TaskGroup
这次针对性的看一看task group里面的内容
之前提到过,一个task group对应了一个pthread worker,里面包含了若干个待运行的bthread任务
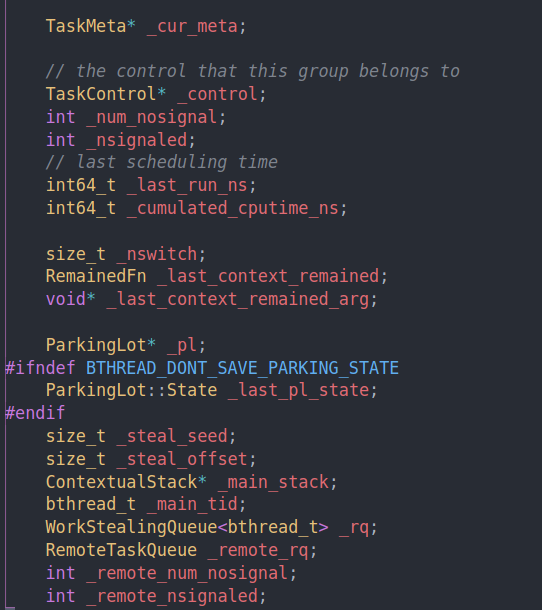
cur meta就是当前执行的任务的信息
task control就是全局的控制点
pl之前我们也提过,是用来停闲置的worker的
steal seed和steal offset是用来计算我们要偷取哪个worker的任务的。因为我们要保证随机
rq是running queue,就是目前正在执行的bthread的queue
remote rq则是存储从远端发送来的task,比如在start background的时候将remote设为true,就会插入到remote rq中
目前还不清楚main task是用来干什么的,我们一步一步看
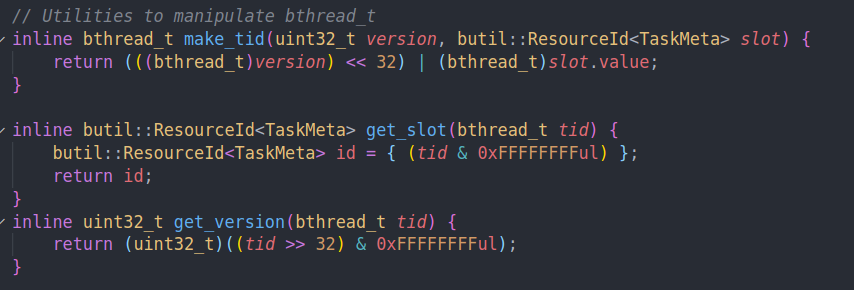
bthread id是由高32位的version和低32位的slot id组成的。slot id就是task meta在resource pool中的位置
wait task就是从remote queue中取一个task运行。之前我有一个点说错了就是他会优先运行rq的任务,而非remote queue的任务,只不过从rq中取任务不在wait task中
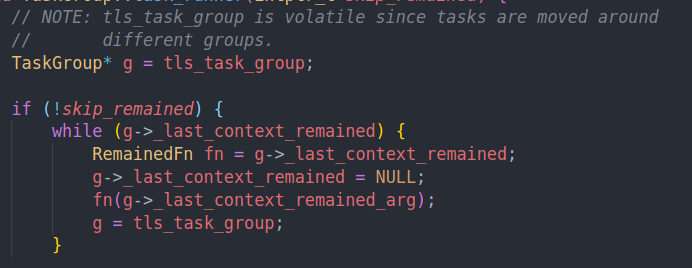
来到task runner中。如果没有skip remained,也就是不会跳过上次剩余的task的话,我们就会先运行之前剩余的任务,一般是一些收尾的处理工作。
值得一提的是编码上要注意的点。每次我们运行完user function之后,就要重新获取一下tls task group,因为我们有可能在user function中调用yield等函数,从而让出worker,然后再被其他人偷走。这样当代码运行完之后回来时,tls task group已经不是原本的值了,因为我们切换了worker
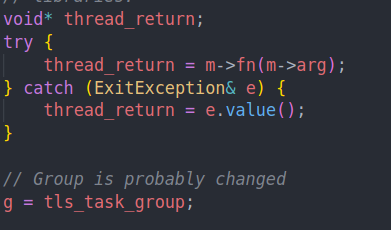
