introduction里就是一些对MVCC的介绍。不过最后他提了一点我觉得比较关键
Careful engineering, however, matters as the performance of version maintenance greatly affects transaction and query processing.
Main Contribution:
1. 低开销的MVCC implementation
2. 基于Precision Locking的变体的一种串行化的方法
3. 一种synopses-based方法来达到高效的单版本扫描
4. 对于MVCC的实验以及tradeoff的演示
MVCC Implementation
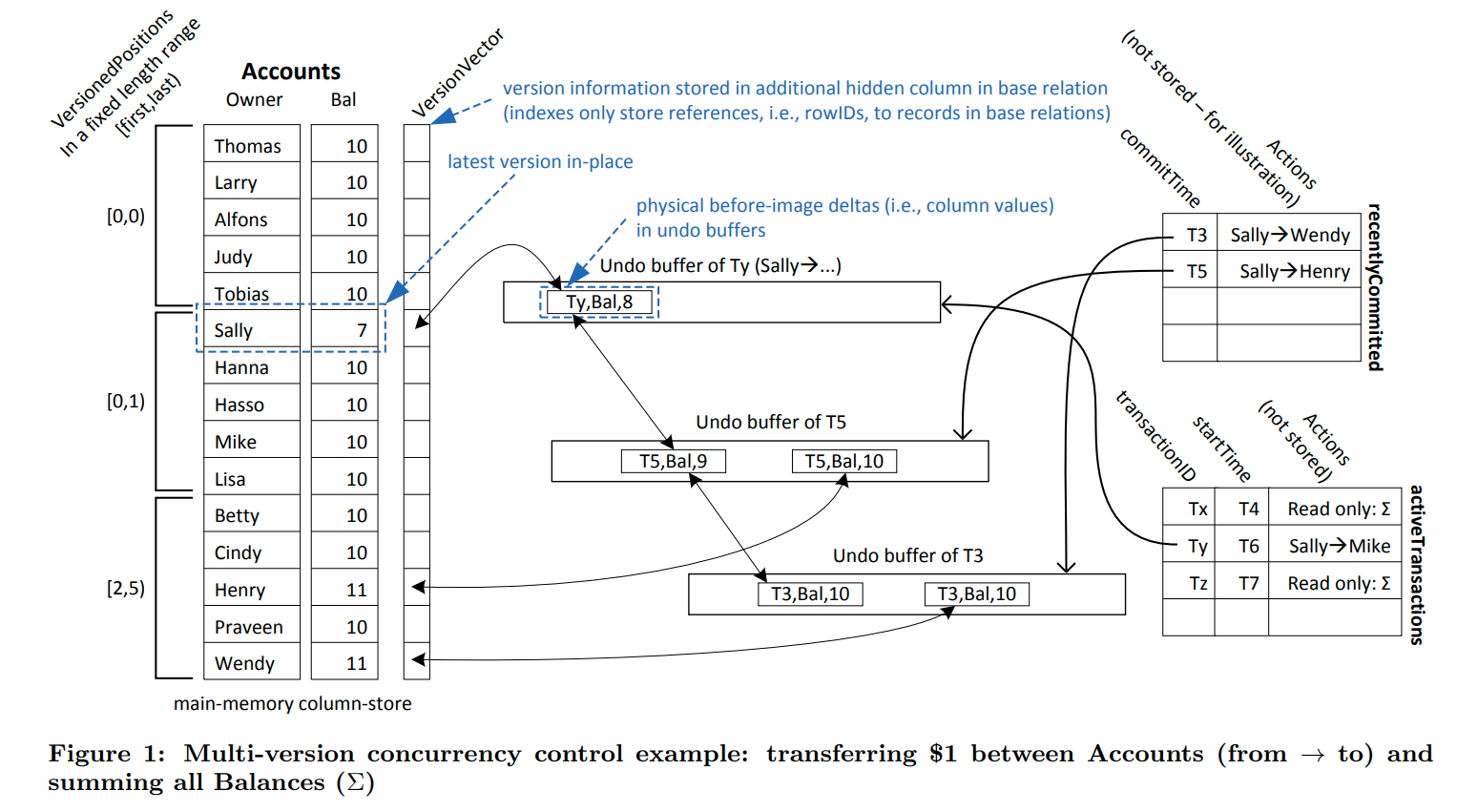
为了保证高效的扫描,我们没有创建一个新的版本放在新的地方,而是update inplace,并且在undo buffer中维护了backward delta。即新的版本(yet uncommitted)和之前版本的变化
存储的形式是newest2oldest,版本链中的每一项存储的都是对应列中的变化。并且为了实现GC,链接是双向的
Version Maintenance
如果所有的txn都都在当前的version的timestamp后开始,那么说明这个version已经过时了
VersionVector存了指向在undo buffer中最近的版本的指针
每一个txn都有两个timestamp:transactionID和startTime-stamps
在提交的时候,他会收到第三个timestamp,commitTime-stamp,用来决定串行化的顺序
系统保证了startTime-stamp总是会比transactionID小。目前还不清楚他这么做是为了什么
事务会原地修改数据,并把之前的版本存储在他的undo buffer中。这个old version有两个作用:
1. rollback的时候用来恢复
2. 他会作为一个最新的已经提交的版本
新创建的版本会被赋与transactionID,并且只有创建他的事务才能访问他
在commit的时候,事务会得到commitTime-stamp。并且从现在开始他的undo logs会被标记为与他无关。
回看一下figure1貌似可以明白,每个版本上的标号代表了他的删除时间。看Sally 7这个版本,这个版本链上对应了3个timestamp,分别是ty,t5和t3。如果是小于t3的事务就会读到10这个值,大于或者等于t3,但是小于t5则会读到9。对应的,如果是大于等于ty才能inplace的读。所以我们需要保证transactionID大于startTimestamp,这样就可以防止其他的事务读到未提交的值
所以我们才需要在undo buffer里把这些版本都存起来,这样最后提交的时候只要把所有的undo buffer中的值改成commitTimestamp就可以了。
Version Access
访问一个元组的时候,他会跟着版本链找到满足条件的第一个版本:
v.pred null or v.pred.TS = T or v.pred.TS < T.startTime
其中pred表示版本v的前一个版本(版本链的后一个,因为我们是N2O)
第一个条件对应的是没有前一个版本的时候,即以前的版本都已经被GC掉了或者没有创建过
第二个条件对应的就是我们自己能看到自己的修改
第三个条件则是对应了看到StartTime > CommitTime的最新版本。因为v.pred.TS其实是创建当前版本的CommitTimestamp(我怀疑他们会这样分开存么?这样每次都会多一个间接访存,不如维护startTimestamp和endTimestamp查找更快一些
Serializability Validation
我们特意的避免了写写冲突,让一个事务尝试更新一个未提交的数据的时候,他就会abort并且restart。所以第一个VersionVector指针总会指向一个含有commit version的undo buffer。如果一个txn尝试更新数据多次,那么就会创建多个版本,但是最终他们还是会指向一个已提交的版本(我好奇为什么不原地更新呢?为了子事务么?)
为了提高并发性,算法是基于乐观执行的(MVOCC),也就是说为了保证可串行化,我们需要在最后添加一个验证阶段(貌似正常的SSI都需要最后的验证,先提交者胜)
我们必须保证所有的读都能保证在提交的时候也是不会改变的。即处理RW和WR依赖(我想了一下貌似只需要处理RW,因为WR来说,一个读遇到了已有的写,他只要读提交的版本就OK,因为这个写的CommitTimestamp一定在读的ReadTimestamp之后,所以我们无论如何也读不到他,这里和percolator是不同的,因为percolator可能出现延迟的更新。不对这里也可以出现,还是需要处理的。。)
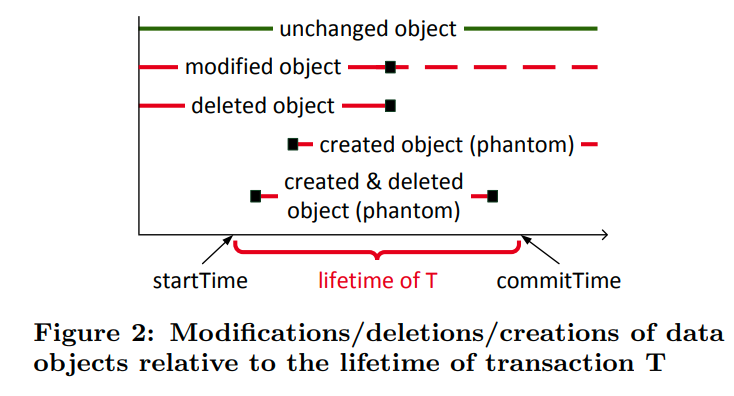
figure2列出了我们需要检测的几个现象。也就是要检测发生在T的生命期之间的改变。
这里使用了Precision Locking来进行检查,他消除了谓词锁所需要可满足性测试的问题。(这个可能还需要之后继续研究研究)。我们的检测阶段会检测正在提交事务中的对应的谓词读与最近提交事务的写入的冲突。当最近提交事务的写入与谓词读产生交集的时候,测试就会失败。(所以前面提到了是用undo buffer验证,因为undo buffer里存了事务所有的写入)
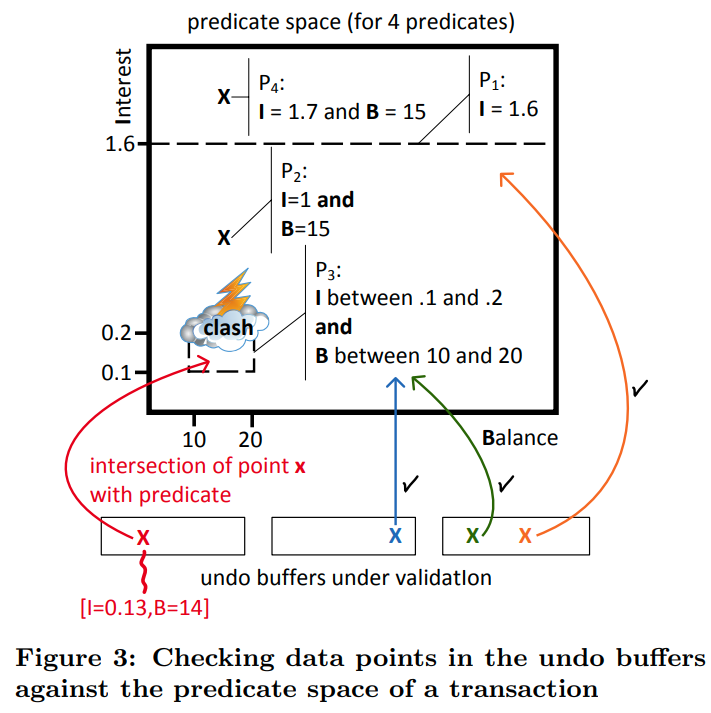
这个是验证阶段的演示
这些谓词构成了空间中的区域(读所涉及到的区域),然后我们把undo buffer里的东西往里丢,如果出现了交集说明出现了问题。对于实现来说,我们只需要把undo buffer里的东西都应用一遍谓词即可(这个思路不错,不是在索引等地方记录读取的信息,从而防止其他人写。而是在提交的时候把写集验证一下有没有影响谓词)
