Innodb Undo
在前文中已经介绍了Innodb中的Undo Log的作用,主要有三个点,分别是保存旧版本,回滚事务,以及作为持久化的活跃事务状态表。这篇文章中来细节介绍一下Innodb中的Undo Log,对于Undo Log来说,需要关注的有:Undo Log是如何组织的,Undo Log的类型,Undo Log何时做GC,Innodb如何通过Undo做事务回滚,保证事务原子性,在Crash Recovery的时候,Undo起到了什么作用。
Undo Log 组织
先回忆一下,Innodb中的一个表空间下有若干的Segment,Segment中包含了由Extent为分配单位的连续的Page。
对于Innodb来说,Undo Log Record被记录在Undo Page中,为了避免事务过大,当一个Undo Page不足以存储一个事务的Undo Log Record的时候,Innodb就会再去申请新的Undo Page,并通过链表的方式与之前的Undo Page链接在一起。
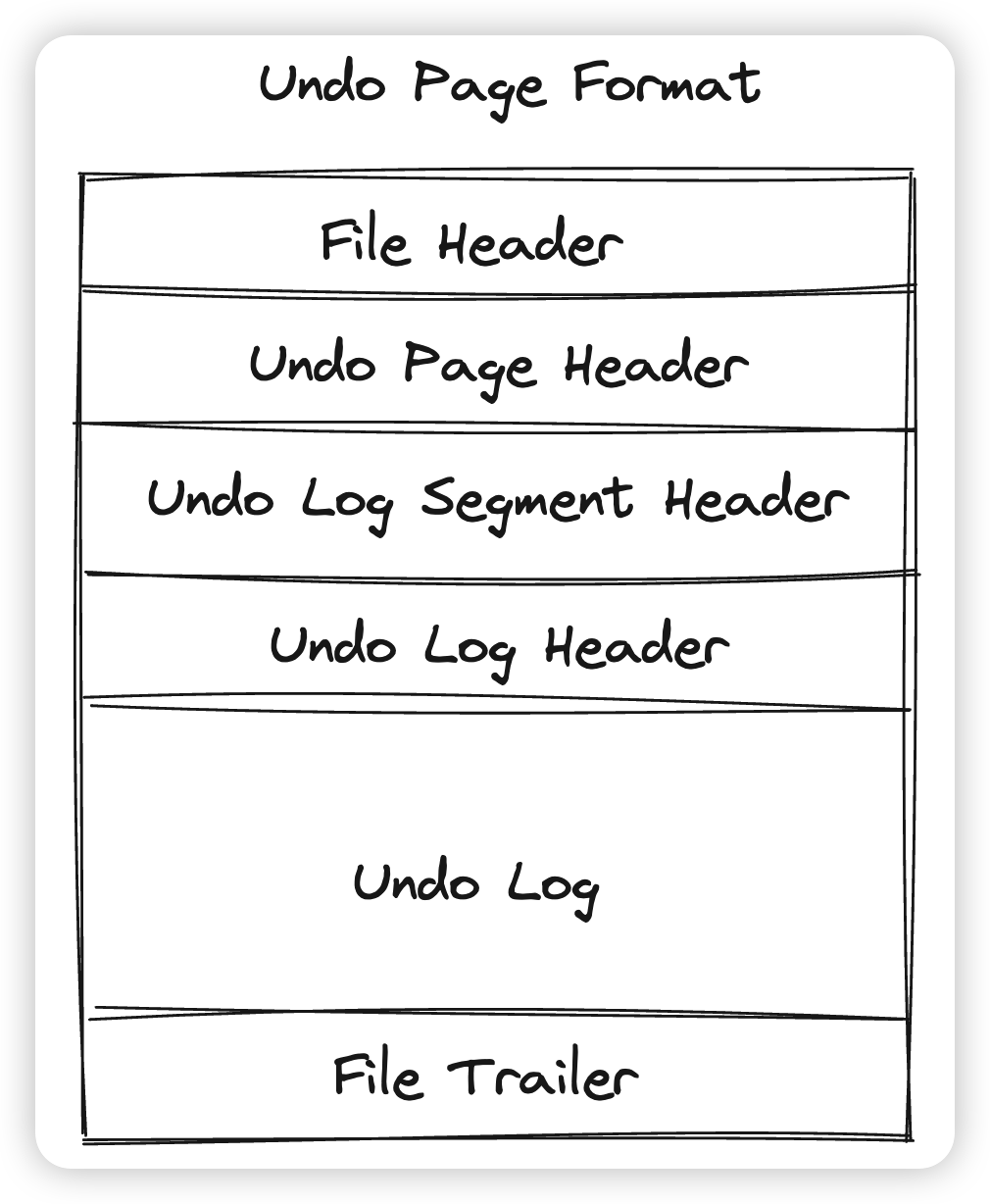
分别介绍一下这几块的作用:
- File Header中包含了SpaceID,Page offset,LSN,Type,Checksum等通用字段
- File Trailer中包含Checksum和LSN,用来做原子写入的校验,和File Header一样,是通用字段,不局限于Undo
- Undo Page Header用来记录当前的Undo Page存储什么类型的Undo Log,第一条和最后一条Undo Log Record的偏移量,以及双向链表的节点,用来将Undo Page组织成链表。
- Innodb中将每个由Undo Page组成的链表都划分为一个段(物理上尽可能连续,比如Btree的叶子结点就是在一个段中)。Undo Log Segment Header就是维护这个段信息的(从这个段中分配Page)。同时Undo Log Segment Header还纪录了当前这个Undo段的状态,比如Active/ToFree等
- Undo Log Header则是用来串联一个事务的Undo log,里面会保存TrxID,TrxNO等信息
可能一个最直观的问题是,为什么有了Undo Page组成的链表,内部还需要一个Undo Log Header来串联Undo Log呢?这是因为Innodb中为了减少对Undo Segment的申请,不会为每个事务都创建一个Segment,而是复用现有的Segment。那么为了区分不同的事务的Undo Log,就有Undo Log Header来管理他们。大概感觉如下图
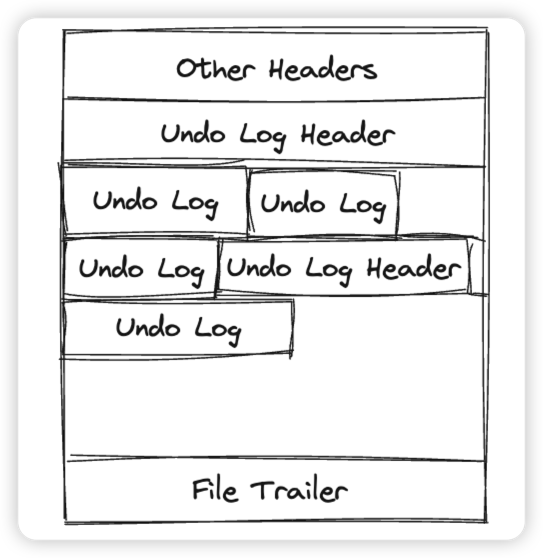
在Innodb中,一个活跃(Active)的Undo Page链表(后面统称Undo Segment)只能属于一个事务。一个Undo Segment中因为Undo Page的复用,可能保存有多个事务的Undo Log。因为系统中肯定会存在很多并发的事务,那么这些并发的事务也暗示了会同时存在多个活跃的Undo Segment,下面看一下Innodb中是如何组织这些活跃的Undo Segment的
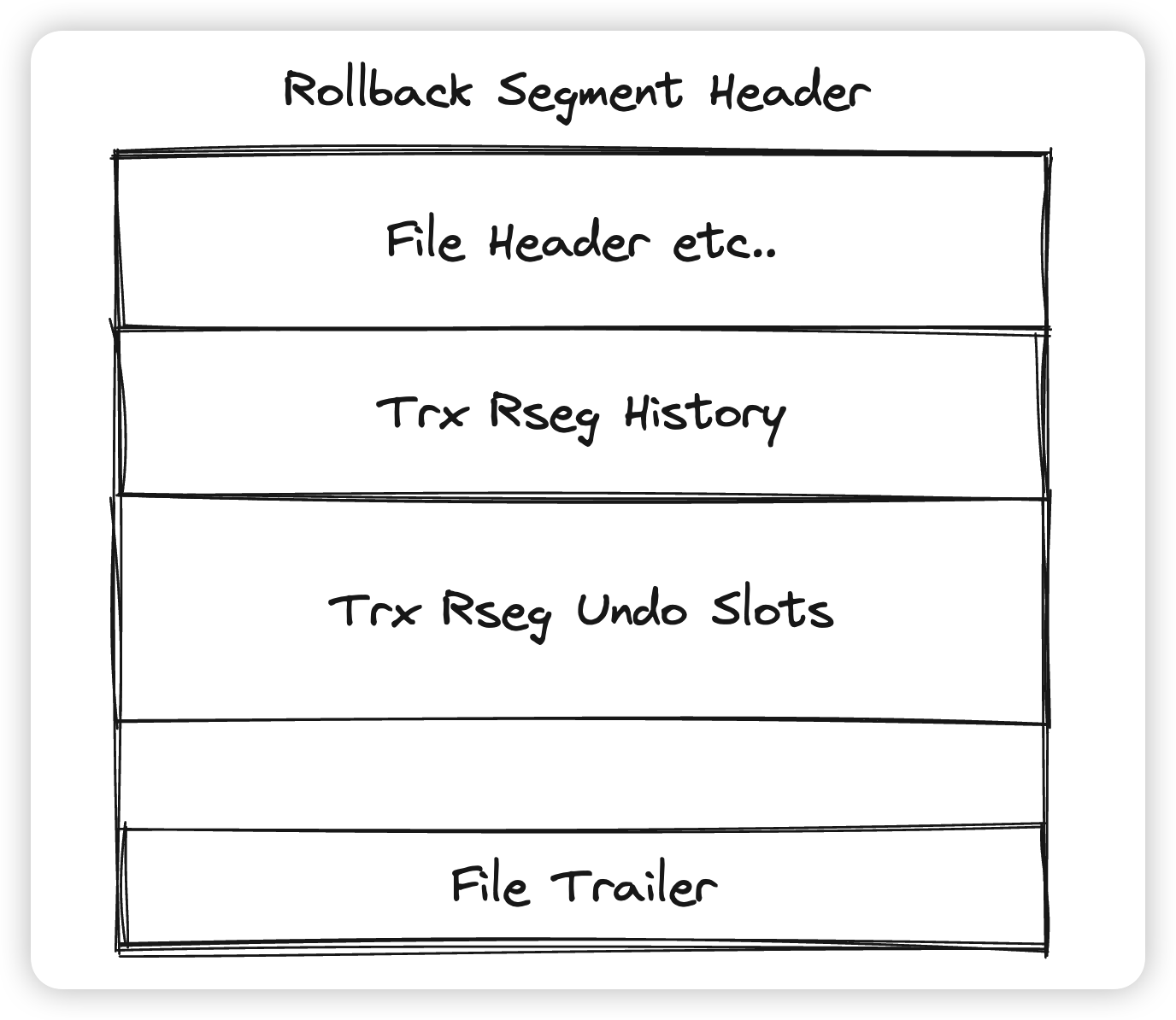
Innodb中有一种Page叫做Rollback Segment Header,简称为Rseg,其中需要关注的主要有两个位置,一个是Rseg History,用来做Purge/Truncate,后面会提到,另一个是Undo Slots,里面记录了每个Undo Segment的第一个Page的PageID,每个Undo Segment对应一个Undo Slot,一个Rseg Header中会记录1024个Undo Slots。即一个Rollback Segment Header可以维护1024个Undo Segment
一个系统中1024个并发的读写事务肯定是不够的,所以Innodb中会存在多个Rollback Segment Header,维护在系统表空间的5号Page中。这里会存有128个PageID,每个PageID都指向一个Rollback Segment Header,所以系统中一共可以存在128 * 1024个并发的事务(不是很严谨)。
整体的组织结构如下:
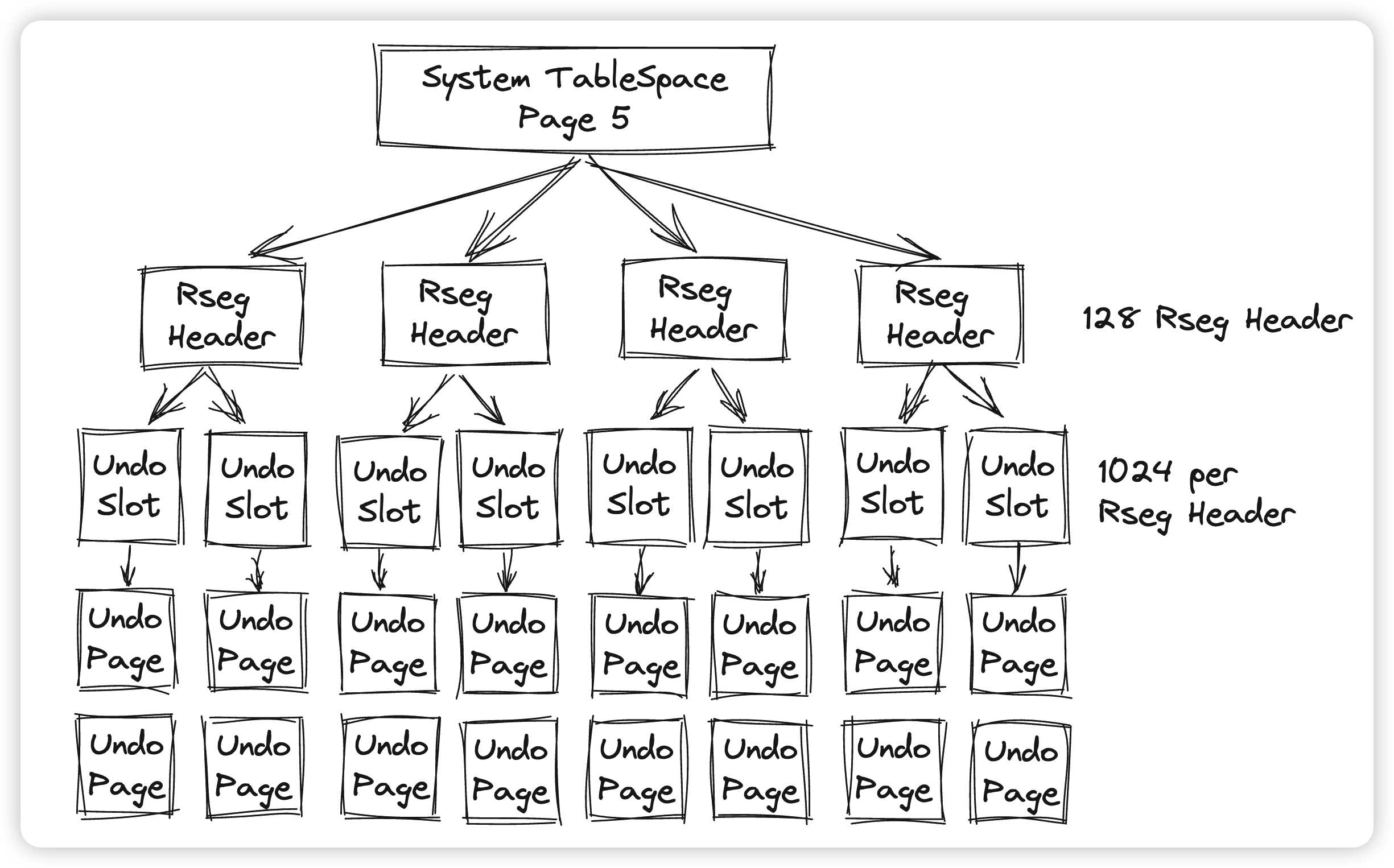
