WorkStealingQueue
这次我们看看bthread比较关键的两个queue,work stealing queue,以及remote queue
先看work stealing queue
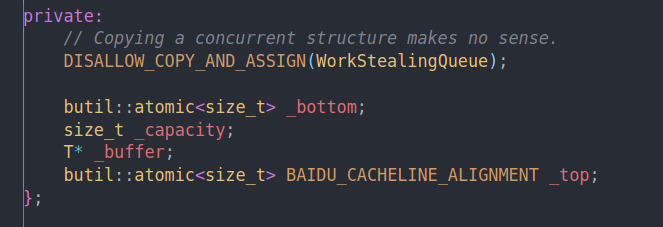
从这个成员变量就可以大概猜出来一些东西。这应该是一个循环队列类似的东西。最朴素的队列应该不太可能,因为性能太差。当然也有可能是一个batch一个batch的分配元素,如果是那样的话我们需要内部维护一个链表,但是这里看貌似什么都没有。
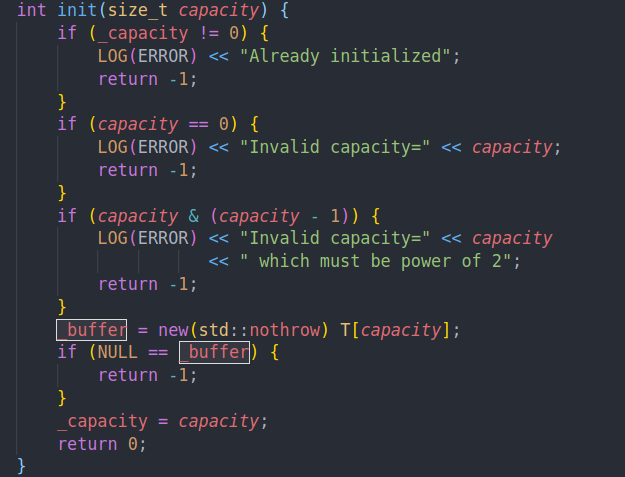
初始化部分可以看到我们是按照2的次幂的大小进行分配空间的
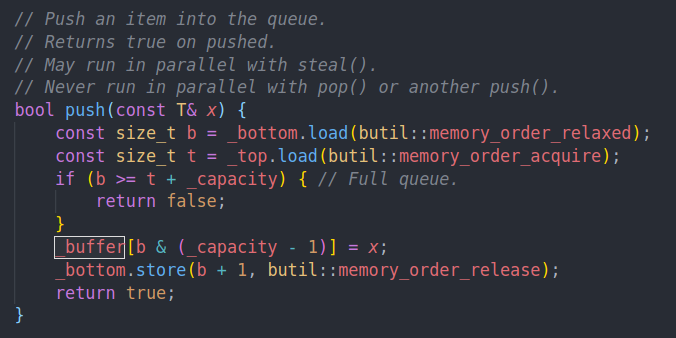
注释中可以看到,push可能与steal并发执行,但是不可能与pop和push并发执行。这是因为一个pthread worker只会在自己的queue上执行push和pop,而在其他人的queue上执行steal
他不会动态的扩大容量,而是在空间满的时候就返回false
以2的次幂为大小的好处就是mod的时候可以简单的通过位运算来实现
然后移动bottom,bottom为队尾,top为队头。这里我们不需要通过原子加来改变bottom,因为不会有并发的插入
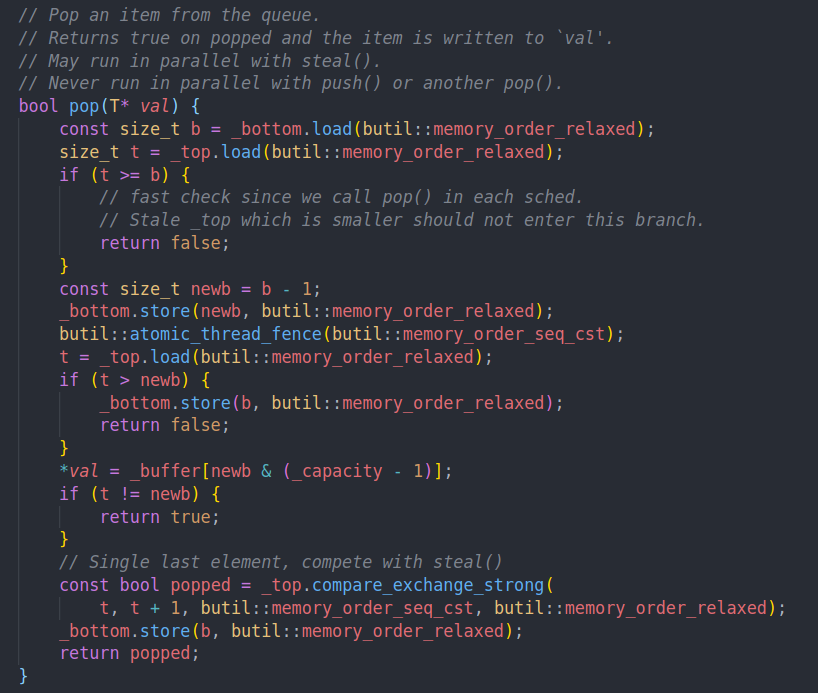
