Percolator Tutorial
Percolator是google推出的用来做增量计算的系统,主要用来替换MapReduce在Google Indexing System中的作用
这里我们只关注Percolator中的事务模型
前置知识:
* 2PC - 保证跨分区事务的原子提交
* Bigtable - 底层存储,可以看作是分布式KVS
* MVOCC - 并发控制算法
Bigtable
Bigtable是Google基于GFS的一个存储系统
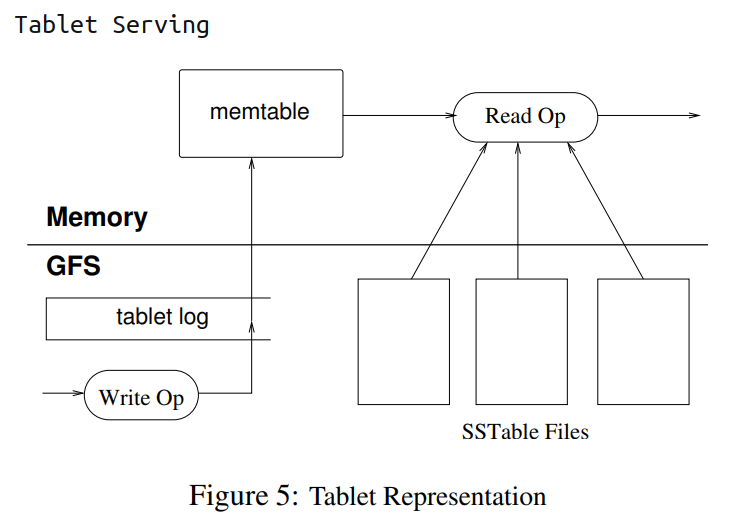
不看容错的话,就是一个LSM-Tree
和现代KVS不同的是,Bigtable的容错是在GFS上做的。而现代KVS的容错则是在上层。
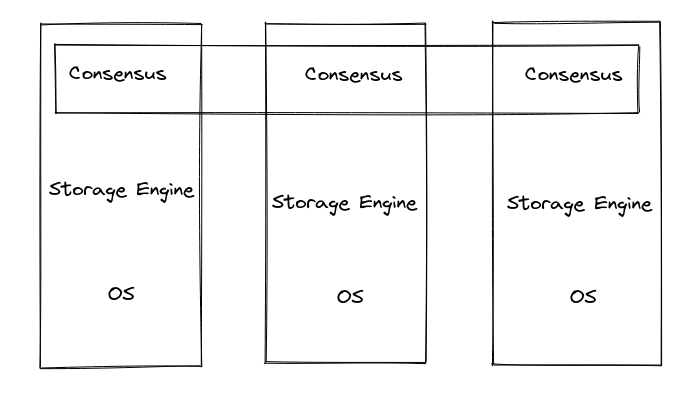
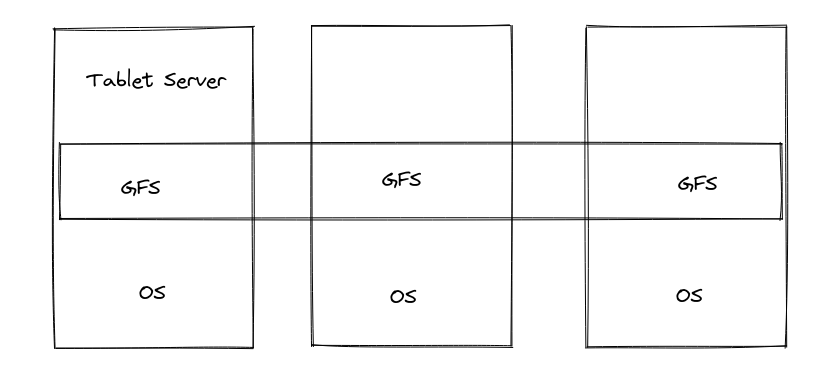
Bigtable还有几个比较关键的特性,决定了后面Percolator的设计:
* 稀疏列:和关系模型中的表不同,每一个主键所确定的一行数据并不一定是“满”的,也就是说并不是所有列都有数据
* 多版本:Bigtable在存储层就支持多版本的数据,所以在索引一个某一个属性的时候,我们需要通过主键+列名+timestamp来得到具体的数据
* 行事务:Bigtable支持行级别的并发操作
实现细节,通过普通kv来实现支持多版本和稀疏列的时候。我们可以简单的拓展主键为:primary_key#column_name#timestamp
MVOCC
基于有效性检查的多版本并发控制,这里我们的目标是提供SI,核心思路如下:
- 写操作:写入本地写缓冲中
- 读操作:当写缓冲未命中的时候,读原始数据,否则读写缓冲的数据
- 提交检查:设当前事务的时间戳为StartTS和CommitTs, 提交检查分为两种,先提交者胜和先更新者胜,这里主要说先提交者胜。
-
先提交者胜:
fn Commit(txn) {
for row in txn.write_set {
// acquire the lock on current row
while !try_lock(row) {
let txn_id = GetOwner(row);
WaitUntilTxnFinish(txn_id);
if IsCommit(txn_id) {
// data item has been updated
Abort();
}
// another approach would be whenever we encounter
// situation that might lead to lost-update, we abort
// immediately
}
// data item has been updated
if row.latest_version > StartTS {
Abort();
}
}
// if all locks has been acquired, perform write
for row in txn.write_set {
PerformWrite(row);
}
return true;
}
核心思路就是提交的时候获取所有写集上的锁,当一个事务的所有的锁都能成功获得的时候,我们才写入再提交。
2PC
上述MVOCC的算法的过程和2PC非常类似。提交的时候第一阶段先获得所有的行上面的锁。第二阶段进行写回。
单机情况和分布式情况的区别就在于,如果单机数据库挂掉了,所有人都会挂掉。而分布式数据库一个节点挂掉了,其他人很可能还在线。
那么在上面的算法中,如果一个获得锁的事务的节点挂掉了,他就会一直阻塞其他的人。
因为是否提交的话语权在协调者上面,而我们又不能保证协调者会一直在线。Percolator的一个很棒的思路就是将协调者的职务下放到存储层。
由于存储层容错能力较强,所以我们只需要从存储层获得事务是否提交的信息即可。
Percolator

```C++
class Transaction {
struct Write { Row row; Column col; string value; };
vector<Write> writes_;
int start_ts_;
Transaction() : start_ts_(oracle.GetTimestsamp()) {}
void Set(Write w) { writes_.push_back(w); }
bool Get(Row row, Column c, string *value) {
while (true) {
bigtable::Txn T = bigtable::StartRowTransaction(row);
// Check for locks that signal concurrent writes
