Access Path Selection in Main-Memory Optimized Data Systems: Should I Scan or Should I Probe?
Abstract
列式数据分析引擎的发展引起了一系列对scan operator的优化。比如column-group storage, vectorized execution, shared scans, working directly over compressed data, using SIMD and multi-core execution.
更大的主存以及深层次的缓存结构进一步增加了扫描的性能。这要求我们重新审视对于访问路径(AccessPath)选择的问题。
本文比较了现代的sequential scan和secondary index scan。实验表明目前的scan比以往在更多的情况下变得更有用。
我们展示了如何进行access path selection(APS)。和传统的方法不同的是,我们不仅只考虑查询的选择率,同时还考虑到了底层的硬件,系统的设计,以及查询的并发性。
我们展示了一个轻量级的机制,用来将APS集成到主存分析系统中,并且不会影响到低延迟的查询。我们也通过APS模型解释了在sequential scan和secondary index scan之间的界限已经由于硬件和工作负载的改变发生了改变。
Introduction
Access Path Selection是用来选择operator的一个核心组建。比如当一个查询的谓词在clustered index上,那我们使用index去扫描是毫无疑问的。类似的,如果选择的属性上没有索引,那我们就只能执行sequential scan。
然而更常见的情况是查询上有二级索引。在这种情况下,二级索引扫描不一定能比sequential scan效果更好。
决策的点通过是根据selectivity threshold。选择率比较大的查询通过sequential scan更好一些。同时还有底层硬件,系统设计参数,以及数据分布也会被考虑在内。(我个人感觉是后面这三个可以决定选择率阈值,然后通过选择率阈值去决策)
Access Paths In Modern Analytical Systems
在过去20年间,数据库系统从传统的行存储设计中离开,并转移到了列存系统中,同时还为主存系统做了很多的优化。在这样的分析系统中,大量的优化技术让scan变得非常快,从而给二级索引带来了压力。
首先在列存数据库中,我们可以之去处理查询需要的那些属性,从而避免了不必要的属性扫描。
其次就是向量化的执行让我们可以一次执行多个元组(这个是行存和列存都可以)
当系统在相同的属性下有多个并发查询的时候,扫描的结果是可以被共享的。
在列存模型中压缩能够更加有效,并且我们可以直接在压缩的数据上进行操作,增加了局部性。
通过列存模型,我们可以通过SIMD来加速在这个属性上的操作。并且当SIMD允许我们并行处理多个tuple的时候,多核性质允许我们并行的处理若干个不相关的block(数据级并行+线程级并行)
Access Path Decisions in Main-Memory
由于目前的(热)数据都可以存在主存中。并且本质上二级索引是为了减少磁盘IO的数量。而目前的主存数据库不存在这方面的瓶颈。所以现代的分析系统都会选择不去用二级索引,而是选择优化顺序扫描(配合cluster index和data skipping techniques(比如zone map))
并且由于主存系统的处理相当快,所以我们不能有很多的时间去做access path selection。因为优化的时间可能导致了新的bottleneck
Open Questions
本文中我们回答两个问题:
1. Is there still a case for secondary indexes in modern analytical systems?
2. How should we perform access path selection given the advancements in system design?
第一个问题实际上是对scan的优化的一个延伸,因为当我们可以让一次sequential scan去回应多个query,还有使用二级索引的必要么?