因为Innodb中会存在临时表空间,这些地方在系统崩溃后是不需要进行Undo的,所以Innodb也会区分不同表空间的Undo。具体来说,这128个Rseg中,0号一定在系统表空间中,1-32号属于临时表空间,而33-127号则可以自由分配,既可以在系统表空间,也可以在自己配置的表空间中。
Undo Log 格式
看完Undo Log在Innodb中是怎么组织之后,来看一下Undo Log的格式
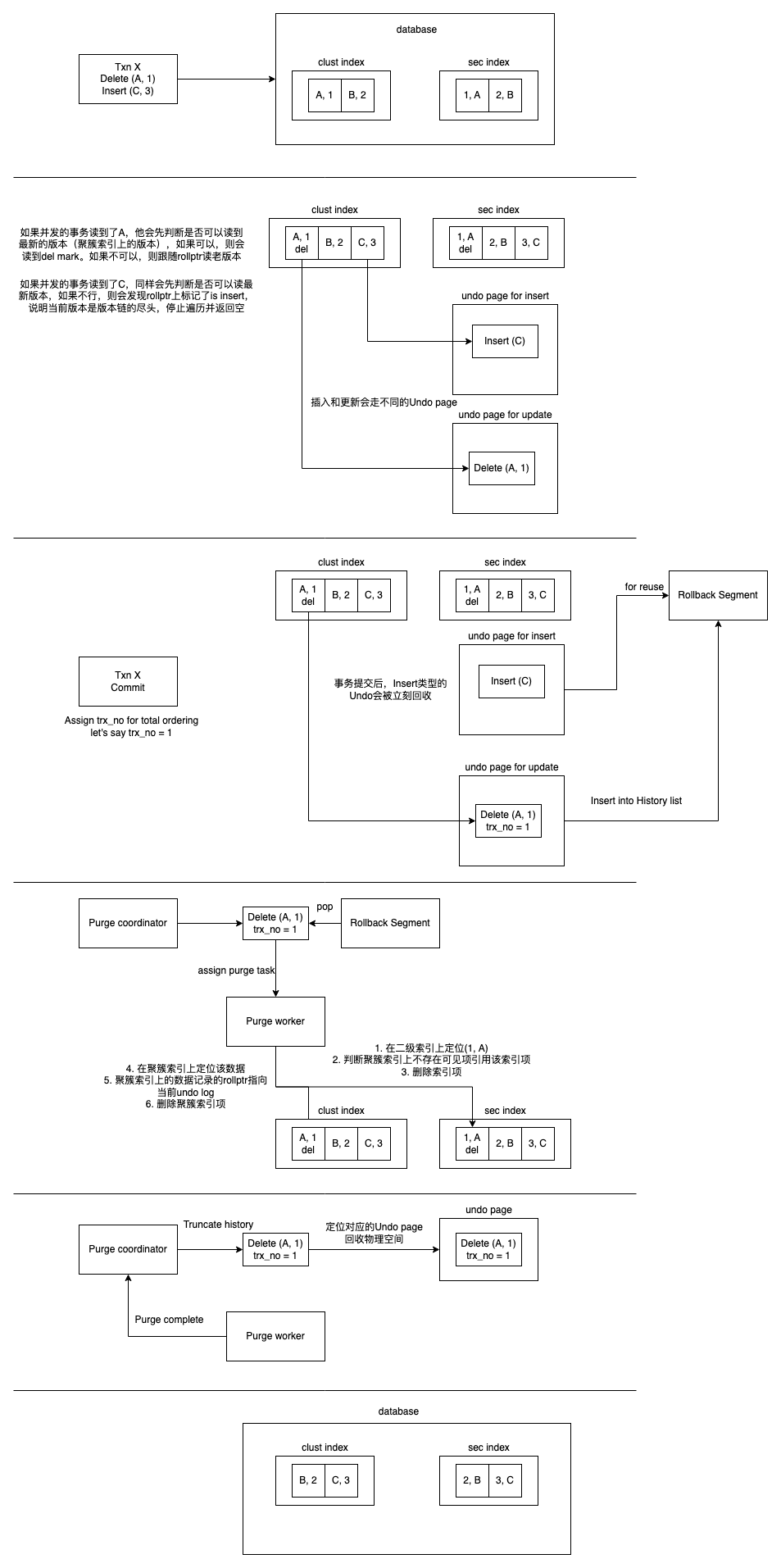
注意Undo Log的作用是回滚用户的操作,以及保存旧版本,所以每次Undo Log的产生一定对应了用户的某次操作。之前介绍过,用户的操作主要是Insert,Update,Delete,对应到Btree上就是Insert,Update,Delete mark。
Innodb的Undo是在写入聚簇索引(主表)之前写入的,写入的信息需要能够Undo主索引以及二级索引上的变更。
Undo Log的类型主要有4种:
- TRX_UNDO_INSERT_REC,对应插入一条数据。
- TRX_UNDO_UPD_EXIST_REC,更新一个没有被del mark标记的record,对应的是原地更新
- TRX_UNDO_UPD_DEL_REC,更新一个被del mark标记的record,比如insert_by_modify的时候会用
- TRX_UNDO_DEL_MARK_REC,给一个record标记del mark,对应的是删除一个record
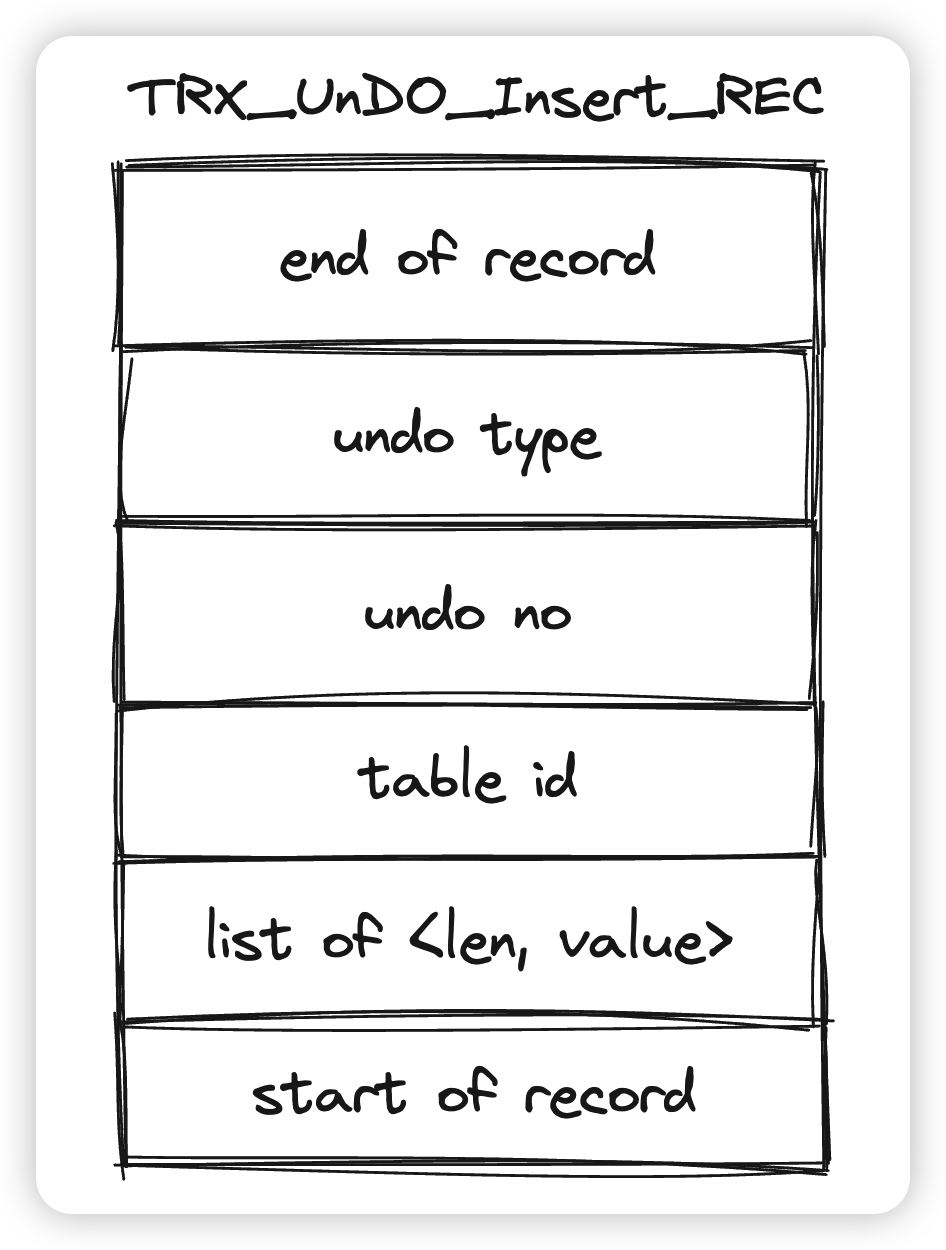
先看TRX_UNDO_INSERT_REC类型:
- start of record和end of record的作用和双向链表相同,可以通过这两个字段快速定位到下一条undo log或者上一条undo log。start of record记录的时候本条undo log开始的地址,end of record记录的是本条undo log结束,也就是下一条undo log开始的地址
- undo type为TRX_UNDO_INSERT_REC
- undo no表示的是这是当前事务第几条undo log,从0开始
- table id是对应的表。因为undo log是表级别的,我们需要能够找到对应的表去undo
- list of <len, value>则是本次插入数据的主键,通过长度+值的格式来存储。
- 你可能想问,为什么一次插入操作的Undo不把所有的数据都记录下来呢?在Undo作为旧版本的时候,Insert的旧版本就是空,所以实际上不需要任何数据。
- 那下一个问题是,既然不需要任何数据,为什么还要记录主键呢。这是因为Undo的作用还有回滚操作,Innodb需要能够通过Undo中记录的信息从表中回滚操作,对于Insert来说回滚操作就是把插入的数据删除掉,删除掉这个数据只需要通过主键定位到他即可,不需要其他的列。
- 那么你可能又会问,二级索引还有二级索引项呢,为什么不需要记录索引项的数据?这个和Innodb的写入以及Undo的顺序有关,等下在写入流程中会提到。
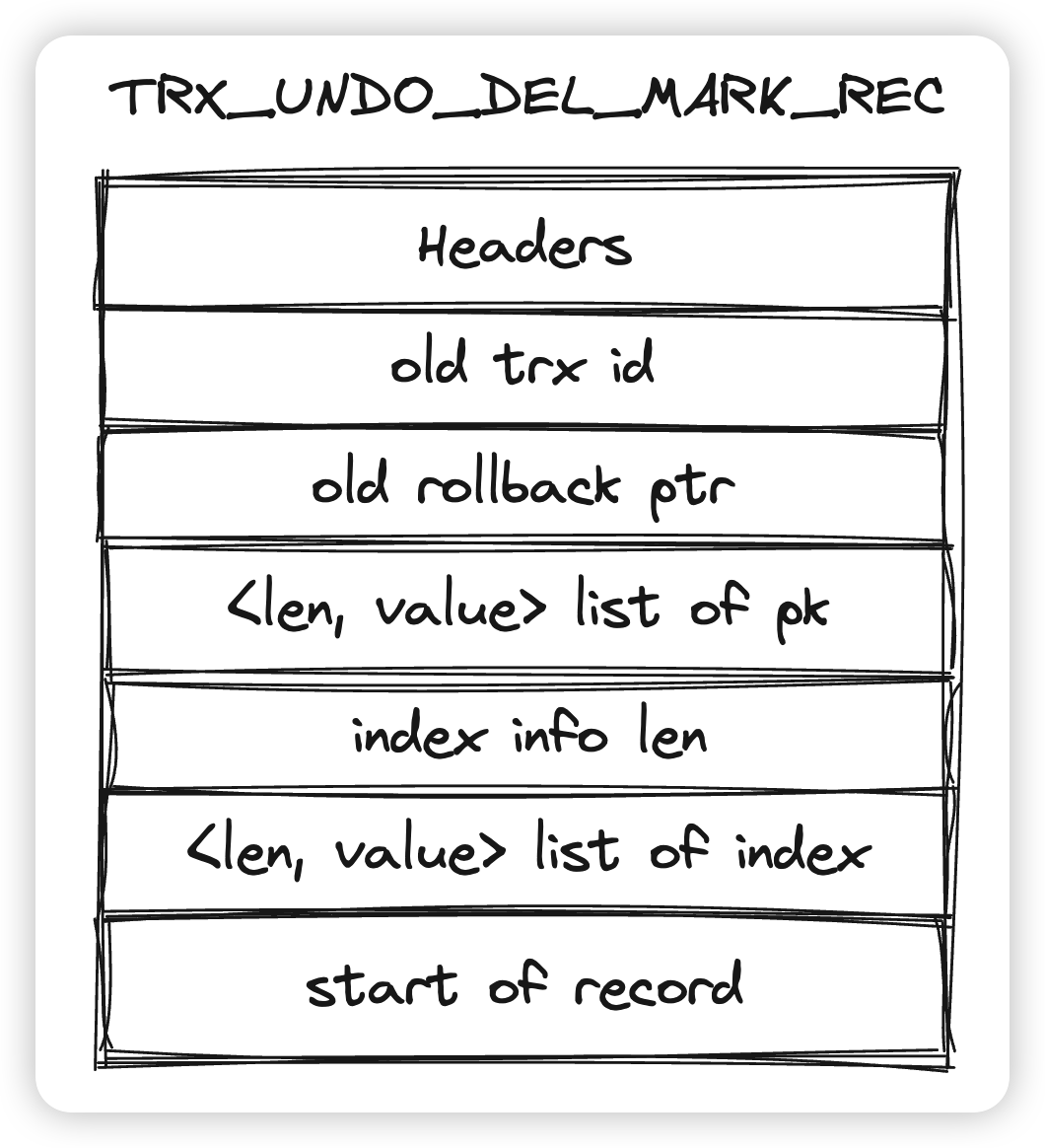
然后是TRX_UNDO_DEL_MARK_REC,删除一个record对应的Undo:
- Headers上面已经讲过,包含end of record, undo type, undo no, table id
- old trx id/old rollback ptr会记录前一个版本的txn id,以及rollback ptr,用来回溯到老版本
- <len, value> list of pk就是本次删除数据的主键
- index info len和<len, value> list of index共同记录了索引列相关的信息,这里是旧值的索引列
- 这里可能你又有一个疑问,del mark应该只是标记一个record的上flag,不需要修改任何column,为什么还需要记录索引列到undo中呢?因为我们完全可以通过聚簇索引上的数据得到所有的索引列。
- 对于undo来说,是这样。因为不会有并发的事务修改相同的主键,那么我们完全可以通过主键定位到数据,然后去undo二级索引。
- 但是undo在作为旧版本的时候,还需要做真删,即不能简单的del mark了一个record就完事了,还需要在合适的时候将这个数据真正的删除掉,从而释放空间。但是由于有insert by modify这种操作,一个del mark的数据仍然可能被修改,这样之前删除他的事务就无法通过这个tombstone定位到索引列的信息了,那么undo就必须记录索引列的信息,才能对二级索引的数据做到“真删”
