Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age
Abstract
随着计算机架构的发展,在parallel query execution中出现了两个问题:
* 为了利用好多核的优势,每个查询需要被均匀的分布到每个线程中
* 即便是我们拥有相当准确的统计数据,也很难将负载均匀的划分开
这两个问题导致了目前的plan-driven parallelism陷入了负载均衡和上下文切换的瓶颈中
第三个问题是在many-core的架构中,内存控制器是去中心化的(可能是若干个核对应一个内存控制器),从而导致了NUMA
这篇文章提出了morsel-driven query execution framework。调度将变成细粒度NUMA-aware的运行时调度。并行度不再在plan中详细规划,而是可以在执行时动态的变化。调度器是NUMA-aware的,所以绝大多数的查询将会在本地内存中进行
Introduction
之前的火山模型中的并行执行是通过exchange算子来实现的。exchange会将元组流转发给多个线程,每个线程都会执行相同的pipeline segments。这样的实现被称为plan-driven:optimizer statically determines at query compile-time how many threads should run, instantiates one query operator plan for each thread, and connects these with exchange operators.
而morsel-driven的idea如下
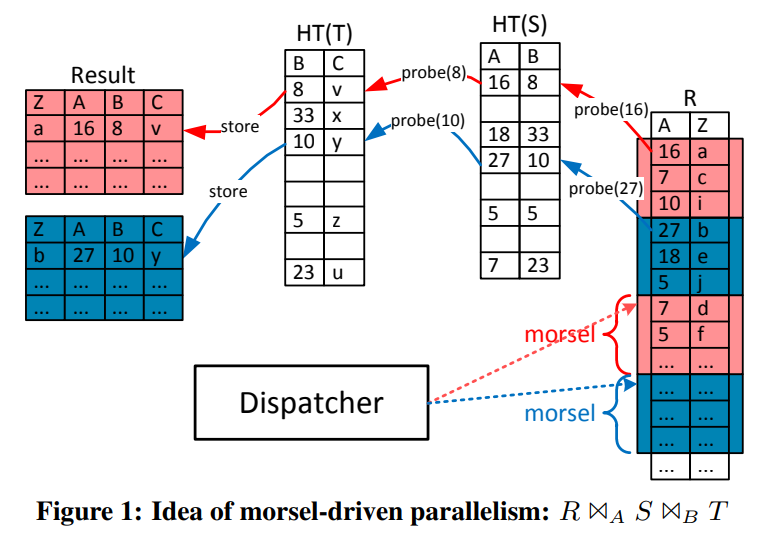
一个查询会被划分为若干个segments,每个segment取一小部分的数据并执行,并最终将他们物化到pipeline breaker中。
图中的颜色则代表了NUMA-aware的特性:A thread operates on NUMA-local input and writes its result into a NUMA-local storage area.
