Serializable Snapshot Isolation in PostgreSQL
Abstract
就是SSI在Postgres中的实现
Overview
Postgres之前只有snapshot isolation。9.1版本提供了SSI的实现。
Postgres的SSI实现必须要和现有的特性结合,而不能像research prototype一样忽略很多细节。比如要支持replication,two phase commit,subtransaction。还有控制memory useage。
和之前的系统,比如MySQL不同的是,mysql之前提供的是基于2PL的serializable,在port到SSI的时候,他可以利用已有的predicate locking infrastructure来处理冲突。对于Postgres,他们构建了一个新的LockManager来处理冲突。
Snapshot Isolation Versus Serializability
主要是提了一下SI发生的异常。一个是最简单的写偏斜。还有一个则是和read only transaction有关的

这里的report希望读到所有batch号为x - 1的receipts。但是在SI的隔离级别中,在figure2的执行顺序下,他没有达成目的。因为他没有读到T2插入的receipt。
和write skew不同的是,除掉t1后,t2 t3本身却是可串行化的。只有在加入t1这个只读事务后异常才会出现。
在这篇paper中作者说出了他的本质原因。The fact that SI allows commit order different than serial order is what causes the anomaly
在上面的例子中,serial order为 T2 < T3,然而由于t3提前提交,导致后来的txn看到了t3,却没看到t2。虽然看到了所有事务的更改,并且没有看到intermediate result,但是仍然发生了异常。
要注意的是,这些anomaly的直接表现都是违背了冲突可串行化的标准。但是他们的成因却有所不同。比如write skew是因为基于过期假设做了决策。而这个由read only txn所导致的异常是因为提交顺序和执行顺序不同,从而导致了读事务读到的状态和可串行化顺序的状态不同。(或者说叫解释的角度不同,冲突可串行化在page model解释事务。而write skew等则是在高层次语义角度解释异常)
有很多的技术是用来避免anomalies:
* 有些workload不会出现异常,比如tpcc在si下也没有问题
* explicit locking。比如LOCK TABLE可以锁住整个table,SELECT FOR UPDATE会在元组上上锁
* materialized the conflict。比如有的冲突可以通过在dummy row上来将冲突显式表示。比如write skew的时候,我们可以固定更新某个特定的row,从而保证这些txn的可串行化。
* integrity constraint。由DBMS保证,和隔离级别无关
Serializable Snapshot Isolation
SSI会让txn运行在snapshot isolation中,但是额外增加了一些检查来避免异常。
SSI的一个特性就是他不会有blocking,那些可能导致违反可串行化的事务会被abort。所以可以提供更好的性能。(有点OCC的感觉)
Snapshot Isolation Anomalies
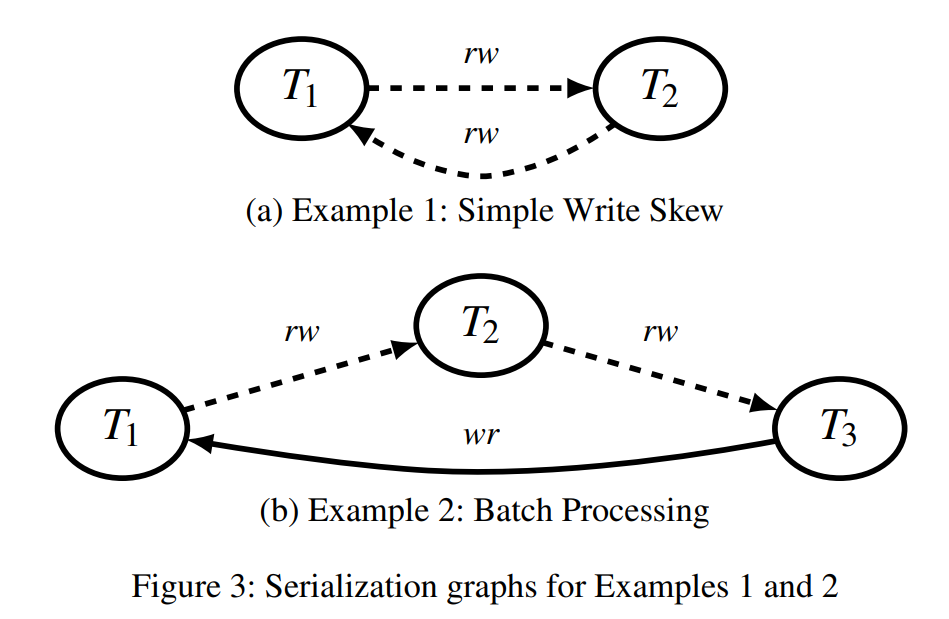
Example1说的是write skew,两个事物都修改了对方读的结果。所以都对对方有rw-conflict。rw-conflict说的是,如果A读了一个t1版本,然后B写了这个tuple,为t2版本,那么A应该排在B前面,因为A没有读到B的t2版本。
而Example2说的就是read only txn引起的问题。2应该在3前面,而1应该在2前面。因为3修改了counter,而2修改了reciept。但是由于T1读到了T3修改的counter,所以出现了问题。
这个其实就是冲突可串行化的依赖图。只不过说的是object level,而非tuple level,目的是包含谓词读。
Serializability Theory
在wr依赖中,如果A到B有wr依赖,那么A一定在B之前提交了。这样B的snapshot里才会有A。而ww也是一样的道理。A一定在B之前提交了。
对于rw来说,他发生于并发的事务。因为一定是一个事务活跃的时候,另一个事务开始了,所以读事务看不到写事务的结果,从而要求读事务排序在写事务之前。
有研究发现在SI中的anomaly,至少存在着两个rw-antidependency edge。并且这两个edge一定是邻接的。


