Abstract
他首先提出HTAP workload中,GC通常会成为bottleneck
现有的GC技术过于粗粒度。并且不能很好的处理sudden spike的workload
Introduction
MVCC的一个问题就是如果workload中有很多的long-running transactions,那么活跃的版本就会增加的非常快,并且我们不能删除掉这些版本因为他们可能要被活跃事务使用
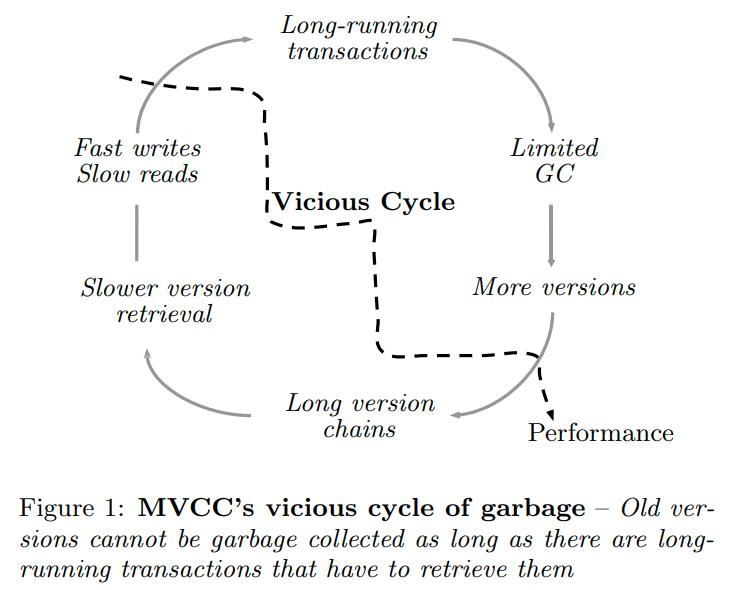
所以这些long-running transaction就会导致一个恶性循环
因为他们持续的越久,那么活跃的版本就越多,导致事务读的速度会更慢,从而导致更多的long-running transaction
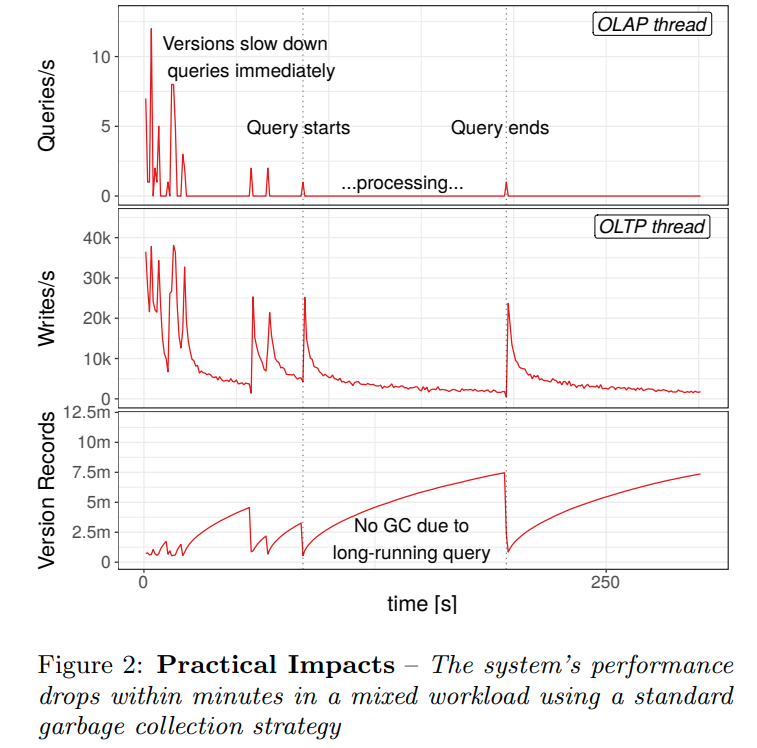
一个比较直观的图,显示了version的数量对于performance的影响
Versioning In MVCC
还是MVOCC可见性核心的一点,我们只能看到commitTimestamp小于我们的事务开始时间的元组
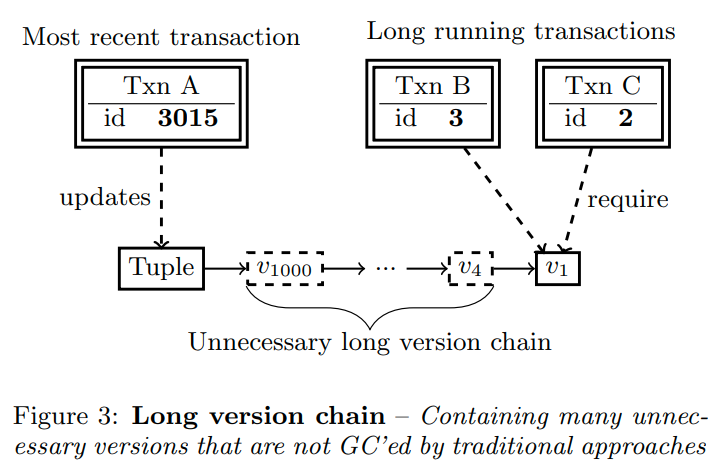
这里给出了一个示例,中间有很多无用的元组。其实从这里我们也可以有一定的感觉,他所谓的细粒度的GC就是不去维护high water mark,而是具体的可见性。
Identifying Obsolete Versions
可见的版本与并发运行的事务有关。即一个版本的生命周期取决于目前的活跃事务。
这里提到了,传统的垃圾回收器只会跟踪活跃事务中最老的那个timestamp。所以会得到一个比较粗粒度的估计,导致很多其实无用的版本不能被删除
Practical Impacts of GC
这里其实是一个对于figure1的解释
当出现长事务的时候,version record就会堆积。当reader结束的时候,writer才能开始清理这些元组,并且在GC的时候新的事务不能进行写操作。(这里的意思应该是后台的GC线程需要锁住版本链才能就检查是否需要进行GC,版本链越长进入临界区的时间也就越久,导致其他的写入会被阻塞)
并且随着版本的增多,读事务会越来越慢,导致更多的长事务
总结起来就是传统的垃圾回收器有三个缺点:
1. scalability due to global synchronization
2. vulnerability to long-living transactions
3. inaccuracy in garbage identification
