Building a Bw-Tree Takes More Than Just Buzz Words
两个贡献,一个是Bw-Tree的实现教程,并且提出了新的优化策略。第二个则是发现BwTree并不如其他使用锁的并发数据结构更快
Introduction
Lock-free的数据结构实现的难点:
1. 需要明白所有的race conditions
2. 并发线程的同步点通常不会放到算法中,导致人们实现出错,最后变成了busy-waiting loop
3. 需要保证所有的读者全部离开后才能回收内存(在mit os中提到过linux在使用RCU的时候,会等待一个时间上限再去清理)
4. 原子操作会成为performance bottleneck
BwTree的思想就是通过间接层,将逻辑标识符映射到物理地址中,从而避免锁。每个线程通过追加delta record到modification log中来实现修改。后续的操作就必须重放这些delta record来获得当前的状态
间接层和delta record有两个优势:
1. 通过将global state变成atomic steps来避免锁的开销
2. 由于是追加delta record而不是修改,会减少cache invalidation的次数,从而获得更小的同步开销
BwTree Essentials
BwTree和其他的基于B+Tree的区别就是BwTree避免了直接修改树上的节点(因为会导致cache invalidation)。他为每个节点都维护了一个delta chain,从而可以让BwTree通过CAS来更新。indirection layer的作用就是可以让我们原子的更新对树节点的引用(比如孩子节点和祖父节点都指向父亲节点,我们可以通过间接层原子的让他们都指向新的父亲节点)
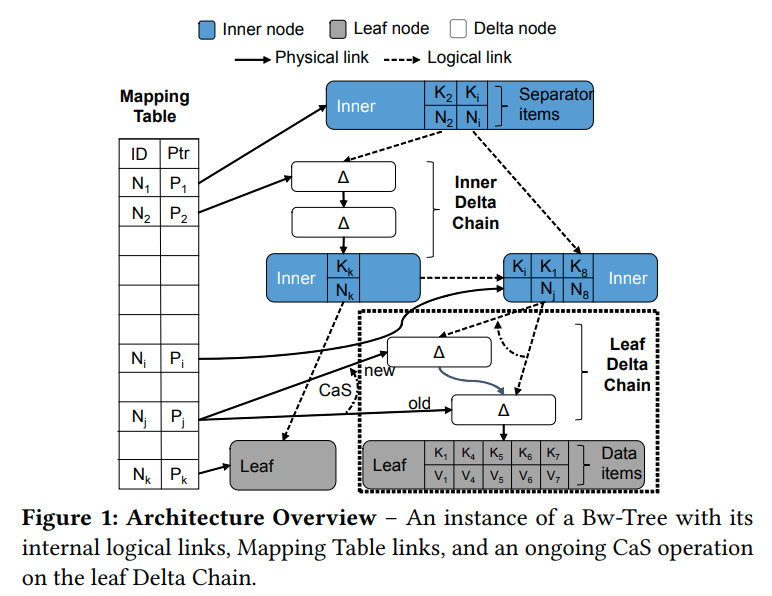
每一个节点都有一个逻辑ID,节点在指向其他节点的时候会用这个逻辑ID。当一个线程需要他的物理地址的时候,就会去MappingTable中查。MappingTable允许我们通过CAS来更新节点的地址
Base Nodes and Delta Chains
一个逻辑节点在BwTree中有两个部分,一个base node,以及一个delta chain
这里有两种类型的base node:
1. inner base node,存储的是有序的(key, NodeID)的数组
2. leaf based node,存储的是有序的(key, Value)的数组
(和b树一样)
最开始的时候,BwTree有两个节点,一个空的叶子节点,以及一个inner节点,指向了叶子节点。
Base Node是不可变的
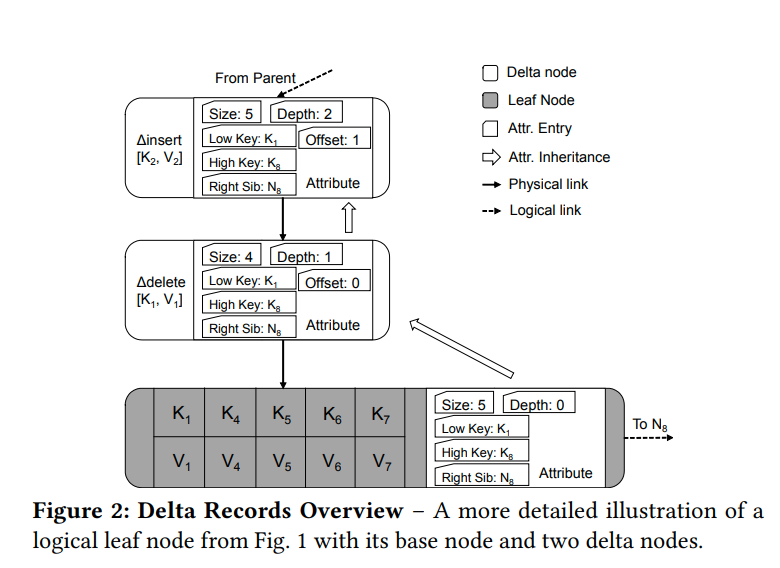
delta chain是一个单向链表,存储的是按序排的针对base node的修改历史
base node和delta record都存储了可以表示那个时刻状态的元信息

这样我们就不需要一步一步重放操作来获得最新状态。(但是当需要数据的时候应该还是需要重放,这里只是保存了状态而已)
线程在修改数据的时候,会追加delta record,再修改mapping table让他指向新的delta record
