这篇文章简略介绍一下Innodb中的一些组件,以及一些实现的优化。后续会针对不同的模块做细致的分析。之所以要先做一个简略的介绍,是因为Innodb本身的代码结构层次划分的并不是很清晰,无法层层递进式的去分析,个人在阅读源码的时候流程也是这样,先有一个大概的思路,再去扣细节。所以先有一个简略的介绍,每个模块的作用都是什么,也可以让读者在后续文章的阅读中有更多的背景,也省略了后续文章中需要介绍相关模块背景的时间。
可能叫Introduction不是很妥,因为并没有很全面的介绍,这篇文章我们主要关注前台的读写链路。
InnoDBis a general-purpose storage engine that balances high reliability and high performance. In MySQL 8.0,InnoDBis the default MySQL storage engine. Unless you have configured a different default storage engine, issuing aCREATE TABLEstatement without anENGINEclause creates anInnoDBtable.Key Advantages of Innodb
- Its DML operations follow the ACID model, with transactions featuring commit, rollback, and crash-recovery capabilities to protect user data.
- Row-level locking and Oracle-style consistent reads increase multi-user concurrency and performance.
InnoDBtables arrange your data on disk to optimize queries based on primary keys. EachInnoDBtable has a primary key index called the clustered index that organizes the data to minimize I/O for primary key lookups- To maintain data integrity,
InnoDBsupportsFOREIGN KEYconstraints. With foreign keys, inserts, updates, and deletes are checked to ensure they do not result in inconsistencies across related tables.
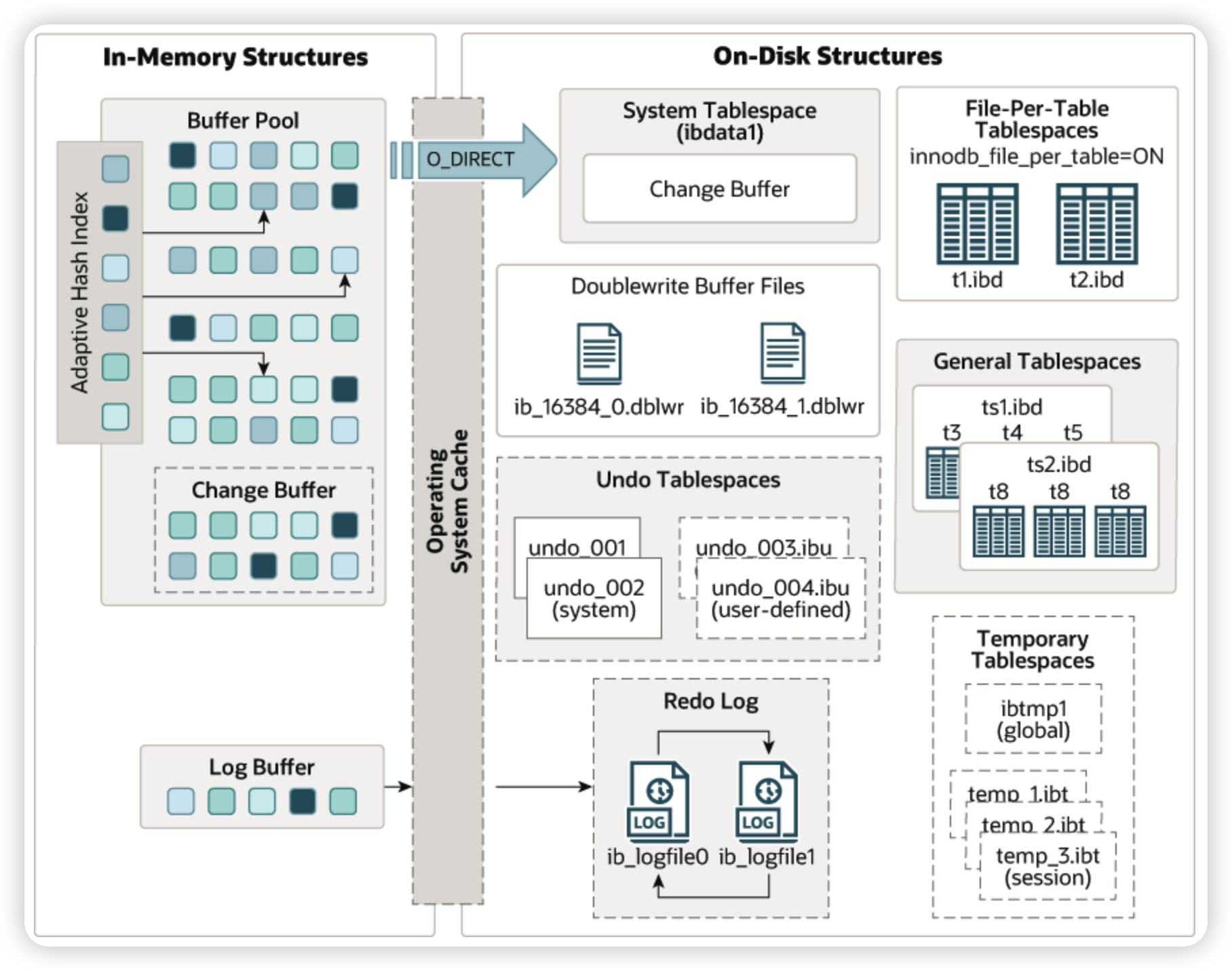
大体的架构我更推荐直接去看MySQL的官方文档
从上面的架构图中,已经可以看到一些组件,如Change Buffer,Adaptive Hash Index,Undo TableSpace等。在图上没画到的我们比较关注的还有数据的组织形式(这里只关注Btree,忽略Full-text search index和Geospatial index),并发控制相关的一些组件,如Lock Manager,元数据的存储Data Dictionary等。
下面简单介绍一下Innodb中的这些组件,看一下他们的作用,和其他组件的联动,以及他们的大概流程。
Interface
先从Innodb提供的接口来看MySQL的存储引擎都需要提供些什么功能
较为细节的语义以及更加全面的接口描述都在sql/handler.h中,这里我们只介绍最常用的一些,并且现阶段先关注DML相关的接口,DDL相关的概念之后再介绍
index_read,参数中会有一个Server层传入的search key,根据这个search key定位cursor,然后返回cursor指向的数据。一般用于点查的场景,或者用于范围查询的起点。index_next/index_prev,移动cursor,并返回指向的row。在innodb的实现中,cursor的移动都是通过general_fetch来做的,里面会传入移动的方向,以及匹配条件等。这里的接口虽然有cursor的概念,但是并没有一个参数用来保存cursor相关的上下文,所以Innodb的做法是将cursor藏到了请求的上下文THD中index_init,用于切换索引,因为索引选择实在Server层做的write_row/update_row/delete_row,写入相关,分别是插入,更新以及删除。其中Update是可以选择更新排序键的。这里的写入都是表语义的写入,即写入表中所有的索引。innobase_commit/innobase_rollback/innobase_xa_prepare,事务相关的在Server层用的是ha_commit_trans等接口。这里就是做事务的提交,回滚
Indexes
Each
InnoDBtable has a special index called the clustered index that stores row data. Typically, the clustered index is synonymous with the primary key. To get the best performance from queries, inserts, and other database operations, it is important to understand howInnoDBuses the clustered index to optimize the common lookup and DML operations.
- When you define a
PRIMARY KEYon a table,InnoDBuses it as the clustered index. A primary key should be defined for each table. If there is no logical unique and non-null column or set of columns to use a the primary key, add an auto-increment column. Auto-increment column values are unique and are added automatically as new rows are inserted.- If you do not define a
PRIMARY KEYfor a table,InnoDBuses the firstUNIQUEindex with all key columns defined asNOT NULLas the clustered index.- If a table has no
PRIMARY KEYor suitableUNIQUEindex,InnoDBgenerates a hidden clustered index namedGEN_CLUST_INDEXon a synthetic column that contains row ID values. The rows are ordered by the row ID thatInnoDBassigns. The row ID is a 6-byte field that increases monotonically as new rows are inserted. Thus, the rows ordered by the row ID are physically in order of insertion.Indexes other than the clustered index are known as secondary indexes. In
InnoDB, each record in a secondary index contains the primary key columns for the row, as well as the columns specified for the secondary index.InnoDBuses this primary key value to search for the row in the clustered index.
Innodb中,二级索引包含了主键,并且主键的要求是唯一且不为NULL(貌似内部代码实现中是允许null的)。
Innodb在写入的时候,不会原地更新二级索引,只会有对二级索引的删除和插入。由于二级索引中包含了主键,并且主键也会参与到二级索引键的排序中,所以如果两个Row具有相同的索引值,他们在二级索引中是通过两行来分别指向的。
虽然二级索引没有唯一性约束,但是拼接上主键后使得物理上的Btree也有了唯一性,可以简化很多的实现,这块在Database System Concept中也有所讨论:
A major problem with both these approaches, as compared to the unique searchkey approach, lies in the efficiency of record deletion. (The complexity of lookup and insertion are the same with both these approaches, as well as with the unique search-key approach.) Suppose a particular search-key value occurs a large number of times, and one of the records with that search key is to be deleted. The deletion may have to search through a number of entries with the same search-key value, potentially across multiple leaf nodes, to find the entry corresponding to the particular record being deleted. Thus, the worst-case complexity of deletion may be linear in the number of records.