Access Path Selection in Modern Analytical Systems
我们展示了在现代系统中,低选择率的情况下,二级索引还是有必要的。但是在考虑Access Path的时候,我们同样要考虑到query concurrency。

通过figure1可以看到本文的基本概念。即在APS中考虑了concurrency
注意到我们不能因为这个原因去把并发度设的很高,因为这里还有其他的因素影响着性能。比如写数据的时候如果并发程度很高可能导致大量的TLB miss
System Integration
我们会讨论如果将这个APS机制集成到现有的系统中。
优化器需要考虑到硬件配置,以及持续监视workload(selectivity和query concurrency)
Contribution:
* 提出了一个增强版的AccessPath cost model用来支持access sharing
* 展示出我们需要APS,tuned secondary index即便是在有很快的扫描情况下也有用
* 展示出除了选择率和硬件环境,query concurrency也是APS要考虑的问题
* 集成了APS到一个prototype中,并说明即便APS是一个比较复杂的操作,也可以很快的完成操作。
* APS的性能优势
* 通过模型我们展示出何时使用index的决策由于硬件以及数据分布的变化在近几年已经发生了改变
Access Path Selection
Model Preliminaries
Select Operator:
本文的目的就在于研究select opeator的性能。他的作用就是过滤掉查询中的数据。
select operator的输入是一列(for pure column-store)或者一个column-group(for hybrid or pure row-storage)
select operator的任务就是根据给定的谓词来生成所有符合条件的tuple。输出则是一个rowID的集合。
Parameters and Notation:
我们的APS model捕捉的参数有:
1. query workload
2. dataset and physical storage layout
3. underlying hardware
4. index and scan design
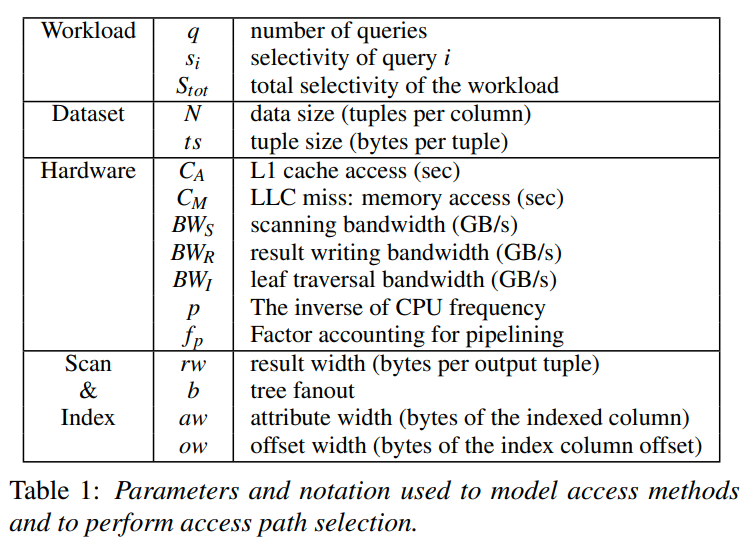
Modeling the Query Workload:
workload是通过并发的query的数量,以及他们的选择率所建模
总选择率就是选择率的和,他可能超过100%
Other Scan Enhancements:
zone map可以用来跳过data block。但是并发查询会导致zone map的能力降低,因为必须让所有query都能跳过zone map的时候我们才能真的不去扫描这个block
Modeling In-Memory Shared Scans
数据扫描的开销

谓词的开销:
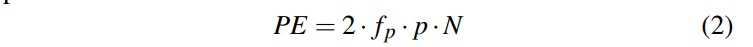
fp是影响指令流水线的因子。p就是cpu频率的倒数,表示的是period
由于我们可能是受到内存限制或者是cpu的限制。所以执行scan的开销是max(TDs, PE)。即移动数据时间和评估谓词时间取最大值。
另一个比较关键的就是写入结果的开销:
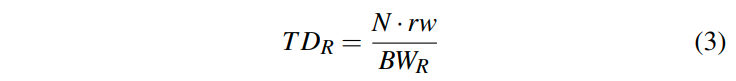
他说为了减少branch mispredictions,我们会通过predication的方法来生成结果集。(这里我不太明白,说的是写入的方法么?)
由于在写入结果的时候,要么我们会写入到一个cache line中,或者是顺序写内存。那么我们也可以达到memory bandwidth的速度。所以一个查询总共的开销为:
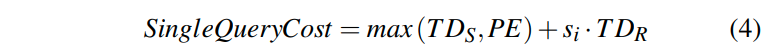
Scan Sharing:
scan sharing可以让我们共享移动数据的开销。但是多个query会增加PE的开销。
系统需要首先将query组成组,然后对于每一个数据我们需要让每一个query的谓词都去执行一遍。
每一个query都通过一个独立的线程执行。(这样的话主要的时间就是从memory移动到cpu的时间,cache中会共享这些数据,因为他们是只读的,所以我们也不需要显式的同步,但是如果一个核很快另一个很慢会不会引起缓存的震荡呢?)