文章中提到了他的dispatcher是pin在固定的核上的,所以不会出现由于OS移动线程导致的局部性缺失的问题(我的感觉是dispatcher的位置是无所谓的,因为他与数据无关,然而工作线程应该是pin在核上才对)
morsel-wise的框架中,所有的算子在任何阶段都是可以被并行化的,这相对于火山模型来说不仅在输入输出数据是并行化的,在中间的状态也是并行化的。比如用于做join的hash table,就需要被多个核共享访问。
在火山模型的框架中,并行会被算子隐藏起来,并且我们会避免共享的状态(比如要执行hash join的时候就需要先物化哈希表,变成一个算子的工作)。并且由于隐藏了并行的细节,我们就需要在exchange operator中进行on-the-fly的数据分区,(比如round-robin),而这个工作可以通过我们的locality-aware的dispatcher来进行。对于算子并行来说,有的系统提倡使用per-operator的并行从而实现执行的灵活性,然而这需要引入额外的算子间的同步。我们认为morsel-wise的框架可以被集成到现有的系统中。我们可以修改exchange operator的实现来达到morsel-wise scheduling,并且引入数据结构的共享。
(我感觉核心的思路就是将operator-thread变成了morsel-thread,这样我们的线程就不需要绑定到具体的operator,从而引发额外的同步或者灵活性较差的问题。现在每个线程只需要执行自己的morsel就可以。直观的感觉就是之前的模型就是提前搭建好了管道,然后我们往里喂数据。现在则是一堆工人在数据堆里一块一块的取。有点data-oriented的感觉,因为每一个morsel我们不需要关注他的worker是谁(当然优先local worker),只要关注执行的逻辑即可)
Morsel-Driven Execution
通过这个例子来演示:
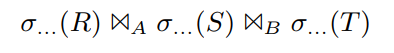
假设R是filter之后最大的表,所以我们会用R作为probe input,并在另外两个表上构建哈希表
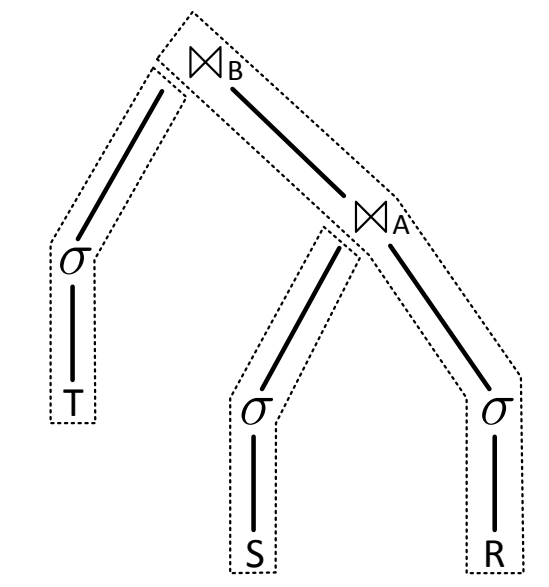
我们得到了3个pipeline:
1. scan,filter,并构建哈希表HT(T)
2. scan,filter,并构建哈希表HT(S)