In contrast, record deletion can be done efficiently using the unique search key approach. When a record is to be deleted, the composite search-key value is computed from the record and then used to look up the index. Since the value is unique, the corresponding leaf-level entry can be found with a single traversal from root to leaf, with no further accesses at the leaf level. The worst-case cost of deletion is logarithmic in the number of records, as we saw earlier.
Due to the inefficiency of deletion, as well as other complications due to duplicate search keys, B + -tree implementations in most database systems only handle unique search keys, and they automatically add record-ids or other attributes to make nonunique search keys unique.
Btree的结构在这篇文章中有比较详细的介绍,这里简单看几个图
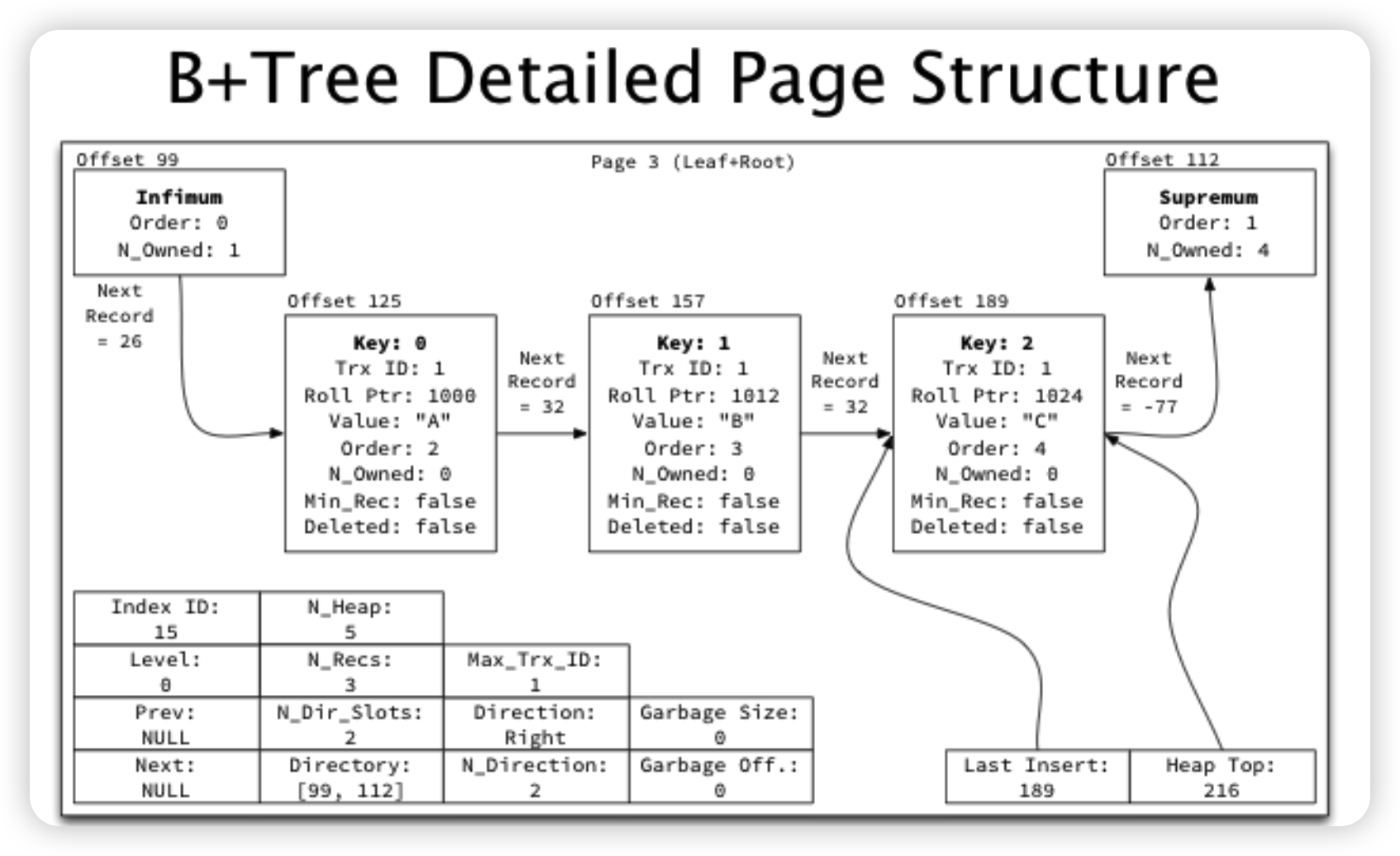 有关Page内结构这里更推荐去看一下MySQL是怎样运行的
有关Page内结构这里更推荐去看一下MySQL是怎样运行的
- 若干行会被划分成一个chunk/group,Page内是由chunk/group连接起来的块状链表
- Page内会有两个特殊的记录,Infimum/Supremum,表示上界和下界
- 为了快速二分,Page内会记录每个chunk的位置,称为Page Directory/Slot
- 在搜索的时候,会先通过Page Directory做二分,定位到某个group,然后再在group内做线性搜索
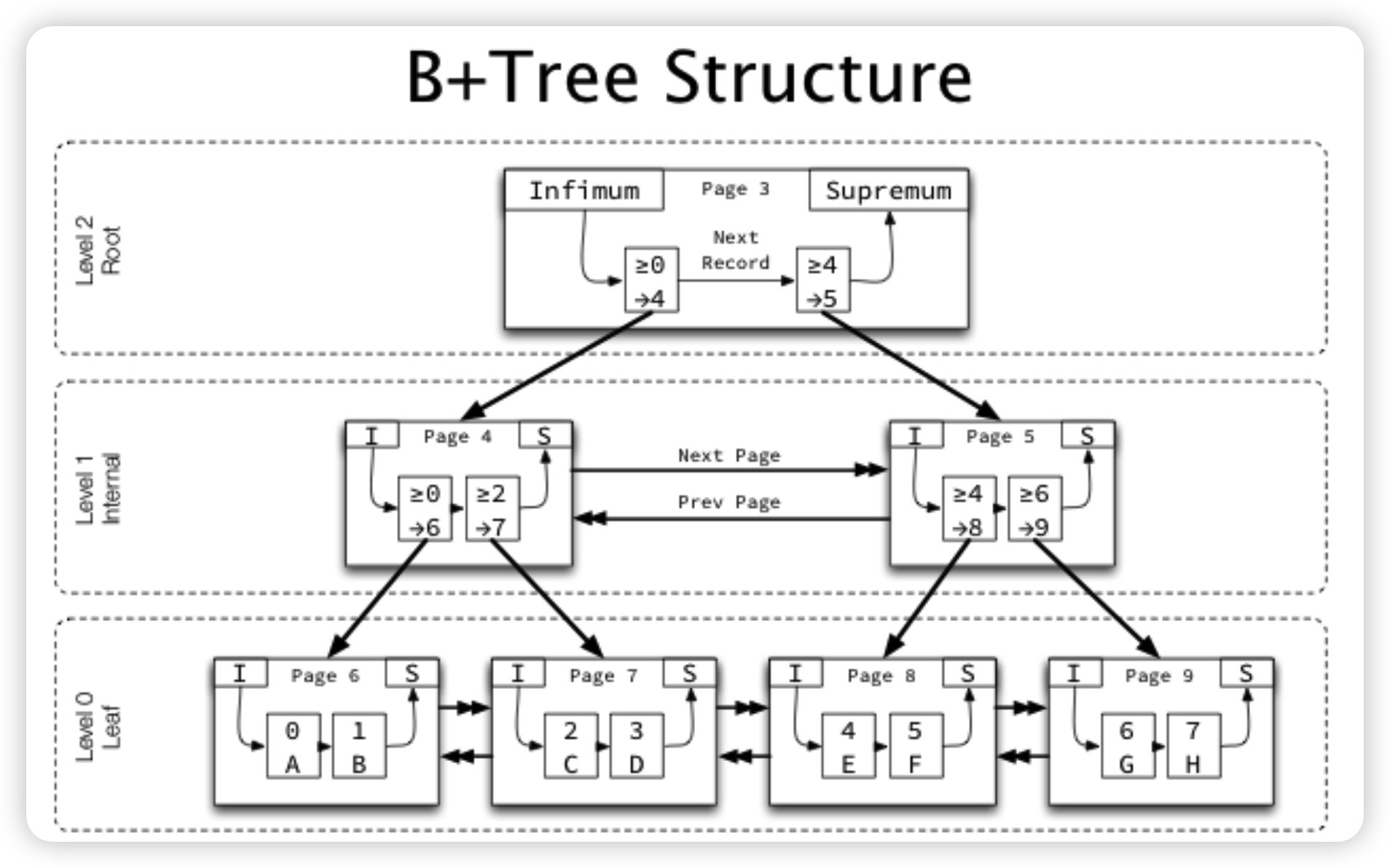
整体Btree的结构:
- 叶子结点为level 0,每往上一层level + 1。所以可以快速通过root上的level来判断这个Btree有多少层。
- 非叶子结点的每一项的Key为对应子节点中最小的行的Key(排序键),Value为对应子节点的PageID。
- 每一层的Page都会通过双向链表连接,其中只有叶子结点这一层才会通过双向链表加速读取,非叶节点的双向链表不会在搜索的时候使用
- 因为Btree每一层所需要覆盖的都是整个值域,所以每一层最左边节点所负责的值域是一个类似负无穷到x的形式。比如上图中的Page 4,实际上Page 6并不是只负责大于等于0,小于2的这段区间,而是小于2的所有值。为了处理这种情况,Innodb在每一层的最左边的行上面标记了
min_rec,在比较的时候,如果发现这一行被标记了min_rec,就会认为他小于一切值,而不会去比较具体的排序键。
Lock & Undo & Redo
在开始介绍写入之前,有几个写入链路上需要知道的背景知识,主要就是锁,Undo Log,以及Redo Log。
在不考虑事务/RDBMS对外提供的语义的时候,单纯的内存中的Btree + Latch Coupling可以简单的看作是并发安全的Btree。并没有唯一性约束(Consistency, ACID中的C),原子性,持久性等事务相关的性质。而这几个组件,就是辅助Btree,从而构成能力更强的具有事务能力的表语义接口。