每一个query都需要生成他自己的写集。所以cost变成了:
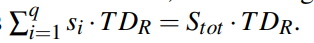
(这就是为什么我们计算了Stot,而没有考虑重复谓词的情况)
那么最终总共的开销如下:
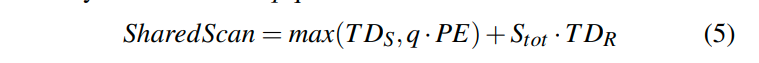
(这么看他认为评估谓词是一个固定的时间)
Modeling In-Memory Secondary B-Trees
Selects Using a Secondary Index:
B+Tree作为二级索引的时候,叶节点存储的就是rowID。
我们也可以直接扫描叶节点上的值来达成sequential scan的效果。因为B+Tree的叶子之间有链接。
Modeling Secondary Index Scan:
在index scan中有这么几个步骤。首先我们遍历到在请求的范围中的第一个叶节点。然后遍历叶节点并读取数据。最后我们写入结果。(如果只需要二级索引上的列我们就不用再次根据rowID去读数据,否则就需要根据rowID再去定位数据)
Tree Traversal:
找到第一个叶节点的开销为:
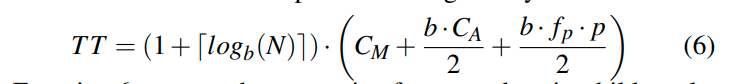
b为fanout,也就是一个节点内部的kv对的数量。
平均我们需要读取一半的键来找到需要的键。这里是假设结点内的sequential scan。
每次读都是缓存命中的访问,加上一个谓词评估的时间。第一次的访问则是一个random access,也就是Cm。
Leaves Traversal:
遍历叶结点是随机访问。我们一共有N/b个叶节点。再乘上选择率就是需要访问的叶节点的个数。
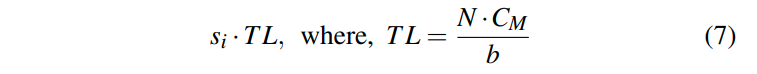
Data Traversal for Secondary Indexes:
这个是读取叶节点上的rowID数据,是顺序遍历。
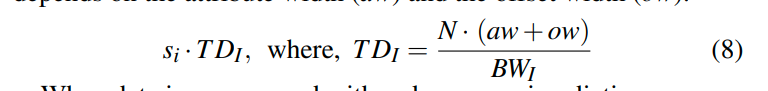
aw + ow就是一个row需要的大小。乘上N就是叶节点数据的大小。然后再除以bandwidth(这个感觉应该和sequential scan的bandwidth一样)
Result Writing:
写结果的开销和之前顺序扫描中的是相同的
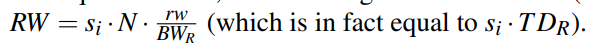
Sorting the Result Set:
基于rowID进行sort。每次访问都是一个cache hit,因为我们刚刚把它写入到result set中
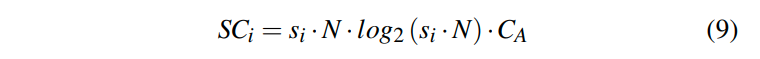
虽然sort的独立的,但是如果我们需要让他和full scan对比的话是必要的。并且如果在query plan中,index scan的下一步是tuple reconstruction,那么我们输出的这个rowID的集合就会导致大量的随机访问,从而降低性能。
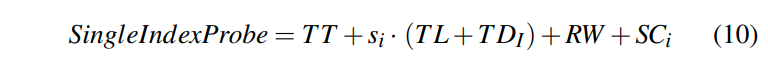
总共的开销就是这些。
Concurrent Index Access:
这里他给出的是最差的情况。原文中说虽然并发的访问会有缓存的共享,但是在最差的情况下就假设他们都没有成功共享。所以总的cost就是q乘上单个访问的开销。(我感觉不太合理,因为共享肯定是存在的)
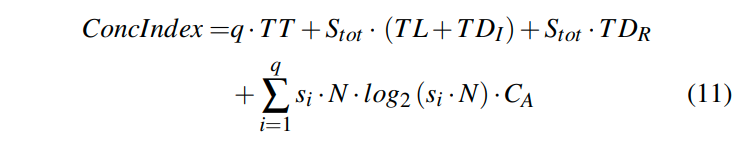
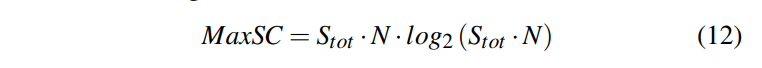