3. scan,filter,并用结果从HT(S)中探测,然后再从HT(T)中探测,最后存储结果
morsel-driven execution会被QEPobject来控制。他会把executable pipeline传给dispatcher执行。QEPobject负责跟踪数据的依赖性。比如上面的例子中,只有当前两个pipeline都执行完成的时候,最后一个pipeline才能开始。QEPobject会为每个pipeline分配临时的空间用于存储他们的结果。当pipeline结束后,这个临时的空间会被划分为等大小的morsels。这样后续的pipeline就会从新的morsel开始执行,而不会保留之前的morsel的边界(因为可能之前相同的morsel的结果不是等大的,从而可能导致负载偏斜)
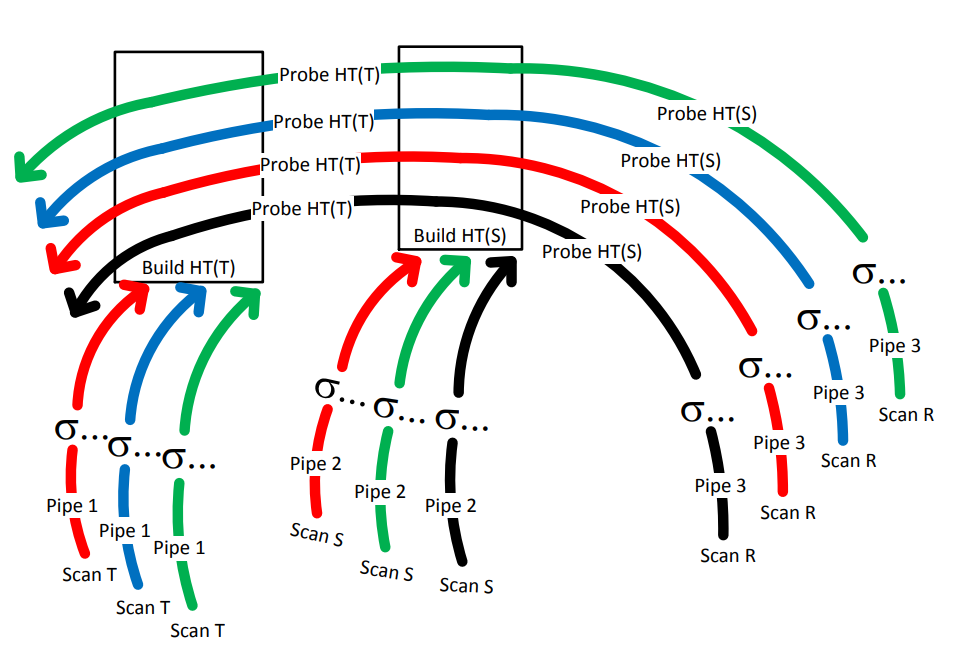
对应生成的pipeline
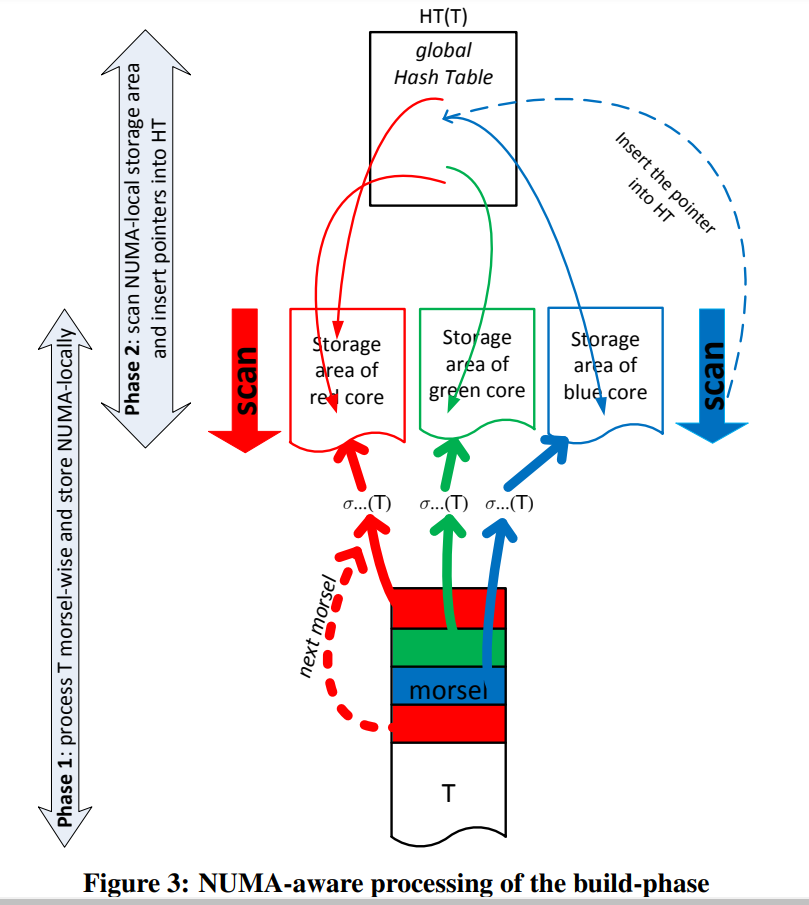
构建哈希表的pipeline
每一个线程会操作一个morsel。基本表T存在了morsel-wise的NUMA-organized memory中。
每当一个线程处理完一个morsel的时候,他要么会被分配到另一个任务上(被dispatcher),要么会获取相同颜色的另一个morsel来作为下一个任务。
而构建哈希表的这个pipeline是由两个物理的pipeline组成的。逻辑上讲,我们是读取一个tuple,做filter,并插入到哈希表中。实际上在figure3中则是划分为两个阶段。
第一阶段主要是filter tuple,并插入到NUMA-local的存储区。
当所有的morsel都被scan并filter了以后,我们会重新扫描这些结果,并将指针插入到哈希表中。(我好奇难道不能直接插入吗)
这里说到是因为我们可以知道有多少元素会被插入到哈希表中,从而可以得到一个具体的哈希表的大小(这里我感觉是因为动态变化大小的哈希表不容易处理,并且可以均匀的把哈希表划分到每个NUMA-area中)。并且由于会有很多的线程同时插入,所以lock-free的实现是必要的
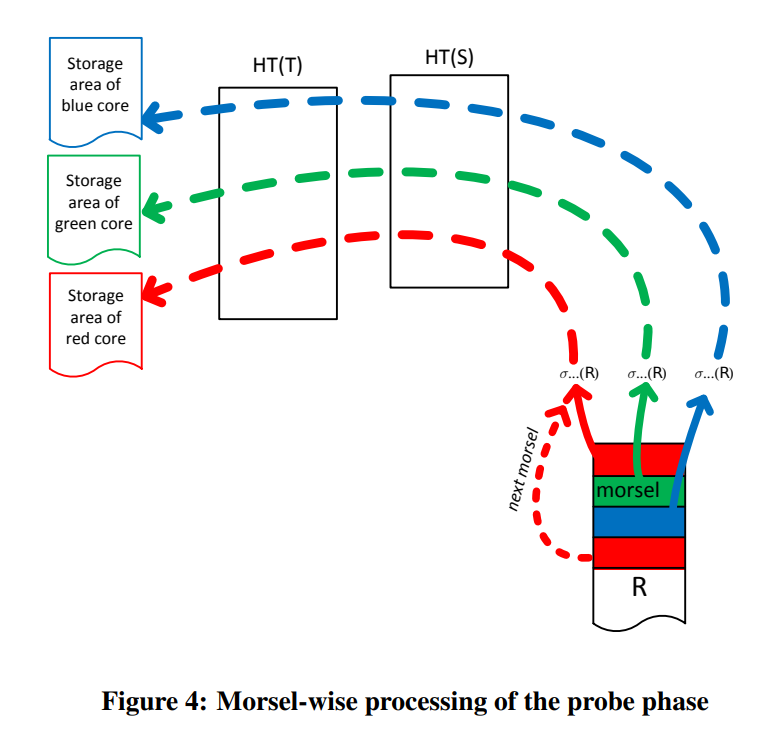
当所有的哈希表都构建完毕的时候,我们就可以开始执行probing pipeline
