GentleRain: Cheap and Scalable Causal Consistency with Physical Clocks
Abstract
GentleRain是geo-replicated data store,提供因果一致性
GentleRain用periodic aggregation protocol来决定更新是否能被其他人看到
GentleRain通过一个标量的时间戳来实现因果一致性。时间戳是从loosely synchronized physical clocks导出的,时钟漂移不会影响因果一致性,但是可能导致推迟一个更新被他人可见的时间。
Introduction
一个在Geo-replication data store的关键决策就是一致性模型。选择强一致性模型可以让我们有更简单的语义,但是延迟会增加,并且不能容忍网络分区。而最终一致性模型可以提供很好的性能,并且可以容忍网络分区,缺点就是编程模型会变的更加复杂。
大型的数据中心会将数据分区用来存储非常大的数据集。(这里有一个比较有意思的地方,他说:Recent papers have shown how to implement causal consistency in a replicated partitioned data store without incurring the serialization bottleneck of going thought a single log. 他的意思应该是大型数据中心有一个接受者负责将接受到的数据写入log)
更新是异步复制的,casual dependencies也会随着更新一起发送。在远端的数据中心上,接受者会发送依赖检查消息给其他分区的方式来确认所有的依赖是否已经满足,然后安装新的版本。然而这个方法的缺点就是依赖检查消息的交换可能导致吞吐量的下降。
GentleRain提供了不同的方案:
* GentleRain eliminates dependency check messages for updates
* GentleRain uses only a single physical timestamp to track dependencies
GentleRain相较于其他系统而言会导致更长的延迟(在远端的数据中心中,这个更新可见的所需要的延迟更长)
Motivation
比较causal consistency和eventual consistency的性能
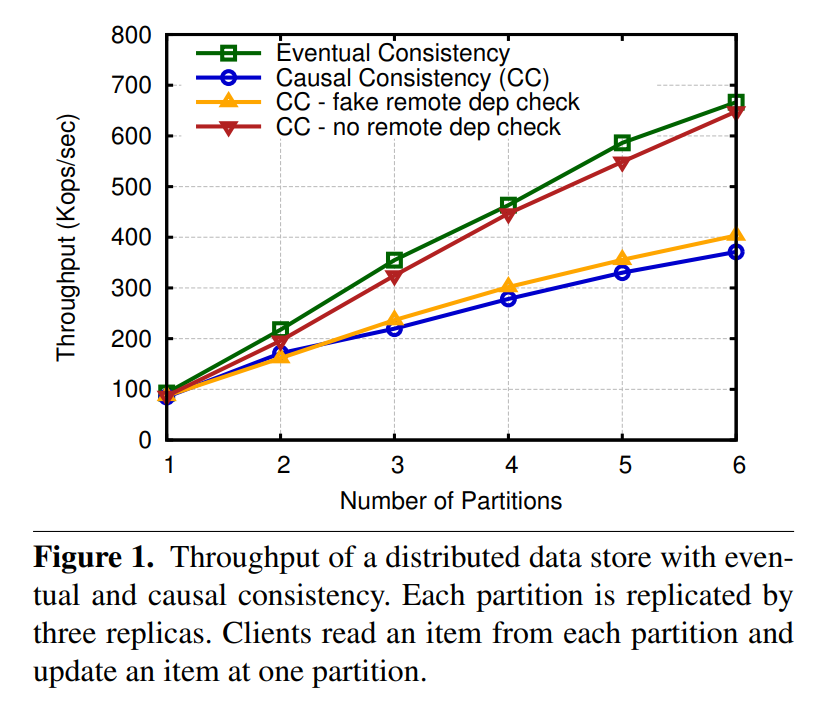
这个workload中,用户会读所有的partition,然后更新一个partition。从而导致跟踪因果一致性的开销变大。
他做的实验是移除掉causal consistency所需要的分片间依赖检查,为no remote dep check,以及不去掉检查,但是去掉计算逻辑,为fake remote dep check。
根据试验结果得到的motivation就是要想提高causal consistency的吞吐量,我们不能引入dependency check message
Definition and Model
Causality
应该Causality都是从lamport的那个文章中来的。也就是happens-before的关系
当以下三种情况之一出现的时候,则出现了因果关系:
* Thread-of-execution. a and b are operations in a single thread of execution, and a happens before b.
* Reads-from. a is a write operation, b is a read operation, and b reads the value written by a.
* Transitivity. There is some other operation c such that a happens-before c and c happens-before b
A store is causally consistent if, when a certain version of a data item is visible to a client, then all of its causal dependencies are also visible.