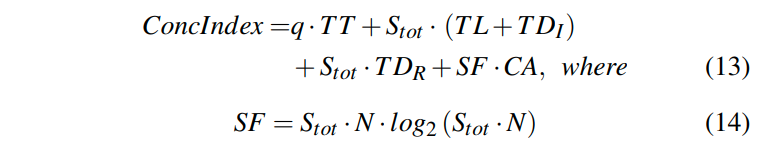
Evaluating Access Path Selection
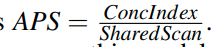
通过这个公式来的到APS,然后用APS和1对比从而确定我们是选择Index Scan还是Shared Scan
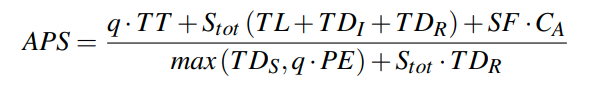
我们将这个公式展开并化成有关runtime workload的函数,即对q和Stot的函数
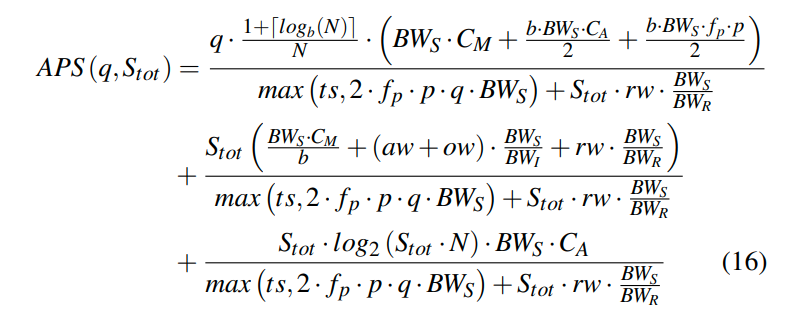
我们研究一下这个公式。
公式中第一部分考虑到了q,数据量N,fanout b,以及hardware tradeoff,这里说的是BWs和Cm与Ca的项。
第二部分则主要由predicate evaluation cost,选择率Stot以及data layout所影响
第一部分中,分子主要由q所决定。由于那个log项的存在,在并发程度提高的时候,这个项提高的程度会很小。
在后面的乘积中,第一项是我们可以在Cache miss的时间中读到的数据量。(可以这么考虑,cache miss越严重,这个项越大,我们就应该多使用sequential scan)。第二项则主要是有b个L1访问的时间中,我们可以读到的数据量。第三项是在我们进行b个比较的时候所能读到的数据量。这后面两项完全对应了树节点访问数据的开销。即我们在访问树节点的时间中,能够顺序扫描的数据量越大,则越应该使用顺序扫描。
可以看到他是通过时间和BWs去tradeoff我们是否应该做顺序扫描。
第二部分则主要由Stot所决定。BWs * Cm / b说的是我们在一次cache miss的时候大概可以顺序读多少个index node。而后面的项则主要取决于data layout。
在分母中,我们有项ts,说明更大的tuple size可以带来更加有用的index scan。因为低选择率的情况,更大的tuple size说明我们可以读到更少的数据。同时分母还引入了predicate evaluation cost,越大则会让顺序扫描开销越大,因为我们需要在每个tuple上都去评估谓词。其中max的含义表示的取移动一个tuple,或者评估谓词时间中所能读到的数据的最大值。评估越慢读到的数据越多,index的效果就越好。
对于q比较小的情况下,我们可以通过Stot来选择是否进行full scan或者index scan。对于q比较大的情况下,第一项则会成为主导。这时候分母中的谓词评估时间也会成为主导。
后面有一些observation可以看一下:
1. In a modern main-memory optimized analytic data system there is a break-even point regarding the performance of a scan and a shared index scan; access path selection is needed to maximize performance in all scenarios
2. Unlike traditional query optimization decisions, choosing between a sequential scan and an index scan in a modern system depends on concurrency in addition to selectivity.