和之前一样,dispatcher会让本地的核去获取本地的数据,并将结果存到本地的内存中。(这里他没提到的一点,我猜测hash table的访问肯定会引入remote memory access,但是由于我们是给全局共享了哈希表,这也是必要的)
和火山模型不同的是morsel-driven的执行中,pipeline不是独立的(pipeline segment不同并且有依赖)。morsel-driven的pipeline会共享数据结构,从而需要一些同步手段。还有就是不同的pipeline segment的线程数不同,并且pipeline segment内部的线程也可以变化。
(这个感觉有点像数据并行和模型并行,数据并行不需要考虑依赖和同步,数据与数据之间是独立的。而模型并行则需要考虑依赖性,并且内部也会有数据的并行。但是这篇文章的重点不在这里,而是在细粒度的执行,NUMA-aware的scheduling,以及共享的数据结构)
Dispatcher: Scheduling Parallel Pipeline Tasks
dispatcher负责控制以及分发计算资源给每个pipeline。我们通过将task分配给每个worker来实现这一点。我们会为每个硬件线程(逻辑核我猜测)绑定一个对应的worker。因此查询的并行度不由创建或者终止线程来实现,而是通过将分配任务来实现。
一个task是由一个pipeline job,以及一个morsel组成的。任务的抢占只有在morsel的边界处才会出现,即执行的粒度是morsel,从而可以不需要引入额外的中断机制。
分配task给worker的主要目标为:
1. Perserving locality by assigning data morsels to cores on which the morsels are allocated
2. Full elasticity concerning the level of parallelism of a particular query
3. Load balancing requires that all cores participating in a query pipeline finish their work at the same time in order to prevent fast cores from waiting for other slow cores.
