Efficiently Compiling Efficient Query Plans for Modern Hardware
Abstract
这个Abstract写的很清楚。现有的iterator model在执行的时候对locality,以及instruction prediction利用率很差。导致执行性能比不上hand-written的代码。即便是有vectorized tuple processing,只能缓解这个问题,但是性能还是不够。
本文提出了一种基于LLVM框架的将query翻译成机器码的方法。通过对于locality和instruction prediction的关注,从而获得可以和hand written code竞争的性能。
(如果他没有说LLVM可能就要先去看看LLVM相关的东西)
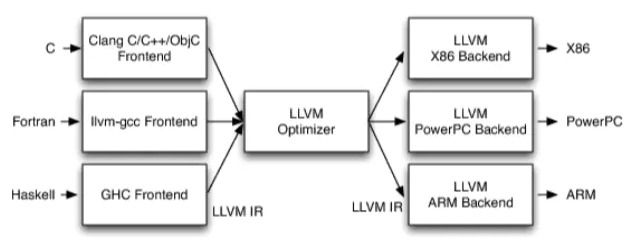
这个是llvm框架。具体的代码通过前端编译成统一的IR,然后优化,再根据后端从IR转化成对应的机器码。
可以大概猜测我们做的就是类似JIT,根据query生成llvm ir,然后llvm ir优化后生成为对应的机器码再执行。(或者可能执行是数据库模拟的虚拟机)
Introduction
传统的iterator模型就不介绍了,核心就是若干个实现了next的算子,不断递归调用
iterator model是从以前的I/O dominated的时候发展出来的,那个时候CPU开销不大。因为每次iterator的next调用都是通过virtual call实现的,从而降低了分支预测的性能。并且每一个tuple都需要一次函数调用,从而加剧了上面virtual call的performance downgrade。同时,这种模型要求维护很多信息,并且局部性不好。比如我们需要记录上一次扫描到字节流的位置等。
所以现代的系统中使用的是block-oriented,也就是一次处理一个block,多个tuple。从而均谈iterator model的开销。然而这种模型也削弱了iterator model的主要特点,也就是去pipeline data,即tuple流动的过程中不需要额外的拷贝。
(这里我的理解就是由于我们需要一个block一个block的传输数据,当operator要更改数据的时候,比如用过select筛掉一些tuple,或者join得到一些新的tuple的时候,我们需要重新构建这个block,也就是需要额外的拷贝来将tuple组装成新的block传给下一个operator)
然而block的好处还有就是我们可以利用向量指令来加速执行,也就是减少instruction count
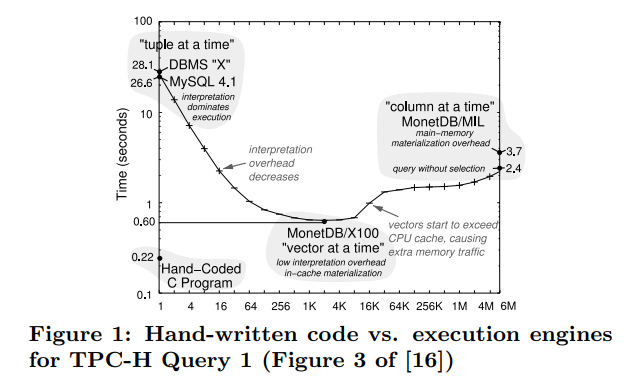
figure1中可以发现,hand written code很明显性能会好很多。关系代数算子模型对于多个查询来说很有用(因为比较generialize),但是对于单个查询内部,则表现的不好。(因为这种表示法可以简便的表示任意种查询,但是对于单个查询的性能,则没有好的保证。我个人感觉他说的是iterator model,或者说是这种算子表示法的问题)
他的核心点:
1. Processing is data centric and not operator centric. Data is processed such that we can keep it in CPU registers as long as possible. Operator boundaries are blurred to achieve this goal.