这里的atomic thread fence就是指定这里的memory order,而没有关联的原子操作
表示的是在所有线程的视角中,一定是先有bottom = newb后,才会有加载top的指令。
这里的含义我感觉就是希望看到最新的top,并且要保证bottom已经被保存了。否则的话就有可能pop出一个错误的值。这里我们保证bottom已经减一,然后再加载top,再去比较,就能保证当t小于new b的时候,其他人不可能把我们当前拿到的值pop走,因为他们在看到top的时候,必定已经发现bottom被修改了。
这里的细节很多,由于我们不会有多个线程同时写bottom,所以bottom的写入可以是relaxed的。
这个atomic thread fence + seq cst memory order会生成full fence,所以我们的top是可以读到最新的值的。
这里我们优先从队尾进行pop,从而减少冲突。只有当发现t = newb,也就是当前队列只有一个元素的时候,我们才会通过compare exchange来进行竞争。
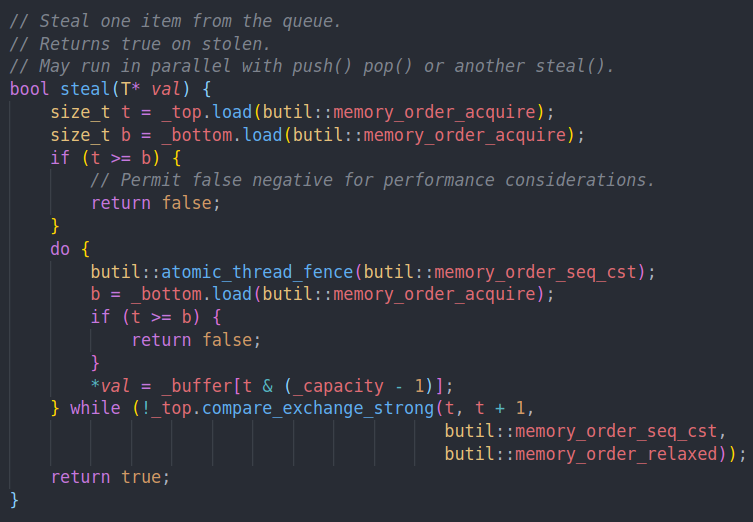
而这里的steal,是从远端的线程执行的,所以我们需要一些比较强的语义。通过acquire load确保读到最新的值。注意我们上面pop中最后存储bottom的时候是relaxed的语义,这并不保证被acquire读到,但是这不会影响结果。因为假如有后续的push,他会通过release来更新bottom。假如没有push,那么无论如何也没有新的元素,steal仍然会返回false
