这个paper提出了session guarantee从而可以避免弱一致性级别带来的问题,同时还可以保持弱隔离级别的优势
A session is an abstraction for the sequence of read and write operations performed during the execution of an application
提出session的目的不是为了和事务对应(事务是用来保证ACID的),session的目的则是为了给用户提供一个一致性的视角。
贴一下原文:Sessions are not intended to correspond to atomic transactions that ensure atomicity and serializability. Instead, the intent is to present individual applications with a view of the database that is consistent with their own actions, even if they read and write from various, potentially inconsistent servers.
我们希望在一个session中的操作可以像是在一个服务器上进行的一样
在session的基础上,提供了四个保证:
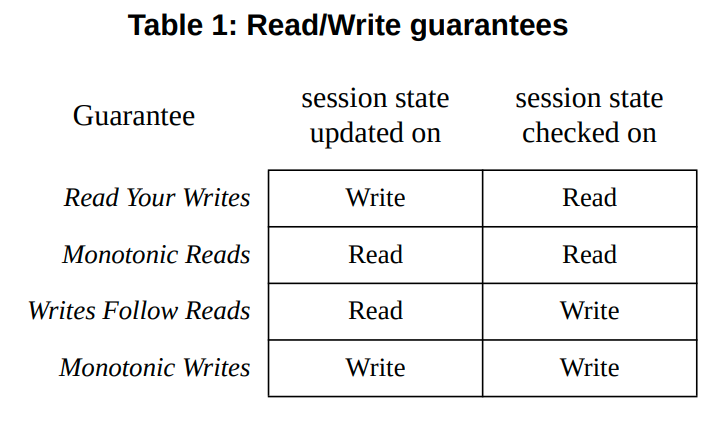
* Read Your Writes - read operations reflect previous writes
* Monotonic Reas - successive reads reflect a non-decreasing set of writes
* Writes Follow Reads - writes are propagated after reads on which they depend
* Monotonic Writes - writes are propagated after writes that logically precede them
我们可以通过在一些弱一致性的系统上构建一个层来提供上面的这些保证。我们通过让应用操作的这些服务器是足够up-to-date的,来提供上面的这些保证
Data storage model and terminology
假设下层的系统: Such a system consists of a number of servers that each hold a full copy of some replicated database and clients that run applications desiring access to the database.
session guarantees适用于那些客户和服务器处于不同的机器上,并且客户的访问会访问到不同的机器中的场景
比如一个移动客户端可能会根据他的地区来选择server
每一个写操作都有一个全局独一的标识符,称为WID
定义DB(S, t)为服务器S在t时间及以前收到的写操作的有序序列。概念上,服务器S从一个空的数据库开始,然后根据顺序apply接受到的写操作,与此同时处理读请求。现实中,服务器可以按照不同的顺序应用写操作,只要他们的效果是不变的就行(我猜测,可能是类似tomas写规则那样的?)。并且DB(S)中写操作的序列并不代表是他们接受到写操作的顺序(也就是说不是先接受就先应用,应该是根据WID来的)
我们假设底层的系统提供了最终一致性,那么也就提供了能够保证最终一致性的机制,即: total propagation和 consistent ordering
写操作通过反熵(anti-entropy)来在服务器之间进行传播,这个操作有的时候也叫做rumor mongering, lazy propagation, update dissemination。反熵保证了每一个写操作最终都会被每一个服务器接收到。(反熵带来了total propagation)
对于不可交换的操作(比如覆盖写),所有服务器必须有相同的应用顺序。形式化的说:定义WriteOrder(W1, W2)为一个布尔谓词,代表W1是否应该在W2之前。系统保证了如果有WriteOrder(W1, W2),那么对于任何的接收到W1和W2的服务器来说,W1被排序到W2之前。这篇文章对于系统如何保证Order没有任何的假设,他只假设了在每台服务器上写操作都有一个一致的顺序。(比如想要写操作match real time,我们可以用一个TSO来做order,如果没有要求的话可以通过logical lock来做order)
最后,弱一致性系统通常允许写冲突,比如两个并发的写同一个数据项。在某些系统中,Write order会决定那个写胜利了,也有的系统会让人来解决这些冲突。系统怎么解决这些冲突对于用户很关键,但是对我们的session guarantees不重要。(我感觉是因为我们的session guarantee说的是一个人的一系列操作能看到的事情,即看到一个一致的数据库,而上面的冲突解决说的是怎么处理并发的操作)
Read/Write guarantees
这一节就是定义一下,然后给了几个例子
Read Your Writes
RYW-guarantee: If Read R follows Write W in a session and R is performed at server S at time t, then W is included in DB(S, t)
Monotonic Reads
We say a Write set WS is complete for Read R and DB(S, t) if and only if WS is a subset of DB(S, t) and for any set WS2 that contains WS and is also a subset of DB(S, t), the result of R applied to WS2 is the same as the result of R applied to DB(S, t)