2. Data is not pulled by operators but pushed towards the operators. This results in much better code and data locality
3. Queries are compiled into native machine code using the optimizing LLVM compiler framework.
(核心在于是data centric,我们操纵的是data,而非实例化很多operator去pull data)
(他是用的现有的llvm framework,而非集成编译技术到query engine中)
Related Work
MonetDB会将所有的结果都物化,从而不需要重复调用operator function。对于OLTP system比较适用
MonetDB/X100会传一批数据。也就是block oriented
一些系统会将query编译成java bytecode,从而通过jvm执行。然而他们仍然在使用iterator model(我猜测可能是通过编译来避免虚函数调用)
HIQUE系统将query编译成C代码。他们为每个operator编写code template,然后生成C代码。并且他们通过物化结果来消除掉iterator model的影响,但是iterator的边界仍然十分清晰。(我猜测应该是利用编译技术来避免虚函数调用,然后通过物化结果才减少function call,以及去除其他的book keeping)。并且还有一个缺点就是生成C代码的开销比较高。
还有一些技术可以用来加速query processing。一个比较关键的就是去结合连接词谓词,比如AND,OR,来减少branching的数量。还有比如通过SIMD指令来加速评估谓词。
The Query Compiler
Query Processing Architecture
首先定义pipeline breaker:
An algebraic operator is a pipeline breaker for a given input side if it takes an incoming tuple out of the CPU registers. It is a full pipeline breaker if it materializes all incoming tuples from this side before continuing processing.
他这个定义是从寄存器角度来定义的。更加严格,也和他前面说的对应,从bottom up向上push数据可以拥有对寄存器的控制。
核心点就是我们会将数据传到内存的操作视为pipeline breaker。从而尽可能的让数据停留在寄存器中
iterator model每次的function call都会导致寄存器的内容被存到栈中。而block-oriented的方法虽然减少了function call,但是一个block肯定也不能存在register中。文章中提到:any iterator-style processing paradigm that pulls data up from the input operators risks breaking the pipeline
由于在提供iterator-based view的时候,我们需要提供一个linearized access interface。(这里我理解就是在为operator提供这种lineraized access interface的时候,这种pull data的操作需要额外的book keeping(比如栈,迭代器指针等),从而会导致breaking pipeline)
所以我们反转data flow control的方向。我们会持续push data到consumer operator中,直到遇到一个pipeline breaker。所以data is always pushed from one pipeline-breaker into another pipeline-breaker
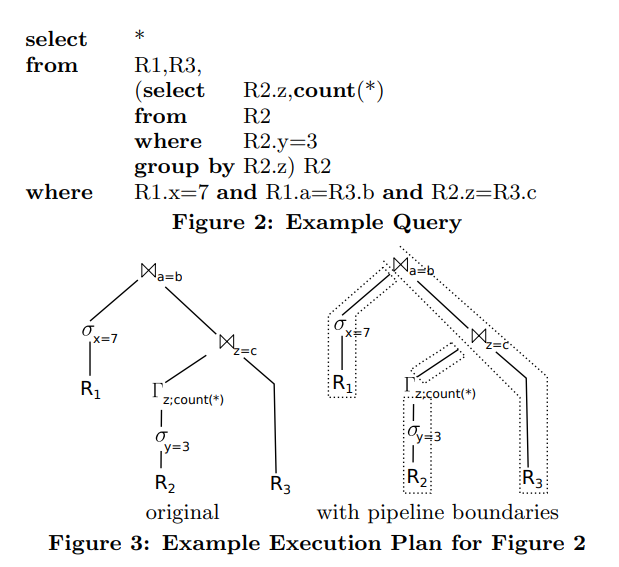
那个长的很像F的我后面就用F,是group by
从R2扫描元组,然后通过z去group by,再和R3的c去join。得到的元组再让R3.b和R1.a去join