Innodb中虽然有MVCC保证Repeatable Read,但是对于一些Select for update的场景,需要保证读取最新的数据。这时候就需要有锁来参与。Innodb不仅实现了最经典(也是最基础)的基于行锁的2PL,为了避免Phantom Read,Innodb也实现了一套Predicate Lock。Database System Concepts中介绍了Predicate Lock可能的实现,比如锁住Btree的节点,或者是锁住KV,Innodb中使用的就是基于索引中KV的Lock——Innodb的每个锁都是和Btree中的一行强绑定的。
Innodb有一个Lock Manager,可以简单看作是一个哈希表,哈希表中记录了每个锁当前由哪些事务持有,以及哪些事务在等待哪些锁,之所以说Innodb中的锁和数据强绑定是因为这个哈希表的Key并非是数据的排序键,而是PageID, HeapNo,每条数据在Page中都会被分配一个HeapNo,可以理解为是Page内的RowID,当这个数据被删除/移动的时候,他所对应的PageID, HeapNo也会发生改变,LockManager中的对应项的锁也就会失效。
为了实现Predicate Lock,Innodb引入了Gap Lock的概念,即锁住某一个区间,这个区间和Btree的结构也是强绑定的。Gap Lock的引入主要是为了防止在Gap中发生插入操作,导致Phantom Read。所以在Innodb中Gap Lock只会于插入操作所携带的锁Insert Intention相冲突。举一个防止Phantom Read的例子:
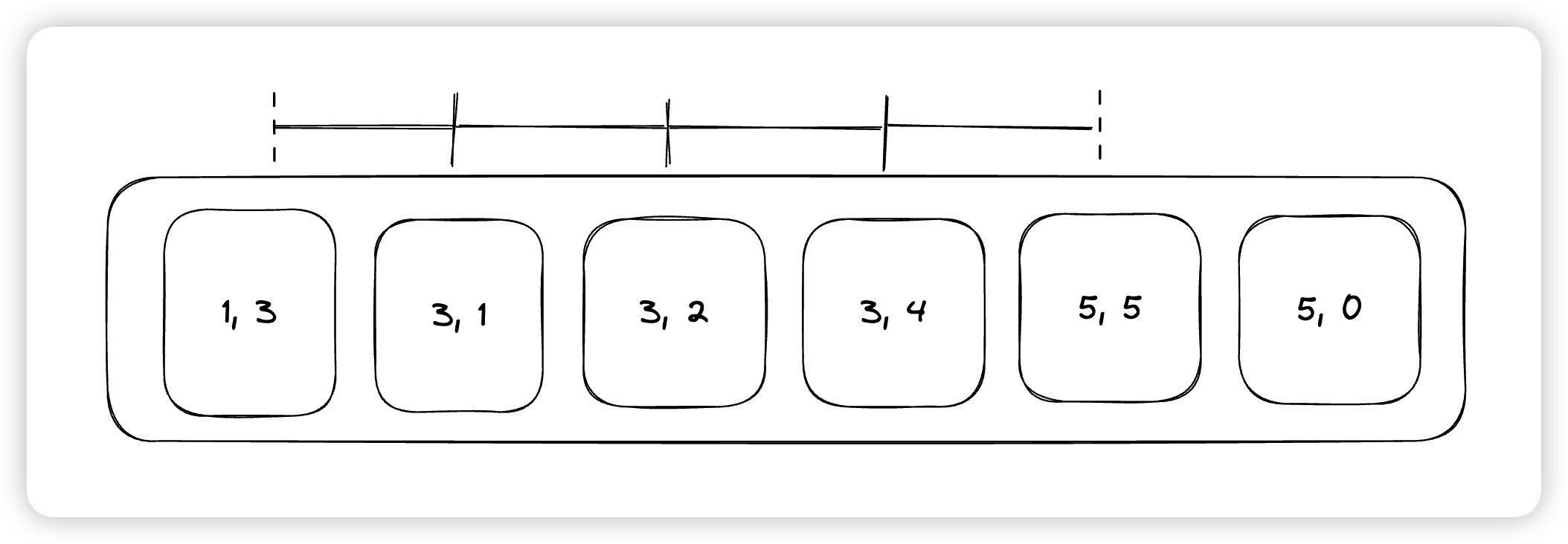
Innodb中的锁类型主要有四种,Rec not gap, gap, ordinary, insert intention。其中Rec not gap代表是单纯锁一个行,gap表示的是锁这一行前面的这个区间,比如上面的(5, 5),如果上Gap,则是锁住了(3, 5)这段区间,ordinary是rec not gap和gap的结合版,有的时候也被称之为next key lock。最后insert intention则是插入的时候用的锁,用来和gap lock互斥。
A next-key lock is a combination of a record lock on the index record and a gap lock on the gap before the index record.
这里虚线代表的是开区间。比如我们本次希望插入一个值为3的索引项,就会在二级索引中搜索,将上面的含有3的record都加上LOCK_ORDINARY,然后在最后一个(5, 5)上加LOCK_GAP,表示只锁最后的[3, 5)这段区间。这样就可以锁住所有的可能插入3的位置。
说完Lock来看一下Undo,Undo在Innodb中还是比较关键的,个人认为主要有三个作用:
- 保存旧版本。可以看作是
An Empirical Evaluation of In-Memory Multi-Version Concurrency Control中的Delta Storage
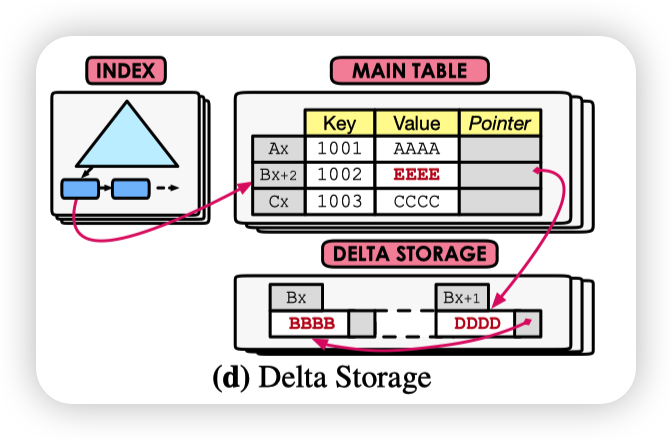
- 记录本次事务的修改(逻辑操作),用于在事务Abort的时候做回滚操作
- 记录未提交的事务。所有提交的事务都会在Undo中进行标记。所以在宕机恢复的过程中,我们可以通过扫描Undo来获取所有未提交的事务,选择将其回滚或者交给上层决策(Binlog/XA场景)
上面说的这三点实际上都可以单独成为一个模块去实现:
- 比如多版本可以引入单独的一类Page,或者直接塞到主表中(类似PG)
- 逻辑的Undo可以通过
Begin/End操作带上操作信息和RedoLog放到一起(类似ARIES) - 可以将事务状态表持久化到checkpoint中 + Redo阶段来恢复出未提交的事务(类似ARIES)
Innodb能够将这三个放到一起也是非常牛逼了。。
有关Undo的写入/读取/删除操作在下面会介绍。