3. In hybrid systems supporting column-groups, secondary indexes are useful in more cases than plain column-stores because using a secodary index helps to avoid moving a larger amount of unnecessary data through the memory hierarchy.
4. Although hardware characteristics change the point where a sequential scan is preferred over a secondary index scan, all systems require run time analysis to make the decision.
5. Access path selection becomres more crucial for bigger data inputs as data movement becomres more expensive - and as a result every wrong decision has a larger cost.
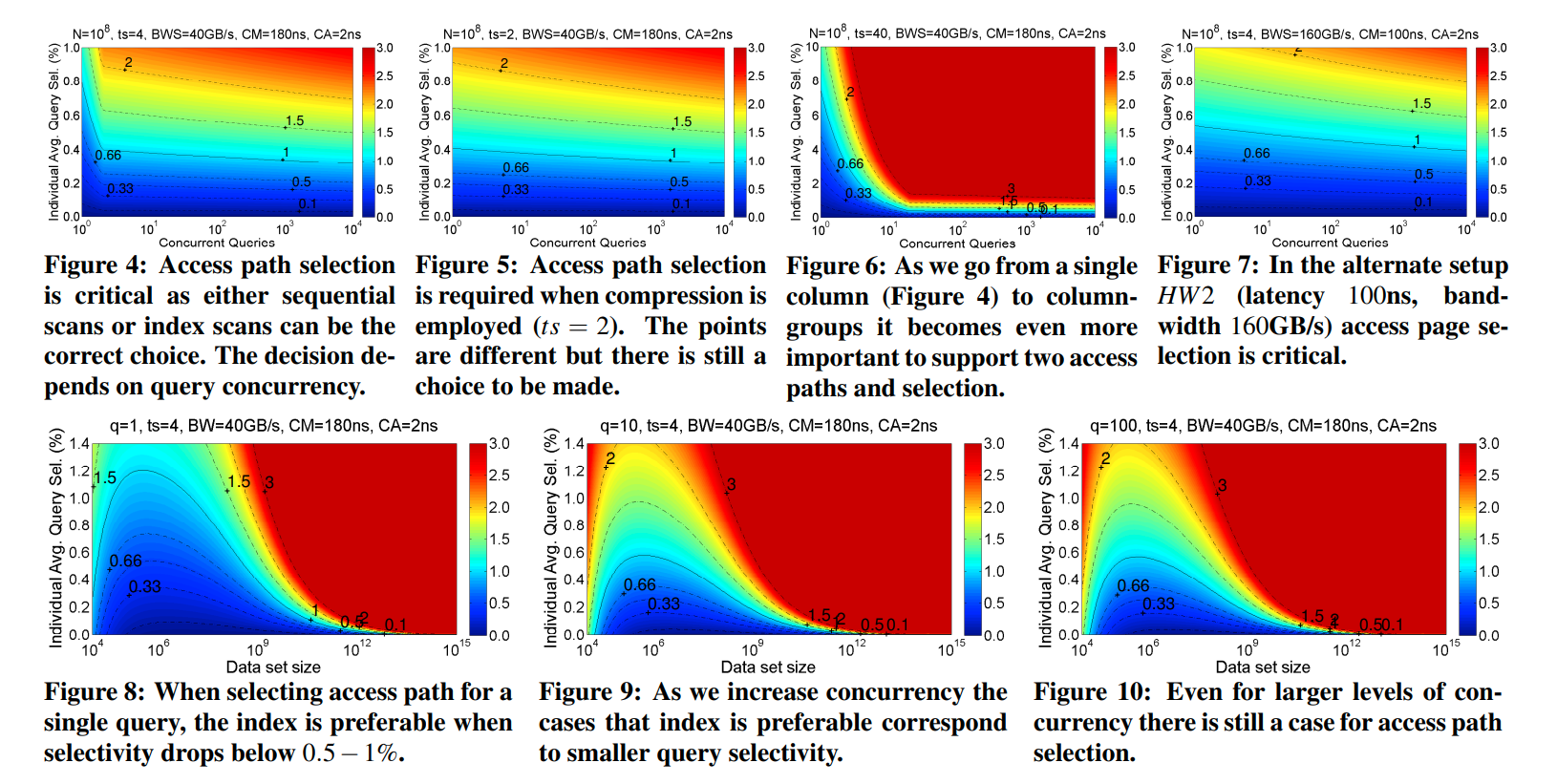
这个图还是值得看一下的。在figure8中,很有意思的是即便是一个查询,在大数据量低选择率的情况下,全表扫描也是一个更好的选择。这是因为我们会在index scan后进行排序。并且即便是低选择率,在大数据量下也会有很多满足条件的元组。我们基于rowID排序进一步加剧了这个效果,导致index scan的效果不好。(这个结论感觉就怪怪的,感觉应该还是更大的数据量上去做index scan效果更好)
然后看一下最后我感觉比较有用的lesson:
1. Data set size can be pivotal. For small data sets scanning the data outperforms secondary indexes in all cases. Index remains useful for larger data sets as full attribute scans become costly.