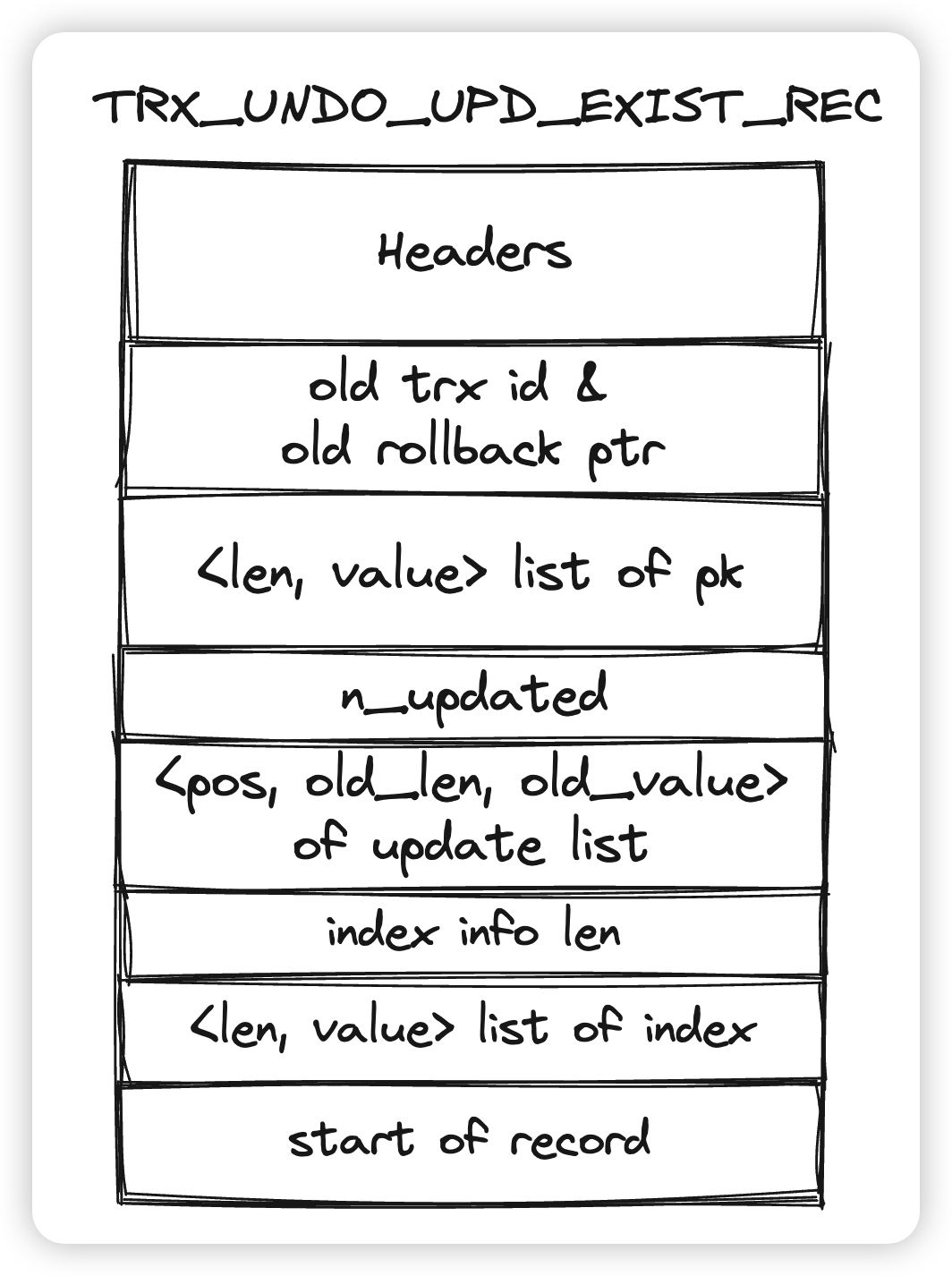
最后是TRX_UNDO_UPD_EXIST_REC,对应了原地更新的undo:
- Headers,old trx id & old rollback ptr还是一样的
- pk和上面也一样,因为总是要定位是那一行被修改了
- n_updated和update list组成了update vector,记录了本次修改的那些数据在更新前的值。我们可以通过这两项构建出来一个“逆向”的update vector,从而将数据从新版本更新称老版本
- index info len和index list和上面也一样,如果本次修改变更了索引项,就会记录在这里,用来在合适的时机对索引列做真删。
- TRX_UNDO_UPD_EXIST_REC和TRX_UNDO_UPD_DEL_REC的格式是一样的,都是通过update vector记录老版本。只不过UPD_DEL_REC不会记录索引项(因为不需要做真删),并且对UPD_DEL_REC类型的操作做undo不是做update,而是delete。
- 在这里敏锐一点的同学可能会发现,因为TRX_UNDO_UPD_DEL_REC实际上就是Insert操作,那为什么Insert undo只记录了pk,而这里的Update del rec却额外记录了update vector呢。这里记录的数据实际上是del mark的前一个版本的数据。具体的逻辑我们会在写入的时候看到
Undo 写入
- 在真正开始介绍Undo log究竟是怎么用之前,这里还有一个点需要提一下。Innodb中的每个事务,可能会分配4个Undo log segment,分别是需要redo的insert undo和update undo,以及不需要redo的insert undo和update undo。
- 其中,区分是否需要redo(即持久化)的undo在上面已经提过,临时表不需要崩溃恢复,使用的也是特殊的rollback segment,所以会把对临时表的操作和对普通表的操作区分开来,放到两个Undo log segment中
- 区分Insert undo和Update undo算是一个进一步的优化。对于Insert操作来说,他的Undo在事务提交后就没有用了,因为Insert是不需要旧版本的,回忆一下,上面提到的Insert Undo所记录的信息中,都是用来做Rollback的。而对于Update来说,就算这个事务提交了,因为他本次修改对应的旧版本信息仍然记录在Undo中,所以不能简单的将旧版本回收,而是需要等到没有其他事务可以看到这个旧版本后,才能回收这段Undo log。两种操作的Undo回收时机不同,也就导致了后续处理逻辑不同,所以Innodb区分开了Insert Undo和Update Undo
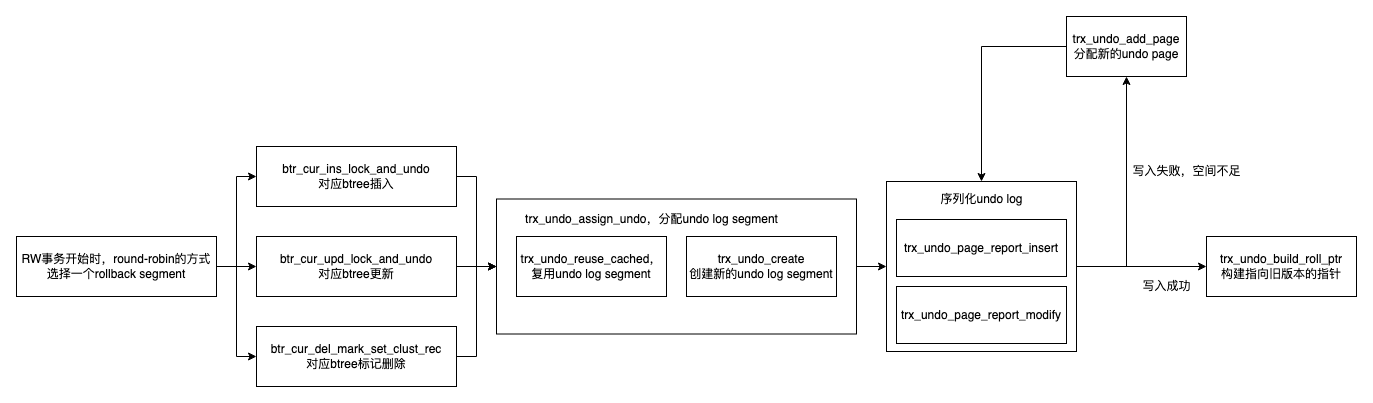
- 在RW事务开始的时候,会给这个事务分配对应的rollback segment。分配方式就是在这个表空间的128个rseg中以round-robin的方式挑选一个
trx_start_if_not_started_low
trx_start_low
trx_assign_rseg_durable
get_next_redo_rseg
- 写入Btree的时候,Innodb会先打开一个MTR写入undo,再打开一个MTR写redo以及修改内存中的Page。这里写入undo都是走的
trx_undo_report_row_operation。在这里会传入undo log需要的相关信息,如本次写入的数据/update vector,undo类型等。在写入成功后,他会返回一个roll_ptr,用来回填到数据中。
btr_cur_ins_lock_and_undo
trx_undo_report_row_operation
btr_cur_upd_lock_and_undo
trx_undo_report_row_operation
btr_cur_del_mark_set_clust_rec
trx_undo_report_row_operation
- 先看
