GentleRain tutorial
首先要知道最简单的causal consistency是怎么实现的
在论文Session Guarantees For Weak Consistent Replicated Data中有详细的说明
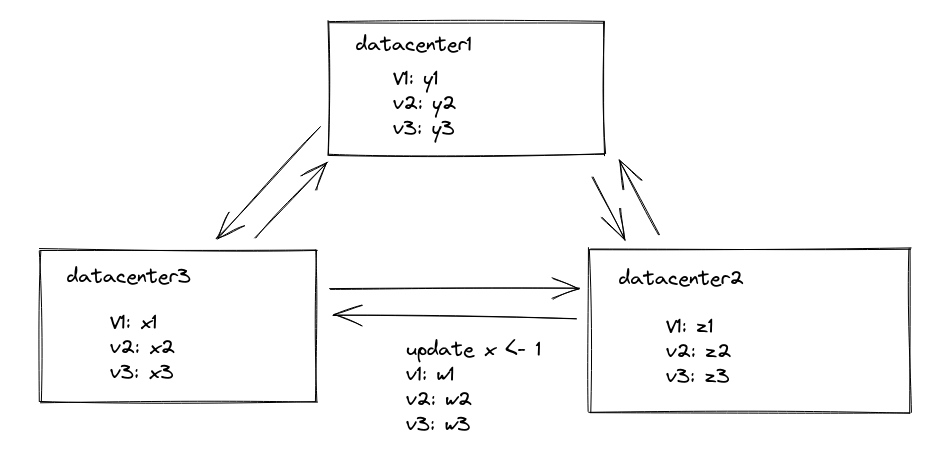
每一个更新都附带一个version vector,当远端数据中心的version vector大于这个更新的version vector的时候,这个更新才能被安装到远端数据库中。从而保证因果一致性。
下一个问题,当数据中心内进行数据分区的时候,我们要怎么处理?
每个分区内部都维护一个version vector。当一个数据中心内部的每个分区对应的version vector都大于这个更新中对应分区的version vector的时候,这个更新才能被安装。