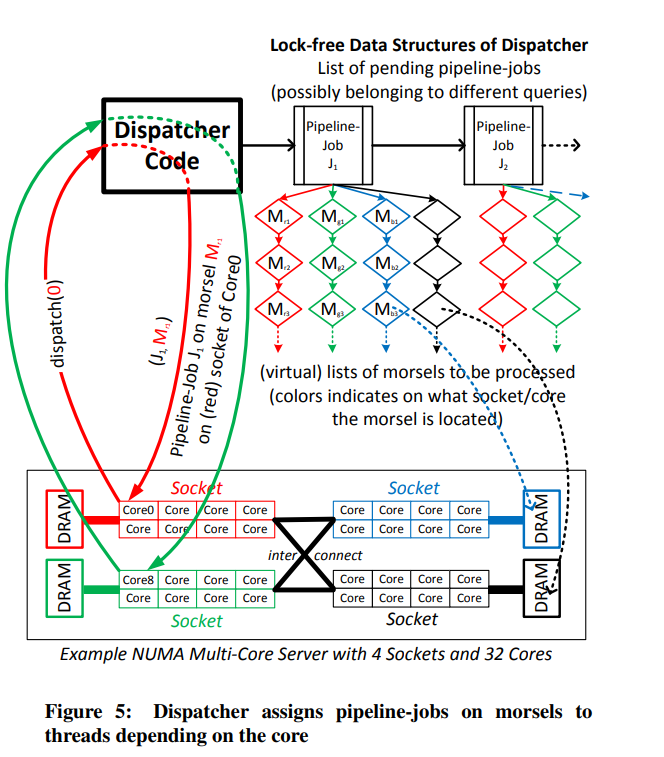
dispatcher维护了一个链表,里面存储了那些依赖已经被满足的pipeline job。前面提到过QEPobject负责跟踪pipeline的依赖,所以他负责将可执行的pipeline发给dispatcher。
Elasticity
通过dispatching jobs a morsel at a time来实现调度的elasticity。比如我们有一个长的查询Ql在运行,当出现了一个更加高优先级的查询Q+的时候,我们可以降低Ql的并行度,并优先处理Q+,当Q+执行结束后,我们就可以回来提高Ql的并行度。
每个pipeline job都会维护一个pending morsels的list。他的这个list是每个core单独维护的,Core0上存的就是core0的morsel。而不是有一个中心化的结构来保存所有的morsel。
Implementation Overview
实现上,我们并不是在每个socket上都执行一个dispatcher thread,而是让core在需要morsel的时候去自己执行dispatcher的code。
通过lock-free的数据结构来减少争用(lock-free应该是减少等待而不是减少争用)
数据之间的依赖的处理,即QEPobject是通过一个状态机来实现的(他这里说的是passive state machine,我个人感觉就是拓扑排序的实现)。当我们的dispatcher发现pipeline job执行完的时候,他就会通过QEPobject来尝试找到新的pipeline job。和dispatcher一样,代码也是在worker上执行的。
(这里说白了就是没有真的dispatcher,就是socket上有对应的pipeline job列表,以及morsel列表。然后worker自己去拿,或者通过QEPobject去放新的pipeline job。)
当某一个socket的job都完成了,他就会尝试从其他的socket去steal work,从而防止闲置的线程。
并且这个模型还可以提供很好的方法来取消查询。比如当我们事务abort,或者内存耗尽等问题出现的时候,我们可以不去让OS杀掉对应的线程,而是可以标记这个query。当worker发现这个query被取消了,他就可以不从里面获取morsel。这个方法可以让worker自己去做clean up的工作,而不需要引入额外的机制(比如RAII,杀掉线程的时候释放线程申请的资源)
Morsel Size
Morsel size不是一个很关键的因素,和Vectorwise的执行不同,我们不要求morsel可以放入缓存中,他们只是一个用于调度的任务单元而已。在选择的时候,只要保证他们足够大可以均摊调度开销就可以。