在这里也可以看到,我们会重新获取一下task group
后面有一些bthread回收相关的我们之后再看
主要是看最后这一段

因为我们当前用的栈就是task meta中的栈,所以不能直接释放,必须要让下一个人来帮我们释放
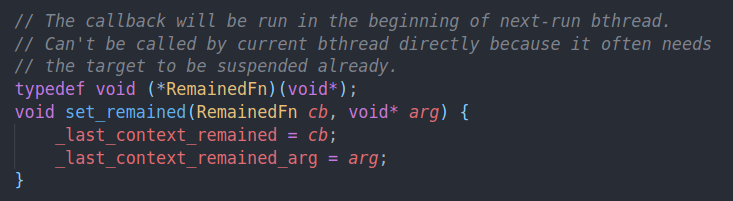
注释也说的比较清楚,运行的时候去回收是不可能的
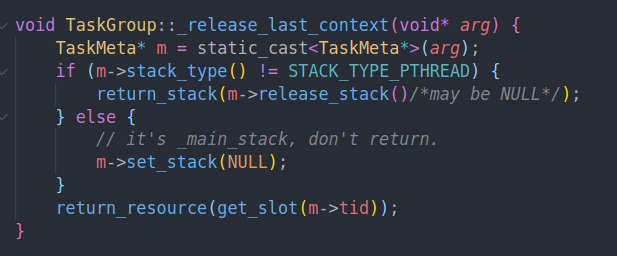
释放资源也很容易,归还栈,然后归还task meta就行
然后调用ending sched
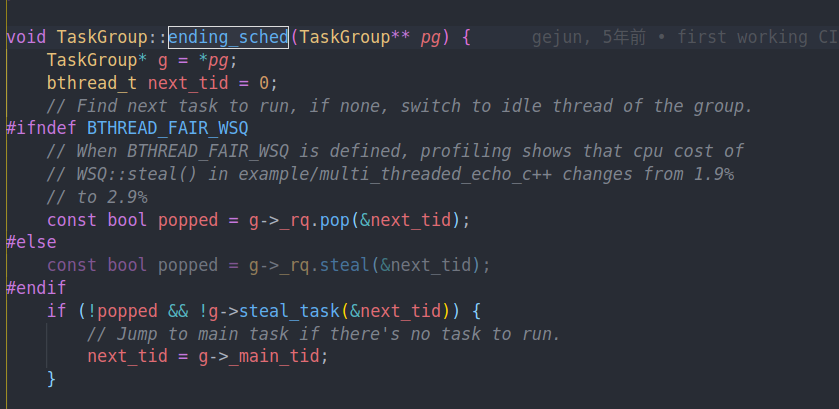
他会首先从rq中取一个任务,如果失败的话则会尝试先从本地remote queue取一个任务,如果本地任务空了,就从远端偷一个来。
可以看到这是一次launch就把能跑的任务全都跑光,才会回到最开始的线程中
拿到任务以后,会为这个任务分配栈,分配的逻辑和sched_to中是一样的
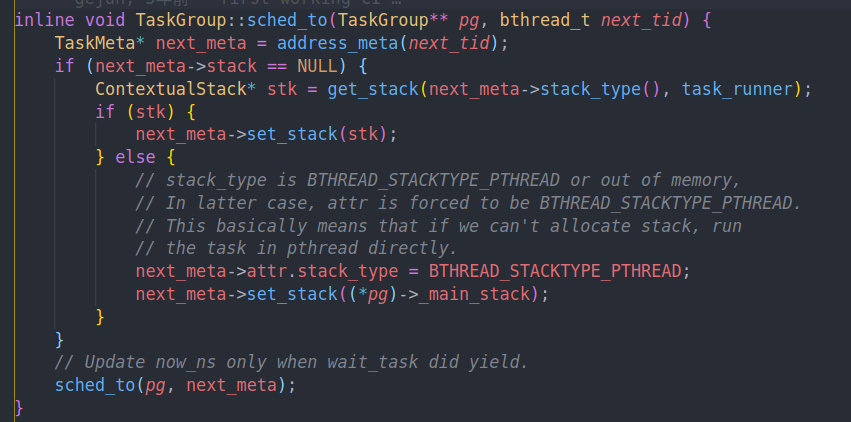
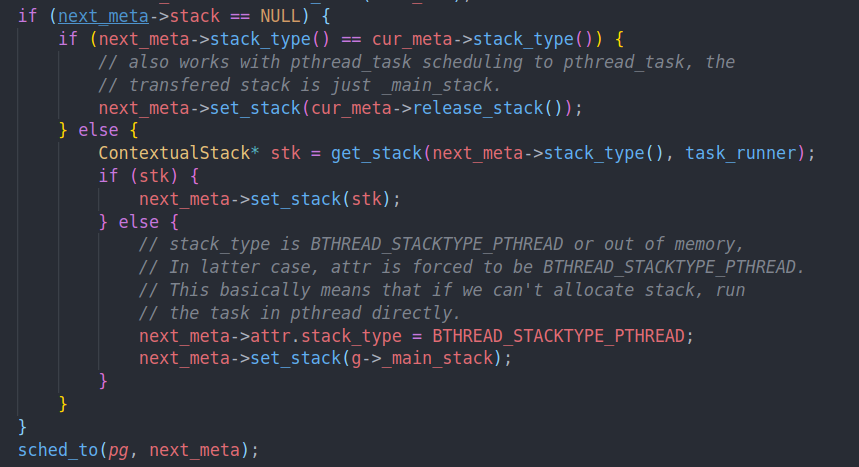
可以看到唯一不同的点就在于,如果前一个任务的栈和当前任务的栈类型是相同的话,我们就直接把栈继承过来
而在sched_to中,由于前一个任务可能没有结束,所以我们不能直接覆盖他的栈。而ending sched中任务已经结束了
一个疑惑点就是如果我们是继承的栈,那入口点是怎么设置的呢?我们应该从task runner进入才对
答案就在task runner的那个循环中
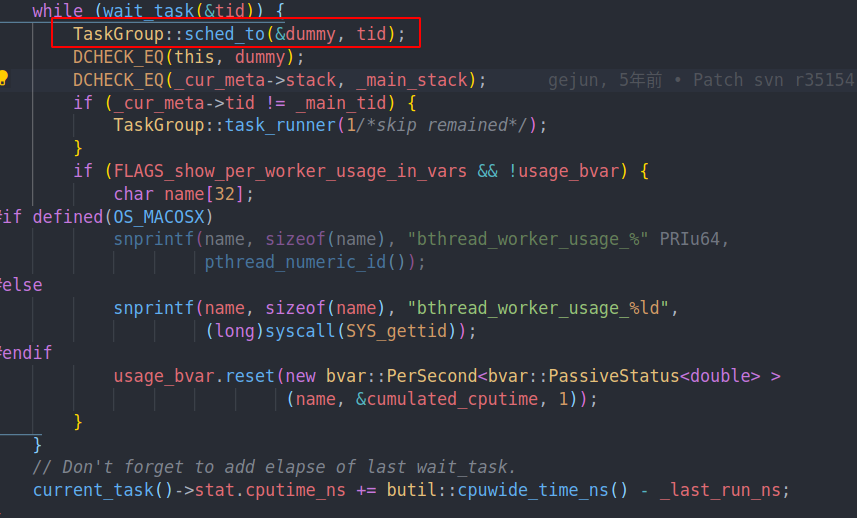
注意到当我们调用ending sched的时候,如果没有任务了,我们会把tid设置成main tid

所以当有任务继续进行的时候,我们会重复这个循环,也就是重新执行了task runner的逻辑。从而开始执行下一个任务的逻辑
所以要么我们会继承栈,然后回到循环中继续执行。要么就是直接跳到新的context中,把之前的stack释放,并重新执行task runner。