Mapping Table
BwTree借用了BlinkTree的设计,每个节点有两个入指针,一个是从父亲来的,一个是从左兄弟来的。在更新的时候我们需要进行原子的修改这些指针,所以要么使用transactional memory,或者multi-wrod CAS
而BwTree通过用间接层来避免这些问题。从而允许一次CAS来完成原子修改
当CAS失败的时候,这次操作就会重启。每次重启都会从树根开始重新遍历。虽然更复杂的重启协议是可能的,但是我们认为从树根开始遍历简化了实现。并且我们要遍历的节点很可能会在cache中
他提了一点就是这里的Mapping Table只关注了BwTree的实现。实际上他也可以支持log-structured updates。(这里我不太明白,可能需要再去研究一下log-structured相关的细节。他的意思可能是LSM中一个数据会在多层出现,我们通过只修改间接层从而可以直接修改多层数据)
Consolidation and Garbage Collection
当delta chain增长的时候,worker每次来就需要重新遍历并重建当前的状态。为了防止过长的delta chain,worker会周期性的压缩delta chain并重组成一个新的base node。
在压缩的最开始,线程首先把logical node的base node复制到他的私有内存中,然后开始应用delta chain。接着他会更新MappingTable中的指针,指向新的logical node。最后当所有的线程都离开老的节点的时候,我们就可以回收他的内存
Structural Modification
和B+树一样,Bw树也会出现overflow或者underflow的情况。从而导致了splitting以及merging
核心思想就是利用特殊的delta record来表示内部结构的变化
SMO(structural modification protocol)的操作有两个阶段,一个是logical phase,用来追加特殊的delta record来通知其他的线程这里会有一个SMO,以及一个physical phase,用来实际执行SMO(即split或者merge,然后通过CAS来替换掉老的节点)
尽管BwTree是lock-free的,但是如果CAS失败的话线程仍然无法make progress(比如在这个两阶段操作中,我们不能假设是同一个线程在做,否则就会阻塞其他的线程的进度)。一个解决这个的方法就是合作执行multi-stage的SMO,也被称为help-along protocol。线程必须在节点被遍历之前帮助完成SMO的未完成阶段
(我怎么感觉他这块说的都好迷幻,应该看一下BwTree之前的文章)
Missing Components
Non-unique Key Support
在遍历的过程中,BwTree会停在第一个匹配搜索键的地方。但是这样是无法支持non-unique key的
我们在遍历的时候维护两个集合,S_{present}和S_{deleted}。S_{present} contains the values that are already known to be present. S_{deleted} contains the value that are known to be deleted
