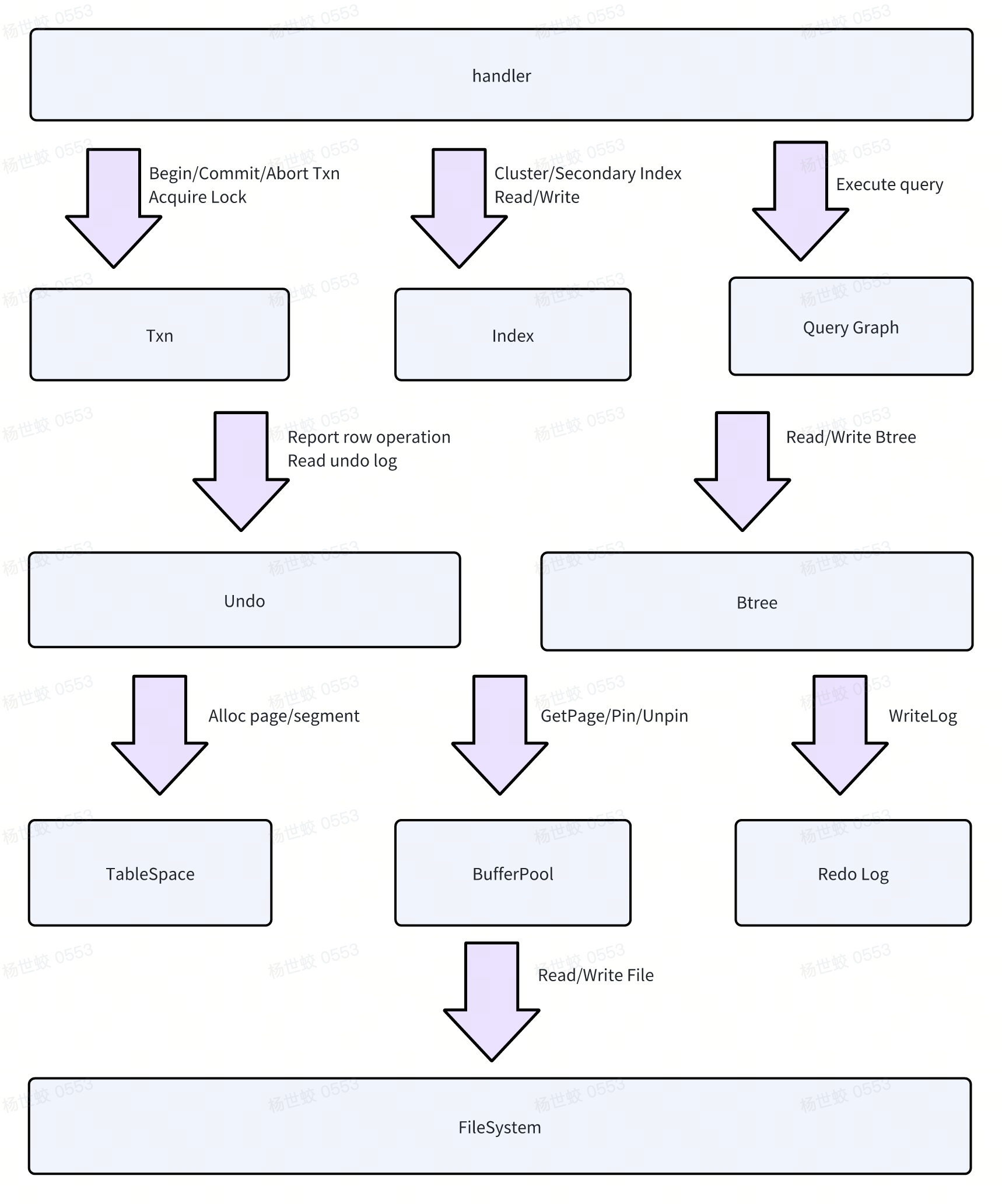
这篇文章来介绍一下MySQL的默认存储引擎Innodb,文章整体基于MySQL8.0的代码实现。
之前的介绍中Innodb Introduction,主要讲了很多前台写链路相关的代码,对于Innodb整体介绍的并非那么全面,所以这篇文章来做一下更加全面但是相对简要的介绍,期望读者可以了解Innodb中各个模块的基本原理
这次来尝试一下bottom-up approach
TableSpace
Innodb构建于文件系统之上,不过没有使用多少文件系统的特性,很多管理相关的工作都是TableSpace这一层做的,约等于可以直接放在裸盘上。
Innodb中,主要的表空间有两种:
- 系统表空间,可能对应文件系统中的一个或者多个文件
-
独立表空间,对应一个
表名.ibd的文件
在Innodb中,page_id就是由table space id和page number共同组成的,即“文件名,offset”。page number为32bit,所以一个表空间最多有2^32个页,按照默认一个页16KB来算,一个table space最多支持存储64TB的数据
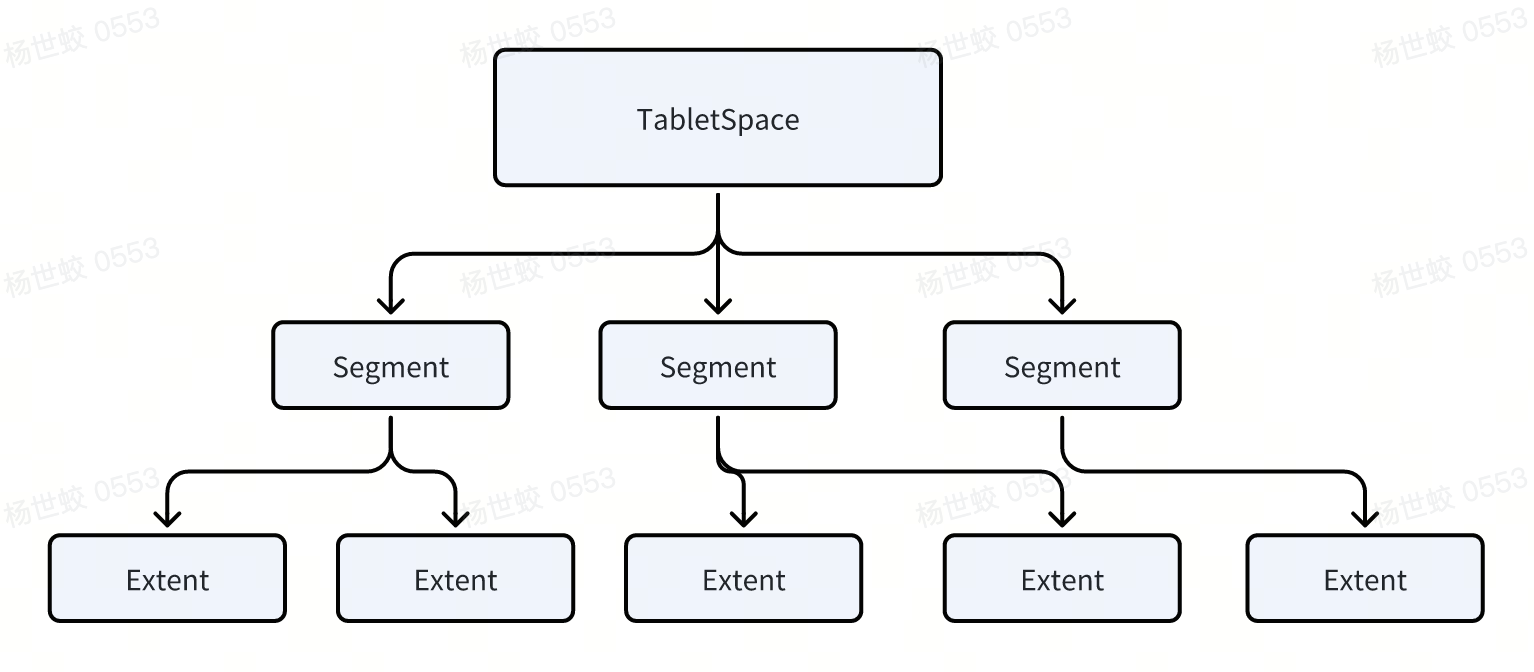
文件的组织结构可以理解成是3层:
- 表空间下有Segment,每个Segment包含若干个Extent,每个Extent下包含若干个连续的Page
-
为了避免碎片化,有的Segment用不满一整个Extent的时候,会用一些特殊的Extent服务一些零散的Page
引入Segment的目的主要是希望将Btree的Page放到一个Extent中,提高局部性
在实现上,一般是开头的几个Page会保存一些元数据,如XDES Entry用来描述Extent的状态,以及INode Entry用来管理Segment
更加具体的细节推荐读一下《MySQL是怎样运行的》
BufferPoolManager
BufferPoolManager的核心作用就是管理缓存页,让数据库系统拥有能够处理超过内存大小数据的能力。对于BufferPool来说,提供的最核心的接口就是GetPage,给定PageId,得到Page的内容。一般使用BufferPool的流程为:
- 通过GetPage得到Page的内容
-
调用Pin,将page pin在内存中,防止换出
-
对Page进行修改,并在修改结束后unpin page
-
BufferPoolManager会将脏页写回到磁盘上
-
最后BufferPoolManager会释放掉这个Page的内存,为其他的Page留出空间
针对上述流程,对于BufferPoolManager,我们主要关注的点有:
- BufferPoolManager是怎么组织的
-
如何决策要换出那些Page来释放内存
-
写回脏页的流程是什么
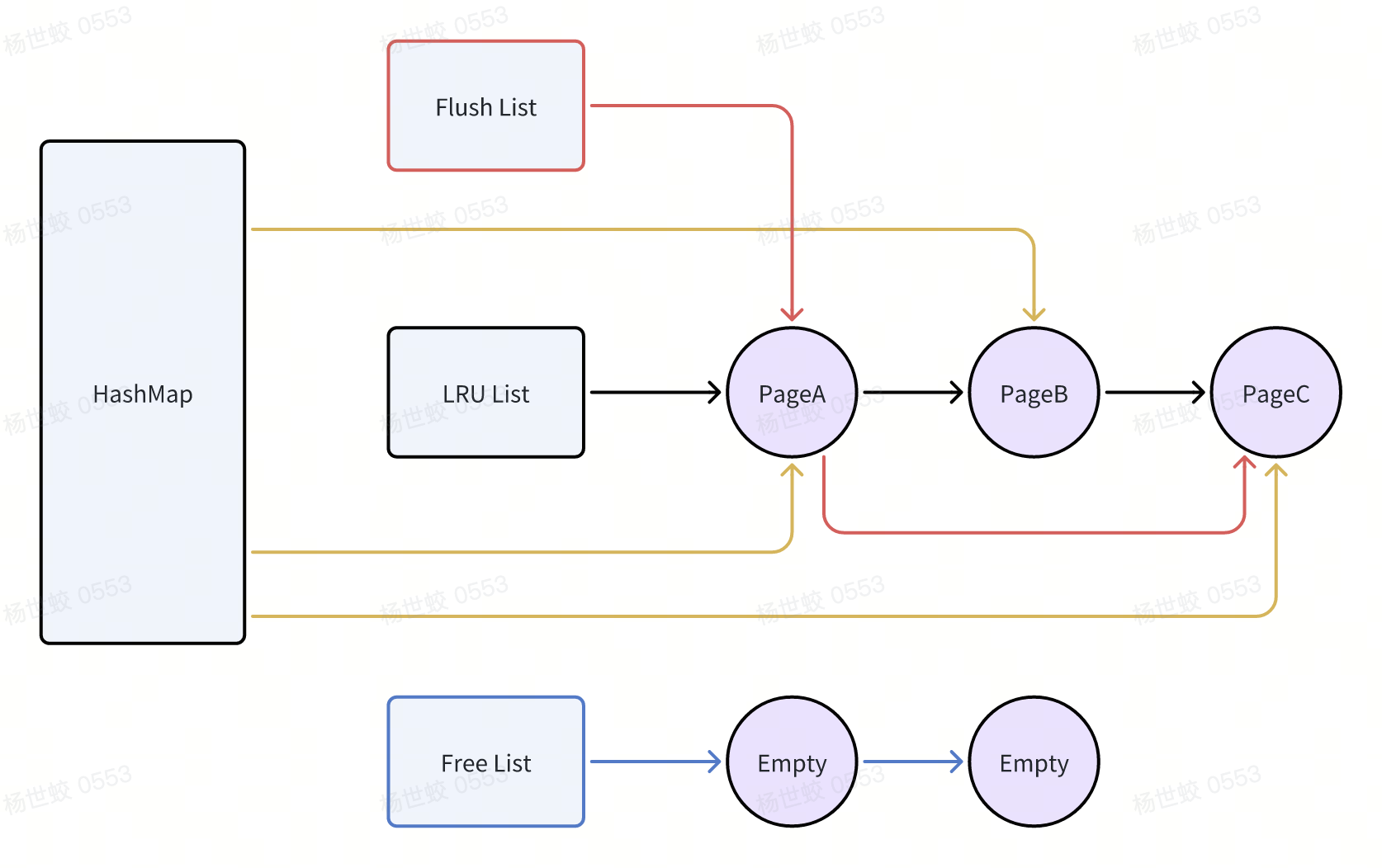
- Innodb中BufferPool的实现是一个分Shard的LRU。有几个链表需要关注下:
- LRU List,用来确定最近使用过的Page,从而找到那些Page很久没有用过,来换出Page
-
Flush List,确定哪些Page是脏页,用来回写到磁盘上
-
Free List,还未被分配的Block,在分配Page时会优先从Free List中获取
-
换出流程:
- 在前台获取Page的过程中,会先尝试从Free List中获取Block
-
如果Free List不存在空闲Block,会开始逆向遍历LRU List,第一轮遍历若干个Page,当找到没有被Pin住的非脏页的时候,会将其换出
-
如果第一轮没有找到空闲块,第二轮会遍历整个LRU。
-
