Don't Hold My Data Hostage - A Case For Client Protocol Redesign
Abstract
我感觉之后我还是把摘要整个写一下
从数据库传输大量的数据到客户端是一个相当昂贵的操作。这个传输时间可以很容易就占有整个语句执行时间的主导部分。这对于一些外部数据分析的工具来说是一个很大的影响。在这篇论文中,我们将分析并探索将结果集序列化的设计空间。通过实现表明现有的方法都会有性能不足的情况。然后我们提出了一种列式的序列化方法。
(我猜测是不是通过列式存储提高压缩率,从而减少网络负担)
Introduction
Result Set Serialization(RSS)对整个系统的性能有比较大的影响
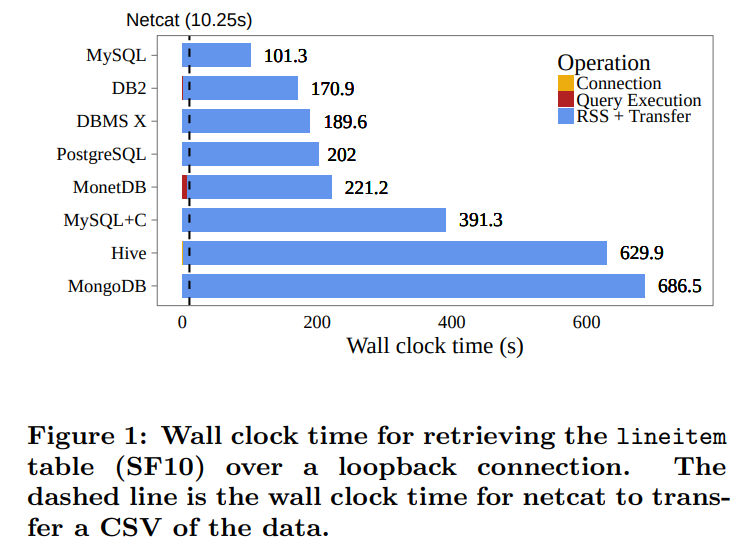
本地环回的传输时间
可以发现基本上所有的时间都是在做网络传输(我好奇linux不会对本地环回优化吗?比如引入zero-cost copy之类的)
现有的大多数分析工具都要求传入一个已经在内存中的数据表,并且即便是支持从数据库加载数据的工具,也会受到网络的限制。
有一些工作则是希望在数据库内部执行计算,从而避免数据的传输。然而这种大规模的系统级计算不容易实现以及优化
main contribution为:
1. benchmark了不同的序列化方法。并解释了他们为什么是这样,以及他们设计上的缺陷。
2. 探索了序列化方法的设计空间,调查并测评了一些可以用来优化RSS的技术,并且讨论了他们的优缺点
3. 提出了column-based序列化方法
State Of The Art
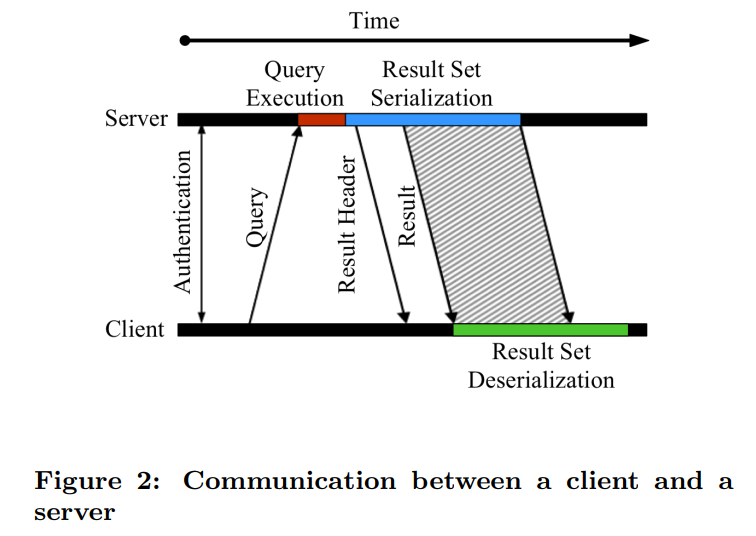
客户和服务器一次交互的过程如图2
结果集的设计决定了每一步的执行时间。如果我们使用了heavy compression,那么结果集的序列化和反序列化就需要更多的时间,然而带给我们的是网络传输的优化。反之,我们可以更快的进行序列化和反序列化,但是代价就是更多的网络传输的时间。