我们维护了最近提交的事务,并且含有指向undo buffer的指针。对于在T的lifetime期间提交的事务来说,我们取出每一个新创建的版本,并且检查他是否满足事务T的谓词。(这里检查要仔细考虑,因为我们要满足的是CO,也就是CommitTimestamp代表了串行化序列中的顺序。并且貌似不只是要考虑一个版本,因为有可能之前可以读到但是新版本不满足谓词,或者新版本满足谓词但是之前不满足)
论文中提到了,对于删除操作。我们要检查这个项是不是在T的读集中(也就是读到了被删除的东西),而对于修改操作,我们需要检查before-image和after-image,只有两个都不相交的时候才能满足条件
(但是这还是解释不了为什么不原地修改,因为我们检查的应该都是commited version才对,否则不可能被读取到)
验证完成以后,首先把数据写入到redo-log中,然后修改undo buffer中的timestamp(一个问题,这里需要原子的修改么?我觉得需要)。论文中还提到了这个验证过程是可以并行的,那么就可能出现一个问题,如果正在验证的事务会影响另一个事务要怎么办呢?比如事务10刚开始验证,事务11也开始了,但是根据串行顺序来说,事务11必须知道事务10是否验证完毕了)
Predicae Logging
谓词并不只是有where语句等,比如join连接等操作都会影响读集
对于table的扫描,我们记录下他对于某些属性的限制
而对于索引访问的时候对应的谓词也是类似的,比如记录下谓词的范围
索引连接则是不同的,我们会记录下所有从索引中读到的数据作为谓词,并把这些数据合并成为Ranges记录下来。其他类型的join则是作为全表扫描来记录
这里可能说的不太清楚,我仔细解释一下。比如说我们目前有一个index nested loop join,即首先按顺序扫描A表,对于A表中的每个元组,我们通过索引查找B表中有没有对应的值。这时候我们就可以记录下来所有的成功匹配的B表的值,合并成为Range作为谓词使用。那么后续的插入操作如果满足了这个谓词,就说明他会对这次index nested loop join有贡献。
其实思路还是比较清晰的,因为我们访问数据的方法其实就两种,一种是显式的谓词,这时候我们直接记录下这些谓词就行,比如应用在基表或者索引上的谓词。还有一种就是隐式的谓词,比如上面的index nested loop join,这里的谓词其实就是是否满足连接条件,而连接条件就是A表对应属性的范围,我们log下来即可。其实这里应该可以推广到任意连接中,只不过维护成本较大,比如哈希连接,就需要我们保存所有的属性,所以选择扩大粒度,直接相当于全表扫描就行
Implementation Details
通过64位的摘要来快速的进行谓词判定,变长的数据会被hash成64位摘要
这里的摘要是针对每个属性的,而非元组,所以他会比一些“locking the record”的方法更好,因为record-level可能会导致false positive
我们还会额外的log那些属性被访问了,从而处理没有谓词的访问,以及优化检查粒度
所以在validation的时候,就可以跳过那些修改了没有访问过的属性的版本(比如我这个版本虽然满足了你的谓词,但是我修改的地方不是你读取的)