(TODO:感觉这里还需要深入理解一下。rw依赖是因为在SI中并发的事务无法看到对方的修改,从而隐式的确定的了一个顺序。至于为什么T3要最早提交,我感觉是因为如果T3没有提交的话,T3无法构成和T1的WR或者WW依赖。从而组不出环。)
SSI
SSI的思路类似serialization graph testing的并发控制方法(他会在运行的时候检测是否出现环,从而保证可串行化。个人猜测应该是一个读或者一个写就是一个object。每次新的object都要和现有的object做判断,如果有交集就连边,然后判断是否有环。)
不同的是他检查的是dangerous structure,即两个相邻的rw-antidependency edges。如果某一个txn有一个rw入边和一个rw出边,那么SSI就会abort掉其中一个txn。好处就是SSI不需要去检查wr以及ww。从而可以提高性能。
在S2PL中,以及OCC中,他们不会允许rw的产生。假设我们拆掉了之前例子中的只读事务T1,在OCC中,是不允许提交的。因为T2的读集被修改了。而在S2PL中,读会阻塞写者。所以T3会在T2完成后才能修改。而在SSI中,这是被允许的。并且没有异常会出现。从而允许了更高的并发度。
SSI的论文中。要求我们在读的时候在元组上加上SIREAD的锁。他不会阻塞并发的写入。而是会检测在SIREAD上的写所引起的rw-antidependency。并且这个SIREAD在txn提交后还应该存在。比如write skew的情况下。我们在读的集合上加上SIREAD,然后T1写入x,T2也加上SIREAD,然后T1提交了,这时候会有T2 -> T1,T2这时候写入y的话,会检测到T1 -> T2,那么T2应该abort。如果释放掉SIREAD的话,在T2写入y的时候就会检测不到冲突。
上面的推论2中说明了SIREAD必须要在所有并发的事务都结束后才能释放。(怎么实现呢?维护high watermark?)
Variants on SSI
在理论1中,说两个邻接的rw边,并且T3的提交时间要大于T1。如果我们可以保证T1或者T2先提交。那么就可以避免某些false positive的情况(即有相邻rw边,但是提交顺序不满足的时候)。Postgres使用了这个优化。然而他并不能清除掉所有的false positive。因为我们还需要保证有环。比如在上面的例子中,如果只读事务不读batch number,那么T3到T1不会有wr依赖。从而可以达到可串行化的执行顺序。
Read Only Optimizations
Theory