Architecture and Interface
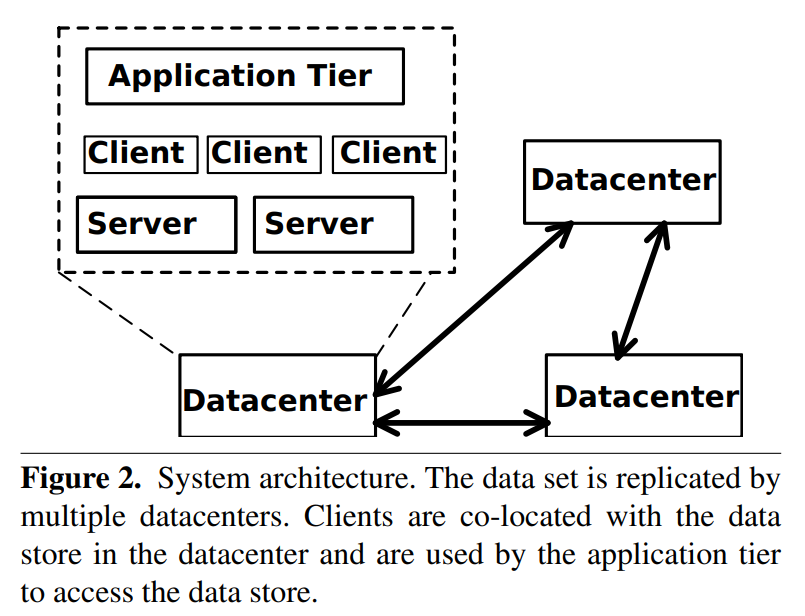
接口:
* PUT(key, val)
* val <- GET(key)
* {vals} <- GET-SNAPSHOT{keys}: 返回一个因果一致的快照。即对于任何一个数据,他依赖的其他数据也会存在于这个快照中。有一个特殊的点就是: Datastore is free is return a snapshot from any point in the past. It can therefore exclude values that have been already ready bt the client before executing the snapshot read.(如果用户曾经读到了一些值的话,说明这些值所依赖的所有数据都已经在这个store中了,我不太明白为什么他会去除掉这些值)
* {vals} <- GET-ROTS{keys}: 和上面的因果一致的快照类似,但是他保证单调读。
GentleRain Protocol
GentleRain的timestamp是物理时间加上partition和replica标识符。这个timestamp可以为所有的更新操作提供全序关系
States
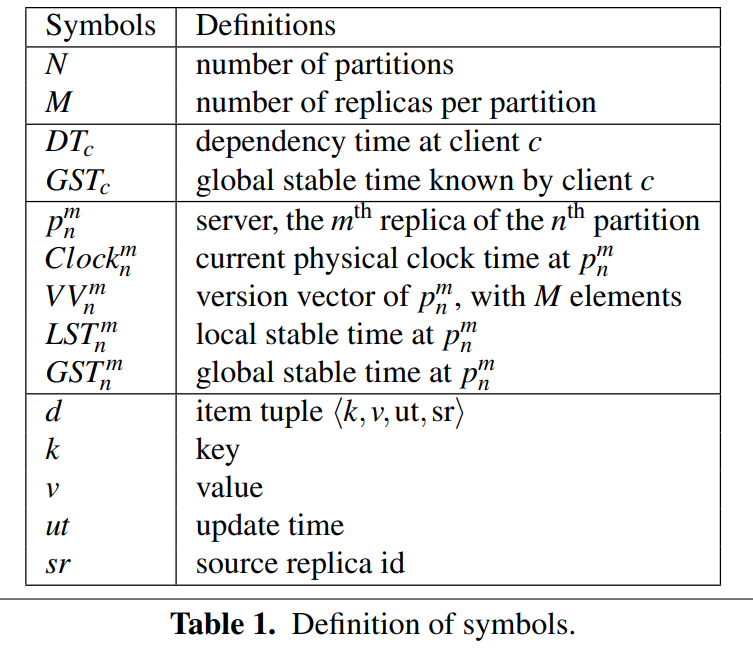
Client States:
客户端会为其会话维护一个依赖时间DT。这个值是client读到的所有数据的最大的timestamp。
同时客户端还会维护GST。
Server States:
每一个服务器会维护一个version vector。VV[i]表示当前服务器已经从副本i处接受了直到VV[i]之前所有的更新
定义LST,local stable time为服务器上的VV的最小值
GST,global stable time为相同data center上的最小LST
Item Version:每一个数据都有多个版本。通过{k, v, ut, sr}来表示一个版本。其中kv为键值,ut为update time,是源服务器创建这个版本的时间。sr为source replica,表示源服务器的replica id
Protocol


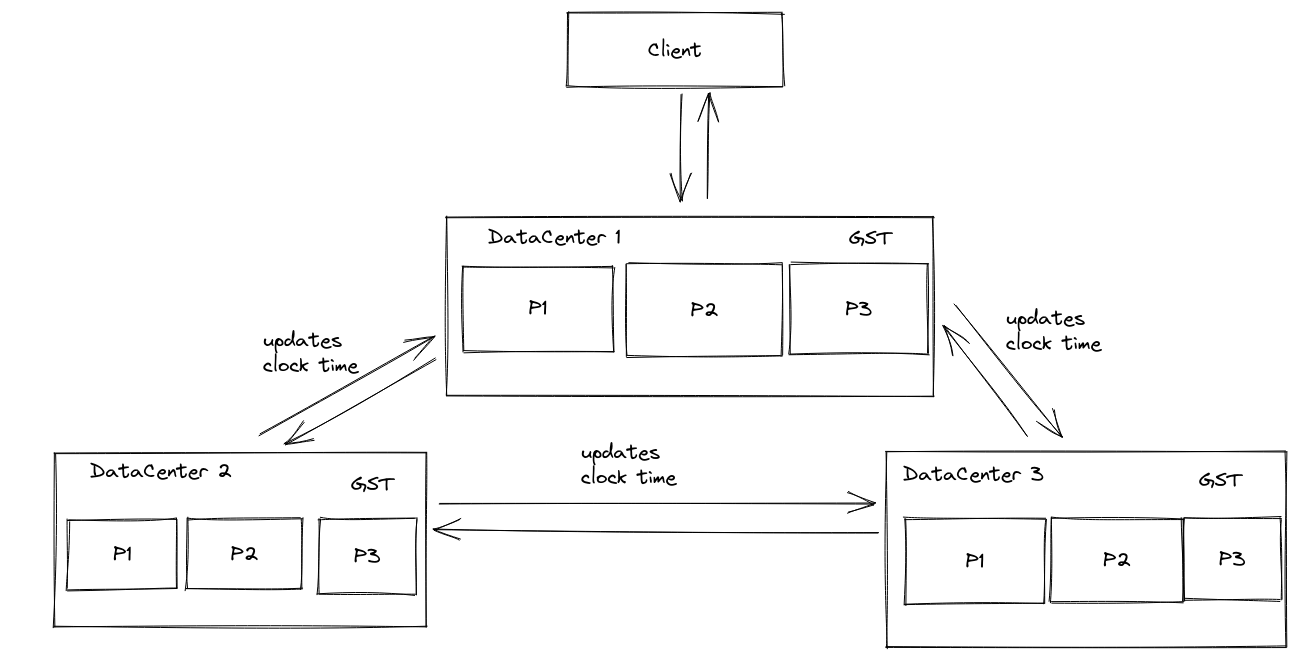
分片之间独立的同步他们的时间戳。通过Version Vector来记录其他分片中的时间。最小的时间记为LST,即local stable time,表示所有小于这个时间的在这个分片上的更新,已经稳定了。