这里注释说了允许false negative,也就是说可能有新的值但是没有被读到。(但是我想不到false negative的情况,因为这要求b是stale value,然而可以进入这个分支的stale value说明这个stale value小于最新的bottom,这只有两种情况,一种是pop中的单元素情况,此时对这个元素的竞争已经结束了,第二种就是pop中t > newb的情况,这时候即便是新的b会进入这个分支)
然后他会尝试不断的通过CAS去拿一个元素,直到队列为空,或者成功获取这个元素为止。这里的load也是acquire的,为了读到最新的值。但是有一点比较奇怪,他会先拷贝这个元素,再去做CAS,这样当T比较大的时候开销会比较大。我个人感觉应该是成功CAS之后再去拿这个元素。
可以看到为了性能考虑这里的实现是相当精妙的。并且充足的考虑了程序的语义。分割开了steal和pop,让本地的pop从队尾进行,从而避免了seq cst的开销。让remote worker通过CAS去竞争。
remote task queue就是一个用mutex保护的queue而已,所以不用细说。
仔细想一下貌似pop中的fence不能保证bottom被其他的线程看到。这时候其他的线程会不断pop直到超过b,然后我们load top,发现top > newb,我们就恢复b,然后返回false。这里感觉fence的意义不大?如果把top的load换成seq cst load会不会效果是一样的呢?
我目前猜测可能是语义的原因,即seq cst fence会插入fence保证全序,而seq cst load可能不会保证bottom的顺序?这里有两种情况,当我们写入bottom锁定一个值的时候,如果有其他的线程在stealing,他可能看不到我们的写入,这时候他会增加top到大于newb。
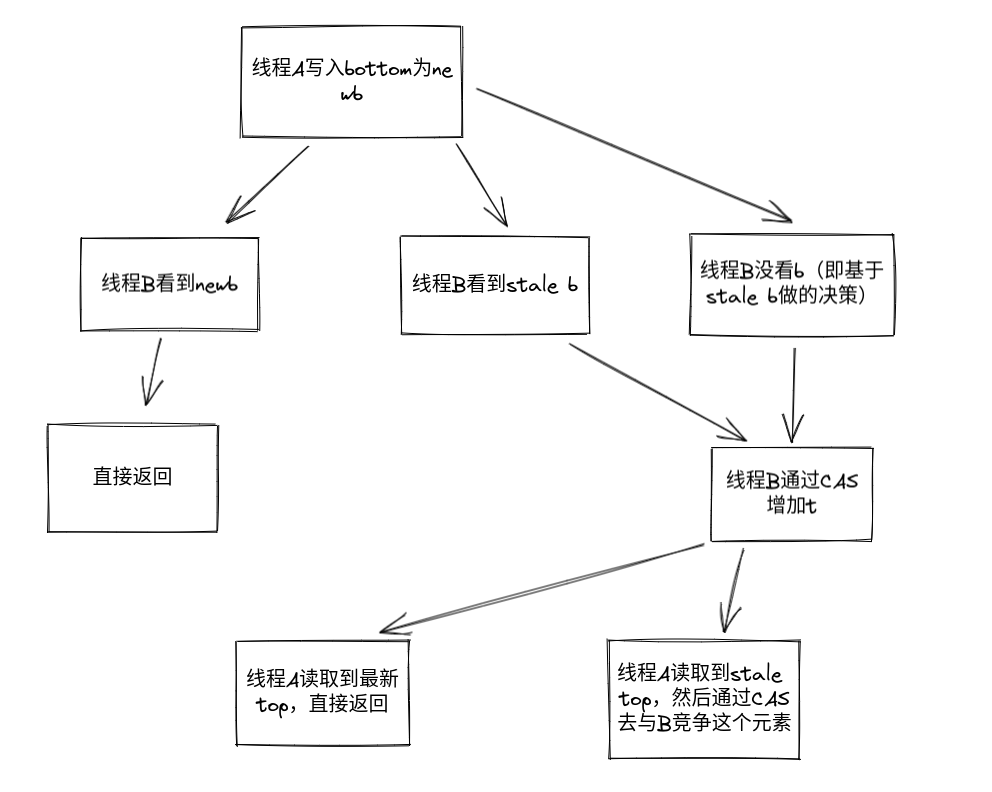
这个图是本地线程和远端线程争用一个元素的情况。争用一个元素的话两个人会都通过CAS执行,所以不会出错。
考虑这种情况
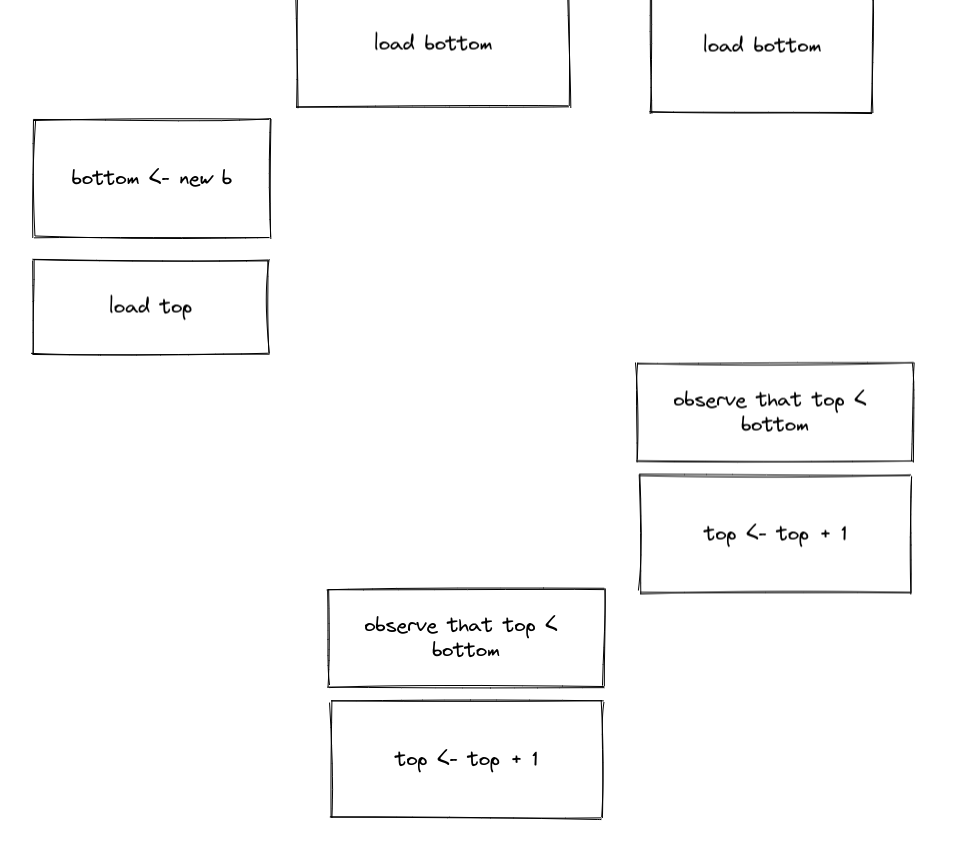
这时候线程A读到的是最新的top,然而在他load top之后,出现了很多stealing,将队列偷空。然而我们基于过期的top决定把过期的元素pop出来。
这种情况会被seq cst fence否认掉。原因是并发的两个steal线程一定会有一个人失败,然后他会重新读取bottom,这时候由于我们在store bottom和load top之间有fence,steal线程一定会读到这个bottom。从而结束stealing。