Overview
评测现有数据库的传输时间,隔离开每个部件分别计算。通过netcat(nc)传输一个相同的CSV文件来作为baseline
baseline的作用是为了包含需要传输这些数据的时间,而不引入额外的database-specific overhead
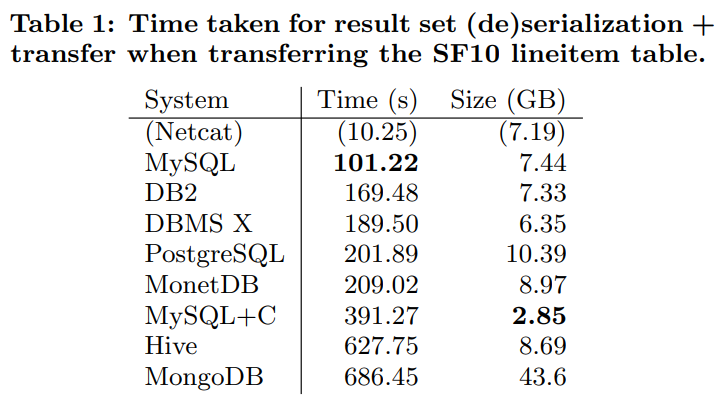
table1显示了隔离后的传输数据。没有系统可以接近baseline的速度
(我在想他这个测试是不是不太公平,毕竟loopback的传输开销很低。但是看table1的size貌似也不能说明数据库就是在压缩,可能是因为额外的overhead导致的?)
mongodb是文档模型,所以传输数据也传输了每一个field name,导致开销很大
文章中也说了loopback传输开销低,所以大多数的时间都是在做序列化和反序列化。但是即便如此这些文件的大小也没有小,甚至还大了
Network Impact
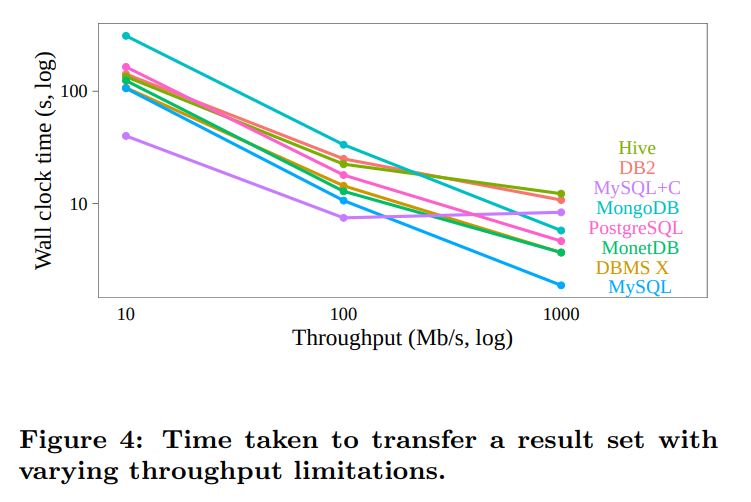
netem是linux的工具,可以用来模拟有限带宽以及延迟下的网络连接。测试他们传了1百万行数据
限制延迟:
延迟增加将导致传输数据的固定开销增加,因为我们需要更长的时间去传确认包。
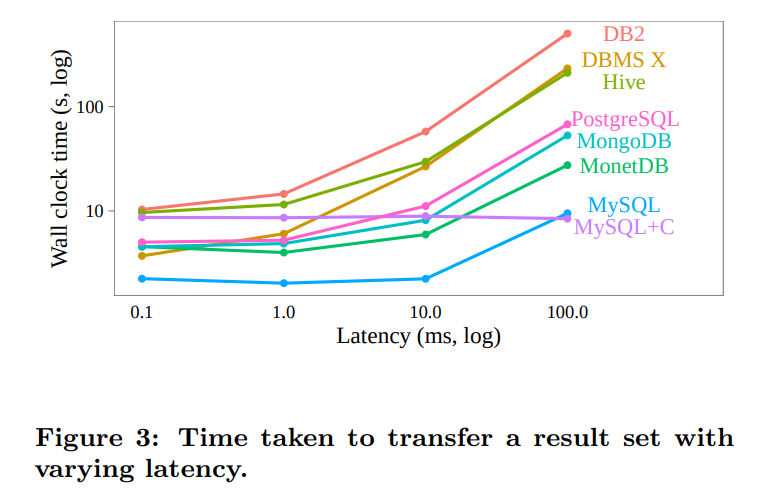
DB2和DBMS X貌似显式的发送确认包,从而导致了更多的开销。即便是没有显式发送确认,底层的TCP也会这样做,从而导致传输速度减慢(我在想如果我们可以显式的增大tcp缓冲区的长度是不是可以缓解这个问题,让他可以pipeline)
限制吞吐:
这里指的就是限制带宽
限制带宽意味着在socket上发送的字节越多,我们的性能就会越差。所以随着带宽的降低,数据压缩就越来越重要
Result Set Serialization
这一节是有关序列化的编码

对于每一种格式,我们给出他们对table2的16进制编码