2. While the corssover between access methods is lower than in the past, it still corresponds to a growing result carinality. e.g. a query that selects 0.6% of 500 million integers, has 3 million qualifying tuples.
3. While sharing data access minimizes repetitive reads, it includes the overhead to distribute the results to their consumers. Result sharing is efficient up to a batch size, because of the bookkeeping and the result distributing overhead.
4. As the cache and memory latency decreases, or the memory bandwidth decreases, secondary indexes becomre more beneficial. On the contrary, slower caches or memory, and faster memory buses benefit scan. In this way, future hardware generations that affect the balance between these hardware properties will also affect path selection accordingly. These properties are captured by the APS model.
可以看到他这里也说了大数据量下index scan的效果更好。同时大数据量下也会导致更多的结果。
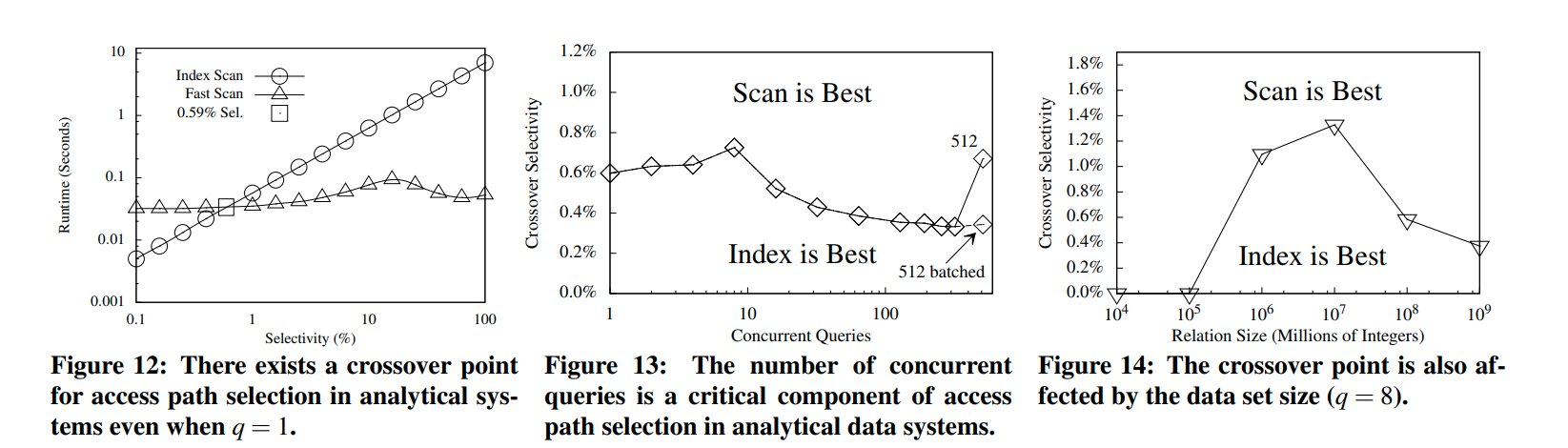
但是这个crossover point会逐渐下降。因为虽然索引扫描复杂度是log的,但是排序的复杂度是nlogn的。这样的话当结果集增大的时候,排序开销会变的不可忽视。

文章评论