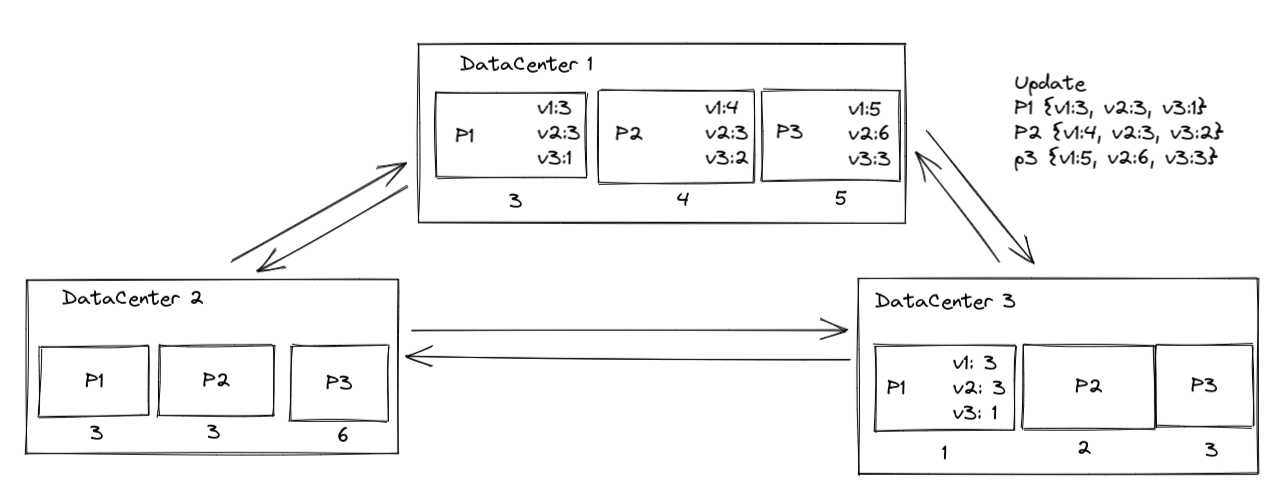
缺点就是需要传输的东西太多了。
一个优化,我们可以适当放宽粒度,还是类似最开始无分区那种情况来处理,每个数据中心只用一个version来表示
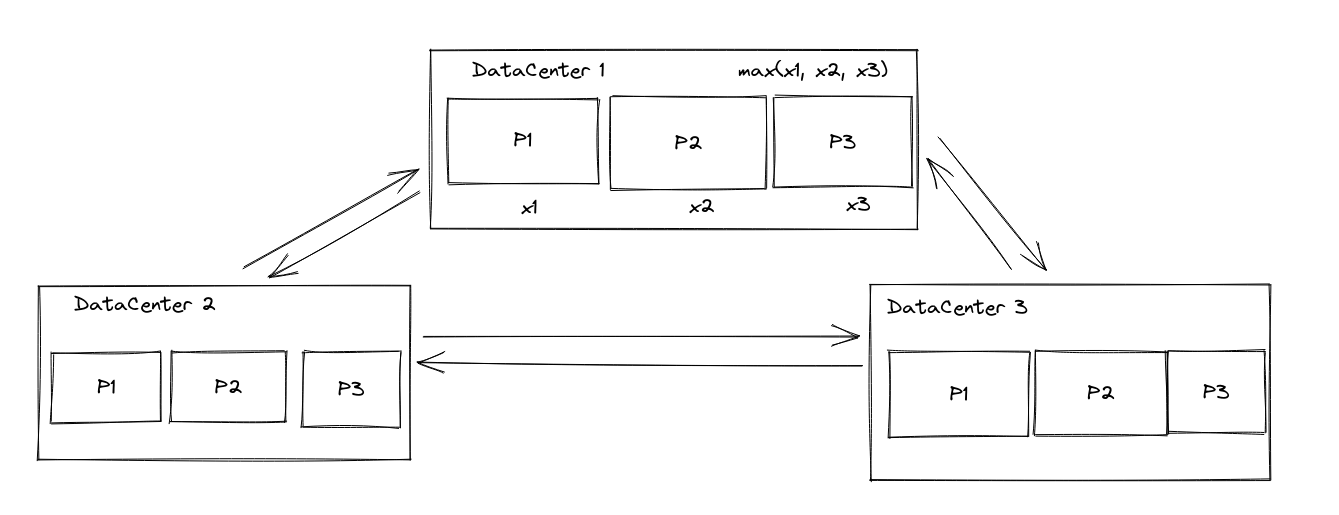
我们取分区的版本最大值来代表整个数据中心的版本。
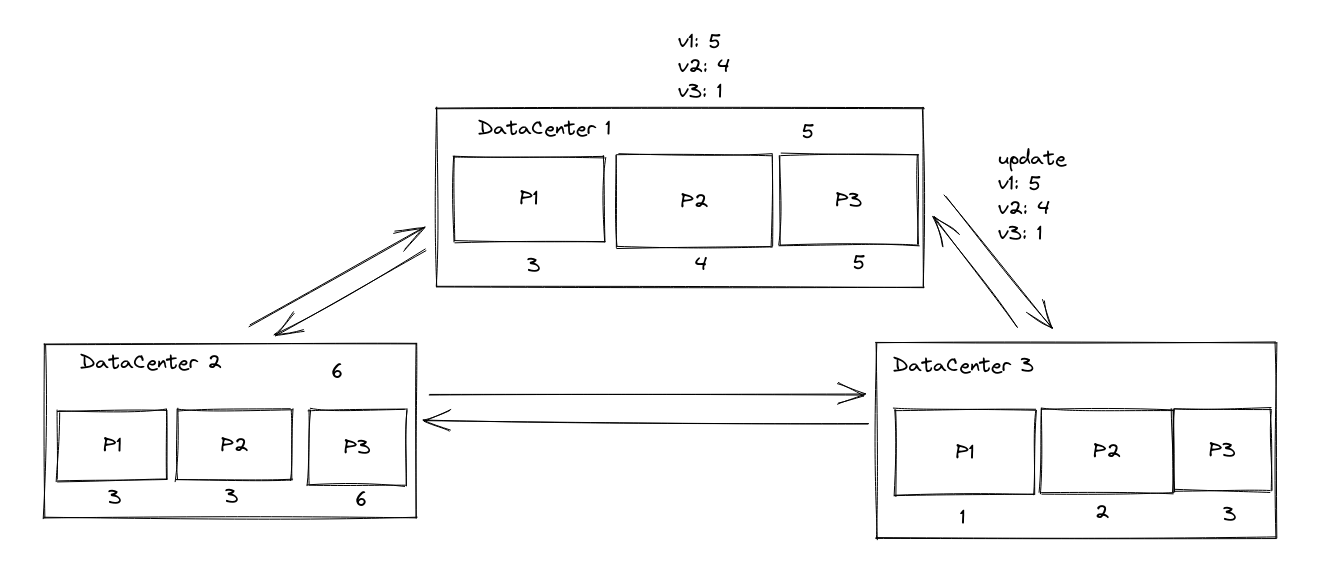
一个例子,当DC1向DC3传播更新的时候,DC3会检查本地分区中的版本。他会等待直到所有分区上的version vector中DC2大于4,并且DC1大于5的时候,才能保证本次的依赖已经满足了。才能安装本次更新。