然后是Redo,Innodb的Redo是从ARIES中介绍的物理逻辑日志,即日志记录的是针对每个Page的逻辑操作(为了性能还是有一些纯物理操作为),幂等性通过Page上的LSN来保证。
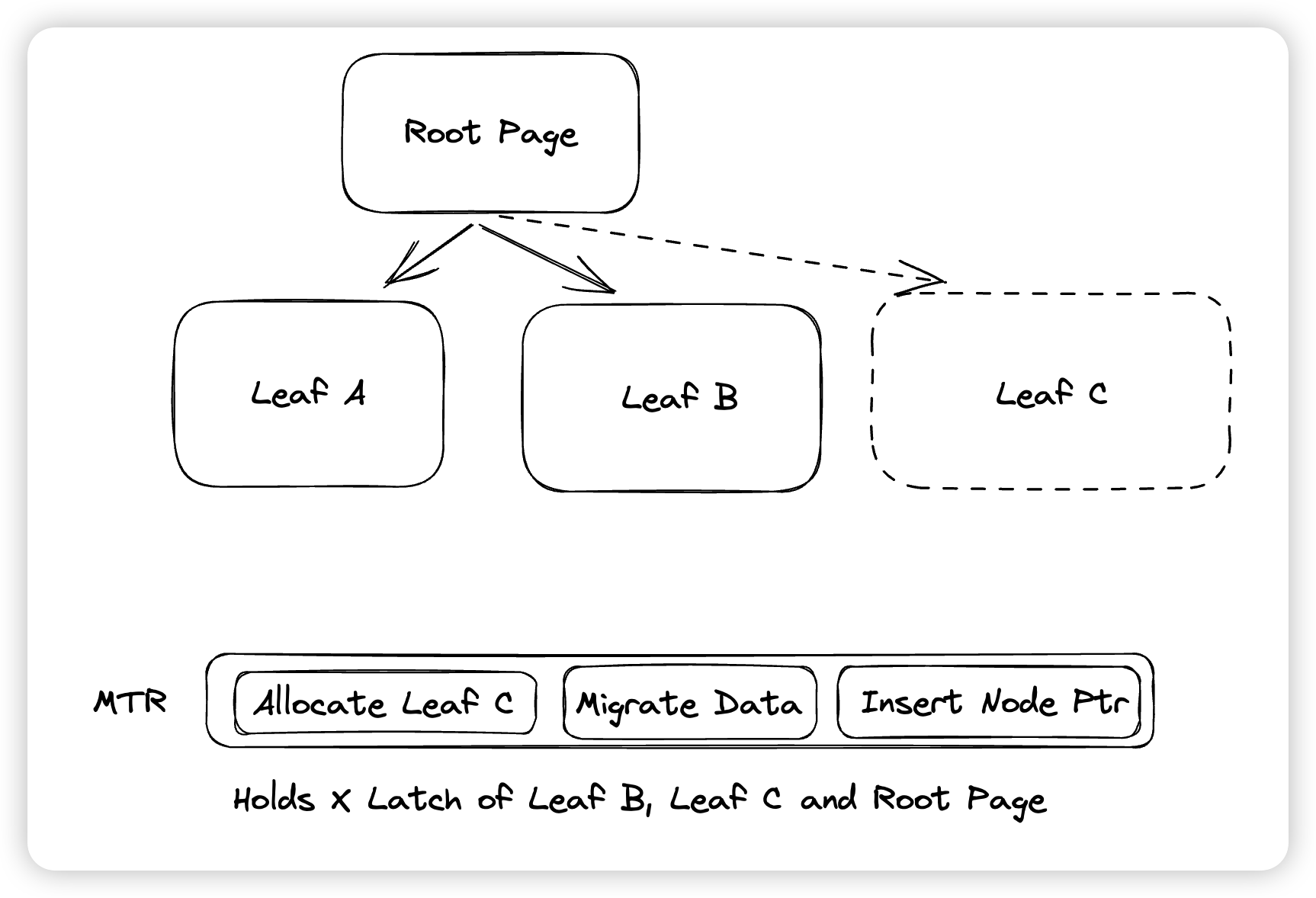
Innodb在Redo之上构建了一层Mini transaction的概念,在一个Mini transaction中,所有的写入都是原子的,并且Mini transaction是Redo Only的,不需要Undo来保证原子性。在实现上,这是通过上面提到的Begin/End机制来做的,在Recover阶段,每个Mini transaction(后称MTR)只有在解析完全后才会重放,即Innodb不会重放一个日志不全的Mini transaction。Innodb的每个操作都是由一个个的MTR所组成的,MTR的引入简化了很多内部修改物理结构的代码,这样我们就不需要考虑,假如某个事务触发了Btree的分裂以及Extent的分配,这个事务回滚的时候要怎么办的问题了。
MTR不仅有原子写入的保证,他还确实有事务的性质。这是因为Innodb中的Latch都会受到MTR的保护,比如某次SMO操作,MTR中不仅会记录这次SMO操作所修改的数据对应的redo log都有什么,还会持有这些被修改的Page的Latch,防止这些数据被其他人修改。在最后提交MTR的时候,Innodb会将redo log放到log buffer中(不会等持久化),并释放掉MTR所保护的Page,这实际上就是SS2PL(Strong Strict Two Phase Locking)的实现。
这里还需要提的一点是,Innodb的实现将Undo和Redo分离开并不是没有理论依据的:
- Transaction T ienters the commit state after the
log record has been output to stable storage. Before the
log record can be output to stable storage, all log records pertaining to transaction T i must have been output to stable storage. Before a block of data in main memory can be output to the database (in nonvolatile storage), all log records pertaining to data in that block must have been output to stable storage.
This rule is called the write-ahead logging (WAL) rule. (Strictly speaking, the WAL rule requires only that the undo information in the log has been output to stable storage, and it permits the redo information to be written later. The difference is relevant in systems where undo information and redo information are stored in separate log records.)
严格说,Undo本身的落盘时机和Redo就不同,其写入Pattern以及格式也和Redo不同。所以分开存储还是非常合理的。
写入
从上面的接口也看到了,Innodb中提供的表语义的写入分别有插入行,更新行,以及删除行。这一节看一下这些接口最终是会被转化成什么样子的操作并被持久化到磁盘中的。
先看一下表语义到索引这一层,Innodb都做了哪些事,这里以Insert举例,在代码中是row_ins_step
- 对表上IX锁(锁相关的等下介绍)
- 根据每个索引的schema,生成对应索引的数据