trx_undo_report_row_operation中Undo page的分配流程。Innodb中的Undo是懒分配的,所以是在写入的时候检查有没有给这个事务分配对应的undo log segment,如果没有,则会尝试先分配一个undo log segment。- 上面提到过,为了减少对元数据的修改,Innodb会将之前使用完的undo log segment缓存下来。后面在分配的时候,会直接从缓存中拿Undo log segment,并初始化自己的Undo log header。
- 如果复用失败了,则fallback到分配Undo log segment的链路,这里就会从表空间中分配新的Page了
- Undo log segment分配好了之后,如果某个事务写入的数据过多,导致一个Undo page放不下,这里就需要多个Undo page了,走的就是
trx_undo_add_page,在当前Undo log segment对应的segment中分配一个新的Page,并将其加入到链表尾部
trx_undo_report_row_operation
trx_undo_assign_undo
trx_undo_reuse_cached
trx_undo_insert_header_reuse // for insert
trx_undo_header_create // for update
trx_undo_mem_init_for_reuse
trx_undo_create
trx_undo_seg_create
trx_undo_header_create
trx_undo_mem_create
trx_undo_add_page
fseg_alloc_free_page_general
trx_undo_page_init
- 在分配好Undo page之后,我们就可以将本次要写入的undo log record追加到undo page后面了。这里没有什么特殊的逻辑,就是按照上面提到的格式进行序列化
trx_undo_page_report_insert
trx_undo_page_report_modify
- undo log record写入成功后,最后一步就是构建rollback ptr,他的作用就是在构建旧版本的时候,直接定位到具体的undo log record。注意到Innodb用了1位表示本次操作是否是Insert,这是因为Insert类型的Undo在事务提交后已经失效了,不能直接找对应的Undo,而是在发现本次操作是Insert的时候,告诉用户版本链的遍历已经到头了。
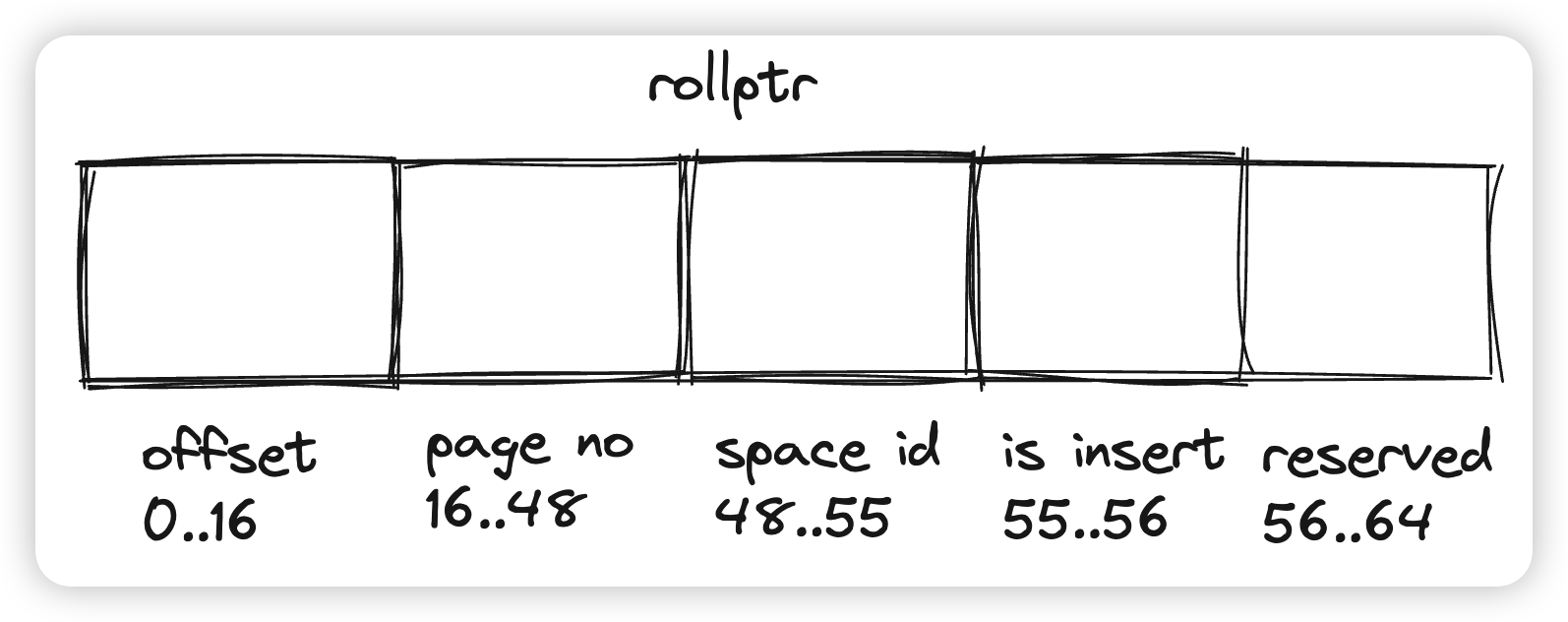
trx_undo_build_roll_ptr
row_upd_index_entry_sys_field
这样一个事务中,一次写入与Undo相关的操作就介绍完了,放一张流程图
Undo 多版本
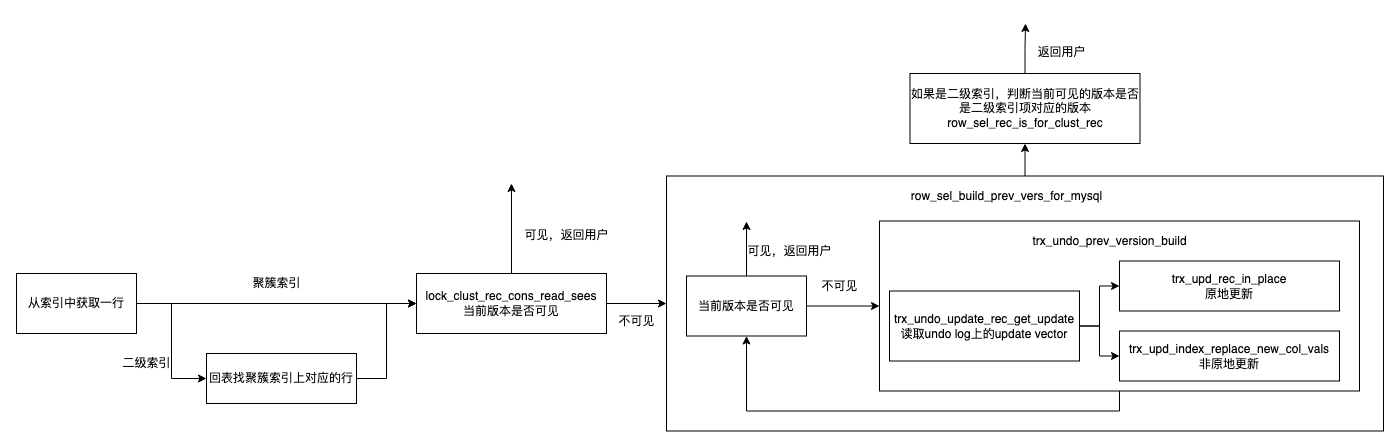
下面来看看读链路是怎么利用Undo来构建旧版本的。读链路在之前的文章中有过大概的介绍,这里涉及到旧版本的主要是Consistent read,可以理解为read snapshot。在使用RC/RR隔离级别的时候,一些只读的事务就可以使用MVCC来读取,避免上锁阻塞其他的事务。
之前也提到,Innodb中的单线程读取的代码主要在row_search_mvcc中,这里涉及到读取旧版本的地方有两个:
* 当前读的是主索引,如果最新的版本不可见,那么需要追溯版本链找到当前事务可见的版本
* 当前读的是二级索引,那么在回表的时候也需要读主索引,并返回这个二级索引项所对应的旧版本
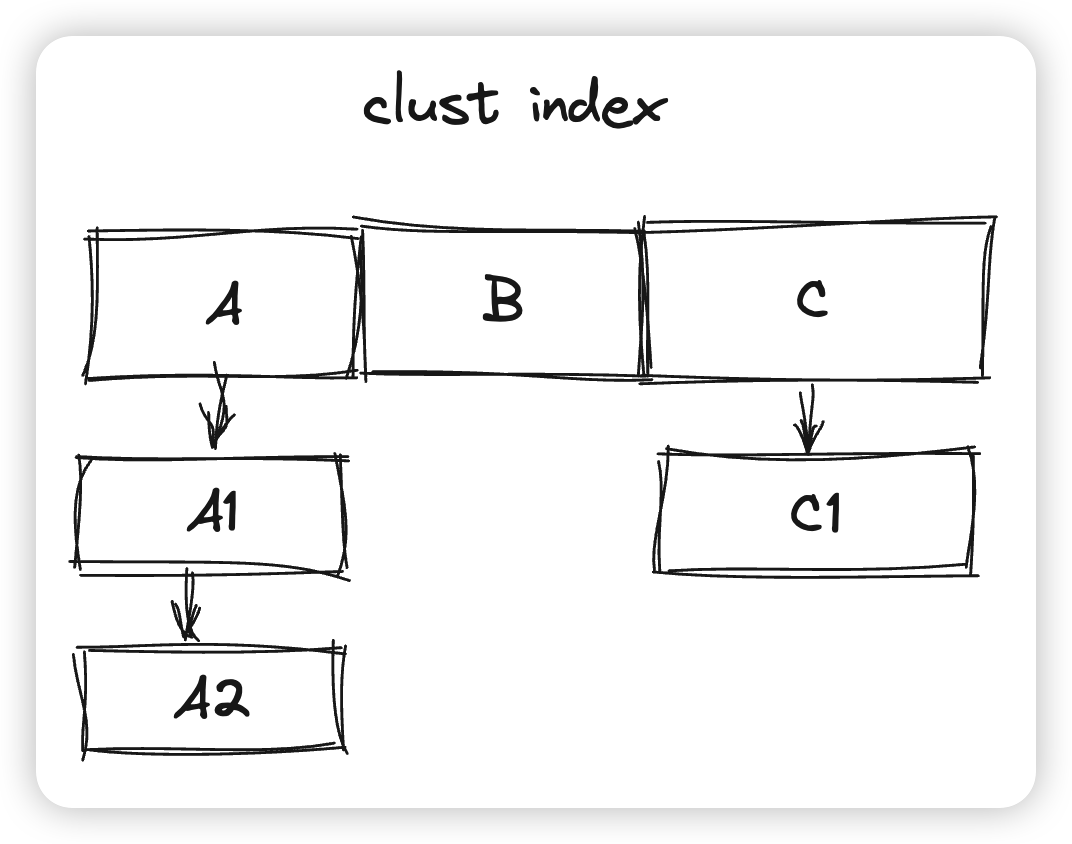
* 第一种情况对应上面这个例子,要顺序遍历A/B/C三行,这里会先把cursor放到A上,然后判断这个最新版本对当前事务是否可见,如果不可见,则回溯到A1判断,直到版本链结束或者找到一个可见版本为止。这时候就会返回这个对应的版本给MySQL Server,然后将cursor移动到B上
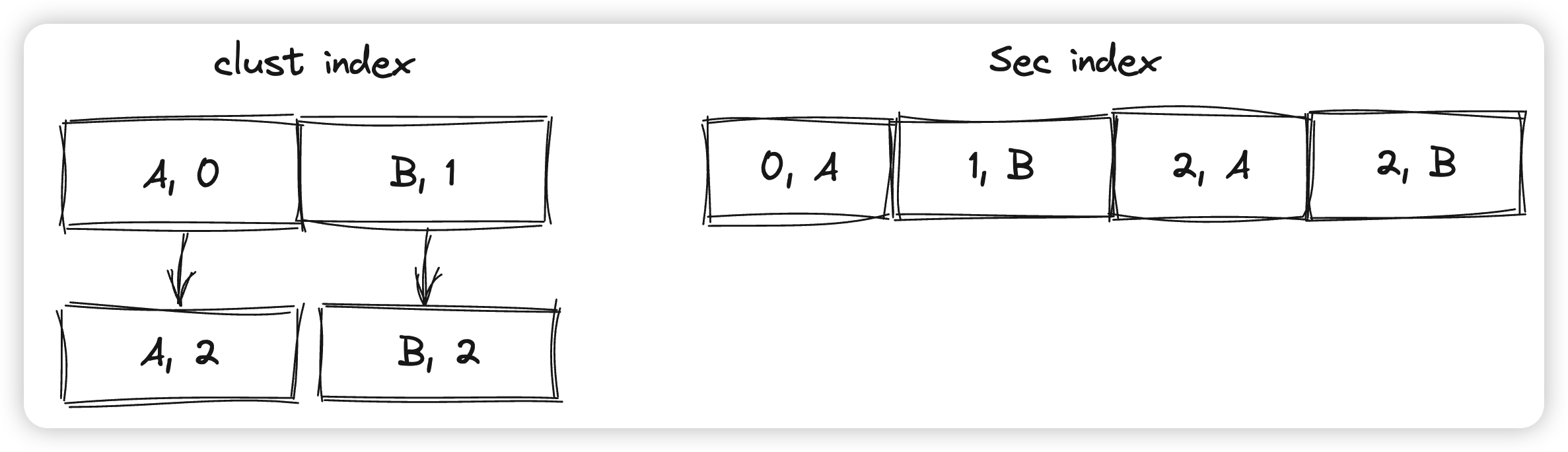
* 第二种情况则对应需要回表的时候,比如这里要顺序遍历二级索引,先走到(0, A)这行上,然后回表到主索引(A, 0),如果发现不可见,则回溯到老版本(A, 2)上。需要注意的是如果这时候发现(A, 2)是可见的,还需要再去判断(A, 2)这一行是不是对应了刚才的索引项(0, A),如果不对应也不能返回,否则就会打破索引扫描的有序性
// clust index