系统中的shared-datastructure,也就是dispatcher,不容易成为瓶颈。因为我们最开始会为每个线程分配他们的range,只有当他们本地的range使用完之后线程才会尝试steal其他的range,从而导致一定的争用。同时如果有多个任务同时执行的时候,这个效果会变得更小(因为我们更不容易去steal work)。并且我们可以通过增加morsel size来减少对共享数据结构的访问。只要有足够的query,增加morsel size就不会影响整体的吞吐量。
Parallel Operator Details
我们需要保证每个算子都是可以并行执行的。这一节则是讨论并行算子的实现
Hash Join
前面已经提到过,hash join有两个阶段。第一阶段是将输入的数据物化到thread-local area中。第二阶段则是通过CAS将tuple的指针插入到哈希表中
文章提到了一些选择single-table hash join的优点。这里就不提了。
Lock-Free Tagged Hash Table
他的hashtable有一个优化就是在指针上存了一个filter。64位中有16位的filter,以及48位的指针。
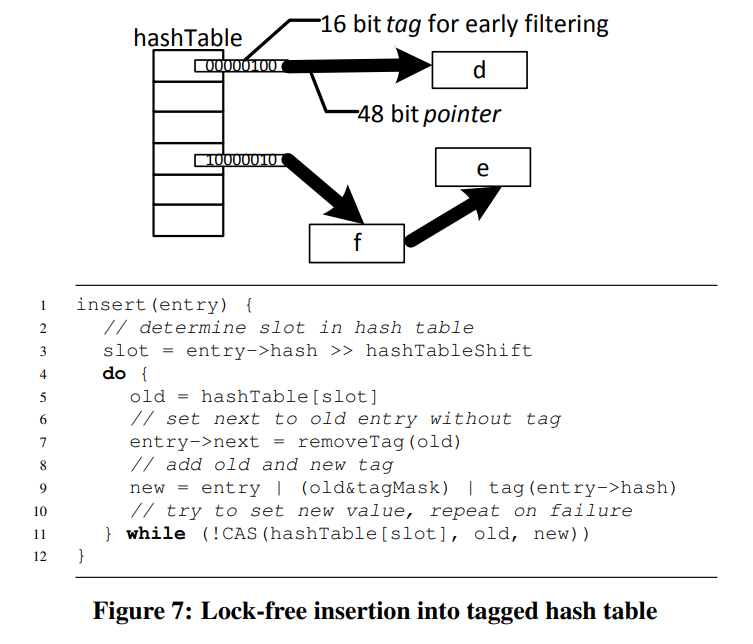
在指针上存了一个bloom filter,然后通过bloom filter可以减少cache miss
(我好奇他都已经确定了哈希表的大小了,为什么还要用链式哈希,而不是用开放寻址)文章中他说因为开放寻址法需要把tuple保存到哈希表中,而链式的则保存指针就好。并且链式的缺点是缓存命中率低,也通过filter解决了。
这里有一个很有意思的点。实现的时候是通过mmap来分配哈希表的空间的。并且由于OS会进行lazy allocation,只有第一次写入才会真正的分配空间。带来两个好处,一就是我们不需要手动初始化哈希表,让OS在分配页的时候帮我们初始化即可。二就是哈希表会适应性的分布到每个NUMA-node中。因为当第一个线程写入的时候,对应的页会被分配到这个线程所在的节点上。所以如果有很多线程在构建哈希表的话,哈希表会在各个node中交错分布(并且node访问的越多,他就越可能是第一次访问数据,从而拥有更多的local page)。当只有一个node的时候,哈希表就会整个坐落于这个node上。
NUMA-Aware Table Partitioning
最简单的分区方法就是用round-robin。
一个好一些的方法就是基于一些比较重要的属性来做哈希分区。这样的话在我们做join的时候,能够join的元组通常是在同一个socket上的。所以可以带来更少的跨socket的通信。
