下,就是secondary CSI和hekaton支持CSI都是加上一个可以更新的CSI,但是他们的实现方式是不同的。
* hekaton的CSI是利用tail index,用的是单一的delta。数据的完整性和可见性靠的是hekaton的事务机制。
* 而secondary CSI则是可以有多个delta,数据的完整性保证是类似lsm tree,应该读取的时候可以拿一个version出来。
* 个人感觉hekaton之所以没有用多delta的形式,是因为多delta拿version读取这一套可能有中心化的竞争,对hekaton的性能有损。而选择了单一一个二级索引,然后靠额外的机制(RID的可见性,以及hekaton本身的事务能力)去保证数据的完整性。也是一个性能上的tradeoff了

文章评论