if (T.Read(row, c + "lock", [0, start_ts_])) {
// there is an pending lock; try to clean it and wait
BackoffAndMaybeCleanupLock(row, c);
continue;
}
// find the latest write below out start-timestamp
latest_write = T.Read(row, c + "write", [0, start_ts_]);
if (!latest_write.found()) {
return false; // no data
}
int data_ts = latest_write.start_timestamp()
*value = T.Read(row, c + "data", [data_ts, data_ts]);
return true;
}
}
// Prewrite tries to lock cell w, returning false in case of conflict
bool Prewrite(Write w, Write primary) {
Column c = w.col;
bigtable::Txn T = bigtable::StartRowTransaction(w.row);
// abort on writes after out start timestamp
if (T.Read(w.row, c + "write", [start_ts_, *])) return false;
// ... or locks at any timestamp
if (T.Read(w.row, c + "lock", [0, *])) return false;
<pre><code> T.write(w.row, c + "data", start_ts_, w.value);
T.write(w.row, c + "lock", start_ts,
{primary.row, primary.col}); // primary's location
return T.Commit();
}
bool Commit() {
Write primary = writes_[0];
vector<Write> secondaries(writes_.begin() + 1, writes_.end());
if (!Prewrite(primary, primary)) return false;
for (Write w : secondaries)
if (!Prewrite(w, primary)) return false;
int commit_ts = oracle.GetTimestamp();
// commit primary first
Write p = primary;
bigtable::Txn T = bigtable.StartRowTransaction(p.row);
if (!T.Read(p.row, p.col + "lock", [start_ts_, start_ts_]))
return false; // aborted while working
// pointer to data written at start_ts_
T.Write(p.row, p.col + "write", commit_ts, start_ts_);
// clean lock before commit_ts
T.Erase(p.row, p.col + "lock", commit_ts);
if (!T.Commit()) return false; // commit point
for (Write w : secondaries) {
bigtable::Write(w.row, w.col + "write", commit_ts, start_ts_);
bigtable::Erase(w.row, w.col + "lock", commit_ts);
}
return true;
}
</code></pre>
}
```
Percolator的核心思路就是将提交点放到第一个写入的元素上面。当我们的所有锁都获得了以后,如果第一个写入元素成功提交了,那么整个事务也就提交了。
所以他会在锁上面记录primary的位置,方便其他事务去检查当前持有锁的事务是否提交了。
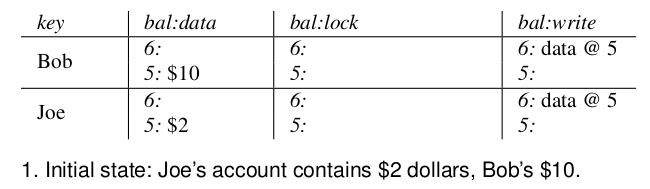
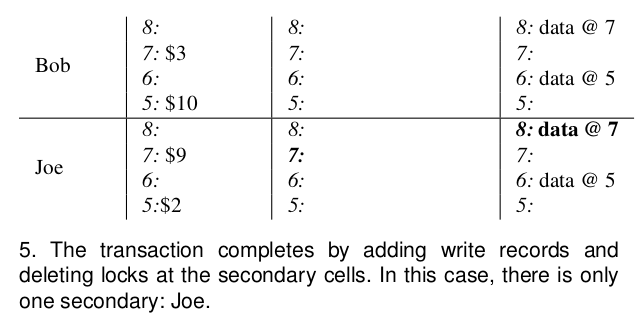
转账的例子,从Bob转账7刀到Joe上




文章评论