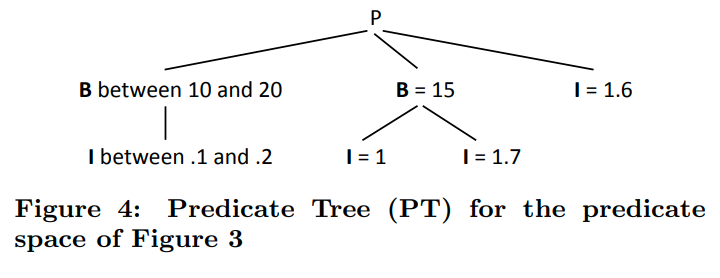
每一个关系表都会构建这样的一个predicate tree。不同的路径是OR连接。一个路径下由AND连接
所以每一个版本都会去检查他们是否满足了PT的某一个分支
Garbage Collection
每次提交之后,我们都会在最近提交的事务里确定最老的可见事务ID是多少,那么所有在他之前的事务就都可以从最近提交事务列表里移除。指向他们的undo buffer的指针也会被移除。undo buffer会被打上tombstone的标记。但是我们不能立刻释放undo buffer的内存,因为有可能有其他的事务有对他的引用(我们可以确定他看不到undo buffer里的内容,但是他需要这里面的信息来终止version chain的遍历)。
但是如果已经标记的tombstone就可有直接终止了(那可能是先去检查一下tombstone,然后再访问)
(个人猜想:可以通过维护undo buffer的refcnt来让最后一个人释放掉他,有点类似in-memory inode)
Handling of Index Structures
当我们修改的元组涉及到索引的时候,对于关系表来说他会删除原本的版本并插入新的版本。而对于索引来说,他会存储原始的版本和新的版本。这样我们的索引中就存储了任何事务都可以看到的所有元组。
对于检查一致性来说,比如主键约束。论文中的意思应该是对于uncommited的版本也会主动中止。因为我们在index中存储了所有的版本,所以当一个新的主键插入的时候他会检查索引,如果索引中有这个主键了,说明这个快照里就有,或者有一个未提交的主键,我们就会主动abort。理由是大多数的事务都会提交,所以事务将uncommited数据视为已经存在的版本。
但是我感觉如果只是检查约束的话,我们可以为最后的检查阶段添加额外的谓词来实现。(可能是因为索引检查更快?不太清楚他们这里的tradeoff)
Efficient Scanning
很多AP和TP的workload都依赖clock-rate scan performance。所以每次都对数据做可见性测试会导致性能下降
通过synopses of versioned record positions来加速扫描
在上面的figure1中,VersionedPositions就是这个摘要。他维护了具有版本的记录的位置的一个范围。
由于我们会不断的进行GC,所以大多数的元组都没有其他的版本。比如figure1中的前5个元组,他们是没有其他版本的,所以我们可以不需要去进行额外的version check,以达到最大的扫描速度
而对于已经修改的版本我们就需要根据version vector进行重建
这里有一个奇怪的点:Again, a range for modified records is determined in advance by scanning the VersionVector for set version pointers to avoid repeated testing whether a record is versioned.