- 将数据写入到索引中
即表这一层做的事情基本上就是将数据写入到不同的索引中
对于索引的写入则会区分是主索引的写入还是二级索引的写入,对应到代码中则是row_ins_clust_index_entry和row_ins_sec_index_entry
在真正决定写入Btree之前,这里还会做一下判重 + 上锁:
- 根据排序键定位到插入位置之后,检查一下是否有重复
- 如果存在重复,要先对重复的行加锁。这里是行锁(而非Gap锁)
- 上锁成功后,检查这个行是否被删掉。如果没有,说明是一次重复的插入,则会返回Duplicate。
- 对于主索引来说,直接定位具体的行,然后在上面加锁即可。
- 对于二级索引来说,判重只会发生于索引有唯一约束的情况,这里会遍历所有可能导致重复的行,在上面加
LOCK_ORDINARY类型的锁。这个含义是锁当前的record,以及这个record之前的gap。需要注意的是这里还有最后一个GAP也需要锁上。
判断完成后,就会进入到Btree的写入流程中了,这里主要是btr_cur_optimistic_insert以及btr_cur_pessimistic_insert这两个函数进行Btree的插入
在写入的第一次,Innodb会尝试进行乐观的写入,即在Btree下降的过程中,会获取路经上节点的S Latch,以及叶子节点的X Latch。并且在定位到叶子结点后,会释放路经上的S Latch。这里乐观的含义是说认为本次写入不会触发SMO,所以不会获取路经上可能触发SMO节点的X锁。这里还会获取Btree的S锁。
写入的大概流程就是:
- 先判断是否可能触发SMO
- 对目标点加上INSERT_INTENTION锁(严格来说这里是LOCK_GAP | LOCK_INSERT_INTENTION,这里还有点说法,会在后面的细节介绍中提到)
- 加锁成功后,写入Undo,获取Undo log的指针,即Rollback ptr。
- 执行Page上数据的写入,并将trx id/rollback ptr也记录到数据中,这里也会将对应操作的Redo log记录到MTR中。
如果本次判断可能发生SMO,则会放弃乐观插入,转而进行悲观写入。这时候在Btree下降的过程中,会获取路经上可能触发SMO的节点的X Latch,以及Btree的SX锁。在level 0层,会获取叶子结点,以及他的两个兄弟节点的X Latch。即SMO与SMO不并发,但是SMO与写入可以并发。
这里下降到Leaf node之后,会尝试进行SMO,并且会根据当前Page类型的不同走不同的路径。对于Root的分裂,走的是btr_root_raise_and_insert,而对于非root节点,则是btr_page_split_and_insert。
SMO的流程为:
- 判断分裂方向,以及分裂的边界。Innodb中有50/50,0/100两种分裂策略,这里会判断如果本次插入的位置是在上次插入的右侧,且在最后,则说明workload可能是向右插入。这时候可以直接分配一个新的页出去,来减少未来SMO的次数,也降低了碎片率。
- 创建新的Page,这里会给一个hint page id,因为Innodb中page id如果连续,那么在物理存储上也是连续的,这里希望创建出来的新页和老的页在物理空间上是连续的,这样可以减少随机IO。
- 将新的节点注册到父亲节点中,这里可能触发级联的SMO
- 根据分裂边界,将数据搬移到新分配的兄弟节点中。
这里SMO之所以会区分当前是否是根节点是因为Innodb不会修改一个Btree的Root Page的PageID。如果都复用一套流程的话,在分裂根节点的时候,会创建一个新的根节点出来。这里Innodb的做法是,先创建一个空的子节点,将原本根节点的数据搬移到空的子节点中,然后再对子节点进行分裂。
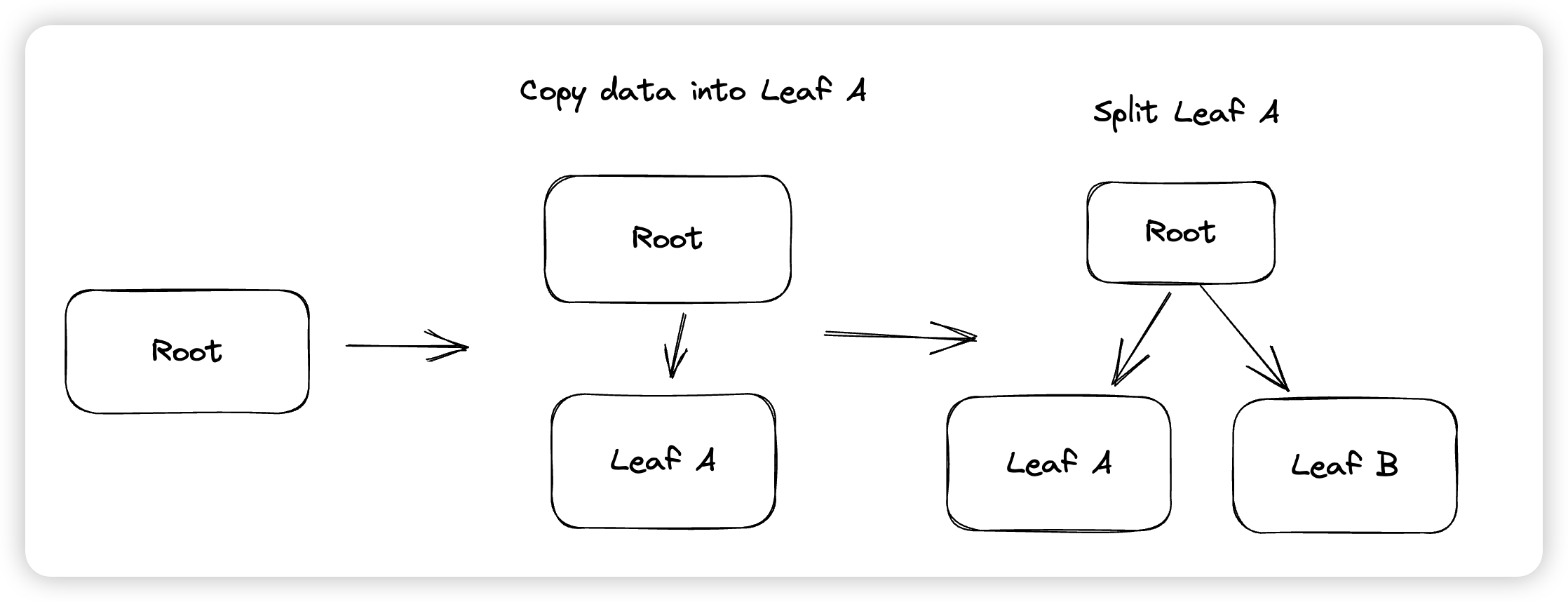