当然也有可能是两个steal线程成功了。这个时候说明我们的store bottom在他们load的下面。那么这时候我们的load top一定可以读到最新的值,从而保证我们可以正确返回。
所以可以看到,决定的点其实在我们的load pop。如果load到了最新的值,那么我们的pop就会失败。因为没有元素了。如果load到了stale的值,那么由于fence的存在,其他的线程一定可以看到store bottom,从而提前退出,让pop可以成功。
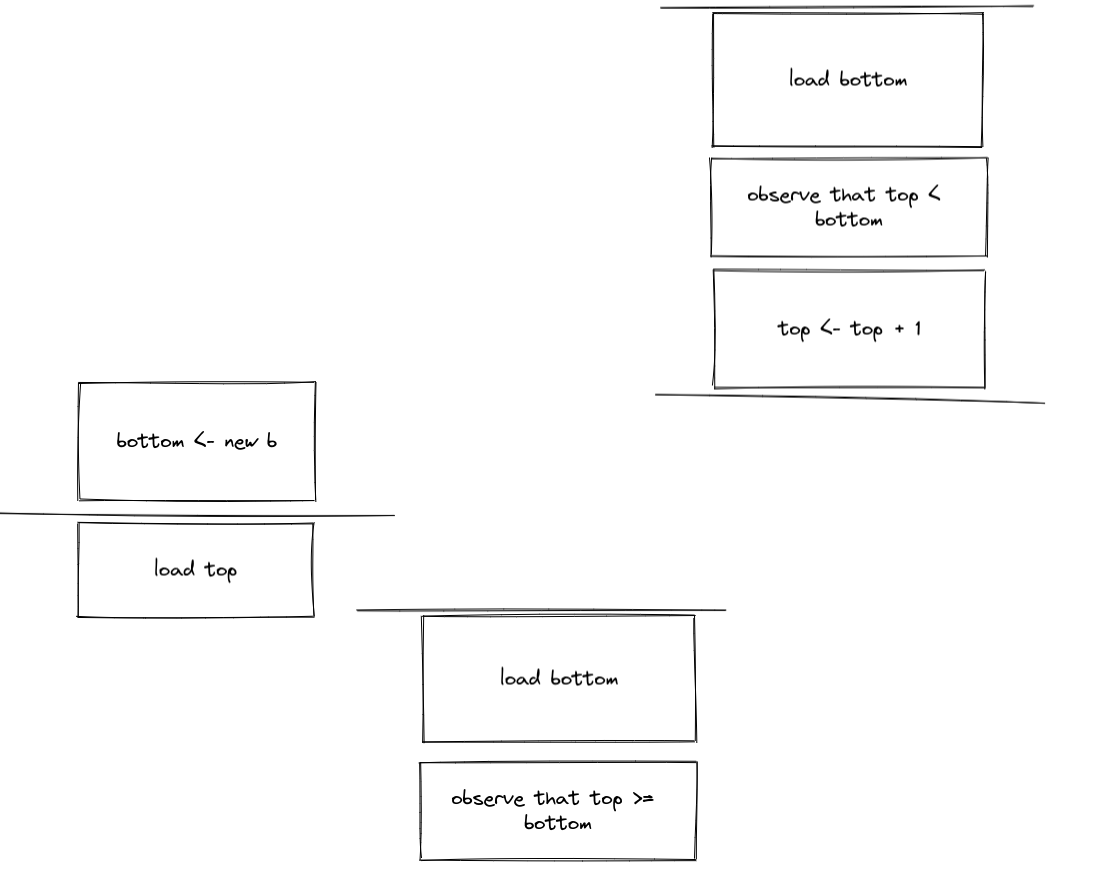
加上fence可以这么看
实际上如果seq cst fence是通过mfence实现的,那么steal中的fence就不需要了。因为他本身的load就是acquire,我们只要保证看到pop中写入的bottom即可。
详细可以看这里issue
用来确保steal线程可以看到新的bottom。如果他看到了,那么steal线程会失败。如果他没看到,那么pop线程一定会看到新的top,那么pop线程会失败。
新的疑问?貌似这里的fence只用来保证bottom被全局可见,因为top的更新是seq的,所以我们的load是可以读到最新值的。这样的话,为什么不简单的通过acquire release来同步呢?答案是top的store在seq cst下可能实现的是release语义,所以我们需要mfence来同步才能让top加载到最新的值。

文章评论