Constant Time Recovery in Azure SQL Database
Abstract
这个恢复机制结合了ARIES和MVCC,从而实现了常数时间的恢复。
允许连续的log trucation,从而减少了日志空间的使用量,即使是有长事务的存在(对比Innodb,如果Undo table用完了就不能开新的事务了)
对于云数据库(Cloud database,应该是DBaaS)来说,这个能力是相当重要的,因为:
1. 数据库大小是不断增加的
2. 对于commodity hardware来说,failure很常见
3. 高可用的要求
4. 云平台负责管理和升级软件,所以可能导致对于用户不可预见的failure(这里指的是服务软件的升级由云平台决定,而非用户。如果是用户控制的话他们可能选择一个流量小的时间进行维护)
Introduction
ARIES使用WAL,并且定义了不同的恢复阶段(Scan,Redo,Undo)来避免专用的恢复手段(ad-hoc recovery techniques,这里应该说的是针对不同种类的transaction有不同的恢复技术,而ARIES把这个过程泛化了)
恢复的一个很主要的点就是Undo,我们需要把那些未提交的事务全部Undo,对于长事务来说,这个过程可能持续很久。一个例子就是一个用户尝试在一个事务中加载亿级的数据,然而当数据库在这个过程中崩溃的话,我们需要把加载的这些数据整个undo
在SQL Server中,他有一些针对恢复阶段的优化,比如利用并行来加速恢复。尽管这些优化对于内部部署的数据库是足够的(指的应该是企业内部的服务器部署)。但是当数据库迁移到云端的时候,情况就不一样了:
* 数据库大小的增加通常导致了更长的事务
* 云平台所使用的commodity hardware失效的频率越高,就会导致在此之上的服务崩溃的概率也变高
* 上面提到过的云平台负责管理和升级服务,导致用户不可预见的崩溃
我猜测应该是利用MVCC的版本机制来加速Undo。
有两个要点,一个就是恢复机制和MVCC怎么结合来实现常数时间的恢复,还有一个就是他是怎么允许aggressively truncating log的,对于长事务来说他的log应该只能在提交的时候被截断,否则我们无法保证原子性
Background On SQL Server
第一部分就是正常的ARIES算法
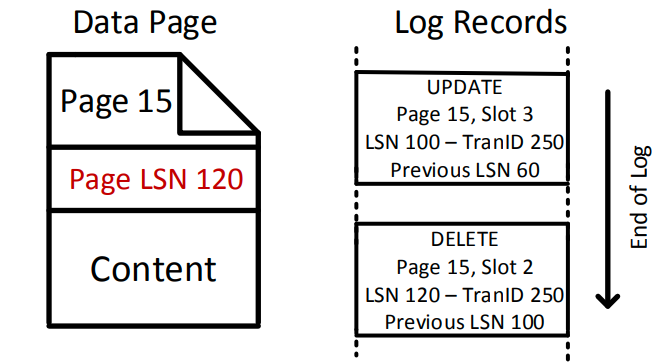
可以看到这里的日志就是物理逻辑的,即日志标识了数据的位置,并且记录了页内的逻辑操作。减少了日志空间的占用。并且相对于逻辑日志来说允许了更高的并发性,并且逻辑更简单,因为逻辑日志依赖数据库的元数据。
但是SQL server在Redo阶段有个变化
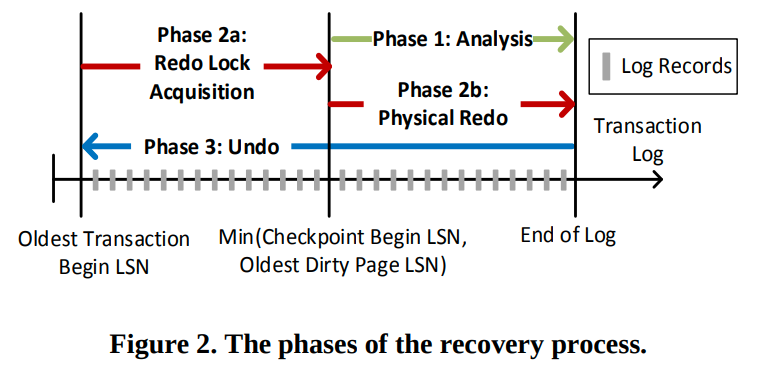
他为了提高可用性,他会记录最小的活跃事务,并获取对应的锁。这样就可以在Redo阶段把数据库恢复到失效前的状态,从而提高可用性(Undo阶段则是启动后再进行)。但是这会导致Redo阶段和最长的活跃事务大小相关(因为我们需要重新获得上面的锁)
Undo阶段会扫描日志,并undo未提交的日志。这个阶段则和未提交的事务的大小相关(或者说是活跃事务的大小)。为了保证Undo的幂等性,我们还需要用CLR来记录undo操作。
MVCC,SQL Server更新会原地更新,然后把老的版本放到version store中。
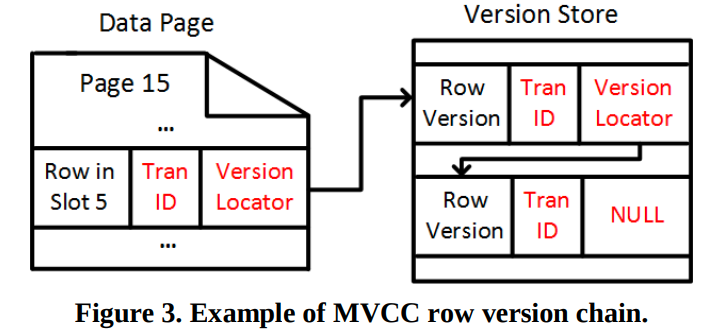
version locator是(PageId, SlotId)
SQLServer会在重启的时候释放掉Version store,因为新的事务看不到老版本的数据
Constant Time Recovery
CTR支持了:
1. Database recovery in constant time, regardless of the user workload and transaction sizes.
2. Transaction rollback in constant time regardless of the transaction size.
3. Continuous transaction log truncation, even in the presence of long running transactions
CTR将事务的操作分成了3类
Data Modifications
之前的存储是把老版本存在version store,然后每次重启丢弃version store。现在则是把所有的版本都持久化下来。每个版本都记录了transaction id,从而允许我们去识别对应事务的状态(active,committed,aborted)。当一个事务回滚的时候,他可以简单的标记为rollback,这样后续的版本链遍历的时候,就会跳过这个版本(这样每次读版本都需要去看一个中心化的结构,不会慢么?)。这样就实现了常数时间的Undo,因为我们只需要打一个标记,不需要回滚具体的数据
System Operations
这个是内部的操作,比如空间分配,B树的分裂等。这些信息不能被versioned。
这些操作会通过短时间的系统事务来执行并且提交。比如当用户需要插入大个的数据并请求空间分配的时候,我们就会通过system transaction来分配空间并且提交。当出现崩溃的时候,这些操作不会被undo。而那些空间以及其他被更新的内部数据结构则会在后台被回收以及修复。
Logical And Other Non-versioned Operations
这个类别下的操作也是不能被versioned,因为:
1. 他们是逻辑操作,比如获得一个锁
2. 这些操作修改的是那些在数据库启动时候,但是在恢复过程开始之前要读取的数据
我们仍然需要log来进行redo/undo,但是这些操作一般都是schema changes等,并且数量会很少,所以CTR通过额外的一类log来记录他们,并且可以在很短的时间内恢复他们。(这个类别就是正常的ARIES了,没有额外的优化)
Persistent Version Store
PVS由于存储了所有的版本,所以他需要回收老的版本,并且处理数据库空间占用大的问题。
为了解决这个问题PVS分成了两层
In-row Version Store

一个tuple(row)存储了不仅是最新的数据,还有delta,用来重建之前的版本
in-row version可以减少存储开销,以及用日志记录新的版本,因为:
1. We effectively log the version together with the data modification
2. We only increase the log generated by the size of diff
这里说的应该是我们不需要额外的日志来记录版本的生成,现在版本的生成以及数据的改变都在行内执行,用一个log就可以记录下来。(第二点我不太清楚,可能意思是只log增量)
为了防止一个row过大,PVS还限制了一行的大小,以及diff的大小。当一行过大的时候,我们就会生成一个新的version
Off-row Version Store
每个database(SQL-level)都有一个version table存储了所有表的off-row version。并且通过传统的恢复技术来保证持久化。就和正常存储一个元组没有区别,只是这个表不需要索引,因为我们是通过version locator来进行遍历的
通过table来简化version的存储,并且针对并发插入是高度优化的。accessor会被分区,并且日志只需要记录redo(保证持久化),而不需要额外实例化一个事务来插入。(分区这个我猜测应该是每个分配表的一部分用来插入,从而避免冲突)