回顾SMO的流程,可能比较令人费解的是为什么Innodb在做Btree下降的时候没有使用Latch Coupling,而是Latch住路径上的所有Page,到叶子结点才释放。这里涉及到Innodb的一个优化(btr_insert_into_right_sibling),在Innodb发现某个节点要分裂的时候,为了避免触发SMO(新Page的申请),他会判断,如果导致分裂的这次Insert插入的是某个Page的最后一个位置,他会尝试直接将本次要写入的数据插入到右兄弟中,由于这个操作实际上修改了右兄弟负责的Key Range,所以他会更新右兄弟的父亲节点的指针。
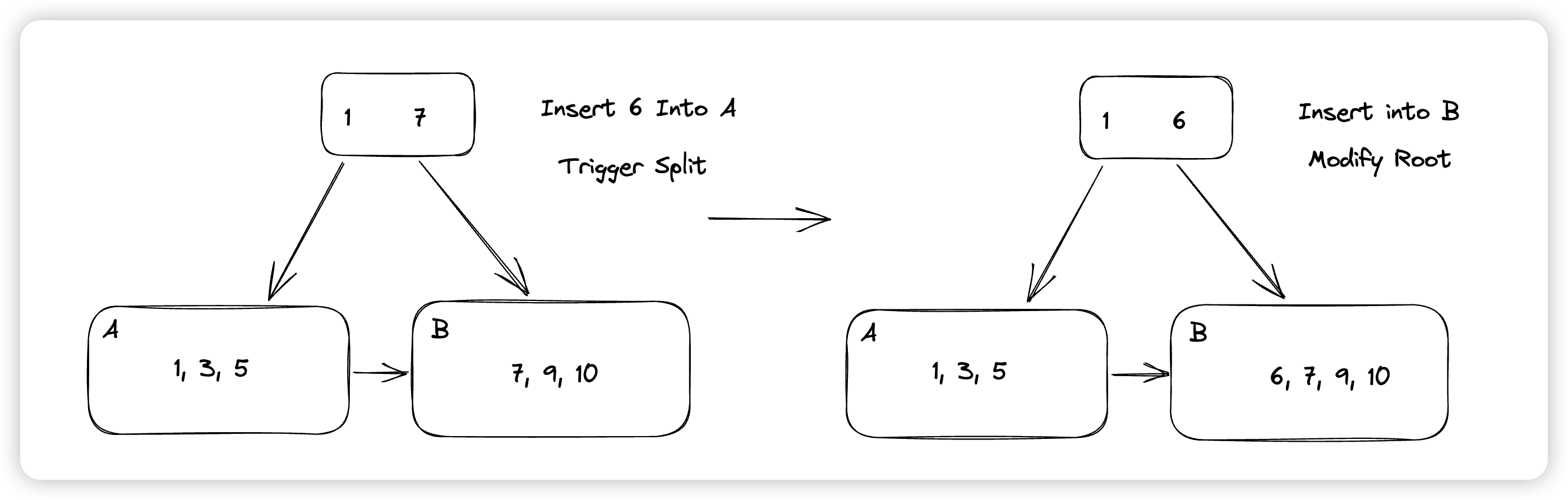
但如果我们的树结构是这样的:
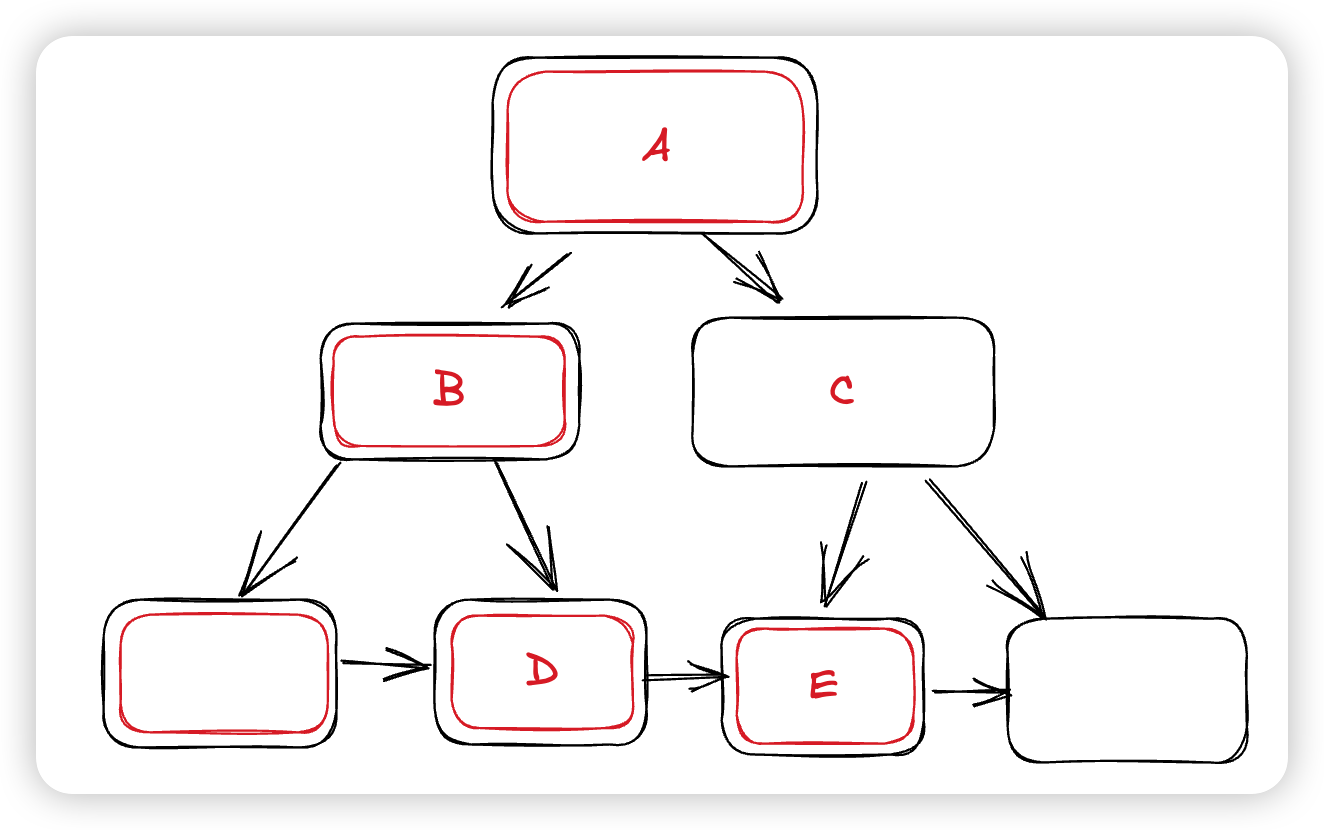
这次悲观插入在下降的时候上锁的Page是图中红框的部分,如果触发了上述优化,这里会尝试将数据插入到E中,并修改C的指针,这里也就需要获取C的锁。注意这种从下到上的获取Latch是不符合Latch Order的,即有可能触发死锁。为了避免死锁的发生,Innodb做出的决策是,希望X Latch住一个Internal Page的时候,表示的是这个子树都没有其他的修改,具体做法是:
- 在悲观写入Btree下降的时候,会锁住目标节点和其右兄弟的LCA,比如上图中的D/E的LCA是A,这里就会在下降的时候锁住A,因为这次写入可能导致修改C,进而导致修改A。
- 如果正常写链路仍然是Latch Coupling,这里可能出现有一个线程在C,要获取E的锁。另一个线程在E,要获取C的锁。所以为了让锁住LCA这个规则有用,还需要正常的下降链路获取路径上的所有锁,这样锁住LCA才相当于锁住整个子树,才能防止发生死锁。
这样一次偏细节的写入流程就介绍完了,下面简单介绍一下其他操作(Update/Delete),以及二级索引的处理:
- Innodb的二级索引的排序键包含了索引项,以及主键。并且没有MVCC的功能,版本链(Rollbackptr)只被保存在聚簇索引的行中。在读取的时候,如果定位了二级索引,需要根据记录的主键回表查找聚簇索引。
-
Innodb不会原地更新一个二级索引项,而是总通过Delete & Insert的方式更新二级索引。这是因为,如果一次修改没有修改到某个索引项,那么Innodb会跳过对这次二级索引的修改。如果某次更新修改了一个索引项,那么对于二级索引来说是更新了排序键,所以也是用Delete & Insert处理。
- MySQL貌似没支持可以指定部分排序键,然后含有全量数据的二级索引。他对Covering index的定义为:
-
covering index
An *index* that includes all the columns retrieved by a query. Instead of using the index values as pointers to find the full table rows, the query returns values from the index structure, saving disk I/O.
InnoDBcan apply this optimization technique to more indexes than MyISAM can, becauseInnoDB*secondary indexes* also include the *primary key* columns.InnoDBcannot apply this technique for queries against tables modified by a transaction, until that transaction ends.
- 对于一个多版本的系统来说,我们在执行删除的时候不能直接把这一行从表中移除,而是留一个Tombstone,只有能保证没有其他人可以看到这个Tombstone之前的版本的时候,才能删除Tombstone。否则版本链会断开,导致并发的事务无法看到删除前的老版本。
- Innodb中,Tombstone是通过在数据行上面标记一个Delete mark。用户的写入请求不会导致真正的删除,只会标记一个Delete mark。