如果第二轮还是没有找到空闲块,说明Page要么是脏页,要么是正在被使用。这里会触发一次前台的Flush,同步将脏页刷回到磁盘并释放该Page
-
刷脏流程:Innodb中有一个Page Coordinator和一组Page Cleaner线程负责进行刷脏。这里会综合考虑当前的脏页率,Redo log的数量,脏页增长率,Redo log增长率等信息,来决定每一轮需要刷脏的Page数量。Coordinator在计算完毕后,从Flush List中取出对应数量的Page进行刷脏。
- 这里,脏页率的考虑主要是为了防止没有足够的空间服务正常的前台流量
-
如果刷盘过于激进则会导致写放大过大,对磁盘压力也较大
-
Redo log的数量主要是考虑Recover的速度,因为越多的Redo log代表越慢的恢复速度
简单说一下Innodb在BufferPool中做的一些优化:
- 对于LRU本身来说,有可能因为一些全表Scan等操作导致缓存被污染,进而导致影响缓存命中率
- Innodb的做法是在LRU List拆分成old(3/8)和yong(5/8)两个List,新请求的Page只会放入到old list的开头。从而避免整个LRU被污染
- LRU每次调整链表的开销比较大
- Innodb的做法是,对于一些频繁访问的Page,如果他距离LRU List的Header的位置比较近,就不再把它移动到链表头了
- SingleFlight的优化,在进行IO的时候,会先放置一个控制块到BufferPool中,放锁进行IO,等到IO结束后再将数据填充到对应的Block内
Redo
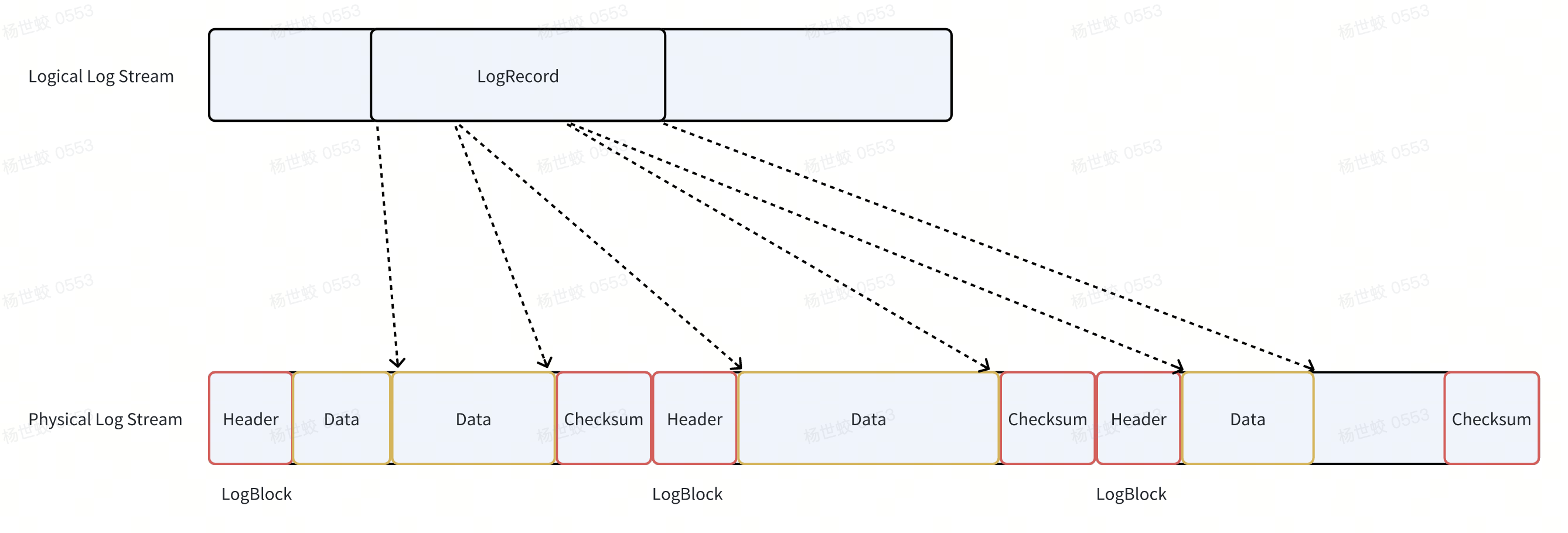
Innodb的RedoLog是ARIES中提出的物理逻辑日志,这里的物理指的是日志以Page为单位,逻辑指的是日志记录的是针对Page中内容的逻辑操作。
物理逻辑做的好处是,日志可以以Page为粒度进行并行的恢复,Page在落盘时不需要考虑和其他Page的联动,并且逻辑日志可以让日志的数据量更小,节省带宽。
每条日志都有自己唯一的标识符,成为LSN(Log Sequence Number),一般实现是日志在日志流中的位置(byte offset)
需要注意的是,逻辑日志的缺点是不能保证幂等性,所以Innodb会在每个Page上记录这个Page所应用过的最大的一条日志的LSN。在恢复的时候,所有LSN小于Page上记录的LSN的日志都被认为已经写入过,就会被跳过。
需要注意的是,LSN是逻辑的标号,到物理文件中,还需要有一些转化,因为日志文件需要记录一些额外的元信息
在MySQL8.0之前,日志的写入需要上一把大锁,然后根据LSN的顺序加入到Flush List中,从而保证Flush List中Page的oldest modified lsn是不断递增的,以此来保证Checkpoint正常推进,以及日志文件的正常回收。导致日志模块成为一个比较严重的单点。
MySQL8.0引入了无锁的Redo log,允许并发写入Redo log。每个线程可以先Reserve一段log buffer,然后并发的将日志写入到自己的log buffer中即可,极大程度的提高了性能。不过在带来高性能的同时,还带来了两个问题需要解决:
- 每个线程并发的写入自己的log buffer,日志线程什么时候知道要将日志刷到磁盘上?
- 比如拥有LSN更大的log buffer的线程先写完,日志线程不能随便的将这段log buffer刷到磁盘上,因为日志是按序写入的,所以需要等待前面的人都写完才能做IO
- 每个线程独立Reserve log buffer,在将脏页加入到dirty list的时候则可能出现乱序。即LSN更大的page放到了dirty list的前面,此时如何确定Checkpoint位点?