我好奇这个范围不是一定被VersionedPositions确定了么?为什么还要再扫描VersionVector
他提到了实践中两个versioned object的跨越是很大的。
并且提前确定好versioned object的范围可以让我们在热点区域少查询VersionedPositions。(这块和上面的问题是一样的)
这里是因为文章中提到了,他们维护这个摘要的方法,对于插入的修改来说,我们只要更新这个范围就可以,而对于删除来说,他们会在下次扫描的时候修正摘要。所以对于我们维护的这个摘要可能并不是准确的摘要,所以他重新扫描version vector来得到更准确的值。并且他是列存储的,所以这个代价并不高,比起每次重新找version vector要高效
Synchronization of DataStructures
简单提了一下怎么做的同步
在一个task中,获得MVCC数据上的latch(一个transaction通常由多个task组成,应该就是对应的sql statement。为了防止race,就在操作的时候加上短期锁)
提交的时候会进入一个临界区,首先拿到commitTimestamp,然后做validation,然后写redo log。最后的更新undo buffer中的timestamp可以通过原子操作在临界区外做。(所以这里的意思是还是只能一个一个的提交么?)他这个前后貌似不太一致,他前面说validation是可以并发的,但是后面说这个是在临界区的
Theory
这里说了txn是并发的运行,但是提交是串行的
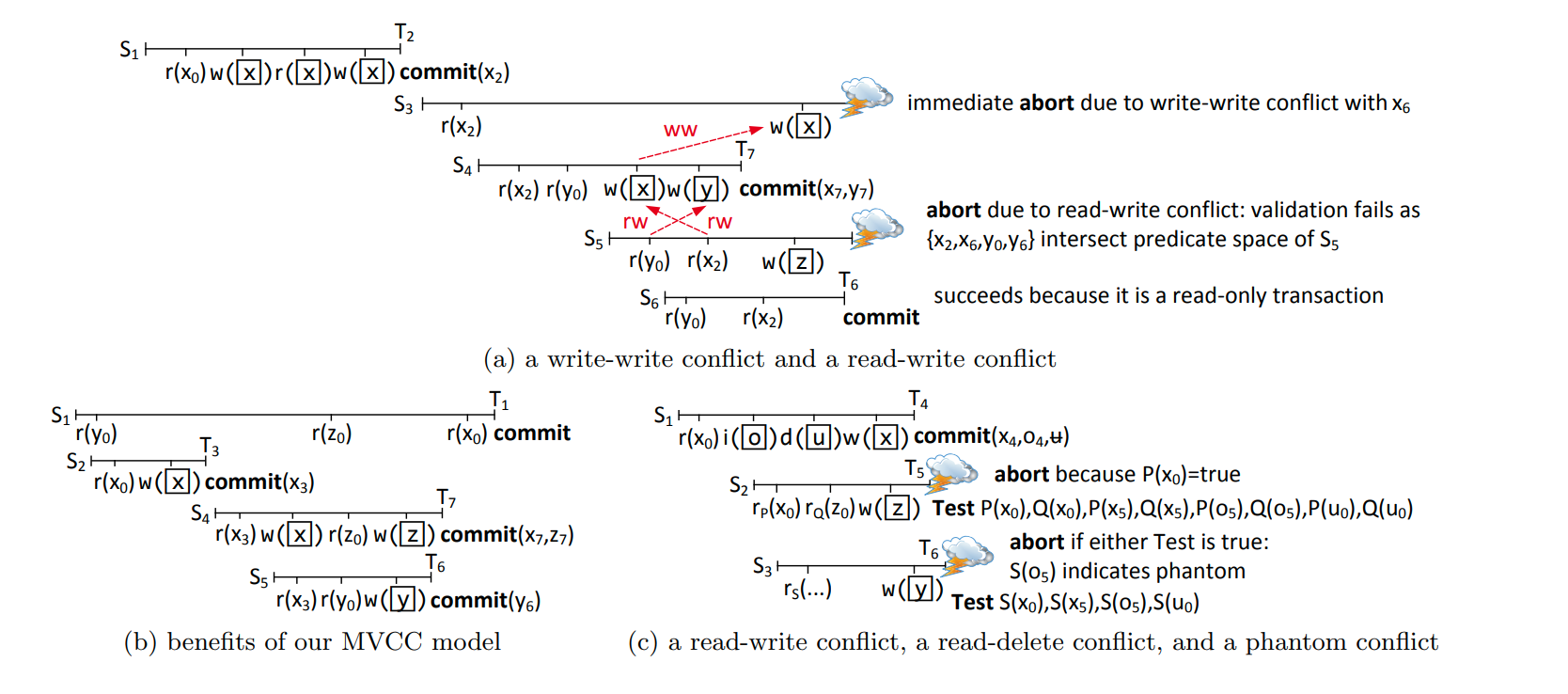
schedule的实例。其中图C值得仔细看一下。因为这里演示的是使用谓词的检查。我们用P和Q谓词读取了数据,在提交的时候就要验证最近的写入是否满足这两个谓词
后面是一个证明,但是感觉这个算法还比较直观,就不贴了。

文章评论