(我感觉23其实是一个问题,细粒度的去检查就可以了,1他所谓的global synchronizatio我不太清楚,感觉可能是lock-free的GC方法,从而防止GC线程阻塞worker线程)
Garbage collection survey
通过在事务处理的过程中进行version prune,而非使用后台线程
他的系统还是基于HyPer的,所以应该是在txn提交的时候,我们应该有一段时间需要latch住undo buffer并修改timestamp,这个时候就可以进行GC
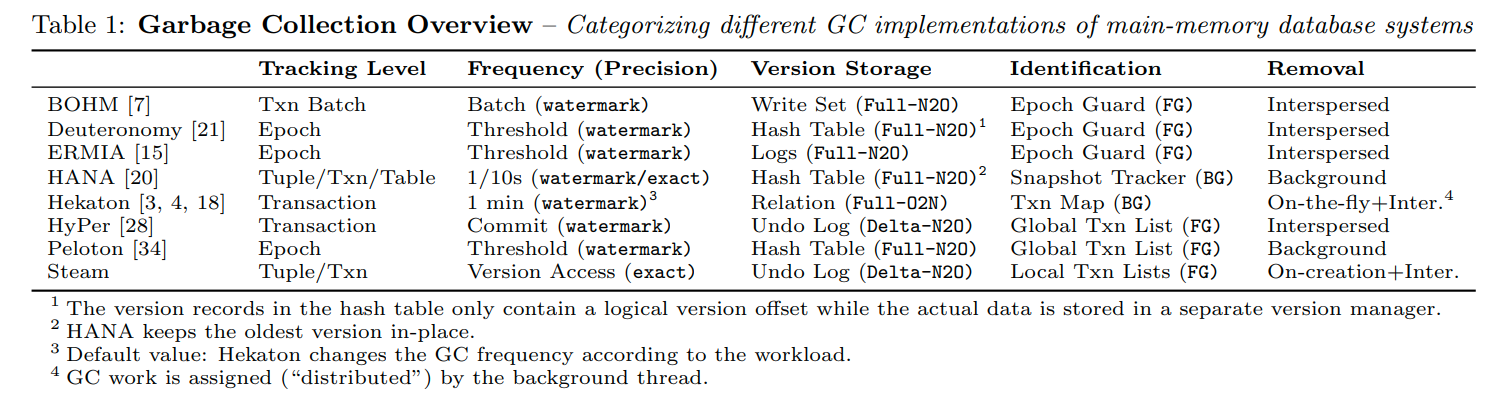
一个overview
Tracking Level
最细粒度的方法是tuple-level,GC线程会扫描每一个元组并识别他们是不是过期的元组
我们可以每过一段时间开启这个线程(bg),也可以在运行txn的时候去检查这些过时的元组(fg)
系统也可有以transaction为粒度去清理,因为一个txn中创建的所有版本都共享着同一个commit timestamp,所以如果他们不可见的时候,应该是同时不可见的。所以我们可以一次性识别并清除同一个txn中的版本(他这里说清理独立的版本可能会更慢一些,这里我不太明白,因为一个版本如果不可见了,那么和他同一个事务的版本也就不可见了。他的意思可能是一次要清除一个事务的版本会慢一些?但是这个可以通过事务级别的undo buffer来保证locality)
Epoch-based的方法是让若干个事务成为一个Epoch,这样我们就可以一个Epoch一个Epoch的清理
最粗粒度的方法就是table-level,当整个table不再使用的时候我们会清理他,或者说是一次锁住一整个表,然后清理,然后释放。
个人想法:所以粒度其实就是一次GC多少,tuple-level就是需要我们latch住tuple,然后回收。transaction level就是latch住一个txn的undo buffer,然后回收。这里具体的tracking level应该和我们怎么存储版本,怎么识别过时record是有关联的
Frequency and Precision
多久GC一次,以及清理的多干净。
比如Epoch的方法就是当到达阈值的时候,我们会前进一个Epoch,并把前一个epoch的version清除掉
还有就是很常见的后台线程。每过一段时间就开启一次去进行GC
还有batch-level的,但是这个感觉和Epoch的有点类似,每个batch结束都会确定这个batch的txn已经结束了,我们就可以安全的回收那些老版本