-
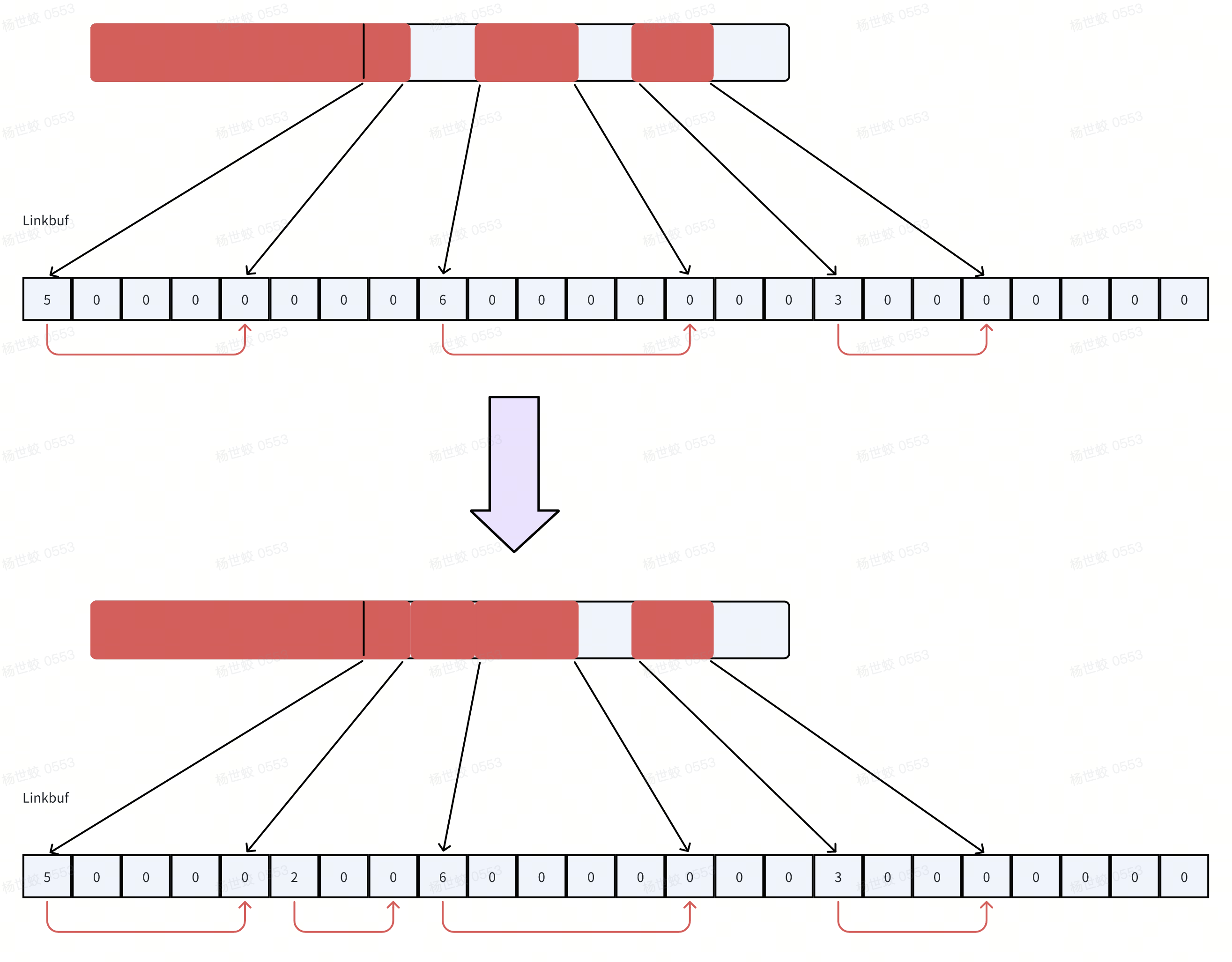
针对第一个问题,Innodb引入了一个叫做Linkbuf的结构来解决。Linkbuf的作用就是维护一段流中的连续的区间。每当前台线程将自己的数据写到Logbuffer后,会通过Linkbuf的add_link接口标记某一段区间已经连续,Linkbuf会维护最长的已经连续的位置,IO线程会根据这个位置计算出需要IO的位置,从而保证刷日志时不会出现空洞。
- Linkbuf的实现就是一个普通的数组作为buffer,以及一些原子变量用来指示最大连续的位置,数组的开头和结尾等。因为日志流是无限的,我们不可能分配无限大的Linkbuf来追踪连续的窗口,所以会做循环复用。
-
需要注意的是,Linkbuf的长度限制了并发的程度。比如分配了4M的Linkbuf,如果每个线程都写一个1K的日志,那么就最多允许4k个线程同时写。
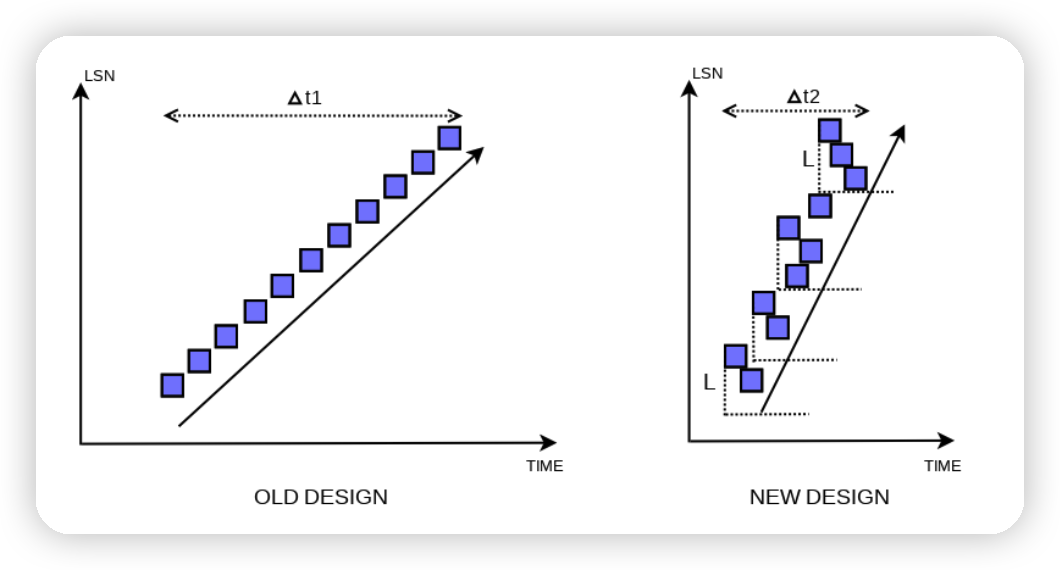
- 针对第二个问题,Innodb也是同样引入了一个Linkbuf,这里的原理恰好利用了第一点问题的一个缺点,就是Linkbuf不是无限长的,他的长度限制了并发的程度。
- 详细点说,对于某一段区间
[begin_lsn, end_lsn],在我们将其加入到Linkbuf之前,我们知道Linkbuf中最小的区间起点一定大于begin_lsn - link_buf_capacity -
这里Innodb的做法是:
- 对于一段日志,先等待Linkbuf中有空间可以存放自己这段区间
-
先将对应的DirtyPage加入到Flush List中
-
然后将这段区间加入到Linkbuf中。
-
这保证了,在当前日志对应的Page加入到Flush List的时候,Flush List中所包含的具有最小的modify lsn一定不会小于
begin_lsn - link_buf_capacity -
对比上面的图可以看到,在old design中,Flush List中的Page一定是按照LSN递增的,而新的设计中则允许一定程度的乱序,不过这个乱序程度不会超过Linkbuf的大小。那么在确定Checkpoint的时候,就只需要选择Flush List中最小的lsn 减去Linkbuf的Capacity即可
-
注意这两个问题用的是两个Linkbuf,不要搞混
- 详细点说,对于某一段区间
Innodb的日志是用ib_logfile0和ib_logfile1交替写入的,其中ib_logfile0文件的前几个Block被留作存储Checkpoint。文件中会预留两个Checkpoint位置交替写,里面会保存Checkpoint LSN。
MTR
MTR全称是Mini Transaction,有的地方也称为System Transaction,表示的是系统内部使用的事务。Innodb中,所有对系统的操作都会被转化为若干个MTR,比如写一个Page会被放入到一个MTR中,分配一个Segment也会被放到一个MTR中。
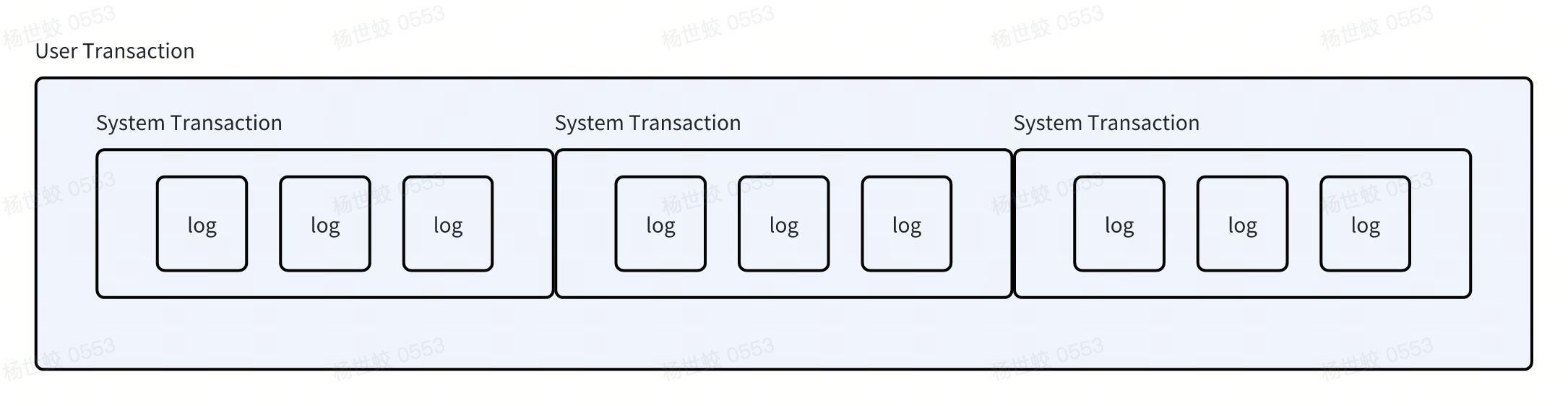
- System Transaction的特点有:
- 不需要Redo log落盘就可以提交的,这个角度叫Transaction可能比较迷惑