lock_clust_rec_cons_read_sees // 检查可见性
row_sel_build_prev_vers_for_mysql // 构建旧版本
// sec index
lock_clust_rec_cons_read_sees // 检查可见性
row_sel_build_prev_vers_for_mysql // 构建旧版本
row_sel_sec_rec_is_for_clust_rec // 确定旧版本是产生对应索引项的版本
看一下寻找旧版本的逻辑,代码实现比较直观,就是不断的构建旧版本,判断对应版本对当前ReadView是否可见,可见就说明找到对应版本了,不可见就是还需要继续追溯旧版本。
对于构建旧版本的逻辑:
* 先判断本次rollptr上是否标记了insert,如果有说明当前是最后一个版本
* 读取rollptr上记录的位置,定位到具体的undo page,上锁,将undo log record拷贝出来
* 然后跳过undo log中记录的clust index columns,因为这里的clust index column的作用是定位这一行,是在purge/undo的时候用,在构建旧版本的时候不需要用
* 解析undo log中记录的被更新的column的数据,从而构建出update vector
* 将update vector应用到当前版本上,就得到了老版本的数据。
* 这里还有一个优化,为了减少内存的分配,innodb会判断本次更新是否可能导致数据列的长度变化,如果没有的话就可以原地更新,不需要再为新的版本分配内存了。
row_sel_build_prev_vers_for_mysql
row_vers_build_for_consistent_read
trx_undo_prev_version_build
trx_undo_get_undo_rec // 读取undo
trx_undo_get_undo_rec_low
trx_undo_page_get_s_latched
trx_undo_rec_copy
trx_undo_update_rec_get_update // 读取update vector
trx_upd_index_replace_new_col_vals // 非原地更新
trx_upd_rec_in_place // 原地更新
对于检查一个二级索引项是否对应一个聚簇索引项,遍历二级索引上的排序键,看是否和主索引上的数据相等即可。
row_sel_sec_rec_is_for_clust_rec
rec_get_nth_field_instant
com_data_data
最后再贴一个大致的流程图:
Purge
Innodb的Purge系统的作用是回收旧版本,其中主要包括两块内容:
- 对那些被逻辑删除的旧版本做物理删除用的,比如某一个数据在被删除的时候,只是在Btree上被标记了一个delete mark,并没有真正的删除这条数据。在所有活跃的事务都可以观测到这次删除操作后,我们就可以做真正的删除,从而释放物理空间
- 回收不可见的Undo log,当不会再有事务追溯rollback ptr到undo log中读取旧版本的时候,我们可以安全的回收掉Undo log,释放物理空间
在开始介绍Purge的流程之前,这里需要先介绍一个在innodb事务中的概念,叫做trx_no。每个事务在提交的时候都会被分配一个trx_no。这个trx_no和一些并发控制协议中的commit_ts非常类似,不同的点在于innodb不会用他做可见性判断,他的作用是为了让Purge system可以判断哪些undo已经不可见了,从而可以被purge system删除掉。
事务在提交的时候被分配一个递增的trx_no。读事务在获取readview的时候,会保存当前活跃事务的最小的trx_no。purge system在工作的时候,会找所有readview中保存的最小的trx_no,所有trx_no小于这个值的事务对应的undo log,都会被purge + truncate掉。
有关trx_no分配的细节会在事务相关的文章中介绍,这里了解他的两个属性即可:
* trx_no全局递增
* 如果readview中的trx_no大于undo log中的trx_no,那么这个undo log一定对该readview不可见
*

可以理解成trx_no是把由trx_id构建的偏序关系映射到有全序关系的集合中
Purge System组织