即对于R来说,WS是包含R中所有元素的最新的写操作的集合
Let RelevantWrites(S, t, R) denote the function that returns the smallest set of Writes that is complete for Read R and DB(S, t)
MR-guarantee: If Read R1 occurs before R2 in a session and R1 accesses server S1 at time t1 and R2 accesses server S2 at time t2, then RelevantWrites(S1, t1, R1) is a subset of DB(S2, t2)
也就是说t2时刻的S2至少要包含t1时刻S1中关于R1的写操作
Writes Follow Reads
这个我的理解就是因果一致性了(类似因果一致性但是不是,后面会说)
WFR-guarantee: If Read R1 precedes Write W2 in a session and R1 is performed at server S1 at time t1, then for any server S2, if W2 is in DB(S2), then any W1 in RelevantWrites(S1, t1, R1) is also in DB(S2) and WriteOrder(W1, W2)
解释一下就是如果读后写的时候,对于新的写操作应用在服务器上的时候,要保证之前读到的那些值也已经被应用了,并且之前的写要排序在新的写操作之前。
这个guarantee和之前的区别在于他是在说session之外的事情,即其他的client应该也能看到相同的写操作的顺序
对于这个保证,其实我们是保证了两件事。一个是写操作的顺序,我们保证有相关性的写操作是有序的。第二个则是传播的顺序,我们保证只有当看到了依赖的写操作后,才能看到之后的写操作。
WFRO(Order)-guarantee: If Read R1 precedes Write W2 in a session and R1 is performed at server S1 at time t1, then WriteOrder(W1, W2) for any W1 in RelevantWrites(S1, t1, R1)
WFRP(propagate)-guarantee: If Read R1 precedes Write W2 in a session and R1 is performed at server S1 at time t1, then for any server S2, if W2 is in DB(S2) then any W1 in RelevantWrites(S1, t1, R1) is also in DB(S2)
其实就是把上面的这个拆开了,一个保证的是WriteOrder(W1, W2),另一个保证的则是if W2 is in DB(S2), then W1 is also in DB(S2)
Monotonic Writes
MW-guarantee: If Write W1 precedes Write W2 in a session, then, for any server S2, if W2 in DB(S2) then W1 is also in DB(S2) and WriteOrder(W1, W2)
就是写操作要有序并且按序传播
防止immortal write
在某些情况下,MW可以通过WFR和RYW推出。但是有的时候不能,比如操作W1 R W2,对于MW来说,W1应该在W2前面,但是对于WFR和RYW来说,R有可能读到了其他的写操作Wx,那么因果就变成了Wx happen before W2了,而W1和W2就没有了关系
通过jepsen的这个图来想一下
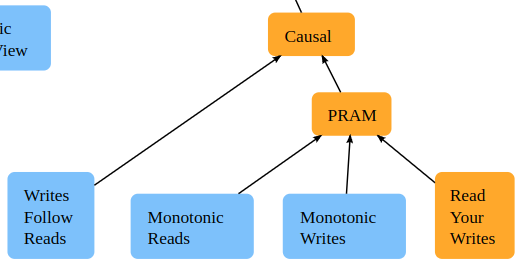
PRAM是pipelined random access memory,指的是读写操作是向流水线一样产生效果的,所以我们天然的就有了MW,MR以及RYW,因为读写操作不会沿着流水线往回走,所以他们只会越来越新
PRAM没有对跨越session的操作做任何保证,所以我们加上WFR,来保证跨session的操作的因果一致性,就得到了Causal consistency。那么WFR和Causal的区别是什么呢?就是对于单个session的操作的顺序的保证。因为WFR只保证了读写依赖的情况下的顺序,但是没有保证单个session情况下的读写顺序,而causal consistency是保证了的。更准确的来说,应该是happen before的关系
而对于sequential来说,则没有什么更多额外的保证,只是在不可比较的事件之间提供了一个全序关系,让我们可以排序没有因果的事件。那么有个问题就是,sequential是不是就没什么作用了,毕竟他也没提供real time的保证,只是排序了不相关的东西。其实不是,因为当我们无法排序不相关的事件的时候,那么我们就无法保证某一时刻数据库的一致性,比如两个写操作同时写入同一个数据项,怎么确保谁先谁后呢?就算是我们有确定的手段确保这个顺序,还是会有异常。比如我们某一时刻的读可能在两个不同的服务器上读到的是不同的状态,那么我们之后所做的抉择就取决于去那个服务器上读了,也是一个比较奇怪的现象。所以目前的系统如果可以都会提供这样的全序关系。
Providing the guarantees
有一个session manager负责维护信息,并负责与服务器通信
服务器需要提供给我们新的写操作对应的WID,读操作读到的数据对应的WID,以及当前数据库中所有的WID
session manager维护了两组集合
read-set = set of WIDs for the Writes that are relevant to session reads
write-set = set of WIDs for those writes performed in the session