和上面说的一样,thoroughness和我们识别的方法是有很大关联的。对于timestamp-based的方法,他只会移除那些timestamp比high watermark还小的版本。所以会被长事务所影响。对于interval-based的方法来说,他们会做出更仔细的识别,并只保留那些必须的版本
Version Storage
很多的系统会将版本保存在一个全局的结构中,这可以让我们单独的回收每一个版本。但是缺点就是所有的版本都需要在这个global storage中去检查(我感觉他想说的意思是临界区太大,并且回收需要一个一个的扫描)
HyPer和Steam会把这些版本存储在与txn相关的buffer中,叫Undo Log。当txn落后于high watermark的时候,所有的版本都可以被直接回收。并且,单个版本也可以被独立的回收,我们只需要断开版本链即可。并且使用Undo Log存储是一个比较直观的事情,因为我们无论如何也需要这个信息做回滚,现在只是把它暴露给全局,可以让其他的事务去访问before-image(他这里提到了说我们断开版本链,但是这块内存是属于undo log的,还是需要等待整体的回收,所以内存的回收会被delay,可能就是他上面说的清楚独立版本会慢一点的原因)
Identification
这里说的就是检查的方法。
比如维护一个global txn map,可以让我们在常数时间内找到high watermark。虽然这个方法简化了version identification(我们只需要比较timestamp和high watermark),但是清理的不干净。
Steam和HANA的方法则是使用更细粒度的检测方法,这时候我们需要跟踪所有的活跃事务,并且对每一条version chain都做细粒度的检查
更加粗粒度的方法则是用Epoch来确定版本是否过期,相当于是一个对high watermark的一个近似。然而epoch方法会让我们的memory management更加轻松。Epoch guard会等待所有的线程离开这个epoch后,回收这个epoch使用的内存
和检查方法无关,检查可以在后台线程进行,也可以在前台进行
我在想识别和实际的回收是不是不是同步的呢?在disk-oriented的system中,这个是分开的,因为我们需要重新整理碎片,比如postgres。在主存数据库中这里应该可以直接释放,因为不会出现碎片(碎片被runtime管理了)
Removal
看起来Removal是实际清理的过程
HANA中,GC是通过后台线程进行的。Hekaton中则是clean on-the-fly