如果发现了一个insert record,键为K,值为V,并且V不属于S_{deleted},我们就会把V加入到S_{present}中。
如果发现了delete record,并且V不属于S_{present},他就会把V加入到S_{deleted}中
更新操作是通过删除后插入来完成的。当遇到最后的base的时候,最终构建出的节点就是S_{present} \cup (S_{base} - S_{deleted})
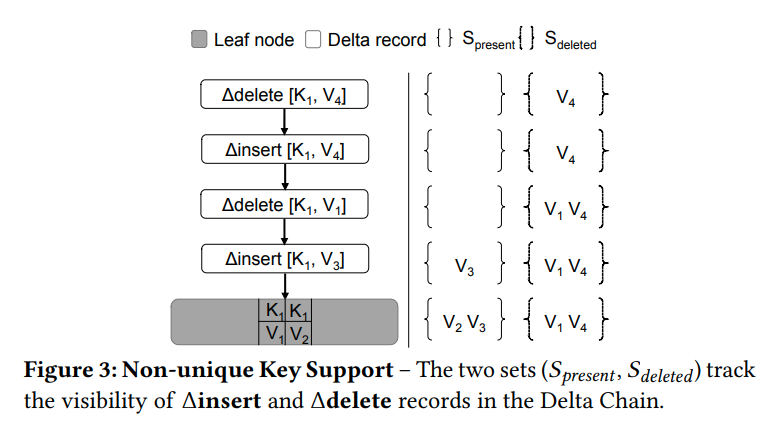
这里的查找是针对叶子节点单个K的,不是这个K的record会被忽略掉
Iteration
直接在BwTree上进行遍历是非常困难的,因为我们很难定位当前迭代器的位置。并且还需要处理SMO以及并发插入删除的问题
我们的迭代器不直接放在树节点上。每个迭代器都会维护一个只读的logical node的副本。
当迭代器移动的时候,如果当前的副本用完了,我们就会通过low key或者high key来重新遍历一次
Mapping Table Expansion
每个线程都会访问Mapping Table,所以不让他成为bottleneck是很关键的
Mapping Table就是一个数组。动态增长的方法就是使用Lazy allocation。我们提前分配好虚拟空间,当实际使用的时候再分配物理内存
而对于Shinking的情况,没有很好的方法,我们只能阻塞住worker thread,然后重构索引
(我在想他们的logical id是怎么复用的?用free list吗?个人猜想是先放到free list中,但是不用。每过一段时间冻结free list,然后再用free list中的内容)
Component Optimization
Delta Record Pre-allocation
Delta Chain in Bw-Tree is a linked list of delta records that is allocated on the heap. 遍历这个Delta chain会变得很慢,因为局部性很差。并且大量的并发内存分配会导致分配器的争用,从而导致了bottleneck
我们会在base node中提前分配delta record
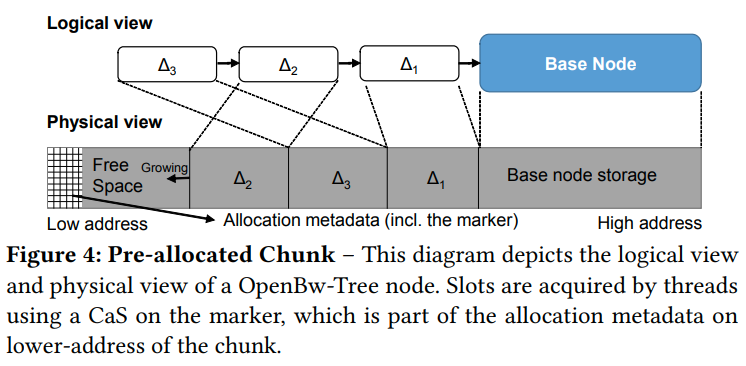
base node会在高地址的边缘。而delta record会从高到低进行分配(利用pre-fetch)
每个链也会维护一个allocation marker,指向的是最后一个delta record。当worker需要一个slot的时候,他就会减少这个marker(和栈类似),如果预先分配好的区域满了,他就会触发压缩操作
delta record不会删除,所以没有free-list的问题。图中的交错是因为并发的操作导致的,比如第一个线程先分配了空间,但是是后面才append到链中(如果这里失效了,他会放弃掉这段内存吗?因为前面说了当CAS失败的时候要重新遍历,但是重新遍历有可能我们就不会回到相同的node了,是不是只有split/merge的情况才需要重新遍历呢?)