证明这里就不说了。但是可以通过这个理论来减少read only txn的false positive的情况。即当T1是一个read only txn的时候,只有在t3在t1获取他的snapshot之前提交,才可能出现问题。即T1一定要能读到T3的snapshot。
Safe Snapshots
这个说的就是snapshot可能会出现问题,比如上面那个read only的txn生成的snapshot可能读到的是不对的数据。所以Postgres会跟踪生成snapshot时候的并发的事务。最开始他和普通的事务是一样的,要加SIREAD锁,当并发的事务都提交了以后,这时候的snapshot就可以不用再加SIREAD锁
Deferrable Transactions
说的是长时间运行的可能被abort,并且加SIREAD也会导致很大的开销。所以他会等待其他的并发事务运行完毕后,再开始运行,从而避免加SIREAD锁。
Implementing SSI in PostgreSQL
PostgreSQL Background
之前的Postgres提供两种,SI和RC,其中RC每次query都会获取一个最新的snapshot。而SI只有一次。
Detecting Conflicts
对于rw-conflict,这里有两种情况。分别是先写再读,以及先读再写。注意rw说的是读事务要排序在写事务之前,而非真正的发生在他之前。比如在写事务提交之前,读事务读到了一个之前的版本,这时候就会出现rw-conflict。在postgres现有的实现中,通过xmin和xmax来确定tuple的可见性。当一个读者在遍历tuple的时候,发现xmin是一个活跃的事务。或者他读到的xmax也是一个活跃的事务。说明出现了rw-conflict。这时候读者就必须在写者之前提交。
而对于读者先的情况,Postgres构建了单独的SIREAD锁表。用来添加SIREAD lock,以及检查冲突。这样就可以检测到所有的rw-conflict。
Implementation of the SSI Lock Manager
读操作会在tuple上SIREAD lock。而对于索引读,则会在B+Tree的页级别来上锁。
虽然使用了多级粒度的锁(page, tuple, table),但是意图锁是没必要的。我们可以按顺序检查各个级别的锁。从而防止并发的锁更新的问题。(这个目前我也不太清楚,我个人感觉意图锁和多粒度的锁的目的是一样的)
SSI lock mananger需要额外处理的东西就是当有DDL来的时候,lock manager中那些通过物理位置定位的锁会失效。比如锁住的是某个tuple id。当DDL修改table之后,tuple会移动位置。所以这时候我们会将SIREAD转移到表级别。同样在索引失效的时候,索引上的锁也会转移到表级别。这些问题在S2PL的LockManager中不会有问题,因为read lock会阻塞DDL(intention lock)
Tracking Conflicts
我们的核心目的是跟踪连续的rw边。不同的实现有不同的方法。原始的SSI说每个transaction可以维护两个bit,代表是否有入边,以及是否有出边。
Postgres的选择是跟踪所有的rw边。因为Postgres希望实现上面提到的commit ordering优化。即只有T3提交时间比T1和T2早才可能出现问题。所以我们不能简单的记录一个bit。而是需要记录具体的txn id,从而知道txn的提交时间。并且当有一个txn abort的时候,我们还可以去除掉这些rw边。
Postgres提到他们没有选择跟踪wr和ww关系的一个原因是这些依赖可能存在于外部。
比如上面Example2中的例子。如果T1会划分为两个txn。一个读batch number,一个根据读到的x去读reciept。
这时候依赖图会变成这样
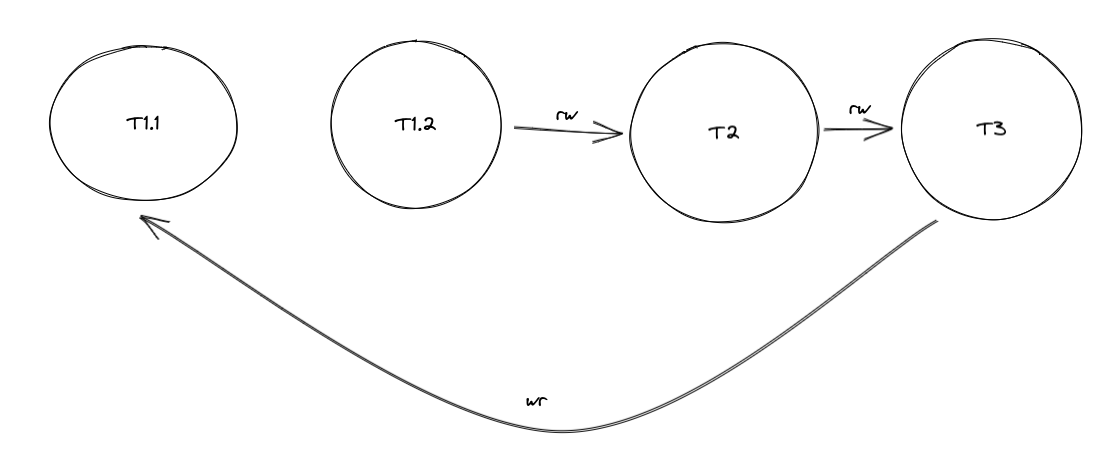
其中T1.1到T1.2的依赖会变成因果依赖。这是数据库系统跟踪不到的。
Resolving Conflicts: Safe Retry
当发现了危险的结构的时候,我们希望要abort掉的txn具有某些性质:

这里有三条规则
1. T3 commit之前不要abort事务。因为我们要使用commit ordering optimization
2. 总是尝试abort T2。因为T3已经提交了。当T2 retry的时候,他一定不会和T3并发,构成rw依赖。所以不会出现相同的结构。
3. 假如T2已经提交了。那么就abort T1。这样也是安全的。因为T1不会再和T2,T3并发。
(说白了就是T1和T2都存在的时候不要abort T1)
由于我们没有在出现危险结构的时候立刻abort txn。所以我们也需要在txn尝试提交的时候去检查一下。比如T3在提交的时候会发现这个结构。那么他会尝试abort掉T2,来让自己提交。
结合上面的理论我们可以猜测一下他的实现方案。由于只有T3是第一个提交的事务的时候才会构成问题。那么当T3提交的时候,我们可以检查T3所有的入边。对于起点的txn,如果他提交了,那么不会构成危险结构。忽略即可。对于未提交的txn,则需要再次遍历他的入边。只有找到了T1和T2都未提交的情况下,我们才需要abort掉链上的T2。

文章评论