-
是Redo only的,不会出现属于System Transaction的部分Redo log落盘,导致需要回滚未完成的System Transaction的情况存在。Innodb的实现中,是会在日志中做标记,然后保证回放的时候只回放具有完整日志的System Transaction
-
个人更倾向理解成ARIES中,Redo only的logical operation
MTR本身和ARIES中的Logical operation差距不大,引入这个概念的核心目的是将数据的物理组织结构和事务所看到的逻辑内容区分开。这里的物理组织结构说的就是Page等概念,而逻辑内容则是具体的某一行。
在ARIES之前,可以想象一下用户事务直接操作具体的Page,回滚一个用户事务不仅要回滚具体的数据,还要回滚这个事务可能触发的页分配/SMO等操作,并且在整个事务执行期间持有Page的写锁会对并发度造成比较大的影响。
在有了Logical operation(System Transaction)后,每个Logical operation相当于一个子事务,子事务未完成,他自己负责回滚自己写入的内容,子事务如果完成,他会释放掉他持有的锁,此时如果用户事务希望回滚,因为子事务已经释放掉锁,无法通过物理日志进行回滚了,则需要通过补偿事务做回滚。
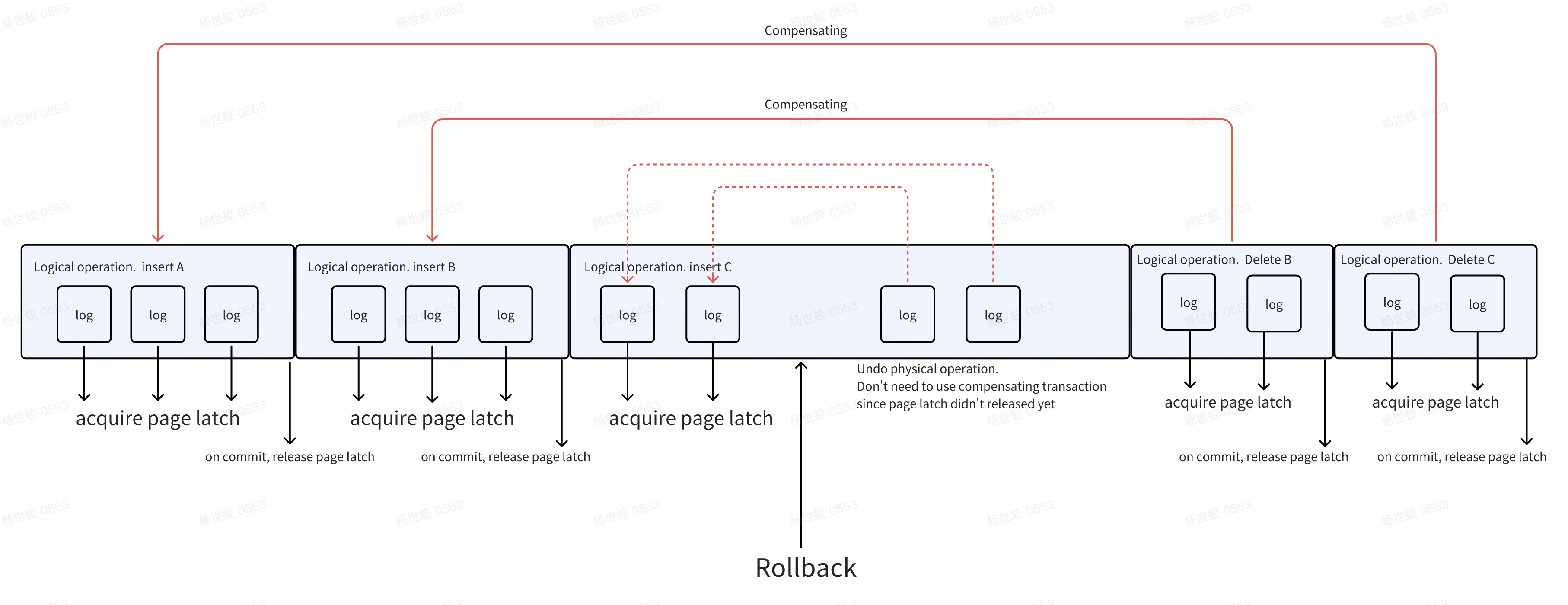
- 这里,System Transaction负责的就是物理内容,持有的锁就是Page级别的。
-
User Transaction负责的是逻辑内容,持有的锁是行级别的。
这里的感觉也有点像是,物理层通过System Transaction对上层暴露的是逻辑语意的各种原语,如Btree Insert Row,Btree Delete Row。然后事务层再将这些组织成对用户暴露的用户事务。
还需要额外注意的一点是,Innodb的MTR是Redo only的,一个MTR下所修改的Page就不能随便落盘,需要保证整个MTR的日志都落盘了,对应的Page才能落盘。实现上,这是将Page的oldest modifiy lsn设置成MTR的end_lsn来达到的。
Btree
Btree在前面的文章中有讲过,这里就不细说了
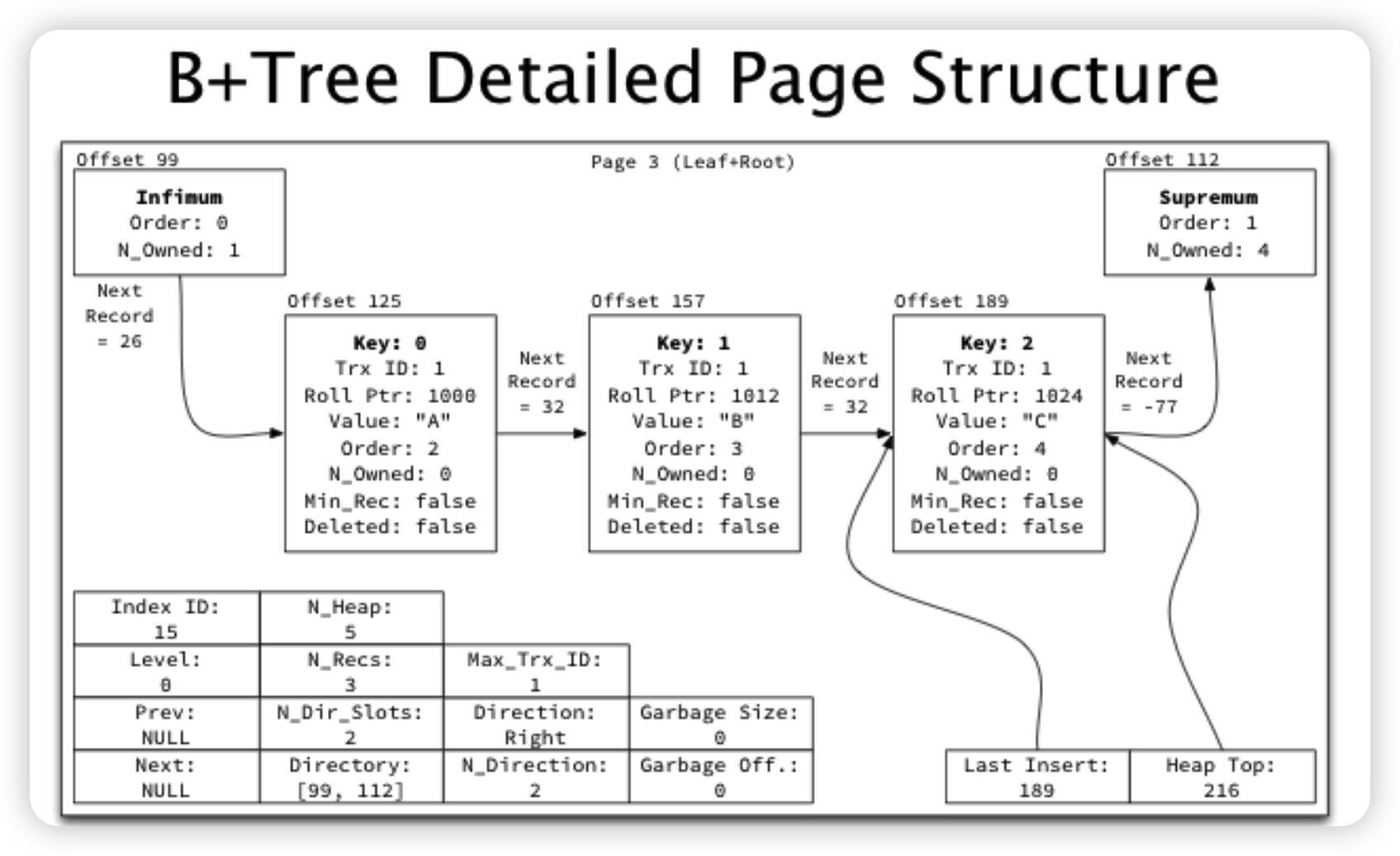
有关Page内结构这里更推荐去看一下MySQL是怎样运行的
- 若干行会被划分成一个chunk/group,Page内是由chunk/group连接起来的块状链表
-
Page内会有两个特殊的记录,Infimum/Supremum,表示上界和下界
-
为了快速二分,Page内会记录每个chunk的位置,称为Page Directory/Slot
-
在搜索的时候,会先通过Page Directory做二分,定位到某个group,然后再在group内做线性搜索
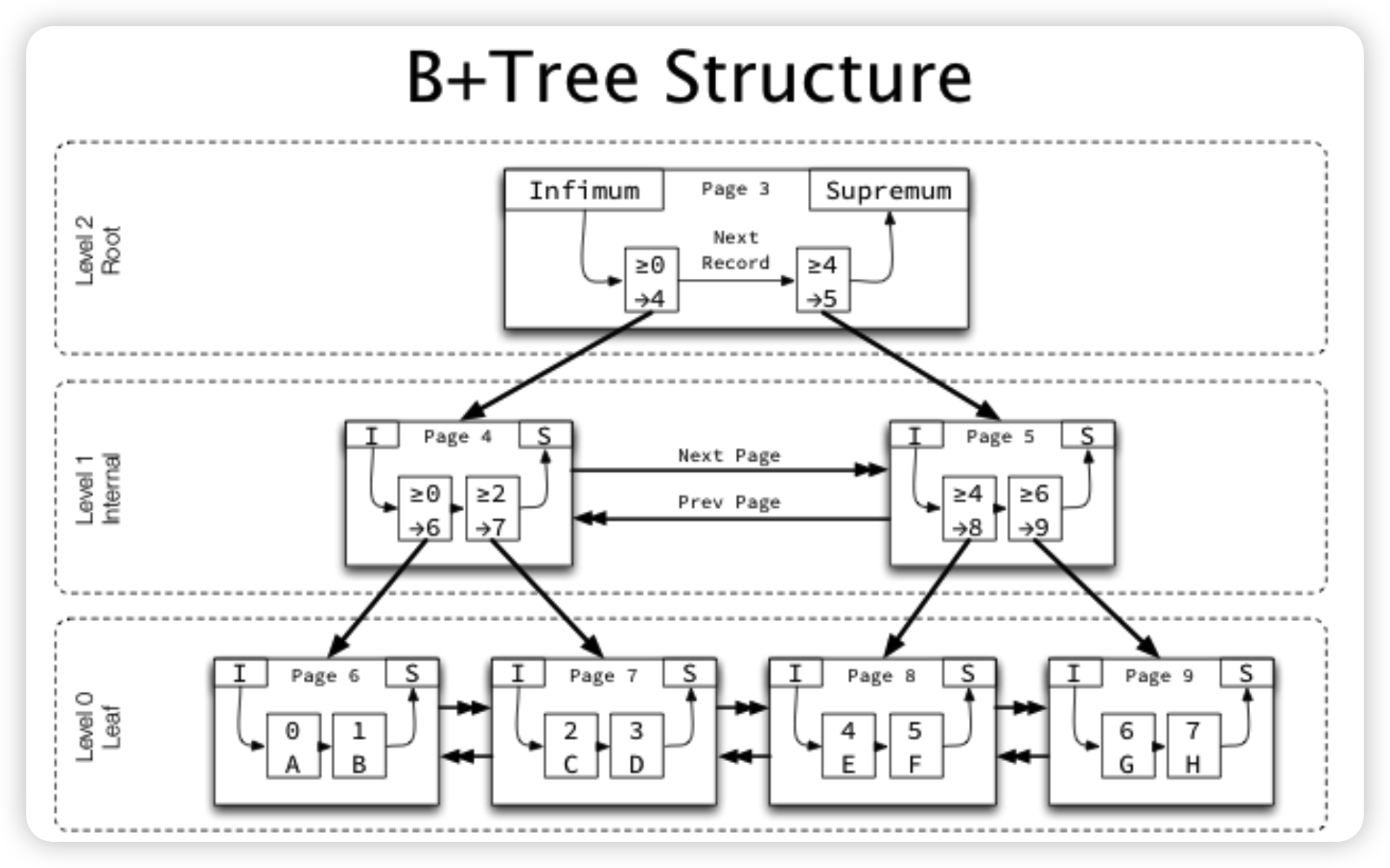
整体Btree的结构:
- 叶子结点为level 0,每往上一层level + 1。所以可以快速通过root上的level来判断这个Btree有多少层。
-
非叶子结点的每一项的Key为对应子节点中最小的行的Key(排序键),Value为对应子节点的PageID。