(感觉PVS的核心还是在于怎么回收历史版本,至于存储的话,这个应该相当于是一个append-only version store和delta store的混合版)
Logical Revert
这里就是前面说的,我们在每个版本中记录txn id(可以和timestamp合并),当abort的时候,可以简单的修改事务的状态,而不需要去触碰具体的版本链中的数据。在遍历的时候遇到abort的数据就可以直接跳过。
但是读操作可能需要遍历很多的版本才能读到一个提交的版本。并且一个事务如果想基于aborted version更新的话,他必须先把回滚掉这个abort的数据,再写入新的数据(比如我们希望执行一个read-modify-write,必须先读到一个提交的版本,然后得到新的数据,再计算delta。(这样感觉本质还是因为我们需要很多的读)(也有一个可能是CTR只允许在commit version上进行更新,所以遇到abort version的时候要主动进行清理)
CTR提供了两种机制来回滚abort txn的更新:
Logical Revert:
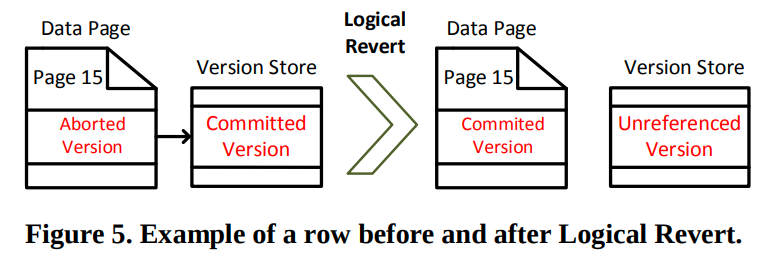
用来把最新的提交的版本带回到main row中。从而避免后续额外的遍历
他会比较目前abort version以及commit version的状态,并做出补偿操作,从而让主存储中的这一行变成提交的版本。而这个操作是在system transaction中执行的。
logical revert是在系统后台进行的,用来回收那些aborted version
Overwrite Abort:
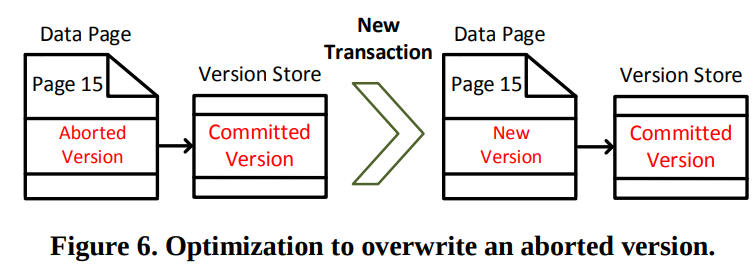
当一个新的事务需要更新一个带有abort version的行的时候,不去使用Logical Revert。(这里的意思应该是更新操作不允许在abort version上进行,而是要先去回滚到commit version再执行)我们可以直接覆盖掉这个abort version,并且将指针指向上一个提交的版本。(我在想他们不考虑in-row version store了么?这里感觉考虑的都是off-row的)
(这么想的话是不是版本链只可能在最前面有一个abort version,其他都是commit version连起来的)
(而且这个机制感觉就像是lazy abortion,abort的时候只打个标记,然后在后续读/写的时候再做清理,或者后台做清理)
Transaction State Management
CTR要求我们跟踪所有的abort txn的状态,直到他们的版本被logical reverted。
(这里的用意应该是当所有的版本都不可见的时候,我们可以把这个txn移除掉。因为后续都不会有人来查询他的状态。)
(我们可以通过read view来跟踪当前活跃事务,遇到非活跃事务的版本的时候,去查询他是否是aborted,就可以知道他是否可见)
CTR将这个信息保存在了Aborted Transaction Map(ATM)中,他是一个哈希表。
当事务abort的时候,他会把自己加入到ATM中。并且添加一个abort的日志。当出现检查点的时候,ATM会被完整的序列化到log中。从而允许我们恢复ATM。
当一个事务所有的版本都被revert了,那么我们就可以把它从ATM中移除掉。移除的这个操作也需要进行log,因为我们需要保证ATM可恢复,所以所有操作都要log。通过FORGET来记录从ATM中移除一个txn
Short Transaction Optimization
对于short oltp transaction,他们的恢复时间本身就很短,当使用了上述提到的技术后会导致增加开销,从而导致性能下降。