Epoch-based的系统貌似是在Epoch内进行重用,比如一个版本提交了,那么他的老版本就可以放到free-list中。(这里貌似说的不是很清楚,之后再看看)
HyPer和Steam则是在txn之间进行回收。当存在过期版本的时候,在txn提交的时候worker thread就会回收他们
感觉刚才说的这个里面有很多都是类似的概念
tracking level是一次回收多少版本
frequency是多久进行检查和回收
precision是指每次回收是不是干净
version storage指怎么存储版本数据
Identification指通过什么信息来识别过期版本
Removal指什么时候回收,和frequency的区别是frequency说的是时间上的。比如在commit的时候,每过一分钟等。而Removal说的是具体清理version的过程,比如是在后台清理,还是在运行txn的时候清理等(分散在txn之间还是在后台)
举个例子就是peleton,每个epoch他会识别出所有的过期的版本,然后后台线程会执行回收
而Steam,则是在创建的时候就去检查是否可以回收,同时在commit的时候也会检查是否可以回收Undo buffer(他的细粒度检索我猜测应该是在遍历版本链的时候去检查,比如说打标记或者一边遍历一边剪枝。然后在最后提交的时候把那些过期的版本回收)
Steam Garbage Collection
Basic Design
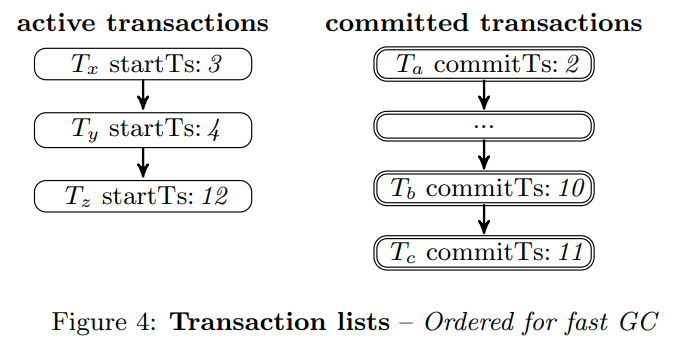
用两个链表来追踪active和committed txns(HANA和Hekaton用的是reference-counted list和map)
两个链表都是有序的,我们可以很快找到最老的active txn的timestamp
并且当active txn的timestamp大于commit txn的时候,我们就可以回收commit txn的Undo buffer
Scalable Synchronization
前面描述的方法虽然可以在常数时间内进行GC,但是他需要全局的txn list。从而导致无法scale
Steam没有像Hekaton那样使用了latch-free txn map,而是用了一种不需要同步的算法
这里还有一个点: For GC, we exploit the domain-specific fact that the correctness is not affected by keeping versions slightly longer than necessary-the versions can still be reclaimed in the "next round"