Garbage Collection
之前的BwTree用的是Epoch-based GC,每过一段时间他会在一个全局的链表上追加一个epoch object。每个线程在访问索引之前必须先在epoch object上注册自己
让线程结束操作以后,他就会把自己从epoch object上移除。所有的删除操作都会被加入到当前epoch的garbage list中,当所有的线程都离开这个epoch的时候,我们就可以安全的回收garbage list中的对象
(这样可以安全的保证吗?我感觉在这个操作结束之前的epoch都可能出问题,而不是只有开始的epoch。貌似文章中说了,在操作完成的时候,把删除的对象加入到当前epoch,而不是他进入的那个epoch,所以应该没问题。我们只要保证epoch是按序删除的就行)
(第二个思考是他们为什么回避对单个node进行refcnt呢?这样最后一个人负责删除他就好了,可能是为了防止写元数据导致的cache invalidation)
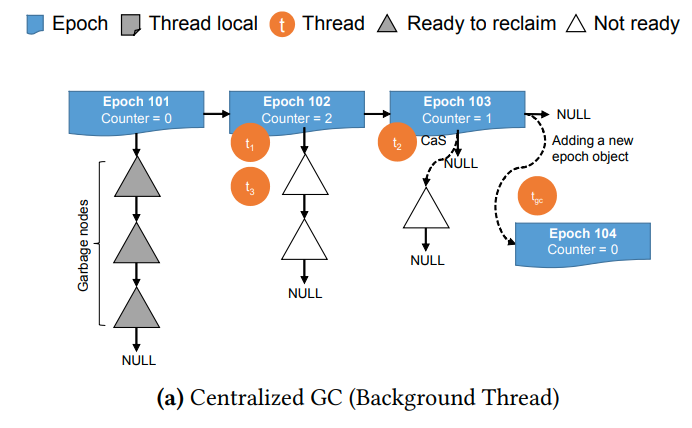
这种中心化的方法会导致scalability的问题。因为cache coherence这时候会变成瓶颈
OpenBwTree用了一种去中心化的方法。
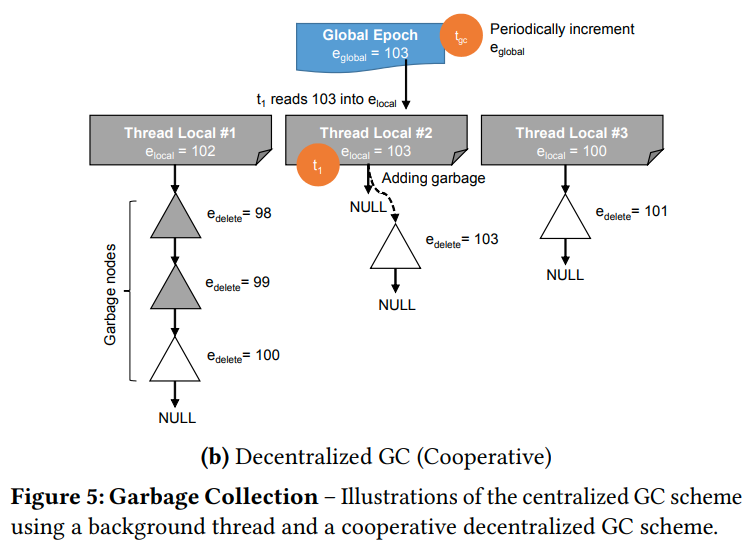
索引自己维护了global epoch。每个线程自己维护了本地的epoch,以及他删除的对象列表。
在开始操作的时候,线程会把当前的全局epoch复制到本地的epoch中。当他完成操作的时候,他会再次将全局epoch复制到本地epoch中,并且把garbage打上最新的global epoch的标记(表示所有小于这个epoch的线程都有可能访问到他)。然后开始GC。他会收集其他线程的local epoch,并且删除所有小于最小local epoch的那些对象。
线程的local epoch表示的就是这个线程目前的操作正在那个epoch。如果所有人都高于garbage的epoch,就可以安全的回收
这样其实是分散了争用。之前用的是计数器。这里是维护的本地的watermark,从而获得全局最小。然后我们回收小于全局最小的对象。并且这里的删除分摊到了每个线程中