-
每一层的Page都会通过双向链表连接,其中只有叶子结点这一层才会通过双向链表加速读取,非叶节点的双向链表不会在搜索的时候使用
-
因为Btree每一层所需要覆盖的都是整个值域,所以每一层最左边节点所负责的值域是一个类似负无穷到x的形式。比如上图中的Page 4,实际上Page 6并不是只负责大于等于0,小于2的这段区间,而是小于2的所有值。为了处理这种情况,Innodb在每一层的最左边的行上面标记了
min_rec,在比较的时候,如果发现这一行被标记了min_rec,就会认为他小于一切值,而不会去比较具体的排序键。
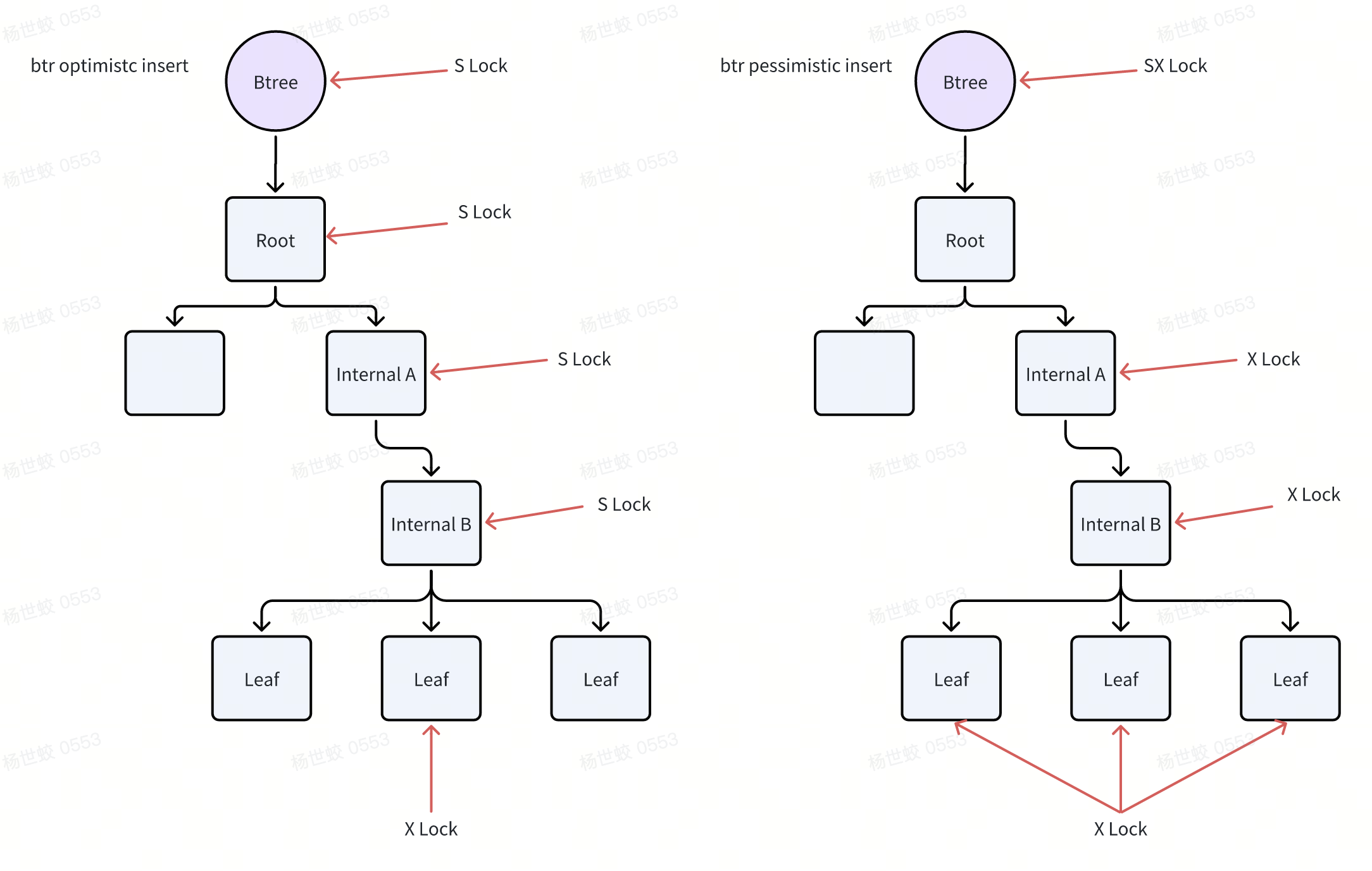
Btree的写入流程基本上都有两个阶段,即会尝试乐观写入和悲观写入,对应Btree是否可能发生SMO
- 先定位到需要写入的LeafPage,会获取搜索路径上的S锁,以及叶子结点的X锁,然后再释放路径上的S锁
-
判断是否可能发生SMO,如果没有则正常写入
-
如果需要做SMO,会从Root上再重新来一遍,并且会获取Btree的SX锁(保证SMO与SMO不会并发),然后获取路径上的可能发生SMO的节点的X锁,以及左右兄弟节点的X锁(因为在SMO的时候需要维护Sibling link)
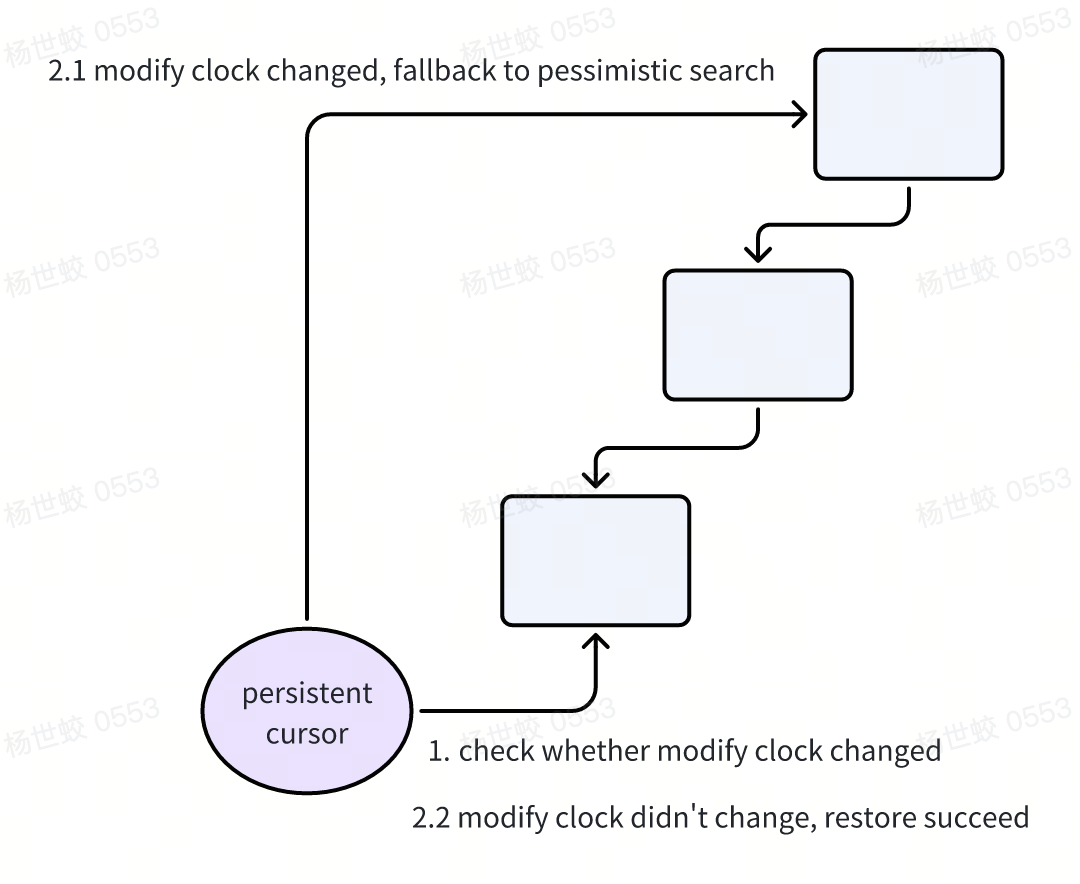
在读取Btree的时候,Innodb会先根据起点定位cursor,然后进行前向或者后向的遍历。这里有几个优化点可以注意下:
- 因为返回数据前必须释放Page latch,但是释放Page latch后,Btree的样子可能会发生改变,最安全的方法是下次读取的时候从root重新下降到leaf。为了减少下降的次数,Innodb引入了Persistent cursor。
- 大概机制为,读取数据完成后,通过pcur保存当前扫描到的位置,包括Page内的offset,Page Block等。然后在下一次读取的时候,会尝试直接读取上次保存的内存地址,判断modify clock是否发生变化,如果没变,说明Page还是之前的page,可以继续读取。如果变了,则fallback到悲观的restore,从Btree上重新下降。
- 对于向右移动cursor,因为latch order是从左到右的,所以直接latch下一个page即可
-
对于向左移动cursor,有两种方式:
- 会先尝试乐观策略,这里会先Latch当前Page,读取前一个Page的PageID,释放当前Page的Latch,Latch住前一个Page,然后乐观读取当前Page,判断Modify clock没有改变,并且记录的Prev page不变,则认为移动成功
-
乐观策略失败的时候,走悲观策略,从Btree根节点重新下降,搜索小于上一个读取的record的位置。
有关Btree,还有两个优化,Change buffer和Adaptive Hash Index,在前文中有过介绍,感兴趣的可以读读
Undo
这一节很多都是直接抄的上面文章的。。
Innodb中的Undo log并不是真的Log,而是数据,保存在Page中。核心作用有三点:
- 保存旧版本
-
回滚事务
-
作为持久化的活跃事务状态表
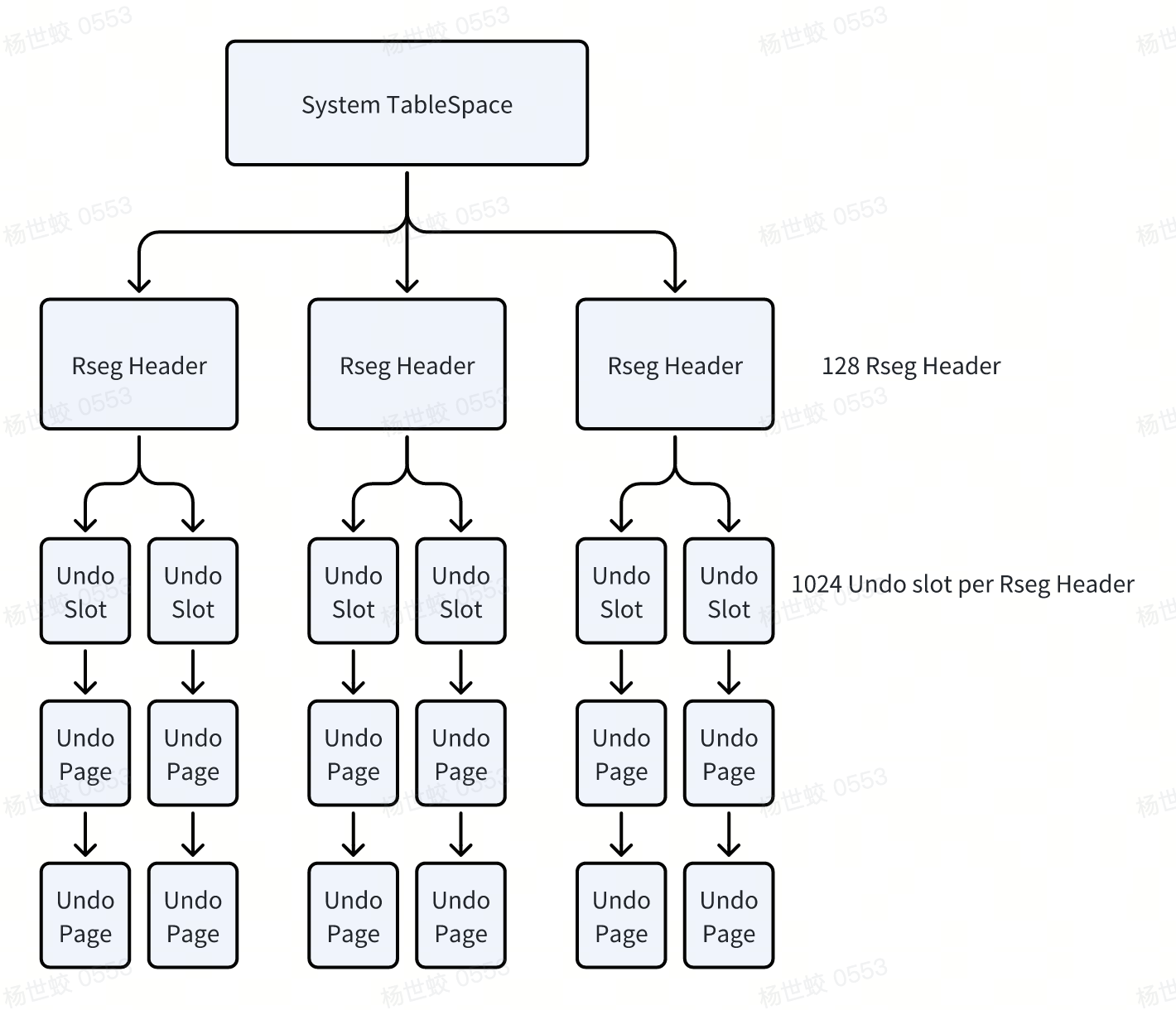