CTR动态的决定txn的种类,根据txn的大小,CTR决定txn是否应该被简单的标记为abort(lazy abortion),或者是直接进行undo。(这样看的话任何操作都需要有redo/undo log,但是CTR的Undo貌似不依赖undo log,而是通过版本来进行。正常的undo貌似也可以直接通过版本信息来进行。)
Non-versioned Operations
前面提到的,获取锁,更新元数据等操作不能被版本化,所以我们需要额外的机制来处理
SLog: A Secondary Log Stream
用一个额外的日志流来记录这些信息,并且这些操作一般很少,所以我们可以实现快速的恢复。
SLog一般用作回滚那些non-versioned operation。但是他也可以用在Redo阶段,用来重做logical operation,比如重新获得锁。
SLog在内存中是一个链表
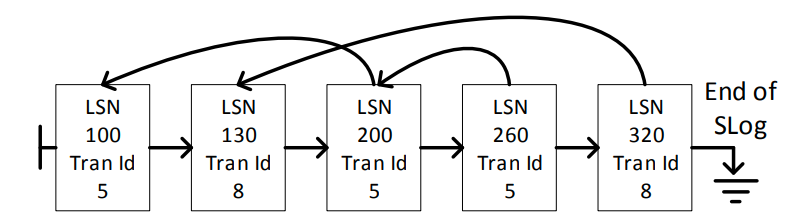
日志同样指向了相同事务的前一个日志,用来快速进行undo
在检查点的时候,我们可以把SLog序列化到transaction log中。并且平常的单个操作也会加入到transaction log中。所以在分析阶段,我们就可以构造出目前的in-memory SLog,并在后续的Redo/Undo阶段使用
我总感觉他这个SLog怪怪的,可能是因为我没有了解过元信息的恢复
我感觉只需要一个特殊的标记就可以在分析阶段重构元信息了
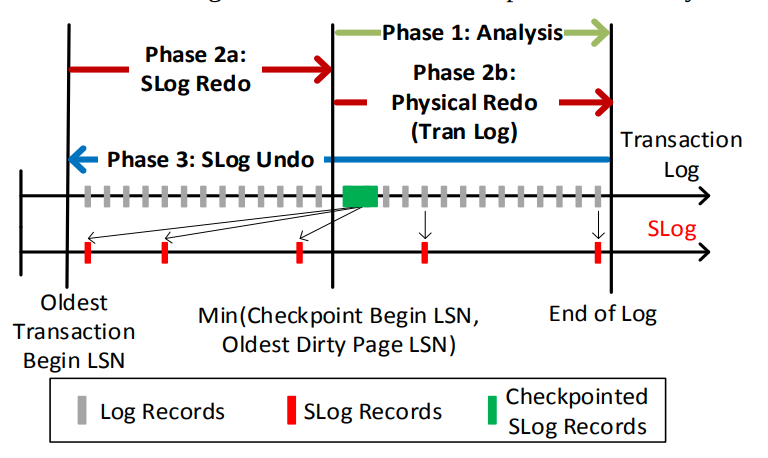
这么看的话可能就是优化了,毕竟如果我们从最老的地方开始扫描的话,虽然也可以重建,但是比较慢。并且逻辑操作不能通过lsn来确定,所以SLog应该是为了保证快速恢复的一个优化
Leveraging System Transactions
我们希望SLog尽量的少,因为恢复阶段都需要SLog来参与,并且SLog是存储在内存中的,相比磁盘更加昂贵。
空间的分配和回收是最常见的不可版本化的操作了。在SQL Server中,这个信息是存储在了一个特殊的元数据页中,包含了一个bitmap用来指示空间分配情况。而我们不希望用SLog来记录空间分配的信息,所以CTR通过系统事务来进行空间的分配以及回收。
在CTR中,新页的分配会通过系统事务立刻提交,并且会被标记为potentially containing unused space,为了防止用户事务回滚后,新页中的数据不再有效。CTR通过后台线程去扫描这样的数据页,并在他们不包含数据项的时候回收这个页。(我在想这个页的回收可不可以让Logical Revert来标识并通知后台线程呢?但是Logical Revert可能不会碰到这些新插入的数据项)
对于释放来说,则是在用户提交的时候,通过SLog来标记这些页。然后后台线程会扫描并通过系统事务来释放之前标记的页。
Redo Locking Optimization
之前SQL Server可以通过在Redo阶段获取锁来提高可用性。但是CTR的Undo非常快,所以我们没必要去跳过Undo阶段。但是仍然是有一些情况需要我们获取锁的,比如分布式事务的情况,我们不能简单的认为事务提交了或者失败了。
前面提到过我们可以通过SLog来获得锁。然而SLog是用来跟踪和获取粗粒度的锁的,比如table lock,或者metadata lock。同时还引入了一个新的机制用来获取细粒度的锁。
在Redo的最后,每个未提交的txn都会锁定他的txn id。当新的事务尝试读取行的时候,他会首先尝试获得对应txn id上的锁。如果这个txn仍然在恢复阶段,那么他就会被阻塞住,直到事务提交或者abort,后续的访问才允许继续进行。当恢复阶段的所有事务都被处理完毕后,后续新的访问就不需要再去获取txn id上的锁了,从而避免了性能的损失。这个机制可以让我们跟踪所有的行级锁,并且不需要额外的跟踪锁的操作。(很显然,提交前,写入日志的那些数据都是已经获得锁的数据,我们直接通过txn id来将锁集中到一起)