同时这个哈希函数也会被应用到哈希连接中哈希表桶的位置的最高位。(所以我猜测应该是哈希表的分布和数据的分布是相同的,这样查询哈希表的时候也是NUMA-Aware的)
这种分区方法会对我们的morsel-driven执行模型有好处,但并不是决定性的。因为本身的表扫描就具有NUMA-locality,输出的结果也是具有局部性的。上面的分区方案的作用只是增强在连接时候的性能,而不会影响其他地方。
Grouping/Aggregation
在做aggregation的时候,如果我们只有很少的几个组,那么聚合就会非常快,因为缓存命中率高。但是当组很多的时候,就会出现很多的cache miss,从而导致性能降低。

算法分为两个阶段。第一阶段是thread-local pre-aggregation
先在本地做一个小的哈希表,对应图中就是ht。在本地将数据进行分区,得到若干个partition。
第二阶段就是每个线程扫描其他的partition,然后将他们聚合到本地的哈希表中。这里的意思应该是一个线程负责一个或者多个group,然后扫描其他线程的partition。从而得到自己负责的group的结果。
当一个partition处理完成后,会立刻被推到下一个算子中,这样他更有可能是fit-in-cache的。
(有点类似分布式的aggregation,先做本地然后再去交换数据)
和join不同的是聚合操作必须要所有的数据都输入后才能有输出。所以选择了用分区的方法。而join则是可以pipeline的,所以用一个哈希表去检查是否可以连接就可以。
Sorting
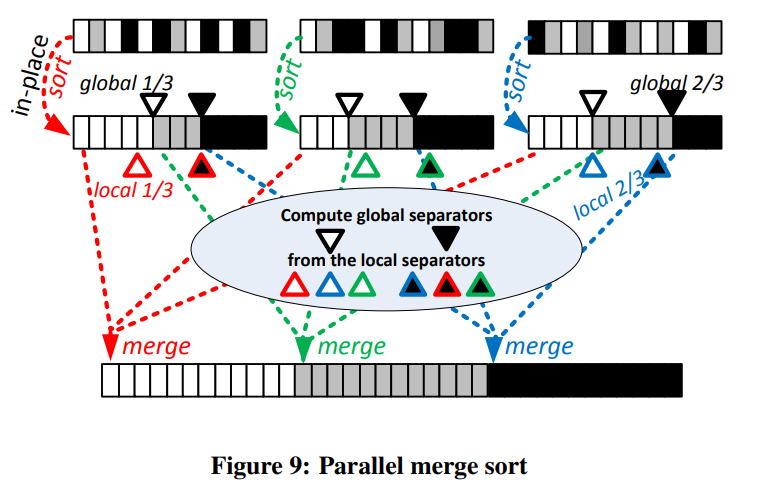
首先先执行local sort,或者local top-k
每个线程首先计算local separator。然后为了防止分布偏斜的情况,所有的线程的local separator会被结合起来,并计算global separator。
得到了global separator后,我们找到具体的separator的index,并通过这些index可以得出最终数组的具体分布,然后我们就可以直接把数据拷贝过去而不需要任何的同步。
比如figure9,我们有3个worker,那么就需要将数组分为三段做并发的merge。每个worker挑出两个local separator,然后合并成2个global separator。如图所示,三个数组的第一段会被红色的worker合并,第二段会被绿色的worker合并,第三段则是蓝色worker。这样worker之间就不需要任何的同步。(但是缺点就是worker越多,每个线程所访问的远端内存也就越多,可能导致局部性比较差)

文章评论