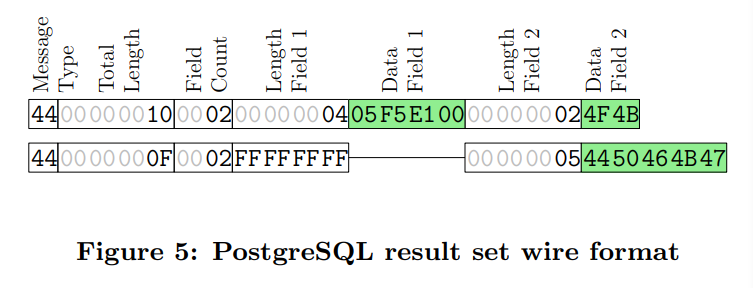
postgres的方法,每一行都是一个独立的消息。每一行包含了总长度,属性数量,每个属性的长度,以及数据。
我们可以发现很多的数据都是冗余的,比如对于一个结果集来说,属性数量应该是一个定值
这解释了为什么上面postgres会传那么多的数据了。但是在另一个方面,这种方法可以让我们更快速的进行序列化和反序列化。

figure6是MySQL/MariaDB的协议。每行是一个3字节的数据长度。然后是一个一字节的packet sequence number(0-256,循环)。然后是每个域的长度,以及对应的数据

DBMS X的编码格式。每一行是一个header,加上所有的值以及他们的长度。并且长度是变长的。
底层DBMS X还用了固定的网络消息长度来进行批量传输,应该是一个消息若干行
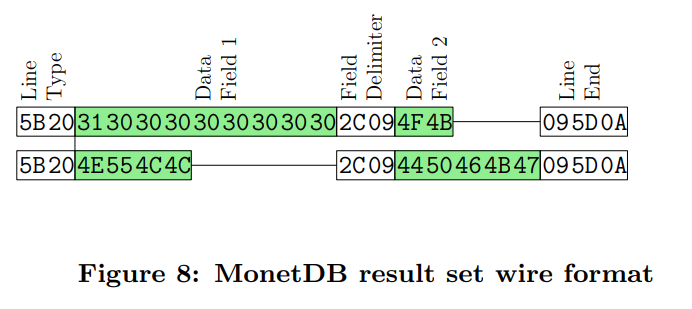
MonetDB。他是text-based序列化方法,所以显示出来的就是ASCII码的编码方式。
虽然这种方式很简单,但是将内部的值转化成test,再反序列化回去是比较耗时的。
值与值之间通过特殊的分割符话分开,就类似CSV一样
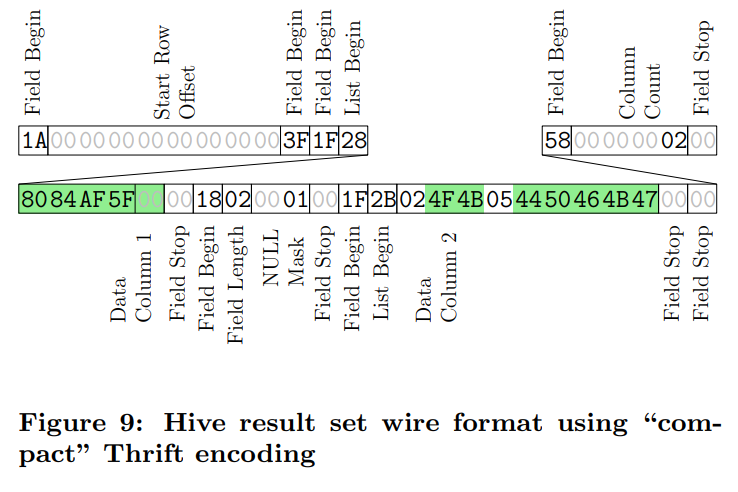
Hive,使用的是基于Thrift的协议
编码中包含了各种元数据字节,从而允许在客户端处将数据进行反序列化
而且看这个表示也可以发现他是列存的,把每个列存在了一起。
列存的特性让元数据的存储不取决于结果集的行数。
Hive在benchmark中表现的很差,这可能是因为在整数列中,每一个值都是变长的。导致我们反序列化会比较慢。
(这么看的话,metadata可以让我们self-contain,但是需要额外空间。fixed-length可以加速序列化,但是会浪费空间。而variable-length虽然节省空间,但是序列化较慢)
Protocol Design Space