(思考,其实是一种去中心化的维护watermark的方法。因为在中心化的实现中,我们完全可以用一个sorted-list来维护当前的active-operation的epoch,每次结束操作就把他产生的garbage打上最新epoch的标记,然后把自己从sorted-list中移除。这样的话垃圾回收器只要读第一个节点就可以,但是对于注册这个操作来说,他可能会引起争用,同时lock-free的双向链表也不清楚有没有。所以这个方法是写慢,但是读快。而去中心化之后,每个人其实相当于都遍历了一遍链表才能获得global minimum,读虽然慢了,但是他的写很快,并且没有争用。这么想的话其实lsm tree也有这个思路,加快写(通过append only),但是代价就是读变慢)
Fast Consolidation
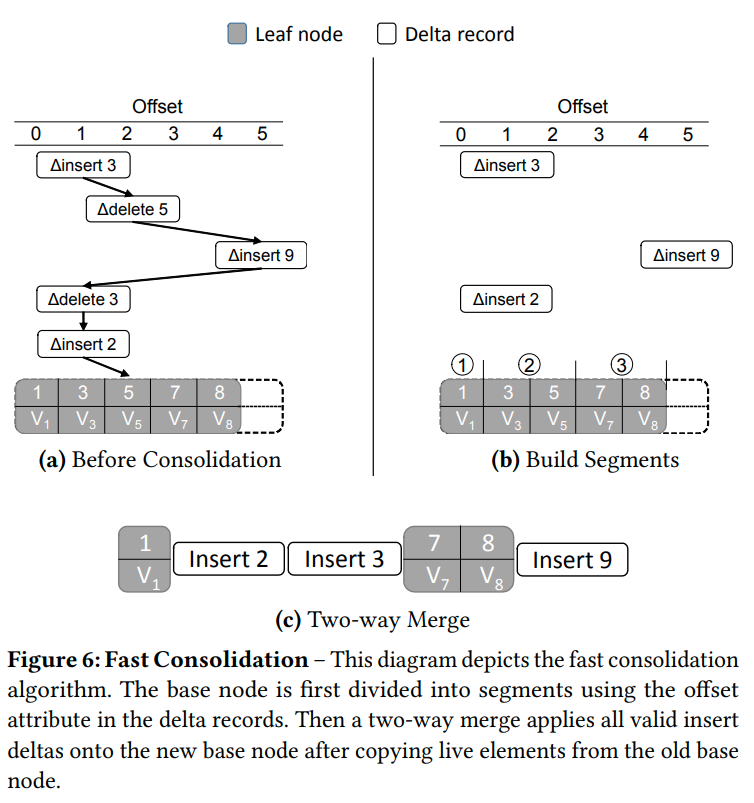
consolidation分为两个阶段,第一个阶段是复用之前的non-unique key的方法来找到那些元组被删掉了,那些被插入了。然后第二个阶段则是把插入的新元组和之前的老节点做一次2路归并,从而生成新的base-node
insert record和delete record在作用于base node的时候,会存储一个offset字段,用来表示这次操作会作用到哪里。然后我们用Spresent和Sdeleted来将base node划分成若干个片段。再用这些片段和insert record做归并
(我在想维护这些segment的overhead难道不大么,直接sort感觉会更好一些)
Node Search Shortcuts
当节点很大的时候,我们一次二分搜索可能会跨越多个cache line,从而导致效率不高
我们通过micro-indexing来减少节点内的搜索
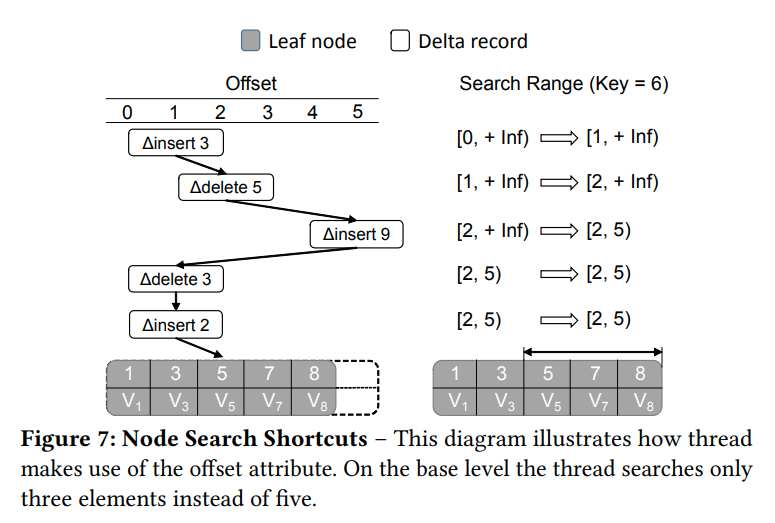
这里是减少了最后的base node的扫描范围
因为之前的insert以及delete record记录的都是当前的Key对应在base node的偏移量。所以当我们在路上比较的时候就可以顺便获取base node中值的范围。从而在最后一步实现快速的查找