好处就是我们节省了一些消息传输的开销。然而分区导致的缺点还在,就是我们需要不断的进行数据中心内的信息交换,从而保证分区间的最小version vector的值
然而不断的数据中心内的信息交换,以及版本向量导致的scalability的问题仍然存在
我们可以继续简化刚才的设计,直接把整个版本向量用一个最大值来表示。
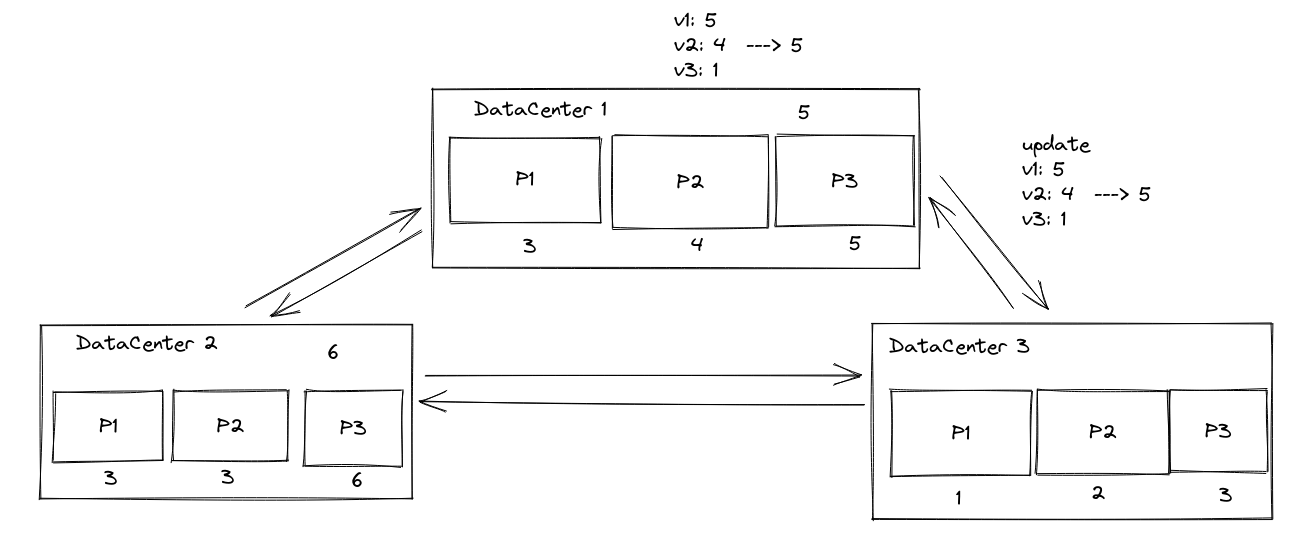
那么这时候,DC3就必须让所有的分区,在version vector上所有的值都大于5的时候,才能保证依赖被满足了。
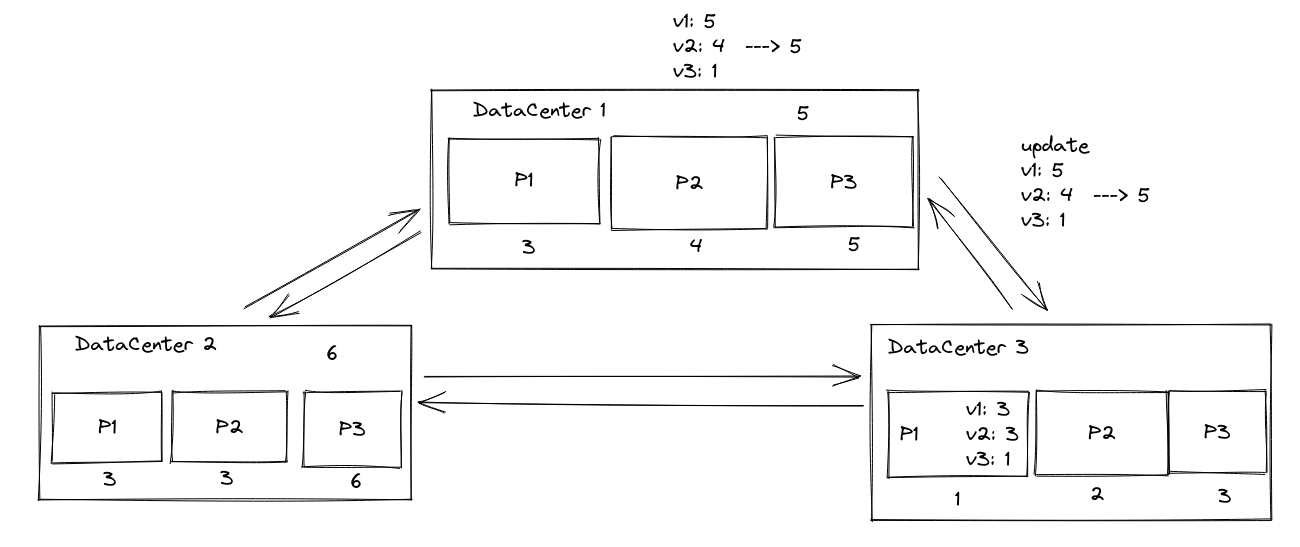
需要注意的是version vector一直在被维护,只是不被传输了。
这时候我们用了更粗粒度的版本,节省了消息发送的成本。最后一个问题就是数据中心内部的同步了。
之前的思路是新的更新到来时需要一次分区内部的广播来确定本次更新是否能够进行。(或者直接安装新版本,但是读取时只能读到保证可见的数据。相当于是将分区间信息交换推迟了)
我们可以阻塞住新到来的更新,然后每过一段时间进行一次数据中心内部的同步,统计最小的时间戳。任何更新如果小于这个时间戳,就已经被持久化到了本地数据中心中。当这个最小时间戳大于这次更新的时间戳的时候,我们就可以确定他依赖的所有数据项都被持久化到了本地数据中心中。从而可以安装这个更新。
有关数据中心内的广播开销,在分区多的时候开销比较大。可以通过树形的合并来达到O(n)的消息数量以及O(logn)的RTT的合并。
通过物理时钟来保证时间戳正常推进,而不会像逻辑时钟那样发生很大的偏差。

文章评论