数据中心内部的分片会相互交换信息,统计出所有分片中最小的LST,作为GST。表示任何的更新,如果他的时间戳小于GST,则这个更新对用户可见。(因为在所有分片上的所有副本的时间都已经大于这个时间了,前面的算法可以保证一个更新的时间戳一定大于所有他依赖的更新的时间戳,所以可以保证因果一致性)
Reads of Multiple Items

核心就是确定GST,然后在所有分区执行读就可以

ROT要保证单调读,所以他需要保证之前读到的那些数据被同步到其他数据中心,并更新了GST后才能读。
所以他会等GST更新到DT,然后再执行algorithm3
Conflict Detection
更新冲突的情况下,我们需要外部逻辑来处理这个冲突。
GentleRain的冲突检测有点类似Raft,即新到来的Update会保存他前一个版本的信息。在install new version的时候,他会检查新的Update和前一个版本和当前版本链是否对应。如果出现冲突,则需要外部逻辑来处理。
Efficient Global Stable Time Derivation
相同数据中心的服务器会周期性的交换他们的LST来计算GST。
全体广播的消息复杂度是n方的,所以当数据中心内的分区数很多的时候广播的方法会成为瓶颈
通过树形结构来聚合GST
叶子节点会发送LST给他的父节点,最终GST会聚合到根节点。然后再重新下发
消息的数量很小,但是需要log级别的RTT(数据中心内的延迟很小,相较于数据中心之间的Version Vector的聚合来说开销很小。)
Discussion
Why Physical Clocks
因为lamport clock只有在接受到消息的时候才会增加他的值。从而可能导致不同服务器之间的clock移动的速率差距较大。而GST跟踪的是全局的最小时间,这种情况下可能导致GST推进的速度很慢。
通过物理始终可以避免不同服务器之间的时钟偏差较大。
Throughput vs Latency Tradeoff
在现有的系统中,一个更新在远端变为可见的时间是消息从本地传输到远端的时间加上交换依赖检查消息的时间。而后者是在数据中心内部,所以可以简略的认为是本地到远端的时间。
然而在GentleRain中,延迟有很多的因素。首先就是距离最远的数据中心的传输时间。因为GentleRain要求所有的数据都到了所有的replica以后才能被客户看到。第二点,数据中心之间可能存在时钟漂移。第三,树形聚合协议需要计算GST的时间。最后,当请求数量少的时候,我们需要靠heartbeat protocol来传播时间。总体的时间也是接近于最远数据中心之间的传输时间。

文章评论