Evaluation
这里写几个我感觉比较有意思的点吧
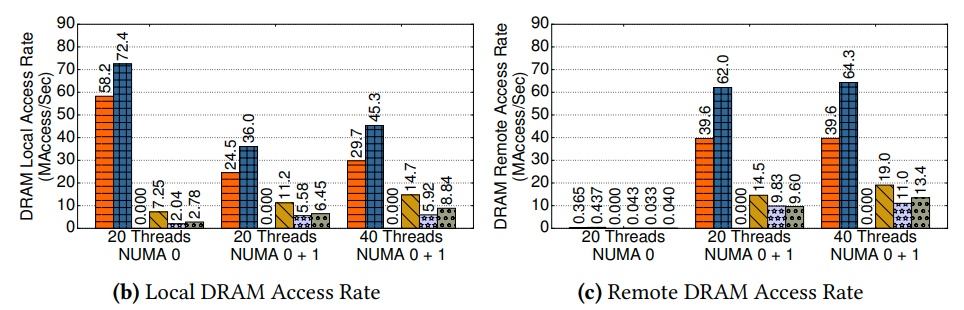
从这个图大概可以看出来,BwTree的效率不高可能是因为访存太多,也就是memory footprint太大导致的。
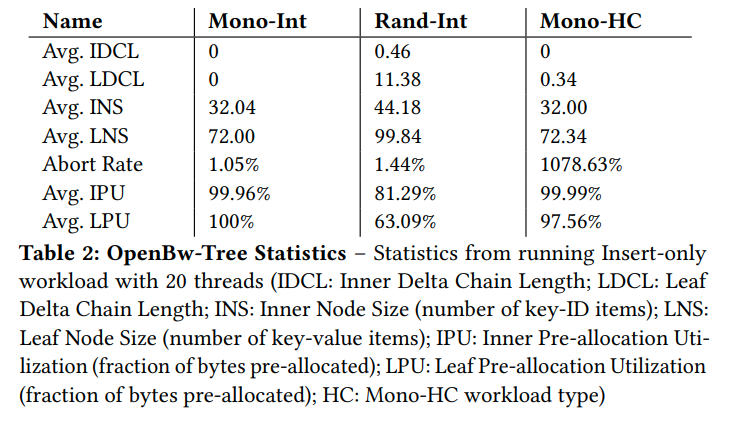
这里也显示了,在HC(high contention)的情况下,abort rate是1000%,所以一次操作会abort10次才能成功,所以导致了大量的footprint。反而降低了lock-free的优势。因为本身lock-free的算法就是在高争用情况下保证可以make progress
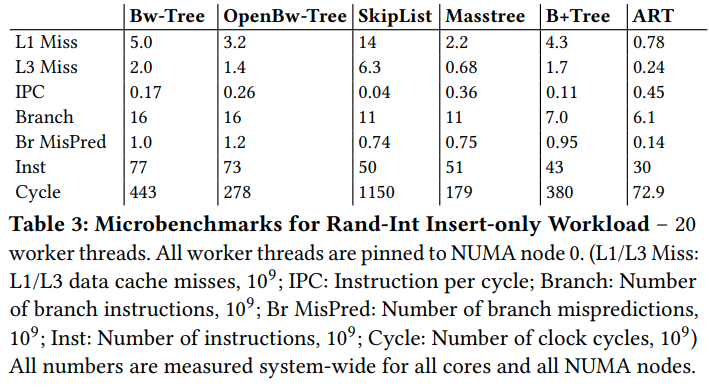
表现最好的ART拥有相当高的局部性
这样看起来是BwTree的结构导致的他表现的不好,比如更多的Branch,更多的预测失败等
所以可能BwTree更适合在flash中,而非memory中。因为他的优势在于append-delta,所以cache invalidation的优化不能弥补更多的memory footprint带来的开销。但是flash中比较偏向这种结构,也就是log-structured形式。所以可能BwTree在flash中表现的会更好
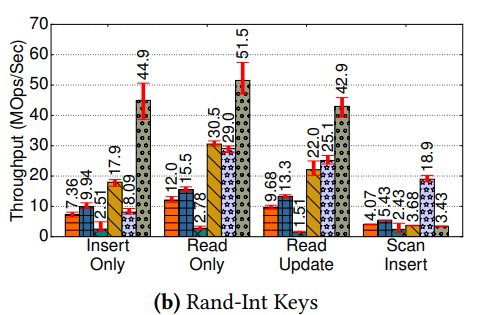
最后他有一个performance decompisition,基本上把BwTree的feature都关掉,然后比较性能
但是结果是即便把feature都关掉,BwTree还是比B+Tree慢一些。原文说: Even Read-only operations perform considerable bookkeeping to maintain the consistency of the tree, limiting its performance.
这里我不太明白他的都维护了什么东西,但是可能就是因为为了latch-free所维护的各种信息吧,导致了高开销

文章评论