Purge时会根据事务的trx_no进行排序来确定Purge的先后顺序。因为trx_no较小的事务一定更先不可见(提交较早),所以Purge的时候会先Purgetrx_no较小的事务。
每个Rollback Segment上有一个链表称为history list,在事务提交的时候,会把他的undo log加入到history list中,history list中的undo log是按照事务的trx_no排序的。
因为每个tablespace有128个rollback segment,为了追踪这128个rollback segment中的最小值,Innodb用了一个最小堆来从这128个history list中的最小节点里定位全局最小的undo log
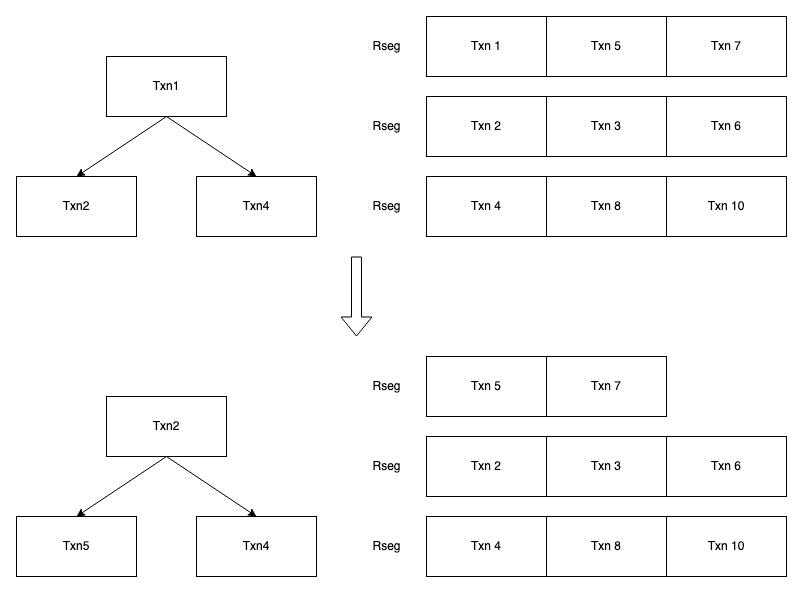
Background Purge
后台Purge的核心流程在trx_purge中,后台有一个Purge的coordinator线程,以及若干个worker线程。
Purge的思路非常简单:
* Coordinator线程先取出一个Purge view,用来确定那些数据仍然可能可见,不可见的数据就可以被Purge掉了
* Coordinator线程遍历上述的Purge Queue,按照trx_no从小到大的顺序将需要被Purge的Undo log收集起来。
* Coordinator线程将收集到的线程分发给worker线程,执行Purge
* Coordinator线程同步等待本批次的Purge操作结束后,执行Truncate,回收Undo log占用的物理空间。(这一步叫Truncate,后面会提到)
对应的代码为:
trx_purge
trx_sys->mvcc->clone_oldest_view(&purge_sys->view) // 获取Purge view
trx_purge_attach_undo_recs // 遍历需要被Purge的undo log,并发放给worker线程
trx_purge_fetch_next_rec
purge_groups.add(rec)
que_run_threads // 执行purge
trx_purge_wait_for_workers_to_complete // 等待purge完毕
trx_purge_truncate // 回收undo log
后台的Purge线程还会有一些流控相关的逻辑,比如发现Purge速度追不上写入的速度了,就需要提高Purge thread的数量,并且会反压前台的写入(srv_dml_need_delay)。
不过这里我们主要关注Purge本身的逻辑,这里主要有3块需要介绍:
* Innodb如何遍历需要被Purge的undo log,并发放给worker
* Purge具体都会做那些事情
* truncate会做那些事情
Scan Undo Log
上面提到过,在Innodb的Rollback Segment中,会按照trx_no的顺序将Undo log header(一个事务所有的Undo log)存放到history_list中。然后将Rseg加入到全局的Purge queue中,根据Rseg的history_list中最小的trx_no来排序,从而定位到全局最小的trx_no
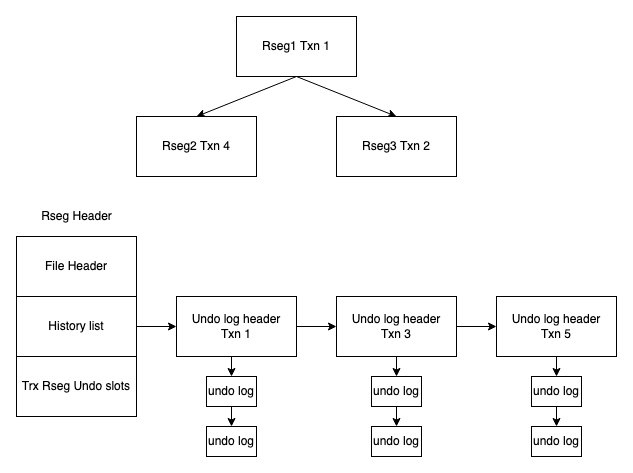
在这个层级结构下,想要遍历一条一条的Undo log思路也比较简单:
* 先定位到具有最小trx_no的Rseg,这一步是通过pop purge queue来实现的
* 定位到具体的Rseg后,会判断下,如果这个Undo log header是没有del mark的,会跳过,说明是不需要做真删的。如果存在del mark,会开始解析undo log header,记录第一个undo log record对应的位置
* 根据记录的undo log record的位置,先锁住对应的undo page,然后读取可能需要做真删的Undo log record,这里包括:
* del mark类型的undo
* 存在extern storage的undo(因为要把溢出页回收)
* 原地更新的undo,并且存在二级索引项的修改。(Update操作本身不需要对主索引做真删,但是如果修改了二级索引,就需要把对应的二级索引做真删了)
* 读取完成后,返回数据即可