protocol的设计空间是一个在computation和transfer的trade-off。如果computation不是问题的话,那么heavy compression会比较好。如果transfer不是问题的话,比如服务器和数据库是在一个机器上的。那么我们就可以选择以更多的数据传输来换取更小的计算代价
Protocol Design Choices
Row/Column-wise:
和存储的选择一样,我们在发送消息的时候也可以选择是按照列式进行序列化还是按照行来序列化
对于行存储的格式来说,优点就是目前的ODBC/JDBC提供的API主要针对的是row-wise access。并且数据库的客户端也是按照行来输出他们的数据的
对于列式序列化来说,优点则是压缩的比率更高。并且目前的数据分析系统在内部都是按照列来存储数据的。所以当数据以行发送过来的时候,他们会首先在内部转换成列式的存储。如果我们使用列式传输的话则不需要这个过程
列式传输的缺点就是一个列必须要等上一个列传完才能开始。如果用户希望访问一行,那么他需要缓存整个数据集
我们的选择则是一个折中。vector-based protcol。在chunk内部是列式编码,访问一行的时候只需要缓存一个chunk
Chunk Size:
当以chunk的格式发送数据的时候,我们需要确定chunk的大小。
chunk越大意味着服务器和客户端需要越大的缓冲区来缓存chunk
然而chunk越小意味着我们不能通过列式编码得到更好的压缩比
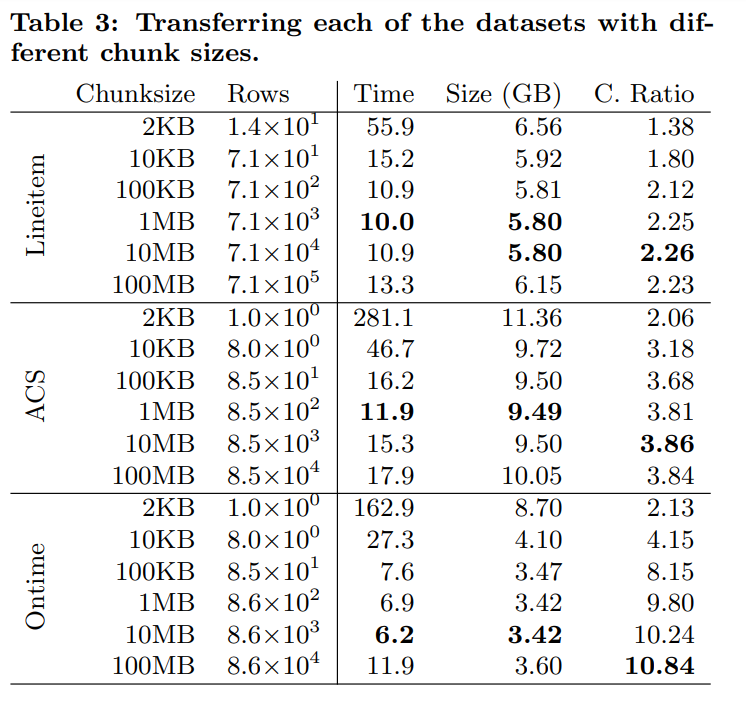
通过实验可以发现压缩比率收敛的很快,并且在chunk size为1mb左右的时候达到了最优性能。这意味着用户可以不需要缓存很大的chunk来提高performance
Data Compression:
Compression Method也是一个比较关键的点。轻量级的压缩工具比如Snappy和LZ4的目的在于快速压缩。而重量级的攻击XZ则是追求压缩比。GZIP则是在他们之间的一个均衡