Undo log在Innodb中的组织如图所示:
- 在系统表空间的5号Page上,会记录128个Rseg Header,表示128个Rollback Segment
-
每个Rollback Segment中包含了1024个Undo slot
-
每个Undo slot中记录的是一个Undo segment的第一个Page的PageID
-
每个Undo segment中可以包含若干个Undo page
-
每个Undo page中可以包含若干条Undo log
在Innodb中,每个事务在写入的时候,会分配一个Undo segment,将对应的Undo log写入到里面。所以系统中的事务并发写事务的数量受到Undo segment数量上限的影响,也就是最多128 * 1024个。
Undo日志的类型一共有4种:
- TRX_UNDO_INSERT_REC,对应插入一条数据
-
TRX_UNDO_DEL_MARK_REC,对应del mark一个数据,也就是删除一条数据
-
TRX_UNDO_UPD_EXIST_REC,更新一个没有被del mark标记的数据,对应原地更新
-
TRX_UNDO_UPD_DEL_REC,更新一个del mark的数据,对应的是insert by modify
Undo的写入和读取流程:
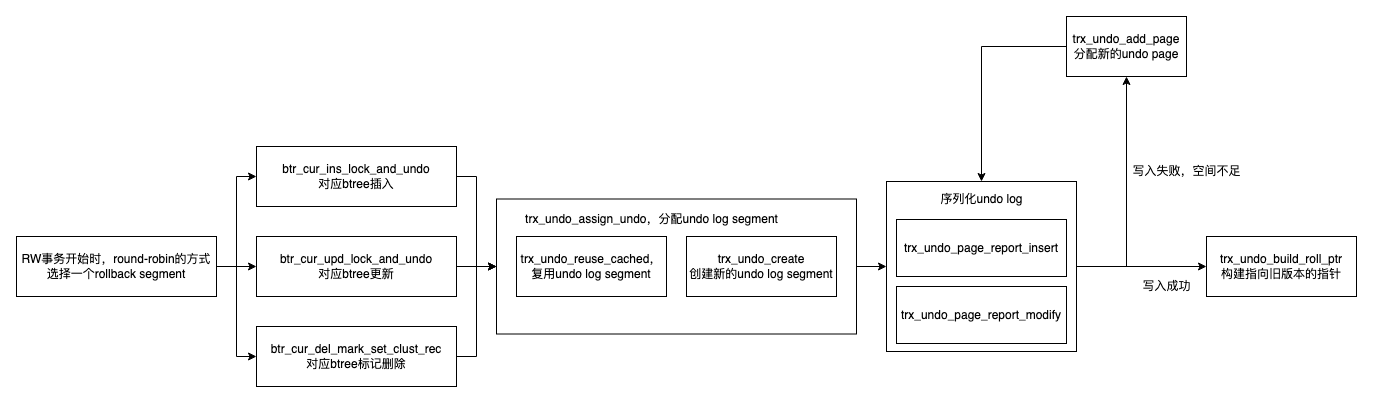
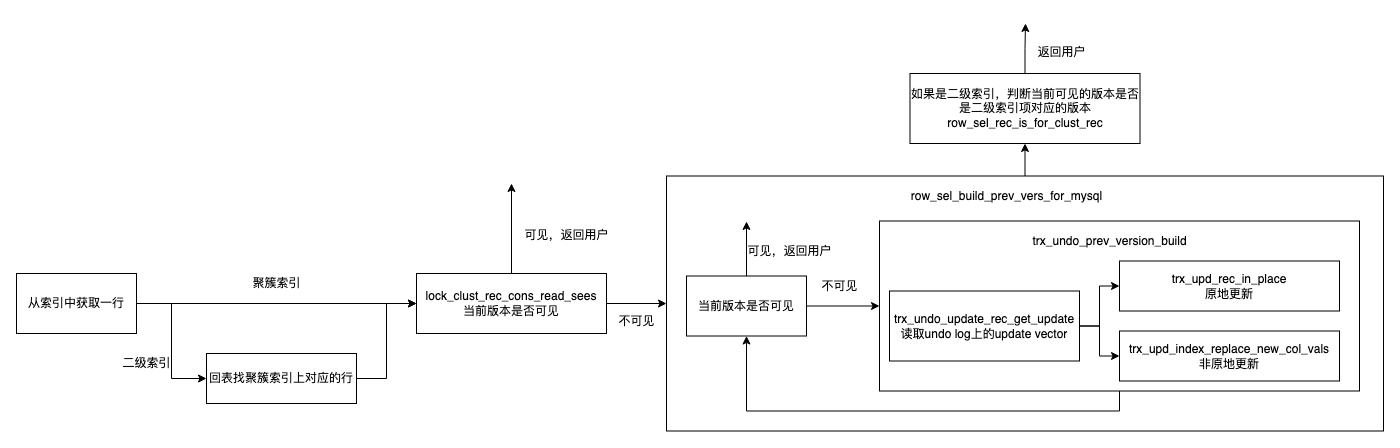
然后说一下Undo的GC的逻辑,在Innodb中,GC数据有两块:
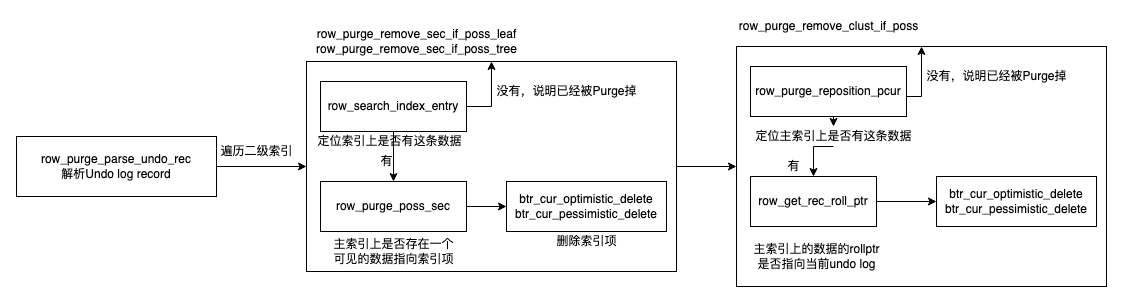
- Purge,表示对全局逻辑不可见的版本做真删
- 这里其实也有两点,一个是在删除一行数据的时候,是在聚簇索引上标记del mark,等到全局不可见以后再删掉这一行,释放物理空间。
-
第二点是因为索引本身没有版本的逻辑,可见性完全依赖聚簇索引,所以当删除一个旧版本的时候,如果有可能有一个二级索引指向他,需要把二级索引项也删掉
-
Truncate,表示对Undo log做GC
在开始介绍Purge的流程之前,这里需要先介绍一个在innodb事务中的概念,叫做trx_no。每个事务在提交的时候都会被分配一个trx_no。这个trx_no和一些并发控制协议中的commit_ts非常类似,不同的点在于innodb不会用他做可见性判断,他的作用是为了让Purge system可以判断哪些undo已经不可见了,从而可以被purge system删除掉。
事务在提交的时候被分配一个递增的trx_no。读事务在获取readview的时候,会保存当前活跃事务的最小的trx_no。purge system在工作的时候,会找所有readview中保存的最小的trx_no,所有trx_no小于这个值的事务对应的undo log,都会被purge + truncate掉。
有关trx_no分配的细节会在事务相关的文章中介绍,这里了解他的两个属性即可:
trx_no全局递增-
如果readview中的
trx_no大于undo log中的trx_no,那么这个undo log对应的事务一定对该readview可见- 那么如果readview中trx_no的最小值大于某条undo log的trx_no了,这条undo log就可以被GC了