去看一下这个过程中的data flow,我们可以发现tuple总是从一个materialized point到另一个。最上面的join,tuple会从一个materializaed state(scan of R1)移动到上面join的hash table中。
在figure3中是这些物化点

由于我们无论如何也需要这些物化点。所以我们将query编译成执行流在物化点之间的移动。在物化点内部则是pure CPU operation。
可以看到核心在于是以full pipeline breaker为粒度的执行。在代码段内部是full pipelined。并且是tight loop,对于数据以及代码的局部性利用的都很好。(因为如果让我们自己写代码,写出来的也是类似的样式)
(在iterator模型中这种物化也是必须的。但是他的思路是不根据operator来划分,而是根据materialized point来划分。根据operator划分的时候,我们的视角是tuple经由一个一个的operator流动,operator是控制的核心点。而根据materialized point划分的时候,则是整体的数据从一个物化点移动到另一个物化点,我们不需要关心这个过程中经过了多少的operator。这个思路很棒要多加体会)
下面一个问题就是我们要怎么将关系代数的执行计划转化成这样的代码段了
Compiling Algebraic Expressions
可以发现在figure4中的代码里,operator的界限是模糊的,没有了很明显的operator的概念了这里。
query execution code is no longer operator centric but data centric
这里划分的点是根据物化点来的,每一段代码处理的都是被物化点所分开的pipeline。然而一个operator的逻辑很有可能被划分到不同的代码段中,从而导致代码生成的难度增高。(比如join,我们需要一块代码段来生成哈希表,另一块去probe)
还有一个难点就是比如对于二元的pipeline breaker。选择物化左边的输入和选择物化右边的输入会有很大的不同(这里我感觉就是物化的那个输入就先处理,目前不太清楚有什么不同点)
虽然会复杂,但是这是优势而非限制。iterator model用了很简单的next call,但是代价就是virtual function call以及frequent memory access(我们需要不断的访问栈去进行函数调用)
我们会看到生成代码的逻辑也含有比较清晰的结构。所有的operator都有统一的接口。但是在生成代码之后,所有的细节都会被暴露出来。
(这里也是看待compile的一个观点,精妙的接口存在于编译期,然后编译器会帮我们生成高效的执行代码。而反观iterator model,他的精简也存在于execution engine中,从而导致我们没能利用query本身的结构。iterator model基本上是对plan的直接翻译,更贴合关系代数,逻辑实现简单。而query compile则是根据plan去利用他的内部结构,根据pipeline breaker划分,从而实现高效。)
每一个operator都有两个函数:
* produce()
* consume(attributes, source)
produce的作用是让operator去生成result tuple,然后会通过调用下一个operator的consume来push到下一个operator上。

figure5是一个简易的翻译映射。
比如对于figure3的plan来说。我们会首先调用最上面的join的.produce,根据figure5,join的produce是分别调用left.produce和right.produce。然后调用select的produce,select的produce会调用input的produce,即scan.produce。他会生成这样的代码:for each tuple in relation,然后调用parent.consume,即回到select的consume,他会根据谓词生成if语句,并调用parent.consume,回到join,这时候他会生成materialize tuple in hash table然后退栈回到之前的right.produce继续调用。
感觉思路上来说,produce有点像是代码生成的依赖,也就是调用他的依赖项去生成代码。而consume则是具体的生成逻辑。(一个问题是为什么不把consume的逻辑放到produce的后面呢?可能这样需要我们从parent中去跟踪tuple的格式,或者consume允许我们处理更加复杂的逻辑)
Code Generation