这块代码可以理解成是一个two-level iterator,第一层是按照trx no的顺序遍历undo log header,也就是定位具体的rseg,第二层是遍历undo log header中的所有需要做真删的undo log record。如果Innodb这样写可能会容易理解很多,比较可惜的是他这里写的比较乱,所以有点影响理解。
为了辅助阅读代码,这里给出一个流程图:
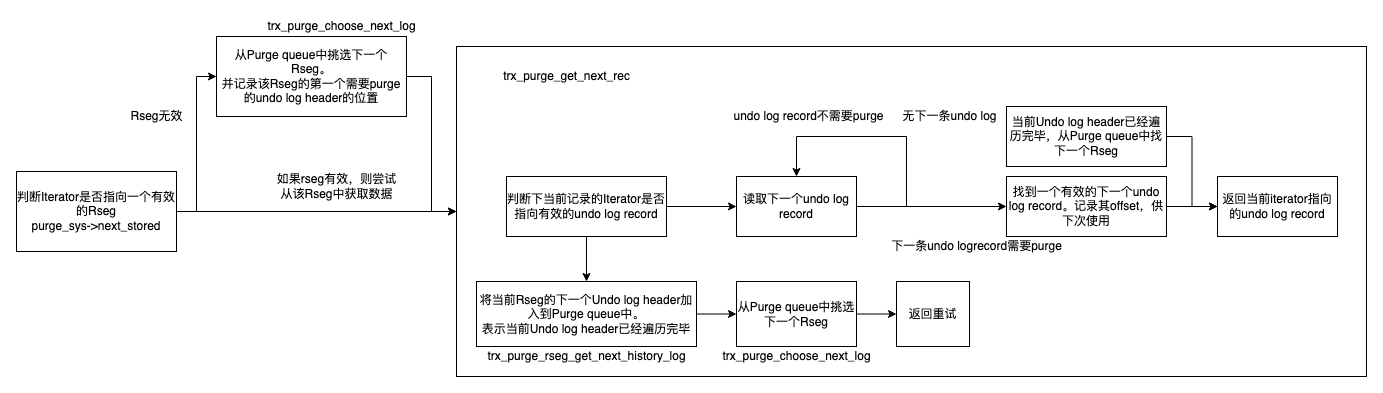
Do Purge
在读取undo log record后,Coordinator会将这些undo log record放到一个叫做Purge group的地方,里面会根据本次purge worker的数量来进行划分,并且会尽量将同一个表的undo log record交给一个worker来执行。
Innodb的一些操作的执行都是通过QueryGraph来实现的,后面会单独出一篇文章来讲解QueryGraph的作用。现在认为是启动了若干个线程执行Purge操作即可,对应到代码中为row_purge_step,其作用就是Purge一组undo log record。
每个worker会对分配到自己的一组Undo log record依次调用row_purge,完成真正的Purge。
row_purge_step // 单个worker的purge任务
row_purge // Purge单个Undo log
row_purge_parse_undo_rec // 解析Undo log
row_purge_record // 做真删
row_purge_record_func
row_purge_del_mark // for delete mark
row_purge_upd_exist_or_extern_func // update extern
其中,row_purge_parse_undo_rec会做的事情有:
* 解析Undo log的元信息,如trx id,undo log对应的表,undo log对应的rollback ptr
* 尝试将需要Purge的表打开,并会处理表文件丢失,表已经被Drop,数据corruption等情况
* 读取undo log中记录的主键(node->ref),update vector(node->update),以及在发生二级索引变更的时候,对应的索引项(node->heap)
因为需要Purge的Undo log有两种:
* del mark,即清理Tombstone,也是最常见的一种情况
* update with extern field,即在更新的时候,如果更新了存储到溢出页中的项,那么当旧版本不可见的时候,也需要将溢出页中的数据处理掉
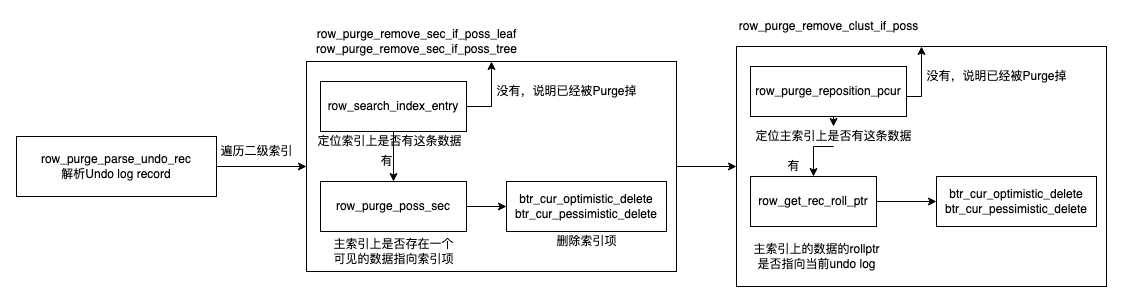
这里我们主要关注最常见的,清理Tombstone的情况。对应row_purge_del_mark。大体逻辑为遍历所有未损坏,且未提交(对应OnlineDDL)的索引,删除二级索引上对应的数据。在二级索引删除完成后,再删除聚簇索引上的数据。
for index in table.valid_index {
row_build_index_entry_low
row_purge_remove_sec_if_poss // 删除二级索引项
row_purge_remove_sec_if_poss_leaf
row_purge_remove_sec_if_poss_tree
}
row_purge_remove_clust_if_poss // 删除聚簇索引项
删除二级索引的流程为:
* 先定位到具体的索引项
* 如果没有找到,说明已经被Purge,放弃本次Purge。
* 因为Innodb没有记录一个Purge的标记,说明那个索引已经被Purge过,那个索引还未被Purge。所以对于一个Undo log record,可能会Purge多次。
* 如果找到索引项,需要去聚簇索引中遍历版本链,看是否存在一个版本指向当前对应的二级索引,如果有,则放弃Purge,说明当前二级索引还有效。如果没有,则可以进行Purge
* 对Btree做真正的删除btr_cur_optimistic_delete/btr_cur_pessimistic_delete
* 这里有个小细节,是删除的时候会使用Change buffer做优化。在悲观删除的时候不会走Change buffer(因为会触发SMO),内部还会涉及到buffer pool watch的逻辑。具体逻辑会在Change buffer的文章中讲解。
Purge需要关注的两个细节:
1. 先Purge二级索引,再Purge主索引。这是为了和前台的写入(先写主索引,再写二级索引)互斥。
* 因为前台写入会根据主索引上的状态进行决策。比如决策是Insert还是Insert by modify。
* 而后台Purge会根据主索引上的状态决定是否进行Purge
* 二者都通过聚簇索引Btree上的Latch做了互斥,从而保证不会丢掉索引项
2. 因为Innodb的Insert by modify,以及更新时的no order change逻辑,可能会存在多个聚簇索引项指向一个二级索引项。所以在Purge的时候需要回到聚簇索引中重新检查一遍,只有保证聚簇索引中没有人引用当前索引项后,才能做删除。
* 那么这里的细节是,检查时需要持有二级索引上的锁,避免有并发的写入请求影响Purge的决策
* 根据Latch order,其实可以先获取二级索引的Latch,再去读主索引,决策后,在持有主索引的锁的时候去做二级索引的Purge。这样比较直观,但是性能会差一些。
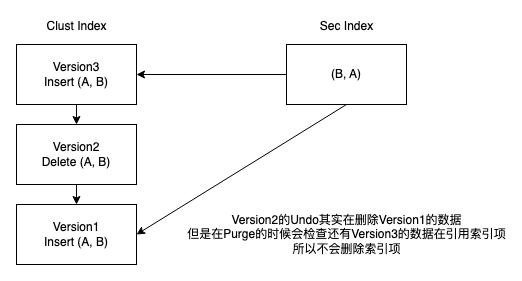
最后删除聚簇索引的流程则较为简单:
* 定位聚簇索引项
* 确定要删除的这个聚簇索引项是当前Undo log对应的聚簇索引项。方法是比较一下聚簇索引项上的rollptr。
* 如果确认没问题,则执行删除即可。btr_cur_optimistic_delete/btr_cur_pessimistic_delete
Truncate
在辛苦的Purge了一段时间的数据后,Btree上的数据都变得干干净净,没有垃圾数据了。现在我们要做的是回收不会被使用的Undo log,从而释放空间。
Innodb会在若干次Purge后执行一次Truncate,默认值是128。
因为Innodb是按照trx_no的顺序进行的Purge,所以Truncate也变得比较简单,因为可以比较容易判断哪些Undo已经被Purge了,就可以直接回收对应的Undo Page了。
Innodb会扫描所有表空间,以及系统表空间的Rollback Segment,分别对他们进行Truncate。前面介绍过,每个Rollback Segment上都有一个History list,保存着历史写入的Undo log,并且按照trx_no进行排序。所以Innodb的做法就是不断获取History list中的尾节点,判断他是否已经被Purge过。如果是,则将其回收。
trx_purge_truncate_history
for table in tables {
for rseg in table {
trx_purge_truncate_rseg_history
trx_purge_free_segment
trx_purge_remove_log_hdr
}
}
因为Innodb中存在Undo page的复用,所以在确定一个Undo log list可以被truncate后,还需要确认他是否是这个Undo segment上唯一的一个Undo log list。如果是,则直接释放整个Undo segment(trx_purge_free_segment),否则只是移除Undo log header(trx_purge_remove_log_hdr)。
代码实现上还有一点细节,比如Undo segment的释放操作,要求Undo segment从Rollback segment中摘除的操作和释放filespace segment的操作是原子的。否则可能出现空间未释放,但是Undo segment已经没人引用的情况。
最后的最后,这里补一张简单的示例图,来演示一下Undo这套东西在Innodb的读写链路中的作用。我们假设开启了一个事务,他会在系统中插入一行数据,删除一行数据。与此同时存在并发的读取逻辑。
Reference
http://mysql.taobao.org/monthly/2023/05/01/
https://www.alibabacloud.com/blog/an-in-depth-analysis-of-undo-logs-in-innodb_598966
https://zhuanlan.zhihu.com/p/263038786
《MySQL是怎样运行的:从根儿上理解MySQL》第22章/23章

文章评论
本来在github搜到的时候以为是个平平无奇的大佬,读2022年年终总结发现居然是学长 !:biggrin: 请问您的实验室导师是哪位呀
@farstarr 是张岩峰老师