在每个RollbackSegment上都有一个链表称为history list,在事务提交的时候,会把对应的undo log加入到history list中。每个history list中的undo log是按照trx_no来排序的。因为一共有128个RollbackSegment,GC需要从全局最小开始GC,所以这里会维护一个堆,用来在128个history list中找到最小的undo log进行GC
GC流程:
Txn
事务在Innodb中被简写为trx,事务相关的内容穿插于上面介绍的各个组件内,我们这一节就只关注3个点:
- ReadView的构建
-
trx_no的获取
-
隐式锁机制
ReadView:
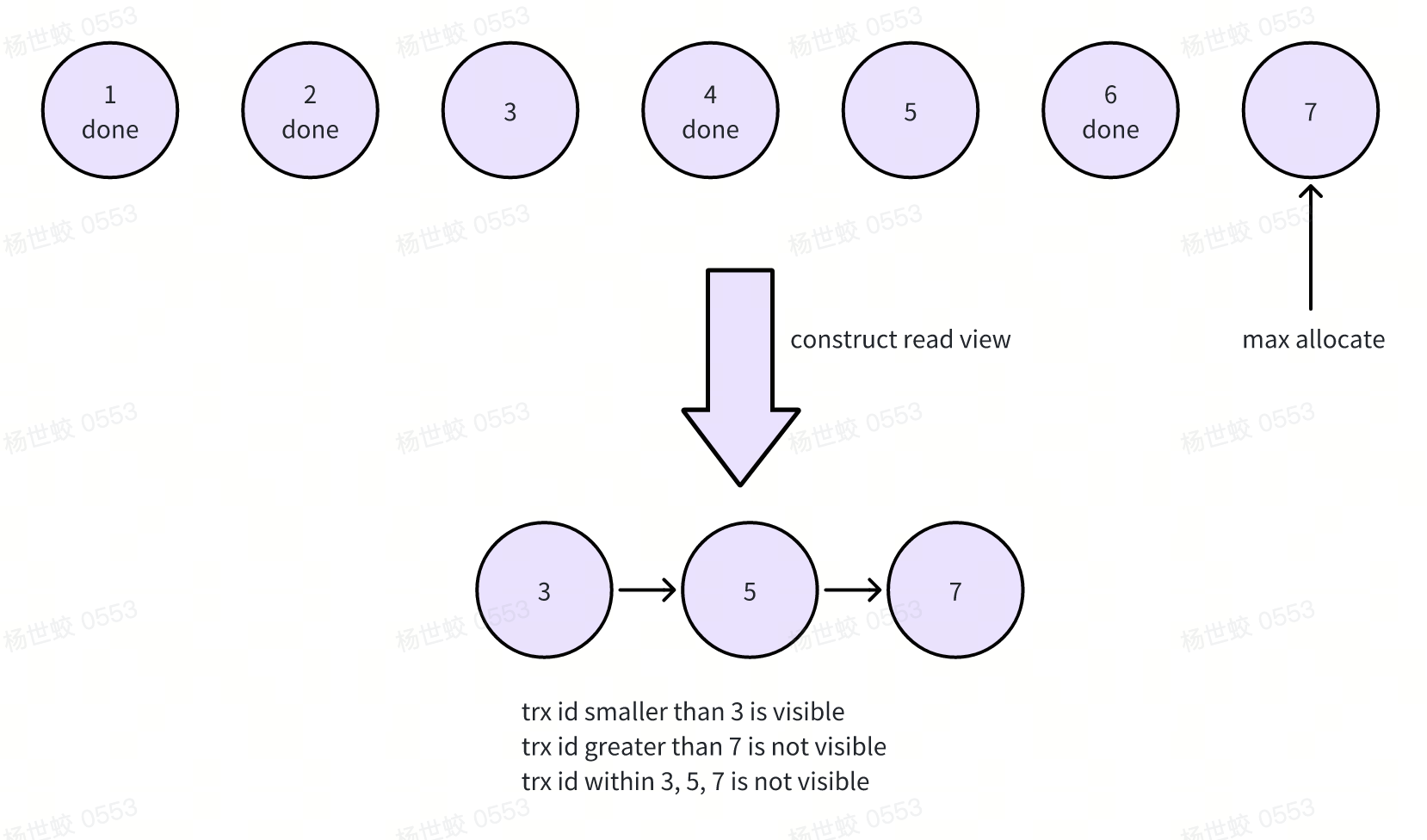
- 核心思路就是,事务开始时会分配事务ID,并加入到全局活跃事务链表中。事务结束后会将自己从活跃事务链表中移除。ReadView就是拷贝一下活跃事务链表,对于活跃事务的修改都不可见,从而保证快照语意。
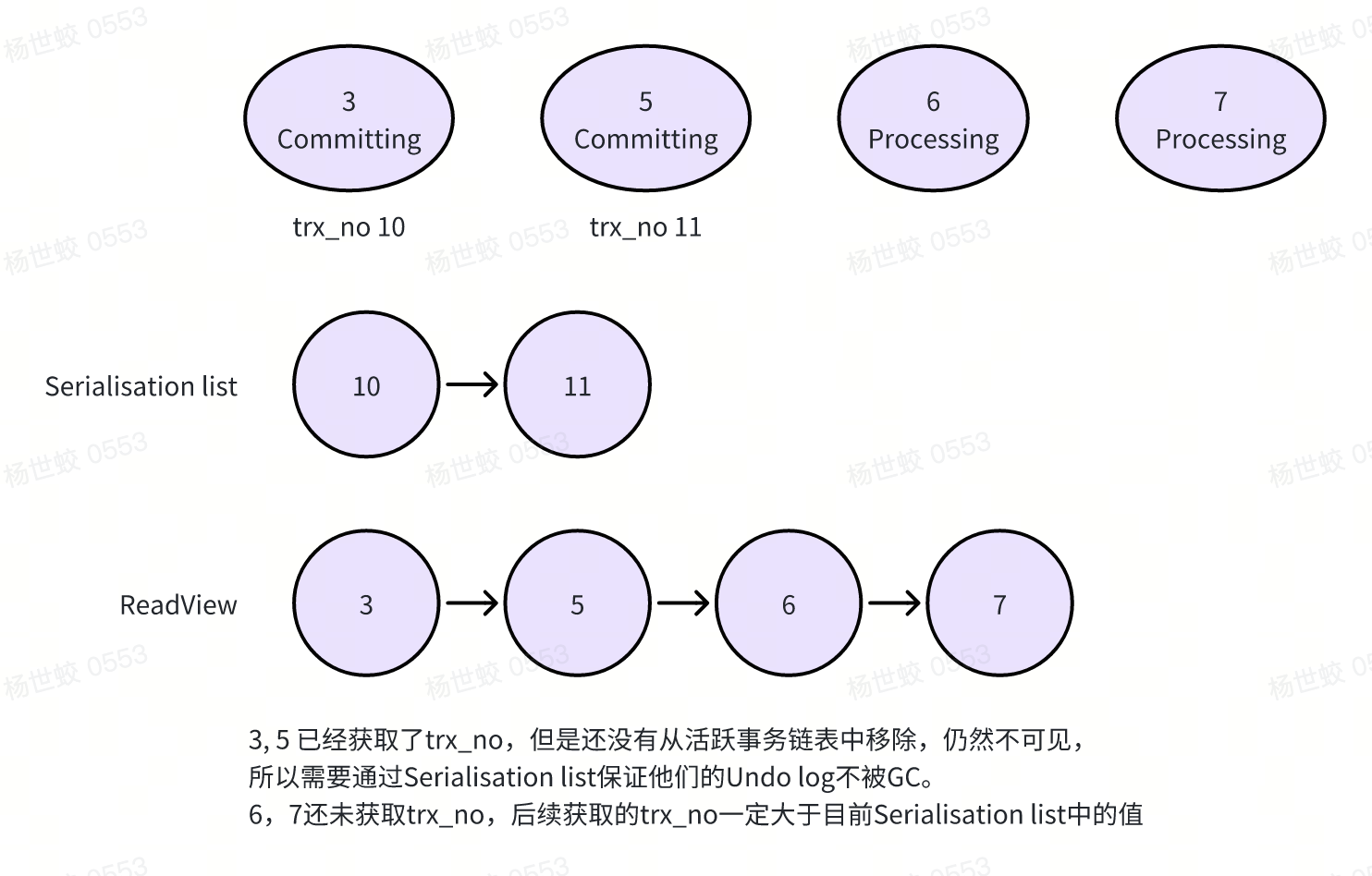
对于trx_no的获取,需要保证的核心点是:
- 如果readview中的
trx_no大于undo log中的trx_no,那么这个undo log对应的事务一定对该readview可见
这里Innodb的做法是:
- 对于写事务:
- 分配一个trx_no,将其加入到serialisation_list中,这是一个根据trx_no排序的链表
-
将事务ID从活跃事务链表中移除
-
将trx_no从serialisation_list中移除
-
对于读事务
- 读取serialisation list中最小的trx_no
-
获取read view
-
根据上述流程,如果readview的trx_no大于undo log的trx_no,说明写事务已经已经将其从serialisation_list中移除了,那么一定也已经将事务ID从活跃事务链表中移除了。
Innodb的锁和Btree的结构有比较强的耦合性,相关的内容在前文已经介绍过,这里就不再介绍了。
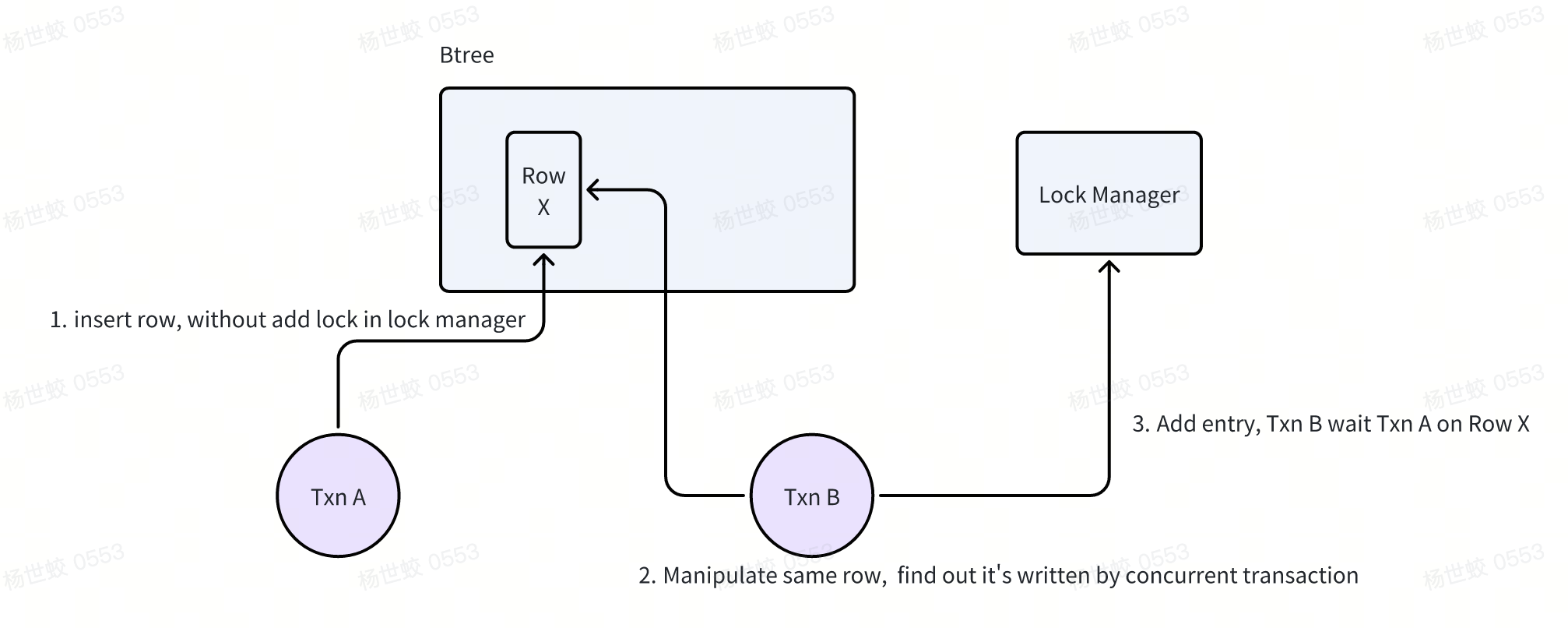
隐式锁,核心目的是为了减少在锁管理器上进行加锁放锁的操作,优化性能。核心思路是在加锁的时候,发现如果没有冲突,则不会在锁管理器上加锁,而是等待后续其他发现可能冲突的时候再一起加锁。
隐式锁只能用于行锁,不能用于间隙锁上。
- 正常的写入流程,在没有冲突的情况下是不会调用加锁的链路的。
-
在其他事务写入的时候,如果发现目标位置上已经有一行数据,则通过这个数据上记录的trx id判断对应事务是否活跃,如果活跃则会尝试将隐式锁转化为显式锁,加锁并等待。
-
对于二级索引来说,没有事务相关信息,这里会先通过page上的max trx id做一次过滤,如果通过了则会走到聚簇索引上,查看对应的聚簇索引项是否对应当前二级索引,以及当前数据是否是一个活跃事务修改的,如果是,则会将二级索引的隐式锁转化为显式锁,然后等待
-
需要注意的是,隐式锁的转化和事务的提交是有race的,需要保证的是,要么事务提交了,隐式锁的转化失败,要么事务还没来得及提交,隐式锁转化成功,然后事务提交释放锁。