Generating Machine Code
现在我们讨论了如何将plan转化成伪代码,但是实际上需要我们编译成机器码来执行。最初是通过生成C++代码,然后传给编译器,然后再通过shared library加载进来并执行。由于HyPer本身是通过C++写的,编写成C++代码的好处就是他可以访问系统中的其他代码。然而缺点就是C++编译器比较慢(在数据库角度看),编译一个复杂的query可能需要几秒中。并且C++并不能含有完整的控制权(我们只能从高层角度去编写代码,但是不能控制底层寄存器级别的操作)
所以选择了LLVM compiler framework。并可以通过LLVM的JIT compiler来直接执行。LLVM隐藏了寄存器分配的问题,提供了无限制的寄存器数量。所以我们可以假定我们为tuple的每个属性都有一个对应的寄存器。从而简化了实现(否则我们需要自己处理寄存器分配问题)。并且由于LLVM是IR,我们不用担心翻译成machine code的问题。JIT compiler会帮我们处理这些。LLVM汇编器是强类型的,可以帮助我们找到很多隐藏的bug。LLVM的优化能力很强,可以生成很快的机器码,并且编译速度只需要几毫秒。(从llvm到machine code比较快,但是从C++到IR相对比较慢)
LLVM还可以让我们可以直接调用C++代码,并且C++也可以调用LLVM代码。
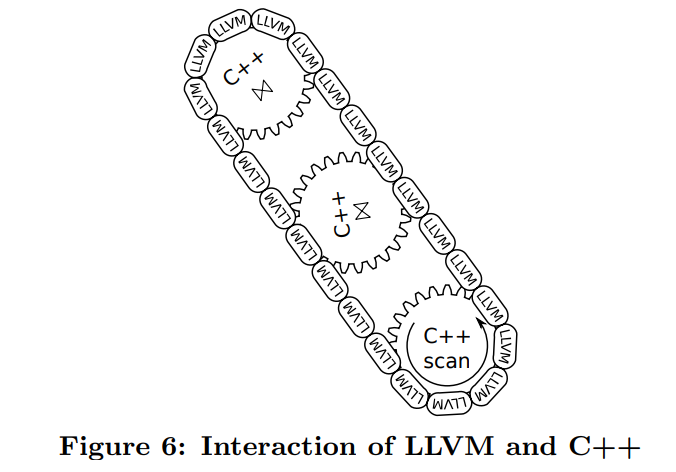
算子中复杂的逻辑,就是途中的齿轮,会被预编译。算子之间的连接是通过生成的LLVM代码实现的。这些LLVM chain是动态生成的。所以我们可以达到非常低的编译时间。
比如实现scan,我们需要定位数据结构,确定下一个要扫描的tuple等复杂逻辑是由C++实现的。但是tuple的处理,比如filter等是由LLVM实现的。
我们希望外部函数的调用尽可能的少,虽然将寄存器压到栈中会通常在cache内,但是当调用次数很多的时候仍然是一个不可忽视的开销。
(这里是一个trade off,我们希望编译时间短,同时有好的性能。用C++实现的复杂逻辑需要引入额外的函数调用开销。好处是我们可以减少编译时间,因为复杂逻辑的编译和优化都是预先执行的。我们只需要保证我们的执行路径主要在LLVM上,就可以忽略掉复杂逻辑的开销。从而实现高性能+快速编译。)
Complex Operators
虽然我们希望不跨越函数调用来执行query,但是这是不可能的,因为生成的代码会增长的非常快。在递归的情况下基本不可能消除函数调用。并且一些复杂的逻辑需要我们调用C++代码,比如sort,join等。我们只要防止在hot path上不要有函数调用就不会有大问题。
这里通过一个例子来演示生成的LLVM代码

可以看到生成的代码中,我们只会在少数情况下调用C++代码去分配空间或者将数据写入磁盘中。主要的逻辑,即评估谓词以及生成哈希表都是通过LLVM来执行的。
(因为分配空间这种数量比较少并且复杂的操作上,如果我们也生成LLVM,那么得到的代码就会很大,并且编译时间较长。所以我们调用C++代码。而对于hash probe这种hot path上的操作,需要生成LLVM代码,从而减少function call)
Performance Tuning
这块我理解的可能不对,他说由于生成的代码相当快,导致一些无关紧要的地方现在变成了瓶颈。比如在访问哈希表的时候,我们不是去延迟计算元组中的属性,而是提前把他们计算出来,从而隐藏计算延迟。(我猜测可能是比如我们知道之后要根据一个value访问哈希表的时候,不是在需要的时候再去计算hash value,然后再probe,而是提前拿到这个value,计算hash value。比如figure7中,我们会在probe之前取到z并哈希,然后probe。我们可以在上面提前计算。)。这块我感觉怪怪的。
还有就是有关分支预测的优化。

这段代码中while干了两件事。确定Entry是否存在,以及遍历这个链。
实际上由于哈希表基本上都是满的,所以Entry存在的概率很大,而碰撞的概率很小,所以next存在的几率不大。

所以在这样写代码的时候,cpu可以分开预测这两个分支,从而达到更好的利用率。
Advanced Parallelization Techniques
通过SIMD去处理tuple有很大的优势,只要我们可以将tuple维持在寄存器中。并且SIMD可以延迟分支(我猜测是通过mask位来避免分支,然后最后再进行branching)
我们还可以通过多核来加速处理。通过将数据分区我们可以很容易让query compile framework支持多核处理。

文章评论