Steam中每一个线程都维护了目前txn的不相交子集。每个thread只会把他的thread-local minimum共享出来(通过64bit atomic integer)。其他的线程就可以读这个值,从而获取全局最小值
local minimum对应的是第一个活跃事务的时间戳。如果没有的话就设为一个极大值
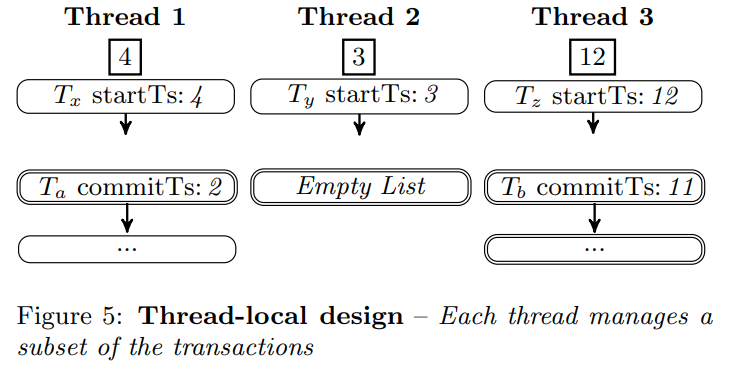
要确定全局最小值,我们需要扫描每个线程的局部最小(但是我想这样不还是会受到多核缓存一致性的问题么?和latch-free没啥区别)
Eager Pruning of Obsolete Versions
前面的方案只是避免了全局同步,但是没有处理long running txn的问题
这里提出来Eager Pruning,可以移除掉所有的不需要的版本
每个线程周期性的取出目前活跃事务的timestamp,并放到一个sorted list中
每当一个线程遇到了版本链的时候,他就会根据下面这个算法去清理掉所有过期的版本

其实就是针对active txn去合并版本链。
这里的意思就是找到第一个版本,然后对于所有的活跃事务,找到他看的版本。然后对于中间的版本(在figure1中就是中间无用的那些版本),我们会把它合并起来。但是注意这里只压缩了不属于attrs(visible)的版本
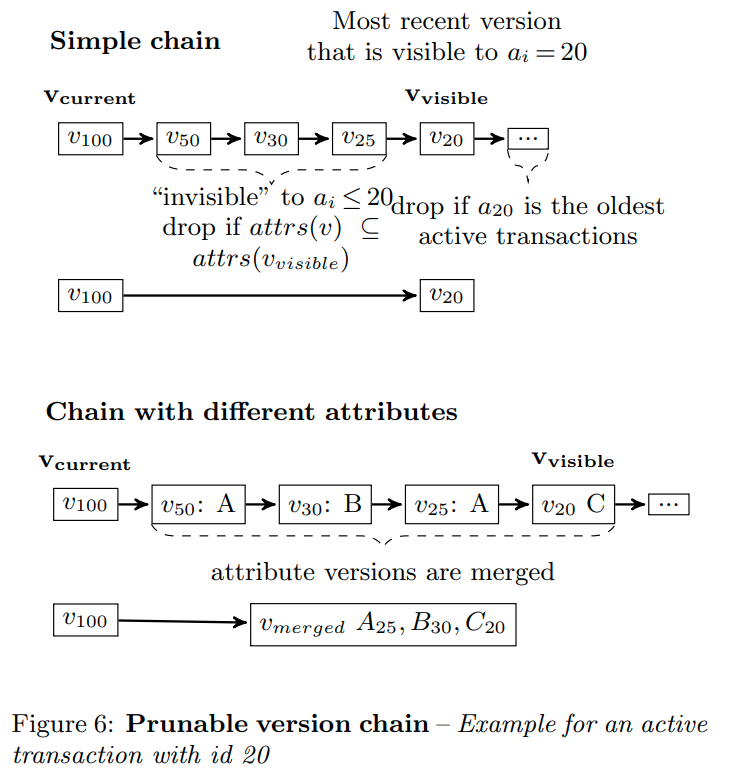
这个是一个剪枝的例子
一个直观的问题就是这样剪枝不会影响其他的txn么?比如我们压缩了其他txn要看到的东西
答案是不会,因为我们的合并是从最大到最小,所以第一个ai就是目前最大的txn,中间不会有其他的活跃事务,所以在figure6中v25会覆盖v50。并且在算法中他会把Vcurrent设成Vvisible,也就是上一次合并的版本。所以每次合并的时候,我们都会保证(Vcurrent, Vvisible)中间是没别人的
这就带来一个新的问题,他们怎么保证active txn是及时更新的呢?因为这个list的周期性更新的。我感觉我们还需要维护一些最值信息(比如只合并这个sortlist中的最大和最小的版本)
我突然想明白了,每个线程当前运行一个txn,所以线程数就是active txn的数量。所以我们从每个线程那里拿当前他的active txn id,然后创建成一个链表就可以。这么想我们找的第一个版本应该是当前事务看到的第一个版本。否则可能有更新的版本在被使用。