- Innodb的Purge system会识别出那些老版本没有被其他人使用了,并对被delete mark的版本做真正的删除。
- delete mark可能会对其他链路有一定的影响,比如删除一行后立刻再插入相同的一行。这时候聚簇索引上的delete mark的版本还没被删除,这时候插入操作会被转化成一次Update操作
row_ins_clust_index_entry_by_modify,通过更新实现插入。 - 上述delete mark相同的逻辑也会发生在二级索引中:从这里的例子也可以看出,二级索引和聚簇索引不是一一对应的,这里一个二级索引的一项就对应了3个版本。
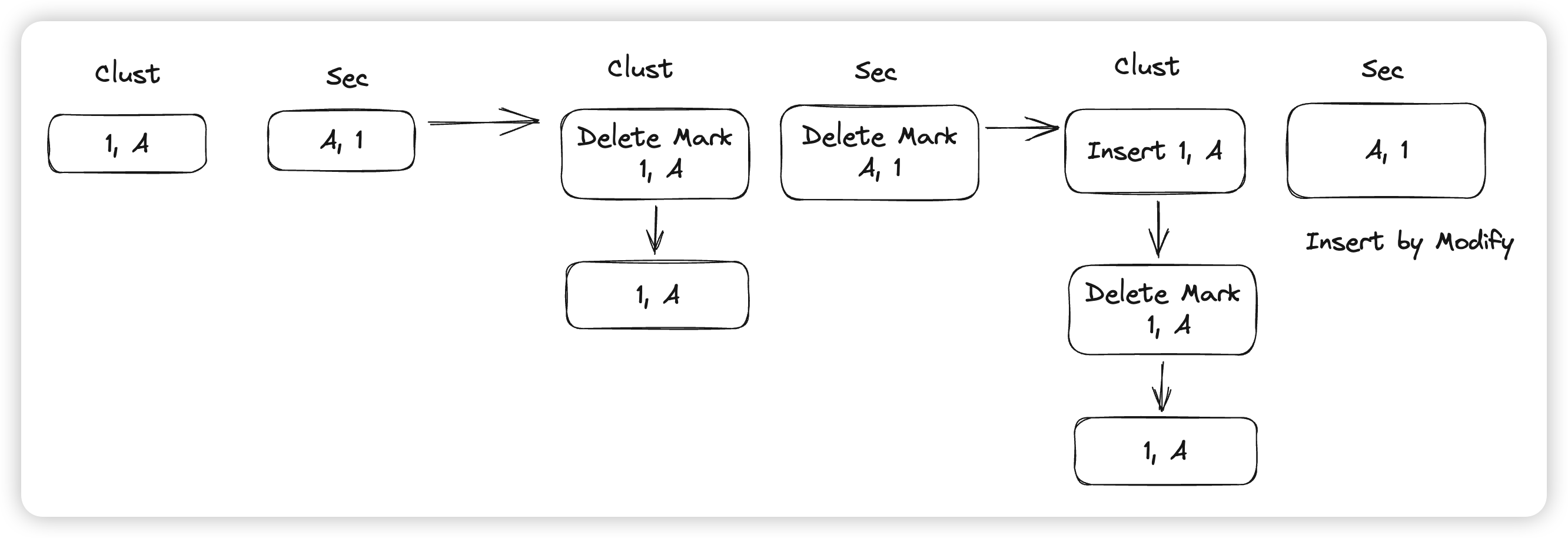
-
对于聚簇索引的更新操作,Innodb为了优化,有几种情况:
- 更新排序键:通过Delete & Insert
- 不更新排序键,新版本的数据大小小于等于老版本,这时候不会触发数据移动,即原地更新。
- 不更新排序键,新版本数据大小大于老版本,这时候不是Delete & Insert,而是直接把老的行删掉,然后插入一行新的。否则如果只是留一个delete mark,就会导致Btree中出现具有相同排序键的row。
简单介绍一下在上面架构图中看到的两个优化:
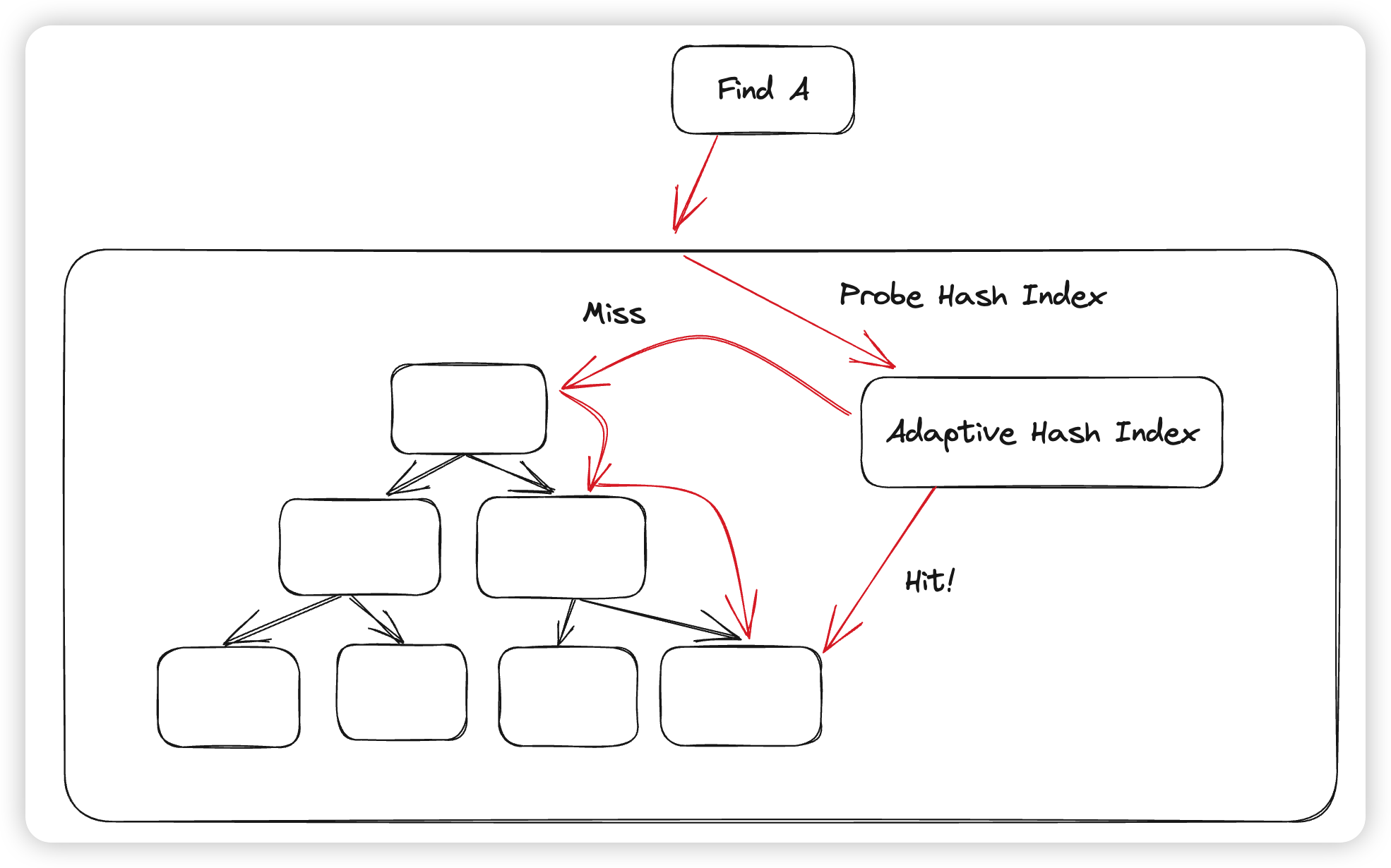
- Adaptive Hash Index:这个是用来减少Btree下降开销的优化,大概思路就是,发现某个Block访问的比较频繁,与其每次访问的时候都去读Page,做二分,再访问子节点,不如直接通过一个哈希表进行O(1)的定位。这样无论是复杂度还是执行的代码逻辑都有所下降。这里Innodb的做法就是通过维护统计信息,发现某个block可以通过哈希进行加速访问的时候,就将这个block内的数据放到一个哈希表中,在Btree下降的时候,会查一下哈希表,如果哈希表查找失败了,才会fallback到Btree的正常下降链路。
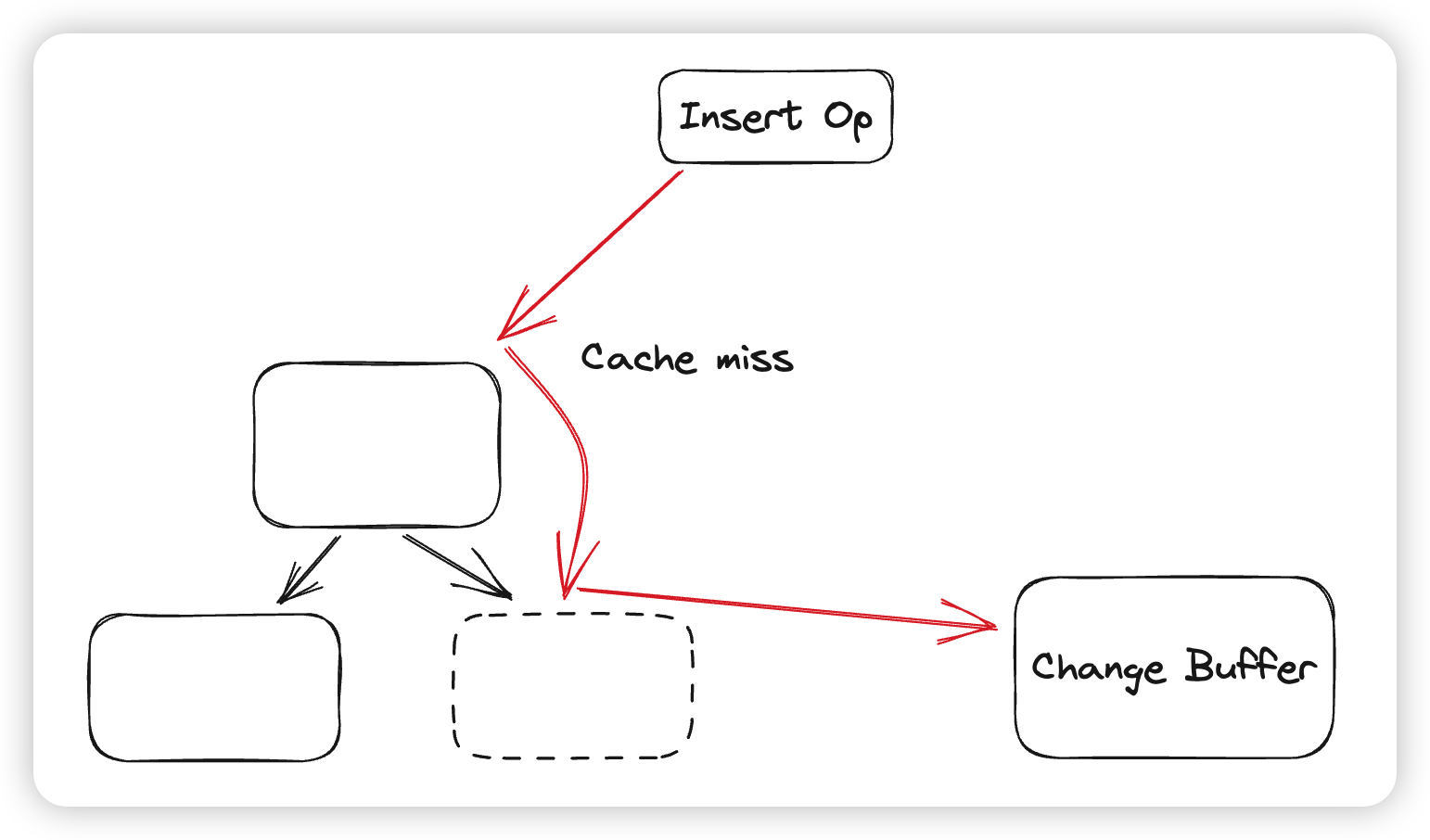
- Change Buffer:Change Buffer的作用是缓存写操作,因为二级索引的写入通常带来大量的随机IO,导致性能不佳。又因为在写入Btree的时候,部分情况下不需要有一致性判断(写入必定会成功),比如在插入二级索引的时候,不需要考虑重复,因为主索引一定已经插入成功了。Innodb为了避免二级索引的写入导致的随机IO,会在二级索引页Cache miss的时候,将数据缓存到Change Buffer中。在读取某个Page的时候,会先判断这个Page是否在Change Buffer中有被缓存的操作,如果有就先重放,完成后才会将Page返回给上层。Change Buffer会被组织成一个Btree,Key就是PageID,Value则是被缓存的PageOp。
在一次写入完成后,为了保证这个写入最终有效,我们还需要提交对应的事务:
- 将Innodb的trx id从活跃事务链表中移除,这样后续事务获取的ReadView就可以读到当前事务的变更
- 放锁,并唤醒等锁的事务
- 在Undo中标记事务已经完成。这样在崩溃恢复的流程中才不会回滚这个事务所做出的修改
- 最后,获取最后写入的lsn,然后等待这个lsn的日志落盘。(WAL的要求)落盘后,就可以认为事务提交并返回给用户
读取
读取核心的入口就是index_read和general_fetch,具体的逻辑主要在row_search_mvcc中,通过index_read进行第一次定位,然后通过general_fetch进行cursor的移动。
- 这里会根据当前的读模式进行上锁,比如对表上IS/IX锁。或者是通过MVCC读,则获取read view
- 定位Btree的cursor,这里有三种情况。如果是一次cursor的移动,会走恢复cursor的流程。如果是一次带有Search tuple的定位,会从Btree中搜索这个search tuple。如果没有search tuple,则是会将指针定位到Btree的一端边界处。