RYW: 每次写操作被接受的时候,我们把返回的新的WID加入到write-set中,每次读的时候,session manager要检查write-set是当前数据库DB(S, t)的子集
MR:每次读取的时候,session manager要保证read-set是DB(S, t)的子集,并且每次读取结束以后,要把读到的数据对应的RelevantWrites(S, t, R)加入到读集中
实现WFR和MW需要我们添加两个限制:
C1. 当服务器S在t时刻接受一个新的写操作W2的时候,他要保证对于现在数据库中的所有写W1,都有WriteOrder(W1, W2). 即新的写操作要保证被排序到已有的写操作后面
C2. 在t时刻进行反熵,把W2从S1传播到S2的时候,我们要保证对于DB(S1, t)中所有的满足WriteOrder(W1, W2)的写操作W1,都已经被传播到了S2中。 即传播是按序的
个人的想法:其实这里的C2间接的让WFRP依赖于WFRO了,也就是传播顺序依赖于Ordering。其实应该有其他的方法去避免,但是我们这里没有细分WFR,所以就直接结合起来了。从这里也可以看出来ordering在propagating中的重要性
实际上,我们并不需要对于DB中所有的写操作都这样执行,而是只要保证session中的read-set和write-set中的写操作遵守这个规则就可以,因为有的写可以不走session。但是这需要服务器额外追踪读写集,不如全部满足更好
幸运的是,很多的系统都满足这样的条件。对于新的写操作来说,他应该被放置在已有的写操作的后面。如果我们通过timestamp来计算WriteOrder这个谓词的话,那么我们只要保证新的写操作的谓词在已有的后面即可。
WFR:和MR中相同,我们保证每次读取结束以后把对应的RelevantWrites(S, t, R)加入到读集中,然后在写的时候,我们保证当前服务器S1的DB(S1, t)包含read-set
MW:每次服务器接受一个写操作的时候,他的DB(S, t)必须已经包含了当前的write-set。并且返回的WID要被加入到write-set中
Practical implementation of the guarantees
上一节说到做法可能会导致一些问题:
* WID的集合可能很大
* 读操作对应的WID集合可能很大
* 在检查读写操作时候使用的WID集合可能很大
* 服务器记录WID的信息可能很大
* 查找一个有效的服务器可能会很费时
* 记录读操作对应的写操作这个过程可能会很多
这一节通过version vector来解决大多数的问题
每次写的时候,我们递增clock字段,这样(server, clock)就可以作为WID使用
invariant: if a server has (S, c) in its version vector, then it has received all Writes that were assigned a WID by server S before or at logical time c on S's clock.
根据这个invariant,服务器需要保证他们在反熵的时候,传播的顺序是根据WID的顺序来的。即当我们有(S, c)的数据的时候,之前的数据也应该被传过来。同时反熵的过程也会更新服务器的version vector
要为一组写集Ws获得一个version vector。我们令V[S] = the time of the latest WID assigned by server S in Ws(or 0 if no Writes are from S)
要获得两个写集的version vector的交集,我们只需要对于每一个服务器S,让V[S] = MAX(V1[S], V2[S])即可
要检查两个集合是否存在包含关系,我们只需要判断一个vector是不是dominates另一个,即对于每一个元素都存在大于或等于的关系
个人的想法:这样的话我们应该需要用logical clock作为version vector中的clock,否则无法满足新的写操作被排序在已有的写操作的后面。并且还有一个额外的问题,就是反熵的时候,我们不仅需要保证同一个服务器中的数据是按序的,还需要保证跨服务器的有依赖的写操作也是按序传播的
并且我们无法很好的计算出读请求的RelevantWrites,因为这需要我们跟踪每个元组对应的version vector。所以我们可以让当前服务器的version vector作为这次读操作的RelevantWrites的一个近似

通过version vector简化了实现
这里是我自己想的一个反熵的算法,目的是为了保证传播顺序
因为version vector可以天然的帮我们保证一个服务器上的写是按序传播的。但是不保证不同服务器上有依赖的写是按序的。比如我们有两个写对应的是<S1, C1>和<S2, C2>,先在S1上写,然后到S2上,发现S1的写被传播过来,然后再写。这时候我们就需要保证MW,即在S2传播给其他服务器,比如说S3的时候,要保证首先把S1的写传过去,再传S2的写。
首先通过logic clock保证C2 > C1,即WriteOrder(<S1, C1>,<S2, C2>)
然后在反熵的过程中,S2会给S3传数据,首先他会要求获得S3的version vector
然后他会尝试传播属于自己的写操作,即<S2, C2>这个数据。在传播之前检查,S3的version vector里是否满足了对于所有的满足WriteOrder(<S, C>, <S2, C2>)的数据项<S, C>,他们是否已经被传播到S3中了。
换句话说,我们不希望存在一个S2中的数据项<St, Ct>,使得,WriteOrder(<St, Ct>, <S2, C2>)且<St, Ct> > <St, Cx> where <St, Cx> from S3
实现上来说,我们可以简单的对比S2和S3的version vector,如果他小于S3肯定是没问题的,但是对于某一些服务器对应的项大于S3的version vector的,同时这个项是小于我们要传播的项的,我们就可以把他放到<S2, C2>前面,保证写操作的按序的
对于存储对应的数据,可能要通过logging,或者让WID作为主键直接查找。logging更容易一些,但是需要我们做GC。什么时候GC也是一个要考虑的问题

文章评论