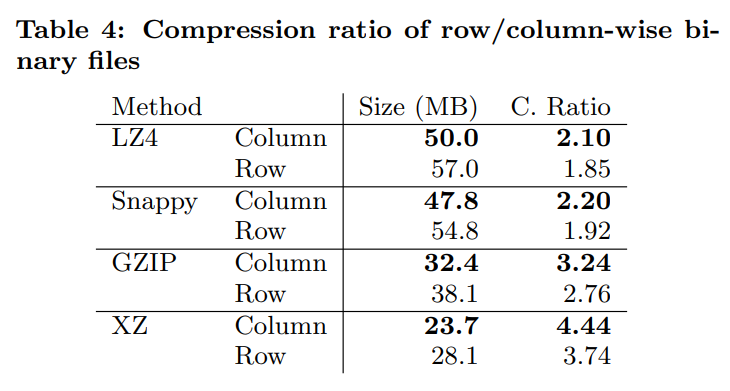
可以看到即便是使用了data-agnostic compression method,列式的也比行式的压缩比更高一些。
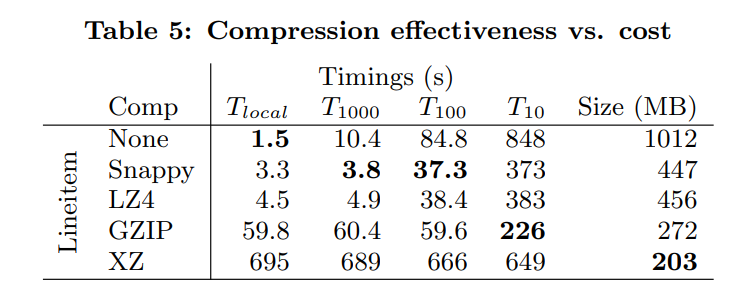
这里是不同的带宽下进行数据传输的开销。T1000表示的就是1000MB/s
可以看到高带宽情况下轻量级的压缩方案更好。而低带宽的时候,GZIP表现的更好一些。
虽然XZ有很高的压缩比率,但是主要耗时都是在压缩的地方,导致他表现的不好。
选择那种压缩方法完全由带宽决定。所以我们使用一个启发式的方法。当数据库和用户在同一个机器的时候,我们不进行压缩。否则就使用轻量级压缩。因为现实场景中他们或者使用的是LAN,或者是高速带宽
Column-Specific Compression:
除了通用的压缩方案,我们还可以单独为列进行压缩。比如RLE,或者delta-encoding
通过这些特殊的压缩方案我们可以得到更高的压缩比率以及更小的开销。整数可以使用更加快速的vectorized binpacking(我猜可能是bitmap?)
这里的实验是针对整数来测试这些特殊的压缩算法。
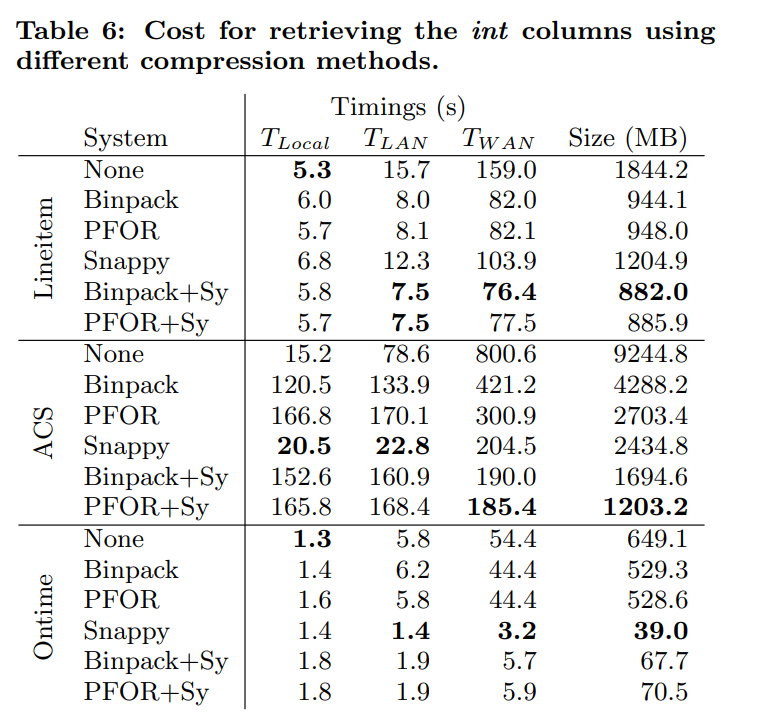
这里的+Sy表示的就是先用特殊算法压缩,然后再用snappy压缩整个消息
然而在ACS数据集中,他们的表现并不好。这是因为当整数的列太多的时候,我们会对每一个整数列都调用压缩算法,从而导致过多次的单列压缩。并且由于列很多,导致每个chunk上的行很少,也影响了压缩的性能。Snappy不会被影响,因为他说data-agnostic的
ontime数据集中这些特定的压缩算法效果也不好,这是因为他们有较大的值,以及最值之间的差值较大。
这些特定的压缩算法对数据分布有一定的要求,并且他们需要一定数量的行才能有效(要求chunk size较大)。所以我们选择不使用这些特殊的压缩算法
Data Serialization:
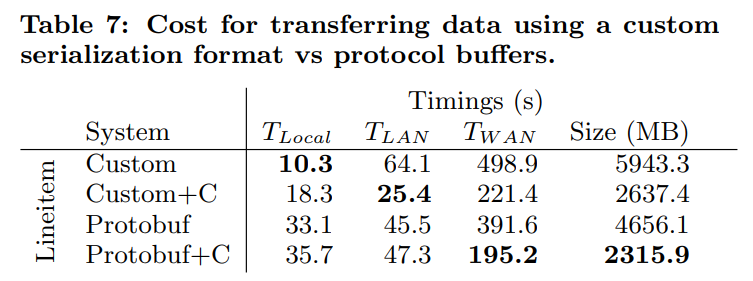
测试不同的序列化方法
由于protobuf是一种通用的序列化方案,他会考虑到传输时候的endian问题,从而导致序列化/反序列化开销昂贵
protobuf会保存变长的int,从而减少消息的大小。
由于protobuf以非常高的开销实现了较低的压缩比,所以我们决定不使用他,而是使用自定义的序列化方案
String Handling:
有三种主要的传输字符的方式:
* Null-Termination
* Length-Prefixing
* Fixed Width
Length-Prefixing需要额外的空间,但是我们可以通过变长的整数来存储字符串长度,从而节省空间。
Null-Termination的好处就是只需要一个byte来分割。但是他必须读完一个字符串之后才能读下一个。
Fixed-Width的优势就是如果字符串大小相同,则我们没有不必要的填充(这里我不太明白,其他的编码应该也没有,他的意思应该是额外的元信息),但是缺点就是对于varchar类型,我们可能有大量的null或者短字符串,从而导致大量的浪费

table8中是传输一个固定大小的字符串,所以对fixed-width来说优势比较大
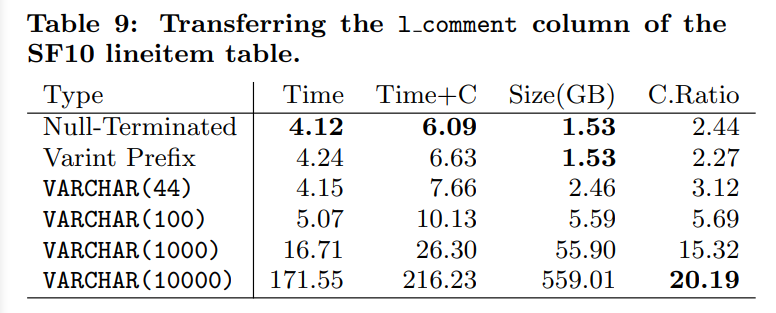
对于fixed-width来说,这里有大量不需要被传输的数据。(可以看到对于44长度的来说,虽然他的大小比较大,但是时间较快,因为我们没有额外的计算开销)
所以我们选择只有在varchar(1)的时候使用fixed-width(即便是varchar(2)使用其他方法都会更好,因为可能会有很多空串)
而对于大字符串来说,我们选择null-termination,因为他具有更好的压缩比率(因为null是相同的值所以可能对于大量空串有较好的压缩率,但是对于fixed-length来说貌似理由也成立。看表的话感觉可能的理由是varint prefix会导致更高的计算开销)

文章评论