当最后我们没有任务的时候,我们会通过ending_sched到sched_to中,并通过jump stack回到main task的context中。而这就会回到main task执行新任务的位置,也就是这里
最后还有一个函数就是yield
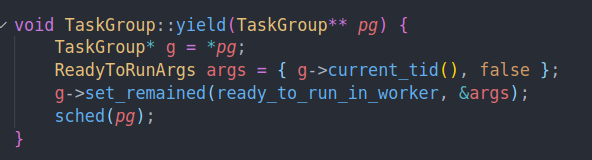
他会主动让出worker,通过调用sched找到一个task,然后继续运行。
如果没有其他的task的话,他会首先跳到main task中。然后main task会从sched to中回来,调用RemainedFN,从而把之前的worker加入到队列中。最后再由当前的worker或者其他的worker把任务拿走运行。(我在想这对于空队列来说是不是路径有点过于长了?)
重新回忆一下相对于简单的实现来说bthread都有那些优化。简单的实现指的是运行user function,然后回到main task中,然后再运行user function。
bthread在运行完一个task之后,会直接从rq中取下一个,并且还会有继承栈的操作,减少了上下文的切换,以及栈的分配。以及相当巧妙的逻辑,使得我们在继承栈的情况下,也可以不需要依赖跳转去回到task runner中。
可以看到bthread对性能这块优化的是非常棒了,能不进行上下文切换就不进行,也就是说在正常情况下,如果我们不调用yield的话,基本上所有的返回不是通过jump stack实现的。
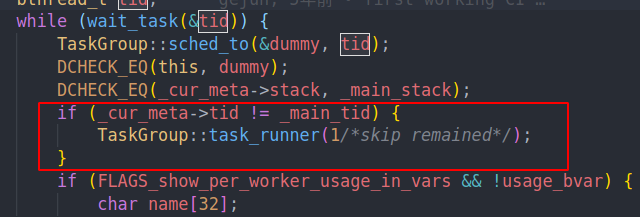
有关这里的判断,我目前猜测是为了给pthread stack用的。因为他会用main stack,在sched_to的时候会直接返回。然后在这里我们手动调用了task runner,即原地执行代码,节省了stack的分配。但是这里的skip remain我就不太清楚是为什么了,可能是为了减少判断,因为在sched_to中也会执行RemainedFN,所以这里可能只是简单的跳过?因为中间过程没有执行用户代码,我们也就不可能切换tls group,但是感觉不太可能,因为这个开销并不大

文章评论