- 定位到cursor之后,开始根据匹配条件定位到第一个符合条件的row,比如EXACT匹配模式,会比较search tuple和cursor指向的数据,还有EXACT_PREFIX做前缀匹配。
- 上锁。比如我们可能需要上一些next key lock来防止Phantom Read
- ICP(Index condition pushdown) check,检查下推下来谓词是否满足,可以减少MySQL Server与Innodb层的交互,以及回表的次数。如果Index condition不满足,则获取下一行数据,当前数据的处理流程就结束了。如果满足条件,则会开始判断可见性。
- 根据二级索引中记录的主键去聚簇索引中读取一个当前事务可见的老版本。
- 最后做一些预读,以及将Innodb的格式转化成MySQL的行格式,并返回给上层。
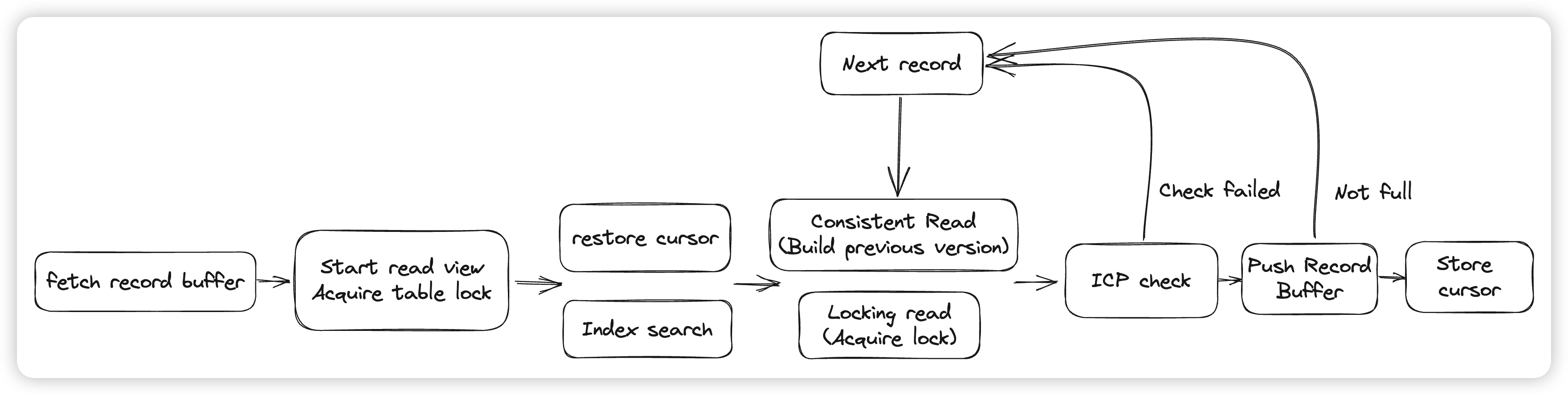
这里涉及到的优化点有几个:
- record buffer,对于一些连续扫描的case,Innodb会提前将一些数据存到record buffer中。这样后续再次读取的时候可以直接将数据返回给Server层,不需要再去做Btree的读取/上锁等操作。
- 虽然有record buffer,但是每次读取完如果都需要从Btree的root节点下降到Leaf,还是会有性能的损耗,Innodb希望可以减少Btree下降的次数。
- Innodb引入了一种cursor叫做persistent cursor,这里的persistent不是指cursor会被持久化的磁盘上,而是在多次MySQL Server与Innodb的交互中是持续存在的。大概机制为,读取数据完成后,通过pcur保存当前扫描到的位置,包括Page内的offset,Page Block等。然后在下一次读取的时候,会尝试直接读取上次保存的内存地址,判断modify clock是否发生变化,如果没变,说明Page还是之前的page,可以继续读取。如果变了,则fallback到悲观的restore,从Btree上重新下降。
- 因为回表本身的开销比较大,需要做Btree下降 + 读Undo,所以Innodb会在扫描二级索引时先进行Index condition的检查,而非先回表判断可见性,从而减少回表的次数
有关Btree cursor的移动:
- 因为Latch order是从左到右的,所以获取下一个页比较容易,直接Latch住下一个Page即可
- 对于逆序扫描的情况,Innodb有两种方式:
- 会先尝试乐观策略,这里会先Latch当前Page,读取前一个Page的PageID,释放当前Page的Latch,Latch住前一个Page,然后乐观读取当前Page,判断Modify clock没有改变,并且记录的Prev page不变,则认为移动成功。
- 乐观策略失败的时候,走悲观策略,从Btree根节点重新下降,搜索小于上一个读取的record的位置。
最后简单讲一下Innodb MVCC是怎么做的:
- 因为数据随时会被并发的事务修改,所以MVCC的核心在于如何获取一个Snapshot,使得后续在读取这个Snapshot的时候,数据是不变的。Innodb会为每个事务都赋予一个TxnID(trx id),用来唯一的标识一个事务,是全局单调递增的。因为读取的数据会受到并发事务的影响,那么我们只要保证所有并发的事务的变更都读不到即可
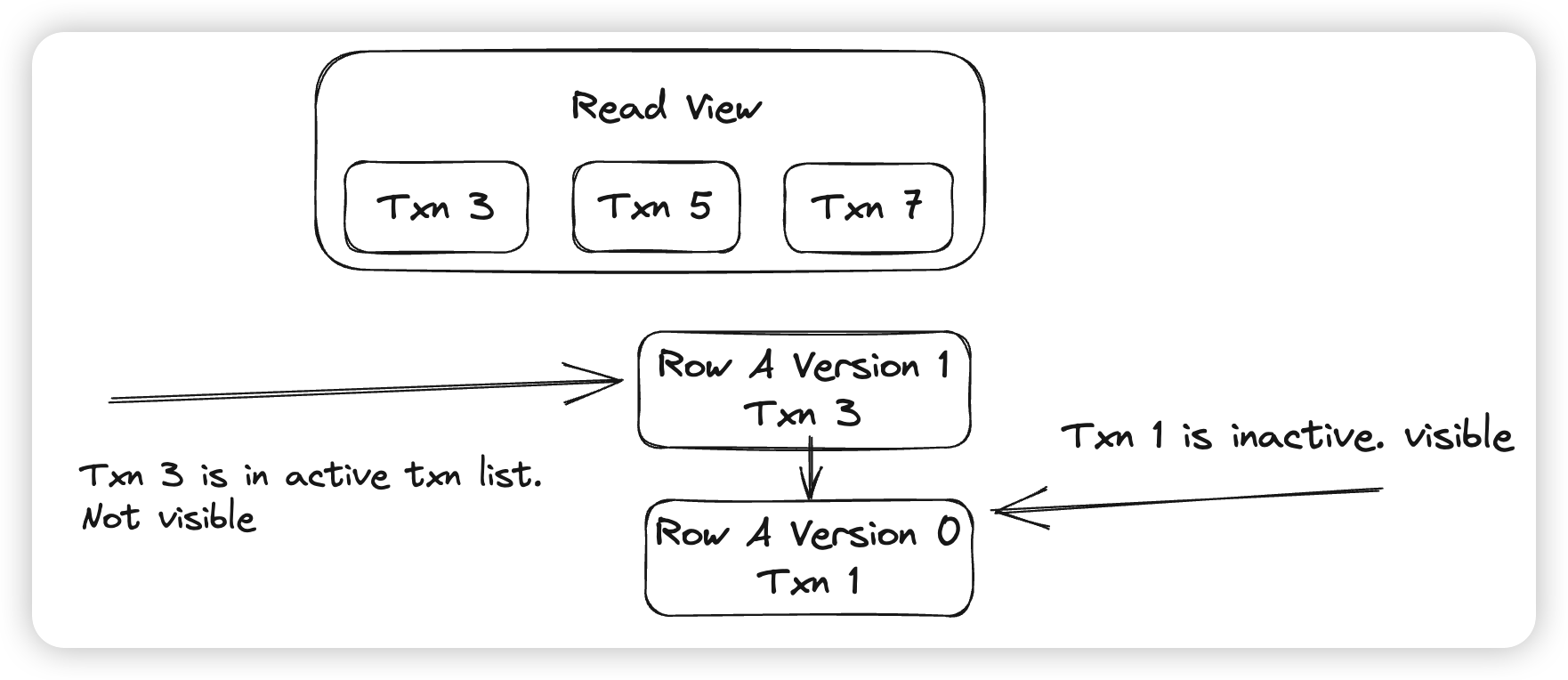
- 上面图中的ReadView就代表了一个Snapshot,他的含义是,所有TxnID小于3的事务都已经结束了,所有TxnID大于7的事务还未开始,在这之间的3,5,7这三个事务是活跃的,也就是不可见的。
-
所以在对某一个版本的数据判断可见性的时候,判断这个版本的创建者对当前ReadView是否可见即可。如上图中,会先判断Version 1的事务Txn 3是否活跃,这里会发现Txn 3是活跃事务,则会认为Version 1不可见,然后读取Version 0,发现Txn 1不活跃,则Version 0可见。
Reference
MySQL官方文档

文章评论