Crash Recovery
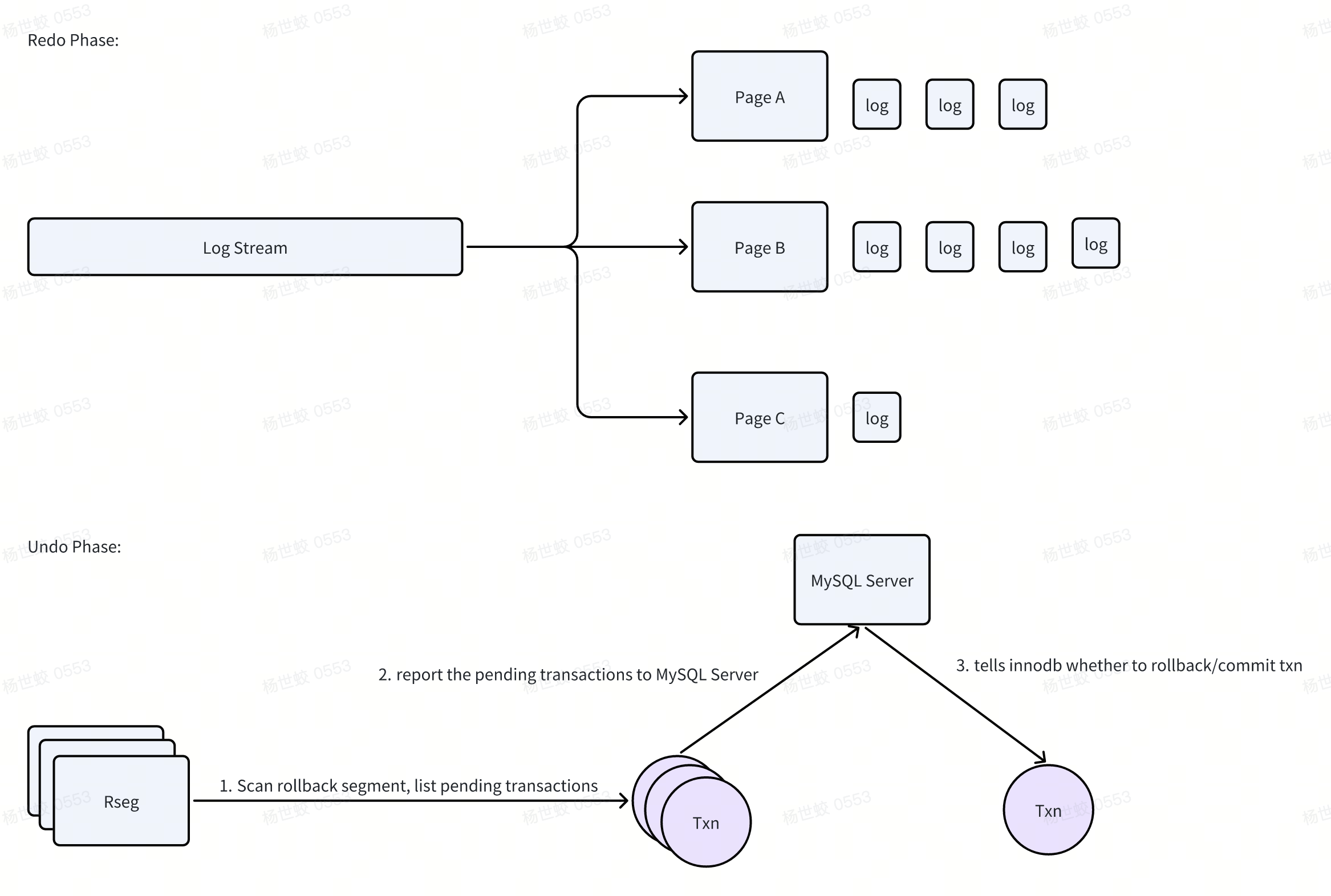
Innodb在崩溃恢复的时候,整体流程和ARIES描述的比较相近,大概的流程在上面也都简单提了提:
- Redo phase:
- 这里会从checkpoint lsn开始,扫描后面所有的redo log,并将其按照page id分发到每个page身上
- 需要注意的是不完整的MTR对应的redo log会被直接丢弃掉
- page在IO完成后会按序apply自己身上的log record,并过滤掉小于Page身上记录的lsn的那些log record
-
Redo阶段完成后,数据库已经恢复成一个物理一致的状态,数据已经可读可写了
- 这里会从checkpoint lsn开始,扫描后面所有的redo log,并将其按照page id分发到每个page身上
-
Undo phase:
- innodb会扫描Rollback Segment,遍历每一个undo slot,将未提交的事务记录下来
- 这里和事务提交/回滚的流程相对应,即事务提交/回滚时会在对应的Undo segment上记录状态未结束,这时候在undo phase就不会挑出这些事务
- 找到所有活跃事务后,Innodb无法直接决策要回滚事务,而是会汇报给MySQL Server层,由上层决定是回滚还是提交。因为有可能上层的2PC已经完成了(比如binlog已经落盘),但是Innodb还没来得及提交。
- 这里的回滚/提交和正常事务的执行一样。对于回滚来说,会逆序遍历Undo log,生成补偿操作做回滚。
- innodb会扫描Rollback Segment,遍历每一个undo slot,将未提交的事务记录下来
- 值得一提的是,Innodb中并没有类似ARIES中的防止重复回滚的机制(生成CLR并设置previous undo lsn),也就是说如果在回滚的过程中崩溃了,Innodb仍然会重复扫描Undo log,尝试回滚整个事务所有的操作,只不过当他发现表中数据已经被回滚过的时候,就会放弃本次操作(即回滚操作是幂等的)
- 比如一次Update的回滚,在回滚的时候发现目标行上的修改事务不是自己,就不需要回滚了
-
这里是因为事务在结束前不会释放锁,不可能有其他事务修改了同一行。那么如果数据已经改变了,只能是自己已经回滚了。
Reference
http://mysql.taobao.org/monthly/2023/08/01/
https://catkang.github.io/2020/02/27/mysql-redo.html
https://catkang.github.io/2022/10/05/btree-crash-recovery.html
https://zhuanlan.zhihu.com/p/164705538
https://zhuanlan.zhihu.com/p/164728032
http://mysql.taobao.org/monthly/2020/09/06
https://dev.mysql.com/blog-archive/mysql-8-0-new-lock-free-scalable-wal-design/

文章评论