最准确的方法应该是每次latch住这个版本链的时候,拿到最新的活跃事务列表再去prune
但是他是每次update的时候才会去prune,那么如果已经有了新的txn来了,他如果更新了我们要去更新的地方,那么他就会进行prune,而我们会abort。(所以当更新失败的时候去更新active txn list是一个合理的选择?)
Short-Lived Transactions
对于没有长事务运行的workload来说,平常使用的GC就已经够用了,使用EPO还会额外的增加负担
但是现实世界的workload是很难预测的,所以我们去tradeoff这里的effectiveness和overhead
(这里的sorted list貌似是thread-local的)所以是每次运行transcation的时候去找活跃事务并创建sorted list
这里的优化就是不是每次都重新创建sorted list,而是重用他们(即更新的频率更小,但是对于长事务仍然有效,因为相比之下我们的活跃事务列表的更新还是更快一些)
但是貌似还是没说怎么取出活跃事务
HANA's Interval-Based GC
这里说Steam中的prune发生在update的时候,貌似还是会出问题,如果我们不能保证有所有的活跃事务的信息的话

什么叫piggybacking the costs while the chain is locked anyway?因为一个线程在访问version chain的时候他需要latch住这个chain,所以我们无论如何也需要去latch住这个chain,就不会出现后台GC线程和worker线程争用的情况了
Layout of Version Records

对version records的设计
这里提到了原子提交的事情,Version中有一个lock bit,用来保证提交是原子的(有点类似Hekaton)
他这里有一个bulk-insert的优化,就不提了
然后用AttributeMask可以加速我们检查一个attribute是否在另一个中。并且还节省了存储attributeID的空间
这里的结构应该和HyPer是一样的,就是原始的表中有数据,然后一个指针指向version vector,表示他这次的操作
Evaluation
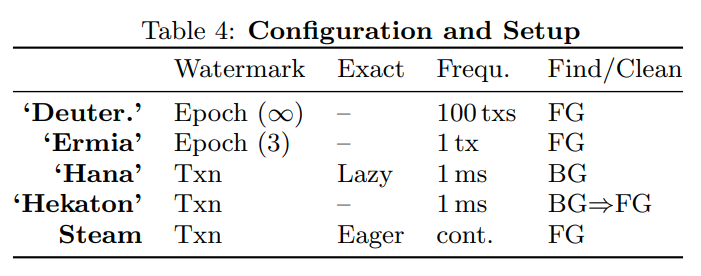
他这个table4的东西比上面清楚多了,就讲的是具体的实现
HANA中,整个GC的工作都是在后台进行的
Hekaton中,后台线程负责更新全局最小值,并识别过期的版本。然后把任务分配给worker线程让他们去清理这些版本

文章评论