Aggressive Log Truncation
这里就可以回答是怎么实现的Log Truncation。对于长事务来说,我们不依赖undo log来实现rollback,而是通过多版本来进行rollback。所以这些log就可以被删除掉。
我们可以截断log到下面三个值的最小值上:
1. 上一次成功检查点的begin lsn
2. 最老的脏页的lsn
3. 最老的活跃系统事务的起始lsn
条件1是保证我们需要redo log来重做操作
条件2也是保证我们可以redo脏页上的内容
条件3则是保证系统事务的恢复,因为系统事务是non-versioned,所以我们需要保存undo 信息
可以发现只要我们及时checkpoint,以及刷盘,那么log可以被截的很短
即便是我们截断了用户的短事务的log,也可以通过version信息来恢复。所以在abort的时候就可以检查当log完整,并且事务大小不超过阈值的时候,就可以用正常的rollback过程。否则就使用标记Abort的过程
Background Cleanup
CTR的后台线程负责:
* 对abort version做Logical Revert
* 将txn从ATM中移除
* 清理在PVS中不需要的版本数据(提交的数据)
Logical Revert and In-row Version Cleanup
为了防止后台线程不断的扫描数据页,SQL Server维护了一个Page Free Space(PFS)页,用来跟踪每个页的大小。在数据更新前,他会用一个额外的位来标识这个页有version。所以后台线程就可以只扫描这些可能含有需要清理的version的页
每过一段时间我们就会唤醒清理线程,然后他会:
1. 对当前ATM中的txn id截取一个快照
2. 扫描PFS页,对于每一个可能有version的页,如果里面含有abort version,则执行Logical Revert。然后移除掉所有SI不再需要的版本(end—ts小于watermark的版本)
3. 清理结束后移除步骤1的snapshot。snapshot的作用就是我们只会删除那些我们已经Logical Revert的事务,而非刚刚abort的事务。(为什么清理新的abort的事务不可以呢?应该只是修改一下计数器而已,感觉遇到abort的就清理也没什么问题。由于我们每次清理后在snapshot中的所有txn都会从ATM中移除,所以我猜测可能是移除的一个优化?比如锁定当前的ATM,创建一个新的,然后后续的查询可以查两个。当清理结束后,我们可以直接移除一个ATM)
Off-row Version Cleanup
off-row的里面只有早期的版本。所以这里的清理只是清理早期版本然后释放空间,即垃圾回收。
off-row table是append only,所以我们可以跟踪额外的信息从而实现页粒度的回收
CTR通过一个哈希表来跟踪每个页中的off-row version,我们只保存每个页的最大的txn id。当这个页的最大txn id已经小于watermark的时候,我们就可以直接回收这个页。这里注意watermark由活跃事务和abort事务共同组成,因为我们需要已提交的版本来做Logical Revert
后面就是一点小优化。
最后的一个思考,CTR实际上是利用了MVCC的特性,将版本信息和Log结合到了一起,从而可以让我们只通过修改txn state来实现批量提交的目的,本质上是批量的将最新的版本通过txn state来删除掉。所谓的SLog实际上就是不能够通过MVCC来处理的信息,我们单独拿出来通过日志来进行redo/undo。所以可以看成是MVCC附带Log信息,然后独立处理非MVCC的数据的一个机制。

文章评论